Tác giả: Kshitija Dound, Siddharth Gupta, Ishneet Kaur, Mohan Gandhi, Murali Balakrishnan Narayanaswamy, Shubham Mehta, Amit Sinha, và Vikramank Singh
Ngày phát hành: 22 JAN 2026
Chuyên mục: Advanced (300), Amazon SageMaker, Technical How-to
Việc tăng tốc phân tích dữ liệu và phát triển học máy (ML) đòi hỏi các công cụ AI hiểu rõ môi trường dữ liệu cụ thể của bạn, chứ không chỉ là tạo mã chung chung. Các trợ lý AI đa năng thiếu ngữ cảnh về môi trường dữ liệu cụ thể của bạn, tạo ra một khoảng cách giữa khả năng của AI và việc triển khai thực tế. Các chuyên gia dữ liệu thường bắt đầu bằng cách tìm kiếm các bảng liên quan, hiểu các mối quan hệ và viết mã khám phá trước khi trả lời câu hỏi kinh doanh đầu tiên của họ. Các nhóm dữ liệu vẫn dành thời gian để dịch các gợi ý do AI tạo ra thành mã hoạt động, tham chiếu chính xác các tài sản dữ liệu thực tế của họ, hiểu các mối quan hệ dữ liệu của tổ chức và tích hợp với các quy trình làm việc hiện có của họ.
AWS đã phát hành Amazon SageMaker Data Agent vào tháng 11 năm 2025, giải quyết những thách thức này bằng cách cung cấp một trợ lý AI được tích hợp sâu trong Amazon SageMaker (chỉ dành cho miền dựa trên IAM) với notebooks. SageMaker Data Agent có quyền truy cập trực tiếp vào ngữ cảnh dữ liệu AWS của bạn, bao gồm siêu dữ liệu AWS Glue Data Catalog, danh mục dữ liệu kinh doanh Amazon DataZone và trạng thái notebook hiện tại của bạn. Điều này giúp nó tạo ra mã nhận biết môi trường hoạt động trực tiếp với dữ liệu quy mô petabyte của bạn thông qua các tài nguyên tính toán phi máy chủ, giúp bạn phân tích các tập dữ liệu khổng lồ mà không cần quản lý cơ sở hạ tầng. Với khả năng nhận biết ngữ cảnh này, tác nhân tạo ra các kế hoạch phân tích có thể thực thi từ các lời nhắc ngôn ngữ tự nhiên, tham chiếu cụ thể các bảng, kiểu dữ liệu và nhu cầu phân tích thực tế của bạn, đồng thời duy trì lý luận trong suốt quá trình phân tích đa bước. Quan trọng là, tác nhân thực hiện các hoạt động này một cách an toàn trong môi trường AWS, sử dụng các kiểm soát quản trị tích hợp, các chính sách Amazon Identity and Access Management (IAM) và các tính năng bảo mật dữ liệu để đảm bảo dữ liệu của bạn không rời khỏi ranh giới tổ chức. Bằng cách hoạt động trong giao diện Amazon SageMaker Unified Studio của bạn, nó giảm thiểu việc chuyển đổi ngữ cảnh giữa các trợ lý AI và môi trường phát triển của bạn, cải thiện cách bạn tương tác với các quy trình phân tích và ML của mình.
Trong bài đăng này, chúng tôi trình bày các khả năng của SageMaker Data Agent, thảo luận về những thách thức mà nó giải quyết và khám phá một ví dụ thực tế phân tích dữ liệu chuyến đi taxi của Thành phố New York để xem tác nhân hoạt động như thế nào.
Thách thức trong quy trình làm việc dữ liệu
Các công cụ AI chung có thể tạo các đoạn mã, nhưng bạn vẫn phải đối mặt với ba thách thức chính khi áp dụng chúng vào môi trường dữ liệu cụ thể của mình:
- Ngắt kết nối ngữ cảnh – Các trợ lý AI tiêu chuẩn tạo mã chung chung tham chiếu các bảng giả định như
customersthay vì các bảng thực tế của bạn nhưcustomer_activity_prod, buộc phải sửa đổi rộng rãi để hoạt động với môi trường dữ liệu của bạn. - Môi trường dữ liệu phức tạp – Nhiều doanh nghiệp làm việc với các môi trường dữ liệu phức tạp chứa nhiều bảng và kho dữ liệu quy mô lớn, khiến việc định vị các tài sản dữ liệu liên quan để phân tích trở nên cực kỳ khó khăn. Bạn phải điều hướng các cấu trúc danh mục phức tạp, hiểu các mối quan hệ bảng và xác định tập hợp con dữ liệu nào phù hợp với nhu cầu phân tích cụ thể của bạn trước khi có thể bắt đầu phân tích thực tế.
- Rào cản ngôn ngữ và cú pháp – Bạn phải làm việc với nhiều ngôn ngữ lập trình và cú pháp truy vấn trong quá trình phân tích. Một số có thể giỏi SQL nhưng gặp khó khăn với Python, trong khi những người khác có thể là chuyên gia Python nhưng có kiến thức PySpark hạn chế.
Ngoài ra, bạn còn đối mặt với các thách thức về xác thực chất lượng dữ liệu, quản trị dữ liệu và tối ưu hóa hiệu suất. SageMaker Data Agent giải quyết những thách thức quy trình làm việc cơ bản này đồng thời thích ứng với các yêu cầu của bạn.
Tổng quan giải pháp
SageMaker Data Agent giải quyết những thách thức chính này thông qua kiến trúc nhận biết ngữ cảnh và tích hợp sâu với AWS. Trong phần này, chúng ta sẽ thảo luận về cách nó hoạt động.
