Tác giả: Jiarong Jiang, Akarsha Sehwag, Mani Khanuja, Peng Shi, Ruo Cheng, và Anil Gurrala
Ngày phát hành: 21 JAN 2026
Chuyên mục: Amazon Bedrock, Amazon Bedrock AgentCore, Amazon Machine Learning, Intermediate (200)
Ngày nay, hầu hết các agent chỉ hoạt động dựa trên những gì hiển thị trong tương tác hiện tại: chúng có thể truy cập các sự kiện và kiến thức, nhưng không thể nhớ cách chúng đã giải quyết các vấn đề tương tự trước đây hoặc tại sao một số phương pháp nhất định thành công hay thất bại. Điều này tạo ra một khoảng trống đáng kể trong khả năng học hỏi và cải thiện theo thời gian của chúng. Bộ nhớ theo tập (episodic memory) của Amazon Bedrock AgentCore giải quyết hạn chế này bằng cách thu thập và hiển thị kiến thức cấp độ kinh nghiệm cho các agent AI. Mặc dù bộ nhớ ngữ nghĩa (semantic memory) giúp agent ghi nhớ những gì nó biết, bộ nhớ theo tập ghi lại cách nó đạt được điều đó: mục tiêu, các bước suy luận, hành động, kết quả và phản ánh. Bằng cách chuyển đổi mỗi tương tác thành một tập (episode) có cấu trúc, bạn có thể cho phép các agent gợi lại kiến thức, diễn giải và áp dụng suy luận trước đó. Điều này giúp các agent thích ứng qua các phiên, tránh lặp lại lỗi và phát triển kế hoạch của chúng theo thời gian.
Amazon Bedrock AgentCore Memory là một dịch vụ được quản lý hoàn toàn giúp các nhà phát triển tạo ra các agent AI nhận biết ngữ cảnh thông qua cả khả năng bộ nhớ ngắn hạn và bộ nhớ thông minh dài hạn. Để tìm hiểu thêm, hãy xem Amazon Bedrock AgentCore Memory: Xây dựng các agent nhận biết ngữ cảnh và Xây dựng các agent AI thông minh hơn: Tìm hiểu sâu về bộ nhớ dài hạn của AgentCore.
Trong bài viết này, chúng tôi sẽ hướng dẫn bạn qua kiến trúc hoàn chỉnh để cấu trúc và lưu trữ các tập (episode), thảo luận về module phản ánh (reflection module), và chia sẻ các điểm chuẩn ấn tượng cho thấy sự cải thiện đáng kể trong tỷ lệ thành công của tác vụ agent.
Các thách thức chính trong việc thiết kế bộ nhớ theo tập cho agent
Bộ nhớ theo tập cho phép các agent lưu giữ và suy luận dựa trên kinh nghiệm của chính chúng. Tuy nhiên, việc thiết kế một hệ thống như vậy đòi hỏi phải giải quyết một số thách thức chính để đảm bảo các kinh nghiệm vẫn nhất quán, có thể đánh giá và tái sử dụng được:
- Duy trì tính nhất quán về thời gian và nguyên nhân – Các tập cần giữ nguyên thứ tự và luồng nguyên nhân-kết quả của các bước suy luận, hành động và kết quả để agent có thể hiểu cách các quyết định của nó đã phát triển.
- Phát hiện và phân đoạn nhiều mục tiêu – Các phiên thường liên quan đến các mục tiêu chồng chéo hoặc thay đổi. Bộ nhớ theo tập phải xác định và tách chúng để tránh trộn lẫn các dấu vết suy luận không liên quan.
- Học hỏi từ kinh nghiệm – Mỗi tập nên được đánh giá về sự thành công hay thất bại. Phản ánh sau đó nên so sánh các tập tương tự trong quá khứ để xác định các mẫu và nguyên tắc có thể khái quát hóa, cho phép agent áp dụng những hiểu biết đó vào các mục tiêu mới thay vì phát lại các quỹ đạo trước đó.
Trong phần tiếp theo, chúng tôi mô tả cách xây dựng chiến lược bộ nhớ theo tập của AgentCore, bao gồm quy trình trích xuất, lưu trữ, truy xuất và phản ánh của nó, cũng như cách các thành phần này hoạt động cùng nhau để giúp biến kinh nghiệm thành trí tuệ thích ứng.
Cách bộ nhớ theo tập của AgentCore hoạt động
Khi ứng dụng agent của bạn gửi các sự kiện hội thoại đến AgentCore Memory, các tương tác thô sẽ được chuyển đổi thành các bản ghi bộ nhớ theo tập phong phú thông qua một quy trình trích xuất và phản ánh thông minh. Sơ đồ sau minh họa cách chiến lược bộ nhớ theo tập này hoạt động và cách các cuộc hội thoại agent đơn giản trở thành những ký ức có ý nghĩa, mang tính phản ánh, định hình các tương tác trong tương lai.

Sơ đồ sau minh họa luồng dữ liệu chi tiết của cùng một kiến trúc với nhiều chi tiết hơn.
