Tác giả: Arun A K, Annie Wang, và Roshin Babu
Ngày phát hành: 26 JAN 2026
Chuyên mục: Analytics, AWS Glue, Intermediate (200), Technical How-to
Các tổ chức ngày càng phụ thuộc vào dữ liệu đáng tin cậy, chất lượng cao để thúc đẩy phân tích, báo cáo quy định và ra quyết định vận hành. Khi các vấn đề về chất lượng dữ liệu không được phát hiện, chúng có thể dẫn đến những hiểu biết không chính xác, các sáng kiến bị đình trệ và khoảng trống tuân thủ ảnh hưởng trực tiếp đến kết quả kinh doanh. Khi khối lượng dữ liệu tăng lên và các pipeline trở nên phân tán hơn, việc duy trì chất lượng dữ liệu nhất quán giữa các nhóm và miền dữ liệu ngày càng trở nên thách thức.
Bạn có thể giải quyết những thách thức này với AWS Glue Data Quality bằng cách cung cấp xác thực dữ liệu tự động, dựa trên quy tắc trên các tập dữ liệu trong AWS Glue Data Catalog và trong các pipeline AWS Glue ETL. Với Data Quality Definition Language (DQDL), bạn có thể tạo các quy tắc xác thực từ đơn giản đến nâng cao để phát hiện các vấn đề về chất lượng dữ liệu sớm trong vòng đời, trước khi chúng đến các ứng dụng hoặc môi trường phân tích hạ nguồn.
Trong bài viết này, chúng tôi nêu bật tính năng nhãn DQDL mới, giúp nâng cao cách bạn tổ chức, ưu tiên và vận hành các nỗ lực chất lượng dữ liệu ở quy mô lớn. Chúng tôi chỉ ra cách các nhãn như mức độ quan trọng của nghiệp vụ, yêu cầu tuân thủ, quyền sở hữu của nhóm hoặc miền dữ liệu có thể được gắn vào các quy tắc chất lượng dữ liệu để hợp lý hóa việc phân loại và phân tích. Bạn sẽ học cách nhanh chóng đưa ra các thông tin chi tiết có mục tiêu (ví dụ: “tất cả các lỗi dữ liệu khách hàng ưu tiên cao thuộc sở hữu của bộ phận marketing” hoặc “các vấn đề liên quan đến GDPR từ pipeline nhập dữ liệu Salesforce của chúng tôi”) và cách các nhãn DQDL có thể giúp các nhóm cải thiện trách nhiệm giải trình và tăng tốc quy trình khắc phục.
Quản lý các quy tắc chất lượng dữ liệu phức tạp trên các nhóm và trường hợp sử dụng
Khi các tổ chức phát triển trong các chương trình chất lượng dữ liệu của mình, một vài quy tắc thường phát triển thành hàng trăm hoặc hàng nghìn quy tắc được duy trì trên nhiều nhóm và miền kinh doanh. Lấy ví dụ về AnyCompany, một tổ chức bán lẻ lớn với nhiều nhóm dữ liệu quản lý dữ liệu khách hàng, sản phẩm và bán hàng trên các đơn vị kinh doanh khác nhau. Các nhóm này chạy nhiều quy tắc chất lượng dữ liệu khác nhau, bao gồm kiểm tra khách hàng hàng tuần, xác thực sản phẩm hàng ngày, kiểm tra bán hàng thường xuyên và đánh giá tuân thủ hàng tháng, với các mẫu đặt tên, lịch trình và quy trình phản hồi khác nhau. Điều này tạo ra một hệ thống phân mảnh, khó điều hướng, nơi các nhóm hoạt động biệt lập và các thực hành chất lượng dữ liệu trở nên không nhất quán.
Thách thức nằm ở khối lượng quy tắc và việc thiếu ngữ cảnh tổ chức xung quanh chúng. Khi hàng chục quy tắc chất lượng dữ liệu vượt qua hoặc thất bại, các nhóm vẫn thiếu sự rõ ràng về quyền sở hữu, mức độ khẩn cấp hoặc tác động kinh doanh. Điều này làm chậm phản ứng sự cố, hạn chế thông tin chi tiết của ban điều hành và làm phức tạp việc lập kế hoạch tài nguyên. Để chuyển từ giám sát kỹ thuật sang giá trị chiến lược, các tổ chức cần một cấu trúc thống nhất kết nối các quy tắc chất lượng dữ liệu với các nhóm, miền và ưu tiên, mang lại ngữ cảnh kinh doanh thiết yếu cho các hoạt động chất lượng dữ liệu.
