Tác giả: Naresh Dhiman, Archana Sharma, Ron Kolwitz, và Karan Lakhwani
Ngày phát hành: 21 JAN 2026
Chuyên mục: Advanced (300), Amazon Aurora, Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Simple Storage Service (S3), PostgreSQL compatible, Technical How-to
Các khách hàng di chuyển từ cơ sở dữ liệu Oracle tại chỗ sang AWS phải đối mặt với một thách thức: di chuyển hiệu quả các kiểu dữ liệu đối tượng lớn (LOBs) sang bộ nhớ đối tượng trong khi vẫn duy trì tính toàn vẹn và hiệu suất dữ liệu. Thách thức này bắt nguồn từ thiết kế cơ sở dữ liệu doanh nghiệp truyền thống, nơi LOBs được lưu trữ cùng với dữ liệu có cấu trúc, dẫn đến các hạn chế về dung lượng lưu trữ, độ phức tạp của sao lưu và các nút thắt cổ chai về hiệu suất trong quá trình truy xuất và xử lý dữ liệu. LOBs, có thể bao gồm hình ảnh, video và các tệp lớn khác, thường khiến các quá trình di chuyển dữ liệu truyền thống bị chậm và gặp vấn đề cắt cụt LOB. Những vấn đề này đặc biệt nghiêm trọng đối với các quá trình di chuyển kéo dài nhiều năm.
Trong bài viết này, chúng tôi trình bày một giải pháp có khả năng mở rộng sử dụng Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Aurora PostgreSQL-Compatible Edition, và Amazon MSK Connect. Việc truyền dữ liệu cho phép sao chép dữ liệu, trong đó các sửa đổi được gửi và nhận trong một luồng liên tục, cho phép cơ sở dữ liệu đích truy cập và áp dụng các thay đổi theo thời gian thực. Giải pháp này tạo ra các sự kiện cho các hành động cơ sở dữ liệu như chèn, cập nhật và xóa, kích hoạt các hàm AWS Lambda để tải xuống LOBs từ cơ sở dữ liệu Oracle nguồn và tải chúng lên các bucket Amazon Simple Storage Service (Amazon S3). Đồng thời, các sự kiện truyền dữ liệu di chuyển dữ liệu có cấu trúc từ cơ sở dữ liệu Oracle sang cơ sở dữ liệu đích trong khi vẫn duy trì liên kết thích hợp với các LOBs tương ứng của chúng.
Việc triển khai hoàn chỉnh có sẵn trên GitHub, bao gồm mã triển khai AWS Cloud Development Kit (AWS CDK), các tệp cấu hình và hướng dẫn thiết lập.
Tổng quan giải pháp
Mặc dù các quá trình di chuyển cơ sở dữ liệu Oracle truyền thống xử lý dữ liệu có cấu trúc hiệu quả, nhưng chúng gặp khó khăn với LOBs có thể bao gồm hình ảnh, video và tài liệu. Các quá trình di chuyển này thường thất bại do giới hạn kích thước và các vấn đề cắt cụt, tạo ra những rủi ro kinh doanh đáng kể, bao gồm mất dữ liệu, thời gian ngừng hoạt động kéo dài và chậm trễ dự án có thể buộc bạn phải trì hoãn các sáng kiến chuyển đổi đám mây của mình. Vấn đề trở nên nghiêm trọng hơn trong các quá trình di chuyển kéo dài nhiều năm, nơi việc duy trì tính liên tục hoạt động là rất quan trọng. Giải pháp này giải quyết các thách thức chính của việc di chuyển LOB, cho phép hoạt động liên tục, dài hạn mà không ảnh hưởng đến hiệu suất hoặc độ tin cậy.
Bằng cách loại bỏ các giới hạn kích thước liên quan đến các công nghệ di chuyển truyền thống, giải pháp của chúng tôi cung cấp một khuôn khổ mạnh mẽ giúp bạn di chuyển LOBs một cách liền mạch trong khi vẫn duy trì tính toàn vẹn dữ liệu trong suốt quá trình.
Cách tiếp cận của chúng tôi sử dụng kiến trúc truyền dữ liệu hiện đại để giảm bớt các hạn chế truyền thống của việc di chuyển LOB từ Oracle. Giải pháp bao gồm các thành phần cốt lõi sau:
- Amazon MSK – Cung cấp cơ sở hạ tầng truyền dữ liệu.
