Tác giả: Manu Pillai, Gabriel Hernandez, Heejoon Jo, Joe Warren, Natalia Jimenez, Marissa Powers, Sean O’Dell, và Shyamal Mehtalia
Ngày phát hành: 20 JAN 2026
Chuyên mục: AWS Batch, High Performance Computing, Life Sciences
Bài viết này được đóng góp bởi Manu Pillai (AWS), Marissa E Powers PhD (AWS), Sean O’Dell (AstraZeneca), Gabriel Hernandez (AstraZeneca), Heejoon Jo (Illumina), Shyamal Mehtalia (Illumina), Joe Warren (AWS), và Natalia Jimenez PhD (AWS).
Nghiên cứu gen đòi hỏi sức mạnh tính toán khổng lồ để xử lý và phân tích các trình tự DNA, từ đó khám phá những hiểu biết sâu sắc về sức khỏe và bệnh tật của con người. Đối với các công ty dược phẩm, việc xử lý hàng triệu bộ gen một cách hiệu quả và bền vững là yếu tố then chốt để đẩy nhanh quá trình khám phá và phát triển các liệu pháp trong tương lai, có tiềm năng giúp con người sống lâu hơn, khỏe mạnh hơn.
Khi cơ sở hạ tầng đám mây phát triển, nhiều tổ chức đối mặt với thách thức di chuyển sang các instance mới hơn, mạnh mẽ hơn trong khi vẫn duy trì tính toàn vẹn của nghiên cứu và quản lý chi phí. Khi các instance Amazon Elastic Compute Cloud (Amazon EC2) F1 sắp hết hạn dịch vụ vào năm 2025, các tổ chức dựa vào các instance dựa trên Field-Programmable Gate Array (FPGA) để xử lý dữ liệu di truyền có thể cần một lộ trình rõ ràng để không ảnh hưởng đến các khối lượng công việc quan trọng.
Trong bài viết này, chúng tôi mô tả một đánh giá có cấu trúc về các instance Amazon EC2 F2 cho các khối lượng công việc genomics được tăng tốc, tập trung vào hiệu suất, chi phí và sự tương đương đầu ra so với các thế hệ instance dựa trên FPGA trước đó.
Thách thức: Đảm bảo cơ sở hạ tầng gen trong tương lai
Trung tâm Nghiên cứu Gen (CGR) của AstraZeneca tích hợp dữ liệu gen và lâm sàng quy mô lớn, tận dụng các phương pháp đa-omics—genomics, transcriptomics, proteomics và metabolomics—ở quy mô dân số, biến nó thành một trong những bộ dữ liệu lớn nhất và đa dạng nhất trên toàn cầu.
CGR sử dụng các khối lượng công việc Illumina DRAGEN®[1] (Dynamic Read Analysis for GENomics) để xử lý dữ liệu Whole Exome Sequencing (WES) và Whole Genome Sequencing (WGS). Với việc các instance F1 sắp hết hạn dịch vụ, chúng tôi đã đánh giá các instance F2 như một giải pháp thế hệ tiếp theo để tiếp tục các khối lượng công việc mà không bị gián đoạn.
Giải pháp: Kiểm thử di chuyển toàn diện từ F1 sang F2
Trong sự hợp tác với AstraZeneca và Illumina, AWS đã dẫn đầu các thử nghiệm rộng rãi so sánh hiệu suất của các instance F1 và F2 trên nhiều khối lượng công việc gen và các AWS Region.
