Tác giả: Tarik Arici, Amin Banitalebi, Erdinc Basci, Mey Meenakshisundaram, Puneet Sahni, and Sameer Thombare
Ngày phát hành: 23 JAN 2026
Chuyên mục: Amazon Bedrock, Amazon Bedrock AgentCore, Customer Solutions, Generative AI, Technical How-to
Danh mục Amazon.com là nền tảng của mọi trải nghiệm mua sắm của khách hàng—nguồn thông tin sản phẩm chính xác với các thuộc tính hỗ trợ tìm kiếm, đề xuất và khám phá. Khi người bán niêm yết một sản phẩm mới, hệ thống danh mục phải trích xuất các thuộc tính có cấu trúc—kích thước, vật liệu, khả năng tương thích và thông số kỹ thuật—đồng thời tạo nội dung như tiêu đề phù hợp với cách khách hàng tìm kiếm. Một tiêu đề không phải là một danh sách đơn giản như màu sắc hoặc kích thước; nó phải cân bằng ý định của người bán, hành vi tìm kiếm của khách hàng và khả năng khám phá. Sự phức tạp này, nhân với hàng triệu lượt gửi hàng ngày, khiến việc làm giàu danh mục trở thành một thử nghiệm lý tưởng cho AI tự học.
Trong bài viết này, chúng tôi trình bày cách Đội ngũ Danh mục Amazon đã xây dựng một hệ thống tự học liên tục cải thiện độ chính xác đồng thời giảm chi phí ở quy mô lớn bằng cách sử dụng Amazon Bedrock.
Thách thức
Trong môi trường triển khai AI tạo sinh, việc cải thiện hiệu suất mô hình đòi hỏi sự chú ý liên tục. Vì các mô hình xử lý hàng triệu sản phẩm, chúng chắc chắn gặp phải các trường hợp ngoại lệ, thuật ngữ đang phát triển và các mẫu cụ thể theo miền mà độ chính xác có thể bị suy giảm. Cách tiếp cận truyền thống—các nhà khoa học ứng dụng phân tích lỗi, cập nhật lời nhắc, kiểm tra thay đổi và triển khai lại—có hiệu quả nhưng tốn nhiều tài nguyên và khó theo kịp khối lượng và sự đa dạng trong thế giới thực. Thách thức không phải là liệu chúng ta có thể cải thiện các hệ thống này hay không, mà là làm thế nào để việc cải thiện có thể mở rộng và tự động thay vì phụ thuộc vào sự can thiệp thủ công. Tại Danh mục Amazon, chúng tôi đã đối mặt trực tiếp với thách thức này. Sự đánh đổi dường như là không thể: các mô hình lớn sẽ mang lại độ chính xác nhưng không thể mở rộng hiệu quả theo khối lượng của chúng tôi, trong khi các mô hình nhỏ hơn gặp khó khăn với các trường hợp phức tạp, mơ hồ mà người bán cần trợ giúp nhiều nhất.
Tổng quan giải pháp
Bước đột phá của chúng tôi đến từ một thử nghiệm độc đáo. Thay vì chọn một mô hình duy nhất, chúng tôi đã triển khai nhiều mô hình nhỏ hơn để xử lý cùng một sản phẩm. Khi các mô hình này đồng ý về việc trích xuất thuộc tính, chúng tôi có thể tin tưởng vào kết quả. Nhưng khi chúng không đồng ý—cho dù do sự mơ hồ thực sự, thiếu ngữ cảnh, hay một mô hình mắc lỗi—chúng tôi đã khám phá ra một điều sâu sắc. Những bất đồng này không phải lúc nào cũng là lỗi, nhưng chúng hầu như luôn là dấu hiệu của sự phức tạp. Điều này đã dẫn chúng tôi đến việc thiết kế một hệ thống tự học tái định hình cách AI tạo sinh mở rộng quy mô. Nhiều mô hình nhỏ hơn xử lý các trường hợp thông thường thông qua sự đồng thuận, chỉ gọi các mô hình lớn hơn khi xảy ra bất đồng. Mô hình lớn hơn được triển khai dưới dạng một tác nhân giám sát có quyền truy cập vào các công cụ chuyên biệt để điều tra và phân tích sâu hơn. Nhưng tác nhân giám sát không chỉ giải quyết tranh chấp; nó tạo ra các kiến thức có thể tái sử dụng được lưu trữ trong một cơ sở tri thức động giúp ngăn chặn toàn bộ các loại bất đồng trong tương lai. Chúng tôi chỉ gọi các mô hình mạnh hơn khi hệ thống phát hiện giá trị học tập cao tại thời điểm suy luận, đồng thời sửa đầu ra. Kết quả là một hệ thống tự học trong đó chi phí giảm và chất lượng tăng—vì hệ thống học cách xử lý các trường hợp ngoại lệ mà trước đây đã kích hoạt các cuộc gọi giám sát. Tỷ lệ lỗi giảm liên tục, không phải thông qua việc đào tạo lại mà thông qua các kiến thức tích lũy từ các bất đồng đã được giải quyết được đưa vào các lời nhắc của mô hình nhỏ hơn. Hình sau đây cho thấy kiến trúc của hệ thống tự học này.
