Tác giả: Karthik Prabhakar, Amber Runnels, Neil Mukerje, và Parul Saxena
Ngày phát hành: 26 JAN 2026
Chuyên mục: Advanced (300), Amazon EMR, Analytics, AWS Well-Architected Framework, Best Practices
Amazon EMR Serverless là một tùy chọn triển khai cho Amazon EMR mà bạn có thể sử dụng để chạy các framework phân tích dữ liệu lớn mã nguồn mở như Apache Spark và Apache Hive mà không cần phải cấu hình, quản lý hoặc mở rộng các cluster và server. EMR Serverless tích hợp với các dịch vụ của Amazon Web Services (AWS) trên các lĩnh vực lưu trữ dữ liệu, streaming, điều phối, giám sát và quản trị để cung cấp một giải pháp phân tích serverless toàn diện.
Trong bài viết này, chúng tôi chia sẻ 10 phương pháp hay nhất để tối ưu hóa các workload EMR Serverless của bạn về hiệu suất, chi phí và khả năng mở rộng. Cho dù bạn mới bắt đầu với EMR Serverless hay đang tìm cách tinh chỉnh các workload sản xuất hiện có, những khuyến nghị này sẽ giúp bạn xây dựng các pipeline xử lý dữ liệu hiệu quả và tiết kiệm chi phí. Sơ đồ sau minh họa kiến trúc EMR Serverless từ đầu đến cuối, cho thấy cách nó tích hợp vào các pipeline phân tích của bạn.
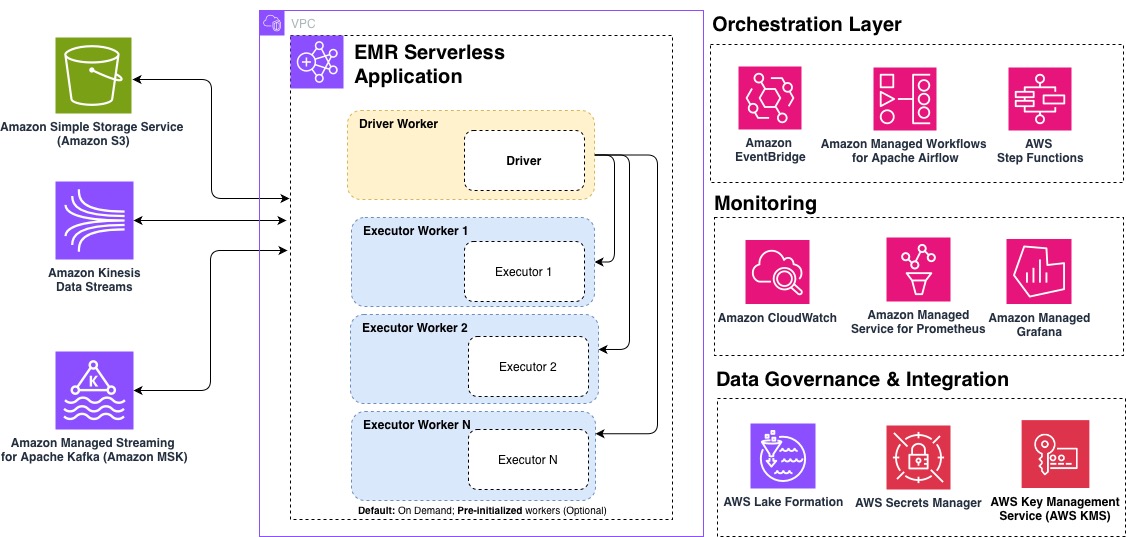
1. Định nghĩa ứng dụng một lần, tái sử dụng nhiều lần
Ứng dụng EMR Serverless hoạt động như các template cluster được khởi tạo khi các job được gửi và có thể xử lý nhiều job mà không cần tạo lại. Thiết kế này giúp giảm đáng kể độ trễ khởi động cho các workload định kỳ và đơn giản hóa việc quản lý vận hành.
