Tác giả: Surya Kari, Joel Carlson, Michael Cai, Morteza Ziyadi, Pradeep Natarajan, and Saurabh Sahu
Ngày phát hành: 30 JAN 2026
Chuyên mục: Amazon Nova, Amazon SageMaker, Amazon SageMaker AI, Announcements, Artificial Intelligence, Foundation models
Việc đánh giá hiệu suất của các mô hình ngôn ngữ lớn (LLM) vượt xa các chỉ số thống kê như perplexity hoặc điểm BLEU (bilingual evaluation understudy). Đối với hầu hết các kịch bản AI tạo sinh trong thế giới thực, điều quan trọng là phải hiểu liệu một mô hình có đang tạo ra các đầu ra tốt hơn so với một baseline hoặc một phiên bản trước đó hay không. Điều này đặc biệt quan trọng đối với các ứng dụng như tóm tắt, tạo nội dung hoặc các tác nhân thông minh, nơi các đánh giá chủ quan và tính đúng đắn tinh tế đóng vai trò trung tâm.
Khi các tổ chức ngày càng triển khai sâu rộng các mô hình này vào sản xuất, chúng tôi nhận thấy nhu cầu ngày càng tăng từ khách hàng muốn đánh giá chất lượng mô hình một cách có hệ thống, vượt ra ngoài các phương pháp đánh giá truyền thống. Các phương pháp hiện tại như đo lường độ chính xác và đánh giá dựa trên quy tắc, mặc dù hữu ích, không thể giải quyết đầy đủ các nhu cầu đánh giá tinh tế này, đặc biệt khi các tác vụ yêu cầu đánh giá chủ quan, hiểu biết ngữ cảnh hoặc sự phù hợp với các yêu cầu kinh doanh cụ thể. Để thu hẹp khoảng cách này, LLM-as-a-Judge đã nổi lên như một phương pháp đầy hứa hẹn, sử dụng khả năng suy luận của LLM để đánh giá các mô hình khác một cách linh hoạt hơn và ở quy mô lớn.
Hôm nay, chúng tôi rất vui mừng giới thiệu một phương pháp toàn diện để đánh giá mô hình thông qua khả năng Amazon Nova LLM-as-a-Judge trên Amazon SageMaker AI, một dịch vụ Amazon Web Services (AWS) được quản lý hoàn toàn để xây dựng, huấn luyện và triển khai các mô hình machine learning (ML) ở quy mô lớn. Amazon Nova LLM-as-a-Judge được thiết kế để cung cấp các đánh giá mạnh mẽ, không thiên vị về đầu ra AI tạo sinh trên các dòng mô hình. Nova LLM-as-a-Judge có sẵn dưới dạng các quy trình làm việc được tối ưu hóa trên SageMaker AI, và với nó, bạn có thể bắt đầu đánh giá hiệu suất mô hình theo các trường hợp sử dụng cụ thể của mình chỉ trong vài phút. Không giống như nhiều trình đánh giá có xu hướng kiến trúc, Nova LLM-as-a-Judge đã được xác thực nghiêm ngặt để duy trì tính khách quan và đã đạt được hiệu suất hàng đầu trên các benchmark judge chính trong khi phản ánh chặt chẽ các ưu tiên của con người. Với độ chính xác vượt trội và độ thiên vị tối thiểu, nó đặt ra một tiêu chuẩn mới cho việc đánh giá LLM đáng tin cậy, cấp độ sản xuất.
Khả năng Nova LLM-as-a-Judge cung cấp các so sánh cặp đôi giữa các phiên bản mô hình, giúp bạn đưa ra các quyết định dựa trên dữ liệu về cải tiến mô hình một cách tự tin.
Cách Nova LLM-as-a-Judge được huấn luyện
Nova LLM-as-a-Judge được xây dựng thông qua một quy trình huấn luyện nhiều bước bao gồm các giai đoạn huấn luyện có giám sát và học tăng cường, sử dụng các tập dữ liệu công khai được chú thích bằng các ưu tiên của con người. Đối với thành phần độc quyền, nhiều người chú thích đã độc lập đánh giá hàng nghìn ví dụ bằng cách so sánh các cặp phản hồi LLM khác nhau cho cùng một prompt. Để xác minh tính nhất quán và công bằng, tất cả các chú thích đều trải qua các kiểm tra chất lượng nghiêm ngặt, với các phán quyết cuối cùng được hiệu chỉnh để phản ánh sự đồng thuận rộng rãi của con người chứ không phải quan điểm cá nhân.
Dữ liệu huấn luyện được thiết kế vừa đa dạng vừa đại diện. Các prompt trải rộng trên nhiều danh mục, bao gồm kiến thức thế giới thực, sự sáng tạo, mã hóa, toán học, các lĩnh vực chuyên biệt và độc hại, để mô hình có thể đánh giá đầu ra trong nhiều kịch bản thế giới thực. Dữ liệu huấn luyện bao gồm dữ liệu từ hơn 90 ngôn ngữ và chủ yếu bao gồm tiếng Anh, tiếng Nga, tiếng Trung, tiếng Đức, tiếng Nhật và tiếng Ý. Điều quan trọng là, một nghiên cứu về độ thiên vị nội bộ đánh giá hơn 10.000 phán đoán ưu tiên của con người so với 75 mô hình của bên thứ ba đã xác nhận rằng Amazon Nova LLM-as-a-Judge chỉ cho thấy độ thiên vị tổng hợp 3% so với các chú thích của con người. Mặc dù đây là một thành tựu đáng kể trong việc giảm độ thiên vị có hệ thống, chúng tôi vẫn khuyến nghị kiểm tra ngẫu nhiên định kỳ để xác thực các so sánh quan trọng.