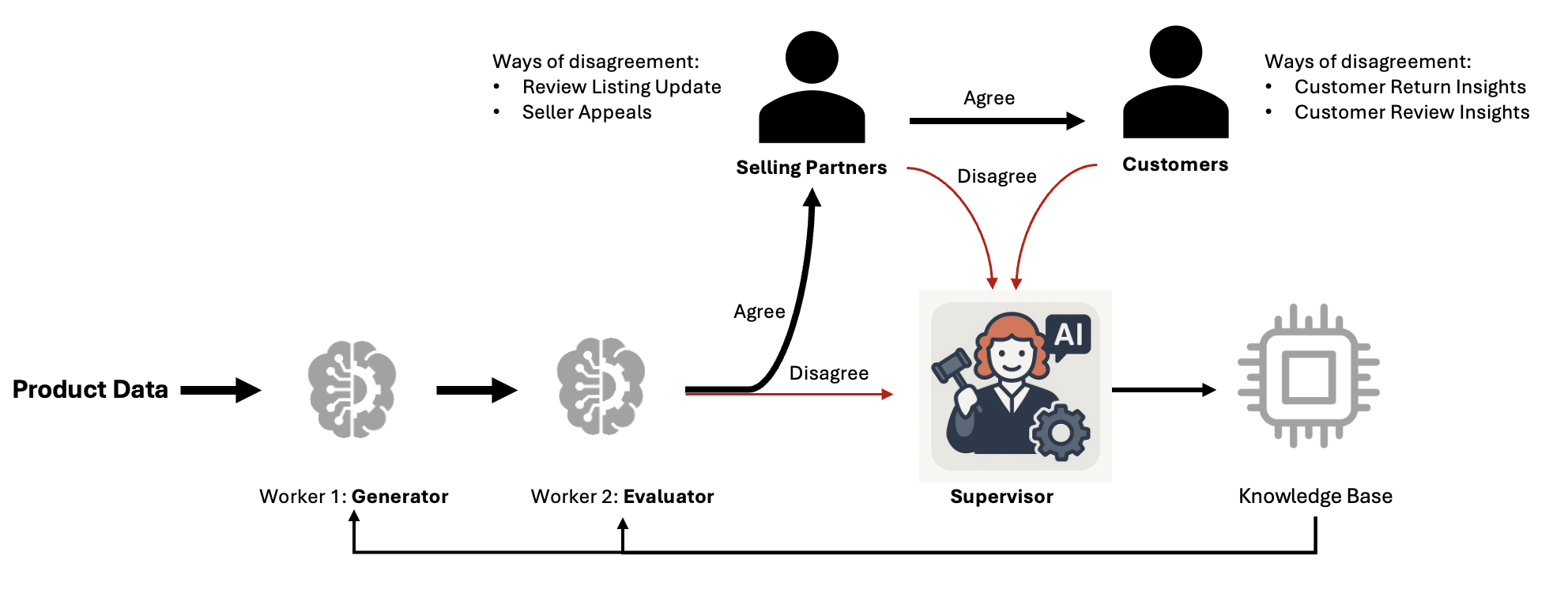
Trong kiến trúc tự học, dữ liệu sản phẩm chảy qua các worker tạo sinh-đánh giá, với các bất đồng được chuyển đến một tác nhân giám sát để điều tra. Sau suy luận, hệ thống cũng thu thập các tín hiệu phản hồi từ người bán (chẳng hạn như cập nhật danh sách và kháng nghị) và khách hàng (chẳng hạn như trả hàng và đánh giá tiêu cực). Các kiến thức từ các nguồn này được lưu trữ trong một cơ sở tri thức phân cấp và được đưa trở lại các lời nhắc của worker, tạo ra một vòng lặp cải tiến liên tục.
Sau đây mô tả một kiến trúc tham chiếu đơn giản hóa minh họa cách mẫu tự học này có thể được triển khai bằng các dịch vụ AWS. Mặc dù hệ thống sản xuất của chúng tôi có độ phức tạp bổ sung, ví dụ này minh họa các thành phần cốt lõi và luồng dữ liệu.