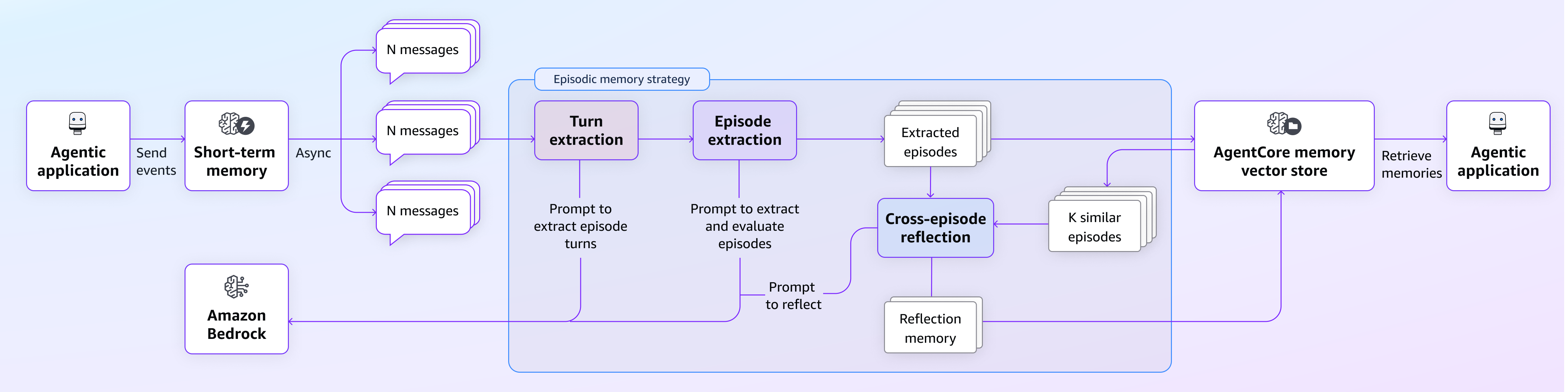
Các sơ đồ trên minh họa các bước khác nhau trong chiến lược bộ nhớ theo tập. Hai bước đầu tiên (được đánh dấu màu hồng và tím) được nhóm lại thành một phương pháp hai giai đoạn của module trích xuất tập (episode extraction module) phục vụ các mục đích riêng biệt nhưng bổ sung cho nhau. Bước thứ ba (được đánh dấu màu xanh lam) là module phản ánh (reflection module), giúp agent học hỏi từ kinh nghiệm trong quá khứ. Trong các phần sau, chúng tôi sẽ thảo luận chi tiết về các bước này.
Module trích xuất tập (Episode extraction module)
Module trích xuất tập là bước nền tảng trong chiến lược theo tập, biến dữ liệu tương tác thô giữa người dùng và agent thành các tập có cấu trúc, có ý nghĩa. Chúng tôi tuân theo phương pháp hai giai đoạn, trong đó các giai đoạn được thiết kế để thu thập cả cơ chế từng bước chi tiết của mỗi tương tác (gọi là trích xuất lượt – turn extraction) và kiến thức rộng hơn theo tập để tạo ra các câu chuyện mạch lạc (gọi là trích xuất tập – episode extraction). Để dễ hình dung, hãy nghĩ về nó như việc ghi chú trong cuộc họp (cấp độ lượt) và viết tóm tắt cuộc họp vào cuối cuộc họp (cấp độ tập). Cả hai giai đoạn đều có giá trị nhưng phục vụ các mục đích khác nhau khi học hỏi từ kinh nghiệm.
Trong giai đoạn đầu tiên của quá trình trích xuất tập, hệ thống thực hiện xử lý cấp độ lượt (turn-level processing) để hiểu điều gì đã diễn ra đúng hoặc sai. Tại đây, các đơn vị trao đổi đơn lẻ giữa người dùng và agent, được gọi là các lượt hội thoại (conversational turns), được xác định, phân đoạn và chuyển đổi thành các bản tóm tắt có cấu trúc theo các khía cạnh sau:
- Turn situation – Mô tả ngắn gọn về hoàn cảnh và ngữ cảnh mà trợ lý đang phản hồi trong lượt này. Điều này bao gồm ngữ cảnh tức thì, các mục tiêu tổng thể của người dùng có thể kéo dài nhiều lượt, và lịch sử liên quan từ các tương tác trước đó đã cung cấp thông tin cho cuộc trao đổi hiện tại.
- Turn intent – Mục đích cụ thể và mục tiêu chính của trợ lý cho lượt này, về cơ bản trả lời câu hỏi “Trợ lý đang cố gắng đạt được điều gì vào thời điểm này?”
- Turn action – Một bản ghi chi tiết về các bước cụ thể đã thực hiện trong tương tác, ghi lại những công cụ cụ thể nào đã được sử dụng, những đối số hoặc tham số đầu vào nào đã được cung cấp cho mỗi công cụ, và cách trợ lý đã chuyển đổi ý định thành các hành động có thể thực thi.
