Tác giả: Stephen Wood, Jungkook Lee, và Souvik Bhattacherjee
Ngày phát hành: 20 JAN 2026
Chuyên mục: Advanced (300), Amazon Aurora, PostgreSQL compatible, Technical How-to
Trong bài viết này, chúng tôi thảo luận về cách tính năng Shared Plan Cache của Amazon Aurora PostgreSQL-Compatible Edition có thể giảm đáng kể mức tiêu thụ bộ nhớ của các kế hoạch SQL chung trong môi trường có độ đồng thời cao, biến một chi phí bộ nhớ tiềm năng 40GB thành một dung lượng 400MB dễ quản lý.
Hãy tưởng tượng cụm cơ sở dữ liệu Aurora PostgreSQL của bạn đang phục vụ hàng nghìn kết nối đồng thời, mỗi kết nối thực thi cùng một prepared statements. Bạn nhận thấy mức sử dụng bộ nhớ tăng lên hàng chục gigabyte, nhưng bản thân các truy vấn lại đơn giản. Điều gì đang xảy ra? Bạn có thể đang gặp phải chi phí ẩn của việc trùng lặp kế hoạch, một vấn đề mà bộ nhớ đệm kế hoạch chia sẻ có thể giải quyết một cách tinh tế.
Tìm hiểu về các kế hoạch chung trong PostgreSQL
Prepared statements thường được sử dụng trong các ứng dụng (khi chúng định nghĩa các hàm hoặc phương thức tương tác với cơ sở dữ liệu), nơi các câu lệnh này được bao gồm trong mã/phương thức truy cập cơ sở dữ liệu của chúng. Giai đoạn chuẩn bị bao gồm cả cấu trúc câu lệnh SQL và các placeholder, sẽ được điền các giá trị thực tế khi ứng dụng thực thi prepared statement. Trong giai đoạn chuẩn bị, câu lệnh được phân tích cú pháp, phân tích và viết lại, do đó tiết kiệm công việc phân tích cú pháp và phân tích lặp lại khi nó được thực thi.
Trước khi đi sâu vào giải pháp, hãy cùng tìm hiểu cách PostgreSQL xử lý prepared statements. Trong PostgreSQL và Aurora PostgreSQL, prepared statements có thể được thực thi bằng hai loại kế hoạch:
- Kế hoạch tùy chỉnh (Custom plans): Được tạo mới cho mỗi lần thực thi với các giá trị tham số cụ thể, trong đó các giá trị cố định (literals) được bao gồm.
- Kế hoạch chung (Generic plans): Các kế hoạch độc lập với tham số được tái sử dụng qua các lần thực thi, trong đó các giá trị cố định không được bao gồm.
Theo mặc định, PostgreSQL sử dụng một phương pháp thông minh để quyết định giữa hai loại kế hoạch này:
- Năm lần thực thi đầu tiên của một prepared statement sử dụng các kế hoạch tùy chỉnh.
- Chi phí trung bình của các kế hoạch tùy chỉnh này được tính toán.
- Trong lần thực thi thứ sáu, một kế hoạch chung được tạo.
- Nếu chi phí của kế hoạch chung tương đương hoặc tốt hơn chi phí trung bình của kế hoạch tùy chỉnh, nó sẽ được sử dụng cho các lần thực thi tiếp theo.
Cách tiếp cận này giúp tiết kiệm thời gian lập kế hoạch cho các truy vấn được thực thi thường xuyên, nhưng nó đi kèm với một chi phí ẩn trong môi trường có nhiều kết nối cơ sở dữ liệu đồng thời.
Vấn đề: Hiệu quả bộ nhớ kém ở quy mô lớn
Mặc dù cách tiếp cận này hoạt động tốt cho các kết nối riêng lẻ, nhưng nó tạo ra hai sự kém hiệu quả đáng kể trong môi trường có nhiều kết nối cơ sở dữ liệu đồng thời:
- Tạo kế hoạch không cần thiết: Ngay cả khi một kế hoạch chung sẽ không được sử dụng (vì các kế hoạch tùy chỉnh hiệu quả hơn), hệ thống vẫn tạo và lưu trữ nó trong bộ nhớ cho mục đích so sánh chi phí. Ví dụ, đối với các bảng được phân vùng, khả năng một kế hoạch chung không được sử dụng cao hơn vì chi phí được tính cho các phân vùng lá và sau đó được tổng hợp.
