Tác giả: Ravikumar Sola, Rodrigue Koffi, and Lucas Vieira Souza da Silva
Ngày phát hành: 26 JAN 2026
Chuyên mục: Amazon Managed Grafana, Amazon Managed Service for Prometheus, Management Tools
Giới thiệu
Cảnh báo kết nối dữ liệu đo lường với hành động. Quản lý cảnh báo hiệu quả giúp bạn phát hiện vấn đề nhanh chóng, duy trì khả năng phục hồi và xây dựng lòng tin của khách hàng. Vậy, cách tốt nhất để quản lý cảnh báo khi lưu trữ các chỉ số trong Amazon Managed Service for Prometheus là gì? Trong bài đăng blog này, bạn sẽ tìm hiểu cách tạo, định tuyến và quản lý các quy tắc cảnh báo trong Amazon Managed Service for Prometheus (AMP) với các ví dụ thực tế. Bạn sẽ học cách sử dụng các chỉ số chính, tận dụng nhật ký Amazon Managed Service for Prometheus được cung cấp và thiết lập bảng điều khiển để trực quan hóa và quản lý cảnh báo. Bài đăng blog này là một phần của chuỗi bài về kiểm soát quản trị với Amazon Managed Service for Prometheus. Để tìm hiểu thêm về phần đầu tiên của chuỗi, hãy truy cập Tối ưu hóa truy vấn với Amazon Managed Prometheus. Đối với phần thứ hai bao gồm tối ưu hóa việc nhập chỉ số, hãy xem Tối ưu hóa việc nhập chỉ số với Amazon Managed Service for Prometheus.
Tổng quan
Bài blog này tập trung vào kiến trúc quan sát tập trung. Example Corp, một công ty đa quốc gia, đang thu thập tất cả các chỉ số nền tảng và ứng dụng ở định dạng Prometheus với một chế độ xem tập trung từ nhiều tài khoản AWS. Nhóm quan sát trung tâm, đã tối ưu hóa truy vấn PromQL của họ trong bài đăng blog ban đầu, giờ đây cần xác thực xem các cảnh báo của Example Corp có được tạo theo các phương pháp hay nhất để tránh tình trạng mệt mỏi do cảnh báo hay không. Đồng thời đảm bảo các quy tắc cảnh báo dễ đọc để các nhóm có thể hành động nhanh chóng với gánh nặng nhận thức giảm. Hãy cùng khám phá cách các tính năng AlertManager, Recording và Alerting rules trong Amazon Managed Service for Prometheus có thể giúp Example Corp giải quyết những thách thức này và giảm thời gian trung bình để phục hồi sau sự cố.
Điều kiện tiên quyết
Bài đăng blog này giả định bạn có những điều sau:
- Khối lượng công việc Amazon Elastic Kubernetes Service (EKS)
- Amazon Managed Service for Prometheus (AMP) Managed Scraper
- Chủ đề Amazon Simple Notification Service (SNS) hoặc tích hợp PagerDuty (tùy chọn)
- AWS Commandline (AWS CLI) đã được cài đặt và cấu hình
- Một IAM role hoặc người dùng có quyền quản lý tài nguyên Amazon Prometheus, nhóm nhật ký CloudWatch và các mục tiêu thông báo cảnh báo
Kiến trúc để giám sát khối lượng công việc Amazon Elastic Kubernetes Service (Amazon EKS)
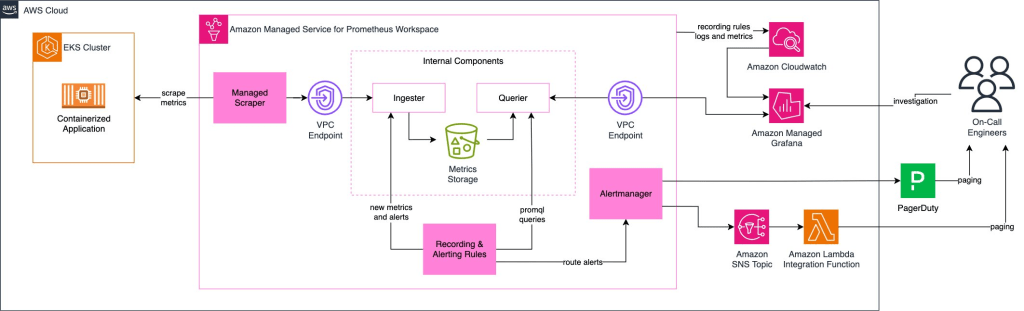
Hình 1: Kiến trúc cảnh báo khối lượng công việc dựa trên Amazon EKS
Vì Example Corp đang sử dụng AMP để giám sát khối lượng công việc dựa trên EKS, họ sẽ cần hiểu kiến trúc trên. Hãy cùng đi sâu vào từng thành phần chi tiết.