Trong hình sau, bạn có thể thấy độ thiên vị của Nova LLM-as-a-Judge so với các ưu tiên của con người khi đánh giá đầu ra của Amazon Nova so với đầu ra từ các mô hình khác. Ở đây, độ thiên vị được đo bằng sự khác biệt giữa ưu tiên của judge và ưu tiên của con người trên hàng nghìn ví dụ. Giá trị dương cho thấy judge hơi ưu tiên các mô hình Amazon Nova, và giá trị âm cho thấy điều ngược lại. Để định lượng độ tin cậy của các ước tính này, khoảng tin cậy 95% được tính toán bằng cách sử dụng sai số chuẩn cho sự khác biệt của các tỷ lệ, giả định phân phối nhị thức độc lập.
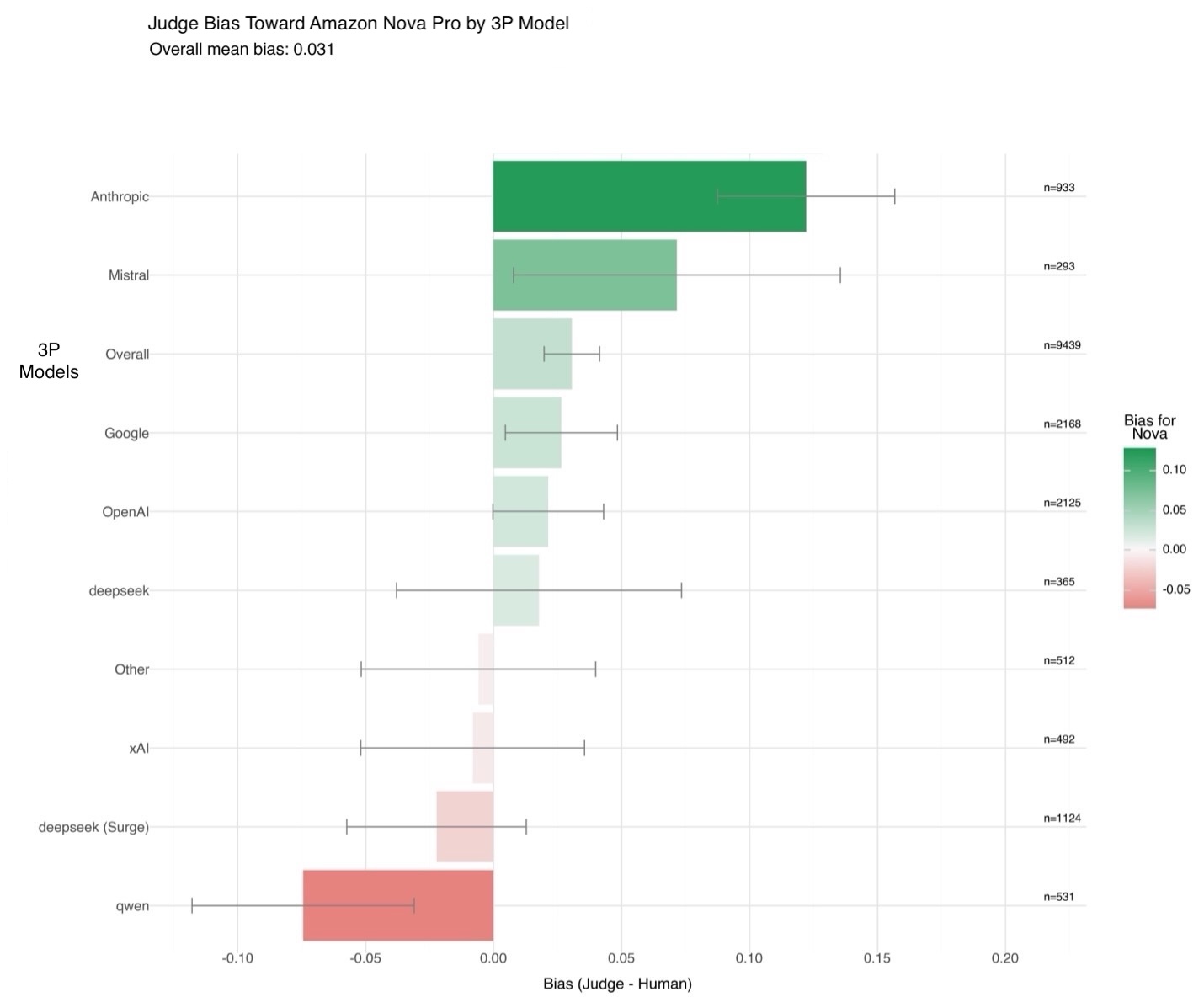
Amazon Nova LLM-as-a-Judge đạt hiệu suất tiên tiến trong số các mô hình đánh giá, thể hiện sự phù hợp mạnh mẽ với các phán đoán của con người trên một loạt các tác vụ. Ví dụ, nó đạt độ chính xác 45% trên JudgeBench (so với 42% đối với Meta J1 8B) và 68% trên PPE (so với 60% đối với Meta J1 8B). Dữ liệu từ Meta J1 8B được lấy từ Incentivizing Thinking in LLM-as-a-Judge via Reinforcement Learning.
Những kết quả này làm nổi bật sức mạnh của Amazon Nova LLM-as-a-Judge trong các đánh giá liên quan đến chatbot, như được thể hiện trong benchmark PPE. Việc benchmark của chúng tôi tuân theo các thực hành tốt nhất hiện tại, báo cáo kết quả đã được điều chỉnh cho các phản hồi hoán đổi vị trí trên JudgeBench, CodeUltraFeedback, Eval Bias và LLMBar, trong khi sử dụng kết quả một lần chạy cho PPE.
| Model | Eval Bias | Judge Bench | LLM Bar | PPE | CodeUltraFeedback |
|---|---|---|---|---|---|
| Nova LLM-as-a-Judge | 0.76 | 0.45 | 0.67 | 0.68 | 0.64 |
| Meta J1 8B | – | 0.42 | – | 0.60 | – |
| Nova Micro | 0.56 | 0.37 | 0.55 | 0.6 | – |
Trong bài đăng này, chúng tôi trình bày một phương pháp tiếp cận hợp lý để triển khai các đánh giá Amazon Nova LLM-as-a-Judge bằng cách sử dụng SageMaker AI, diễn giải các chỉ số kết quả và áp dụng quy trình này để cải thiện các ứng dụng AI tạo sinh của bạn.