Quy trình làm việc điển hình cho EMR trên EC2 transient cluster:

Quy trình làm việc điển hình cho EMR Serverless:

Các ứng dụng có vòng đời tự quản lý, cung cấp tài nguyên khi cần mà không cần can thiệp thủ công. Chúng tự động cung cấp capacity khi một job được gửi. Đối với các ứng dụng không có capacity được khởi tạo trước, tài nguyên sẽ được giải phóng ngay sau khi job hoàn thành. Đối với các ứng dụng có capacity được khởi tạo trước, các worker được khởi tạo trước đó sẽ dừng sau khi vượt quá thời gian chờ idle được cấu hình (mặc định là 15 phút). Bạn có thể điều chỉnh thời gian chờ này ở cấp độ ứng dụng bằng cách sử dụng cấu hình AutoStopConfig trong CreateApplication hoặc UpdateApplication API. Ví dụ, nếu các job của bạn chạy mỗi 30 phút, việc tăng thời gian chờ idle có thể loại bỏ độ trễ khởi động giữa các lần thực thi.
Hầu hết các workload đều phù hợp với việc cung cấp capacity theo yêu cầu (on-demand), tự động mở rộng tài nguyên dựa trên yêu cầu của job mà không phát sinh chi phí khi idle. Cách tiếp cận này tiết kiệm chi phí và phù hợp với các trường hợp sử dụng điển hình bao gồm các workload extract, transform, and load (ETL), các job xử lý hàng loạt (batch processing), và các kịch bản yêu cầu khả năng phục hồi job tối đa.
Đối với các workload cụ thể có yêu cầu khởi động tức thì nghiêm ngặt, bạn có thể tùy chọn cấu hình capacity được khởi tạo trước. Capacity được khởi tạo trước tạo ra một pool driver và executor sẵn sàng chạy các job trong vài giây. Tuy nhiên, lợi thế về hiệu suất này đi kèm với chi phí tăng thêm vì các worker được khởi tạo trước phát sinh chi phí liên tục ngay cả khi idle cho đến khi ứng dụng đạt trạng thái Stopped. Ngoài ra, capacity được khởi tạo trước giới hạn các job trong một Availability Zone duy nhất, điều này làm giảm khả năng phục hồi.
Capacity được khởi tạo trước chỉ nên được xem xét cho:
- Các job nhạy cảm về thời gian với yêu cầu service level agreement (SLA) dưới một giây mà độ trễ khởi động là không thể chấp nhận được.
- Phân tích tương tác (interactive analytics) nơi trải nghiệm người dùng phụ thuộc vào phản hồi tức thì.
- Các pipeline sản xuất tần suất cao chạy mỗi vài phút.
Trong hầu hết các trường hợp khác, capacity theo yêu cầu cung cấp sự cân bằng tốt nhất giữa chi phí, hiệu suất và khả năng phục hồi.
Ngoài việc tối ưu hóa việc sử dụng tài nguyên của ứng dụng, hãy xem xét cách bạn tổ chức chúng trên các workload của mình. Đối với các workload sản xuất, hãy sử dụng các ứng dụng riêng biệt cho các miền kinh doanh hoặc mức độ nhạy cảm dữ liệu khác nhau. Sự cô lập này cải thiện quản trị và ngăn chặn tranh chấp tài nguyên giữa các job quan trọng và không quan trọng.
2. Chọn Bộ xử lý AWS Graviton để có hiệu suất giá tốt hơn
Việc lựa chọn kiến trúc bộ xử lý cơ bản phù hợp có thể ảnh hưởng đáng kể đến cả hiệu suất và chi phí. Bộ xử lý ARM dựa trên Graviton mang lại cải thiện hiệu suất đáng kể so với x86_64.
EMR Serverless tự động cập nhật lên các thế hệ instance mới nhất khi chúng có sẵn, điều này có nghĩa là các ứng dụng của bạn được hưởng lợi từ những cải tiến phần cứng mới nhất mà không yêu cầu cấu hình bổ sung.
Để sử dụng Graviton với EMR Serverless, hãy chỉ định ARM64 với tham số architecture trong quá trình tạo ứng dụng bằng CreateApplication hoặc với UpdateApplication API cho các ứng dụng hiện có:
aws emr-serverless create-application \ --name my-spark-app \ --type SPARK \ --architecture ARM64 \ --release-label emr-7.12.0Những cân nhắc khi sử dụng Graviton:
- Khả năng sẵn có của tài nguyên – Đối với các workload quy mô lớn, hãy xem xét liên hệ với nhóm tài khoản AWS của bạn để thảo luận về kế hoạch capacity cho các worker Graviton.