- Trùng lặp kế hoạch: Khi cùng một truy vấn được thực thi trên hàng trăm hoặc hàng nghìn phiên, mỗi phiên duy trì bản sao riêng của kế hoạch chung giống hệt nhau, dẫn đến việc trùng lặp bộ nhớ lớn.
Hãy cùng minh họa vấn đề này bằng một ví dụ cụ thể:
Thiết lập môi trường thử nghiệm
Trong ví dụ này, chúng tôi tạo 2 bảng t1 và t2, mỗi bảng có 1000 phân vùng trong một phiên mới. Sau đó, chúng tôi chèn 100.000 hàng vào mỗi bảng bằng cách lặp 100 lần, mỗi lần lặp chèn 1000 giá trị. Cuối cùng, chúng tôi thu thập số liệu thống kê mới trên cả hai bảng.
Lưu ý: Để sử dụng tính năng bộ nhớ đệm kế hoạch chia sẻ, bạn phải sử dụng Aurora PostgreSQL phiên bản 17.6 trở lên hoặc phiên bản 16.10 trở lên.
-- Create partitioned tablesCREATE TABLE t1(part_key int, c1 int) PARTITION BY RANGE(part_key);CREATE TABLE t2(part_key int, c1 int) PARTITION BY RANGE(part_key);\pset pager-- Generate 1000 partitions for each table (simulating large-scale partitioning)SELECT 'CREATE TABLE t1_' || x || ' PARTITION OF t1 FOR VALUES FROM (' || x || ') TO (' || x+1 || ')'FROM generate_series(1, 1000) x;\gexecSELECT 'CREATE TABLE t2_' || x || ' PARTITION OF t2 FOR VALUES FROM (' || x || ') TO (' || x+1 || ')'FROM generate_series(1, 1000) x;\gexec-- Populate tables with sample dataDO$do$BEGINFOR i IN 1..100 LOOPINSERT INTO t1 SELECT x, i FROM generate_series(1, 1000) x;INSERT INTO t2 SELECT x, i FROM generate_series(1, 1000) x;END LOOP;END$do$;-- Update statistics for optimal query planningANALYZE t1, t2;Bạn có thể sử dụng tùy chọn \gexec ở đây để chạy kết quả của câu lệnh select của chúng tôi như một câu lệnh SQL độc lập. Bạn có thể tắt psql pager bằng cách sử dụng \pset pager để tránh phải nhấn Enter nhiều lần khi tạo các phân vùng bảng của mình.
Quan sát mức tiêu thụ bộ nhớ
Trong Phiên 1, chúng tôi tạo và thực thi prepared statement sau:
-- Create a prepared statement with a simple joinPREPARE p2(int, int) AS SELECT sum(t1.c1) FROM t1, t2 WHERE t1.part_key = t2.part_key AND t1.c1 = $1 AND t1.part_key = $2;-- Execute 6 times to trigger generic plan creationEXECUTE p2(1, 4); -- Execution 1: Custom planEXECUTE p2(1, 4); -- Execution 2: Custom planEXECUTE p2(1, 4); -- Execution 3: Custom planEXECUTE p2(1, 4); -- Execution 4: Custom planEXECUTE p2(1, 4); -- Execution 5: Custom planEXECUTE p2(1, 4); -- Execution 6: Generic plan createdSau đó, chúng tôi kiểm tra mức tiêu thụ bộ nhớ:
-- Check memory usage for cached plansSELECT name, ident, pg_size_pretty(total_bytes) as sizeFROM pg_backend_memory_contexts WHERE name = 'CachedPlan';-[ RECORD 1 ]-+---------------------------------------name | CachedPlanident | prepare p2(int, int) as +| select sum(t1.c1) +| from t1, t2 +| where t1.part_key = t2.part_key and +| t1.c1 = $1 and t1.part_key = $2;size | 4161 kBĐối với thử nghiệm này, chúng tôi quan sát thấy rằng kế hoạch chung tiêu thụ khoảng 4MB và vẫn còn trong bộ nhớ cho đến khi prepared statement được giải phóng hoặc kết nối chấm dứt.