Tổng quan về quy trình đánh giá
Quá trình đánh giá bắt đầu bằng việc chuẩn bị một tập dữ liệu trong đó mỗi ví dụ bao gồm một prompt và hai đầu ra mô hình thay thế. Định dạng JSONL trông như sau:
{ "prompt":"Explain photosynthesis.", "response_A":"Answer A...", "response_B":"Answer B..."}{ "prompt":"Summarize the article.", "response_A":"Answer A...", "response_B":"Answer B..."}Sau khi chuẩn bị tập dữ liệu này, bạn sử dụng SageMaker evaluation recipe đã cho, cấu hình chiến lược đánh giá, chỉ định mô hình nào sẽ được sử dụng làm judge và định nghĩa các cài đặt suy luận như temperature và top_p.
Quá trình đánh giá chạy bên trong một SageMaker training job sử dụng các container Amazon Nova được xây dựng sẵn. SageMaker AI cung cấp tài nguyên tính toán, điều phối quá trình đánh giá và ghi các chỉ số đầu ra cũng như hình ảnh hóa vào Amazon Simple Storage Service (Amazon S3).
Khi hoàn tất, bạn có thể tải xuống và phân tích kết quả, bao gồm phân phối ưu tiên, tỷ lệ thắng và khoảng tin cậy.
Hiểu cách Amazon Nova LLM-as-a-Judge hoạt động
Amazon Nova LLM-as-a-Judge sử dụng một phương pháp đánh giá được gọi là binary overall preference judge. Binary overall preference judge là một phương pháp trong đó một mô hình ngôn ngữ so sánh hai đầu ra cạnh nhau và chọn cái tốt hơn hoặc tuyên bố hòa. Đối với mỗi ví dụ, nó tạo ra một ưu tiên rõ ràng. Khi bạn tổng hợp các phán đoán này trên nhiều mẫu, bạn sẽ nhận được các chỉ số như tỷ lệ thắng và khoảng tin cậy. Phương pháp này sử dụng khả năng suy luận của mô hình để đánh giá các phẩm chất như sự liên quan và rõ ràng một cách trực tiếp, nhất quán.
- Mô hình judge này nhằm cung cấp các ưu tiên tổng thể chung có độ trễ thấp trong các tình huống không cần phản hồi chi tiết.
- Đầu ra của mô hình này là một trong
[[A>B]]hoặc[[B>A]]. - Các trường hợp sử dụng cho mô hình này chủ yếu là những trường hợp yêu cầu các ưu tiên cặp đôi chung, có độ trễ thấp, tự động, chẳng hạn như chấm điểm tự động để lựa chọn checkpoint trong các pipeline huấn luyện.
Hiểu các chỉ số đánh giá của Amazon Nova LLM-as-a-Judge
Khi sử dụng framework Amazon Nova LLM-as-a-Judge để so sánh đầu ra từ hai mô hình ngôn ngữ, SageMaker AI tạo ra một bộ chỉ số định lượng toàn diện. Bạn có thể sử dụng các chỉ số này để đánh giá mô hình nào hoạt động tốt hơn và độ tin cậy của việc đánh giá. Kết quả thuộc ba loại chính: chỉ số ưu tiên cốt lõi, chỉ số độ tin cậy thống kê, và chỉ số sai số chuẩn.
Chỉ số ưu tiên cốt lõi báo cáo tần suất đầu ra của mỗi mô hình được mô hình judge ưu tiên. Chỉ số a_scores đếm số ví dụ mà Mô hình A được ưu tiên, và b_scores đếm các trường hợp mà Mô hình B được chọn là tốt hơn. Chỉ số ties ghi lại các trường hợp mà mô hình judge đánh giá cả hai phản hồi là ngang nhau hoặc không thể xác định một ưu tiên rõ ràng. Chỉ số inference_error đếm các trường hợp mà judge không thể tạo ra một phán đoán hợp lệ do dữ liệu bị lỗi hoặc lỗi nội bộ.
Chỉ số độ tin cậy thống kê định lượng khả năng các ưu tiên quan sát được phản ánh sự khác biệt thực sự về chất lượng mô hình chứ không phải sự biến đổi ngẫu nhiên. winrate báo cáo tỷ lệ tất cả các so sánh hợp lệ trong đó Mô hình B được ưu tiên. lower_rate và upper_rate định nghĩa giới hạn dưới và trên của khoảng tin cậy 95% cho tỷ lệ thắng này. Ví dụ, winrate là 0.75 với khoảng tin cậy từ 0.60 đến 0.85 cho thấy rằng, ngay cả khi tính đến sự không chắc chắn, Mô hình B vẫn được ưu tiên hơn Mô hình A một cách nhất quán. Trường score thường khớp với số lần thắng của Mô hình B nhưng cũng có thể được tùy chỉnh cho các chiến lược đánh giá phức tạp hơn.
Chỉ số sai số chuẩn cung cấp ước tính về sự không chắc chắn thống kê trong mỗi lần đếm. Chúng bao gồm a_scores_stderr, b_scores_stderr, ties_stderr, inference_error_stderr, và score_stderr. Giá trị sai số chuẩn nhỏ hơn cho thấy kết quả đáng tin cậy hơn. Giá trị lớn hơn có thể chỉ ra nhu cầu về dữ liệu đánh giá bổ sung hoặc kỹ thuật prompt nhất quán hơn.