Hệ thống này có thể được xây dựng bằng Amazon Bedrock, cung cấp cơ sở hạ tầng thiết yếu cho các kiến trúc đa mô hình. Khả năng của Amazon Bedrock trong việc truy cập các Foundation Model đa dạng cho phép các nhóm triển khai các mô hình nhỏ hơn, hiệu quả như Amazon Nova Lite làm worker và các mô hình có khả năng hơn như Anthropic Claude Sonnet làm tác nhân giám sát—tối ưu hóa cả chi phí và hiệu suất. Để đạt hiệu quả chi phí cao hơn nữa ở quy mô lớn, các nhóm cũng có thể triển khai các mô hình nhỏ mã nguồn mở trên các phiên bản GPU Amazon Elastic Compute Cloud (Amazon EC2), cung cấp toàn quyền kiểm soát việc lựa chọn mô hình worker và tối ưu hóa thông lượng theo lô. Để đưa tác nhân giám sát vào sản xuất với các công cụ chuyên biệt và cơ sở tri thức động của nó, Bedrock AgentCore cung cấp khả năng mở rộng thời gian chạy, quản lý bộ nhớ và khả năng quan sát cần thiết để triển khai các hệ thống tự học một cách đáng tin cậy ở quy mô lớn.
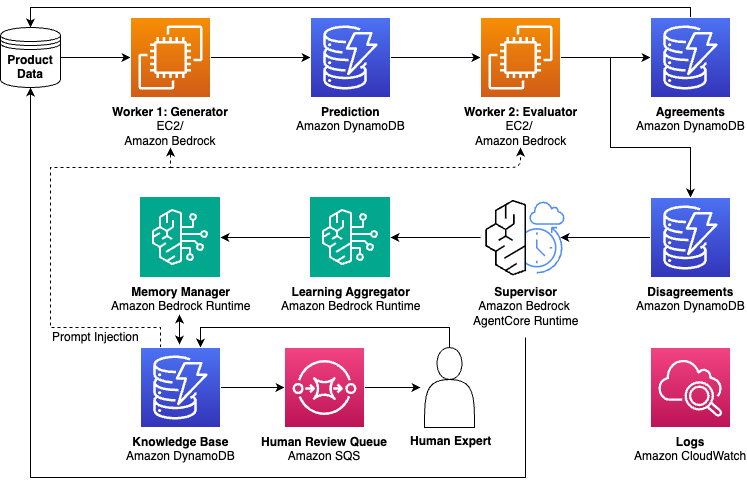
Tác nhân giám sát của chúng tôi tích hợp với các Hệ thống Lựa chọn và Danh mục rộng lớn của Amazon. Sơ đồ trên là một cái nhìn đơn giản hóa cho thấy các tính năng chính của tác nhân và một số dịch vụ AWS giúp điều đó có thể. Dữ liệu sản phẩm chảy qua các worker tạo sinh-đánh giá (Amazon EC2 và Amazon Bedrock Runtime), với các thỏa thuận được lưu trữ trực tiếp và các bất đồng được chuyển đến một tác nhân giám sát (Bedrock AgentCore). Trình tổng hợp kiến thức và trình quản lý bộ nhớ sử dụng Amazon DynamoDB cho cơ sở tri thức, với các kiến thức được đưa trở lại các lời nhắc của worker. Đánh giá của con người (Amazon Simple Queue Service (Amazon SQS)) và khả năng quan sát (Amazon CloudWatch) hoàn thiện kiến trúc. Các triển khai sản xuất có thể sẽ yêu cầu các thành phần bổ sung để mở rộng quy mô, độ tin cậy và tích hợp với các hệ thống hiện có.
Nhưng làm thế nào chúng tôi đạt được kiến trúc này? Insight chính đến từ một nơi bất ngờ.