Hiểu biết nhận biết ngữ cảnh
SageMaker Data Agent xây dựng sự hiểu biết chi tiết về môi trường dữ liệu cụ thể của bạn và tham chiếu các bảng thực tế của bạn thông qua hai quy trình song song. SageMaker Data Agent được nhúng trong môi trường dữ liệu AWS của bạn, cho phép nó hiểu những gì bạn đang yêu cầu, dữ liệu bạn có sẵn, cách nó được cấu trúc và cách nó liên quan đến các mục tiêu phân tích của bạn. Dưới đây là hai cách tác nhân đạt được sự hiểu biết ngữ cảnh này:
- Môi trường dữ liệu tích hợp – SageMaker Data Agent tồn tại trong cùng một môi trường tích hợp với dữ liệu của bạn, khai thác sức mạnh của cơ sở hạ tầng AWS của bạn. Nó bắt đầu bằng cách khám phá AWS Glue Data Catalog và danh mục dữ liệu kinh doanh Amazon DataZone, nơi tiết lộ siêu dữ liệu kinh doanh, bảng chú giải và các mối quan hệ, cho phép nó tham chiếu các bảng thực tế của bạn thay vì các phần giữ chỗ chung chung. Trí thông minh này mở rộng đến việc làm việc trực tiếp với toàn bộ tập dữ liệu của bạn nơi chúng tự nhiên cư trú, bảo toàn các chính sách bảo mật và kiểm soát truy cập hiện có của bạn mà không yêu cầu di chuyển dữ liệu. Tác nhân tích hợp với Amazon Simple Storage Service (Amazon S3), Amazon Athena và Amazon SageMaker AI để sử dụng các khả năng tương ứng của chúng cho lưu trữ dữ liệu, xử lý truy vấn và ML trong khi thích ứng với môi trường dữ liệu của bạn. Điều này cho phép bạn xử lý dữ liệu quy mô petabyte thông qua các tài nguyên tính toán phi máy chủ với tác nhân hoạt động như một giao diện thông minh cho môi trường dữ liệu hoàn chỉnh của bạn.
- Nhận biết ngữ cảnh Notebook – Đồng thời, tác nhân kiểm tra trạng thái notebook hiện tại của bạn, bao gồm các dataframe hiện có, thư viện đã nhập, kết quả ô trước đó và các tạo phẩm ML. Khả năng nhận biết ngữ cảnh này đảm bảo mã được tạo hoạt động với môi trường cụ thể của bạn mà không cần sửa đổi rộng rãi.
Tính linh hoạt về ngôn ngữ và cú pháp
SageMaker Data Agent giải quyết các rào cản về ngôn ngữ và cú pháp bằng cách chọn ngôn ngữ tối ưu cho từng tác vụ phân tích. Tác nhân có thể chuyển đổi giữa SQL để truy vấn dữ liệu hiệu quả và Python cùng PySpark cho các phép biến đổi phức tạp và các hoạt động ML mà không yêu cầu các chuyên gia phải dịch thủ công giữa các ngôn ngữ. Điều này tránh được các rào cản ngôn ngữ, vì tác nhân tự động chọn và tạo cú pháp mã phù hợp, dù là SQL, Python hay PySpark, dựa trên tác vụ phân tích hoặc ML cụ thể đang thực hiện.
SageMaker Data Agent cung cấp bốn khả năng chính hoạt động cùng nhau để giúp bạn kiểm soát các phân tích phức tạp:
- Khi xử lý các yêu cầu phức tạp, tác nhân tạo ra các kế hoạch phân tích có cấu trúc bằng cách chia chúng thành các bước logic với lý do rõ ràng cho từng hoạt động.
- Ở mỗi giai đoạn, bạn có các điểm xác thực trung gian nơi bạn có thể xem xét và phê duyệt từng bước trước khi chuyển sang bước tiếp theo.
- Trong suốt quá trình phân tích đa bước, tác nhân duy trì ngữ cảnh nhất quán, giữ lại sự hiểu biết về môi trường dữ liệu của bạn và các bước trước đó.
- Quan trọng nhất, bạn duy trì quyền kiểm soát “human-in-the-loop” với sự giám sát đầy đủ và khả năng sửa đổi bất kỳ mã nào được tạo ra để phù hợp với các yêu cầu cụ thể của bạn.
Chế độ tương tác
SageMaker Data Agent cung cấp hai chế độ tương tác được tối ưu hóa cho các tác vụ phân tích khác nhau: Bảng điều khiển tác nhân (Agent Panel) và hỗ trợ nội tuyến (in-line assistance).
Bảng điều khiển tác nhân hỗ trợ các tác vụ phân tích toàn diện bằng cách chia chúng thành các bước có cấu trúc, mỗi bước với mã được tạo dựa trên các kết quả trước đó. Khi bạn gửi một yêu cầu như “thực hiện phân đoạn khách hàng”, tác nhân sẽ xác định các bảng liên quan, hiểu các mối quan hệ của chúng và tạo một quy trình làm việc phân tích hoàn chỉnh với các điểm xem xét trung gian. Ảnh chụp màn hình sau đây minh họa ví dụ này.