- Khả năng tương thích – Mặc dù nhiều thư viện tiêu chuẩn và thường được sử dụng tương thích với kiến trúc Graviton (arm64), bạn sẽ cần xác thực rằng các gói và thư viện của bên thứ ba được sử dụng là tương thích.
- Kế hoạch di chuyển – Thực hiện một cách tiếp cận chiến lược để áp dụng Graviton. Xây dựng các ứng dụng mới trên kiến trúc ARM64 theo mặc định và di chuyển các workload hiện có thông qua một kế hoạch chuyển đổi theo từng giai đoạn để giảm thiểu sự gián đoạn. Cách tiếp cận có cấu trúc này sẽ giúp tối ưu hóa chi phí và hiệu suất mà không ảnh hưởng đến độ tin cậy.
- Thực hiện benchmark – Điều quan trọng cần lưu ý là hiệu suất giá chính xác sẽ khác nhau tùy theo workload. Chúng tôi khuyên bạn nên thực hiện các benchmark của riêng mình để đánh giá kết quả cụ thể cho workload của bạn. Để biết thêm chi tiết, hãy tham khảo bài viết Đạt được hiệu suất giá tốt hơn tới 27% cho các workload Spark với AWS Graviton2 trên Amazon EMR Serverless.
3. Sử dụng mặc định, điều chỉnh kích thước worker nếu cần
Worker được sử dụng để thực thi các tác vụ cho workload của bạn. Mặc dù các cài đặt mặc định của EMR Serverless được tối ưu hóa sẵn cho phần lớn các trường hợp sử dụng, bạn có thể cần điều chỉnh kích thước worker để cải thiện thời gian xử lý và tối ưu hóa hiệu quả chi phí. Khi gửi các job EMR Serverless, bạn nên định nghĩa các thuộc tính Spark để cấu hình worker, bao gồm kích thước bộ nhớ (tính bằng GB) và số lượng core.
EMR Serverless cấu hình kích thước worker mặc định là 4 vCPU, 16 GB bộ nhớ và 20 GB đĩa. Mặc dù điều này thường cung cấp một cấu hình cân bằng cho hầu hết các job, bạn có thể muốn điều chỉnh kích thước dựa trên yêu cầu hiệu suất của mình. Ngay cả khi cấu hình worker được khởi tạo trước với kích thước cụ thể, hãy luôn đặt các thuộc tính Spark của bạn khi gửi job. Điều này cho phép job của bạn sử dụng kích thước worker được chỉ định thay vì các thuộc tính mặc định khi nó mở rộng vượt quá capacity được khởi tạo trước. Khi điều chỉnh kích thước workload Spark của bạn, điều quan trọng là phải xác định tỷ lệ vCPU:memory cho job của bạn. Tỷ lệ này xác định lượng bộ nhớ bạn cấp phát cho mỗi core vCPU trong các executor của bạn. Các executor Spark cần cả CPU và bộ nhớ để xử lý dữ liệu hiệu quả, và tỷ lệ tối ưu thay đổi dựa trên đặc điểm workload của bạn.
Để bắt đầu, hãy sử dụng hướng dẫn sau, sau đó tinh chỉnh cấu hình của bạn dựa trên các yêu cầu workload cụ thể của bạn.
Cấu hình Executor
Bảng sau cung cấp các cấu hình executor được khuyến nghị dựa trên các mẫu workload phổ biến:
| Loại Workload | Tỷ lệ | CPU | Bộ nhớ | Cấu hình |
|---|---|---|---|---|
| Compute intensive | 1:2 | 16 vCPU | 32 GB | spark.emr-serverless.executor.cores=16spark.emr-serverless.executor.memory=32G |
| General purpose | 1:4 | 16 vCPU | 64 GB | spark.emr-serverless.executor.cores=16spark.emr-serverless.executor.memory=64G |
| Memory intensive | 1:8 | 16 vCPU | 108 GB | spark.emr-serverless.executor.cores=16spark.emr-serverless.executor.memory=108G |
Cấu hình Driver
Bảng sau cung cấp các cấu hình driver được khuyến nghị dựa trên các mẫu workload phổ biến:
| Loại Workload | Tỷ lệ | CPU | Bộ nhớ | Cấu hình |
|---|---|---|---|---|
| General purpose | 1:4 | 4 vCPU | 16 GB | spark.emr-serverless.driver.cores=4spark.emr-serverless.driver.memory=16G |
| Apache Iceberg workloads | 1:8(Large driver for metadata lookups) | 8 vCPU | 60 GB | spark.emr-serverless.driver.cores=8spark.emr-serverless.driver.memory=60G |
Để giám sát và tinh chỉnh cấu hình của bạn, hãy theo dõi mức tiêu thụ tài nguyên của workload bằng cách sử dụng các metric cấp worker của job Amazon CloudWatch để xác định các ràng buộc. Theo dõi các metric CPU utilization, memory usage và disk utilization, sau đó sử dụng bảng sau để tinh chỉnh cấu hình của bạn dựa trên các tắc nghẽn đã quan sát.