Insight: Biến bất đồng thành cơ hội
Quan điểm của chúng tôi đã thay đổi trong một phiên gỡ lỗi. Khi nhiều mô hình nhỏ hơn (chẳng hạn như Nova Lite) không đồng ý về các thuộc tính sản phẩm—diễn giải cùng một thông số kỹ thuật khác nhau dựa trên cách chúng hiểu thuật ngữ kỹ thuật—chúng tôi ban đầu coi đây là một thất bại. Nhưng dữ liệu lại kể một câu chuyện khác: các sản phẩm mà các mô hình nhỏ hơn của chúng tôi không đồng ý tương quan với các trường hợp yêu cầu xem xét và làm rõ thủ công nhiều hơn. Khi các mô hình không đồng ý, đó chính xác là những sản phẩm cần điều tra thêm. Các bất đồng đang làm nổi bật các cơ hội học tập, nhưng chúng tôi không thể có các kỹ sư và nhà khoa học đi sâu vào từng trường hợp. Tác nhân giám sát thực hiện điều này tự động ở quy mô lớn. Và quan trọng là, mục tiêu không chỉ là xác định mô hình nào đúng—mà là trích xuất các kiến thức giúp ngăn chặn các bất đồng tương tự trong tương lai. Đây là chìa khóa để mở rộng quy mô hiệu quả. Các bất đồng không chỉ đến từ các worker AI tại thời điểm suy luận. Sau suy luận, người bán bày tỏ sự không đồng ý thông qua các cập nhật danh sách và kháng nghị—các tín hiệu mà việc trích xuất ban đầu của chúng tôi có thể đã bỏ lỡ ngữ cảnh quan trọng. Khách hàng không đồng ý thông qua việc trả hàng và đánh giá tiêu cực, thường cho thấy thông tin sản phẩm không khớp với kỳ vọng. Các tín hiệu của con người sau suy luận này được đưa vào cùng một quy trình học tập, với tác nhân giám sát điều tra các mẫu và tạo ra các kiến thức giúp ngăn chặn các vấn đề tương tự trên các sản phẩm trong tương lai. Chúng tôi đã tìm thấy một điểm tối ưu: các thuộc tính có tỷ lệ bất đồng vừa phải của worker AI mang lại nhiều kiến thức nhất—đủ cao để làm nổi bật các mẫu có ý nghĩa, đủ thấp để chỉ ra sự mơ hồ có thể giải quyết được. Khi tỷ lệ bất đồng quá thấp, chúng thường phản ánh nhiễu hoặc các hạn chế cơ bản của mô hình hơn là các mẫu có thể học được—đối với những trường hợp đó, chúng tôi xem xét sử dụng các worker có khả năng hơn. Khi tỷ lệ bất đồng quá cao, nó báo hiệu rằng các mô hình worker hoặc lời nhắc chưa đủ trưởng thành, kích hoạt các cuộc gọi giám sát quá mức làm suy yếu lợi ích hiệu quả của kiến trúc. Các ngưỡng này sẽ khác nhau tùy theo tác vụ và miền; điều quan trọng là xác định điểm tối ưu của riêng bạn, nơi các bất đồng đại diện cho sự phức tạp thực sự đáng để điều tra, thay vì những khoảng trống cơ bản trong khả năng của worker hoặc nhiễu ngẫu nhiên.
Deep dive: Cách hoạt động
Cốt lõi của hệ thống của chúng tôi là nhiều mô hình worker nhẹ hoạt động song song—một số làm trình tạo trích xuất thuộc tính, những mô số khác làm trình đánh giá đánh giá các trích xuất đó. Các worker này có thể được triển khai theo cách không tác nhân với các đầu vào cố định, làm cho chúng thân thiện với lô và có thể mở rộng. Mẫu trình tạo-trình đánh giá tạo ra sự căng thẳng hiệu quả, tương tự về mặt khái niệm với sự căng thẳng hiệu quả trong mạng đối kháng tạo sinh (GANs), mặc dù cách tiếp cận của chúng tôi hoạt động tại thời điểm suy luận thông qua lời nhắc chứ không phải đào tạo. Chúng tôi rõ ràng nhắc nhở các trình đánh giá phải phê phán, hướng dẫn chúng kiểm tra kỹ các trích xuất để tìm sự mơ hồ, thiếu ngữ cảnh hoặc khả năng hiểu sai. Động lực đối kháng này làm nổi bật các bất đồng đại diện cho sự phức tạp thực sự thay vì để các trường hợp mơ hồ trôi qua mà không bị phát hiện. Khi trình tạo và trình đánh giá đồng ý, chúng tôi có độ tin cậy cao vào kết quả và xử lý nó với chi phí tính toán tối thiểu. Đường dẫn đồng thuận này xử lý hầu hết các thuộc tính sản phẩm. Khi chúng không đồng ý, chúng tôi đã xác định một trường hợp đáng để điều tra—kích hoạt tác nhân giám sát để giải quyết tranh chấp và trích xuất các kiến thức có thể tái sử dụng.