Tổ chức quy tắc dựa trên siêu dữ liệu
Nhãn AWS Glue DQDL giải quyết các thách thức về tổ chức vì bạn có thể gắn siêu dữ liệu tùy chỉnh vào các quy tắc chất lượng dữ liệu, biến các xác thực ẩn danh thành các kiểm tra giàu ngữ cảnh, nhận biết nghiệp vụ. Nhãn hoạt động như các cặp khóa-giá trị được gắn vào các quy tắc riêng lẻ hoặc toàn bộ bộ quy tắc, và bạn có thể tổ chức các hoạt động chất lượng xung quanh các chiều kinh doanh như quyền sở hữu của nhóm, mức độ quan trọng, tần suất và yêu cầu quy định, như trong trường hợp ví dụ AnyCompany. Khi một quy tắc thất bại, bạn ngay lập tức xác định điều gì đã thất bại, ai nên phản hồi, mức độ khẩn cấp của nó và khu vực kinh doanh nào bị ảnh hưởng, cho dù đó là bộ phận marketing theo dõi sự hoàn chỉnh của email với các thẻ tần suất hàng ngày, các nhóm tuân thủ giám sát xác minh tuổi với các nhãn quy định, hay nhóm tài chính xác thực dữ liệu thanh toán với các dấu hiệu mức độ quan trọng cao.
Nhãn tích hợp với cú pháp DQDL hiện có mà không yêu cầu thay đổi đối với các định nghĩa quy tắc hiện tại, hoạt động nhất quán trên các ngữ cảnh thực thi AWS Glue Data Quality. Tính linh hoạt của tính năng này hỗ trợ các phân loại tổ chức từ trung tâm chi phí và khu vực địa lý đến mức độ nhạy cảm của dữ liệu và yêu cầu thỏa thuận mức dịch vụ (SLA) với các quy tắc đơn lẻ mang nhiều nhãn đồng thời để lọc và phân tích tinh vi. Nhãn xuất hiện trong các đầu ra, bao gồm kết quả quy tắc, kết quả cấp hàng và phản hồi API, vì vậy ngữ cảnh tổ chức đi kèm với kết quả chất lượng cho dù bạn đang khắc phục sự cố lỗi, phân tích xu hướng trong Amazon Athena hay xây dựng bảng điều khiển điều hành trong Amazon QuickSight.
Bắt đầu: Viết các quy tắc chất lượng dữ liệu được gắn nhãn đầu tiên của bạn
Hãy cùng tìm hiểu cách tạo các quy tắc chất lượng dữ liệu được gắn nhãn đầu tiên của bạn bằng cách sử dụng kịch bản dữ liệu khách hàng của AnyCompany. Chúng ta sẽ sử dụng tập dữ liệu nhân khẩu học khách hàng của họ, chứa thông tin khách hàng mà nhiều nhóm cần xác thực với các ưu tiên và tần suất khác nhau.
Nhãn DQDL tuân theo cú pháp cặp khóa-giá trị đơn giản tích hợp tự nhiên với các định nghĩa quy tắc hiện có. Cú pháp cơ bản hỗ trợ hai cách tiếp cận: nhãn mặc định áp dụng cho các quy tắc trong một bộ quy tắc và nhãn cụ thể theo quy tắc áp dụng cho các quy tắc riêng lẻ. Nhãn cụ thể theo quy tắc có thể ghi đè nhãn mặc định khi sử dụng cùng một khóa, cung cấp quyền kiểm soát chi tiết đối với chiến lược gắn nhãn của bạn.
Khi triển khai nhãn DQDL, hãy ghi nhớ các ràng buộc sau:
- Tối đa 10 nhãn cho mỗi quy tắc
- Khóa nhãn giới hạn 128 ký tự và không được để trống
- Giá trị nhãn giới hạn 256 ký tự và không được để trống
- Cả khóa và giá trị đều phân biệt chữ hoa chữ thường
- Nhãn cụ thể theo quy tắc ghi đè nhãn mặc định khi sử dụng cùng một khóa
Sử dụng cách tiếp cận gắn nhãn này, bạn có thể tổ chức và quản lý các quy tắc chất lượng dữ liệu một cách hiệu quả trên các nhóm và yêu cầu xác thực khác nhau.