- Turn thought – Lý do đằng sau các quyết định của trợ lý, giải thích “tại sao” lại chọn công cụ và phương pháp tiếp cận.
- Turn assessment – Đánh giá trung thực về việc liệu trợ lý có đạt được mục tiêu đã nêu cho lượt cụ thể này hay không, cung cấp phản hồi tức thì về hiệu quả của phương pháp và hành động đã chọn.
- Goal assessment – Một cái nhìn rộng hơn về việc liệu mục tiêu tổng thể của người dùng trong toàn bộ cuộc hội thoại có vẻ đã được thỏa mãn hoặc đang tiến triển đến hoàn thành hay không, nhìn xa hơn các lượt riêng lẻ để đánh giá sự thành công toàn diện.
Sau khi xử lý và cấu trúc các lượt riêng lẻ, hệ thống chuyển sang giai đoạn trích xuất tập, khi người dùng hoàn thành mục tiêu của họ (được phát hiện bởi mô hình ngôn ngữ lớn) hoặc một tương tác kết thúc. Điều này giúp nắm bắt toàn bộ hành trình của người dùng, bởi vì mục tiêu của người dùng thường kéo dài nhiều lượt và dữ liệu lượt riêng lẻ không thể truyền tải liệu mục tiêu tổng thể đã đạt được hay chiến lược tổng thể trông như thế nào. Trong giai đoạn này, các lượt liên quan theo trình tự được tổng hợp thành các bộ nhớ theo tập mạch lạc, nắm bắt toàn bộ hành trình của người dùng, từ yêu cầu ban đầu đến giải quyết cuối cùng:
- Episode situation – Hoàn cảnh rộng hơn đã khởi xướng nhu cầu hỗ trợ của người dùng
- Episode intent – Một sự diễn đạt rõ ràng về điều người dùng cuối cùng muốn đạt được
- Success evaluation – Đánh giá dứt khoát về việc liệu cuộc hội thoại có đạt được mục đích dự định cho mỗi tập hay không
- Evaluation justification – Lý do cụ thể cho các đánh giá thành công hoặc thất bại, dựa trên các khoảnh khắc hội thoại cụ thể cho thấy sự tiến bộ hoặc xa rời mục tiêu của người dùng
- Episode insights – Các hiểu biết sâu sắc nắm bắt các phương pháp đã được chứng minh hiệu quả và xác định những cạm bẫy cần tránh cho tập hiện tại
Module phản ánh (Reflection module)
Module phản ánh làm nổi bật khả năng của bộ nhớ theo tập của Amazon Bedrock AgentCore trong việc học hỏi từ kinh nghiệm trong quá khứ và tạo ra các hiểu biết sâu sắc giúp cải thiện hiệu suất trong tương lai. Đây là nơi các bài học từ từng tập riêng lẻ phát triển thành kiến thức có thể khái quát hóa, có thể hướng dẫn các agent trong nhiều kịch bản khác nhau.
Module phản ánh hoạt động thông qua phản ánh đa tập (cross-episodic reflection), truy xuất các tập thành công tương tự trong quá khứ dựa trên ý định của người dùng và phản ánh trên nhiều tập để đạt được những hiểu biết sâu sắc có thể khái quát hóa hơn. Khi các tập mới được xử lý, hệ thống thực hiện các hành động sau:
- Sử dụng ý định của người dùng làm khóa ngữ nghĩa, hệ thống xác định các tập thành công và liên quan trong lịch sử từ kho lưu trữ vector, chia sẻ các mục tiêu, ngữ cảnh hoặc miền vấn đề tương tự.
- Hệ thống phân tích các mẫu trên tập chính và các tập liên quan, tìm kiếm các hiểu biết có thể chuyển giao về những phương pháp nào hoạt động nhất quán trong các ngữ cảnh khác nhau.
- Kiến thức phản ánh hiện có được xem xét và hoặc được nâng cao với những hiểu biết mới hoặc được mở rộng với các mẫu hoàn toàn mới được phát hiện thông qua phân tích đa tập.
Vào cuối quá trình, mỗi bản ghi bộ nhớ phản ánh chứa thông tin sau:
- Use case – Khi nào và ở đâu hiểu biết này được áp dụng, bao gồm các mục tiêu người dùng liên quan và các điều kiện kích hoạt
- Hints (insights) – Hướng dẫn có thể hành động bao gồm các chiến lược lựa chọn công cụ, các phương pháp hiệu quả và những cạm bẫy cần tránh
- Confidence scoring – Điểm số (0.1–1.0) cho biết mức độ khái quát hóa của hiểu biết này trên các kịch bản khác nhau
Các tập cung cấp cho các agent những ví dụ cụ thể về cách các vấn đề tương tự đã được giải quyết trước đây. Các nghiên cứu điển hình này cho thấy các công cụ cụ thể được sử dụng, suy luận được áp dụng và kết quả đạt được, bao gồm cả thành công và thất bại. Điều này tạo ra một khuôn khổ học tập nơi các agent có thể tuân theo các chiến lược đã được chứng minh và tránh những lỗi đã được ghi lại.