Kiến trúc của chúng tôi coi bất đồng là một tín hiệu học tập phổ quát. Tại thời điểm suy luận, các bất đồng giữa các worker nắm bắt sự mơ hồ. Sau suy luận, phản hồi của người bán nắm bắt sự không phù hợp với ý định và phản hồi của khách hàng nắm bắt sự không phù hợp với kỳ vọng. Ba kênh này cung cấp thông tin cho tác nhân giám sát, tác nhân này trích xuất các kiến thức giúp cải thiện độ chính xác trên toàn bộ hệ thống. Khi các worker không đồng ý, chúng tôi gọi một tác nhân giám sát—một mô hình có khả năng hơn để giải quyết tranh chấp và điều tra lý do tại sao nó xảy ra. Tác nhân giám sát xác định ngữ cảnh hoặc lý do mà các worker thiếu, và những hiểu biết này trở thành các kiến thức có thể tái sử dụng cho các trường hợp trong tương lai. Ví dụ, khi các worker không đồng ý về phân loại sử dụng cho một sản phẩm dựa trên các thuật ngữ kỹ thuật nhất định, tác nhân giám sát đã điều tra và làm rõ rằng chỉ những thuật ngữ đó là không đủ—ngữ cảnh hình ảnh và các chỉ số khác cần được xem xét cùng nhau. Tác nhân giám sát đã tạo ra một kiến thức về cách trọng số các tín hiệu khác nhau cho danh mục sản phẩm đó. Kiến thức này ngay lập tức cập nhật cơ sở tri thức của chúng tôi, và khi được đưa vào các lời nhắc của worker cho các sản phẩm tương tự, đã giúp ngăn chặn các bất đồng trong tương lai trên hàng nghìn mặt hàng. Mặc dù các worker về mặt lý thuyết có thể là cùng một mô hình với tác nhân giám sát, việc sử dụng các mô hình nhỏ hơn là rất quan trọng để đạt hiệu quả ở quy mô lớn. Lợi thế kiến trúc xuất hiện từ sự bất đối xứng này: các worker nhẹ xử lý các trường hợp thông thường thông qua sự đồng thuận, trong khi tác nhân giám sát có khả năng hơn chỉ được gọi khi các bất đồng làm nổi bật các cơ hội học tập có giá trị cao. Khi hệ thống tích lũy các kiến thức và tỷ lệ bất đồng giảm, các cuộc gọi giám sát tự nhiên giảm—lợi ích hiệu quả được tích hợp trực tiếp vào kiến trúc. Sự không đồng nhất giữa worker-giám sát này cũng cho phép điều tra phong phú hơn. Vì các tác nhân giám sát được gọi một cách chọn lọc, chúng có thể đủ khả năng để kéo thêm các tín hiệu—đánh giá của khách hàng, lý do trả hàng, lịch sử người bán—mà sẽ không thực tế nếu truy xuất cho mọi sản phẩm nhưng cung cấp ngữ cảnh quan trọng khi giải quyết các bất đồng phức tạp. Khi các tín hiệu này mang lại những hiểu biết tổng quát về cách khách hàng muốn thông tin sản phẩm được trình bày—những thuộc tính nào cần làm nổi bật, thuật ngữ nào gây được tiếng vang, cách định hình thông số kỹ thuật—các kiến thức thu được sẽ mang lại lợi ích cho các suy luận trong tương lai trên các sản phẩm tương tự mà không cần truy xuất lại các tín hiệu tốn nhiều tài nguyên đó. Theo thời gian, điều này tạo ra một vòng phản hồi: thông tin sản phẩm tốt hơn dẫn đến ít trả hàng và đánh giá tiêu cực hơn, điều này đến lượt nó phản ánh sự hài lòng của khách hàng được cải thiện.
Cơ sở tri thức: Làm cho các kiến thức có thể mở rộng
Tác nhân giám sát điều tra các bất đồng ở cấp độ sản phẩm riêng lẻ. Với hàng triệu mặt hàng cần xử lý, chúng tôi cần một cách có thể mở rộng để biến những hiểu biết cụ thể về sản phẩm này thành các kiến thức có thể tái sử dụng. Chiến lược tổng hợp của chúng tôi thích ứng với ngữ cảnh: các mẫu có khối lượng lớn được tổng hợp thành các kiến thức rộng hơn, trong khi các trường hợp độc đáo hoặc quan trọng được bảo toàn riêng lẻ. Chúng tôi sử dụng cấu trúc phân cấp trong đó trình quản lý bộ nhớ dựa trên mô hình ngôn ngữ lớn (LLM) điều hướng cây tri thức để đặt từng kiến thức. Bắt đầu từ gốc, nó đi qua các danh mục và danh mục con, quyết định ở mỗi cấp độ liệu có tiếp tục theo một đường dẫn hiện có, tạo một nhánh mới, hợp nhất với kiến thức hiện có hay thay thế thông tin lỗi thời. Tổ chức động này cho phép cơ sở tri thức phát triển với các mẫu mới nổi trong khi vẫn duy trì cấu trúc logic. Trong quá trình suy luận, các worker nhận được các kiến thức liên quan trong lời nhắc của chúng dựa trên danh mục sản phẩm, tự động kết hợp kiến thức miền từ các bất đồng trong quá khứ. Cơ sở tri thức cũng giới thiệu khả năng truy xuất nguồn gốc—khi một trích xuất có vẻ không chính xác, chúng tôi có thể xác định chính xác kiến thức nào đã ảnh hưởng đến nó. Điều này chuyển việc kiểm toán từ một nhiệm vụ không thể mở rộng sang một nhiệm vụ thực tế: thay vì xem xét một mẫu của hàng triệu đầu ra—nơi nỗ lực của con người tăng tỷ lệ thuận với quy mô—các nhóm có thể kiểm toán chính cơ sở tri thức, vốn vẫn tương đối cố định về kích thước bất kể khối lượng suy luận. Các chuyên gia miền có thể trực tiếp đóng góp bằng cách thêm hoặc tinh chỉnh các mục, không cần đào tạo lại. Một kiến thức được tạo ra tốt có thể ngay lập tức cải thiện độ chính xác trên hàng nghìn sản phẩm. Cơ sở tri thức bắc cầu giữa chuyên môn của con người và khả năng của AI, nơi các kiến thức tự động và hiểu biết của con người hoạt động cùng nhau.
