Tác giả: Archie Cowan
Ngày phát hành: 26 JAN 2026
Chuyên mục: Amazon CloudWatch, Amazon Cognito, Amazon Data Firehose, Amazon DynamoDB, Artificial Intelligence, AWS AppSync, AWS Glue, Technical How-to
AWS AppSync Events có thể giúp bạn tạo các API Websocket an toàn và có khả năng mở rộng hơn. Ngoài việc phát sóng các sự kiện thời gian thực đến hàng triệu người đăng ký Websocket, nó còn hỗ trợ một yêu cầu trải nghiệm người dùng quan trọng của AI Gateway của bạn: truyền tải sự kiện với độ trễ thấp từ các mô hình AI tạo sinh đã chọn của bạn đến từng người dùng.
Trong bài viết này, chúng tôi thảo luận về cách sử dụng AppSync Events làm nền tảng cho một kiến trúc AI gateway phi máy chủ, có khả năng. Chúng tôi khám phá cách nó tích hợp với các dịch vụ AWS để bao quát toàn diện các khả năng được cung cấp trong kiến trúc AI gateway. Cuối cùng, chúng tôi sẽ giúp bạn bắt đầu hành trình của mình với mã mẫu mà bạn có thể khởi chạy trong tài khoản của mình và bắt đầu xây dựng.
Tổng quan về AI Gateway
AI Gateway là một mẫu kiến trúc middleware giúp tăng cường tính khả dụng, bảo mật và khả năng quan sát của các mô hình ngôn ngữ lớn (LLM). Nó hỗ trợ lợi ích của nhiều đối tượng khác nhau. Ví dụ, người dùng muốn độ trễ thấp và trải nghiệm thú vị. Các nhà phát triển muốn kiến trúc linh hoạt và có khả năng mở rộng. Nhân viên bảo mật cần quản trị để bảo vệ thông tin và tính khả dụng. Các kỹ sư hệ thống cần các giải pháp giám sát và quan sát giúp họ hỗ trợ trải nghiệm người dùng. Các nhà quản lý sản phẩm cần thông tin về hiệu suất sản phẩm của họ với người dùng. Các nhà quản lý ngân sách cần kiểm soát chi phí. Nhu cầu của những người khác nhau trong tổ chức của bạn là những cân nhắc quan trọng khi lưu trữ các ứng dụng AI tạo sinh.
Tổng quan giải pháp
Giải pháp chúng tôi chia sẻ trong bài viết này cung cấp các khả năng sau:
- Identity – Xác thực và cấp quyền cho người dùng từ thư mục người dùng tích hợp sẵn, từ thư mục doanh nghiệp của bạn và từ các nhà cung cấp danh tính người tiêu dùng như Amazon, Google và Facebook
- APIs – Cung cấp cho người dùng và ứng dụng quyền truy cập độ trễ thấp vào các ứng dụng AI tạo sinh của bạn
- Authorization – Xác định tài nguyên mà người dùng của bạn có quyền truy cập trong ứng dụng của bạn
- Rate limiting and metering – Giảm thiểu lưu lượng bot, chặn truy cập và quản lý mức tiêu thụ mô hình để quản lý chi phí
- Diverse model access – Cung cấp quyền truy cập vào các mô hình nền tảng (FM) hàng đầu, tác nhân và các biện pháp bảo vệ để giữ an toàn cho người dùng
- Logging – Quan sát, khắc phục sự cố và phân tích hành vi ứng dụng
- Analytics – Trích xuất giá trị từ nhật ký của bạn để xây dựng, khám phá và chia sẻ những hiểu biết có ý nghĩa
- Monitoring – Theo dõi các điểm dữ liệu chính giúp nhân viên phản ứng nhanh chóng với các sự kiện
- Caching – Giảm chi phí bằng cách phát hiện các truy vấn phổ biến đến các mô hình của bạn và trả về các phản hồi được xác định trước
Trong các phần sau, chúng tôi đi sâu vào kiến trúc cốt lõi và khám phá cách bạn có thể xây dựng các khả năng này vào giải pháp.
Identity và API
Sơ đồ sau minh họa kiến trúc sử dụng API AppSync Events để cung cấp giao diện giữa ứng dụng trợ lý AI và LLM thông qua Amazon Bedrock bằng cách sử dụng AWS Lambda.
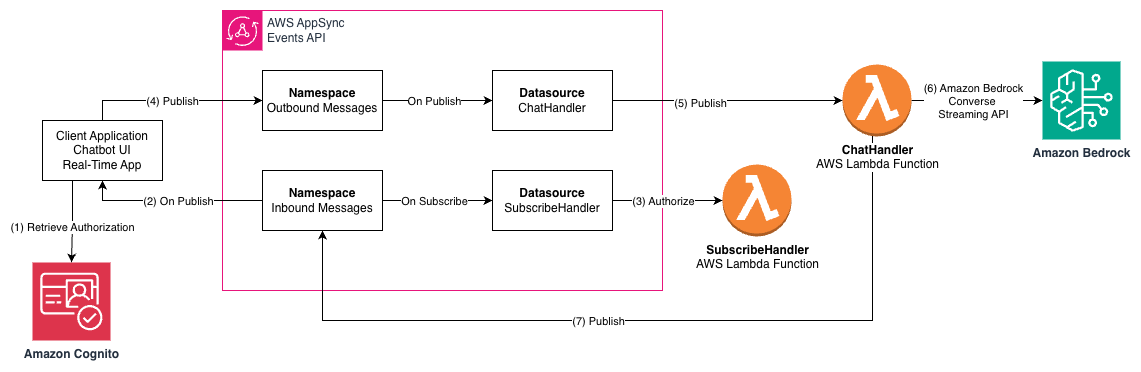
Quy trình làm việc bao gồm các bước sau:
- Ứng dụng khách truy xuất danh tính người dùng và quyền truy cập API bằng Amazon Cognito.
- Ứng dụng khách đăng ký kênh AppSync Events, từ đó nó sẽ nhận các sự kiện như phản hồi streaming từ các LLM trong Amazon Bedrock.
- Hàm Lambda
SubscribeHandlerđược gắn vào namespace Outbound Messages xác minh rằng người dùng này được ủy quyền truy cập kênh. - Ứng dụng khách xuất bản một tin nhắn lên kênh Inbound Message, chẳng hạn như một câu hỏi được đặt ra cho LLM.