Bộ nhớ phản ánh trích xuất các mẫu từ nhiều tập để cung cấp những hiểu biết chiến lược. Thay vì các trường hợp riêng lẻ, chúng tiết lộ công cụ nào hoạt động tốt nhất, phương pháp ra quyết định nào thành công và yếu tố nào thúc đẩy kết quả. Những nguyên tắc chắt lọc này cung cấp cho các agent hướng dẫn cấp cao hơn để điều hướng các kịch bản phức tạp.
Cấu hình ghi đè tùy chỉnh
Mặc dù các chiến lược bộ nhớ tích hợp sẵn bao gồm các trường hợp sử dụng phổ biến, nhiều miền yêu cầu các phương pháp tiếp cận tùy chỉnh để xử lý bộ nhớ. Hệ thống hỗ trợ ghi đè chiến lược tích hợp sẵn thông qua các lời nhắc tùy chỉnh mở rộng logic tích hợp sẵn, giúp các nhóm điều chỉnh việc xử lý bộ nhớ theo yêu cầu cụ thể của họ. Bạn có thể triển khai các cấu hình ghi đè tùy chỉnh sau:
- Lời nhắc tùy chỉnh (Custom prompts) – Các lời nhắc này tập trung vào tiêu chí và logic hơn là định dạng đầu ra và giúp các nhà phát triển xác định những điều sau:
- Tiêu chí trích xuất – Thông tin nào được trích xuất hoặc lọc bỏ.
- Quy tắc hợp nhất – Cách các bộ nhớ liên quan nên được hợp nhất.
- Giải quyết xung đột – Cách xử lý thông tin mâu thuẫn.
- Tạo hiểu biết sâu sắc – Cách các phản ánh đa tập được tổng hợp.
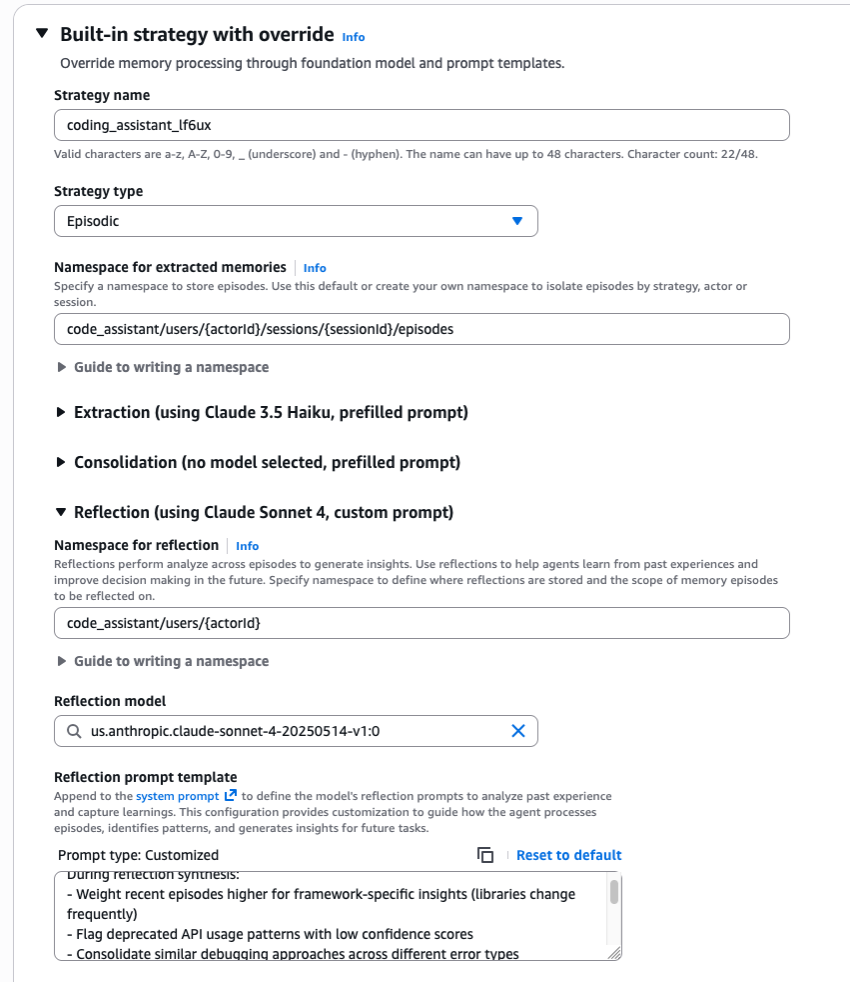
- Mô hình tùy chỉnh (Custom model): AgentCore Memory hỗ trợ lựa chọn mô hình tùy chỉnh cho các hoạt động trích xuất, hợp nhất và phản ánh bộ nhớ. Sự linh hoạt này giúp các nhà phát triển cân bằng độ chính xác và độ trễ dựa trên các yêu cầu cụ thể của họ. Bạn có thể định nghĩa chúng bằng API khi tạo
_memory_resource_dưới dạng ghi đè chiến lược hoặc thông qua bảng điều khiển Amazon Bedrock AgentCore (như trong ảnh chụp màn hình sau). - Không gian tên (Namespaces): Không gian tên cung cấp một tổ chức phân cấp cho các tập và phản ánh, cho phép truy cập vào kinh nghiệm của agent ở các cấp độ chi tiết khác nhau và cung cấp một nhóm logic tự nhiên liền mạch. Ví dụ, để thiết kế một không gian tên cho ứng dụng du lịch, các tập có thể được lưu trữ dưới
travel_booking/users/userABC/episodesvà các phản ánh có thể nằm ởtravel_booking/users/userABC. Lưu ý rằng không gian tên cho các phản ánh phải là một đường dẫn con của không gian tên cho các tập.