- Khối lượng công việc Amazon EKS: Ứng dụng được container hóa chạy trên một cụm Amazon EKS, tạo ra các chỉ số như mức sử dụng CPU, mức tiêu thụ bộ nhớ và tỷ lệ lỗi.
- Amazon AMP Scraper: Scraper được quản lý thu thập các chỉ số từ cụm Amazon EKS, loại bỏ nhu cầu quản lý các máy chủ Prometheus. Nó sử dụng AWS Signature Version 4 để gửi các chỉ số đã nhập một cách an toàn đến đích Amazon Managed Service for Prometheus.
- Recording & Alerting Rules: Các truy vấn PromQL (Prometheus Query Language) được biên dịch trước sẽ chạy định kỳ và tạo ra các chỉ số và cảnh báo mới.
- AlertManager: AlertManager của Amazon Managed Service for Prometheus định tuyến các cảnh báo dựa trên các quy tắc đã định nghĩa, cho phép loại bỏ trùng lặp và nhóm để phân phối thông báo hiệu quả và quản lý tình trạng mệt mỏi do cảnh báo. Bạn cũng có thể sử dụng AlertManager để tắt tiếng và ngăn chặn cảnh báo.
- Amazon SNS: Các cảnh báo từ AlertManager được gửi đến một chủ đề SNS. Example Corp hiện đang sử dụng AWS Lambda để xử lý các cảnh báo đến các hệ thống hạ nguồn cho nhiệm vụ trực.
- Giới thiệu tích hợp trực tiếp PagerDuty: Ngoài lựa chọn gửi cảnh báo đến SNS, giờ đây khách hàng AWS có tùy chọn tích hợp Amazon Managed Service for Prometheus trực tiếp với PagerDuty, giảm độ phức tạp trong việc định tuyến cảnh báo.
Kiến trúc bao gồm các thành phần nội bộ cấp cao của Amazon Managed Service for Prometheus mà bạn không cần cấu hình, cụ thể là Ingester, Querier và Metrics Storage. Chúng được thiết kế trong sơ đồ chỉ với mục đích giải thích cách Recording & Alerting Rules được kết nối với dịch vụ. Thiết lập này tập trung vào việc thu thập chỉ số có thể mở rộng, cảnh báo hiệu quả và tích hợp liền mạch với các quy trình vận hành. Để biết chi tiết về cách thiết lập managed scraper, hãy xem Tự động hóa việc thu thập chỉ số trên Amazon EKS với Amazon Managed Service for Prometheus managed scrapers.
Các quy tắc ghi và cảnh báo
Cả quy tắc ghi (recording rules) và quy tắc cảnh báo (alerting rules) đều là các thành phần thiết yếu của Amazon Managed Service for Prometheus, nhưng chúng phục vụ các mục đích khác nhau. Hãy cùng khám phá cách Example Corp sử dụng từng loại quy tắc để nâng cao chiến lược quan sát của họ.
Các quy tắc ghi
Được sử dụng chủ yếu để tối ưu hóa hiệu suất truy vấn, các quy tắc ghi tính toán trước các biểu thức PromQL phức tạp hoặc được sử dụng thường xuyên và lưu trữ kết quả dưới dạng chuỗi thời gian mới.