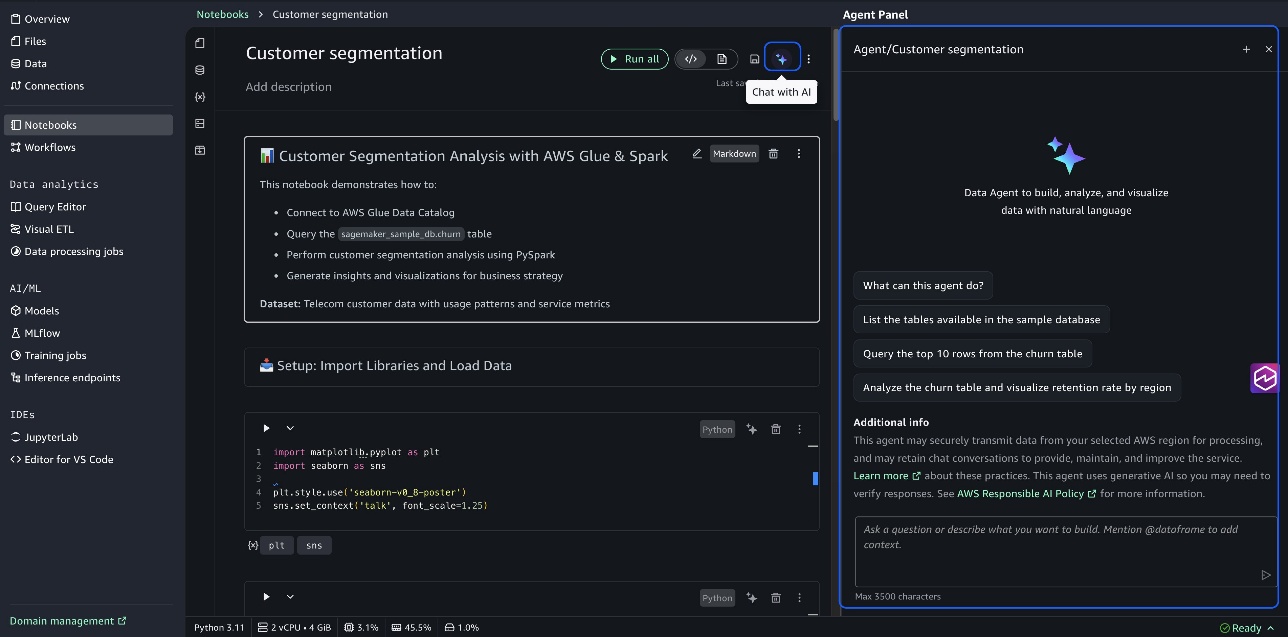
Chế độ hỗ trợ nội tuyến hỗ trợ sửa đổi ô trực tiếp, sửa lỗi bằng một cú nhấp chuột và các phím tắt (Alt+A cho Windows/Linux, Opt+A cho Mac) giúp duy trì luồng mã hóa của bạn. Bạn có thể nhanh chóng cải thiện mã hiện có hoặc sửa lỗi mà không cần rời khỏi ngữ cảnh notebook hiện tại, cải thiện năng suất trong quá trình phát triển lặp lại. Bạn có thể viết mã trực tiếp trong các ô notebook bằng cách sử dụng giao diện nhắc lệnh nội tuyến, như minh họa trong ảnh chụp màn hình sau. Sử dụng hỗ trợ nội tuyến cho các tác vụ tập trung như các truy vấn hoặc hình ảnh hóa cụ thể trực tiếp trong các ô.
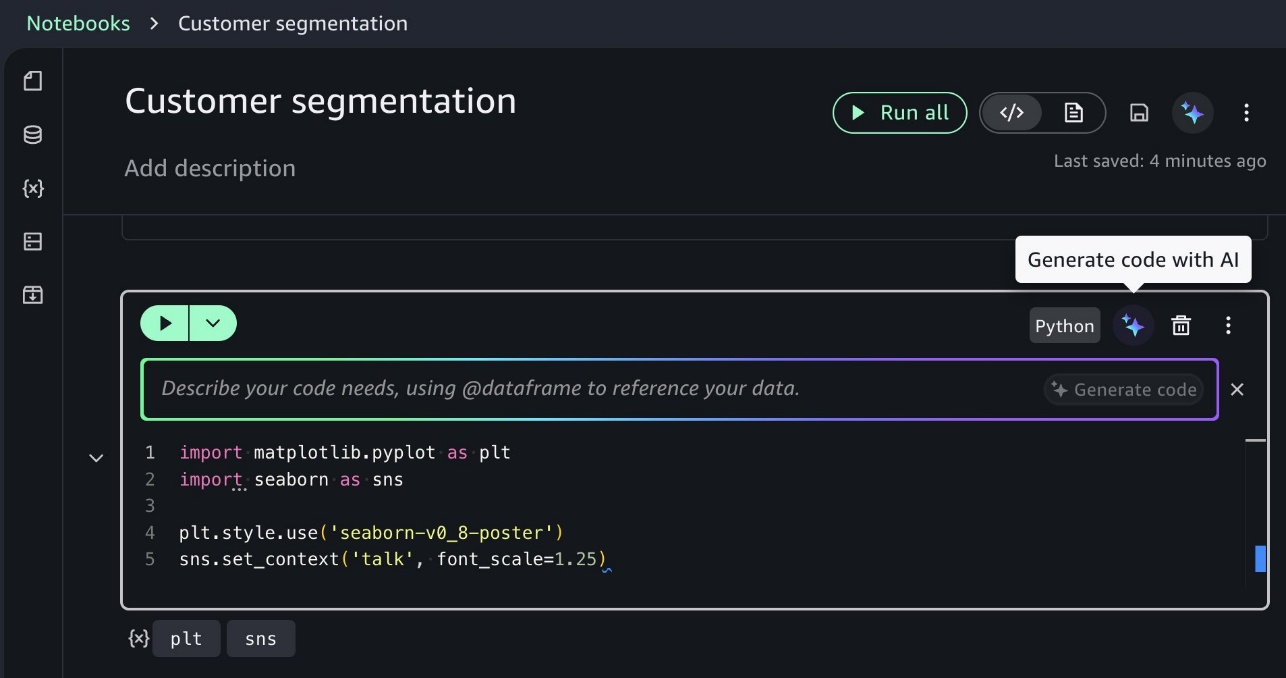
Thực thi và kiểm soát
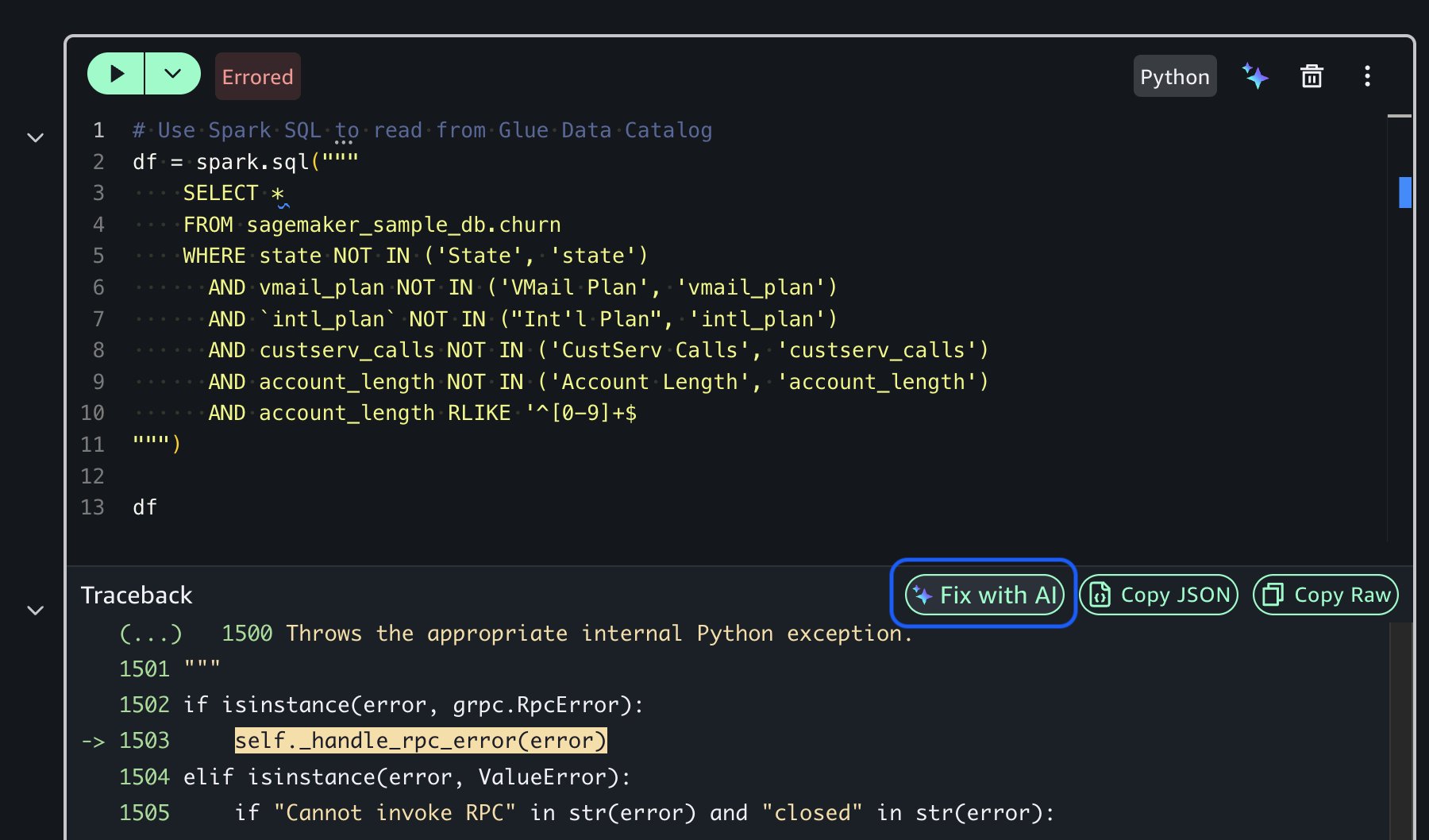
Trong suốt quá trình, bạn duy trì quyền kiểm soát thực thi. Bạn có thể xem xét các kế hoạch được tạo trước khi thực thi, thực hiện từng bước riêng lẻ với việc xem xét kết quả trung gian, sửa đổi mã khi cần thiết cho các yêu cầu cụ thể của bạn bằng cách cung cấp phản hồi và nhận