Đánh giá hiệu suất
Chúng tôi đã đánh giá bộ nhớ theo tập của Amazon Bedrock AgentCore trên các điểm chuẩn hoàn thành mục tiêu trong thế giới thực từ lĩnh vực bán lẻ và hàng không (được lấy mẫu từ τ2-bench). Các điểm chuẩn này chứa các tác vụ phản ánh các kịch bản dịch vụ khách hàng thực tế, nơi các agent cần giúp người dùng đạt được các mục tiêu cụ thể.
Chúng tôi đã so sánh ba thiết lập khác nhau trong các thử nghiệm của mình:
- Đối với baseline, chúng tôi chạy agent (được xây dựng với Claude 3.7 của Anthropic) mà không tương tác với thành phần bộ nhớ.
- Đối với các agent được tăng cường bộ nhớ, chúng tôi đã khám phá hai phương pháp sử dụng bộ nhớ:
- Ví dụ học tập trong ngữ cảnh (In-context learning examples) – Phương pháp đầu tiên sử dụng các tập được trích xuất làm ví dụ học tập trong ngữ cảnh. Cụ thể, chúng tôi đã xây dựng một công cụ có tên
retrieve_exemplars(định nghĩa công cụ trong phụ lục) mà các agent có thể sử dụng bằng cách đưa ra một truy vấn (ví dụ: “làm thế nào để được hoàn tiền?”) để nhận hướng dẫn từng bước từ kho lưu trữ các tập. Khi các agent đối mặt với các vấn đề tương tự, các tập được truy xuất sẽ được thêm vào ngữ cảnh để hướng dẫn agent thực hiện hành động tiếp theo. - Phản ánh làm hướng dẫn (Reflection-as-guidance) – Phương pháp thứ hai chúng tôi khám phá là phản ánh làm hướng dẫn. Cụ thể, chúng tôi xây dựng một công cụ có tên
retrieve_reflections(định nghĩa công cụ trong phụ lục) mà các agent có thể sử dụng để truy cập các hiểu biết rộng hơn từ kinh nghiệm trong quá khứ. Tương tự nhưretrieve_exemplars, agent có thể tạo một truy vấn để truy xuất các phản ánh làm ngữ cảnh, thu được những hiểu biết sâu sắc để đưa ra các quyết định sáng suốt về chiến lược và phương pháp tiếp cận thay vì các hành động từng bước cụ thể.
- Ví dụ học tập trong ngữ cảnh (In-context learning examples) – Phương pháp đầu tiên sử dụng các tập được trích xuất làm ví dụ học tập trong ngữ cảnh. Cụ thể, chúng tôi đã xây dựng một công cụ có tên
Chúng tôi đã sử dụng phương pháp đánh giá sau:
- Agent baseline đầu tiên xử lý một tập hợp các tương tác lịch sử của khách hàng, trở thành nguồn để trích xuất bộ nhớ.
- Agent sau đó nhận các truy vấn người dùng mới từ τ2-bench.
- Mỗi truy vấn được thử bốn lần song song.
- Để đánh giá, các chỉ số tỷ lệ đạt (pass rate metrics) được đo trên bốn lần thử này. Pass^k đo tỷ lệ phần trăm các tác vụ mà agent thành công ít nhất k trong số bốn lần thử:
- Pass^1: Thành công ít nhất một lần (đo khả năng)
- Pass^2: Thành công ít nhất hai lần (đo độ tin cậy)
- Pass^3: Thành công ít nhất ba lần (đo tính nhất quán)
Kết quả trong bảng sau cho thấy sự cải thiện rõ rệt trên cả hai miền và nhiều lần thử.