| | Metric đã quan sát | Loại Workload | Hành động đề xuất |
| : | :——————– | :—————- | :——————- |
| 1 | Bộ nhớ cao (>90%), CPU thấp (<50%) | Workload bị giới hạn bởi bộ nhớ | Tăng tỷ lệ vCPU:memory |
| 2 | CPU cao (>85%), bộ nhớ thấp (<60%) | Workload bị giới hạn bởi CPU | Tăng số lượng vCPU, duy trì tỷ lệ 1:4 (Ví dụ: nếu sử dụng 8 vCPU, sử dụng 32 GB bộ nhớ) |
| 3 | I/O lưu trữ cao, CPU hoặc bộ nhớ bình thường với các hoạt động shuffle kéo dài | Shuffle-intensive | Bật serverless storage hoặc shuffle-optimized disks |
| 4 | Sử dụng thấp trên các metric | Cấp phát quá mức | Giảm kích thước hoặc số lượng worker |
| 5 | Sử dụng cao liên tục (>90%) | Cấp phát thiếu | Mở rộng thông số kỹ thuật của worker |
| 6 | Tạm dừng GC thường xuyên | Áp lực bộ nhớ | Tăng overhead bộ nhớ (10 –15%) |
**Bạn có thể xác định các lần tạm dừng garbage collect (GC) thường xuyên bằng cách sử dụng Spark UI trong tab Executors. Sẽ có một cột GC time mà thường nên nhỏ hơn 10% thời gian tác vụ. Ngoài ra, các log driver có thể thường xuyên chứa các thông báo GC (Allocation Failure)].
4. Kiểm soát giới hạn mở rộng với T-shirt sizing
Theo mặc định, EMR Serverless sử dụng dynamic resource allocation (DRA), tự động mở rộng tài nguyên dựa trên nhu cầu workload. EMR Serverless liên tục đánh giá các metric từ job để tối ưu hóa chi phí và tốc độ, loại bỏ nhu cầu bạn phải ước tính chính xác số lượng worker cần thiết.
Để tối ưu hóa chi phí và hiệu suất có thể dự đoán được, bạn có thể cấu hình giới hạn mở rộng trên bằng một trong các cách tiếp cận sau:
- Đặt tham số spark.dynamicAllocation.maxExecutors ở cấp độ job.
- Đặt maximum capacity cấp ứng dụng.
Thay vì cố gắng tinh chỉnh spark.dynamicAllocation.maxExecutors thành một giá trị tùy ý cho mỗi job, bạn có thể nghĩ về việc đặt cấu hình này như các kích thước áo phông (t-shirt sizes) đại diện cho các hồ sơ workload khác nhau:
| Kích thước Workload | Trường hợp sử dụng | spark.dynamicAllocation.maxExecutors |
|---|---|---|
| Nhỏ | Truy vấn thăm dò, phát triển | 50 |
| Trung bình | Các job ETL thông thường, báo cáo | 200 |
| Lớn | Chuyển đổi phức tạp, xử lý quy mô lớn | 500 |
Cách tiếp cận t-shirt sizing này đơn giản hóa việc lập kế hoạch capacity và giúp bạn cân bằng hiệu suất với hiệu quả chi phí dựa trên danh mục workload của bạn, thay vì cố gắng tối ưu hóa từng job riêng lẻ.
Đối với các bản phát hành EMR Serverless 6.10 trở lên, giá trị mặc định cho spark.dynamicAllocation.maxExecutors là vô hạn, nhưng đối với các bản phát hành trước đó, nó là 100.