chẩn đoán lỗi và sửa lỗi được hỗ trợ bởi AI bằng cách sử dụng tùy chọn Fix with AI khi phát sinh vấn đề. Cách tiếp cận “human-in-the-loop” này đảm bảo bạn duy trì sự giám sát trong khi hưởng lợi từ sự hỗ trợ của AI.
Các ảnh chụp màn hình sau đây minh họa cách tính năng Fix with AI hoạt động trong thực tế, cho thấy cách tác nhân chẩn đoán lỗi mã và cung cấp các giải pháp đã sửa lỗi kèm theo giải thích.
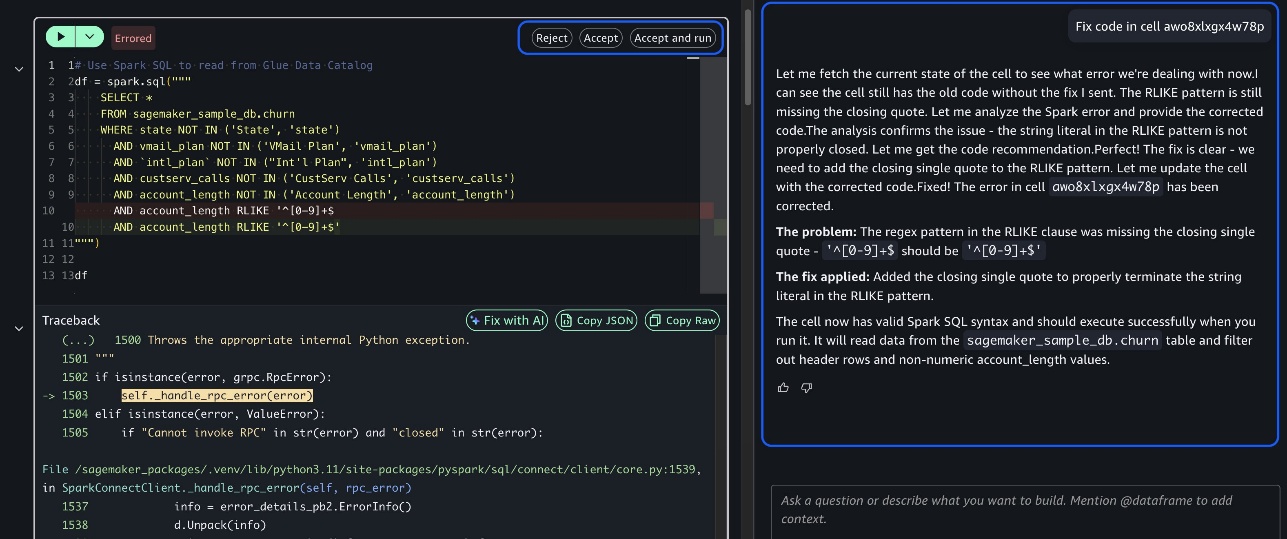
Bằng cách kết hợp khả năng hiểu biết nhận biết ngữ cảnh, lý luận và các chế độ tương tác trong môi trường AWS hiện có của bạn, SageMaker Data Agent cải thiện cách bạn làm việc. Nó loại bỏ ma sát truyền thống giữa hỗ trợ AI và môi trường dữ liệu thực tế của bạn, cung cấp quyền truy cập trực tiếp vào dữ liệu quy mô petabyte mà không có chi phí vận hành. Sự kết hợp này giúp bạn chuyển trọng tâm từ các tác vụ thiết lập lặp đi lặp lại sang phân tích và ra quyết định có giá trị cao, tăng tốc hiểu biết sâu sắc trong khi vẫn duy trì quyền kiểm soát quá trình phân tích.