- Hàm Lambda
ChatHandlernhận tin nhắn và xác minh người dùng được ủy quyền xuất bản tin nhắn trên kênh đó. - Hàm
ChatHandlergọi API Amazon Bedrock ConverseStream và chờ luồng phản hồi từ API Converse phát ra các sự kiện phản hồi. - Hàm
ChatHandlerchuyển tiếp các tin nhắn phản hồi từ API Converse đến kênh Outbound Message cho người dùng hiện tại, kênh này chuyển các sự kiện đến WebSocket mà ứng dụng khách đang chờ tin nhắn.
Các namespace và kênh AppSync Events là các khối xây dựng của kiến trúc truyền thông của bạn trong AI Gateway. Trong ví dụ, các namespace được sử dụng để gắn các hành vi khác nhau vào các tin nhắn đến và đi của chúng ta. Mỗi namespace có thể có các tích hợp xuất bản và đăng ký khác nhau cho mỗi namespace. Hơn nữa, mỗi namespace được chia thành các kênh. Thiết kế cấu trúc kênh của chúng tôi cung cấp cho mỗi người dùng một kênh đến và đi riêng tư, phục vụ như giao tiếp một-một với phía máy chủ:
Inbound-Messages / ${sub}Outbound-Messages / ${sub}
Thuộc tính chủ đề, hoặc sub, đến các hàm Lambda của chúng ta dưới dạng ngữ cảnh từ Amazon Cognito. Nó là một định danh người dùng duy nhất, không thể thay đổi trong mỗi nhóm người dùng. Điều này làm cho nó hữu ích cho các phân đoạn tên kênh của chúng ta và đặc biệt hữu ích cho việc ủy quyền.
Ủy quyền
Danh tính được thiết lập bằng Amazon Cognito, nhưng chúng ta vẫn cần triển khai ủy quyền. Giao tiếp một-một giữa người dùng và trợ lý AI trong ví dụ của chúng ta phải là riêng tư—chúng ta không muốn người dùng có kiến thức về thuộc tính sub của người dùng khác có thể đăng ký hoặc xuất bản lên kênh đến hoặc đi của người dùng khác.
Đây là lý do tại sao chúng ta sử dụng sub trong sơ đồ đặt tên cho các kênh của chúng ta. Điều này cho phép các hàm Lambda được gắn vào các namespace làm nguồn dữ liệu để xác minh rằng người dùng được ủy quyền xuất bản và đăng ký.
Mã mẫu sau là hàm Lambda SubscribeHandler của chúng ta:
def lambda_handler(event, context): """ Lambda function that checks if the first channel segment matches the user's sub. Returns None if it matches or an error message otherwise. """ # Extract segments and sub from the event segments = event.get("info", {}).get("channel", {}).get("segments") sub = event.get("identity", {}).get("sub", None) # Check if segments exist and the first segment matches the user's sub if not segments: logger.error("No segments found in event") return "No segments found in channel path" if sub != segments[1]: logger.warning( f"Unauhotirzed: Sub '{sub}' did not match path segment '{segments[1]}'" ) return "Unauthorized" logger.info(f"Sub '{sub}' matched path segment '{segments[1]}'") return NoneQuy trình làm việc của hàm bao gồm các bước sau:
- Tên kênh đến trong sự kiện.
- Trường chủ đề của người dùng,
sub, là một phần của ngữ cảnh. - Nếu tên kênh và danh tính người dùng không khớp, nó sẽ không ủy quyền đăng ký và trả về một thông báo lỗi.
- Trả về
Nonecho biết không có lỗi và đăng ký được ủy quyền.
Hàm Lambda ChatHandler sử dụng cùng logic để đảm bảo người dùng chỉ được ủy quyền xuất bản lên kênh đến của riêng họ. Kênh đến trong sự kiện và ngữ cảnh mang danh tính người dùng.
Mặc dù ví dụ của chúng ta đơn giản, nó minh họa cách bạn có thể triển khai các quy tắc ủy quyền phức tạp bằng cách sử dụng hàm Lambda để ủy quyền truy cập vào các kênh trong AppSync Events. Chúng ta đã đề cập đến kiểm soát truy cập vào các kênh đến và đi của một cá nhân. Nhiều mô hình kinh doanh xung quanh việc truy cập LLM liên quan đến việc kiểm soát số lượng token mà một cá nhân được phép sử dụng trong một khoảng thời gian nhất định. Chúng ta thảo luận về khả năng này trong phần sau.
Giới hạn tốc độ và đo lường
Việc hiểu và kiểm soát số lượng token được tiêu thụ bởi người dùng AI Gateway là quan trọng đối với nhiều khách hàng. Token đầu vào và đầu ra là cơ chế định giá chính cho các LLM dựa trên văn bản trong Amazon Bedrock. Trong ví dụ của chúng ta, chúng ta sử dụng API Amazon Bedrock Converse để truy cập LLM. API Converse cung cấp một giao diện nhất quán hoạt động với các mô hình hỗ trợ tin nhắn. Bạn có thể viết mã một lần và sử dụng nó với các mô hình khác nhau.
Một phần của giao diện nhất quán là sự kiện siêu dữ liệu luồng. Sự kiện này được phát ra ở cuối mỗi luồng và cung cấp số lượng token được tiêu thụ bởi luồng. Sau đây là một ví dụ về cấu trúc JSON:
{ "metadata": { "usage": { "inputTokens": 1062, "outputTokens": 512, "totalTokens": 1574 }, "metrics": { "latencyMs": 4133 } }}Chúng ta có token đầu vào, token đầu ra, tổng số token và một chỉ số độ trễ. Để tạo một điều khiển với dữ liệu này, trước tiên chúng ta xem xét các loại giới hạn mà chúng ta muốn triển khai. Một cách tiếp cận là giới hạn token hàng tháng được đặt lại mỗi tháng—một cửa sổ tĩnh. Một cách khác là giới hạn hàng ngày dựa trên cửa sổ trượt theo khoảng thời gian 10 phút. Khi người dùng vượt quá giới hạn hàng tháng của họ, họ phải đợi đến tháng tiếp theo. Sau khi người dùng vượt quá giới hạn cửa sổ trượt hàng ngày của họ, họ phải đợi 10 phút để có thêm token.
Chúng ta cần một cách để giữ các bộ đếm nguyên tử để theo dõi mức tiêu thụ token, với quyền truy cập thời gian thực nhanh chóng vào các bộ đếm với sub của người dùng và để xóa các bộ đếm cũ khi chúng trở nên không liên quan.