Vấn đề trùng lặp
Bây giờ, hãy sử dụng một phiên khác (Phiên 2) và thực thi cùng một prepared statement:
-- Session 2: Using the same prepared statementPREPARE p2(int, int) AS SELECT sum(t1.c1) FROM t1, t2 WHERE t1.part_key = t2.part_key AND t1.c1 = $1 AND t1.part_key = $2;-- Execute 6 timesEXECUTE p2(1, 4);EXECUTE p2(1, 4);EXECUTE p2(1, 4);EXECUTE p2(1, 4);EXECUTE p2(1, 4);EXECUTE p2(1, 4);-- Check memory usageSELECT name, ident, pg_size_pretty(total_bytes) as sizeFROM pg_backend_memory_contexts WHERE name = 'CachedPlan';-[ RECORD 1 ]-+---------------------------------------name | CachedPlanident | prepare p2(int, int) as +| select sum(t1.c1) +| from t1, t2 +| where t1.part_key = t2.part_key and +| t1.c1 = $1 and t1.part_key = $2; size | 4161 kBPhiên 2 cũng tiêu thụ 4MB cho cùng một kế hoạch chung!
Hiệu ứng nhân bản
Sự trùng lặp này xảy ra với mỗi phiên thực thi prepared statement. Hãy cùng tính toán tác động:
- 1 prepared statement × 100 kết nối × 4MB = 400MB bộ nhớ
- 100 prepared statements khác nhau × 100 kết nối × 4MB = 40GB bộ nhớ
Mức tiêu thụ bộ nhớ khổng lồ này xảy ra ngay cả khi các phiên đang lưu trữ các bản sao giống hệt nhau của cùng một kế hoạch chung. Trong môi trường có nhiều kết nối cơ sở dữ liệu đồng thời, điều này có thể nhanh chóng làm cạn kiệt bộ nhớ khả dụng và buộc bạn phải sử dụng các loại instance lớn hơn, đắt tiền hơn.
Giải pháp: Bộ nhớ đệm kế hoạch chia sẻ của Aurora PostgreSQL
Aurora PostgreSQL giải quyết vấn đề này bằng bộ nhớ đệm kế hoạch chia sẻ (Shared Plan Cache – SPC), chỉ giữ một bản sao của mỗi kế hoạch chung mà các phiên có thể sử dụng. Điều này giúp giảm đáng kể mức tiêu thụ bộ nhớ trong khi vẫn duy trì lợi ích hiệu suất của việc lưu vào bộ nhớ đệm kế hoạch.
Bạn có thể bật bộ nhớ đệm kế hoạch chia sẻ (SPC) bằng cách sử dụng nhóm tham số cluster hoặc instance:
apg_shared_plan_cache.enable = ONVì apg_shared_plan_cache.enable là một tham số động, bạn không cần phải khởi động lại instance để các thay đổi có hiệu lực.