Phương pháp kiểm thử
Nhóm đã thiết kế một đánh giá toàn diện bằng cách sử dụng:
- Phân tích mẫu: 11 mẫu gen (5 WES và 6 WGS) đại diện cho các khối lượng công việc nghiên cứu điển hình
- Kiến trúc: AWS Batch với các hàng đợi tính toán riêng biệt cho các instance F1 và F2
- Phiên bản Illumina DRAGEN: v3.7.8 cho xử lý WGS, v4.3.6 cho xử lý WES
- Xác thực đa Region: Kiểm thử trên ba AWS Region để đảm bảo khả năng mở rộng toàn cầu
- Các chỉ số hiệu suất: So sánh thời gian chạy và phân tích chi phí cho các khối lượng công việc giống hệt nhau
- Xác thực: Một phương pháp chính thức để xác thực sự tương đương về gen
Kiến trúc đã tận dụng hệ thống quy trình làm việc Nextflow với AWS Batch (một dịch vụ điện toán hàng loạt được quản lý hoàn toàn) để điều phối việc thực thi pipeline DRAGEN, cho phép các điều kiện kiểm thử nhất quán trên cả hai loại instance.
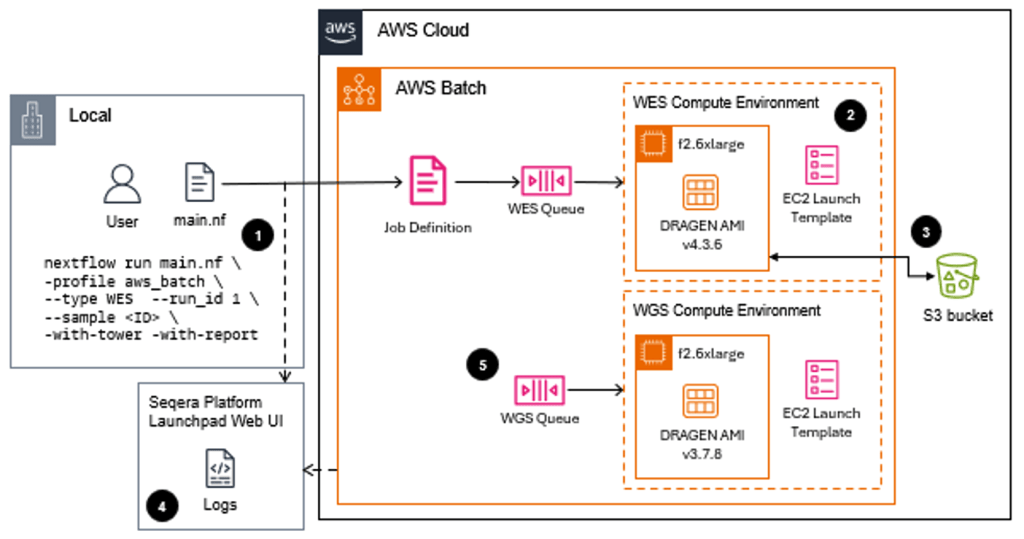
Hình 1 – Sơ đồ này cho thấy môi trường kiểm thử đám mây được sử dụng để so sánh hiệu suất của các instance F1 và F2 cho xử lý gen. Người dùng gửi các quy trình làm việc DRAGEN thông qua Nextflow, điều phối các môi trường tính toán AWS Batch riêng biệt cho các mẫu Whole Exome Sequencing (WES) và Whole Genome Sequencing (WGS) trên các instance F2.6xlarge. Kiến trúc tiêu chuẩn hóa cho phép so sánh hiệu suất chính xác bằng cách duy trì điều phối quy trình làm việc giống hệt nhau trong khi chỉ thay đổi cơ sở hạ tầng tính toán bên dưới, đảm bảo rằng việc cải thiện hiệu suất 60% và giảm chi phí 70% có thể được quy chính xác cho các instance F2.
