Tác giả: Mahek Shah, Nirupam Datta, and Ryan Moore
Ngày phát hành: 21 JAN 2026
Chuyên mục: Advanced (300), Amazon Aurora, Amazon RDS, Amazon Simple Storage Service (S3), MySQL compatible, RDS for MySQL, Technical How-to
Ghi nhật ký kiểm tra đã trở thành một thành phần quan trọng của bảo mật và tuân thủ cơ sở dữ liệu, giúp các tổ chức theo dõi hoạt động của người dùng, giám sát các mẫu truy cập dữ liệu và duy trì hồ sơ chi tiết cho các yêu cầu quy định và điều tra bảo mật. Nhật ký kiểm tra cơ sở dữ liệu cung cấp một dấu vết toàn diện về các hành động được thực hiện trong cơ sở dữ liệu, bao gồm các truy vấn đã thực thi, các thay đổi đối với dữ liệu và các nỗ lực xác thực người dùng. Việc quản lý các nhật ký này trở nên đơn giản hơn với một giải pháp lưu trữ mạnh mẽ như Amazon Simple Storage Service (Amazon S3).
Amazon Relational Database Service (Amazon RDS) cho MySQL và Amazon Aurora MySQL-Compatible Edition cung cấp khả năng ghi nhật ký kiểm tra tích hợp, nhưng khách hàng có thể cần xuất và lưu trữ các nhật ký này để lưu giữ và phân tích dài hạn. Amazon S3 cung cấp một đích đến lý tưởng, mang lại độ bền, hiệu quả chi phí và tích hợp với nhiều công cụ phân tích khác nhau.
Trong bài đăng này, chúng tôi khám phá hai cách tiếp cận để xuất nhật ký kiểm tra MySQL sang Amazon S3: sử dụng xử lý theo lô với tính năng xuất gốc sang Amazon S3 hoặc xử lý nhật ký gần thời gian thực với Amazon Data Firehose.
Tổng quan giải pháp
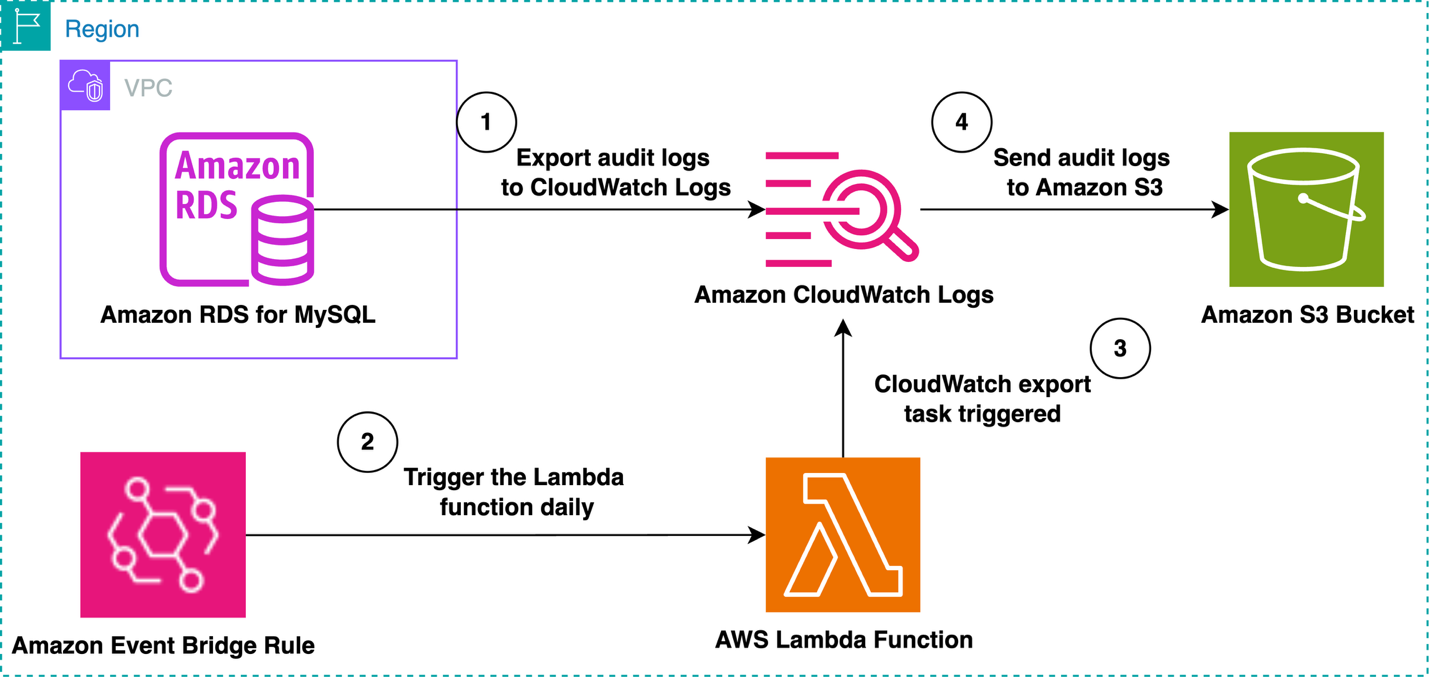
Giải pháp đầu tiên liên quan đến xử lý theo lô bằng cách sử dụng tính năng xuất nhật ký kiểm tra tích hợp trong Amazon RDS cho MySQL hoặc Aurora MySQL-Compatible để xuất nhật ký sang Amazon CloudWatch Logs. Amazon EventBridge định kỳ kích hoạt một hàm AWS Lambda. Giải pháp này tạo một tác vụ xuất CloudWatch gửi nhật ký kiểm tra của một ngày gần nhất đến Amazon S3. Khoảng thời gian (một ngày) có thể cấu hình dựa trên yêu cầu của bạn. Giải pháp này là hiệu quả chi phí nhất và thực tế nếu bạn không yêu cầu nhật ký kiểm tra phải có sẵn gần thời gian thực trong một S3 bucket. Sơ đồ sau minh họa quy trình làm việc này.