Ví dụ:
groups: - name: example-corp-recordings rules: - record: job:http_errors_total:5m expr: sum(rate(http_errors_total[5m])) by (job)Các quy tắc ghi tạo ra các chỉ số mới, và những chỉ số này có thể được sử dụng bởi các quy tắc cảnh báo để quản lý vòng đời cảnh báo. Cả hai loại quy tắc đều được định nghĩa trong các tệp YAML và hoạt động cùng nhau để tạo ra một giải pháp giám sát toàn diện. Trong khi các quy tắc ghi giúp Example Corp duy trì hiệu suất bảng điều khiển ở quy mô lớn, các quy tắc cảnh báo cho phép nhóm của họ phản ứng nhanh chóng với các vấn đề tiềm ẩn.
Các quy tắc cảnh báo
Được sử dụng để phát hiện sự cố chủ động, các quy tắc cảnh báo định nghĩa các điều kiện kích hoạt thông báo khi đạt đến các ngưỡng cụ thể.
Ví dụ:
groups: - name: example-corp-alerts rules: - alert: HighCPUUsage expr: avg by(instance) (cpu_usage_total) > 80 for: 5m labels: severity: warning annotations: description: "Instance {{ $labels.instance }} has high CPU usage"Các cảnh báo được cấu trúc tốt sử dụng các chỉ số rõ ràng, ngưỡng phù hợp và thông báo có thể hành động. Chúng sẽ được xây dựng dựa trên các chỉ số chung hoặc các quy tắc ghi, sẽ trừu tượng hóa các truy vấn phức tạp và tạo điều kiện dễ đọc.
Cấu hình các quy tắc ghi và cảnh báo
Quay lại trường hợp sử dụng của chúng ta với Example Corp, các kỹ sư trực của họ cần được cảnh báo khi tỷ lệ lỗi HTTP cho bất kỳ ứng dụng nào cao hơn 10%. Hiện tại họ có một chỉ số http_requests_total với nhãn trạng thái và các giá trị có thể là 500, 400, 300 và 200. Example Corp muốn tập trung vào các yêu cầu có trạng thái phản hồi 500.
1. Định nghĩa các quy tắc ghi và cảnh báo
- Hãy tạo một quy tắc ghi
app_error_ratetrong Amazon Prometheus workspace bằng cách sử dụng các bước dưới đây. Điều này sẽ tính toán tỷ lệ lỗi bằng tổng số lỗi chia cho tổng số yêu cầu sử dụnghttp_requests_total{status="500"}cho lỗi vàhttp_requests_totalcho tất cả các yêu cầu. Sử dụng quy tắc ghi cải thiện hiệu suất truy vấn và đơn giản hóa quy tắc cảnh báo tiêu thụ chỉ số này. - Bây giờ hãy định nghĩa một cảnh báo nếu
app_error_ratevượt quá 10% trong 5 phút. Chúng ta sẽ sử dụng lại chỉ sốapp_error_rateđã được tính toán trước để kích hoạt cảnh báo khi tỷ lệ lỗi vượt quá 10% (> 0.1). Ví dụ dưới đây được cấu hình để đợi 5 phút trước khi kích hoạt (for: 5m) đồng thời bao gồm các nhãn mức độ nghiêm trọng và nhóm để định tuyến. Lưu ý rằng mô tả cảnh báo cung cấp các chú thích có thể hành động với các liên kết bảng điều khiển và runbook. - Định nghĩa quy tắc ghi và quy tắc cảnh báo trong một tệp YAML
rules.yamlcục bộ như hình dưới đây.