Các bài học kinh nghiệm và thực tiễn tốt nhất
Khi kiến trúc tự học này hoạt động tốt nhất:
- Suy luận khối lượng lớn nơi sự đa dạng đầu vào thúc đẩy việc học tập tổng hợp
- Các ứng dụng quan trọng về chất lượng nơi sự đồng thuận cung cấp sự đảm bảo chất lượng tự nhiên
- Các miền đang phát triển với các mẫu và thuật ngữ mới liên tục xuất hiện
Nó ít phù hợp hơn cho các kịch bản khối lượng thấp (không đủ bất đồng để học) hoặc các trường hợp sử dụng với các quy tắc cố định, không thay đổi.
Các yếu tố thành công quan trọng:
- Xác định bất đồng: Với một cặp trình tạo-trình đánh giá, bất đồng xảy ra khi trình đánh giá gắn cờ trích xuất cần cải thiện. Với nhiều worker, hãy điều chỉnh ngưỡng tương ứng. Chìa khóa là duy trì sự căng thẳng hiệu quả giữa các worker. Nếu tỷ lệ bất đồng nằm ngoài phạm vi hiệu quả (quá thấp hoặc quá cao), hãy xem xét các worker có khả năng hơn hoặc các lời nhắc được tinh chỉnh.
- Theo dõi hiệu quả học tập: Tỷ lệ bất đồng phải giảm theo thời gian—đây là chỉ số sức khỏe chính của bạn. Nếu tỷ lệ vẫn ổn định, hãy kiểm tra việc truy xuất kiến thức, việc đưa lời nhắc hoặc tính phê phán của trình đánh giá.
- Tổ chức kiến thức: Cấu trúc các kiến thức theo phân cấp và giữ cho chúng có thể hành động. Hướng dẫn trừu tượng không giúp ích; các kiến thức cụ thể, rõ ràng trực tiếp cải thiện các suy luận trong tương lai.
Những cạm bẫy thường gặp
- Tập trung vào chi phí hơn là trí thông minh: Giảm chi phí là một sản phẩm phụ, không phải mục tiêu
- Trình đánh giá đóng dấu cao su: Các trình đánh giá chỉ đơn giản chấp thuận đầu ra của trình tạo sẽ không làm nổi bật các bất đồng có ý nghĩa—hãy nhắc nhở chúng chủ động thách thức và phê bình các trích xuất
- Trích xuất kiến thức kém: Các tác nhân giám sát phải xác định các mẫu có thể tổng quát hóa, không chỉ sửa các trường hợp riêng lẻ
- Sự suy thoái kiến thức: Nếu không có tổ chức, các kiến thức trở nên không thể tìm kiếm và không thể sử dụng
Insight chính: coi tỷ lệ bất đồng giảm là chỉ số định hướng của bạn—chúng cho thấy hệ thống thực sự đang học.
Chiến lược triển khai: Hai cách tiếp cận
- Học rồi triển khai (Learn-then-deploy): Bắt đầu với các lời nhắc cơ bản và để hệ thống học một cách tích cực trong môi trường tiền sản xuất. Các chuyên gia miền sau đó kiểm toán cơ sở tri thức—không phải các đầu ra riêng lẻ—để đảm bảo các mẫu đã học phù hợp với kết quả mong muốn. Khi được chấp thuận, triển khai với các kiến thức đã được xác thực. Điều này lý tưởng cho các trường hợp sử dụng mới mà bạn chưa biết điều gì là tốt—các bất đồng giúp khám phá các mẫu đúng, và việc kiểm toán cơ sở tri thức cho phép bạn định hình chúng trước khi sản xuất.