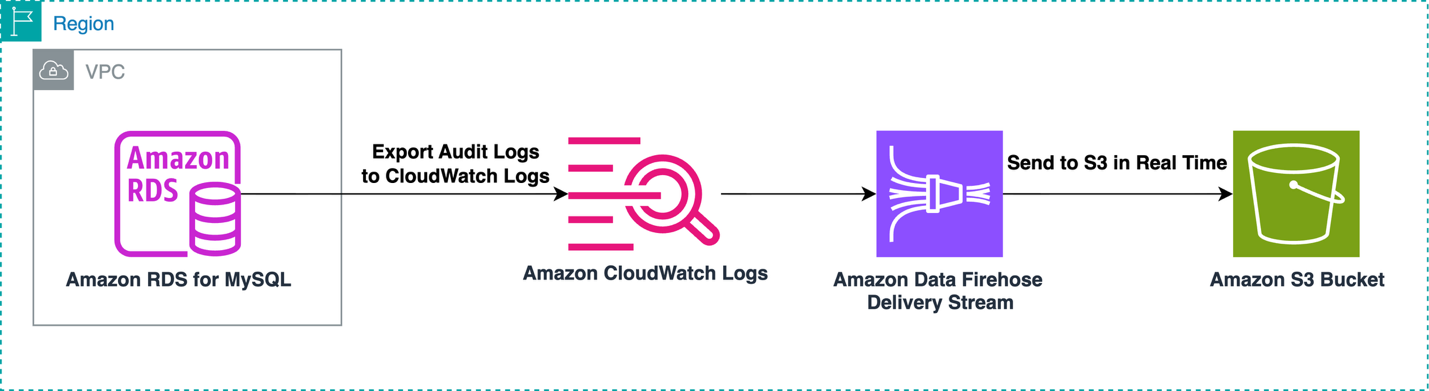
Giải pháp được đề xuất khác sử dụng Data Firehose để xử lý ngay lập tức nhật ký kiểm tra MySQL trong CloudWatch Logs và gửi chúng đến một S3 bucket. Cách tiếp cận này phù hợp cho các trường hợp kinh doanh yêu cầu xuất nhật ký kiểm tra ngay lập tức khi chúng có sẵn trong CloudWatch Logs. Sơ đồ sau minh họa quy trình làm việc này.
Các trường hợp sử dụng
Sau khi bạn đã triển khai một trong hai giải pháp này, nhật ký kiểm tra Aurora MySQL hoặc RDS cho MySQL của bạn sẽ được lưu trữ an toàn trong Amazon S3. Điều này mở ra vô số khả năng để phân tích, giám sát và báo cáo tuân thủ. Dưới đây là những gì bạn có thể làm với nhật ký kiểm tra đã xuất của mình:
- Chạy các truy vấn Amazon Athena: Với nhật ký kiểm tra của bạn trong S3, bạn có thể sử dụng Amazon Athena để chạy các truy vấn SQL trực tiếp trên dữ liệu nhật ký của mình. Điều này cho phép bạn nhanh chóng phân tích hoạt động của người dùng, xác định các mẫu bất thường hoặc tạo báo cáo tuân thủ. Ví dụ, bạn có thể truy vấn tất cả các hành động được thực hiện bởi một người dùng cụ thể hoặc tìm tất cả các lần đăng nhập không thành công trong một khoảng thời gian nhất định.
- Tạo bảng điều khiển Amazon QuickSight: Sử dụng Amazon QuickSight kết hợp với Athena, bạn có thể tạo các bảng điều khiển trực quan về dữ liệu nhật ký kiểm tra của mình. Điều này có thể giúp bạn phát hiện các xu hướng theo thời gian, chẳng hạn như giờ cao điểm sử dụng, người dùng hoạt động nhiều nhất hoặc các đối tượng cơ sở dữ liệu được truy cập thường xuyên.
- Thiết lập cảnh báo tự động: Bằng cách kết hợp nhật ký được lưu trữ trong S3 của bạn với AWS Lambda và Amazon SNS, bạn có thể tạo cảnh báo tự động cho các sự kiện cụ thể. Ví dụ, bạn có thể thiết lập một hệ thống để thông báo cho nhân viên bảo mật nếu có sự gia tăng bất thường trong các lần đăng nhập không thành công hoặc nếu các bảng nhạy cảm được truy cập ngoài giờ làm việc.