Các phương pháp hay nhất cho quy ước đặt tên nhãn
Dưới đây là một số chiến lược gắn nhãn đã được chứng minh có thể mở rộng trên các môi trường doanh nghiệp:
- Thiết lập một phân loại tiêu chuẩn hóa hoàn chỉnh ngay từ đầu – Định nghĩa các khóa nhãn trong
DefaultLabelsvới các giá trị mặc định hợp lý nhưregulation=nonehoặcsla=24hđể cung cấp các quy tắc với các khóa giống hệt nhau cho các truy vấn liên nhóm. - Sử dụng các mẫu đặt tên khóa nhất quán – Thiết lập các khóa tiêu chuẩn như
team,criticality,sla,impact, vàregulationtrên các bộ quy tắc để duy trì tính nhất quán của truy vấn. - Triển khai các giá trị phân cấp – Sử dụng các định dạng như
team=marketing-analyticsđể hỗ trợ cả lọc rộng và cụ thể trong khi vẫn giữ cấu trúc khóa nhất quán. - Bao gồm siêu dữ liệu vận hành trong các giá trị mặc định – Định nghĩa các nhãn như
sla,escalation-level, hoặcnotification-channellàm mặc định để thúc đẩy các quy trình phản hồi tự động. - Lập kế hoạch cho các chiều báo cáo – Bao gồm các khóa như
cost-center,region, hoặcbusiness-unittrong phân loại mặc định của bạn để hỗ trợ phân tích kinh doanh có ý nghĩa. - Sử dụng các mẫu giá trị tiêu chuẩn hóa – Thiết lập các định dạng nhất quán như
criticality=high/medium/lowhoặcsla=15m/1h/1dđể lọc và sắp xếp có thể dự đoán được.
Đây là những hướng dẫn chứ không phải yêu cầu nhưng việc tuân thủ chúng ngay từ đầu sẽ cho phép phân tích liên nhóm mạnh mẽ và giảm nỗ lực tái cấu trúc trong tương lai.
Ví dụ thực hành xác thực dữ liệu khách hàng
Bài viết này giả định bạn đã quen thuộc với các hoạt động AWS Glue Data Quality và ETL. Sử dụng hướng dẫn thực hành sau đây, bạn sẽ học cách triển khai nhãn DQDL để quản lý chất lượng dữ liệu tổ chức.
Bắt đầu bằng cách thiết lập các nhãn mặc định tự động áp dụng cho mọi quy tắc trong bộ quy tắc, cung cấp ngữ cảnh tổ chức nhất quán:
DefaultLabels = ["team"="data-team", "criticality"="medium", "regulation"="none", "sla"="24h", "impact"="medium"]DefaultLabels cung cấp một phân loại nền tảng tự động lan truyền trên toàn bộ bộ quy tắc của bạn, tạo sự đồng nhất và giảm chi phí cấu hình. Bằng cách định nghĩa các giá trị mặc định ở cấp độ tổ chức, chẳng hạn như team=data-team, criticality=medium, regulation=none, sla=24h, và impact=medium, mọi quy tắc đều kế thừa các thuộc tính tiêu chuẩn hóa này mà không yêu cầu khai báo rõ ràng. Mô hình kế thừa này thúc đẩy tính nhất quán trong khi vẫn duy trì sự linh hoạt mà các nhóm cá nhân cần để giải quyết các ngữ cảnh vận hành độc đáo của họ.