groups: - name: error-rate-rules rules: # Recording rule - record: app_error_rate expr: sum(rate(http_requests_total{status="500"}[5m])) by (job) / sum(rate(http_requests_total[5m])) by (job) labels: new_label: "application" # Alert rule - alert: HighErrorRate expr: app_error_rate > 0.1 for: 5m labels: severity: critical team: platform annotations: summary: "High error rate detected" description: "Application error rate is {{ $value | humanizePercentage }} for the last 5 minutes" dashboard: "https://grafana.example.com/d/application-dashboard" runbook: "https://wiki.example.com/runbooks/high-error-rate"2. Tải lên các tệp quy tắc
Hãy tải các quy tắc lên một không gian tên nhóm quy tắc mới trong Amazon Managed Service for Prometheus workspace bằng cách sử dụng AWS Command Line Interface (AWS CLI):
aws amp create-rule-groups-namespace \ --workspace-id <your-workspace-id> \ --name my-rules-namespace \ --data file://rules.yamlOutput:{"name": "my-rules-namespace","status": "ACTIVE"}Các không gian tên là một cách thuận tiện để tổ chức các nhóm quy tắc. Ví dụ, một nhóm có thể có nhiều quy tắc và nhóm cảnh báo khác nhau trong cùng một không gian tên, trong khi các nhóm khác sẽ có không gian tên riêng của họ. Để xác minh các quy tắc của bạn đã được tải lên thành công, bạn có thể chạy lệnh sau:
# List all rule groups namespacesaws amp list-rule-groups-namespaces --workspace-id <your-workspace-id>Output:"ruleGroupsNamespaces": [{"name": "my-rules-namespace","status": "ACTIVE","createdAt": "2025-01-10T14:22:31Z","modifiedAt": "2025-01-10T14:22:31Z"}]# Get the specific namespace detailsaws amp describe-rule-groups-namespace \ --workspace-id <your-workspace-id> \ --name my-rules-namespaceOutput:{"name": "my-rules-namespace","status": "ACTIVE","data": "groups:\n- name: error-rate-rules\n rules:\n - record: app_error_rate\n expr: rate(http_requests_total{status=\"500\"}[5m]) / rate(http_requests_total[5m])\n labels:\n job: \"application\"\n","createdAt": "2025-01-10T14:22:31Z","modifiedAt": "2025-01-10T14:22:31Z"}3. Cấu hình AlertManager với SNS (tùy chọn 1)
Để định tuyến cảnh báo đến Amazon SNS, hãy cấu hình AlertManager bằng cách sử dụng tệp YAML. Thiết lập các nhóm sẽ cho phép AlertManager giảm nhiễu và tình trạng mệt mỏi do cảnh báo. Ví dụ, nếu nhiều cảnh báo cho cùng một Kubernetes namespace được kích hoạt và bạn chọn nhóm chúng lại với nhau, nhóm trực sẽ được thông báo một lần, nhưng có thông tin về tất cả các cảnh báo khác nhau được kích hoạt trong cùng một nhóm thông qua Amazon Managed Grafana. Dưới đây là cách thiết lập:
Tạo một tệp alertmanager.yml cục bộ:
alertmanager_config: | global: resolve_timeout: 5m route: group_by: ['alertname', 'severity', 'team', 'namespace'] group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: 'sns-notifications' receivers: - name: 'sns-notifications' sns_configs: - topic_arn: 'arn:aws:sns:region:account-id:your-topic-name' sigv4: region: region attributes: subject: '[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]'Trước khi tiếp tục, hãy kiểm tra các tham số cấu hình AlertManager quan trọng:
- group_by: Xác định cách các cảnh báo được nhóm lại với nhau. Trong ví dụ này, các cảnh báo sẽ được nhóm lại khi chúng có cùng tên, mức độ nghiêm trọng, nhóm đính kèm và Kubernetes namespace.
- group_wait: Thời gian chờ ban đầu trước khi gửi thông báo.
- group_interval: Thời gian giữa việc gửi các thông báo cập nhật khi các cảnh báo mới từ cùng một nhóm được kích hoạt kể từ thông báo cuối cùng.
- repeat_interval: Thời gian tối thiểu trước khi lặp lại một thông báo mới của cùng một nhóm cảnh báo đã kích hoạt.
- sns_configs: Cấu hình cụ thể của SNS bao gồm ARN chủ đề và AWS region.