- Thực hiện phân tích dài hạn: Với nhật ký kiểm tra của bạn được tập trung trong S3, bạn có thể thực hiện phân tích xu hướng dài hạn. Điều này có thể giúp bạn hiểu cách các mẫu sử dụng cơ sở dữ liệu thay đổi theo thời gian, cung cấp thông tin cho việc lập kế hoạch dung lượng và chính sách bảo mật.
- Đáp ứng các yêu cầu tuân thủ: Nhiều khung pháp lý yêu cầu lưu giữ và phân tích nhật ký kiểm tra cơ sở dữ liệu. Với nhật ký của bạn trong S3, bạn có thể dễ dàng chứng minh sự tuân thủ các yêu cầu này, chạy báo cáo khi cần cho các kiểm toán viên.
Bằng cách tận dụng các khả năng này, bạn có thể biến nhật ký kiểm tra của mình từ một biện pháp bảo mật thụ động thành một công cụ tích cực để quản lý cơ sở dữ liệu, tăng cường bảo mật và thông tin kinh doanh.
So sánh các giải pháp
Giải pháp đầu tiên sử dụng EventBridge để định kỳ kích hoạt một hàm Lambda. Hàm này tạo một tác vụ xuất CloudWatch Log gửi một lô dữ liệu nhật ký đến Amazon S3 theo các khoảng thời gian đều đặn. Phương pháp này rất phù hợp cho các tình huống mà bạn muốn xử lý nhật ký theo lô để tối ưu hóa chi phí và tài nguyên.
Giải pháp thứ hai sử dụng Data Firehose để tạo một đường ống xử lý nhật ký kiểm tra gần thời gian thực. Cách tiếp cận này truyền trực tiếp nhật ký từ CloudWatch đến một S3 bucket, cung cấp quyền truy cập gần thời gian thực vào dữ liệu kiểm tra của bạn. Trong ngữ cảnh này, “gần thời gian thực” có nghĩa là dữ liệu nhật ký được xử lý và phân phối đồng bộ khi nó được tạo ra, thay vì được gửi theo một khoảng thời gian được xác định trước. Giải pháp này lý tưởng cho các tình huống yêu cầu truy cập ngay lập tức vào dữ liệu nhật ký hoặc cho các môi trường ghi nhật ký khối lượng lớn.
Dù bạn chọn cách tiếp cận truyền phát gần thời gian thực hay phương pháp xuất theo lịch trình, bạn sẽ được trang bị tốt để quản lý nhật ký kiểm tra Aurora MySQL và RDS cho MySQL của mình một cách hiệu quả.
Điều kiện tiên quyết cho cả hai giải pháp
Trước khi bắt đầu, hãy hoàn thành các điều kiện tiên quyết sau:
- Tạo hoặc có một phiên bản RDS cho MySQL hoặc cụm Aurora MySQL hiện có.
- Bật ghi nhật ký kiểm tra:
a. Đối với Amazon RDS, hãy thêm MariaDB Audit Plugin vào nhóm tùy chọn của bạn.
b. Đối với Aurora, hãy bật Advanced Auditing trong nhóm tham số của bạn.
Lưu ý: Trong ghi nhật ký kiểm tra, theo mặc định tất cả người dùng đều được ghi nhật ký, điều này có thể tốn kém.
- Xuất bản nhật ký kiểm tra MySQL sang CloudWatch Logs.
- Đảm bảo bạn có một terminal với AWS Command Line Interface (AWS CLI) đã cài đặt hoặc sử dụng AWS CloudShell trong console của bạn.
- Tạo một S3 bucket để lưu trữ nhật ký kiểm tra MySQL bằng lệnh AWS CLI dưới đây:
aws s3api create-bucket --bucket <bucket_name>
Sau khi lệnh hoàn tất, bạn sẽ thấy một đầu ra tương tự như sau:
{ "Location": "/<bucket_name>"}Lưu ý: Mỗi giải pháp có các thành phần dịch vụ cụ thể được thảo luận trong các phần tương ứng của chúng.
Giải pháp #1: Thực hiện xử lý theo lô nhật ký kiểm tra với EventBridge và Lambda
Trong giải pháp này, chúng tôi tạo một hàm Lambda để xuất nhật ký kiểm tra của bạn sang Amazon S3 dựa trên lịch trình bạn đặt bằng EventBridge Scheduler. Giải pháp này cung cấp một cách hiệu quả chi phí để chuyển các tệp nhật ký kiểm tra trong một S3 bucket theo lịch trình.
Tạo vai trò IAM cho EventBridge Scheduler
Bước đầu tiên là tạo một vai trò AWS Identity and Access Management (IAM) chịu trách nhiệm cho phép EventBridge Scheduler gọi hàm Lambda mà chúng ta sẽ tạo sau. Hoàn thành các bước sau để tạo vai trò này:
- Kết nối với một terminal với AWS CLI hoặc CloudShell.
- Tạo một tệp có tên
TrustPolicyForEventBridgeScheduler.jsonbằng trình soạn thảo văn bản ưa thích của bạn:
nano TrustPolicyForEventBridgeScheduler.json
- Chèn chính sách tin cậy sau vào tệp JSON:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "scheduler.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": { "StringEquals": { "aws:SourceAccount": "<AccountID>" } } } ]}Lưu ý: Đảm bảo sửa đổi SourceAccount trước khi lưu vào tệp. Điều kiện này được sử dụng để ngăn chặn truy cập trái phép từ các tài khoản AWS khác.