Các nhóm cá nhân có thể chọn ghi đè các giá trị mặc định được kế thừa để phản ánh các yêu cầu cụ thể của họ. Ví dụ, hãy xem xét bộ quy tắc hoàn chỉnh sau:
DefaultLabels = ["team"="data-team", "criticality"="medium", "regulation"="none", "sla"="24h", "impact"="medium"]Rules = [ IsComplete "c_customer_id" labels=["team"="analytics", "criticality"="high", "sla"="15m", "impact"="high"], ColumnValues "c_customer_id" matches "e.*" labels=["team"="analytics", "criticality"="medium", "impact"="low"], ColumnLength "c_city" > 6 labels=["team"="marketing", "criticality"="medium", "sla"="4h", "impact"="medium"], IsComplete "c_name" labels=["team"="marketing", "sla"="4h"], ColumnValues "c_age" >= 21 labels=["team"="compliance", "criticality"="high", "regulation"="age21", "impact"="high"] with threshold > 0.99, IsComplete "c_birth_date" labels=["team"="compliance", "criticality"="medium", "regulation"="gdpr", "impact"="medium"], IsComplete "c_creditissuer" labels=["team"="finance", "impact"="high"], ColumnValues "c_creditcardnumber" > 100000000000 labels=["team"="finance", "criticality"="high", "regulation"="payment", "impact"="high"] with threshold > 0.95]Lưu ý cách nhóm tuân thủ thay đổi quy định từ 'none' thành 'age21' cho các quy tắc xác minh tuổi và nhóm phân tích nâng mức độ quan trọng lên 'high' cho các kiểm tra quan trọng đối với nghiệp vụ. Các nhãn không được chỉ định tự động kế thừa các giá trị mặc định, cung cấp tính nhất quán trong khi vẫn duy trì sự linh hoạt ở cấp độ nhóm.
Áp dụng các quy tắc được gắn nhãn vào tập dữ liệu
Bây giờ, hãy xem các nhãn DQDL hoạt động bằng cách áp dụng bộ quy tắc của AnyCompany vào dữ liệu thực tế thông qua một pipeline AWS Glue ETL. Phần này giả định bạn đã quen thuộc với AWS Glue EvaluateDataQuality transform và việc tạo job extract, transform, and load (ETL) cơ bản.
Chúng ta sử dụng transform AWS Glue EvaluateDataQuality trong một job ETL để xử lý tập dữ liệu khách hàng của chúng ta và áp dụng bộ quy tắc được gắn nhãn của chúng ta. Transform này tạo ra hai loại đầu ra: kết quả cấp quy tắc hiển thị quy tắc nào đã vượt qua hoặc thất bại với các nhãn liên quan và kết quả cấp hàng xác định các bản ghi cụ thể và các quy tắc được gắn nhãn mà chúng đã vi phạm.
Theo mặc định, nhãn bị loại trừ khỏi kết quả cấp hàng. Tuy nhiên, bằng cách bật chúng, bạn có thể phân tích kết quả chất lượng dữ liệu ở cả cấp độ bản ghi riêng lẻ và trên các chiều tổ chức như nhóm và mức độ quan trọng.
Để bật nhãn trong kết quả cấp hàng, bạn phải cấu hình tham số additionalOptions trong transform EvaluateDataQuality của mình. Cài đặt khóa là "rowLevelConfiguration.ruleWithLabels":"ENABLED", hướng dẫn AWS Glue bao gồm siêu dữ liệu nhãn cho mỗi đánh giá quy tắc ở cấp độ bản ghi riêng lẻ.
Dưới đây là cách triển khai một pipeline ETL áp dụng bộ quy tắc của AnyCompany với các nhãn được bật:
import sysfrom awsglue.transforms import *from awsglue.utils import getResolvedOptionsfrom pyspark.context import SparkContextfrom awsglue.context import GlueContextfrom awsglue.job import Jobfrom awsgluedq.transforms import EvaluateDataQualityfrom awsglue.dynamicframe import DynamicFrameimport boto3def create_table(athena,s3_bucket,df,db_name,table_name): ddl = spark.sparkContext._jvm.org.apache.spark.sql.types.DataType.fromJson(df.schema.json()).toDDL() ddl_stmt_string=f"""CREATE EXTERNAL TABLE IF NOT EXISTS {db_name}.