EMR Serverless tự động mở rộng worker lên hoặc xuống dựa trên workload và mức độ song song cần thiết ở mỗi giai đoạn của job. Việc mở rộng tự động này liên tục đánh giá các metric từ job để tối ưu hóa chi phí và tốc độ, loại bỏ nhu cầu bạn phải ước tính số lượng worker mà ứng dụng cần để chạy các workload của bạn.
Tuy nhiên, trong một số trường hợp, nếu bạn có một workload có thể dự đoán được, bạn có thể muốn đặt tĩnh số lượng executor. Để làm như vậy, bạn có thể tắt DRA và chỉ định số lượng executor theo cách thủ công:
spark.dynamicAllocation.=falsespark.executor.instances=105. Cung cấp lưu trữ phù hợp cho các job EMR Serverless
Hiểu rõ các tùy chọn lưu trữ của bạn và định kích thước chúng một cách thích hợp có thể ngăn ngừa lỗi job và tối ưu hóa thời gian thực thi. EMR Serverless cung cấp nhiều tùy chọn lưu trữ để xử lý dữ liệu trung gian trong quá trình thực thi job. Tùy chọn lưu trữ được chọn sẽ phụ thuộc vào bản phát hành EMR và trường hợp sử dụng. Các tùy chọn lưu trữ có sẵn trong EMR Serverless là:
| Loại lưu trữ | Bản phát hành EMR | Phạm vi kích thước đĩa | Trường hợp sử dụng | Lợi ích |
|---|---|---|---|---|
| Serverless Storage (khuyến nghị) | 7.12+ | N/A (tự động mở rộng) | Hầu hết các workload Spark, đặc biệt là các workload chuyên sâu về dữ liệu | * Không tốn chi phí lưu trữ * Tự động mở rộng * Giảm lỗi đĩa * Giảm chi phí tới 20% |
| Standard Disks | 7.11 trở xuống | 20–200 GB mỗi worker | Các workload nhỏ đến trung bình xử lý tập dữ liệu dưới 10 TB | * Cấu hình đơn giản * Mặc định 20 GB phù hợp với hầu hết các workload, * Tối đa 200 GB để đạt thông lượng tối ưu |
| Shuffle-Optimized Disks | 7.1.0+ | 20–2.000 GB mỗi worker | Các workload ETL quy mô lớn xử lý nhiều TB | * IOPS và thông lượng cao * Capacity lên tới 2 TB mỗi worker |
Bằng cách khớp cấu hình lưu trữ của bạn với các đặc điểm workload, bạn sẽ cho phép các job EMR Serverless chạy hiệu quả và đáng tin cậy ở quy mô lớn.
6. Multi-AZ sẵn có với khả năng phục hồi tích hợp
Các ứng dụng EMR Serverless là multi-AZ ngay từ đầu khi capacity được khởi tạo trước không được bật. Khả năng failover tích hợp này cung cấp khả năng phục hồi chống lại các gián đoạn Availability Zone mà không cần can thiệp thủ công. Một job duy nhất sẽ hoạt động trong một Availability Zone duy nhất để ngăn chặn chi phí truyền dữ liệu giữa các AZ và các job tiếp theo sẽ được phân phối thông minh trên nhiều AZ. Nếu EMR Serverless xác định rằng một AZ bị lỗi, nó sẽ gửi các job mới đến một AZ khỏe mạnh, cho phép các workload của bạn tiếp tục chạy mặc dù AZ bị lỗi.
Để hưởng lợi hoàn toàn từ chức năng multi-AZ của EMR Serverless, hãy xác minh những điều sau:
- Cấu hình kết nối mạng đến VPC của bạn với nhiều subnet trên các Availability Zone đã chọn.
- Tránh capacity được khởi tạo trước vì nó giới hạn các ứng dụng trong một AZ duy nhất.
- Đảm bảo có đủ địa chỉ IP có sẵn trong mỗi subnet để hỗ trợ việc mở rộng worker.
Ngoài multi-AZ, với Amazon EMR 7.1 trở lên, bạn có thể bật khả năng phục hồi job, cho phép các job của bạn tự động được thử lại trong trường hợp gặp lỗi. Nếu có nhiều Availability Zone được cấu hình, nó cũng sẽ được thử lại trong một AZ khác. Bạn có thể bật tính năng này cho cả job batch và streaming, mặc dù hành vi thử lại khác nhau giữa hai loại.