Kết quả: Cải thiện đáng kể về hiệu suất và chi phí
Các thử nghiệm đã tiết lộ những cải thiện đáng kể khi di chuyển từ các instance F1 sang F2:
Lợi ích chính
- Xử lý nhanh hơn 60%: Giảm đáng kể thời gian chạy phân tích gen
- Giảm 70% chi phí: Tiết kiệm đáng kể chi phí tính toán
- Cải thiện tính bền vững: Giảm sử dụng năng lượng và lượng khí thải carbon liên quan bằng cách hoàn thành khối lượng công việc hiệu quả hơn
- Khả năng mở rộng nâng cao: Cải thiện hiệu suất trên nhiều AWS Region
- Duy trì độ chính xác: Không ảnh hưởng đến tính toàn vẹn của dữ liệu nghiên cứu
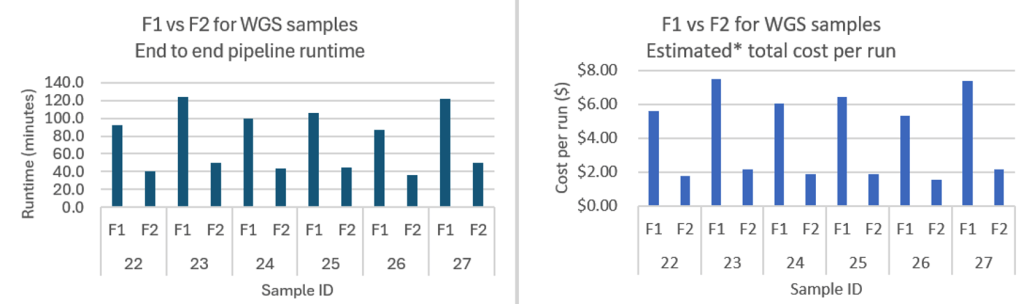
Hình 2 – Biểu đồ này so sánh hiệu suất của các instance F1.4xlarge và F2.6xlarge cho sáu mẫu Whole Genome Sequencing, hiển thị cả thời gian chạy (tính bằng phút) và chi phí mỗi lần chạy (tính bằng đô la). Các instance F2 liên tục mang lại thời gian xử lý nhanh hơn tới 60% và chi phí thấp hơn 70% trên tất cả các mẫu, chứng minh những cải thiện hiệu suất đáng kể và tiết kiệm chi phí mà các tổ chức có thể đạt được khi nâng cấp từ các instance F1 lên F2 cho các khối lượng công việc gen. Giá On Demand cho f1.4xlarge ở eu-west-1 và f2.6xlarge ở eu-west-2 tính đến ngày 16/9/2025.
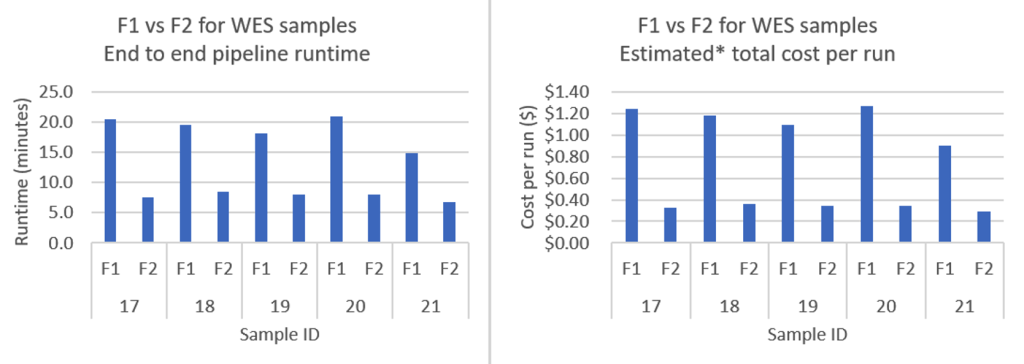
Hình 3 – Biểu đồ này so sánh hiệu suất của các instance F1.4xlarge và F2.6xlarge cho năm mẫu Whole Exome Sequencing, hiển thị cả thời gian chạy (tính bằng phút) và chi phí mỗi lần chạy (tính bằng đô la). Các instance F2 liên tục mang lại thời gian xử lý nhanh hơn tới 63% và chi phí thấp hơn 74% trên tất cả các mẫu, chứng minh những cải thiện hiệu suất đáng kể và tiết kiệm chi phí mà các tổ chức có thể đạt được khi nâng cấp từ các instance F1 lên F2 cho các khối lượng công việc giải trình tự exome. Giá On Demand cho f1.4xlarge ở eu-west-1 và f2.6xlarge ở eu-west-2 tính đến ngày 16/9/2025.