SPC được triển khai dưới dạng một bảng băm động, được chia sẻ giữa các phiên, trong đó số lượng mục nhập trong bộ nhớ đệm có thể được kiểm soát thông qua apg_shared_plan_cache.max. Bạn cũng có thể sử dụng các tham số sau để kiểm soát kích thước tối thiểu và tối đa của một mục nhập.
apg_shared_plan_cache.min_size_per_entryapg_shared_plan_cache.max_size_per_entryMinh họa Bộ nhớ đệm kế hoạch chia sẻ đang hoạt động
Hãy lặp lại thử nghiệm trước đó của chúng ta với bộ nhớ đệm kế hoạch chia sẻ được bật:
Phiên 1 (Kết nối đầu tiên):
-- Create and execute the same prepared statementPREPARE p2(int, int) AS SELECT sum(t1.c1) FROM t1, t2 WHERE t1.part_key = t2.part_key AND t1.c1 = $1 AND t1.part_key = $2;-- Execute 6 timesEXECUTE p2(1, 4);EXECUTE p2(1, 4);EXECUTE p2(1, 4);EXECUTE p2(1, 4);EXECUTE p2(1, 4);EXECUTE p2(1, 4);-- Check memory usageSELECT name, ident, pg_size_pretty(total_bytes) as sizeFROM pg_backend_memory_contexts WHERE name = 'CachedPlan';Phiên đầu tiên vẫn hiển thị kế hoạch 4MB trong bộ nhớ cục bộ của nó (cần thiết để điền vào bộ nhớ đệm chia sẻ).
Phiên 2 (Kết nối tiếp theo):
-- Create the same prepared statementPREPARE p2(int, int) AS SELECT sum(t1.c1) FROM t1, t2 WHERE t1.part_key = t2.part_key AND t1.c1 = $1 AND t1.part_key = $2;-- Execute 6 timesEXECUTE p2(1, 4);EXECUTE p2(1, 4);EXECUTE p2(1, 4);EXECUTE p2(1, 4);EXECUTE p2(1, 4);EXECUTE p2(1, 4);-- Check memory usageSELECT name, ident, pg_size_pretty(total_bytes) as sizeFROM pg_backend_memory_contexts WHERE name = 'CachedPlan';(0 rows)Không có lưu trữ kế hoạch cục bộ! Phiên thứ hai đang sử dụng bộ nhớ đệm kế hoạch chia sẻ.
Giám sát việc sử dụng bộ nhớ đệm
Chúng tôi chạy câu lệnh SQL sau để hiển thị số lượt truy cập bộ nhớ đệm mà các kế hoạch chia sẻ riêng lẻ được lưu trữ trong bộ nhớ đệm của chúng tôi đã nhận được. Mỗi lượt truy cập đại diện cho một kế hoạch không cần phải được sao chép trong bộ nhớ phiên.
-- View shared plan cache statisticsSELECT cache_key, query, hitsFROM apg_shared_plan_cache();-[ RECORD 1 ]-------------------------------------cache_key | -5127257242415815179query | prepare p2(int, int) as +| select sum(t1.c1) +| from t1, t2 +| where t1.part_key = t2.part_key and +| t1.c1 = $1 and t1.part_key = $2;hits | 2Dọn dẹp:
-- clear the cacheSELECT * FROM apg_shared_plan_cache_reset();-- drop the tablesDROP TABLE t1;DROP TABLE t2;Tác động hiệu suất
Trong kịch bản ví dụ của chúng tôi với 100 prepared statements khác nhau trên 100 kết nối, chúng tôi đã quan sát thấy sự chuyển đổi từ 40GB lưu trữ kế hoạch trùng lặp xuống chỉ còn 400MB trong bộ nhớ đệm chia sẻ. Ảnh chụp màn hình bên dưới hiển thị biểu đồ của chỉ số Freeable Memory CloudWatch thu được từ một instance nơi một thử nghiệm được chạy bằng pgbench với 100 prepared statements riêng biệt (được sử dụng từ ví dụ trên) trên 100 kết nối với apg_shared_plan_cache.enable = off. Chúng tôi có thể quan sát thấy rằng trong khoảng thời gian từ 02:05 đến 02:10, FreeableMemory giảm khoảng 40GB, phù hợp với dấu vết lưu trữ kế hoạch trùng lặp dự kiến của chúng tôi. Khi chúng tôi bật bộ nhớ đệm kế hoạch chia sẻ và chạy lại cùng một thử nghiệm, tác động bộ nhớ đã giảm đáng kể, chỉ yêu cầu một lượng nhỏ bộ nhớ thay vì 40GB.