Để biết hướng dẫn đầy đủ, bao gồm các quyền IAM cần thiết, hãy tham khảo tài liệu chính thức.
4. Cấu hình AlertManager với PagerDuty (tùy chọn 2)
Hãy bắt đầu bằng cách lưu trữ khóa tích hợp PagerDuty trong AWS Secrets Manager
# Create secret with PagerDuty integration keyaws secretsmanager create-secret \--name amp-pagerduty-key \--description "PagerDuty integration key for AMP" \--secret-string '{"routing_key":"your-pagerduty-integration-key-here"}'Tương tự như cấu hình trên trong tùy chọn 1, hãy thực hiện các bước sau để cấu hình AlertManager với tích hợp PagerDuty trong tệp alertmanager.yml cục bộ:
alertmanager_config: | route: group_by: ['alertname', 'severity', 'team', 'namespace'] group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: 'pagerduty-receiver' receivers: - name: 'pagerduty-receiver' pagerduty_configs: - routing_key: 'arn:aws:secretsmanager:<REGION>:<ACCOUNT_ID>:secret:amp-pagerduty-key' description: '{{ .CommonLabels.alertname }}' severity: 'severity: '{{ .CommonLabels.severity | default "critical" }}'' details: firing: '{{ .Alerts.Firing | len }}' status: '{{ .Status }}' instance: '{{ .CommonLabels.instance }}'Để biết hướng dẫn đầy đủ, bao gồm cấu hình hoàn chỉnh của bí mật AWS Secrets Manager sẽ lưu trữ an toàn khóa API tích hợp và các quyền IAM cần thiết, hãy tham khảo tài liệu chính thức.
5. Tải cấu hình lên Amazon Managed Service for Prometheus
Bây giờ bạn có thể áp dụng cấu hình bằng cách sử dụng AWS CLI:
# Upload the alertmanager configuration directlyaws amp put-alert-manager-definition \ --workspace-id <your-workspace-id> \ --data file://alertmanager.ymlGiám sát các đánh giá quy tắc ghi và cảnh báo của bạn
Sau khi các quy tắc và AlertManager được cấu hình, các nhóm của Example Corp sẽ bắt đầu nhận được các thông báo phù hợp, dễ đọc khi lỗi tăng trong ứng dụng này. Sử dụng Amazon CloudWatch, họ có thể tận dụng các chỉ số và nhật ký được cung cấp để giám sát việc thực thi và lỗi với các quy tắc ghi và cảnh báo. Để giám sát hiệu suất của các quy tắc của họ, Example Corp có thể thiết lập các bảng điều khiển và cảnh báo Amazon CloudWatch bằng cách sử dụng các chỉ số sau:
- RuleEvaluationLatency: Thời gian cần để đánh giá các quy tắc tính bằng mili giây. Độ trễ cao có thể cho thấy các truy vấn phức tạp hoặc hạn chế về tài nguyên.
- RuleEvaluationFailures: Số lần đánh giá quy tắc thất bại. Điều tra các lỗi cú pháp hoặc chỉ số bị thiếu.
- RulesEvaluated: Tổng số quy tắc đã được đánh giá. Sử dụng để giám sát khối lượng xử lý quy tắc.
Amazon Managed Service for Prometheus có thể được cấu hình để xuất bản các sự kiện lỗi và cảnh báo nhật ký trong các nhóm nhật ký Amazon CloudWatch trong CloudWatch Logs. Để bật nhật ký, hãy thực hiện lệnh dưới đây từ dòng lệnh.