Xác thực sự tương đương
Để đánh giá sự tương đương đầu ra của Illumina DRAGEN giữa các dòng instance AWS F1 và F2, chúng tôi đã đánh giá đầu ra cho năm mẫu được xử lý trên mỗi loại instance và so sánh đầu ra ở ba cấp độ: các chỉ số pipeline, nguồn gốc lệnh và các biến thể được gọi. Đối với các lần chạy tương tự, chúng tôi kỳ vọng kết quả giống hệt nhau trên các instance. Trên thực tế, mọi giá trị và biến thể phải khớp chính xác, với sự khác biệt chỉ giới hạn ở các siêu dữ liệu không xác định như dấu thời gian, đường dẫn tệp hoặc nhãn mẫu.
Nguồn gốc lệnh: Để xác minh rằng các pipeline được gọi giống hệt nhau, chúng tôi đã trích xuất các dòng lệnh DRAGEN từ các tiêu đề VCF và so sánh chúng bằng các công cụ bash. Các lệnh và cờ khớp chính xác giữa các lần chạy F1 và F2, đảm bảo phân tích được thực hiện với cùng cấu hình và tham số.
So sánh chỉ số: Chúng tôi đã so sánh các chỉ số do DRAGEN tạo ra bằng cách sử dụng các tiện ích bash tiêu chuẩn (ví dụ: diff) trên các tệp sau: gc_metrics, mapping_metrics, roh_metrics, sv_metrics và vc_metrics. Trên tất cả năm mẫu, các chỉ số giống hệt nhau giữa đầu ra F1 và F2 ngoại trừ các giá trị mà chúng tôi kỳ vọng sẽ thay đổi (ví dụ: tên, ngày/dấu thời gian). Điều này xác nhận rằng việc căn chỉnh, gọi biến thể và thống kê tóm tắt có thể tái tạo trên cả hai loại instance.
Sự phù hợp của VCF: Chúng tôi đã đánh giá sự phù hợp ở cấp độ biến thể bằng cách sử dụng bcftools isec, công cụ này thực hiện các phép toán tập hợp trên các tệp VCF bằng cách coi mỗi tệp là một tập hợp các bản ghi biến thể. Nó tính toán các giao điểm (các biến thể có mặt trong cả hai tệp) và sự khác biệt (các biến thể chỉ có trong một tệp), biến nó thành một cách thực tế để định lượng sự phù hợp giữa các đầu ra. Trong quy trình làm việc của chúng tôi, chúng tôi đã chạy bcftools isec trên các VCF được ghép nối (F1 so với F2) cho mỗi mẫu. Công cụ này ghi ra các tệp riêng biệt tương ứng với những điều sau:
- Các biến thể chỉ có trong VCF đầu tiên (ví dụ: 0000.vcf)
- Các biến thể chỉ có trong VCF thứ hai (ví dụ: 0001.vcf)
- Các biến thể chung cho cả hai VCF (giao điểm, ví dụ: 0002.vcf và 0003.vcf)
Sau đó, chúng tôi đã đếm các biến thể trong mỗi đầu ra để đo lường sự trùng lặp và khác biệt, loại trừ các dòng tiêu đề bắt đầu bằng # hoặc ##. Trong trường hợp tương đương hoàn toàn, các đầu ra duy nhất phải trống và các tệp giao điểm phải chứa tất cả các biến thể, do đó số lượng bản ghi giao điểm khớp với bản gốc.