- Tạo một tệp có tên
PermissionsForEventBridgeScheduler.jsonbằng trình soạn thảo văn bản ưa thích của bạn:
nano PermissionsForEventBridgeScheduler.json
- Chèn các quyền sau vào tệp JSON:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "lambda:InvokeFunction" ], "Resource": [ "arn:aws:lambda:<Region>:<AccountID>:function:<LambdaFunctionName>*", "arn:aws:lambda:<Region>:<AccountID>:function<LambdaFunctionName>" ] } ]}Lưu ý: Thay thế <LambdaFunctionName> bằng tên của hàm bạn sẽ tạo sau.
- Sử dụng lệnh AWS CLI sau để tạo vai trò IAM cho EventBridge Scheduler để gọi hàm Lambda:
aws iam create-role \--role-name EventBridgeSchedulerLambdaInvoke \--assume-role-policy-document file://TrustPolicyForEventBridgeScheduler.json- Tạo chính sách IAM và đính kèm nó vào vai trò IAM đã tạo trước đó:
aws iam put-role-policy --role-name EventBridgeSchedulerLambdaInvokeRole --policy-name EventBridgeSchedulerLambdaInvoke --policy-document file://PermissionsForEventBridgeScheduler.jsonTrong phần này, chúng tôi đã tạo một vai trò IAM với các chính sách tin cậy và quyền phù hợp cho phép EventBridge Scheduler gọi các hàm Lambda một cách an toàn từ tài khoản AWS của bạn. Tiếp theo, chúng tôi sẽ tạo một vai trò IAM khác định nghĩa các quyền mà hàm Lambda của bạn cần để thực hiện các tác vụ của nó.
Tạo vai trò IAM cho Lambda
Bước tiếp theo là tạo một vai trò IAM chịu trách nhiệm cho phép Lambda đưa các bản ghi từ CloudWatch vào S3 bucket của bạn. Hoàn thành các bước sau để tạo vai trò này:
- Kết nối với một terminal với AWS CLI hoặc CloudShell.
- Tạo và ghi vào một tệp JSON cho chính sách tin cậy IAM bằng trình soạn thảo văn bản ưa thích của bạn:
nano TrustPolicyForLambda.json
- Chèn chính sách tin cậy sau vào tệp JSON:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "lambda.amazonaws.com" }, "Action": "sts:AssumeRole" } ]}- Sử dụng lệnh AWS CLI sau để tạo vai trò IAM cho Lambda để chèn các bản ghi từ CloudWatch vào Amazon S3:
aws iam create-role \--role-name LambdaCWtoS3Role \--assume-role-policy-document file://TrustPolicyForLambda.json- Tạo một tệp có tên
PermissionsForLambda.jsonbằng trình soạn thảo văn bản ưa thích của bạn:
nano PermissionsForLambda.json
- Chèn các quyền sau vào tệp JSON:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetBucketLocation" ], "Resource": [ "arn:aws:s3:::<bucket-name>", "arn:aws:s3:::<bucket-name>/*" ] }, { "Effect": "Allow", "Action": [ "logs:CreateExportTask" ], "Resource": "arn:aws:logs:*:*:log-group:/aws/rds/instance/*/audit:*" }, { "Effect": "Allow", "Action": [ "logs:DescribeExportTasks" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:log-group:/aws/lambda/*" } ]}- Tạo chính sách IAM và đính kèm nó vào vai trò IAM đã tạo trước đó:
aws iam put-role-policy --role-name LambdaCWtoS3Role --policy-name LambdaPermissions --policy-document file://PermissionsForLambda.jsonTạo tệp ZIP cho hàm Lambda Python
Để tạo một tệp với mã mà hàm Lambda sẽ gọi, hãy hoàn thành các bước sau:
- Tạo và ghi vào một tệp có tên
lambda_function.pybằng trình soạn thảo văn bản ưa thích của bạn:
nano lambda_function.py
- Trong tệp, chèn mã sau:
import boto3import osimport datetimeimport loggingimport timefrom botocore.exceptions import ClientError, NoCredentialsError, BotoCoreError# Set up logginglogger = logging.getLogger()logger.setLevel(logging.INFO)def check_active_export_tasks(client): """Check for any active export tasks""" try: response = client.describe_export_tasks() active_tasks = [ task for task in response.get('exportTasks', []) if task.get('status', {}).get('code') in ['RUNNING', 'PENDING'] ] return active_tasks except ClientError as e: logger.error(f"Error checking active export tasks: {e}") return []def wait_for_export_task_completion(client, max_wait_minutes=15, check_interval=60): """Wait for any active export tasks to complete""" max_wait_seconds = max_wait_minutes * 60 waited_seconds = 0 while waited_seconds < max_wait_seconds: active_tasks = check_active_export_tasks(client) if not active_tasks: logger.info("No active export tasks found, proceeding...") return True logger.info(f"Found {len(active_tasks)} active export task(s). Waiting {check_interval} seconds...") for task in active_tasks: task_id = task.get('taskId', 'Unknown') status = task.get('status', {}).get('code', 'Unknown') logger.info(f"Active task ID: {task_id}, Status: {status}") time.sleep(check_interval) waited_seconds += check_interval