Bắt đầu với SageMaker Data Agent
Bây giờ bạn đã hiểu cách SageMaker Data Agent hoạt động, hãy cùng xem các khả năng này trong thực tế. Bắt đầu với SageMaker Data Agent rất đơn giản. Để biết hướng dẫn thiết lập chi tiết, hãy tham khảo bài viết New one-click onboarding and notebooks with a built-in AI agent in Amazon SageMaker Unified Studio. Bài viết này cung cấp hướng dẫn từng bước về cách thiết lập môi trường của bạn và bắt đầu hành trình với SageMaker Data Agent.
Để tận dụng tối đa SageMaker Data Agent, hãy bắt đầu bằng cách đặt các câu hỏi rõ ràng, cụ thể về dữ liệu của bạn thay vì các yêu cầu chung chung. Cung cấp ngữ cảnh về mục tiêu phân tích của bạn để tác nhân có thể điều chỉnh phản hồi phù hợp với trường hợp sử dụng cụ thể của bạn. Luôn xem xét và xác thực mã được tạo trước khi thực thi, sử dụng các giải thích tích hợp của tác nhân để hiểu cách tiếp cận. Đối với các phân tích phức tạp, hãy tận dụng khả năng lý luận của tác nhân có thể chia nhỏ các quy trình đa bước và giải thích logic đằng sau mỗi khuyến nghị.
Phân tích chuyến đi taxi NYC
Trong phần này, chúng tôi trình bày cách SageMaker Data Agent giúp phân tích tập dữ liệu chuyến đi taxi NYC, một bộ sưu tập hơn 1,2 tỷ chuyến đi taxi (khoảng 63,7 GB) trên khắp Thành phố New York với thông tin về địa điểm đón/trả khách, dấu thời gian, khoảng cách chuyến đi, số tiền cước, loại thanh toán và số lượng hành khách.
Nếu bạn đang tìm cách thử một quy trình end-to-end đơn giản hơn trước khi đi sâu vào phân tích quy mô lớn này, SageMaker Unified Studio cung cấp một cơ sở dữ liệu mẫu với dữ liệu khách hàng rời bỏ (customer churn) được tải sẵn. Bạn có thể thực hiện các quy trình làm việc phân tích tương tự trên tập dữ liệu nhỏ hơn này để nhanh chóng làm quen với các khả năng của tác nhân trước khi làm việc với các tập dữ liệu lớn hơn, phức tạp hơn. Để khám phá tập dữ liệu này, hãy hoàn thành các bước sau:
- Trên bảng điều khiển SageMaker Unified Studio, chọn Data trong ngăn điều hướng.
- Trong trình khám phá dữ liệu, dưới Catalogs, chọn
AwsDataCatalog. - Chọn
sagemaker_sample_db. - Chọn bảng
churntừ danh sách các bảng.
Tập dữ liệu chuyến đi taxi NYC
Tập dữ liệu chuyến đi taxi NYC có sẵn công khai trong Amazon S3 tại s3://aws-data-analytics-workshops/shared_datasets/nyc_taxi_trips_parquet/.
Để tái tạo điều này, bạn có thể làm việc với tập dữ liệu này theo hai cách:
- Lập danh mục trước (được khuyến nghị cho phân tích lặp lại)
- Cung cấp đường dẫn S3 trực tiếp trong lời nhắc của bạn (nhanh nhất cho khám phá một lần)
Để minh họa này, chúng tôi đã sử dụng SageMaker Data Agent để lập danh mục tập dữ liệu trước khi phân tích.
Phương pháp phân tích của chúng tôi
Để minh họa này, chúng tôi đã yêu cầu SageMaker Data Agent thực hiện phân tích toàn diện trên dữ liệu chuyến đi taxi đã được lập danh mục để khám phá các thông tin chi tiết kinh doanh. Chúng tôi đã sử dụng lời nhắc sau:
Using Apache Spark, analyze the NYC taxi trips dataset to extract meaningful insights. Please provide:1/ Fare analysis across different NYC boroughs2/ Trip trends across boroughs and timeConclude with multi-panel dashboard and an executive summary highlighting the 3-5 most significant findings and their potential business implications.Bạn có thể thêm đường dẫn S3 (s3://aws-data-analytics-workshops/shared_datasets/nyc_taxi_trips_parquet/) vào lời nhắc trên nếu bạn chưa lập danh mục dữ liệu chuyến đi taxi NYC.
Video sau đây minh họa cách SageMaker Data Agent xử lý lời nhắc ngôn ngữ tự nhiên này và tạo ra một quy trình làm việc phân tích hoàn chỉnh. Tác nhân xây dựng một kế hoạch phân tích sáu bước, tạo mã có thể thực thi cho mỗi bước và dần dần xây dựng hướng tới những hiểu biết sâu sắc có thể hành động.