| System | Memory Type used by Agent | Retail | Airline | ||||
|---|---|---|---|---|---|---|---|
| Pass^1 | Pass^2 | Pass^3 | Pass^1 | Pass^2 | Pass^3 | ||
| Baseline | No Memory | 65.80% | 49.70% | 42.10% | 47% | 33.30% | 24% |
| Memory-Augmented Agent | Episodes as ICL Example | 69.30% | 53.80% | 43.40% | 55.00% | 46.70% | 43.00% |
| Cross Episodes Reflection Memory | 77.20% | 64.30% | 55.70% | 58% | 46% | 41% |
Các agent được tăng cường bộ nhớ liên tục vượt trội hơn baseline trên các miền và mức độ nhất quán. Quan trọng hơn, những kết quả này chứng minh rằng các chiến lược truy xuất bộ nhớ khác nhau phù hợp hơn với các đặc điểm tác vụ khác nhau. Phản ánh đa tập đã cải thiện Pass^1 thêm +11.4% và Pass^3 thêm +13.6% so với baseline, cho thấy rằng những hiểu biết chiến lược tổng quát đặc biệt có giá trị khi xử lý các kịch bản dịch vụ khách hàng mở với các mẫu tương tác đa dạng. Ngược lại, miền hàng không – đặc trưng bởi các chính sách dựa trên quy tắc phức tạp và các quy trình nhiều bước – hưởng lợi nhiều hơn từ các tập làm ví dụ, đạt Pass^3 cao nhất (43.0% so với 41.0% đối với phản ánh). Điều này cho thấy rằng các ví dụ từng bước cụ thể giúp các agent điều hướng các quy trình làm việc có cấu trúc một cách đáng tin cậy. Sự cải thiện tương đối rõ rệt nhất ở các ngưỡng nhất quán cao hơn (Pass^3), nơi bộ nhớ giúp các agent tránh những lỗi gây ra sự cố gián đoạn.
Các phương pháp hay nhất để sử dụng bộ nhớ theo tập
Chìa khóa để có bộ nhớ theo tập hiệu quả là biết khi nào nên sử dụng nó và loại nào phù hợp với tình huống của bạn. Trong phần này, chúng tôi sẽ thảo luận về những gì chúng tôi đã học được là hiệu quả nhất.
Khi nào nên sử dụng bộ nhớ theo tập
Bộ nhớ theo tập mang lại giá trị lớn nhất khi bạn khớp đúng loại bộ nhớ với nhu cầu hiện tại của mình. Nó lý tưởng cho các tác vụ phức tạp, nhiều bước, nơi ngữ cảnh và kinh nghiệm trong quá khứ có ý nghĩa quan trọng, chẳng hạn như gỡ lỗi code, lập kế hoạch chuyến đi và phân tích dữ liệu. Nó cũng đặc biệt có giá trị cho các quy trình làm việc lặp đi lặp lại, nơi việc học hỏi từ các lần thử trước có thể cải thiện đáng kể kết quả, và cho các vấn đề cụ thể theo miền nơi chuyên môn tích lũy tạo ra sự khác biệt thực sự.
Tuy nhiên, bộ nhớ theo tập không phải lúc nào cũng là lựa chọn đúng đắn. Bạn có thể bỏ qua nó đối với các câu hỏi đơn giản, một lần như kiểm tra thời tiết hoặc các sự kiện cơ bản không cần suy luận hoặc ngữ cảnh. Các cuộc hội thoại dịch vụ khách hàng đơn giản, hỏi đáp cơ bản hoặc trò chuyện thông thường không cần các tính năng nâng cao mà bộ nhớ theo tập bổ sung. Lợi ích thực sự của bộ nhớ theo tập được quan sát theo thời gian. Đối với các tác vụ ngắn, tóm tắt phiên cung cấp đủ thông tin. Tuy nhiên, đối với các tác vụ phức tạp và quy trình làm việc lặp đi lặp lại, bộ nhớ theo tập giúp các agent xây dựng dựa trên kinh nghiệm trong quá khứ và liên tục cải thiện hiệu suất của chúng.
Lựa chọn giữa các tập (episodes) và phản ánh (reflection)
Các tập hoạt động tốt nhất khi bạn đối mặt với các vấn đề cụ thể tương tự và cần hướng dẫn rõ ràng. Nếu bạn đang gỡ lỗi một thành phần React không hiển thị, các tập có thể cho bạn thấy chính xác cách các vấn đề tương tự đã được khắc phục trước đây, bao gồm các công cụ cụ thể được sử dụng, quá trình tư duy và kết quả. Chúng cung cấp cho bạn các ví dụ thực tế khi lời khuyên chung không đủ, cho thấy con đường hoàn chỉnh từ việc tìm ra vấn đề đến giải quyết nó.
Bộ nhớ phản ánh hoạt động tốt nhất khi bạn cần hướng dẫn chiến lược trong các ngữ cảnh rộng hơn thay vì các giải pháp từng bước cụ thể. Sử dụng phản ánh khi bạn đối mặt với một loại vấn đề mới và cần hiểu các nguyên tắc chung, chẳng hạn như “Phương pháp hiệu quả nhất cho các tác vụ trực quan hóa dữ liệu là gì?” hoặc “Những chiến lược gỡ lỗi nào có xu hướng hoạt động tốt nhất cho các vấn đề tích hợp API?” Phản ánh đặc biệt có giá trị khi bạn đưa ra các quyết định cấp cao về lựa chọn công cụ và phương pháp cần tuân theo, hoặc hiểu tại sao một số mẫu nhất định lại thành công hoặc thất bại một cách nhất quán.