logger.warning(f"Timed out waiting for export tasks to complete after {max_wait_minutes} minutes") return Falsedef lambda_handler(event, context): try: # Environment variable validation required_env_vars = ['GROUP_NAME', 'DESTINATION_BUCKET', 'PREFIX', 'NDAYS'] missing_vars = [var for var in required_env_vars if not os.environ.get(var)] if missing_vars: error_msg = f"Missing required environment variables: {', '.join(missing_vars)}" logger.error(error_msg) return { 'statusCode': 400, 'body': {'error': error_msg} } # Get environment variables GROUP_NAME = os.environ['GROUP_NAME'].strip() DESTINATION_BUCKET = os.environ['DESTINATION_BUCKET'].strip() PREFIX = os.environ['PREFIX'].strip() NDAYS = os.environ['NDAYS'].strip() # Optional: Get retry configuration from environment MAX_WAIT_MINUTES = int(os.environ.get('MAX_WAIT_MINUTES', '30')) CHECK_INTERVAL = int(os.environ.get('CHECK_INTERVAL', '60')) RETRY_ON_CONCURRENT = os.environ.get('RETRY_ON_CONCURRENT', 'true').lower() == 'true' # Validate environment variables are not empty if not all([GROUP_NAME, DESTINATION_BUCKET, PREFIX, NDAYS]): error_msg = "Environment variables cannot be empty" logger.error(error_msg) return { 'statusCode': 400, 'body': {'error': error_msg} } # Convert and validate NDAYS try: nDays = int(NDAYS) if nDays <= 0: raise ValueError("NDAYS must be a positive integer") except ValueError as e: error_msg = f"Invalid NDAYS value '{NDAYS}': {str(e)}" logger.error(error_msg) return { 'statusCode': 400, 'body': {'error': error_msg} } # Date calculations with validation try: currentTime = datetime.datetime.now() StartDate = currentTime - datetime.timedelta(days=nDays) EndDate = currentTime - datetime.timedelta(days=nDays - 1) fromDate = int(StartDate.timestamp() * 1000) toDate = int(EndDate.timestamp() * 1000) # Validate date range if fromDate >= toDate: raise ValueError("Invalid date range: fromDate must be less than toDate") except (ValueError, OverflowError) as e: error_msg = f"Date calculation error: {str(e)}" logger.error(error_msg) return { 'statusCode': 400, 'body': {'error': error_msg} } # Create S3 path try: BUCKET_PREFIX = os.path.join(PREFIX, StartDate.strftime('%Y{0}%m{0}%d').format(os.path.sep)) except Exception as e: error_msg = f"Error creating bucket prefix: {str(e)}" logger.error(error_msg) return { 'statusCode': 500, 'body': {'error': error_msg} } # Log the export details logger.info(f"Starting export task for log group: {GROUP_NAME}") logger.info(f"Date range: {StartDate.strftime('%Y-%m-%d')} to {EndDate.strftime('%Y-%m-%d')}") logger.info(f"Destination: s3://{DESTINATION_BUCKET}/{BUCKET_PREFIX}") # Create boto3 client with error handling try: client = boto3.client('logs') except NoCredentialsError: error_msg = "AWS credentials not found" logger.error(error_msg) return { 'statusCode': 500, 'body': {'error': error_msg} } except Exception as e: error_msg = f"Error creating boto3 client: {str(e)}" logger.error(error_msg) return { 'statusCode': 500, 'body': {'error': error_msg} } # Check for active export tasks before creating a new one if RETRY_ON_CONCURRENT: logger.info("Checking for active export tasks...") active_tasks = check_active_export_tasks(client) if active_tasks: logger.info(f"Found {len(active_tasks)} active export task(s). Waiting for completion...") if not wait_for_export_task_completion(client, MAX_WAIT_MINUTES, CHECK_INTERVAL): return { 'statusCode': 409, 'body': { 'error': f'Active export task(s) still running after {MAX_WAIT_MINUTES} minutes', 'activeTaskCount': len(active_tasks) } } # Create export task with comprehensive error handling try: response = client.create_export_task( logGroupName=GROUP_NAME, fromTime=fromDate, to=toDate, destination=DESTINATION_BUCKET, destinationPrefix=BUCKET_PREFIX ) task_id = response.get('taskId', 'Unknown') logger.info(f"Export task created successfully with ID: {task_id}") return { 'statusCode': 200, 'body': { 'message': 'Export task created successfully', 'taskId': task_id, 'logGroup': GROUP_NAME, 'fromDate': StartDate.isoformat(), 'toDate': EndDate.isoformat(), 'destination': f"s3://{DESTINATION_BUCKET}/{BUCKET_PREFIX}" } } except ClientError as e: error_code = e.response['Error']['Code'] error_msg = e.response['Error']['Message'] # Handle specific AWS errors if error_code == 'ResourceNotFoundException': logger.error(f"Log group '{GROUP_NAME}' not found") return { 'statusCode': 404, 