Amazon DynamoDB là một cơ sở dữ liệu NoSQL phi máy chủ, được quản lý hoàn toàn, phân tán với hiệu suất mili giây một chữ số ở nhiều quy mô. Với DynamoDB, chúng ta có thể giữ các bộ đếm nguyên tử, cung cấp quyền truy cập vào các bộ đếm được khóa bằng sub và loại bỏ dữ liệu cũ bằng tính năng time to live của nó. Sơ đồ sau cho thấy một tập hợp con của kiến trúc của chúng ta từ trước đó trong bài viết này hiện bao gồm một bảng DynamoDB để theo dõi mức sử dụng token.
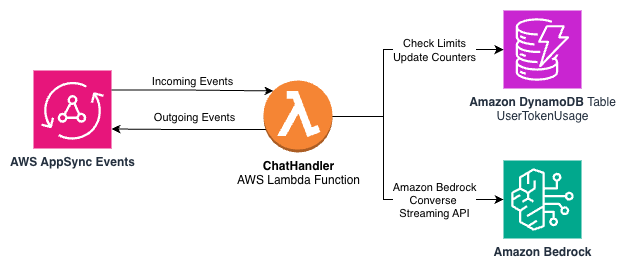
Chúng ta có thể sử dụng một bảng DynamoDB duy nhất với các khóa phân vùng và sắp xếp sau:
- Khóa phân vùng –
user_id(String), định danh duy nhất cho người dùng - Khóa sắp xếp –
period_id(String), một khóa tổng hợp xác định khoảng thời gian
user_id sẽ nhận thuộc tính sub từ JWT được cung cấp bởi Amazon Cognito. period_id sẽ có các chuỗi sắp xếp theo thứ tự từ điển cho biết khoảng thời gian mà bộ đếm dành cho cũng như khung thời gian. Sau đây là một số ví dụ về khóa sắp xếp:
10min:2025-08-05:16:4010min:2025-08-05:16:50monthly:2025-0810min hoặc monthly cho biết loại bộ đếm. Dấu thời gian được đặt thành cửa sổ 10 phút cuối cùng (ví dụ: (minute // 10) * 10).
Với mỗi bản ghi, chúng ta giữ các thuộc tính sau:
input_tokens– Bộ đếm cho token đầu vào được sử dụng trong cửa sổ 10 phút nàyoutput_tokens– Bộ đếm cho token đầu ra được sử dụng trong cửa sổ 10 phút nàytimestamp– Dấu thời gian Unix khi bản ghi được tạo hoặc cập nhật lần cuốittl– Giá trị thời gian tồn tại (dấu thời gian Unix), được đặt thành 24 giờ kể từ khi tạo
Hai cột token được tăng lên bằng thao tác ADD nguyên tử của DynamoDB với mỗi sự kiện siêu dữ liệu từ API Amazon Bedrock Converse. Các cột ttl và timestamp được cập nhật để cho biết khi nào bản ghi tự động bị xóa khỏi bảng.
Khi người dùng gửi tin nhắn, chúng ta kiểm tra xem họ có vượt quá giới hạn hàng ngày hoặc hàng tháng của họ hay không.
Để tính toán mức sử dụng hàng ngày, mô-đun meter.py hoàn thành các bước sau:
- Tính toán các khóa bắt đầu và kết thúc cho cửa sổ 24 giờ.
- Truy vấn các bản ghi với khóa phân vùng
user_idvà khóa sắp xếp giữa các khóa bắt đầu và kết thúc. - Tổng hợp các giá trị
input_tokensvàoutput_tokenstừ các bản ghi khớp. - So sánh tổng với giới hạn hàng ngày.
Xem mã ví dụ sau:
KeyConditionExpression: "user_id = :uid AND period_id BETWEEN :start AND :end"ExpressionAttributeValues: { ":uid": {"S": "user123"}, ":start": {"S": "10min:2025-08-04:15:30"}, ":end": {"S": "10min:2025-08-05:15:30"}}Truy vấn phạm vi này tận dụng các khóa được sắp xếp tự nhiên để truy xuất hiệu quả chỉ các bản ghi từ 24 giờ qua, mà không cần lọc trong mã ứng dụng. Việc tính toán mức sử dụng hàng tháng trên cửa sổ tĩnh đơn giản hơn nhiều. Để kiểm tra mức sử dụng hàng tháng, hệ thống hoàn thành các bước sau:
- Lấy bản ghi cụ thể với khóa phân vùng
user_idvà khóa sắp xếpmonthly:YYYY-MMcho tháng hiện tại. - So sánh các giá trị
input_tokensvàoutput_tokensvới giới hạn hàng tháng.
Xem mã sau:
Key: { "user_id": {"S": "user123"}, "period_id": {"S": "monthly:2025-08"}}Với một mô-đun Python bổ sung và DynamoDB, chúng ta có một giải pháp đo lường và giới hạn tốc độ hoạt động cho cả cửa sổ tĩnh và cửa sổ trượt.
Truy cập mô hình đa dạng
Mã mẫu của chúng tôi sử dụng API Amazon Bedrock Converse. Không phải mọi mô hình đều được bao gồm trong mã mẫu, nhưng nhiều mô hình được bao gồm để bạn nhanh chóng khám phá các khả năng. Sự đổi mới trong lĩnh vực này không dừng lại ở các mô hình trên AWS. Có nhiều cách để phát triển các giải pháp AI tạo sinh ở mọi cấp độ trừu tượng. Bạn có thể xây dựng dựa trên lớp phù hợp nhất với trường hợp sử dụng của mình.
Swami Sivasubramanian gần đây đã viết về cách AWS đang cho phép khách hàng cung cấp các tác nhân AI sẵn sàng sản xuất ở quy mô lớn. Ông thảo luận về Strands Agents, một SDK tác nhân AI mã nguồn mở, cũng như Amazon Bedrock AgentCore, một bộ dịch vụ cấp doanh nghiệp toàn diện giúp các nhà phát triển nhanh chóng và an toàn hơn triển khai và vận hành các tác nhân AI ở quy mô lớn bằng cách sử dụng một framework và mô hình, được lưu trữ trên Amazon Bedrock hoặc ở nơi khác.
Để tìm hiểu thêm về kiến trúc cho các tác nhân AI, hãy tham khảo Strands Agents SDK: Tìm hiểu sâu về kỹ thuật kiến trúc tác nhân và khả năng quan sát. Bài viết thảo luận về Strands Agents SDK và các tính năng cốt lõi của nó, cách nó tích hợp với môi trường AWS để triển khai an toàn, có khả năng mở rộng hơn và cách nó cung cấp khả năng quan sát phong phú để sử dụng trong sản xuất. Nó cũng cung cấp các trường hợp sử dụng thực tế và một ví dụ từng bước.