- Triển khai và học (Deploy-and-learn): Bắt đầu với các lời nhắc được tinh chỉnh và chất lượng ban đầu tốt, sau đó liên tục cải thiện thông qua việc học liên tục trong sản xuất. Điều này hoạt động tốt nhất cho các trường hợp sử dụng đã được hiểu rõ, nơi bạn có thể xác định chất lượng ngay từ đầu nhưng vẫn muốn nắm bắt các sắc thái cụ thể theo miền theo thời gian.
Cả hai cách tiếp cận đều sử dụng cùng một kiến trúc—lựa chọn phụ thuộc vào việc bạn đang khám phá lãnh thổ mới hay tối ưu hóa một lĩnh vực quen thuộc.
Kết luận
Điều bắt đầu như một thử nghiệm trong việc làm giàu danh mục đã tiết lộ một sự thật cơ bản: các hệ thống AI không nhất thiết phải bị đóng băng theo thời gian. Bằng cách chấp nhận các bất đồng như các tín hiệu học tập thay vì thất bại, chúng tôi đã xây dựng một kiến trúc tích lũy kiến thức miền thông qua việc sử dụng thực tế. Chúng tôi đã chứng kiến hệ thống phát triển từ hiểu biết chung đến chuyên môn cụ thể theo miền. Nó đã học các thuật ngữ chuyên ngành. Nó đã khám phá các quy tắc ngữ cảnh khác nhau giữa các danh mục. Nó đã thích nghi với các yêu cầu mà không mô hình được đào tạo trước nào sẽ gặp phải—tất cả mà không cần đào tạo lại, thông qua các kiến thức được lưu trữ trong cơ sở tri thức và được đưa trở lại các lời nhắc của worker. Đối với các nhóm vận hành các kiến trúc tương tự, Amazon Bedrock AgentCore cung cấp các khả năng được xây dựng có mục đích:
- AgentCore Runtime xử lý các quyết định đồng thuận nhanh chóng cho các trường hợp thông thường trong khi hỗ trợ lý luận mở rộng khi các tác nhân giám sát điều tra các bất đồng phức tạp
- AgentCore Observability cung cấp khả năng hiển thị về những kiến thức nào thúc đẩy tác động, giúp các nhóm tinh chỉnh việc truyền bá kiến thức và duy trì độ tin cậy ở quy mô lớn
Các hàm ý mở rộng ra ngoài việc quản lý danh mục. Các ứng dụng AI khối lượng lớn có thể hưởng lợi từ quy trình này—và khả năng của Amazon Bedrock trong việc truy cập các mô hình đa dạng làm cho kiến trúc này trở nên đơn giản để triển khai. Insight chính là: chúng tôi đã chuyển từ việc hỏi “chúng ta nên sử dụng mô hình nào?” sang “làm thế nào chúng ta có thể xây dựng các hệ thống học các mẫu cụ thể của chúng ta?” Cho dù bạn học rồi triển khai cho các trường hợp sử dụng mới hay triển khai và học cho các trường hợp đã có, việc triển khai rất đơn giản: bắt đầu với các worker phù hợp với tác vụ của bạn, chọn một tác nhân giám sát và để các bất đồng thúc đẩy việc học. Với kiến trúc phù hợp, mọi suy luận có thể trở thành một cơ hội để nắm bắt kiến thức miền. Đó không chỉ là mở rộng quy mô—đó là xây dựng kiến thức thể chế vào các hệ thống AI của bạn.
Lời cảm ơn
Công việc này sẽ không thể thực hiện được nếu không có sự đóng góp và hỗ trợ từ Ankur Datta (Nhà khoa học ứng dụng chính cấp cao – trưởng nhóm khoa học tại Everyday Essentials Stores), Zhu Cheng (Nhà khoa học ứng dụng), Xuan Tang (Kỹ sư phần mềm), Mohammad Ghasemi (Nhà khoa học ứng dụng). Chúng tôi chân thành cảm ơn những đóng góp trong thiết kế, triển khai, nhiều buổi động não hiệu quả và tất cả những ý tưởng và đề xuất sâu sắc.