'body': {'error': f"Log group '{GROUP_NAME}' not found"} } elif error_code == 'LimitExceededException': # This is the concurrent export task error logger.error(f"Export task limit exceeded (concurrent task running): {error_msg}") # Check if there are active tasks to provide more context active_tasks = check_active_export_tasks(client) return { 'statusCode': 409, 'body': { 'error': 'Cannot create export task: Another export task is already running', 'details': error_msg, 'activeTaskCount': len(active_tasks), 'suggestion': 'Only one export task can run at a time. Please wait for the current task to complete or set RETRY_ON_CONCURRENT=true to auto-retry.' } } elif error_code == 'InvalidParameterException': logger.error(f"Invalid parameter: {error_msg}") return { 'statusCode': 400, 'body': {'error': f"Invalid parameter: {error_msg}"} } elif error_code == 'AccessDeniedException': logger.error(f"Access denied: {error_msg}") return { 'statusCode': 403, 'body': {'error': f"Access denied: {error_msg}"} } else: logger.error(f"AWS ClientError ({error_code}): {error_msg}") return { 'statusCode': 500, 'body': {'error': f"AWS error: {error_msg}"} } except BotoCoreError as e: error_msg = f"BotoCore error: {str(e)}" logger.error(error_msg) return { 'statusCode': 500, 'body': {'error': error_msg} } except Exception as e: error_msg = f"Unexpected error creating export task: {str(e)}" logger.error(error_msg) return { 'statusCode': 500, 'body': {'error': error_msg} } except Exception as e: # Catch-all for any unexpected errors error_msg = f"Unexpected error in lambda_handler: {str(e)}" logger.error(error_msg, exc_info=True) return { 'statusCode': 500, 'body': {'error': 'Internal server error'} }- Nén tệp bằng lệnh sau:
zip function.zip lambda_function.py
Tạo hàm Lambda
Hoàn thành các bước sau để tạo một hàm Lambda:
- Kết nối với một terminal với AWS CLI hoặc CloudShell.
- Chạy lệnh sau, tham chiếu đến tệp zip đã tạo trước đó:
aws lambda create-function \--function-name <function-name> \--runtime python 3.11--handler lambda_function.lambda_handler \--role arn:aws:iam::<AccountID>:role/Export-RDS-CloudWatch-to-S3-Lambda \--zip-file fileb://function.zip \--memory-size 128 \--timeout 15 \--architectures x86_64 \--environment "Variables={DESTINATION_BUCKET=<bucket-name>,GROUP_NAME=/aws/rds/instance/test/audit,PREFIX=exported-logs,NDAYS=1}" \Biến NDAYS trong lệnh trên sẽ xác định ngày của nhật ký kiểm tra được xuất cho mỗi lần gọi hàm Lambda. Ví dụ, nếu bạn định xuất nhật ký một lần mỗi ngày sang Amazon S3, hãy đặt NDAYS=1, như trong lệnh trên.
- Thêm giới hạn đồng thời để kiểm soát việc thực thi:
aws lambda put-function-concurrency --function-name <function-name> \ --reserved-concurrent-executions 2Lưu ý: Reserved concurrency trong Lambda đặt một giới hạn cố định về số lượng phiên bản hàm của bạn có thể chạy đồng thời, giống như có một số lượng công nhân cụ thể cho một tác vụ. Trong kịch bản xuất cơ sở dữ liệu này, chúng tôi giới hạn nó ở 2 lần thực thi đồng thời để ngăn chặn việc quá tải cơ sở dữ liệu, tránh điều tiết API và đảm bảo việc xuất diễn ra suôn sẻ, có kiểm soát. Giới hạn này giúp duy trì sự ổn định của hệ thống, ngăn chặn tranh chấp tài nguyên và kiểm soát chi phí.
Trong phần này, chúng tôi đã tạo một hàm Lambda sẽ xử lý việc xuất nhật ký CloudWatch, cấu hình các tham số thiết yếu của nó bao gồm các biến môi trường và đặt giới hạn đồng thời để đảm bảo việc thực thi được kiểm soát. Tiếp theo, chúng tôi sẽ tạo một lịch trình EventBridge sẽ tự động kích hoạt hàm Lambda này theo các khoảng thời gian được chỉ định để thực hiện việc xuất nhật ký.
Tạo lịch trình EventBridge
Hoàn thành các bước sau để tạo một lịch trình EventBridge để gọi hàm Lambda theo khoảng thời gian bạn chọn:
- Kết nối với một terminal với AWS CLI hoặc CloudShell.
- Chạy lệnh sau:
aws scheduler create-schedule \ --name <nameForSchedule> \ --description <descriptionForSchedule> \ --schedule-expression "rate(1 day)" \ --state ENABLED \ --target "{\"Arn\":\"arn:aws:lambda:<Region>: <AccountID>:function:<nameOfLambdaFunction>\”,\”RoleArn\":\"<LambdaRoleARN>\",\"RetryPolicy\":{\"MaximumEventAgeInSeconds\":86400,\"MaximumRetryAttempts\":0}}" \ --flexible-time-window "{\"Mode\":\"OFF\"}" \ --action-after-completion "NONE" \ --time-zone "America/New_York" \ --region <Region>Tham số schedule-expression trong lệnh trên phải bằng biến môi trường NDAYS trong hàm Lambda đã tạo trước đó.