{table_name} ({str(ddl)}) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 's3://{s3_bucket}/label/{table_name}/'""" athena.start_query_execution(QueryString=ddl_stmt_string,ResultConfiguration={'OutputLocation': f"s3://{s3_bucket}/athena_results/"})args = getResolvedOptions(sys.argv, ['JOB_NAME'])sc = SparkContext()glueContext = GlueContext(sc)spark = glueContext.spark_sessionjob = Job(glueContext)job.init(args['JOB_NAME'], args)rules="""DefaultLabels = ["team"="data-team", "criticality"="medium", "regulation"="none", "sla"="24h", "impact"="medium"] Rules = [ IsComplete "c_customer_id" labels=["team"="analytics", "criticality"="high", "sla"="15m", "impact"="high"], ColumnValues "c_customer_id" matches "e.*" labels=["team"="analytics", "criticality"="medium", "impact"="low"], ColumnLength "c_city" > 6 labels=["team"="marketing", "criticality"="medium", "sla"="4h", "impact"="medium"], IsComplete "c_name" labels=["team"="marketing", "sla"="4h"], ColumnValues "c_age" >= 21 labels=["team"="compliance", "criticality"="high", "regulation"="age21", "impact"="high"] with threshold > 0.99, IsComplete "c_birth_date" labels=["team"="compliance", "criticality"="medium", "regulation"="gdpr", "impact"="medium"], IsComplete "c_creditissuer" labels=["team"="finance", "impact"="high"], ColumnValues "c_creditcardnumber" > 100000000000 labels=["team"="finance", "criticality"="high", "regulation"="payment", "impact"="high"] with threshold > 0.95 ]"""s3_bucket="REPLACE"row_level_table="dqrowlevel"rule_level_table="dqrulelevel"db_name="default"additional_options={}additional_options["observations.scope"]="ALL"additional_options["performanceTuning.caching"]="CACHE_INPUT"additional_options["rowLevelConfiguration.ruleWithLabels"]="ENABLED"df = spark.read.option("header", "true").option("inferSchema", "true").csv("s3://aws-data-analytics-workshops/aws_glue/aws_glue_data_quality/data/customers/")anycompany_customers=DynamicFrame.fromDF(df, glueContext, "anycompany_customers")dq_check = EvaluateDataQuality().process_rows(frame=anycompany_customers, ruleset=rules, publishing_options={"dataQualityEvaluationContext": "dq_check","enableDataQualityCloudWatchMetrics": True, "enableDataQualityResultsPublishing": True}, additional_options=additional_options)rowlevel = SelectFromCollection.apply(dfc=dq_check, key="rowLevelOutcomes", transformation_ctx="rowlevel")rulelevel = SelectFromCollection.apply(dfc=dq_check, key="ruleOutcomes", transformation_ctx="rulelevel")rowlevel_df=rowlevel.toDF()rulelevel_df=rulelevel.toDF()rowlevel_df.write.mode("overwrite").parquet(f"s3://{s3_bucket}/label/{row_level_table}/")rulelevel_df.write.mode("overwrite").parquet(f"s3://{s3_bucket}/label/{rule_level_table}/")athena = boto3.client('athena')create_table(athena,s3_bucket,rowlevel_df,db_name,row_level_table)create_table(athena,s3_bucket,rulelevel_df,db_name,rule_level_table)job.commit()Để chạy ví dụ này, hãy cập nhật biến s3_bucket với tên bucket Amazon Simple Storage Service (Amazon S3) của riêng bạn, sau đó tạo và thực thi job ETL trong AWS Glue.
Sau khi job hoàn thành, bạn sẽ tìm thấy:
- Kết quả cấp quy tắc và cấp hàng được lưu trữ trong bucket S3 của bạn
- Hai bảng mới tự động được tạo trong cơ sở dữ liệu mặc định của bạn:
dqrulelevelvàdqrowlevel
Trong phần tiếp theo, chúng ta sẽ truy vấn các bảng này bằng Amazon Athena để phân tích kết quả chất lượng dữ liệu được gắn nhãn và trích xuất thông tin chi tiết có thể hành động.
Phân tích kết quả chất lượng dữ liệu theo nhãn bằng Amazon Athena
Chúng ta đã lưu trữ kết quả chất lượng dữ liệu được gắn nhãn trong Amazon S3 và dưới dạng bảng trong danh mục dữ liệu AWS Glue. Bây giờ, chúng ta có thể sử dụng Amazon Athena để phân tích các kết quả này trên các chiều tổ chức được ghi lại trong các nhãn của bạn. Siêu dữ liệu được gắn nhãn biến đổi kết quả chất lượng dữ liệu thô thành thông tin kinh doanh có thể hành động, thúc đẩy khắc phục có mục tiêu và ra quyết định chiến lược.