Ghi nhật ký
Nhiều bên liên quan đến AI Gateway của chúng ta quan tâm đến nhật ký. Các nhà phát triển muốn hiểu cách ứng dụng của họ hoạt động. Các kỹ sư hệ thống cần hiểu các vấn đề vận hành như theo dõi tính khả dụng và lập kế hoạch dung lượng. Chủ doanh nghiệp muốn phân tích và xu hướng để họ có thể đưa ra quyết định tốt hơn.
Với Amazon CloudWatch Logs, bạn có thể tập trung nhật ký từ các hệ thống, ứng dụng và dịch vụ AWS khác nhau mà bạn sử dụng vào một dịch vụ duy nhất, có khả năng mở rộng cao. Sau đó, bạn có thể xem chúng một cách liền mạch, tìm kiếm các mã lỗi hoặc mẫu cụ thể, lọc chúng dựa trên các trường cụ thể hoặc lưu trữ chúng một cách an toàn để phân tích trong tương lai. CloudWatch Logs giúp bạn có thể xem nhật ký của mình, bất kể nguồn gốc của chúng, dưới dạng một luồng sự kiện duy nhất và nhất quán được sắp xếp theo thời gian.
Trong kiến trúc AI Gateway mẫu, CloudWatch Logs được tích hợp ở nhiều cấp độ để cung cấp khả năng hiển thị toàn diện. Sơ đồ kiến trúc sau mô tả các điểm tích hợp giữa AppSync Events, Lambda và CloudWatch Logs trong ứng dụng mẫu.
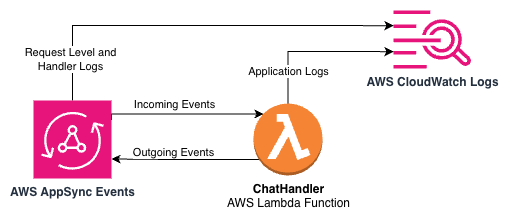
Ghi nhật ký API AppSync Events
API AppSync Events của chúng tôi được cấu hình với ghi nhật ký cấp ERROR để nắm bắt các vấn đề cấp API. Cấu hình này giúp xác định các vấn đề với yêu cầu API, lỗi xác thực và các vấn đề cấp API quan trọng khác. Cấu hình ghi nhật ký được áp dụng trong quá trình triển khai cơ sở hạ tầng:
this.api = new appsync.EventApi(this, "Api", { // ... other configuration ... logConfig: { excludeVerboseContent: true, fieldLogLevel: appsync.AppSyncFieldLogLevel.ERROR, retention: logs.RetentionDays.ONE_WEEK, },});Điều này cung cấp khả năng hiển thị vào các hoạt động API.
Ghi nhật ký có cấu trúc của hàm Lambda
Các hàm Lambda sử dụng AWS Lambda Powertools để ghi nhật ký có cấu trúc. Hàm Lambda ChatHandler triển khai một lớp MessageTracker cung cấp ngữ cảnh cho mỗi cuộc trò chuyện:
logger = Logger(service="eventhandlers")class MessageTracker: """ Tracks message state during processing to provide enhanced logging. Handles event type detection and processing internally. """ def __init__(self, user_id, conversation_id, user_message, model_id): self.user_id = user_id self.conversation_id = conversation_id self.user_message = user_message self.assistant_response = "" self.input_tokens = 0 self.output_tokens = 0 self.model_id = model_id # ...Thông tin chính được ghi nhật ký bao gồm:
- Định danh người dùng
- Định danh cuộc trò chuyện để theo dõi yêu cầu
- Định danh mô hình để theo dõi các mô hình AI nào đang được sử dụng
- Các chỉ số tiêu thụ token (số lượng đầu vào và đầu ra)
- Xem trước tin nhắn
- Dấu thời gian chi tiết để phân tích chuỗi thời gian
Mỗi hàm Lambda đặt một ID tương quan để theo dõi yêu cầu, giúp dễ dàng theo dõi một yêu cầu duy nhất thông qua hệ thống:
# Set correlation ID for request tracinglogger.set_correlation_id(context.aws_request_id)Thông tin chi tiết về hoạt động
CloudWatch Logs Insights cho phép các truy vấn giống SQL trên dữ liệu nhật ký, giúp bạn thực hiện các hành động sau:
- Theo dõi các mẫu sử dụng token theo mô hình hoặc người dùng
- Giám sát thời gian phản hồi và xác định các nút thắt cổ chai về hiệu suất
- Phát hiện các mẫu lỗi và khắc phục sự cố
- Tạo các chỉ số và cảnh báo tùy chỉnh dựa trên dữ liệu nhật ký
Bằng cách triển khai ghi nhật ký toàn diện trong toàn bộ kiến trúc AI Gateway mẫu, chúng tôi cung cấp khả năng hiển thị cần thiết để khắc phục sự cố hiệu quả, tối ưu hóa hiệu suất và giám sát hoạt động. Cơ sở hạ tầng ghi nhật ký này đóng vai trò là nền tảng cho cả giám sát hoạt động và các khả năng phân tích mà chúng tôi thảo luận trong phần sau.
Phân tích
CloudWatch Logs cung cấp khả năng hiển thị hoạt động, nhưng để trích xuất thông tin kinh doanh từ nhật ký, AWS cung cấp nhiều dịch vụ phân tích. Với kiến trúc AI Gateway mẫu của chúng tôi, bạn có thể sử dụng các dịch vụ đó để chuyển đổi dữ liệu từ AI Gateway của mình mà không yêu cầu cơ sở hạ tầng chuyên dụng hoặc các đường ống dữ liệu phức tạp.
Sơ đồ kiến trúc sau cho thấy luồng dữ liệu giữa hàm Lambda, Amazon Data Firehose, Amazon Simple Storage Service (Amazon S3), AWS Glue Data Catalog và Amazon Athena.