Việc diễn giải các chỉ số này đòi hỏi sự chú ý đến cả các ưu tiên quan sát được và khoảng tin cậy:
- Nếu
winratecao hơn đáng kể 0.5 và khoảng tin cậy không bao gồm 0.5, Mô hình B được ưu tiên thống kê hơn Mô hình A. - Ngược lại, nếu
winratedưới 0.5 và khoảng tin cậy hoàn toàn dưới 0.5, Mô hình A được ưu tiên. - Khi khoảng tin cậy chồng chéo 0.5, kết quả không kết luận được và khuyến nghị đánh giá thêm.
- Giá trị cao trong
inference_errorhoặc sai số chuẩn lớn cho thấy có thể có vấn đề trong quá trình đánh giá, chẳng hạn như sự không nhất quán trong định dạng prompt hoặc kích thước mẫu không đủ.
Sau đây là một ví dụ về đầu ra chỉ số từ một lần chạy đánh giá:
{ "a_scores": 16.0, "a_scores_stderr": 0.03, "b_scores": 10.0, "b_scores_stderr": 0.09, "ties": 0.0, "ties_stderr": 0.0, "inference_error": 0.0, "inference_error_stderr": 0.0, "score": 10.0, "score_stderr": 0.09, "winrate": 0.38, "lower_rate": 0.23, "upper_rate": 0.56}Trong ví dụ này, Mô hình A được ưu tiên 16 lần, Mô hình B được ưu tiên 10 lần, và không có hòa hoặc lỗi suy luận. winrate là 0.38 cho thấy Mô hình B được ưu tiên trong 38% các trường hợp, với khoảng tin cậy 95% dao động từ 23% đến 56%. Vì khoảng này bao gồm 0.5, kết quả này cho thấy việc đánh giá không kết luận được, và có thể cần thêm dữ liệu để làm rõ mô hình nào hoạt động tốt hơn tổng thể.
Các chỉ số này, được tạo tự động như một phần của quá trình đánh giá, cung cấp một nền tảng thống kê nghiêm ngặt để so sánh các mô hình và đưa ra các quyết định dựa trên dữ liệu về việc triển khai mô hình nào.
Tổng quan giải pháp
Giải pháp này minh họa cách đánh giá các mô hình AI tạo sinh trên Amazon SageMaker AI bằng cách sử dụng khả năng Nova LLM-as-a-Judge. Mã Python được cung cấp hướng dẫn bạn qua toàn bộ quy trình làm việc.
Đầu tiên, nó chuẩn bị một tập dữ liệu bằng cách lấy mẫu các câu hỏi từ SQuAD và tạo các phản hồi ứng cử viên từ Qwen2.5 và Claude 3.7 của Anthropic. Các đầu ra này được lưu trong một tệp JSONL chứa prompt và cả hai phản hồi.
Chúng tôi đã truy cập Claude 3.7 Sonnet của Anthropic trong Amazon Bedrock bằng cách sử dụng client bedrock-runtime. Chúng tôi đã truy cập Qwen2.5 1.5B bằng cách sử dụng một SageMaker hosted Hugging Face endpoint.
Tiếp theo, một PyTorch Estimator khởi chạy một job đánh giá bằng cách sử dụng một Amazon Nova LLM-as-a-Judge recipe. Job chạy trên các instance GPU như ml.g5.12xlarge và tạo ra các chỉ số đánh giá, bao gồm tỷ lệ thắng, khoảng tin cậy và số lượng ưu tiên. Kết quả được lưu vào Amazon S3 để phân tích.
Cuối cùng, một hàm hình ảnh hóa hiển thị các biểu đồ và bảng, tóm tắt mô hình nào được ưu tiên, mức độ ưu tiên mạnh mẽ như thế nào và độ tin cậy của các ước tính. Thông qua phương pháp tiếp cận end-to-end này, bạn có thể đánh giá các cải tiến, theo dõi các hồi quy và đưa ra các quyết định dựa trên dữ liệu về việc triển khai các mô hình tạo sinh—tất cả mà không cần chú thích thủ công.
Điều kiện tiên quyết
Bạn cần hoàn thành các điều kiện tiên quyết sau trước khi có thể chạy notebook:
- Thực hiện các yêu cầu tăng hạn mức sau cho SageMaker AI. Đối với trường hợp sử dụng này, bạn cần yêu cầu tối thiểu 1 instance g5.12xlarge. Trên bảng điều khiển Service Quotas, yêu cầu các hạn mức SageMaker AI sau, 1 instance G5 (g5.12xlarge) cho việc sử dụng training job.
- (Tùy chọn) Bạn có thể tạo một domain Amazon SageMaker Studio (tham khảo Sử dụng thiết lập nhanh cho Amazon SageMaker AI) để truy cập Jupyter notebooks với vai trò đã nêu. (Bạn cũng có thể sử dụng JupyterLab trong thiết lập cục bộ của mình.)
- Tạo một vai trò AWS Identity and Access Management (IAM) với các chính sách được quản lý
AmazonSageMakerFullAccess,AmazonS3FullAccess, vàAmazonBedrockFullAccessđể cấp quyền truy cập cần thiết cho SageMaker AI và Amazon Bedrock để chạy các ví dụ. - Gán chính sách sau làm mối quan hệ tin cậy cho vai trò IAM của bạn:
- Tạo một vai trò AWS Identity and Access Management (IAM) với các chính sách được quản lý
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "Service": [ "bedrock.amazonaws.com", "sagemaker.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ]}- Clone GitHub repository với các tài sản cho việc triển khai này. Repository này bao gồm một notebook tham chiếu các tài sản huấn luyện:
git clone https://github.com/aws-samples/amazon-nova-samples.gitcd customization/SageMakerTrainingJobs/Amazon-Nova-LLM-As-A-Judge/Tiếp theo, chạy notebook Nova Amazon-Nova-LLM-as-a-Judge-Sagemaker-AI.ipynb để bắt đầu sử dụng triển khai Amazon Nova LLM-as-a-Judge trên Amazon SageMaker AI.