Video: Phân tích chuyến đi taxi NYC
Các kết quả hiển thị trong video minh họa này là cụ thể cho phiên phân tích này. Do tính chất tạo sinh của AI, kết quả của bạn có thể khác nhau khi chạy cùng một lời nhắc. Tác nhân đã thực thi từng bước một cách tuần tự, vì vậy chúng ta có thể xem xét các kết quả trung gian và cung cấp phản hồi. Sau khi tải và làm sạch các bản ghi chuyến đi taxi NYC, tác nhân đã phân tích các mẫu cước phí và xu hướng chuyến đi trên các quận và khoảng thời gian, sau đó tạo một bảng điều khiển đa bảng toàn diện để hình dung các thông tin chi tiết chính, như được hiển thị trong các ảnh chụp màn hình sau.
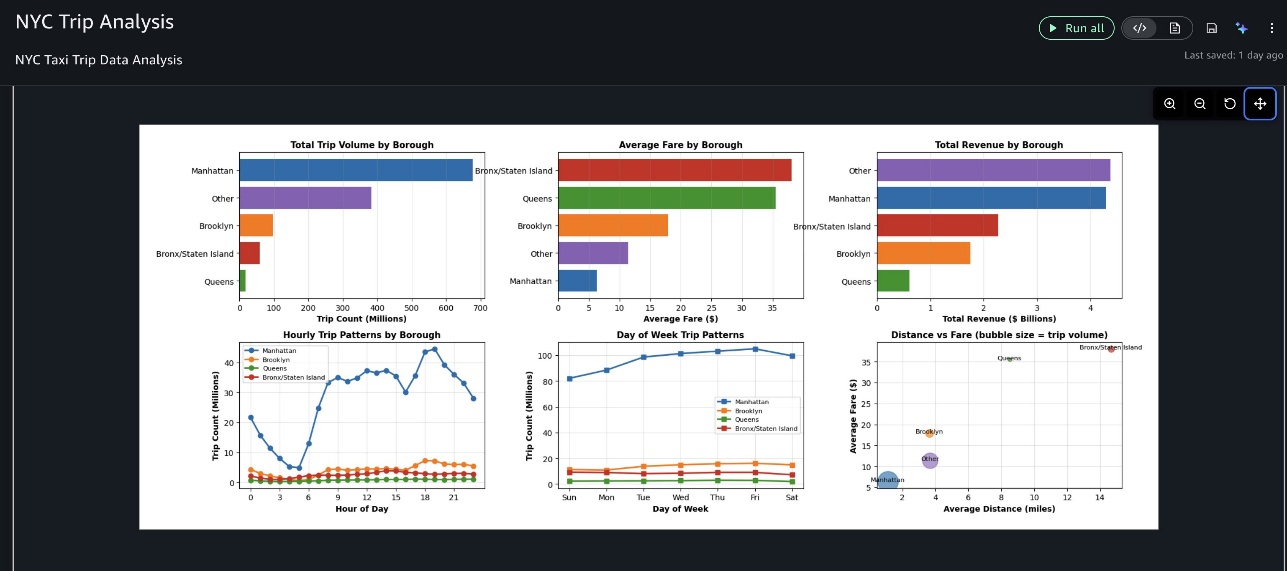
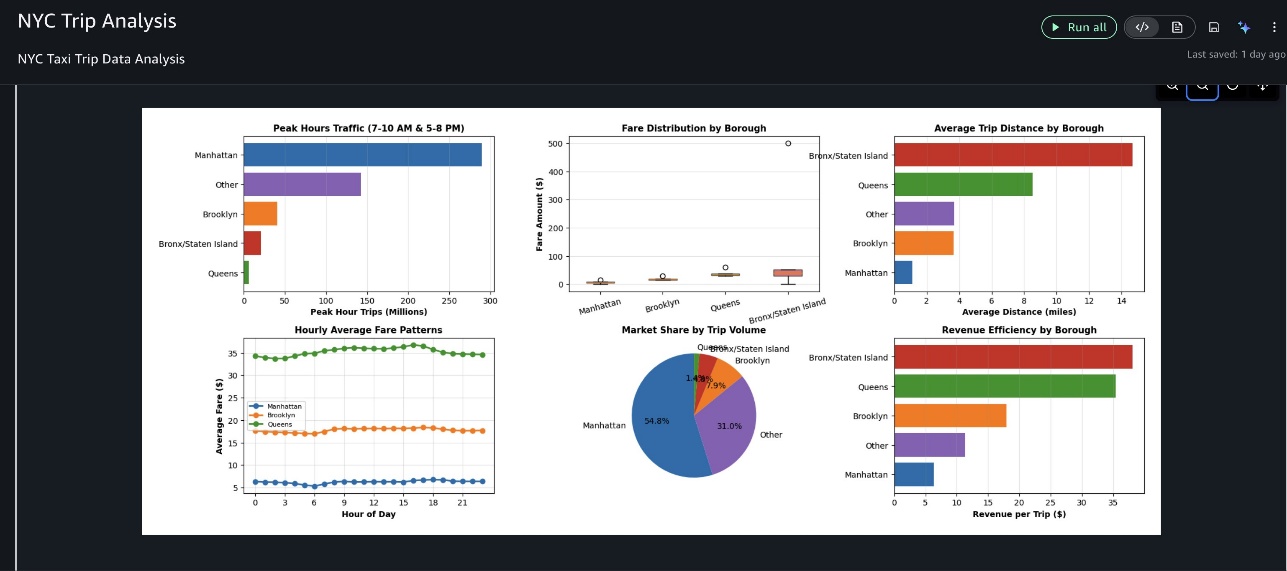
Cuối cùng, nó cung cấp các thông tin chi tiết kinh doanh có thể hành động, làm nổi bật những phát hiện quan trọng nhất và các khuyến nghị kinh doanh của chúng.