# Run bcftools isec$> bcftools isec -p results sample1_f1.vcf.gz sample1_f2.vcf.gz# Count variant records (exclude header lines)$> grep -c -v "^#" results/*.vcf0000.vcf:00001.vcf:00002.vcf:2991310003.vcf:299131Trên tất cả năm mẫu, bcftools isec cho thấy giao điểm chứa tất cả các biến thể, và các tập hợp duy nhất trống rỗng, cho thấy không có sự khác biệt ở cấp độ biến thể giữa đầu ra F1 và F2. Nói cách khác, các VCF hoàn toàn phù hợp.
Tóm lại, dưới các cấu hình DRAGEN giống hệt nhau, các instance Amazon EC2 F1 và F2 tạo ra các đầu ra tương đương ở cả cấp độ chỉ số và biến thể. Các chỉ số chỉ khác nhau ở các siêu dữ liệu không xác định, dự kiến (dấu thời gian và nhãn mẫu), và bcftools isec cho thấy các giao điểm biến thể chứa tất cả các cuộc gọi mà không có sự khác biệt duy nhất. Những kết quả này hỗ trợ việc chạy các pipeline gen DRAGEN một cách hoán đổi trên F1 và F2.
Tác động: Đẩy nhanh khám phá gen
Dữ liệu cho thấy rằng việc di chuyển thành công bao gồm những lợi thế vượt ra ngoài việc nâng cấp cơ sở hạ tầng đơn giản hơn. Các lợi ích tức thì bao gồm việc thiết lập một lộ trình di chuyển rõ ràng, đã được xác thực từ các instance F1 sang F2, đảm bảo tính liên tục của hoạt động kinh doanh và đạt được tối ưu hóa đáng kể về chi phí và lượng khí thải CO2 cho các khối lượng công việc gen quy mô lớn.
Kết luận
Kết quả chứng minh cách sự phát triển của cơ sở hạ tầng đám mây có thể thúc đẩy cải thiện hiệu quả trong khả năng nghiên cứu gen. Việc cải thiện hiệu suất 60%, giảm chi phí 70%, cũng như cải thiện tính bền vững đạt được thông qua việc di chuyển instance F2 cung cấp dữ liệu thuyết phục có thể hữu ích cho các tổ chức đang tìm cách tối ưu hóa khối lượng công việc xử lý gen của họ.
Đối với các nhóm genomics hiện đang sử dụng các instance F1, nghiên cứu xác thực này mang lại sự tự tin trong việc di chuyển sang các instance F2 trong khi vẫn duy trì tính toàn vẹn của nghiên cứu và đạt được những lợi ích hoạt động đáng kể.
Để tìm hiểu thêm về các instance AWS F2 cho các khối lượng công việc genomics, hãy truy cập Genomics on AWS. Để được hướng dẫn triển khai DRAGEN, hãy khám phá trang thông tin sản phẩm Illumina DRAGEN.
[1] DRAGEN® là nhãn hiệu đã đăng ký của Illumina Inc.
Về tác giả

Manu Pillai
Manu Pillai là Kiến trúc sư Giải pháp Chuyên gia cấp cao tại AWS, tập trung vào điện toán hiệu năng cao và các giải pháp đám mây cho các tổ chức khoa học đời sống. Với hơn 12 năm kinh nghiệm trong ngành khoa học đời sống, ông mang đến chuyên môn sâu rộng để giúp các tổ chức tận dụng công nghệ đám mây nhằm thúc đẩy khám phá khoa học. Ông thích khám phá những điểm đến mới cùng gia đình khi không tìm hiểu những đổi mới công nghệ mới nhất.

Gabriel Hernandez
Gabriel Hernandez là nhà khoa học gen và tin sinh học tại Trung tâm Nghiên cứu Gen (CGR) của AstraZeneca. Anh giải quyết các vấn đề bằng cách kết hợp chuyên môn tính toán và sinh học để tìm ra câu trả lời một cách hiệu quả. Công việc của anh tập trung vào việc tìm hiểu dữ liệu gen để cải thiện cách nó được xử lý và phân tích.