Truy vấn kết quả cấp hàng
Với các nhãn được lưu trữ cùng với kết quả cấp hàng, bạn có thể truy vấn các bản ghi cụ thể đã không vượt qua kiểm tra chất lượng dữ liệu dựa trên tiêu chí nhãn. Ví dụ, truy vấn sau xác định các bản ghi khách hàng riêng lẻ đã không vượt qua các quy tắc tuân thủ có mức độ quan trọng cao. Bạn có thể sử dụng nó để nhanh chóng định vị và khắc phục dữ liệu có vấn đề cho các trường hợp sử dụng quy định hoặc quan trọng đối với nghiệp vụ:
SELECTc_customer_id,c_age,failed_ruleFROM (SELECT *FROM dqrowlevelWHERE dataqualityevaluationresult = 'Failed')CROSS JOIN UNNEST(dataqualityrulesfail) AS t(failed_rule)WHERE failed_rule LIKE '%criticality"="high"%'AND failed_rule LIKE '%team"="compliance"%'LIMIT 5;
Kết quả truy vấn các bản ghi bị lỗi được lọc theo nhãn ‘high’ criticality và ‘compliance’ team.
Truy vấn kết quả cấp quy tắc
Bây giờ chúng ta đã lưu trữ kết quả cấp quy tắc với các nhãn, chúng ta có thể chạy các truy vấn tổng hợp để phân tích các lỗi trên các chiều khác nhau. Ví dụ, truy vấn sau nhóm các quy tắc bị lỗi theo mức độ quan trọng và nhóm để xác định nhóm nào có nhiều lỗi nghiêm trọng nhất. Bạn có thể sử dụng nó để ưu tiên các nỗ lực khắc phục và phân bổ tài nguyên một cách hiệu quả:
SELECTc_customer_id,c_age,failed_ruleFROM (SELECT *FROM dqrowlevelWHERE dataqualityevaluationresult = 'Failed')CROSS JOIN UNNEST(dataqualityrulesfail) AS t(failed_rule)WHERE failed_rule LIKE '%criticality"="high"%'AND failed_rule LIKE '%team"="compliance"%'LIMIT 5;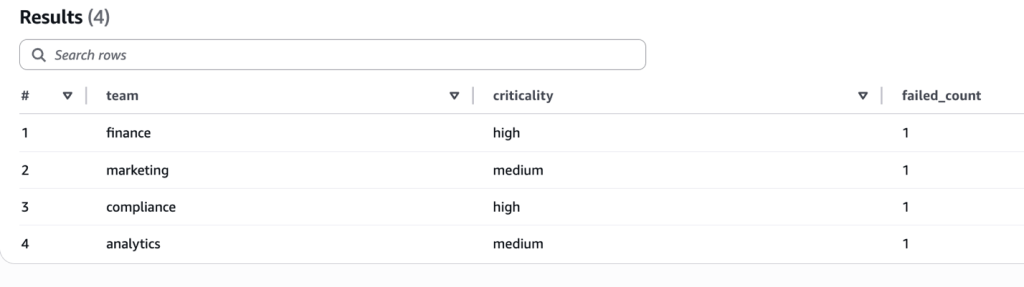
Số lượng lỗi tổng hợp được nhóm theo nhóm và mức độ quan trọng.
Xem kết quả chất lượng dữ liệu bằng AWS CLI
Ngoài việc truy vấn kết quả trong Athena, bạn cũng có thể truy xuất kết quả chất lượng dữ liệu trực tiếp bằng AWS Command Line Interface (AWS CLI). Điều này hữu ích cho tự động hóa, scripting và tích hợp kiểm tra chất lượng dữ liệu vào các pipeline tích hợp liên tục và phân phối liên tục (CI/CD).