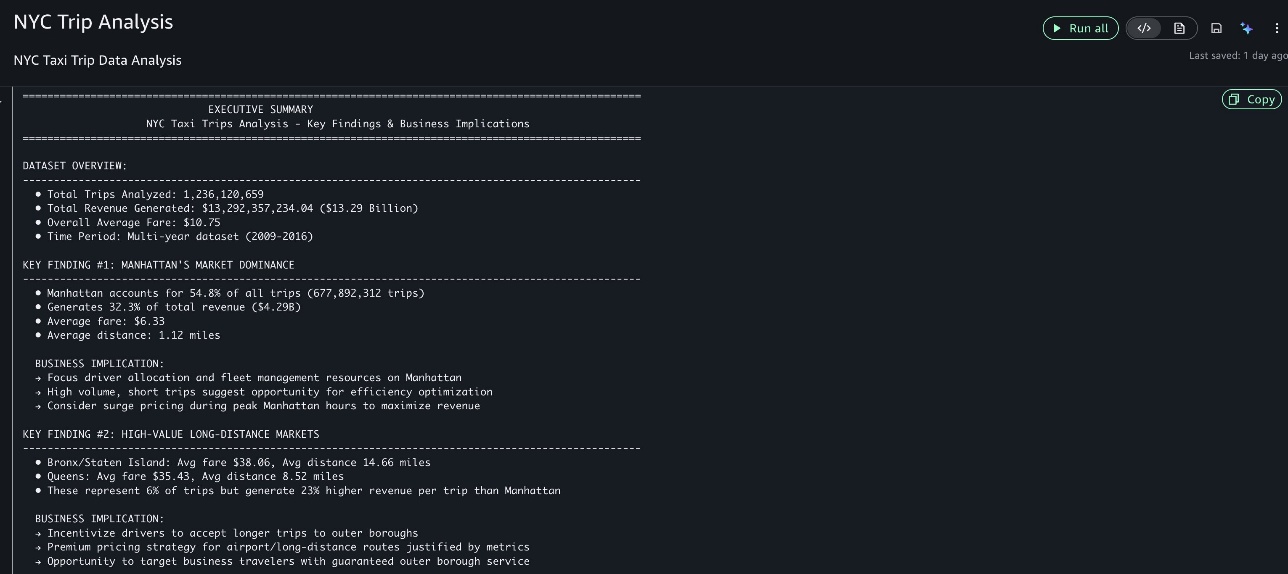
Ví dụ này minh họa cách SageMaker Data Agent giúp biến các tác vụ phân tích phức tạp thành những hiểu biết sâu sắc có thể hành động mà không yêu cầu mã hóa hoặc chuẩn bị dữ liệu rộng rãi. Khả năng của tác nhân trong việc hiểu cả cấu trúc dữ liệu và ngữ cảnh kinh doanh cho phép nó tạo ra các phân tích có ý nghĩa trực tiếp giải quyết các mục tiêu kinh doanh.
Bảo mật và quản trị
SageMaker Data Agent tuân thủ các cài đặt bảo mật AWS của bạn. Nó truy cập dữ liệu mà bạn đã cho phép rõ ràng thông qua các kiểm soát truy cập IAM của bạn hoặc sử dụng AWS Lake Formation, giúp duy trì các chính sách bảo mật của tổ chức bạn. Để sử dụng SageMaker Data Agent, vai trò dự án của bạn phải có quyền gọi các API Amazon DataZone cụ thể, bao gồm SendMessage, GenerateCode, StartConversation, GetConversation và ListConversations. Để biết thêm thông tin, hãy truy cập Actions, resources, and condition keys for Amazon DataZone.
Rào chắn bảo vệ
SageMaker Data Agent có các rào chắn bảo vệ tích hợp để ngăn tác nhân phản hồi các yêu cầu không mong muốn. Những yêu cầu này bao gồm nhưng không giới hạn ở các yêu cầu tác nhân tiết lộ lời nhắc hệ thống, công cụ nội bộ hoặc các triển khai kỹ thuật khác. Các rào chắn bảo vệ này cũng cấm tác nhân nói về các chủ đề không liên quan đến AWS và tạo ra đầu ra bằng bất kỳ ngôn ngữ nào ngoại trừ tiếng Anh.
Lưu trữ dữ liệu và quyền riêng tư
SageMaker Data Agent không lưu trữ mã bạn tự viết hoặc sửa đổi, ngữ cảnh hoặc siêu dữ liệu notebook, hoặc dữ liệu từ AWS Glue Data Catalog của bạn hoặc các nguồn khác. Tác nhân chỉ lưu trữ các lời nhắc ngôn ngữ tự nhiên, câu hỏi và mã/phản hồi được tạo của bạn trong AWS Region nơi miền SageMaker Unified Studio của bạn được tạo. AWS có thể sử dụng nội dung được lưu trữ (lời nhắc, câu hỏi và mã/phản hồi được tạo) để cải thiện dịch vụ, khắc phục sự cố hoặc để gỡ lỗi, nhưng duy trì ranh giới rõ ràng bằng cách không sử dụng mã tự viết, mã được sửa đổi thủ công, siêu dữ liệu notebook hoặc các nguồn dữ liệu thực tế của bạn để cải thiện dịch vụ. Để từ chối sử dụng dữ liệu cho việc cải thiện dịch vụ, bạn có thể cấu hình chính sách từ chối dịch vụ AI cho Amazon DataZone trong AWS Organizations, điều này sẽ xóa dữ liệu đã thu thập trước đó và ngăn chặn việc thu thập hoặc sử dụng trong tương lai. Để biết thêm thông tin, hãy tham khảo Data storage in the SageMaker Data Agent, Service improvement và AI services opt-out policies.
Kết luận
SageMaker Data Agent cải thiện cách các chuyên gia dữ liệu tăng tốc thu thập thông tin chi tiết. Bằng cách kết hợp khả năng hiểu biết nhận biết ngữ cảnh, tích hợp AWS và các chế độ tương tác linh hoạt, nó giảm bớt ma sát truyền thống giữa phát triển được hỗ trợ bởi AI và môi trường dữ liệu thực tế của bạn. Phân tích taxi NYC đã chứng minh điều này trong thực tế: những gì có thể yêu cầu khám phá dữ liệu thủ công, điều hướng danh mục và dịch mã thay vào đó chỉ mất vài phút thông qua các lời nhắc ngôn ngữ tự nhiên.