- Amazon MSK Connect – Sử dụng hai trình kết nối:
- Debezium Connector for Oracle làm trình kết nối nguồn để thu thập các thay đổi cấp hàng xảy ra trong cơ sở dữ liệu Oracle. Trình kết nối phát ra các sự kiện thay đổi và xuất bản lên một topic Kafka nguồn.
- Debezium Connector for JDBC làm trình kết nối đích để tiêu thụ các sự kiện từ topic Kafka nguồn và sau đó ghi các sự kiện đó vào Aurora PostgreSQL-Compatible bằng cách sử dụng trình điều khiển JDBC.
- Hàm Lambda – Được kích hoạt bởi ánh xạ nguồn sự kiện tới Amazon MSK. Hàm xử lý các sự kiện từ topic Kafka nguồn, trích xuất khóa chính hàng Oracle từ mỗi payload sự kiện. Nó sử dụng khóa này để tải xuống dữ liệu BLOB tương ứng từ cơ sở dữ liệu Oracle nguồn và tải nó lên Amazon S3, tổ chức các tệp theo các thư mục khóa chính để duy trì liên kết đơn giản với các bản ghi cơ sở dữ liệu quan hệ.
- Amazon RDS for Oracle – Amazon Relational Database Service (Amazon RDS) for Oracle được sử dụng làm cơ sở dữ liệu nguồn để mô phỏng cơ sở dữ liệu Oracle tại chỗ.
- Aurora PostgreSQL-Compatible – Được sử dụng làm cơ sở dữ liệu đích cho dữ liệu đã di chuyển.
- Amazon S3 – Được sử dụng làm bộ nhớ đối tượng để lưu trữ dữ liệu BLOB từ cơ sở dữ liệu nguồn.
Sơ đồ sau đây cho thấy kiến trúc giải pháp di chuyển dữ liệu LOB từ Oracle.
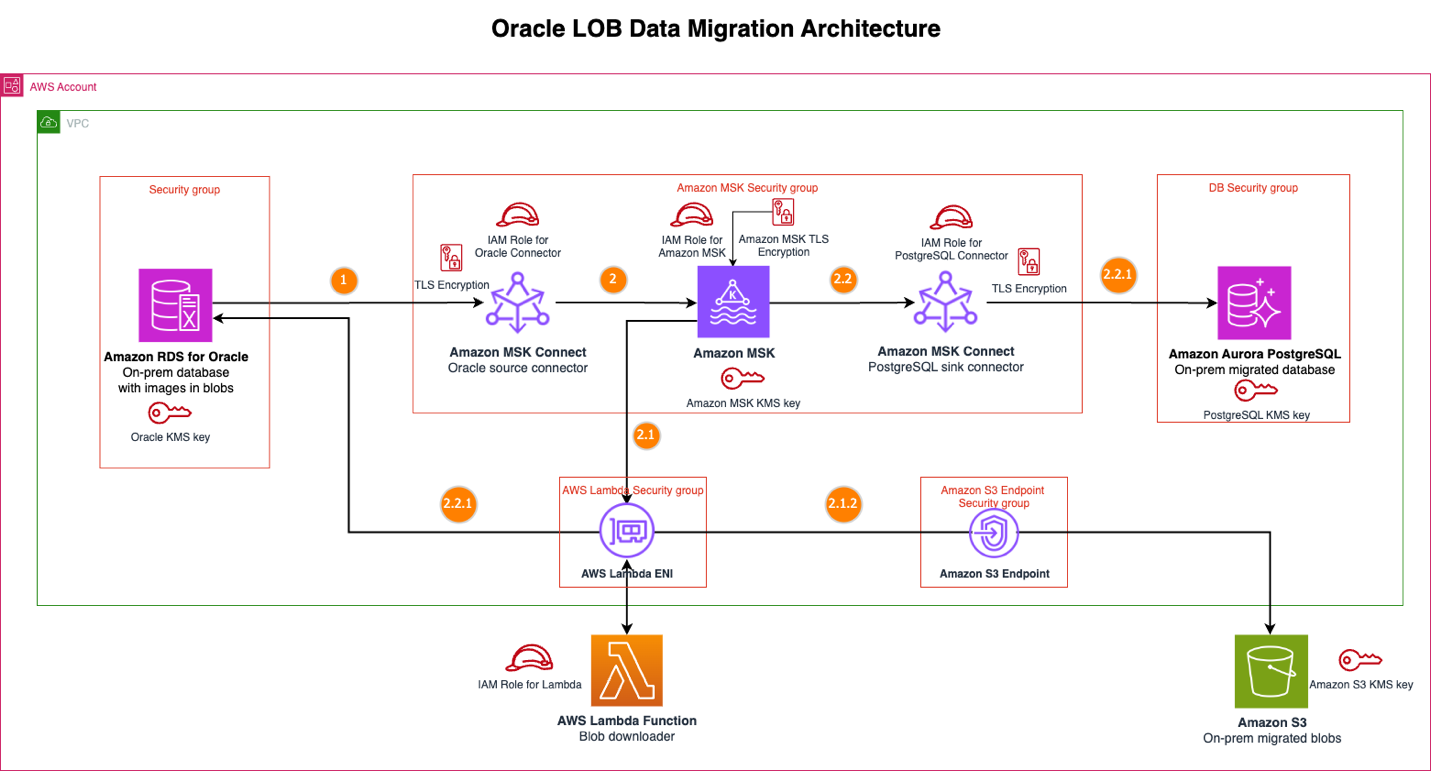
Luồng thông báo
Khi các thay đổi dữ liệu xảy ra trong cơ sở dữ liệu Amazon RDS for Oracle nguồn, giải pháp thực hiện chuỗi sau, di chuyển qua việc phát hiện và xuất bản sự kiện, xử lý BLOB bằng Lambda và xử lý dữ liệu có cấu trúc:
- Trình kết nối nguồn Oracle thu thập các sự kiện thay đổi dữ liệu (CDC), bao gồm cả thay đổi đối với cột dữ liệu BLOB. Trình kết nối này cấu hình cột dữ liệu BLOB để loại trừ khỏi sự kiện Kafka nhằm tối ưu hóa payload Kafka.
- Trình kết nối xuất bản sự kiện này lên một topic MSK.