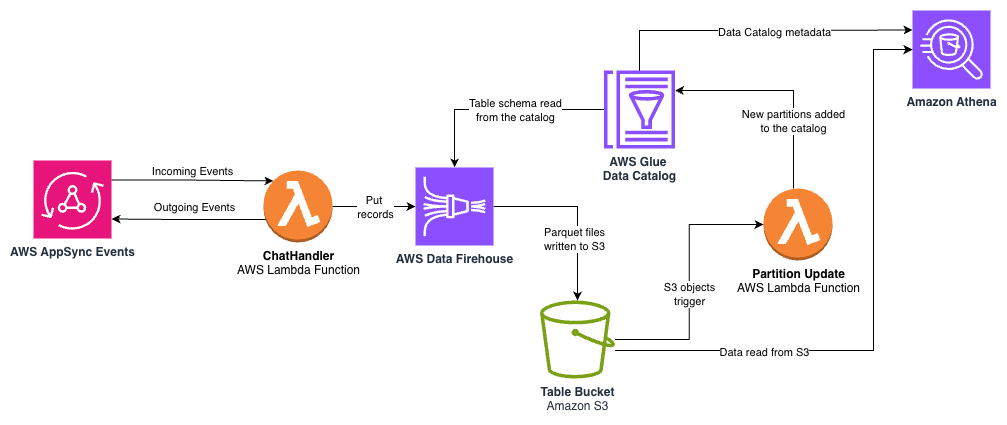
Các thành phần chính bao gồm:
- Data Firehose – Hàm Lambda
ChatHandlertruyền dữ liệu nhật ký có cấu trúc đến một luồng phân phối Firehose ở cuối mỗi phản hồi người dùng đã hoàn thành. Data Firehose cung cấp một dịch vụ được quản lý hoàn toàn tự động mở rộng theo thông lượng dữ liệu của bạn, giảm bớt nhu cầu cung cấp hoặc quản lý cơ sở hạ tầng. Mã sau minh họa cách gọi API tích hợp hàm LambdaChatHandlervới luồng phân phối:
# From messages.pyfirehose_stream = os.environ.get("FIREHOSE_DELIVERY_STREAM")if firehose_stream: try: firehose.put_record( DeliveryStreamName=firehose_stream, Record={"Data": json.dumps(log_data) + "\n"}, ) logger.debug(f"Successfully sent data to Firehose stream: {firehose_stream}") except Exception as e: logger.error(f"Failed to send data to Firehose: {str(e)}")- Amazon S3 với định dạng Parquet – Firehose tự động chuyển đổi dữ liệu nhật ký JSON sang định dạng Parquet dạng cột trước khi lưu trữ nó trong Amazon S3. Parquet cải thiện hiệu suất truy vấn và giảm chi phí lưu trữ so với nhật ký JSON thô. Dữ liệu được phân vùng theo năm, tháng và ngày, cho phép truy vấn hiệu quả các phạm vi thời gian cụ thể trong khi giảm thiểu lượng dữ liệu được quét trong quá trình truy vấn.
- AWS Glue Data Catalog – Một cơ sở dữ liệu và bảng AWS Glue được tạo trong ứng dụng AWS Cloud Development Kit (AWS CDK) để định nghĩa lược đồ cho dữ liệu phân tích của chúng ta, bao gồm
user_id,conversation_id,model_id, số lượng token và dấu thời gian. Các phân vùng bảng được thêm vào khi các đối tượng S3 mới được Data Firehose lưu trữ. - Athena để phân tích dựa trên SQL – Với bảng trong Data Catalog, các nhà phân tích kinh doanh có thể sử dụng SQL quen thuộc thông qua Athena để trích xuất thông tin chi tiết. Athena là phi máy chủ và được định giá theo truy vấn dựa trên lượng dữ liệu được quét, làm cho nó trở thành một giải pháp hiệu quả về chi phí cho phân tích một lần mà không yêu cầu cơ sở hạ tầng cơ sở dữ liệu. Sau đây là một truy vấn ví dụ:
-- Example: Token usage by modelSELECT model_id, SUM(input_tokens) as total_input_tokens, SUM(output_tokens) as total_output_tokens, COUNT(*) as conversation_countFROM firehose_database.firehose_tableWHERE year='2025' AND month='08'GROUP BY model_idORDER BY total_output_tokens DESC;Đường ống phân tích phi máy chủ này chuyển đổi các sự kiện chảy qua AppSync Events thành các bảng có cấu trúc, có thể truy vấn được với chi phí vận hành tối thiểu. Mô hình định giá trả theo mức sử dụng của các dịch vụ này tạo điều kiện thuận lợi cho hiệu quả chi phí, và bản chất được quản lý của chúng giảm bớt nhu cầu cung cấp và bảo trì cơ sở hạ tầng. Hơn nữa, với dữ liệu của bạn được lập danh mục trong AWS Glue, bạn có thể sử dụng toàn bộ bộ dịch vụ phân tích và học máy trên AWS như Amazon QuickSight và Amazon SageMaker Unified Studio với dữ liệu của bạn.
Giám sát
AppSync Events và các hàm Lambda gửi các chỉ số đến CloudWatch để bạn có thể giám sát hiệu suất, khắc phục sự cố và tối ưu hóa các hoạt động API AWS AppSync của mình một cách hiệu quả. Đối với AI Gateway, bạn có thể cần thêm thông tin trong hệ thống giám sát của mình để theo dõi các chỉ số quan trọng như mức tiêu thụ token từ các mô hình của bạn.
Ứng dụng mẫu bao gồm một lệnh gọi đến các chỉ số CloudWatch để ghi lại mức tiêu thụ token và độ trễ LLM ở cuối mỗi lượt trò chuyện để các nhà điều hành có khả năng hiển thị dữ liệu này trong thời gian thực. Điều này cho phép các chỉ số được đưa vào bảng điều khiển và cảnh báo. Hơn nữa, dữ liệu chỉ số bao gồm định danh mô hình LLM làm một chiều để bạn có thể theo dõi mức tiêu thụ token và độ trễ theo mô hình. Các chỉ số chỉ là một thành phần trong số những gì chúng ta có thể tìm hiểu về ứng dụng của mình trong thời gian chạy với CloudWatch. Bởi vì các thông báo nhật ký của chúng ta được định dạng dưới dạng JSON, chúng ta có thể thực hiện phân tích trên dữ liệu nhật ký của mình để giám sát bằng CloudWatch Logs Insights. Sơ đồ kiến trúc sau minh họa các nhật ký và chỉ số được AppSync Events và Lambda cung cấp thông qua CloudWatch và CloudWatch Logs Insights.