Giá trị thực sự vượt xa tốc độ. SageMaker Data Agent bảo toàn tư thế bảo mật của bạn, duy trì các kiểm soát quản trị và giữ dữ liệu của bạn trong môi trường AWS của bạn trong khi hỗ trợ phân tích quy mô petabyte mà không có chi phí vận hành. Quan trọng hơn, nó chuyển trọng tâm của nhóm bạn từ thiết lập lặp đi lặp lại sang phân tích kinh doanh và ra quyết định.
Bắt đầu rất đơn giản. Bắt đầu với các lời nhắc đơn giản đối với danh mục dữ liệu hiện có của bạn, sau đó dần dần giải quyết các thách thức phân tích phức tạp hơn. Đầu tư thời gian làm phong phú danh mục dữ liệu của bạn bằng siêu dữ liệu kinh doanh—khoản đầu tư này trực tiếp nhân lên hiệu quả của tác nhân bằng cách cung cấp ngữ cảnh phong phú hơn để tạo mã.
SageMaker Data Agent thích ứng với các nhu cầu phân tích cụ thể của bạn, chẳng hạn như phân tích hành vi khách hàng, làm việc với dữ liệu tài chính hoặc xây dựng các mô hình ML. Hãy truy cập ngay hôm nay thông qua miền SageMaker Unified Studio dựa trên IAM của bạn và khám phá cách hỗ trợ AI nhận biết ngữ cảnh có thể tăng tốc quá trình ra quyết định dựa trên dữ liệu của tổ chức bạn.
Về tác giả

Kshitija Dound
Kshitija là Kiến trúc sư Giải pháp Chuyên gia tại AWS có trụ sở tại Thành phố New York, tập trung vào dữ liệu và AI. Cô hợp tác với khách hàng để biến ý tưởng của họ thành các giải pháp đám mây, sử dụng các dịch vụ AWS Big Data và AI. Cô cũng tham gia các cơ hội diễn thuyết trước công chúng, chia sẻ chuyên môn của mình về công nghệ đám mây, xu hướng ngành và sự nghiệp trong lĩnh vực đám mây. Trong thời gian rảnh rỗi, Kshitija thích khám phá các bảo tàng, thưởng thức nghệ thuật và tận hưởng khung cảnh ngoài trời của NYC.

Siddharth Gupta
Siddharth đang dẫn đầu mảng AI tạo sinh trong các trải nghiệm hợp nhất của SageMaker. Trọng tâm của anh là thúc đẩy các trải nghiệm tác nhân, nơi các hệ thống AI hoạt động tự chủ thay mặt người dùng để hoàn thành các tác vụ phức tạp. Là cựu sinh viên của Đại học Illinois tại Urbana-Champaign, anh mang đến kinh nghiệm sâu rộng từ các vai trò của mình tại Yahoo, Glassdoor và Twitch.

Mohan Gandhi
Mohan là Kỹ sư Phần mềm Chính tại AWS. Anh đã làm việc tại AWS trong 10 năm qua và đã làm việc trên nhiều dịch vụ AWS khác nhau như Amazon EMR, Amazon EFA và Amazon RDS. Hiện tại, anh đang tập trung vào việc cải thiện trải nghiệm suy luận của Amazon SageMaker. Trong thời gian rảnh rỗi, anh thích đi bộ đường dài và chạy marathon.

Ishneet Kaur
Ishneet là Giám đốc Phát triển Phần mềm trong nhóm Amazon SageMaker Unified Studio. Cô dẫn dắt đội ngũ kỹ thuật thiết kế và xây dựng các khả năng AI tạo sinh trong SageMaker Unified Studio.

Shubham Mehta
Shubham là Giám đốc Sản phẩm Cấp cao tại AWS Analytics. Anh dẫn dắt việc phát triển tính năng AI tạo sinh trên các dịch vụ như AWS Glue, Amazon EMR và Amazon MWAA, sử dụng AI/ML để đơn giản hóa và nâng cao trải nghiệm của các chuyên gia dữ liệu xây dựng ứng dụng dữ liệu trên AWS.

Vikramank Singh
Vikramank là Nhà khoa học Ứng dụng Cấp cao trong tổ chức Agentic AI tại AWS, làm việc trên các sản phẩm bao gồm Amazon SageMaker Unified Studio, Amazon RDS và Amazon Redshift. Lĩnh vực nghiên cứu của anh nằm ở giao điểm của AI, hệ thống điều khiển và RL, đặc biệt là sử dụng chúng để xây dựng các hệ thống cho các ứng dụng thực tế có thể tự động nhận thức môi trường, mô hình hóa chúng và đưa ra các quyết định tối ưu ở quy mô lớn.

Murali Narayanaswamy
Murali là Nhà khoa học Học máy Chính trong tổ chức Agentic AI tại AWS, làm việc trên các sản phẩm bao gồm Amazon SageMaker Unified Studio, Amazon Redshift và Amazon RDS. Lĩnh vực nghiên cứu của anh nằm ở giao điểm của AI, tối ưu hóa, học tập và suy luận, đặc biệt là sử dụng chúng để hiểu, mô hình hóa và chống lại nhiễu và sự không chắc chắn trong các ứng dụng thực tế và học tăng cường trong thực tế và ở quy mô lớn.

Amit Sinha
Amit là Giám đốc Cấp cao dẫn dắt các bộ sản phẩm GenAI và ML của SageMaker Unified Studio. Anh có hơn một thập kỷ kinh nghiệm trong các sản phẩm AI/ML, quản lý cơ sở hạ tầng và các dịch vụ xử lý dữ liệu lớn của AWS. Là cựu sinh viên Đại học Columbia, trong thời gian rảnh rỗi Amit thích đi bộ đường dài và xem các bộ phim tài liệu về lịch sử Mỹ.