# Create a log group for vended logsaws logs create-log-group \ --log-group-name "/aws/vendedlogs/prometheus/example-corp-workspace" \ --region <REGION># Enable logging for the workspaceaws amp create-logging-configuration \ --workspace-id <your-workspace-id> \ --log-group-arn "arn:aws:logs:<REGION>:<ACCOUNT_ID>:log-group:/aws/vendedlogs/prometheus/example-corp-workspace"Để biết thêm hướng dẫn, hãy tham khảo tài liệu chính thức. Example Corp giờ đây có thể sử dụng CloudWatch Logs Insights để biết về bất kỳ quy tắc nào bị cấu hình sai:
fields @timestamp, @message| filter @message like /ERROR.*rule/| sort @timestamp desc| limit 100Xem các chỉ số quan trọng trong bảng điều khiển
Để đưa tất cả các chỉ số và nhật ký này vào một nơi chung, sử dụng cả chỉ số Prometheus, chỉ số CloudWatch và nhật ký, chúng tôi đã chuẩn bị một ví dụ về bảng điều khiển Grafana mà bạn có thể sử dụng để giám sát các cảnh báo và quy tắc ghi của mình với Amazon Managed Service for Prometheus.
Lưu ý: Vui lòng xem lại bảng điều khiển mẫu trước khi triển khai trong tài khoản của bạn để đảm bảo nó đáp ứng các tiêu chuẩn bảo mật của tổ chức bạn.
Để nhập bảng điều khiển, hãy làm theo các bước sau.
- Tải xuống JSON từ GitHub
- Trong Amazon Managed Grafana, điều hướng đến Dashboards → Import
- Tải lên tệp JSON
- Cấu hình nguồn dữ liệu:
- Prometheus: AMP workspace của bạn
- CloudWatch: Tài khoản/region AWS của bạn
- Đặt biến
workspace_idthành ID AMP workspace của bạn
Dưới đây là tổng quan về bảng điều khiển và hãy cùng phân tích nó.

Hình 2: Bảng điều khiển cảnh báo và quy tắc ghi
- Alerts’ State Over Time: Bảng điều khiển này cung cấp trực quan hóa dòng thời gian của các cảnh báo chuyển đổi giữa các trạng thái. Nó tận dụng các bộ lọc với các biến như:
- Alert: lọc theo tên cảnh báo đã chọn, hoặc tất cả các cảnh báo
- State: lọc theo tất cả các cảnh báo đang ở trạng thái được chỉ định, đang chờ xử lý hoặc đang kích hoạt
- Severity: lọc theo tất cả các cảnh báo được phân loại theo mức độ nghiêm trọng đã chọn, chẳng hạn như critical
- Vended Logs: Tại đây, chúng tôi hiển thị nhật ký đánh giá quy tắc chi tiết và thông báo lỗi. Để sử dụng lại, bạn sẽ cần trỏ nó đến các nhóm nhật ký được cung cấp của bạn, ví dụ:
/aws/vendedlogs/prometheus/example-corp-workspace - Rule Groups’ Metrics: Điều này giám sát tình trạng đánh giá quy tắc ghi và các chỉ số hiệu suất của Amazon Managed Service for Prometheus, tận dụng các chỉ số CloudWatch bao gồm:
AWS/Prometheus:RuleEvaluations,AWS/Prometheus:RuleEvaluationFailures,AWS/Prometheus:RuleGroupIterationsMissed
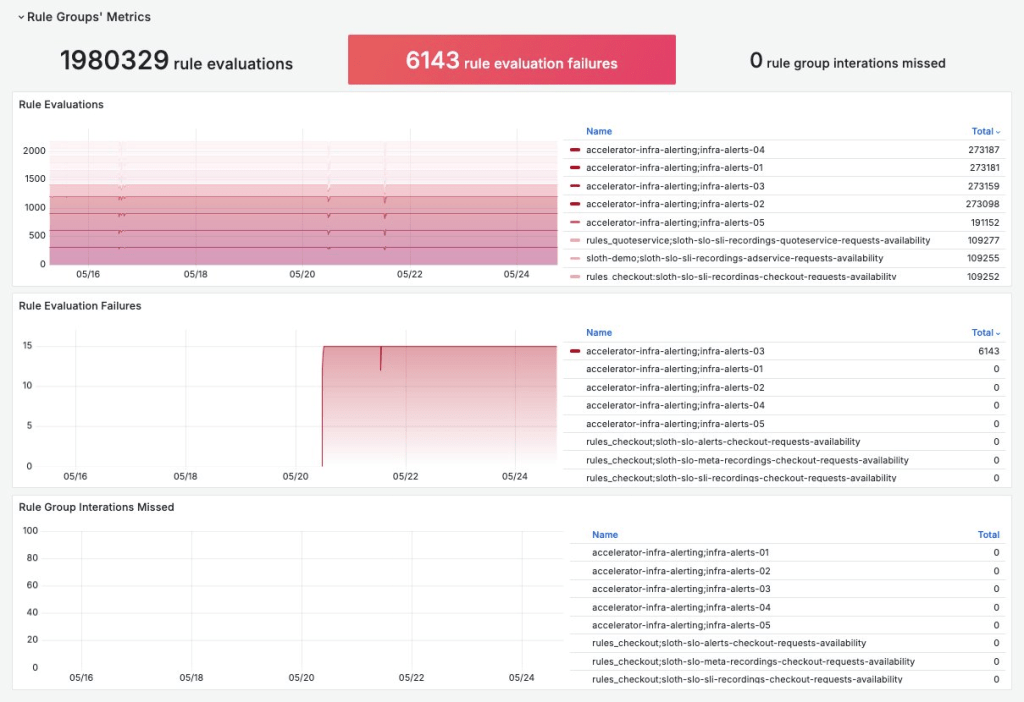
Hình 3: Bảng điều khiển cảnh báo và quy tắc ghi – Hàng chỉ số nhóm quy tắc
Để hoàn thiện trải nghiệm trực quan hóa và khắc phục sự cố cảnh báo trong Amazon Managed Grafana, hãy cân nhắc cấu hình AlertManager datasource.
Ví dụ về cách khắc phục sự cố cảnh báo sản xuất bằng bảng điều khiển
Các nhóm kỹ sư từ Example Corp bắt đầu cấu hình các quy tắc ghi và cảnh báo cho các ứng dụng và cơ sở hạ tầng của họ ở quy mô lớn. Nhưng sau một thời gian, một trong các nhóm này bắt đầu phàn nàn rằng họ không thể trực quan hóa các chỉ số quy tắc của mình trong Amazon Managed Grafana, và các cảnh báo phụ thuộc vào các quy tắc này hoàn toàn không được kích hoạt. Để hiểu tại sao mỗi vấn đề này lại xảy ra, nhóm quan sát đã xác nhận các quy tắc ghi đã được cấu hình trong Amazon Managed Service for Prometheus:
- Tru cập Bảng điều khiển Cảnh báo và Quy tắc ghi và kiểm tra trạng thái cảnh báo bằng cách chọn các giá trị phù hợp cho các biến Alert và Severity và kiểm tra hàng Alerts’ State Over Time.
- Mở rộng phạm vi thời gian và thấy rằng các cảnh báo không bao giờ được kích hoạt. Sau đó, họ tìm thấy trong Rule Evaluation Failures một dấu hiệu cho thấy một quy tắc ghi liên tục bị lỗi.
- Bằng cách kiểm tra hàng AMP Vended Logs, xác nhận quy tắc bị lỗi thuộc về nhóm đó và kết luận có điều gì đó không ổn với truy vấn quy tắc ghi, gây ra lỗi.
- Sao chép truy vấn quy tắc và thực thi nó trong tab Explore, xác nhận nó bị hỏng. Sau đó, họ liên hệ với nhóm, nhóm này đã có thể sửa truy vấn và làm cho các cảnh báo của họ hoạt động bình thường.
Dọn dẹp
Để xóa các tài nguyên được tạo trong hướng dẫn này, hãy làm theo các bước sau:
1. Xóa cấu hình AlertManager
aws amp delete-alert-manager-definition \ --workspace-id <your-workspace-id>2. Xóa không gian tên nhóm quy tắc
aws amp delete-rule-groups-namespace \ --workspace-id <your-workspace-id> \ --name my-rules-namespace3. Xóa nhóm nhật ký CloudWatch
aws logs create-log-group \ --log-group-name "/aws/vendedlogs/prometheus/example-corp-workspace" \ --region <REGION>4. Xóa chủ đề SNS (nếu được tạo riêng cho hướng dẫn này)
aws sns delete-topic \ --topic-arn "arn:aws:sns:region:account-id:your-topic-name"5. Dọn dẹp các vai trò và chính sách IAM
Xóa bất kỳ IAM roles và policies nào được tạo riêng cho tích hợp AlertManager SNS.