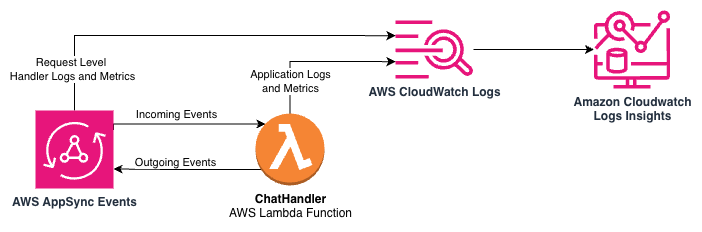
Ví dụ, truy vấn sau đối với các nhóm nhật ký của ứng dụng mẫu cho chúng ta thấy những người dùng có nhiều cuộc trò chuyện nhất trong một cửa sổ thời gian nhất định:
fields , | filter like "Message complete"| stats count_distinct(conversation_id) as conversation_count by user_id| sort conversation_count desc| limit 10@timestamp và @message là các trường tiêu chuẩn cho nhật ký Lambda. Trên dòng 3, chúng ta tính toán số lượng định danh cuộc trò chuyện duy nhất cho mỗi người dùng. Nhờ định dạng JSON của các tin nhắn, chúng ta không cần cung cấp hướng dẫn phân tích cú pháp để đọc các trường này. Thông báo nhật ký Message complete được tìm thấy trong packages/eventhandlers/eventhandlers/messages.py trong ứng dụng mẫu.
Ví dụ truy vấn sau cho thấy số lượng người dùng duy nhất sử dụng hệ thống trong một cửa sổ nhất định:
fields , | filter like "Message complete"| stats count_distinct(user_id) by bin(5m) as unique_users Một lần nữa, chúng ta lọc Message complete, tính toán các thống kê duy nhất trên trường user_id từ các tin nhắn JSON của chúng ta, và sau đó phát ra dữ liệu dưới dạng chuỗi thời gian với khoảng thời gian 5 phút bằng hàm bin.
Bộ nhớ đệm (phản hồi đã chuẩn bị)
Nhiều AI Gateway cung cấp cơ chế bộ nhớ đệm cho các tin nhắn trợ lý. Điều này sẽ phù hợp trong các tình huống mà số lượng lớn người dùng hỏi chính xác cùng một câu hỏi và cần chính xác cùng một câu trả lời. Điều này có thể tiết kiệm chi phí đáng kể cho một ứng dụng bận rộn trong tình huống phù hợp. Một ứng cử viên tốt cho bộ nhớ đệm có thể là về thời tiết. Ví dụ, với câu hỏi “Hôm nay ở NYC có mưa không?”, mọi người nên thấy cùng một phản hồi. Một ứng cử viên không tốt cho bộ nhớ đệm sẽ là một trường hợp mà người dùng có thể hỏi cùng một điều nhưng sẽ nhận được thông tin riêng tư để đổi lại, chẳng hạn như “Hiện tại tôi có bao nhiêu giờ nghỉ phép?”. Hãy cẩn thận khi sử dụng ý tưởng này một cách an toàn trong lĩnh vực công việc của bạn. Một triển khai bộ nhớ đệm cơ bản được bao gồm trong mẫu để giúp bạn bắt đầu với cơ chế này. Bộ nhớ đệm trong AI đàm thoại đòi hỏi rất nhiều sự cẩn thận để đảm bảo thông tin không bị rò rỉ giữa những người dùng. Với lượng ngữ cảnh mà một LLM có thể sử dụng để điều chỉnh phản hồi, bộ nhớ đệm nên được sử dụng một cách thận trọng.
Sơ đồ kiến trúc sau cho thấy việc sử dụng DynamoDB làm cơ chế lưu trữ cho các phản hồi đã chuẩn bị trong ứng dụng mẫu.
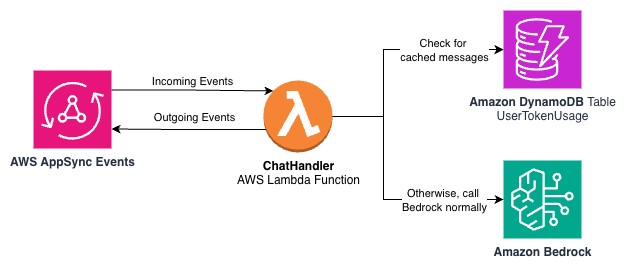
Ứng dụng mẫu tính toán một hàm băm trên tin nhắn người dùng để truy vấn một bảng DynamoDB với các tin nhắn đã lưu trữ. Nếu có một tin nhắn có sẵn cho một khóa băm, ứng dụng sẽ trả về văn bản cho người dùng, các chỉ số tùy chỉnh ghi lại một lượt truy cập bộ nhớ đệm trong CloudWatch, và một sự kiện được chuyển trở lại AppSync Events để thông báo cho ứng dụng rằng phản hồi đã hoàn tất. Điều này đóng gói hoàn toàn hành vi bộ nhớ đệm trong cấu trúc sự kiện mà ứng dụng hiểu.
Cài đặt ứng dụng mẫu
Tham khảo tệp README trên GitHub để biết hướng dẫn cài đặt ứng dụng mẫu. Cả cài đặt và gỡ cài đặt đều được điều khiển bởi một lệnh duy nhất để triển khai hoặc gỡ triển khai ứng dụng AWS CDK.
Định giá mẫu
Bảng sau ước tính chi phí hàng tháng của ứng dụng mẫu với mức sử dụng nhẹ trong môi trường phát triển. Chi phí thực tế sẽ thay đổi tùy theo cách bạn sử dụng các dịch vụ cho trường hợp sử dụng của mình.