Thiết lập mô hình
Để thực hiện đánh giá Amazon Nova LLM-as-a-Judge, bạn cần tạo đầu ra từ các mô hình ứng cử viên mà bạn muốn so sánh. Trong dự án này, chúng tôi đã sử dụng hai phương pháp khác nhau: triển khai mô hình Qwen2.5 1.5B trên Amazon SageMaker và gọi mô hình Claude 3.7 Sonnet của Anthropic trong Amazon Bedrock. Đầu tiên, chúng tôi đã triển khai Qwen2.5 1.5B, một mô hình ngôn ngữ đa ngôn ngữ mã nguồn mở, trên một SageMaker endpoint chuyên dụng. Điều này được thực hiện bằng cách sử dụng giao diện triển khai HuggingFaceModel. Để triển khai mô hình Qwen2.5 1.5B, chúng tôi đã cung cấp một script tiện lợi để bạn gọi: python3 deploy_sm_model.py
Khi nó được triển khai, suy luận có thể được thực hiện bằng cách sử dụng một hàm trợ giúp bao bọc API SageMaker predictor:
# Initialize the predictor oncepredictor = HuggingFacePredictor(endpoint_name="qwen25-<endpoint_name_here>")def generate_with_qwen25(prompt: str, max_tokens: int = 500, temperature: float = 0.9) -> str: """ Sends a prompt to the deployed Qwen2.5 model on SageMaker and returns the generated response. Args: prompt (str): The input prompt/question to send to the model. max_tokens (int): Maximum number of tokens to generate. temperature (float): Sampling temperature for generation. Returns: str: The model-generated text. """ response = predictor.predict({ "inputs": prompt, "parameters": { "max_new_tokens": max_tokens, "temperature": temperature } }) return response[0]["generated_text"]answer = generate_with_qwen25("What is the Grotto at Notre Dame?")print(answer)Song song đó, chúng tôi đã tích hợp mô hình Claude 3.7 Sonnet của Anthropic trong Amazon Bedrock. Amazon Bedrock cung cấp một lớp API được quản lý để truy cập các mô hình nền tảng (FM) độc quyền mà không cần quản lý cơ sở hạ tầng. Hàm tạo Claude đã sử dụng client AWS SDK for Python (Boto3) bedrock-runtime, chấp nhận một prompt người dùng và trả về phần hoàn thành văn bản của mô hình:
# Initialize Bedrock client oncebedrock = boto3.client("bedrock-runtime", region_name="us-east-1")# (Claude 3.7 Sonnet) model ID via BedrockMODEL_ID = "us.anthropic.claude-3-7-sonnet-20250219-v1:0"def generate_with_claude4(prompt: str, max_tokens: int = 512, temperature: float = 0.7, top_p: float = 0.9) -> str: """ Sends a prompt to the Claude 4-tier model via Amazon Bedrock and returns the generated response. Args: prompt (str): The user message or input prompt. max_tokens (int): Maximum number of tokens to generate. temperature (float): Sampling temperature for generation. top_p (float): Top-p nucleus sampling. Returns: str: The text content generated by Claude. """ payload = { "anthropic_version": "bedrock-2023-05-31", "messages": [{"role": "user", "content": prompt}], "max_tokens": max_tokens, "temperature": temperature, "top_p": top_p } response = bedrock.invoke_model( modelId=MODEL_ID, body=json.dumps(payload), contentType="application/json", accept="application/json" ) response_body = json.loads(response['body'].read()) return response_body["content"][0]["text"]answer = generate_with_claude4("What is the Grotto at Notre Dame?")print(answer)Khi bạn đã tạo và kiểm tra cả hai hàm, bạn có thể chuyển sang tạo dữ liệu đánh giá cho Nova LLM-as-a-Judge.
Chuẩn bị tập dữ liệu
Để tạo một tập dữ liệu đánh giá thực tế nhằm so sánh các mô hình Qwen và Claude, chúng tôi đã sử dụng Stanford Question Answering Dataset (SQuAD), một benchmark được áp dụng rộng rãi trong hiểu ngôn ngữ tự nhiên được phân phối theo giấy phép CC BY-SA 4.0. SQuAD bao gồm hàng nghìn cặp câu hỏi-trả lời được crowdsource bao gồm nhiều bài viết Wikipedia đa dạng. Bằng cách lấy mẫu từ tập dữ liệu này, chúng tôi đảm bảo rằng các prompt đánh giá của chúng tôi phản ánh các tác vụ hỏi-đáp thực tế, chất lượng cao, đại diện cho các ứng dụng trong thế giới thực.
Chúng tôi bắt đầu bằng cách tải một tập hợp con nhỏ các ví dụ để giữ cho quy trình làm việc nhanh chóng và có thể tái tạo. Cụ thể, chúng tôi đã sử dụng thư viện datasets của Hugging Face để tải xuống và tải 20 ví dụ đầu tiên từ phân tách huấn luyện SQuAD:
from datasets import load_datasetsquad = load_dataset("squad", split="train[:20]")Lệnh này truy xuất một lát cắt của tập dữ liệu đầy đủ, chứa 20 mục với các trường có cấu trúc bao gồm ngữ cảnh, câu hỏi và câu trả lời. Để xác minh nội dung và kiểm tra một ví dụ, chúng tôi đã in ra một câu hỏi mẫu và câu trả lời đúng của nó:
print(squad[3]["question"])print(squad[3]["answers"]["text"][0])Đối với tập đánh giá, chúng tôi đã chọn sáu câu hỏi đầu tiên từ tập hợp con này:
questions = [squad[i]["question"] for i in range(6)]
Tạo tập dữ liệu đánh giá Amazon Nova LLM-as-a-Judge
Sau khi chuẩn bị một bộ câu hỏi đánh giá từ SQuAD, chúng tôi đã tạo đầu ra từ cả hai mô hình và tập hợp chúng thành một tập dữ liệu có cấu trúc để được sử dụng bởi quy trình làm việc Amazon Nova LLM-as-a-Judge. Tập dữ liệu này đóng vai trò là đầu vào cốt lõi cho các SageMaker AI evaluation recipe. Để làm điều này, chúng tôi đã lặp lại từng prompt câu hỏi và gọi hai hàm tạo đã định nghĩa trước đó:
generate_with_qwen25()cho các phần hoàn thành từ mô hình Qwen2.5 được triển khai trên SageMaker.generate_with_claude()cho các phần hoàn thành từ Claude 3.7 Sonnet của Anthropic trong Amazon Bedrock.