Giải pháp này cung cấp một cách tiếp cận hiệu quả, theo lịch trình để xuất nhật ký kiểm tra RDS sang Amazon S3 bằng cách sử dụng AWS Lambda và EventBridge Scheduler. Bằng cách tận dụng các thành phần serverless này, chúng tôi đã tạo ra một hệ thống tự động, hiệu quả chi phí định kỳ chuyển nhật ký kiểm tra sang S3 để lưu trữ và phân tích dài hạn. Phương pháp này đặc biệt hữu ích cho các tổ chức cần xuất nhật ký kiểm tra cơ sở dữ liệu theo lô, thường xuyên, cho phép báo cáo tuân thủ và phân tích dữ liệu lịch sử dễ dàng hơn.
Trong khi giải pháp đầu tiên cung cấp cách tiếp cận xử lý theo lô, theo lịch trình, một số kịch bản yêu cầu giải pháp gần thời gian thực hơn để xử lý nhật ký kiểm tra. Trong giải pháp tiếp theo của chúng tôi, chúng tôi sẽ khám phá cách tạo một hệ thống xử lý nhật ký kiểm tra gần thời gian thực bằng cách sử dụng Amazon Kinesis Data Firehose. Cách tiếp cận này sẽ cho phép truyền liên tục nhật ký kiểm tra từ RDS đến S3, cung cấp quyền truy cập gần như ngay lập tức vào dữ liệu nhật ký.
Giải pháp 2: Tạo xử lý nhật ký kiểm tra gần thời gian thực với Amazon Data Firehose
Trong phần này, chúng tôi xem xét cách tạo một bản xuất nhật ký kiểm tra gần thời gian thực sang Amazon S3 bằng sức mạnh của Data Firehose. Với giải pháp này, bạn có thể trực tiếp tải các tệp nhật ký kiểm tra mới nhất vào một S3 bucket để phân tích, thao tác hoặc các mục đích khác một cách nhanh chóng.
Tạo vai trò IAM cho CloudWatch Logs
Bước đầu tiên là tạo một vai trò IAM chịu trách nhiệm cho phép CloudWatch Logs đưa các bản ghi vào luồng phân phối Firehose (CWLtoDataFirehoseRole). Hoàn thành các bước sau để tạo vai trò này:
- Kết nối với một terminal với AWS CLI hoặc CloudShell.
- Tạo và ghi vào một tệp JSON cho chính sách tin cậy IAM bằng trình soạn thảo văn bản ưa thích của bạn:
nano TrustPolicyForCWL.json
- Chèn chính sách tin cậy sau vào tệp JSON:
{ "Statement": { "Effect": "Allow", "Principal": { "Service": "logs.amazonaws.com" }, "Action": "sts:AssumeRole", "Condition": { "StringLike": { "aws:SourceArn": "arn:aws:logs:<Region>:<AccountID>:*" } } }}- Tạo và ghi vào một tệp JSON mới cho chính sách quyền IAM bằng trình soạn thảo văn bản ưa thích của bạn:
nano PermissionsForCWL.json
- Chèn các quyền sau vào tệp JSON:
{ "Statement":[ { "Effect":"Allow", "Action":["firehose:PutRecord"], "Resource":[ "arn:aws:firehose:region:account-id:deliverystream/<delivery-stream-name>"] } ]}- Sử dụng lệnh AWS CLI sau để tạo vai trò IAM cho CloudWatch Logs để chèn các bản ghi vào luồng phân phối Firehose:
aws iam create-role \--role-name CWLtoDataFirehoseRole \--assume-role-policy-document file://TrustPolicyForCWL.json- Tạo chính sách IAM và đính kèm nó vào vai trò IAM đã tạo trước đó:
aws iam put-role-policy --role-name CWLtoDataFirehoseRole --policy-name Permissions-Policy-For-CWL --policy-document file://PermissionsForCWL.jsonTạo vai trò IAM cho luồng phân phối Firehose
Bước tiếp theo là tạo một vai trò IAM (DataFirehosetoS3Role) chịu trách nhiệm cho phép luồng phân phối Firehose chèn nhật ký kiểm tra vào một S3 bucket. Hoàn thành các bước sau để tạo vai trò này:
- Kết nối với một terminal với AWS CLI hoặc CloudShell.