6. Xóa bí mật Secrets Manager (nếu sử dụng PagerDuty)
aws secretsmanager delete-secret \ --secret-id <YOUR_SECRET_NAME> \ --force-delete-without-recoveryLưu ý: Hãy cẩn thận khi xóa tài nguyên. Đảm bảo bạn chỉ xóa các tài nguyên được tạo cho hướng dẫn này chứ không phải tài nguyên sản xuất.
Kết luận
Trong bài blog này, chúng tôi đã khám phá cách Example Corp tận dụng các phương pháp hay nhất về cảnh báo trong Amazon Managed Service for Prometheus để giám sát khối lượng công việc được container hóa của họ ở quy mô lớn. Chúng tôi đã chứng minh cách các tổ chức có thể triển khai các chiến lược cảnh báo toàn diện thông qua các quy tắc ghi và cảnh báo, sử dụng AlertManager để định tuyến thông báo hiệu quả, và tận dụng nhật ký được cung cấp cùng các chỉ số CloudWatch để có khả năng hiển thị giám sát. Chúng tôi đã chỉ ra cách các nhóm có thể giảm thiểu tình trạng mệt mỏi do cảnh báo trong khi vẫn duy trì khả năng phản ứng sự cố hiệu quả. Các phương pháp cảnh báo này cung cấp khả năng hiển thị về tình trạng ứng dụng và cho phép phát hiện vấn đề chủ động. Khi môi trường container hóa ngày càng phức tạp, các phương pháp hay nhất về cảnh báo này trở nên ngày càng quan trọng để duy trì tính sẵn sàng cao và sự xuất sắc trong vận hành. Để tìm hiểu thêm về AWS Observability, hãy xem Hướng dẫn các phương pháp hay nhất về AWS Observability. Để có kinh nghiệm thực hành với các dịch vụ AWS Observability, hãy xem One Observability Workshop.
Về tác giả

Ravikumar Sola
Ravikumar Sola là Trưởng nhóm Hỗ trợ Doanh nghiệp tại AWS, chuyên về Quan sát (Observability) và Vận hành Xuất sắc (Operational Excellence). Anh hợp tác với các khách hàng Hỗ trợ Doanh nghiệp của AWS để tối ưu hóa hoạt động và khối lượng công việc của họ trên AWS, giúp họ đạt được các mục tiêu kinh doanh thông qua hướng dẫn chiến lược và chuyên môn kỹ thuật thực tế.

Rodrigue Koffi
Rodrigue là Kiến trúc sư Giải pháp Chuyên gia tại Amazon Web Services về Quan sát. Anh đam mê quan sát, các hệ thống phân tán và học máy. Anh có nền tảng vững chắc về DevOps và phát triển phần mềm, và yêu thích lập trình với Go. Ngoài công việc, Rodrigue thích bơi lội và dành thời gian chất lượng bên gia đình. Tìm anh ấy trên LinkedIn tại /grkoffi

Lucas Vieira Souza da Silva
Lucas Vieira Souza da Silva là Kiến trúc sư Giải pháp tại Amazon Web Services (AWS). Anh dành thời gian để tìm hiểu sâu về các công nghệ Quan sát, các trường hợp sử dụng và các tiêu chuẩn mở; tự động hóa việc đo lường từ xa các khối lượng công việc chạy trên đám mây thông qua Infrastructure as Code; kết nối Quan sát với vòng đời ứng dụng kinh doanh. Lucas cũng đam mê thiết kế các bảng điều khiển chức năng, ý nghĩa và có khả năng mở rộng.