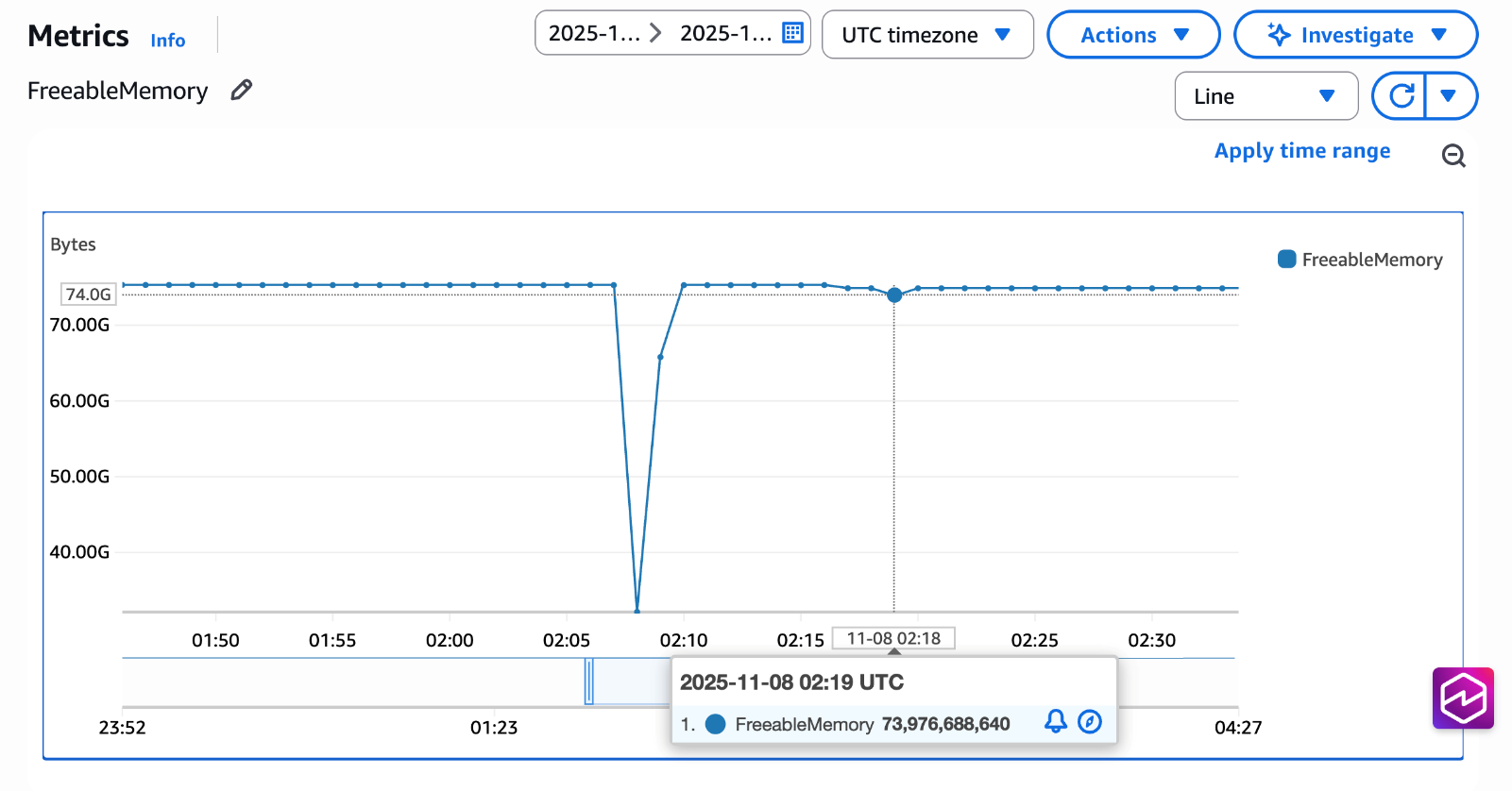
Sự giảm thiểu này có nghĩa là bạn có thể:
- Chạy cùng một khối lượng công việc trên các instance nhỏ hơn, giảm đáng kể chi phí AWS của bạn.