Cấu hình khả năng phục hồi job bằng cách chỉ định một chính sách thử lại (retry policy) định nghĩa số lần thử lại tối đa. Đối với các job batch, mặc định là không tự động thử lại (maxAttempts=1). Đối với các job streaming, EMR Serverless thử lại vô thời hạn với tính năng ngăn chặn lặp lại tích hợp (built-in thrash prevention) sẽ dừng thử lại sau năm lần thất bại trong vòng 1 giờ. Bạn có thể cấu hình ngưỡng này từ 1–10 lần thử. Để biết thêm thông tin, hãy tham khảo Job resiliency.
Trong trường hợp bạn cần hủy job của mình, bạn có thể chỉ định một thời gian ân hạn để cho phép các job của bạn tắt một cách sạch sẽ thay vì hành vi mặc định là chấm dứt ngay lập tức. Điều này cũng có thể bao gồm các hook tắt máy tùy chỉnh nếu bạn cần thực hiện các hành động dọn dẹp tùy chỉnh.
Bằng cách kết hợp hỗ trợ multi-AZ, tự động thử lại job và thời gian tắt máy ân hạn, bạn tạo ra một nền tảng mạnh mẽ cho các workload EMR Serverless có thể chịu đựng sự gián đoạn và duy trì tính toàn vẹn dữ liệu mà không cần can thiệp thủ công.
7. Bảo mật và mở rộng kết nối với tích hợp VPC
Theo mặc định, EMR Serverless có thể truy cập các dịch vụ AWS như Amazon Simple Storage Service (Amazon S3), AWS Glue, Amazon CloudWatch Logs, AWS Key Management Service (AWS KMS), AWS Security Token Service (AWS STS), Amazon DynamoDB, và AWS Secrets Manager. Nếu bạn muốn kết nối với các kho dữ liệu trong VPC của mình, chẳng hạn như Amazon Redshift hoặc Amazon Relational Database Service (Amazon RDS), bạn phải cấu hình quyền truy cập VPC cho ứng dụng EMR Serverless.
Khi cấu hình quyền truy cập VPC cho ứng dụng EMR Serverless của bạn, hãy ghi nhớ những cân nhắc chính sau để đạt được hiệu suất và hiệu quả chi phí tối ưu:
- Lập kế hoạch đủ địa chỉ IP – Mỗi worker sử dụng một địa chỉ IP trong một subnet. Điều này bao gồm các worker sẽ được khởi chạy khi job của bạn đang mở rộng. Nếu không có đủ địa chỉ IP, job của bạn có thể không thể mở rộng, điều này có thể dẫn đến lỗi job. Xác minh bạn đã tuân thủ các phương pháp hay nhất để lập kế hoạch subnet để đạt hiệu suất tối ưu.
- Thiết lập Gateway endpoints cho Amazon S3 cho các ứng dụng trong các subnet riêng tư – Chạy EMR Serverless trong một subnet riêng tư mà không có VPC endpoint cho Amazon S3 sẽ định tuyến lưu lượng Amazon S3 của bạn qua NAT Gateway, dẫn đến các khoản phí truyền dữ liệu bổ sung. VPC endpoint cho S3 sẽ giữ lưu lượng này trong VPC của bạn, giảm chi phí và cải thiện hiệu suất cho các hoạt động Amazon S3.
- Quản lý chi phí AWS Config cho các network interface – EMR Serverless tạo một bản ghi network interface đàn hồi trong AWS Config cho mỗi worker, điều này có thể tích lũy chi phí khi các workload của bạn mở rộng. Nếu bạn không yêu cầu theo dõi AWS Config cho các network interface của EMR Serverless, hãy xem xét sử dụng các loại trừ dựa trên tài nguyên hoặc các chiến lược gắn thẻ để lọc chúng ra trong khi vẫn duy trì phạm vi phủ sóng của AWS Config cho các tài nguyên khác.
Để biết thêm chi tiết, hãy tham khảo Cấu hình quyền truy cập VPC cho các ứng dụng EMR Serverless.
8. Đơn giản hóa việc gửi job và quản lý dependency
EMR Serverless hỗ trợ gửi job linh hoạt thông qua StartJobRun API, chấp nhận cú pháp spark-submit đầy đủ. Để cấu hình môi trường runtime, hãy sử dụng các tiền tố spark.emr-serverless.driverEnv và spark.executorEnv để đặt các biến môi trường cho các tiến trình driver và executor. Điều này đặc biệt hữu ích để truyền cấu hình nhạy cảm hoặc cài đặt cụ thể cho runtime.