a. Sự kiện MSK kích hoạt hàm Lambda BLOB Downloader cho các sự kiện CDC.
i. Hàm Lambda kiểm tra hai điều kiện chính: mã sự kiện Debezium (cụ thể là kiểm tra tạo (c) hoặc cập nhật (u)) và danh sách các tên bảng BLOB của Oracle đã cấu hình cùng với tên cột của chúng. Khi một thông báo Kafka khớp với cả danh sách bảng đã cấu hình và các sự kiện Debezium hợp lệ, hàm Lambda sẽ bắt đầu tải xuống dữ liệu BLOB từ nguồn Oracle bằng cách sử dụng khóa chính và tên bảng; nếu không, hàm sẽ bỏ qua quá trình tải xuống BLOB. Cách tiếp cận chọn lọc này đảm bảo hàm Lambda chỉ thực hiện các truy vấn SQL khi xử lý các thông báo Kafka cho các bảng chứa dữ liệu BLOB, tối ưu hóa các tương tác cơ sở dữ liệu.
ii. Hàm Lambda tải BLOB lên Amazon S3, tổ chức theo các thư mục khóa chính với tên đối tượng duy nhất, cho phép liên kết giữa các bản ghi cơ sở dữ liệu có cấu trúc và dữ liệu BLOB tương ứng của chúng trong Amazon S3.
b. Trình kết nối đích PostgreSQL nhận sự kiện từ topic MSK.
i. Trình kết nối áp dụng các thay đổi này cho cơ sở dữ liệu Aurora PostgreSQL đối với các thay đổi cơ sở dữ liệu Oracle ngoại trừ cột dữ liệu BLOB. Cột dữ liệu BLOB bị loại trừ bởi trình kết nối nguồn Oracle.
Lợi ích chính
Giải pháp mang lại những lợi thế chính sau:
- Tối ưu hóa chi phí và cấp phép – Cách tiếp cận của chúng tôi mang lại lợi ích tối ưu hóa chi phí đáng kể bằng cách giảm tổng kích thước cơ sở dữ liệu của bạn và giảm nhu cầu về các giấy phép đắt tiền liên quan đến cơ sở dữ liệu và công nghệ sao chép truyền thống. Bằng cách tách lưu trữ LOB khỏi cơ sở dữ liệu và sử dụng Amazon S3, bạn có thể giảm tổng dung lượng cơ sở dữ liệu của mình và giảm chi phí liên quan đến cấp phép và công nghệ sao chép truyền thống. Kiến trúc truyền dữ liệu cũng giảm thiểu chi phí cơ sở hạ tầng của bạn trong các quá trình di chuyển kéo dài.