Để liệt kê kết quả chất lượng dữ liệu cho job ETL của bạn, hãy nhập lệnh sau:
aws glue list-data-quality-results --filter '{"JobName":"<your-job-name>"}'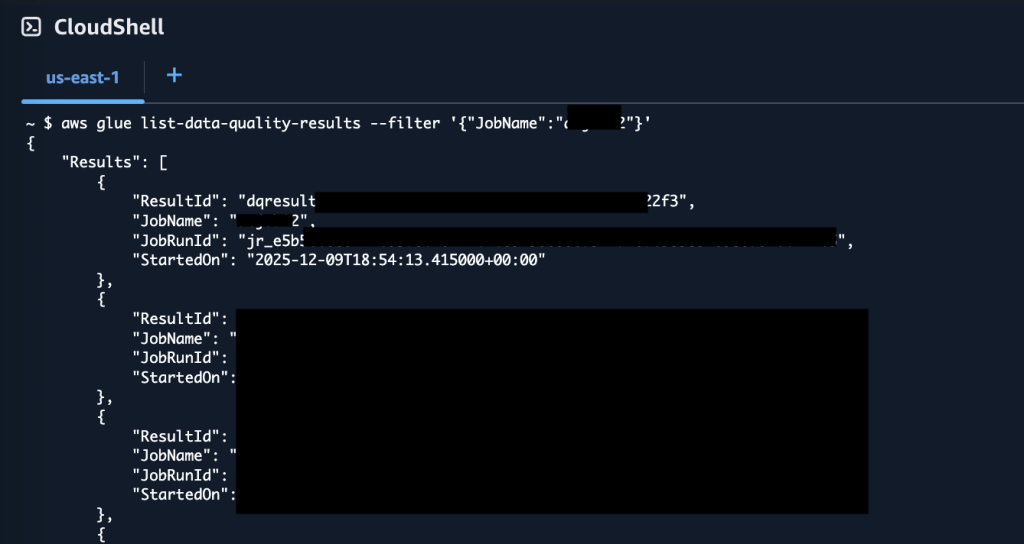
JSON kết quả bao gồm một ResultId cho mỗi lần chạy kiểm tra chất lượng dữ liệu.
Để truy xuất chi tiết của một kết quả cụ thể, hãy nhập lệnh sau:
aws glue get-data-quality-result --result-id <result-id>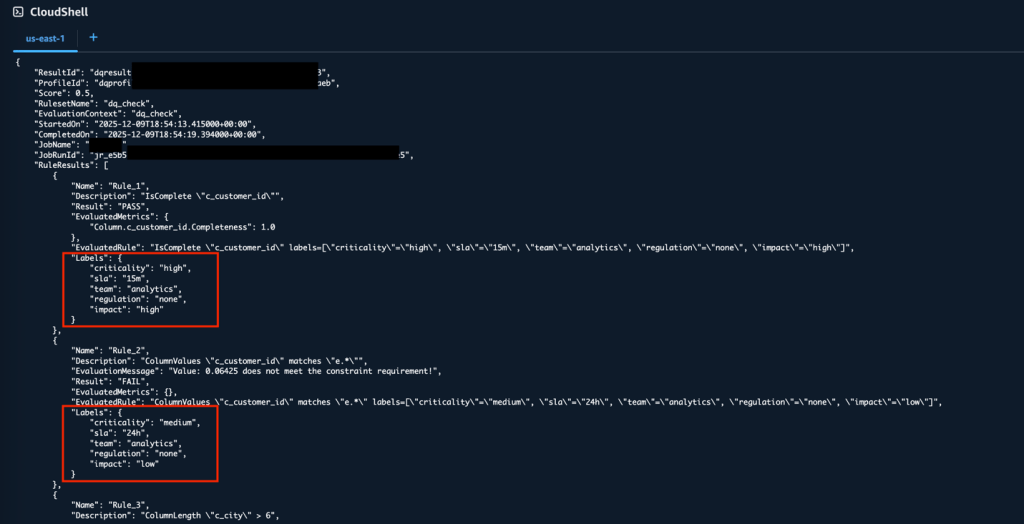
Kết quả đầu ra bao gồm một đối tượng Labels cho mỗi quy tắc trong mảng RuleResults, chứa các cặp khóa-giá trị nhãn mà bạn đã định nghĩa. Điều này cung cấp quyền truy cập theo chương trình vào cùng các kết quả chất lượng dữ liệu được gắn nhãn, hữu ích cho các quy trình tự động hóa và scripting.
Dọn dẹp
Để tránh phát sinh chi phí liên tục, hãy xóa các tài nguyên được tạo trong bài viết này:
- Để xóa các thư mục S3 chứa kết quả chất lượng dữ liệu, hãy làm theo hướng dẫn tại Deleting Amazon S3 objects.
- Để xóa job ETL bạn đã tạo cho thử nghiệm, hãy làm theo hướng dẫn tại Delete jobs trong Hướng dẫn sử dụng AWS Glue.
- Để xóa các bảng
dqrulelevelvàdqrowlevelcủa AWS Glue Data Catalog, hãy làm theo hướng dẫn tại DeleteTable trong Tài liệu tham khảo API Web của AWS Glue.