Đối với các ứng dụng Python, hãy đóng gói các dependency bằng cách sử dụng môi trường ảo (virtual environments) bằng cách tạo một venv, đóng gói nó dưới dạng kho lưu trữ tar.gz hoặc tải lên Amazon S3 bằng cách sử dụng spark.archives với biến môi trường PYSPARK_PYTHON thích hợp. Điều này cho phép các dependency Python có sẵn trên các worker driver và executor.
Để kiểm soát tốt hơn dưới tải cao, hãy bật job concurrency và queuing (có sẵn trong EMR 7.0.0+) để giới hạn số lượng job có thể được thực thi đồng thời. Với tính năng này, các job được gửi vượt quá giới hạn concurrency sẽ được xếp hàng đợi cho đến khi tài nguyên có sẵn.
Bạn có thể cấu hình cài đặt Job concurrency và queue bằng cách sử dụng thuộc tính SchedulerConfiguration bằng cách sử dụng CreateApplication hoặc UpdateApplication API.
--scheduler-configuration '{"maxConcurrentRuns": 5, "queueTimeoutMinutes": 30}'
9. Sử dụng cấu hình EMR Serverless để thực thi giới hạn
EMR Serverless tự động mở rộng tài nguyên dựa trên nhu cầu workload, cung cấp các giá trị mặc định được tối ưu hóa hoạt động tốt cho hầu hết các trường hợp sử dụng mà không yêu cầu tinh chỉnh cấu hình Spark. Để quản lý chi phí hiệu quả, bạn có thể cấu hình giới hạn tài nguyên phù hợp với ngân sách và yêu cầu hiệu suất của mình. Đối với các trường hợp sử dụng nâng cao, EMR Serverless cũng cung cấp các tùy chọn cấu hình để bạn có thể tinh chỉnh mức tiêu thụ tài nguyên và đạt được hiệu quả tương tự như các triển khai dựa trên cluster. Hiểu rõ các giới hạn này giúp bạn cân bằng hiệu suất với hiệu quả chi phí cho các job của mình.
| Loại giới hạn | Mục đích | Cách cấu hình |
|---|---|---|
| Cấp độ job | Kiểm soát tài nguyên cho các job riêng lẻ | spark.dynamicAllocation.maxExecutors hoặc spark.executor.instances |
| Cấp độ ứng dụng | Giới hạn tài nguyên cho mỗi ứng dụng hoặc miền kinh doanh | Đặt maximum capacity khi tạo ứng dụng hoặc khi cập nhật. |
| Cấp độ tài khoản | Ngăn chặn các đột biến tài nguyên bất thường trên tất cả các ứng dụng | Auto-adjustable service quota Max concurrent vCPUs per account; yêu cầu tăng thông qua Service Quotas console |
Ba lớp giới hạn này hoạt động cùng nhau để cung cấp quản lý tài nguyên linh hoạt ở các phạm vi khác nhau. Đối với hầu hết các trường hợp sử dụng, việc cấu hình giới hạn cấp độ job bằng cách tiếp cận t-shirt sizing là đủ, trong khi giới hạn cấp độ ứng dụng và tài khoản cung cấp các rào cản bổ sung để kiểm soát chi phí.
10. Giám sát với CloudWatch, Prometheus và Grafana
Giám sát các workload EMR Serverless đơn giản hóa quá trình gỡ lỗi, thực hiện tối ưu hóa chi phí và theo dõi hiệu suất. EMR Serverless cung cấp ba cấp độ giám sát hoạt động cùng nhau: Amazon CloudWatch, Amazon Managed Service for Prometheus và Amazon Managed Grafana.
- Amazon CloudWatch – Tích hợp CloudWatch được bật theo mặc định và xuất bản các metric vào namespace AWS/EMRServerless. EMR Serverless gửi các metric đến CloudWatch mỗi phút ở cấp độ ứng dụng, cũng như cấp độ job, loại worker và loại phân bổ capacity. Sử dụng CloudWatch, bạn có thể cấu hình dashboard để tăng cường khả năng quan sát vào các workload hoặc cấu hình alarm để cảnh báo về lỗi job, bất thường về mở rộng và vi phạm SLA. Sử dụng CloudWatch với EMR Serverless cung cấp thông tin chi tiết về các workload của bạn để bạn có thể phát hiện các vấn đề trước khi chúng ảnh hưởng đến người dùng.