Về tác giả

Tarik Arici là Nhà khoa học chính tại Amazon Selection and Catalog Systems (ASCS), nơi ông tiên phong thiết kế các hệ thống AI tạo sinh tự học để nâng cao chất lượng danh mục ở quy mô lớn. Công việc của ông tập trung vào việc xây dựng các hệ thống AI tự động tích lũy kiến thức miền thông qua việc sử dụng trong sản xuất—học hỏi từ các đánh giá và trả hàng của khách hàng, phản hồi của người bán và các bất đồng của mô hình để cải thiện chất lượng đồng thời giảm chi phí. Tarik có bằng Tiến sĩ Kỹ thuật Điện và Máy tính từ Viện Công nghệ Georgia.

Sameer Thombare là Giám đốc sản phẩm cấp cao tại Amazon với hơn một thập kỷ kinh nghiệm trong Quản lý sản phẩm, Quản lý danh mục/P&L trên nhiều ngành công nghiệp đa dạng, bao gồm kỹ thuật nặng, viễn thông, tài chính và thương mại điện tử. Sameer đam mê phát triển các hệ thống vòng lặp kín liên tục cải tiến và dẫn dắt các sáng kiến chiến lược trong Amazon Selection and Catalog Systems (ASCS) để xây dựng một hệ thống vòng lặp kín tự học tinh vi tổng hợp các tín hiệu từ khách hàng, người bán và hoạt động chuỗi cung ứng để tối ưu hóa kết quả. Sameer có bằng MBA từ Viện Quản lý Ấn Độ Bangalore và bằng kỹ sư từ Đại học Mumbai.

Amin Banitalebi nhận bằng Tiến sĩ về Truyền thông Kỹ thuật số tại Đại học British Columbia (UBC), Canada, vào năm 2014. Kể từ đó, ông đã đảm nhận nhiều vai trò khoa học ứng dụng trong các lĩnh vực thị giác máy tính, xử lý ngôn ngữ tự nhiên, hệ thống đề xuất, học máy cổ điển và AI tạo sinh. Amin đã đồng tác giả hơn 90 ấn phẩm và bằng sáng chế. Hiện ông là Giám đốc Khoa học ứng dụng tại Amazon Everyday Essentials.

Puneet Sahni là Kỹ sư chính cấp cao tại Amazon Selection and Catalog Systems (ASCS), nơi ông đã dành hơn 8 năm để cải thiện tính đầy đủ, nhất quán và chính xác của dữ liệu danh mục. Ông chuyên về mô hình hóa dữ liệu danh mục và ứng dụng của nó để nâng cao trải nghiệm của Đối tác bán hàng và khách hàng, đồng thời sử dụng làm giàu dựa trên ML/DL và LLM để thúc đẩy cải thiện chất lượng dữ liệu danh mục.

Erdinc Basci gia nhập Amazon vào năm 2015 và mang theo hơn 23 năm kinh nghiệm trong ngành công nghệ. Tại Amazon, ông đã dẫn dắt sự phát triển của kiến trúc hệ thống Danh mục—bao gồm các đường ống nhập liệu, xử lý ưu tiên và định hình lưu lượng—cũng như cải thiện kiến trúc dữ liệu danh mục như ưu đãi phân đoạn, thông số kỹ thuật sản phẩm cho các sản phẩm sản xuất theo yêu cầu và thử nghiệm dữ liệu danh mục. Erdinc đã ủng hộ văn hóa kỹ thuật hiệu suất thực tế trên các dịch vụ của Amazon, giúp tiết kiệm chi phí hàng năm hơn 1 tỷ USD và giảm độ trễ hơn 20% trên các dịch vụ Cửa hàng cốt lõi. Hiện ông đang tập trung vào việc cải thiện hiệu suất ứng dụng AI tạo sinh và hiệu quả GPU trên Amazon. Erdinc có bằng Cử nhân Khoa học Máy tính từ Đại học Bilkent, Thổ Nhĩ Kỳ, và bằng MBA từ Đại học Seattle, Hoa Kỳ.

Mey Meenakshisundaram là Giám đốc tại Amazon Selection and Catalog Systems, nơi ông dẫn dắt các giải pháp GenAI đổi mới để thiết lập danh mục toàn cầu của Amazon làm nguồn thông tin sản phẩm tốt nhất. Nhóm của ông tiên phong các kỹ thuật học máy tiên tiến, bao gồm hệ thống đa tác nhân và mô hình ngôn ngữ lớn, để tự động làm giàu các thuộc tính sản phẩm và cải thiện chất lượng danh mục ở quy mô lớn. Thông tin sản phẩm chất lượng cao trong danh mục rất quan trọng để làm hài lòng khách hàng trong việc tìm kiếm sản phẩm phù hợp, trao quyền cho các đối tác bán hàng niêm yết sản phẩm của họ một cách hiệu quả và cho phép các hoạt động của Amazon giảm thiểu nỗ lực thủ công.