Heejoon Jo
Heejoon Jo là Kỹ sư Phần mềm cấp cao tại Illumina Inc., làm việc trong bộ phận Kiến trúc Giải pháp Phần mềm. Anh tập trung vào hợp tác và đổi mới với khách hàng, đặc biệt nhấn mạnh vào DRAGEN. Heejoon dẫn dắt việc phát triển và bảo trì pipeline cho DRAGEN, đồng thời cung cấp hỗ trợ kỹ thuật cho các nhóm bán hàng và thương mại. Anh có kinh nghiệm sâu rộng trong lĩnh vực gen ung thư và ứng dụng các phương pháp thống kê. Heejoon có bằng Thạc sĩ Thống kê Sinh học từ Đại học North Carolina tại Chapel Hill.

Joe Warren
Joe Warren là Giám đốc Tài khoản Toàn cầu tại AWS, chuyên về các giải pháp Dữ liệu, AI & ML cho khoa học đời sống. Trong hơn 4 năm, ông đã thúc đẩy chuyển đổi khối lượng công việc khoa học trên chuỗi giá trị của AstraZeneca, mang đến những đổi mới dựa trên đám mây để đẩy nhanh kết quả nghiên cứu. Ông sống tại NYC kể từ khi chuyển từ London vào năm 2023.

Natalia Jimenez
Natalia Jimenez là chuyên gia điện toán hiệu năng cao trong khoa học đời sống tại AWS. Cô có bằng Tiến sĩ Sinh học Phân tử và hơn 25 năm kinh nghiệm trong lĩnh vực nghiên cứu và công nghệ. Cô đến từ Tây Ban Nha nhưng hiện sống ở Cambridge, Vương quốc Anh và thích giao lưu, đạp xe và làm vườn.

Marissa Powers
Marissa Powers là kiến trúc sư giải pháp chuyên gia tại AWS, tập trung vào điện toán hiệu năng cao và khoa học đời sống. Cô có bằng Tiến sĩ về khoa học thần kinh tính toán và thích làm việc với các nhà nghiên cứu và nhà khoa học để đẩy nhanh khối lượng công việc khám phá thuốc của họ. Cô sống ở Boston cùng gia đình và là một fan hâm mộ lớn của các môn thể thao mùa đông và các hoạt động ngoài trời.

Sean O’Dell
Sean O’Dell là một chuyên gia giàu kinh nghiệm trong lĩnh vực dữ liệu đám mây và gen, chuyên thiết kế, xây dựng và vận hành các giải pháp đám mây có khả năng mở rộng cao cho gen và khoa học đời sống. Với sứ mệnh khai thác công nghệ để thúc đẩy đổi mới, Sean dẫn dắt một nhóm các nhà phát triển phần mềm, kỹ sư và kiến trúc sư tại Trung tâm Nghiên cứu Gen (CGR) của AstraZeneca. Mục tiêu chính của anh là trao quyền cho các nhà khoa học với những hiểu biết sâu sắc có thể hành động được từ các bộ dữ liệu khổng lồ.

Shyamal Mehtalia
Shyamal Mehtalia là Giám đốc Quản lý Sản phẩm Kỹ thuật tại Illumina, nơi ông hợp tác chặt chẽ với các nhóm phát triển và khách hàng để xác định các tính năng và lộ trình cho giải pháp phân tích thứ cấp hàng đầu của Illumina, DRAGEN. Shyamal gia nhập Illumina vào tháng 5 năm 2018 như một phần của thương vụ mua lại Edico Genome, công ty đã phát minh ra nền tảng DRAGEN, nơi ông giữ vai trò Giám đốc Vận hành trong ba năm. Trước đó, ông giữ vai trò lãnh đạo trong lĩnh vực di động không dây để phát triển phần mềm. Shyamal có bằng thạc sĩ kỹ thuật điện từ Đại học Texas A&M.