- Amazon Managed Service for Prometheus – Với bản phát hành EMR Serverless 7.1+, bạn có thể bật Prometheus để có các metric engine Spark chi tiết để đẩy các metric đến Amazon Managed Service for Prometheus. Điều này mở khóa khả năng hiển thị cấp độ executor, bao gồm mức sử dụng bộ nhớ, khối lượng shuffle và áp lực GC. Bạn có thể sử dụng điều này để xác định các executor bị giới hạn bộ nhớ, phát hiện các giai đoạn chuyên sâu về shuffle và tìm độ lệch dữ liệu.
- Amazon Managed Grafana – Grafana kết nối với cả nguồn dữ liệu CloudWatch và Prometheus, cung cấp một giao diện duy nhất để quan sát thống nhất và phân tích tương quan. Cách tiếp cận phân lớp này giúp bạn tương quan các vấn đề về cơ sở hạ tầng với các vấn đề về hiệu suất cấp ứng dụng.
Các metric chính cần theo dõi:
- Thời gian hoàn thành job và tỷ lệ thành công
- Mức sử dụng worker và các sự kiện mở rộng
- Khối lượng đọc/ghi shuffle
- Các mẫu sử dụng bộ nhớ
Để biết thêm chi tiết, hãy tham khảo Giám sát các worker Amazon EMR Serverless trong thời gian gần thực bằng Amazon CloudWatch.
Kết luận
Trong bài viết này, chúng tôi đã chia sẻ 10 phương pháp hay nhất để giúp bạn tối đa hóa giá trị của Amazon EMR Serverless bằng cách tối ưu hóa hiệu suất, kiểm soát chi phí và duy trì các hoạt động đáng tin cậy ở quy mô lớn. Bằng cách tập trung vào thiết kế ứng dụng, các workload có kích thước phù hợp và các lựa chọn kiến trúc, bạn có thể xây dựng các pipeline xử lý dữ liệu vừa hiệu quả vừa có khả năng phục hồi.
Để tìm hiểu thêm, hãy tham khảo hướng dẫn Bắt đầu với EMR Serverless.
Về tác giả

Karthik Prabhakar
Karthik là Kiến trúc sư Công cụ Xử lý Dữ liệu cho Amazon EMR tại Amazon Web Services (AWS). Anh chuyên về kiến trúc hệ thống phân tán và tối ưu hóa truy vấn, làm việc với khách hàng để giải quyết các thách thức hiệu suất phức tạp trong các workload xử lý dữ liệu quy mô lớn. Trọng tâm của anh bao gồm các chi tiết nội bộ của engine, các chiến lược tối ưu hóa chi phí và các mẫu kiến trúc cho phép khách hàng chạy phân tích quy mô petabyte một cách hiệu quả.

Neil Mukerje
Neil là Giám đốc Sản phẩm chính tại Amazon Web Services.

Amber Runnels
Amber là Kiến trúc sư Giải pháp Chuyên gia Phân tích cấp cao tại Amazon Web Services (AWS), chuyên về dữ liệu lớn và hệ thống phân tán. Cô giúp khách hàng tối ưu hóa các workload trong các dịch vụ dữ liệu của AWS để đạt được kiến trúc có khả năng mở rộng, hiệu suất cao và tiết kiệm chi phí. Ngoài công nghệ, cô còn đam mê khám phá nhiều địa điểm và nền văn hóa mà thế giới này mang lại, đọc tiểu thuyết và xây dựng terrarium.

Parul Saxena
Parul là Kiến trúc sư Giải pháp Chuyên gia Dữ liệu lớn cấp cao tại Amazon Web Services (AWS). Cô giúp khách hàng và đối tác xây dựng các giải pháp được tối ưu hóa cao, có khả năng mở rộng và bảo mật. Cô chuyên về Amazon EMR, Amazon Athena và AWS Lake Formation, cung cấp hướng dẫn kiến trúc cho các workload dữ liệu lớn phức tạp và hỗ trợ các tổ chức hiện đại hóa kiến trúc của họ và di chuyển các workload phân tích sang AWS.