Đối với mỗi prompt, quy trình làm việc đã cố gắng tạo một phản hồi từ mỗi mô hình. Nếu một lệnh gọi tạo thất bại do lỗi API, hết thời gian chờ hoặc vấn đề khác, hệ thống đã ghi lại ngoại lệ và lưu trữ một thông báo lỗi rõ ràng cho biết lỗi. Điều này đảm bảo rằng quá trình đánh giá có thể tiếp tục một cách duyên dáng ngay cả khi có lỗi tạm thời:
import jsonoutput_path = "llm_judge.jsonl"with open(output_path, "w") as f: for q in questions: try: response_a = generate_with_qwen25(q) except Exception as e: response_a = f"[Qwen2.5 generation failed: {e}]" try: response_b = generate_with_claude4(q) except Exception as e: response_b = f"[Claude 3.7 generation failed: {e}]" row = { "prompt": q, "response_A": response_a, "response_B": response_b } f.write(json.dumps(row) + "\n")print(f"JSONL file created at: {output_path}")Quy trình làm việc này đã tạo ra một tệp JSON Lines có tên llm_judge.jsonl. Mỗi dòng chứa một bản ghi đánh giá duy nhất có cấu trúc như sau:
{ "prompt": "What is the capital of France?", "response_A": "The capital of France is Paris.", "response_B": "Paris is the capital city of France."}Sau đó, tải llm_judge.jsonl này lên một S3 bucket mà bạn đã định nghĩa trước:
upload_to_s3( "llm_judge.jsonl", "s3://<YOUR_BUCKET_NAME>/datasets/byo-datasets-dev/custom-llm-judge/llm_judge.jsonl")Khởi chạy job đánh giá Nova LLM-as-a-Judge
Sau khi chuẩn bị tập dữ liệu và tạo evaluation recipe, bước cuối cùng là khởi chạy SageMaker training job thực hiện đánh giá Amazon Nova LLM-as-a-Judge. Trong quy trình làm việc này, training job hoạt động như một quy trình tự chứa, được quản lý hoàn toàn, tải mô hình, xử lý tập dữ liệu và tạo các chỉ số đánh giá tại vị trí Amazon S3 được chỉ định của bạn.
Chúng tôi sử dụng lớp PyTorch estimator từ SageMaker Python SDK để đóng gói cấu hình cho lần chạy đánh giá. Estimator định nghĩa các tài nguyên tính toán, image container, evaluation recipe và các đường dẫn đầu ra để lưu trữ kết quả:
estimator = PyTorch( output_path=output_s3_uri, base_job_name=job_name, role=role, instance_type=instance_type, training_recipe=recipe_path, sagemaker_session=sagemaker_session, image_uri=image_uri, disable_profiler=True, debugger_hook_config=False,)Khi estimator được cấu hình, bạn khởi tạo job đánh giá bằng cách sử dụng phương thức fit(). Lệnh gọi này gửi job đến SageMaker control plane, cung cấp cụm tính toán và bắt đầu xử lý tập dữ liệu đánh giá:
estimator.fit(inputs={"train": evalInput})
Kết quả từ job đánh giá Amazon Nova LLM-as-a-Judge
Đồ họa sau minh họa kết quả của job đánh giá Amazon Nova LLM-as-a-Judge.