| Dịch vụ | Đơn vị | Giá/Đơn vị | Mức sử dụng mẫu | Liên kết |
|---|---|---|---|---|
| AWS Glue | Đối tượng được lưu trữ | Không có chi phí bổ sung cho một triệu đối tượng đầu tiên được lưu trữ, 1,00 USD/100.000 đối tượng trên 1 triệu mỗi tháng | Dưới 1 triệu | https://aws.amazon.com/glue/pricing/ |
| Amazon DynamoDB | Đơn vị yêu cầu đọc | 0,625 USD cho mỗi triệu đơn vị yêu cầu ghi | 2,00 USD | https://aws.amazon.com/dynamodb/pricing/on-demand/ |
| Đơn vị yêu cầu ghi | 0,125 USD cho mỗi triệu đơn vị yêu cầu ghi | |||
| Amazon S3 (Standard) | 50 TB đầu tiên / Tháng | 0,023 USD cho mỗi GB | 2,00 USD | https://aws.amazon.com/s3/pricing/ |
| AppSync Events | Hoạt động API sự kiện | 1,00 USD cho mỗi triệu hoạt động API | 1,00 USD | https://aws.amazon.com/appsync/pricing/ |
| Phút kết nối | 0,08 USD cho mỗi triệu phút kết nối | |||
| Amazon Data Firehose | TB / tháng | 0,029 USD cho 500 TB đầu tiên / tháng | 1,00 USD | https://aws.amazon.com/firehose/pricing/ |
| Chuyển đổi định dạng mỗi GB | 0,018 USD / GB | |||
| AWS Lambda | Yêu cầu | 0,20 USD / 1 triệu yêu cầu | 1,00 USD | https://aws.amazon.com/lambda/pricing/ |
| Thời lượng | 0,0000000067 USD / GB-giây / tháng | |||
| Amazon Bedrock | Token đầu vào | 3,00 USD / 1 triệu token đầu vào (Anthropic Claude 4 Sonnet) | 20,00 USD-40,00 USD | https://aws.amazon.com/bedrock/pricing/ |
| Token đầu ra | 15,00 USD / 1 triệu token đầu ra (Anthropic Claude 4 Sonnet) | |||
| AWS WAF | Cơ sở | 5,00 USD / tháng | 8,00 USD | https://aws.amazon.com/waf/pricing/ |
| Quy tắc | 1,00 USD / quy tắc / tháng | |||
| Yêu cầu | 0,60 USD / 1 triệu yêu cầu | |||
| Amazon Cognito | Người dùng hoạt động hàng tháng | 10.000 người dùng đầu tiên, không có chi phí bổ sung | 0,00 USD | https://aws.amazon.com/cognito/pricing/ |
| Amazon CloudFront | Yêu cầu, Truyền dữ liệu ra | Xem giá | 0,00 USD | https://aws.amazon.com/cloudfront/pricing/ |
| Amazon CloudWatch | Nhật ký, Chỉ số | Xem giá | 0,00 USD | https://aws.amazon.com/cloudwatch/pricing/ |
Chi phí hàng tháng của ứng dụng mẫu, giả sử sử dụng phát triển nhẹ, dự kiến sẽ nằm trong khoảng từ 35–55 USD mỗi tháng.
Giao diện người dùng mẫu
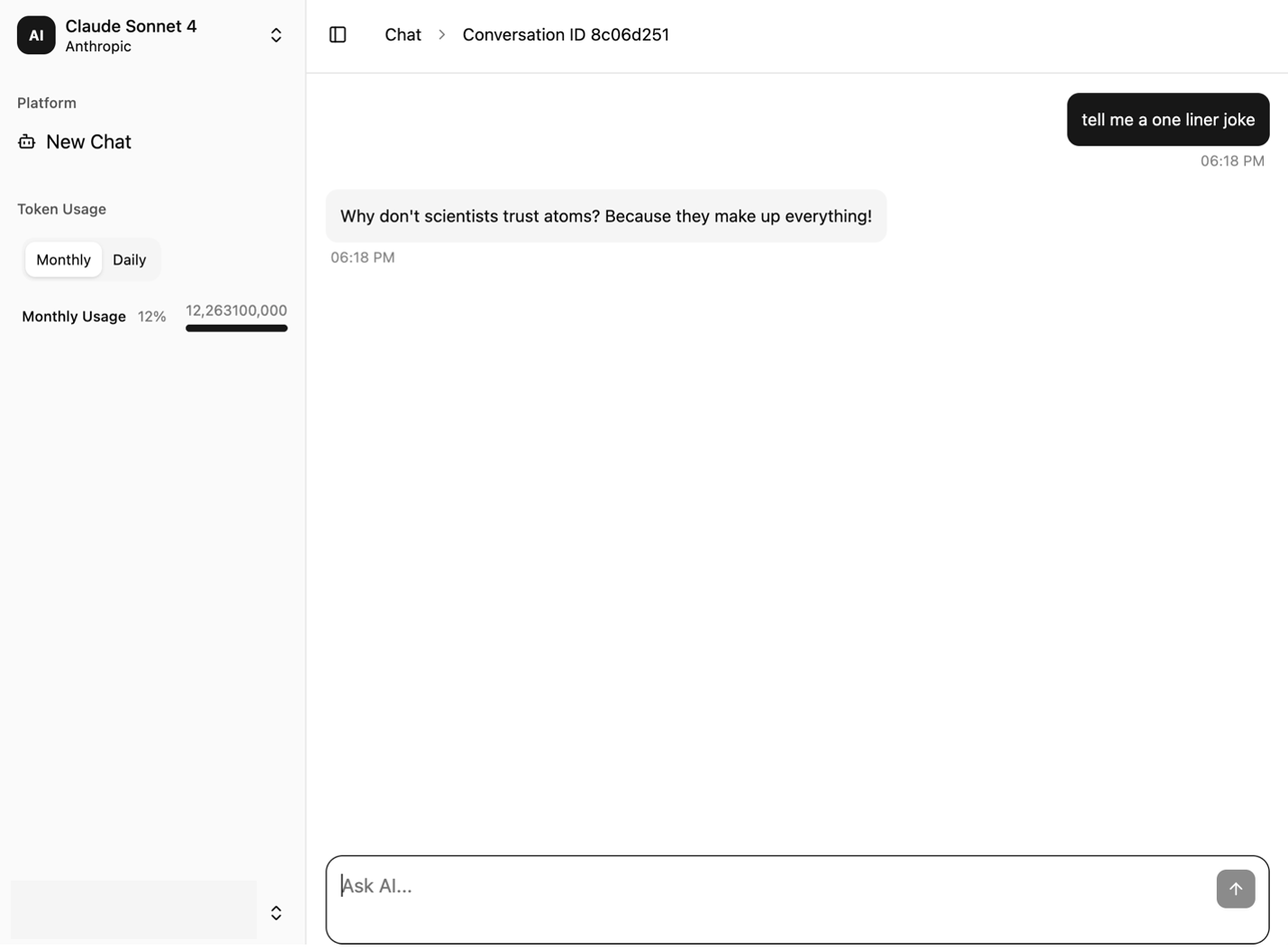