Trước khi bắt đầu các tác vụ, hãy kiểm tra các phản ánh để được hướng dẫn chiến lược, xem xét các tập tương tự để tìm các mẫu giải pháp và tìm các lỗi có độ tin cậy cao đã được ghi lại trong các lần thử trước. Trong quá trình thực hiện tác vụ, hãy xem xét các tập khi bạn gặp trở ngại, sử dụng các hiểu biết sâu sắc từ phản ánh để lựa chọn công cụ và suy nghĩ về cách tình huống hiện tại của bạn khác với các ví dụ trong quá khứ.
Kết luận
Bộ nhớ theo tập lấp đầy một khoảng trống quan trọng trong khả năng hiện tại của các agent. Bằng cách lưu trữ các đường dẫn suy luận hoàn chỉnh và học hỏi từ kết quả, các agent có thể tránh lặp lại lỗi và xây dựng dựa trên các chiến lược thành công.
Bộ nhớ theo tập hoàn thiện khuôn khổ bộ nhớ của Amazon Bedrock AgentCore cùng với bộ nhớ tóm tắt (summarization), bộ nhớ ngữ nghĩa (semantic) và bộ nhớ ưu tiên (preference). Mỗi loại phục vụ một mục đích cụ thể: bộ nhớ tóm tắt quản lý độ dài ngữ cảnh, bộ nhớ ngữ nghĩa lưu trữ các sự kiện, bộ nhớ ưu tiên xử lý cá nhân hóa, và bộ nhớ theo tập thu thập kinh nghiệm. Sự kết hợp này giúp các agent có cả kiến thức có cấu trúc và kinh nghiệm thực tế để xử lý các tác vụ phức tạp hiệu quả hơn.
Để tìm hiểu thêm về bộ nhớ theo tập, hãy tham khảo Chiến lược bộ nhớ theo tập, Cách tốt nhất để truy xuất các tập nhằm cải thiện hiệu suất của agent, và các mẫu AgentCore Memory trên GitHub.
Phụ lục
Trong phần này, chúng tôi thảo luận về hai phương pháp sử dụng bộ nhớ cho các agent được tăng cường bộ nhớ.
Ví dụ về tập (Episode example)
Sau đây là một ví dụ sử dụng các tập được trích xuất làm ví dụ học tập trong ngữ cảnh:
** Context **A customer (Jane Doe) contacted customer service expressing frustration about a recent flight delay that disrupted their travel plans and wanted to discuss compensation or resolution options for the inconvenience they experienced.** Goal **The user's primary goal was to obtain compensation or some form of resolution for a flight delay they experienced, seeking acknowledgment of the disruption and appropriate remediation from the airline.---### Step 1:**Thought:**The assistant chose to gather information systematically rather than making assumptions, as flight delay investigations require specific reservation and flight details. This approach facilitates accurate assistance and demonstrates professionalism by acknowledging the customer's frustration while taking concrete steps to help resolve the issue.**Action:**The assistant responded conversationally without using any tools, asking the user to provide their user ID to access reservation details.--- End of Step 1 ---...** Episode Reflection **:The conversation demonstrates an excellent systematic approach to flight modifications: starting with reservation verification, then identifying confirmation, followed by comprehensive flight searches, and finally processing changes with proper authorization. The assistant effectively used appropriate tools in a logical sequence - get_reservation_details for verification, get_user_details for identity/payment info, search_direct_flight for options, and update tools for processing changes. Key strengths included transparent pricing calculations, proactive mention of insurance benefits, clear presentation of options, and proper handling of policy constraints (explaining why mixed cabin classes aren't allowed). The assistant successfully leveraged user benefits (Gold status for free bags) and maintained security protocols throughout. This methodical approach made sure user needs were addressed while following proper procedures for reservation modifications.Ví dụ về phản ánh (Reflection example)
Sau đây là một ví dụ về bộ nhớ phản ánh, có thể được sử dụng để hướng dẫn agent:
**Title:** Proactive Alternative Search Despite Policy Restrictions**Use Cases:**This applies when customers request flight modifications or changes that are blocked by airline policies (such as basic economy no-change rules, fare class restrictions, or booking timing limitations). Rather than simply declining the request, this pattern involves immediately searching for alternative solutions to help customers achieve their underlying goals. It's particularly valuable for emergency situations, budget-conscious travelers, or when customers have specific timing needs that their current reservations don't accommodate.