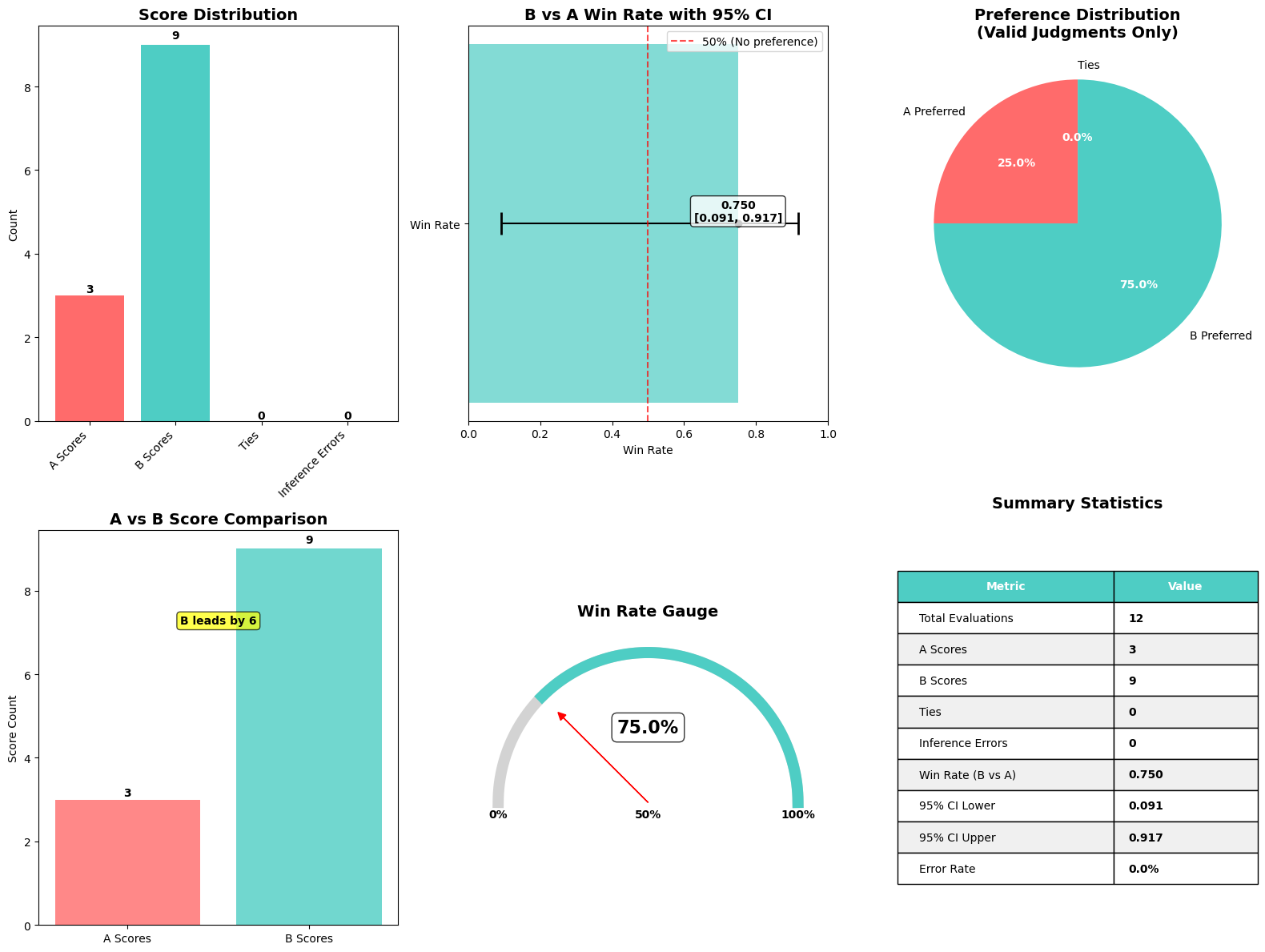
Để giúp các nhà thực hành nhanh chóng diễn giải kết quả của một đánh giá Nova LLM-as-a-Judge, chúng tôi đã tạo một hàm tiện ích tạo ra một hình ảnh hóa duy nhất, toàn diện tóm tắt các chỉ số chính. Hàm này, plot_nova_judge_results, sử dụng Matplotlib và Seaborn để hiển thị một hình ảnh với sáu bảng, mỗi bảng làm nổi bật một khía cạnh khác nhau của kết quả đánh giá.
Hàm này lấy từ điển chỉ số đánh giá—được tạo khi job đánh giá hoàn tất—và tạo ra các thành phần hình ảnh sau:
- Biểu đồ thanh phân phối điểm – Cho thấy số lần Mô hình A được ưu tiên, số lần Mô hình B được ưu tiên, số lần hòa xảy ra và tần suất judge không đưa ra quyết định (lỗi suy luận). Điều này cung cấp một cảm giác tức thì về mức độ quyết đoán của đánh giá và liệu mô hình nào đang chiếm ưu thế.
- Tỷ lệ thắng với khoảng tin cậy 95% – Vẽ biểu đồ tỷ lệ thắng tổng thể của Mô hình B so với Mô hình A, bao gồm một thanh lỗi phản ánh giới hạn dưới và trên của khoảng tin cậy 95%. Một đường tham chiếu dọc ở 50% đánh dấu điểm không có ưu tiên. Nếu khoảng tin cậy không vượt qua đường này, bạn có thể kết luận kết quả có ý nghĩa thống kê.
- Biểu đồ tròn ưu tiên – Hiển thị trực quan tỷ lệ số lần Mô hình A, Mô hình B hoặc không mô hình nào được ưu tiên. Điều này giúp nhanh chóng hiểu phân phối ưu tiên giữa các phán đoán hợp lệ.
- Biểu đồ thanh so sánh điểm A so với B – So sánh số lượng ưu tiên thô cho mỗi mô hình cạnh nhau. Một nhãn rõ ràng chú thích biên độ khác biệt để nhấn mạnh mô hình nào có nhiều chiến thắng hơn.
- Đồng hồ đo tỷ lệ thắng – Mô tả tỷ lệ thắng dưới dạng đồng hồ đo hình bán nguyệt với một kim chỉ hiệu suất của Mô hình B so với phạm vi lý thuyết 0–100%. Hình ảnh hóa trực quan này giúp các bên liên quan không chuyên về kỹ thuật hiểu tỷ lệ thắng một cách nhanh chóng.
- Bảng thống kê tóm tắt – Tổng hợp các chỉ số số—bao gồm tổng số đánh giá, số lỗi, tỷ lệ thắng và khoảng tin cậy—thành một bảng nhỏ gọn, rõ ràng. Điều này giúp dễ dàng tham chiếu các giá trị số chính xác đằng sau các biểu đồ.
Vì hàm xuất ra một Matplotlib figure tiêu chuẩn, bạn có thể nhanh chóng lưu hình ảnh, hiển thị nó trong Jupyter notebooks hoặc nhúng nó vào các tài liệu khác.
Dọn dẹp
Hoàn thành các bước sau để dọn dẹp tài nguyên của bạn:
- Xóa Qwen 2.5 1.5B Endpoint của bạn
import boto3 # Create a low-level SageMaker service client. sagemaker_client = boto3.client('sagemaker', region_name=<region>) # Delete endpoint sagemaker_client.delete_endpoint(EndpointName=endpoint_name) - Nếu bạn đang sử dụng SageMaker Studio JupyterLab notebook, hãy tắt JupyterLab notebook instance.