Các ảnh chụp màn hình sau đây giới thiệu giao diện người dùng mẫu. Nó cung cấp một cửa sổ trò chuyện ở bên phải và một thanh điều hướng ở bên trái. Giao diện người dùng có các thành phần chính sau:
- Phần Token Usage được hiển thị và cập nhật theo mỗi lượt trò chuyện
- Tùy chọn New Chat xóa các tin nhắn khỏi giao diện trò chuyện để người dùng có thể bắt đầu một phiên mới
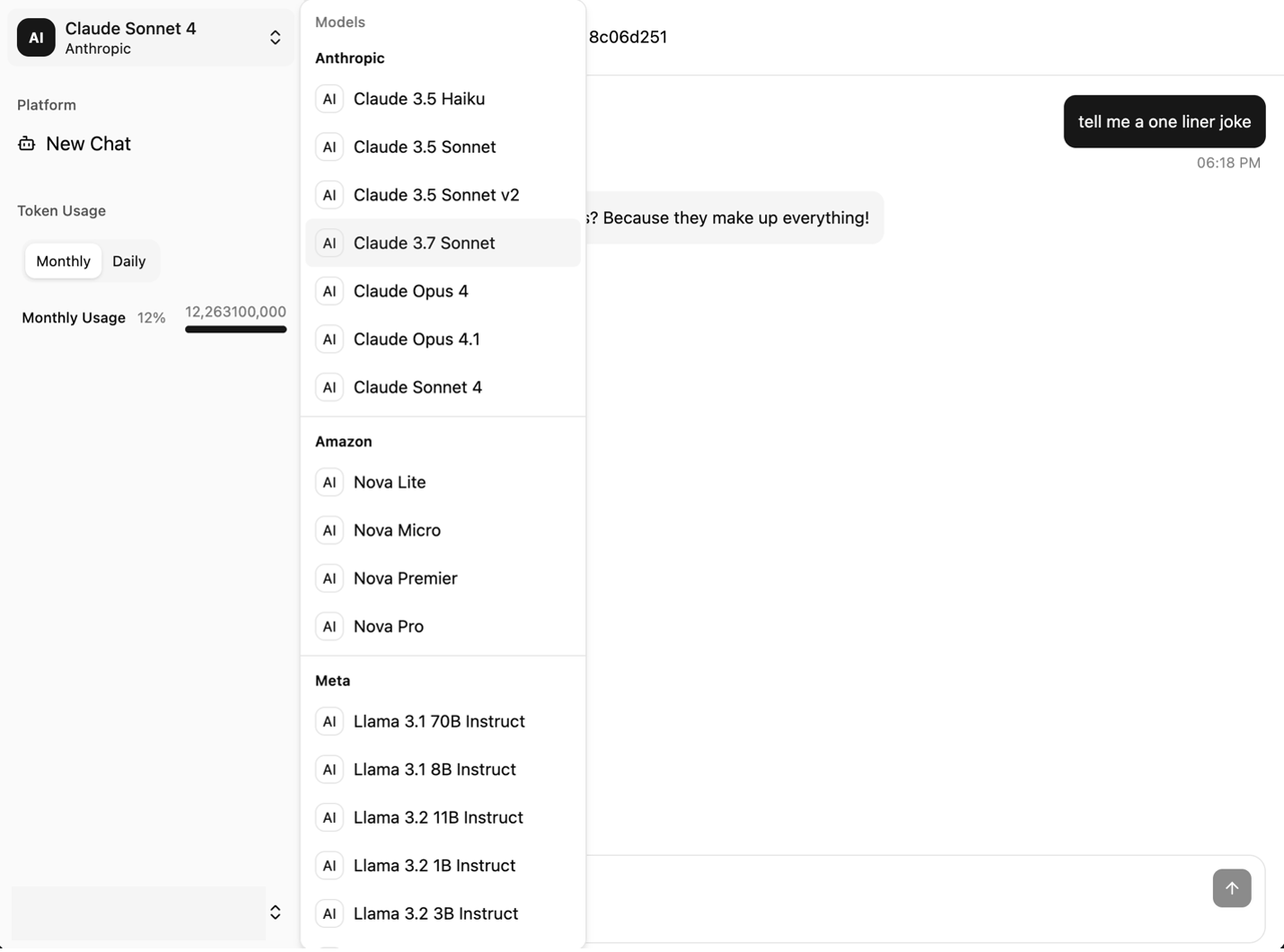
- Menu thả xuống chọn mô hình hiển thị các mô hình có sẵn
Ảnh chụp màn hình sau đây cho thấy giao diện trò chuyện của ứng dụng mẫu.
Ảnh chụp màn hình sau đây cho thấy menu chọn mô hình.
Kết luận
Khi bối cảnh AI phát triển, bạn cần một cơ sở hạ tầng thích ứng nhanh chóng như chính các mô hình. Bằng cách tập trung kiến trúc của bạn xung quanh AppSync Events và các mẫu phi máy chủ mà chúng ta đã đề cập—bao gồm xác thực danh tính dựa trên Amazon Cognito, đo lường được cung cấp bởi DynamoDB, khả năng quan sát của CloudWatch và phân tích của Athena—bạn có thể xây dựng một nền tảng phát triển theo nhu cầu của mình. Ứng dụng mẫu được trình bày trong bài viết này cung cấp cho bạn một điểm khởi đầu minh họa các mẫu trong thế giới thực, giúp các nhà phát triển khám phá tích hợp AI, các kiến trúc sư thiết kế các giải pháp doanh nghiệp và các nhà lãnh đạo kỹ thuật đánh giá các cách tiếp cận.
Mã nguồn hoàn chỉnh và hướng dẫn triển khai có sẵn trong kho lưu trữ GitHub. Để bắt đầu, hãy triển khai ứng dụng mẫu và khám phá chín kiến trúc đang hoạt động. Bạn có thể tùy chỉnh logic ủy quyền để phù hợp với yêu cầu của tổ chức mình và mở rộng lựa chọn mô hình để bao gồm các mô hình ưa thích của bạn trên Amazon Bedrock. Chia sẻ thông tin chi tiết triển khai của bạn với tổ chức của bạn và để lại phản hồi và câu hỏi của bạn trong phần bình luận.
Về tác giả

Archie Cowan là Nhà phát triển Prototype cấp cao trong nhóm Kỹ thuật Đám mây và Tạo mẫu Công nghiệp AWS. Anh gia nhập AWS vào năm 2022 và đã phát triển phần mềm cho các công ty trong ngành Ô tô, Năng lượng, Công nghệ và Khoa học Đời sống. Trước khi làm việc tại AWS, anh đã lãnh đạo nhóm kiến trúc tại ITHAKA, nơi anh đóng góp vào công cụ tìm kiếm trên jstor.org và giúp tăng tốc độ triển khai sản xuất từ 12 lên 10.000 bản phát hành mỗi năm trong suốt thời gian làm việc tại đó. Bạn có thể tìm thấy thêm các bài viết của anh về các chủ đề như lập trình với AI tại fnjoin.com và x.com/archiecowan.