Kết luận
Nhãn AWS Glue DQDL bổ sung ngữ cảnh tổ chức vào quản lý chất lượng dữ liệu bằng cách gắn siêu dữ liệu nghiệp vụ trực tiếp vào các quy tắc xác thực. Điều này giúp các nhóm xác định quyền sở hữu quy tắc, ưu tiên các lỗi và phối hợp các nỗ lực khắc phục hiệu quả hơn. Xuyên suốt bài viết này, chúng ta đã thấy cách AnyCompany chuyển từ việc quản lý hàng trăm quy tắc chung chung sang triển khai một hệ thống được gắn nhãn, nơi kết quả chất lượng dữ liệu bao gồm quyền sở hữu của nhóm và ngữ cảnh nghiệp vụ. Các nhóm marketing có thể xác định các lỗi xác thực email của họ, các nhóm tuân thủ có thể tập trung vào các vi phạm quy định và các nhóm tài chính có thể giải quyết các vấn đề liên quan đến thanh toán mà không cần phối hợp thủ công. Để triển khai nhãn DQDL trong tổ chức của bạn:
- Bắt đầu đơn giản – Bắt đầu với các chiều tổ chức cơ bản như quyền sở hữu của nhóm, mức độ quan trọng và yêu cầu SLA. Mở rộng cách tiếp cận gắn nhãn của bạn khi cần.
- Thiết lập tiêu chuẩn – Định nghĩa phân loại nhãn của bạn ngay từ đầu, bao gồm các giá trị mặc định cho các chiều không sử dụng. Tính nhất quán này hỗ trợ phân tích trên các nhóm.
- Tích hợp dần dần – Thêm nhãn vào các bộ quy tắc hiện có trong quá trình bảo trì định kỳ.
- Sử dụng phân tích – Áp dụng các mẫu truy vấn Athena từ bài viết này để xây dựng các công cụ như bảng điều khiển và quy trình cảnh báo.
- Xây dựng tự động hóa thông minh – Khám phá việc tạo cảnh báo và thông báo phù hợp với mức độ quan trọng của nghiệp vụ và định nghĩa SLA của bạn. Ví dụ, cấu hình thông báo ngay lập tức cho các lỗi tuân thủ có mức độ quan trọng cao trong khi nhóm các vấn đề marketing ưu tiên thấp vào các báo cáo hàng ngày.
Chúng tôi mong muốn được thấy cách bạn triển khai nhãn DQDL trong tổ chức của mình và mở rộng vượt ra ngoài các ví dụ chúng tôi đã đề cập ở đây. Để tìm hiểu sâu hơn về các API AWS Glue Data Quality, hãy tham khảo tài liệu API Data Quality. Để tìm hiểu thêm về AWS Glue Data Quality, hãy xem AWS Glue Data Quality.
Về tác giả

Arun A K
Arun là Kiến trúc sư Giải pháp Chuyên gia Dữ liệu lớn cấp cao tại Amazon Web Services (AWS). Anh ấy giúp khách hàng thiết kế và mở rộng các nền tảng dữ liệu thúc đẩy đổi mới thông qua phân tích và AI. Arun đam mê khám phá cách dữ liệu và các công nghệ mới nổi có thể giải quyết các vấn đề trong thế giới thực. Ngoài công việc, anh ấy thích chia sẻ kiến thức với cộng đồng công nghệ và dành thời gian cho gia đình.

Annie Wang
Annie là Kỹ sư Phát triển Phần mềm tại AWS Glue. Cô tập trung vào việc xây dựng các tính năng chất lượng dữ liệu, bao gồm DQDL, giúp khách hàng định nghĩa, giám sát và xác thực chất lượng dữ liệu trên các pipeline của họ. Cô đam mê làm cho việc đảm bảo độ tin cậy của dữ liệu trở nên dễ dàng hơn cho khách hàng.

Roshin Babu
Roshin là Kiến trúc sư Giải pháp Chuyên gia cấp cao tại AWS, nơi anh hợp tác với nhóm bán hàng để hỗ trợ các khách hàng thuộc khu vực công. Khi không làm việc, Roshin đam mê khám phá những điểm đến mới, khám phá những món ăn tuyệt vời và thưởng thức bóng đá với tư cách là một cầu thủ và người hâm mộ.