- Tạo và ghi vào một tệp JSON cho chính sách tin cậy IAM bằng trình soạn thảo văn bản ưa thích của bạn:
nano PermissionsForCWL.json
- Chèn chính sách tin cậy sau vào tệp JSON:
{ "Statement": { "Effect": "Allow", "Principal": { "Service": "firehose.amazonaws.com" }, "Action": "sts:AssumeRole" } }- Tạo và ghi vào một tệp JSON mới cho các quyền IAM bằng trình soạn thảo văn bản ưa thích của bạn:
nano PermissionsForCWL.json
- Chèn các quyền sau vào tệp JSON:
{ "Statement": [ { "Effect": "Allow", "Action": [ "s3:AbortMultipartUpload", "s3:GetBucketLocation", "s3:GetObject", "s3:ListBucket", "s3:ListBucketMultipartUploads", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::<bucket-name>", "arn:aws:s3:::<bucket-name>/*" ] } ]}- Sử dụng lệnh AWS CLI sau để tạo vai trò IAM cho Data Firehose để thực hiện các hoạt động trên S3 bucket:
aws iam create-role \--role-name DataFirehosetoS3Role \--assume-role-policy-document file://TrustPolicyForFirehose.json- Tạo chính sách IAM và đính kèm nó vào vai trò IAM đã tạo trước đó:
aws iam put-role-policy --role-name DataFirehosetoS3Role --policy-name Permissions-Policy-For-Firehose --policy-document file://PermissionsForFirehose.jsonTạo luồng phân phối Firehose
Bây giờ bạn tạo luồng phân phối Firehose để cho phép chuyển nhật ký kiểm tra MySQL gần thời gian thực từ CloudWatch Logs sang S3 bucket của bạn. Hoàn thành các bước sau:
- Tạo luồng phân phối Firehose bằng lệnh AWS CLI sau. Việc đặt khoảng thời gian và kích thước bộ đệm xác định thời gian dữ liệu của bạn được đệm trước khi được gửi đến S3 bucket. Để biết thêm thông tin, hãy tham khảo tài liệu AWS. Trong ví dụ này, chúng tôi sử dụng các giá trị mặc định:
aws firehose create-delivery-stream \ --delivery-stream-name '<delivery-stream-name>' \ --s3-destination-configuration \ '{"RoleARN": "arn:aws:iam::<AccountID>:role/DataFirehosetoS3Role", "BucketARN": "arn:aws:s3:::<bucket-name>"}'- Đợi cho đến khi luồng phân phối Firehose hoạt động (việc này có thể mất vài phút). Bạn có thể sử dụng lệnh Firehose CLI
describe-delivery-streamđể kiểm tra trạng thái của luồng phân phối. Ghi lại giá trịDeliveryStreamDescription.DeliveryStreamARN, để sử dụng trong bước sau:
aws firehose describe-delivery-stream --delivery-stream-name <delivery-stream-name>
- Sau khi luồng phân phối Firehose ở trạng thái hoạt động, hãy tạo một bộ lọc đăng ký CloudWatch Logs. Bộ lọc đăng ký này ngay lập tức bắt đầu luồng dữ liệu nhật ký gần thời gian thực từ nhóm nhật ký đã chọn đến luồng phân phối Firehose của bạn. Đảm bảo cung cấp tên nhóm nhật ký mà bạn muốn đẩy lên Amazon S3 và sao chép đúng
destination-arncủa luồng phân phối Firehose của bạn:
aws logs put-subscription-filter \ --log-group-name <log-group-name> \ --filter-name "Destination" \ --filter-pattern "" \ --destination-arn "arn:aws:firehose:region:accountID:deliverystream/<delivery-stream-name>" \ --role-arn "arn:aws:iam::accountID:role/CWLtoDataFirehoseRole"Giải pháp nhật ký kiểm tra MySQL gần thời gian thực của bạn hiện đã được cấu hình đúng cách và sẽ bắt đầu gửi nhật ký kiểm tra MySQL đến S3 bucket của bạn thông qua luồng phân phối Firehose.
Dọn dẹp
Để dọn dẹp tài nguyên của bạn, hãy hoàn thành các bước sau (tùy thuộc vào giải pháp bạn đã sử dụng):
- Xóa phiên bản RDS hoặc cụm Aurora.
- Xóa các hàm Lambda.
- Xóa quy tắc EventBridge.
- Xóa S3 bucket.
- Xóa luồng phân phối Firehose.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày hai giải pháp để quản lý nhật ký kiểm tra Aurora MySQL hoặc RDS cho MySQL, mỗi giải pháp mang lại những lợi ích riêng cho các trường hợp sử dụng kinh doanh khác nhau.
Chúng tôi khuyến khích bạn triển khai các giải pháp này trong môi trường của riêng mình và chia sẻ kinh nghiệm, thách thức và câu chuyện thành công của bạn trong phần bình luận. Phản hồi và triển khai thực tế của bạn có thể giúp những người dùng AWS khác lựa chọn và điều chỉnh các giải pháp này để phù hợp nhất với nhu cầu ghi nhật ký kiểm tra cụ thể của họ.
Về tác giả

Mahek Shah
Mahek là Kỹ sư Hỗ trợ Đám mây cấp I, đã làm việc trong nhóm cơ sở dữ liệu AWS gần 2 năm. Mahek là chuyên gia về Amazon Aurora MySQL và RDS MySQL với chuyên môn sâu sắc trong việc giúp khách hàng triển khai các giải pháp cơ sở dữ liệu mạnh mẽ, hiệu suất cao và an toàn trong AWS Cloud.

Ryan Moore
Ryan là Quản lý Tài khoản Kỹ thuật tại AWS với ba năm kinh nghiệm, bắt đầu sự nghiệp trong nhóm cơ sở dữ liệu AWS. Anh là chuyên gia về Aurora MySQL và RDS MySQL, chuyên giúp khách hàng xây dựng các kiến trúc hiệu suất cao, có khả năng mở rộng và an toàn trong AWS Cloud.

Nirupam Datta
Nirupam là Quản lý Tài khoản Kỹ thuật cấp cao tại AWS. Anh đã làm việc tại AWS hơn 6 năm. Với hơn 14 năm kinh nghiệm trong kỹ thuật cơ sở dữ liệu và kiến trúc hạ tầng, Nirupam cũng là chuyên gia về các hệ thống cốt lõi của Amazon RDS và Amazon RDS cho SQL Server. Anh cung cấp hỗ trợ kỹ thuật cho khách hàng, hướng dẫn họ di chuyển, tối ưu hóa và điều hướng hành trình của họ trong AWS Cloud.