- Tránh các hạn chế về kích thước và lỗi di chuyển – Các công cụ di chuyển truyền thống thường áp đặt các giới hạn kích thước đối với việc truyền LOB, dẫn đến các vấn đề cắt cụt và lỗi di chuyển. Giải pháp này loại bỏ hoàn toàn các hạn chế đó, vì vậy bạn có thể di chuyển LOBs với các kích thước khác nhau trong khi vẫn duy trì tính toàn vẹn dữ liệu. Kiến trúc hướng sự kiện cho phép sao chép dữ liệu gần thời gian thực, cho phép các hệ thống nguồn của bạn vẫn hoạt động trong quá trình di chuyển.
- Tính liên tục kinh doanh và xuất sắc trong vận hành – Các thay đổi liên tục chảy vào môi trường đích của bạn, cho phép tính liên tục kinh doanh. Giải pháp duy trì mối quan hệ giữa các bản ghi cơ sở dữ liệu có cấu trúc và các LOBs tương ứng của chúng thông qua tổ chức dựa trên khóa chính trong Amazon S3, cho phép tính toàn vẹn tham chiếu trong khi cung cấp tính linh hoạt của bộ nhớ đối tượng cho các tệp lớn.
- Ưu điểm kiến trúc – Lưu trữ LOBs trong Amazon S3 trong khi duy trì dữ liệu có cấu trúc trong Aurora PostgreSQL-Compatible tạo ra sự tách biệt rõ ràng. Kiến trúc này đơn giản hóa các hoạt động sao lưu và khôi phục của bạn, cải thiện hiệu suất truy vấn trên dữ liệu có cấu trúc và cung cấp các mẫu truy cập linh hoạt cho các đối tượng nhị phân thông qua Amazon S3.
Các phương pháp hay nhất khi triển khai
Hãy xem xét các phương pháp hay nhất sau khi triển khai giải pháp này:
- Bắt đầu nhỏ và mở rộng dần dần – Để triển khai giải pháp này, hãy bắt đầu với một dự án thử nghiệm sử dụng dữ liệu không sản xuất để xác thực cách tiếp cận của bạn trước khi cam kết di chuyển toàn diện. Điều này giúp bạn có cơ hội giải quyết các vấn đề trong một môi trường được kiểm soát và tinh chỉnh cấu hình của mình mà không ảnh hưởng đến các hệ thống sản xuất.
- Giám sát – Thiết lập giám sát toàn diện thông qua Amazon CloudWatch để theo dõi các chỉ số chính như độ trễ Kafka, lỗi hàm Lambda và độ trễ sao chép. Thiết lập ngưỡng cảnh báo sớm để bạn có thể phát hiện và giải quyết các vấn đề nhanh chóng trước khi chúng ảnh hưởng đến thời gian di chuyển của bạn. Kích thước cụm MSK của bạn dựa trên khối lượng CDC dự kiến và cấu hình đồng thời dành riêng cho Lambda để xử lý tải cao điểm trong quá trình đồng bộ hóa dữ liệu ban đầu.
- Bảo mật – Để bảo mật, hãy sử dụng mã hóa khi truyền và khi lưu trữ cho cả dữ liệu có cấu trúc và LOBs, đồng thời tuân thủ nguyên tắc đặc quyền tối thiểu khi thiết lập các vai trò và chính sách AWS Identity and Access Management (IAM) cho cụm MSK, các hàm Lambda, các bucket S3 và các phiên bản cơ sở dữ liệu của bạn. Ghi lại các ánh xạ lược đồ của bạn giữa Oracle và Aurora PostgreSQL-Compatible, bao gồm cách các bản ghi cơ sở dữ liệu liên kết với các LOBs tương ứng của chúng trong Amazon S3.
- Kiểm tra và chuẩn bị – Trước khi bạn triển khai, hãy kiểm tra kỹ lưỡng các quy trình chuyển đổi dự phòng và khôi phục của bạn. Xác thực các kịch bản như lỗi hàm Lambda, sự cố cụm MSK và các vấn đề kết nối mạng để đảm bảo bạn đã chuẩn bị cho các vấn đề tiềm ẩn. Cuối cùng, hãy nhớ rằng kiến trúc truyền dữ liệu này duy trì tính nhất quán cuối cùng giữa các hệ thống nguồn và đích của bạn, vì vậy có thể có những khoảng thời gian trễ ngắn trong các giai đoạn khối lượng lớn. Lập kế hoạch chiến lược chuyển đổi của bạn với điều này trong tâm trí.