**Hints:**When policy restrictions prevent the requested modification, immediately pivot to solution-finding rather than just explaining limitations. Use search_direct_flight to find alternative options that could meet the customer's needs, even if it requires separate bookings or different approaches. Present both the policy constraint explanation AND viable alternatives in the same response to maintain momentum toward resolution. Consider the customer's underlying goal (getting home earlier, changing dates, etc.) and search for flights that accomplish this objective. When presenting alternatives, organize options clearly by date and price, highlight budget-friendly choices, and explain the trade-offs between keeping existing reservations versus canceling and rebooking. This approach transforms policy limitations into problem-solving opportunities and maintains customer satisfaction even when the original request cannot be fulfilled.Định nghĩa công cụ
Đoạn code sau là định nghĩa công cụ cho retrieve_exemplars:
def retrieve_exemplars(task: str) -> str: """ Retrieve example processes to help solve the given task. Args: task: The task to solve that requires example processes. Returns: str: The example processes to help solve the given task. """Sau đây là định nghĩa công cụ cho retrieve_reflections:
def retrieve_reflections(task: str, k: int = 5) -> str: """ Retrieve synthesized reflection knowledge from past agent experiences by matching against knowledge titles and use cases. Each knowledge entry contains: (1) a descriptive title, (2) specific use cases describing the types of goals where this knowledge applies and when to apply it, and (3) actionable hints including best practices from successful episodes and common pitfalls to avoid from failed episodes. Use this to get strategic guidance for similar tasks. Args: task: The current task or goal you are trying to accomplish. This will be matched against knowledge titles and use cases to find relevant reflection knowledge. Describe your task clearly to get the most relevant matches. k: Number of reflection knowledge entries to retrieve. Default is 5. Returns: str: The synthesized reflection knowledge from past agent experiences. """Về tác giả

Jiarong Jiang là Nhà khoa học ứng dụng chính tại AWS, thúc đẩy đổi mới trong Retrieval Augmented Generation (RAG) và các hệ thống bộ nhớ agent để cải thiện độ chính xác và thông minh của AI doanh nghiệp. Cô ấy đam mê giúp khách hàng xây dựng các ứng dụng nhận biết ngữ cảnh, dựa trên suy luận, sử dụng dữ liệu của riêng họ một cách hiệu quả.

Akarsha Sehwag là Nhà khoa học dữ liệu AI tạo sinh cho nhóm Amazon Bedrock AgentCore Memory. Với hơn 6 năm kinh nghiệm trong AI/ML, cô đã xây dựng các giải pháp doanh nghiệp sẵn sàng sản xuất trên nhiều phân khúc khách hàng đa dạng trong các lĩnh vực AI tạo sinh, học sâu và thị giác máy tính. Ngoài công việc, cô thích đi bộ đường dài, đạp xe và chơi cầu lông.

Mani Khanuja là Chuyên gia SA AI tạo sinh chính và là tác giả của cuốn sách Applied Machine Learning and High-Performance Computing on AWS. Cô dẫn dắt các dự án học máy trong nhiều lĩnh vực khác nhau như thị giác máy tính, xử lý ngôn ngữ tự nhiên và AI tạo sinh. Cô thường phát biểu tại các hội nghị nội bộ và bên ngoài như AWS re:Invent, Women in Manufacturing West, hội thảo trực tuyến trên YouTube và GHC 23. Trong thời gian rảnh rỗi, cô thích chạy bộ dài dọc bãi biển.

Peng Shi là Nhà khoa học ứng dụng cấp cao tại AWS, nơi anh dẫn đầu các tiến bộ trong hệ thống bộ nhớ agent để nâng cao độ chính xác, khả năng thích ứng và năng lực suy luận của AI. Công việc của anh tập trung vào việc tạo ra các ứng dụng thông minh hơn và nhận biết ngữ cảnh, kết nối nghiên cứu tiên tiến với tác động trong thế giới thực.

Anil Gurrala là Kiến trúc sư giải pháp cấp cao tại AWS có trụ sở tại Atlanta. Với hơn 3 năm làm việc tại Amazon và gần hai thập kỷ kinh nghiệm trong đổi mới và chuyển đổi kỹ thuật số, anh giúp khách hàng với các sáng kiến hiện đại hóa, thiết kế kiến trúc và tối ưu hóa trên AWS. Anil chuyên triển khai các giải pháp AI agentic trong khi hợp tác với các doanh nghiệp để kiến trúc các ứng dụng có khả năng mở rộng và tối ưu hóa việc triển khai chúng trong môi trường đám mây AWS. Ngoài công việc, Anil thích chơi bóng chuyền và cầu lông, cũng như khám phá những điểm đến mới trên khắp thế giới.

Ruo Cheng là Nhà thiết kế UX cấp cao tại AWS, thiết kế trải nghiệm AI doanh nghiệp và nhà phát triển trên Amazon Bedrock và Amazon Bedrock AgentCore. Với một thập kỷ kinh nghiệm, cô dẫn dắt thiết kế cho AgentCore Memory, định hình các quy trình làm việc và khả năng liên quan đến bộ nhớ cho các ứng dụng dựa trên agent. Ruo đam mê chuyển đổi các khái niệm AI và cơ sở hạ tầng phức tạp thành trải nghiệm trực quan, lấy người dùng làm trung tâm.