- Hỗ trợ nhiều kết nối đồng thời hơn mà không gặp giới hạn bộ nhớ.
- Tránh lỗi hết bộ nhớ trong các đợt tăng lưu lượng truy cập.
Các phương pháp hay nhất
Tính năng này đặc biệt hữu ích khi:
- Ứng dụng của bạn duy trì hàng trăm hoặc hàng nghìn kết nối cơ sở dữ liệu.
- Bạn sử dụng prepared statements rộng rãi.
- Các truy vấn của bạn liên quan đến các bảng được phân vùng hoặc các toán tử phức tạp (ví dụ: các phép nối và biểu thức bảng chung) tạo ra các kế hoạch lớn.
- Bạn quan sát thấy mức sử dụng bộ nhớ cao từ các tiến trình backend.
- Khối lượng công việc của bạn có các mẫu truy vấn lặp lại với các truy vấn có tham số.
Mặc dù Shared Plan Cache mang lại những lợi ích đáng kể, nhưng lưu ý rằng tính năng này có thể không phù hợp với các kịch bản sau:
- Các khối lượng công việc với các truy vấn ad-hoc, rất độc đáo.
- Các ứng dụng hiếm khi tái sử dụng prepared statements.
- Môi trường có ít kết nối đồng thời.
Kết luận
Trong bài viết này, chúng tôi đã chỉ cho bạn cách bật bộ nhớ đệm kế hoạch chia sẻ trong Aurora PostgreSQL. Chúng tôi đã chỉ ra rằng khi sử dụng prepared statements trên nhiều phiên cơ sở dữ liệu đồng thời, bạn sẽ tiết kiệm được việc trùng lặp cùng một kế hoạch truy vấn chung trong bộ nhớ.
Bằng cách loại bỏ lưu trữ kế hoạch dư thừa trên các phiên, bạn có thể chạy nhiều kết nối hơn trên các instance nhỏ hơn, giảm cả độ phức tạp trong vận hành và chi phí. Để biết thêm chi tiết về các loại kế hoạch khác nhau, hãy xem tài liệu PostgreSQL về câu lệnh prepare và các chỉ số Amazon CloudWatch cho Amazon Aurora để biết thêm chi tiết về việc đo lường bộ nhớ khả dụng.
Về tác giả

Souvik Bhattacherjee
Souvik là Kỹ sư phần mềm cấp cao tại AWS, nơi anh tập trung vào việc phát triển khả năng xử lý truy vấn trong cơ sở dữ liệu Aurora PostgreSQL. Anh có hơn 8 năm kinh nghiệm trong ngành cơ sở dữ liệu/HPC, nơi anh đã đóng góp vào các chủ đề liên quan đến hệ thống cơ sở dữ liệu và hệ thống điện toán hiệu năng cao.

Jungkook Lee
Jungkook là Kỹ sư phát triển phần mềm cấp cao tại AWS, nơi anh dẫn dắt một nhóm tập trung vào việc cải thiện hiệu suất và mở rộng chức năng cho Aurora PostgreSQL. Với hơn 10 năm kinh nghiệm trong các hệ thống cơ sở dữ liệu và kiến trúc điện toán phân tán, anh chuyên về tối ưu hóa truy vấn và hiệu suất cơ sở dữ liệu.

Stephen Wood
Stephen là Kiến trúc sư giải pháp cơ sở dữ liệu chuyên gia cấp cao tại AWS. Stephen chuyên về Amazon RDS PostgreSQL, Amazon Aurora PostgreSQL và Amazon Aurora DSQL. Anh đã làm việc với các hệ thống cơ sở dữ liệu trên nhiều loại doanh nghiệp khác nhau trong 24 năm qua và luôn yêu thích làm việc với công nghệ cơ sở dữ liệu mới.