Hạn chế và cân nhắc
Mặc dù giải pháp này cung cấp một cách tiếp cận mạnh mẽ để di chuyển cơ sở dữ liệu Oracle với LOBs sang AWS, nhưng có một số hạn chế cố hữu cần hiểu trước khi triển khai.
Giải pháp này yêu cầu kết nối mạng giữa cơ sở dữ liệu Oracle nguồn của bạn và môi trường AWS. Đối với các cơ sở dữ liệu Oracle tại chỗ, bạn phải thiết lập kết nối AWS Direct Connect hoặc VPN trước khi triển khai. Băng thông mạng ảnh hưởng trực tiếp đến tốc độ sao chép và hiệu suất di chuyển tổng thể, vì vậy kết nối của bạn phải có khả năng xử lý khối lượng sự kiện CDC và truyền LOB dự kiến.
Giải pháp sử dụng Debezium Connector for Oracle làm trình kết nối nguồn và Debezium Connector for JDBC làm trình kết nối đích. Kiến trúc này được thiết kế đặc biệt cho các quá trình di chuyển từ Oracle sang PostgreSQL của bạn. Các kết hợp cơ sở dữ liệu khác yêu cầu cấu hình trình kết nối khác hoặc có thể không được hỗ trợ bởi việc triển khai hiện tại. Thông lượng di chuyển cũng bị hạn chế bởi dung lượng cụm MSK của bạn và giới hạn đồng thời của Lambda. Bạn cũng có thể vượt quá hạn ngạch dịch vụ AWS cho các quá trình di chuyển quy mô lớn và bạn có thể cần yêu cầu tăng hạn ngạch thông qua AWS Enterprise Support.
Kết luận
Trong bài viết này, chúng tôi đã trình bày một giải pháp giải quyết thách thức quan trọng trong việc di chuyển các đối tượng nhị phân lớn của bạn từ Oracle sang AWS bằng cách sử dụng kiến trúc truyền dữ liệu tách biệt lưu trữ LOB khỏi dữ liệu có cấu trúc. Cách tiếp cận này tránh các hạn chế về kích thước, giảm chi phí cấp phép Oracle và duy trì tính toàn vẹn dữ liệu trong suốt các giai đoạn di chuyển kéo dài.
Bạn đã sẵn sàng để chuyển đổi chiến lược di chuyển Oracle của mình chưa? Hãy truy cập kho lưu trữ GitHub, nơi bạn sẽ tìm thấy mã triển khai AWS CDK hoàn chỉnh, các tệp cấu hình và hướng dẫn từng bước để bắt đầu.
Về tác giả

Naresh Dhiman
Naresh là Kiến trúc sư Giải pháp cấp cao tại AWS, hỗ trợ các khách hàng liên bang Hoa Kỳ. Ông có hơn 25 năm kinh nghiệm làm lãnh đạo công nghệ và là một nhà phát minh được công nhận với sáu bằng sáng chế. Ông chuyên về containers, machine learning và generative AI trên AWS.

Archana Sharma
Archana là Kiến trúc sư Giải pháp Chuyên gia Cơ sở dữ liệu cấp cao, làm việc với các khách hàng thuộc Khu vực Công cộng Toàn cầu. Cô có nhiều năm kinh nghiệm về cơ sở dữ liệu quan hệ và đam mê giúp khách hàng trong hành trình lên AWS Cloud với trọng tâm là di chuyển và hiện đại hóa cơ sở dữ liệu.

Ron Kolwitz
Ron là Kiến trúc sư Giải pháp cấp cao hỗ trợ các khách hàng Khoa học Chính phủ Liên bang Hoa Kỳ bao gồm NASA và Bộ Năng lượng. Ông đặc biệt đam mê hàng không vũ trụ và thúc đẩy việc sử dụng GenAI và các công nghệ dựa trên lượng tử cho nghiên cứu khoa học. Trong thời gian rảnh rỗi, ông thích dành thời gian cho gia đình những người trượt nước cuồng nhiệt của mình.

Karan Lakhwani
Karan là Giám đốc Giải pháp Khách hàng cấp cao tại Amazon Web Services. Anh chuyên về các công nghệ generative AI và là người nhận giải AWS Golden Jacket. Ngoài công việc, Karan thích khám phá các nhà hàng mới và trượt tuyết.