Cách bạn có thể sử dụng framework đánh giá này
Quy trình làm việc Amazon Nova LLM-as-a-Judge cung cấp một cách đáng tin cậy, có thể lặp lại để so sánh hai mô hình ngôn ngữ trên dữ liệu của riêng bạn. Bạn có thể tích hợp điều này vào các pipeline lựa chọn mô hình để quyết định phiên bản nào hoạt động tốt nhất, hoặc bạn có thể lên lịch nó như một phần của đánh giá liên tục để phát hiện các hồi quy theo thời gian.
Đối với các nhóm xây dựng hệ thống tác nhân hoặc hệ thống chuyên biệt theo miền, phương pháp này cung cấp cái nhìn sâu sắc phong phú hơn so với các chỉ số tự động đơn thuần. Vì toàn bộ quy trình chạy trên SageMaker training jobs, nó mở rộng nhanh chóng và tạo ra các báo cáo trực quan rõ ràng có thể được chia sẻ với các bên liên quan.
Kết luận
Bài đăng này minh họa cách Nova LLM-as-a-Judge—một mô hình đánh giá chuyên biệt có sẵn thông qua Amazon SageMaker AI—có thể được sử dụng để đo lường một cách có hệ thống hiệu suất tương đối của các hệ thống AI tạo sinh. Hướng dẫn chi tiết cho thấy cách chuẩn bị tập dữ liệu đánh giá, khởi chạy SageMaker AI training jobs với Nova LLM-as-a-Judge recipes và diễn giải các chỉ số kết quả, bao gồm tỷ lệ thắng và phân phối ưu tiên. Giải pháp SageMaker AI được quản lý hoàn toàn đơn giản hóa quy trình này, giúp bạn có thể chạy các đánh giá mô hình có thể mở rộng, lặp lại phù hợp với các ưu tiên của con người.
Chúng tôi khuyên bạn nên bắt đầu hành trình đánh giá LLM của mình bằng cách khám phá tài liệu và các ví dụ chính thức của Amazon Nova. Cộng đồng AWS AI/ML cung cấp các tài nguyên phong phú, bao gồm các workshop và hướng dẫn kỹ thuật, để hỗ trợ hành trình triển khai của bạn.
Để tìm hiểu thêm, hãy truy cập:
- Tài liệu Amazon Nova
- Tổng quan về Amazon Bedrock Nova
- Tinh chỉnh các mô hình Amazon Nova
- Hướng dẫn tùy chỉnh Amazon Nova
Về tác giả

Surya Kari là một Nhà khoa học dữ liệu AI tạo sinh cấp cao tại AWS, chuyên phát triển các giải pháp tận dụng các mô hình nền tảng tiên tiến. Anh có kinh nghiệm sâu rộng trong việc làm việc với các mô hình ngôn ngữ tiên tiến bao gồm DeepSeek-R1, dòng Llama và Qwen, tập trung vào việc tinh chỉnh và tối ưu hóa chúng. Chuyên môn của anh mở rộng sang việc triển khai các pipeline huấn luyện hiệu quả và chiến lược triển khai bằng cách sử dụng AWS SageMaker. Anh cộng tác với khách hàng để thiết kế và triển khai các giải pháp AI tạo sinh, giúp họ điều hướng lựa chọn mô hình, phương pháp tinh chỉnh và chiến lược triển khai để đạt được hiệu suất tối ưu cho các trường hợp sử dụng cụ thể của họ.

Joel Carlson là một Nhà khoa học ứng dụng cấp cao trong nhóm mô hình nền tảng Amazon AGI. Anh chủ yếu làm việc về phát triển các phương pháp tiếp cận mới để cải thiện khả năng LLM-as-a-Judge của dòng mô hình Nova.

Saurabh Sahu là một nhà khoa học ứng dụng trong nhóm mô hình nền tảng Amazon AGI. Anh nhận bằng Tiến sĩ Kỹ thuật Điện từ Đại học Maryland College Park vào năm 2019. Anh có nền tảng về machine learning đa phương thức, làm việc về nhận dạng giọng nói, phân tích cảm xúc và hiểu âm thanh/video. Hiện tại, công việc của anh tập trung vào việc phát triển các recipe để cải thiện hiệu suất của các mô hình LLM-as-a-judge cho các tác vụ khác nhau.

Morteza Ziyadi là Giám đốc Khoa học ứng dụng tại Amazon AGI, nơi anh lãnh đạo một số dự án về các recipe sau huấn luyện và các mô hình ngôn ngữ lớn (Đa phương thức) trong nhóm mô hình nền tảng Amazon AGI. Trước khi gia nhập Amazon AGI, anh đã dành bốn năm tại Microsoft Cloud and AI, nơi anh lãnh đạo các dự án tập trung vào việc phát triển các mô hình tạo ngôn ngữ tự nhiên thành mã cho các sản phẩm khác nhau. Anh cũng từng là giảng viên phụ trợ tại Đại học Northeastern. Anh nhận bằng Tiến sĩ từ Đại học Nam California (USC) vào năm 2017 và kể từ đó đã tích cực tham gia với tư cách là người tổ chức workshop và người đánh giá cho nhiều hội nghị NLP, Computer Vision và machine learning.

Pradeep Natarajan là Nhà khoa học chính cấp cao trong nhóm mô hình nền tảng Amazon AGI, làm việc về các recipe sau huấn luyện và các mô hình ngôn ngữ lớn đa phương thức. Anh có hơn 20 năm kinh nghiệm trong việc phát triển và ra mắt nhiều hệ thống machine learning quy mô lớn. Anh có bằng Tiến sĩ Khoa học Máy tính từ Đại học Nam California.

Michael Cai là Kỹ sư phần mềm trong Nhóm Tùy chỉnh Amazon AGI, hỗ trợ phát triển các giải pháp đánh giá. Anh nhận bằng Thạc sĩ Khoa học Máy tính từ Đại học New York vào năm 2024. Trong thời gian rảnh rỗi, anh thích in 3D và khám phá công nghệ đổi mới.
