Tác giả: Rajesh Kantamani, Siva Palli, và Vijay kumar
Ngày phát hành: 29 JAN 2026
Chuyên mục: Amazon Keyspaces (for Apache Cassandra), Announcements, Intermediate (200)
Amazon Keyspaces hiện hỗ trợ tính năng pre-warming để cung cấp cho bạn khả năng quản lý thông lượng chủ động. Với pre-warming, bạn có thể đặt các giá trị thông lượng khởi động (warm throughput) tối thiểu mà bảng của bạn có thể xử lý ngay lập tức, tránh các độ trễ khởi động lạnh (cold start delays) xảy ra trong quá trình phân chia phân vùng động.
Trong bài viết này, chúng tôi thảo luận về các khả năng của tính năng pre-warming trong Amazon Keyspaces và trình bày cách nó có thể nâng cao hiệu suất thông lượng của bạn. Thông qua việc kiểm tra chi tiết chức năng cốt lõi, các mẫu triển khai thực tế và phân tích chi phí, chúng tôi sẽ chỉ cho bạn cách chuẩn bị hiệu quả các bảng của mình cho việc ra mắt sản phẩm hoặc các sự kiện bán hàng.
Amazon Keyspaces (dành cho Apache Cassandra) có thể chạy các khối lượng công việc Apache Cassandra của bạn trên AWS bằng cách sử dụng một dịch vụ cơ sở dữ liệu phi máy chủ, được quản lý hoàn toàn. Bạn có thể mở rộng các ứng dụng Cassandra của mình với thông lượng và lưu trữ gần như không giới hạn, đồng thời duy trì độ trễ ở mức mili giây. Amazon Keyspaces tự động mở rộng các bảng dựa trên nhu cầu khối lượng công việc, với hành vi mở rộng được xác định bởi chế độ dung lượng của bảng. Amazon Keyspaces cung cấp hai chế độ dung lượng, on-demand và provisioned, được thiết kế để xử lý các khối lượng công việc biến động và có thể dự đoán được tương ứng. Tuy nhiên, mặc dù chế độ on-demand vượt trội trong việc tự động mở rộng, nó có độ trễ tích hợp khi các bảng cần xử lý các đợt tăng lưu lượng truy cập lớn ngay lập tức khi tạo hoặc trong các đợt tăng đột biến không mong muốn như ra mắt sản phẩm hoặc các sự kiện bán hàng.
Tìm hiểu về thông lượng khởi động (warm throughput)
Thông lượng khởi động (đạt được bằng cách pre-warming các bảng) định nghĩa các hoạt động đọc và ghi tối thiểu mà bảng Amazon Keyspaces của bạn có thể xử lý ngay lập tức mà không yêu cầu mở rộng động. Được đo bằng đơn vị đọc mỗi giây và đơn vị ghi mỗi giây, nó thiết lập một đường cơ sở hiệu suất chứ không phải giới hạn tối đa, với các giá trị mặc định là 12.000 đơn vị đọc và 4.000 đơn vị ghi cho các bảng on-demand, và khớp với dung lượng được cấp phát hiện tại của bạn cho các bảng provisioned. Không giống như dung lượng được cấp phát (thiết lập giới hạn thông lượng có thể thanh toán), thông lượng khởi động đại diện cho dung lượng mà cơ sở hạ tầng của bảng của bạn có thể xử lý ngay lập tức. Bạn có thể cấu hình thông lượng khởi động lên đến 40.000 đơn vị cho cả hoạt động đọc và ghi theo mặc định, với các giới hạn cao hơn có sẵn thông qua AWS Support. Quá trình pre-warming này hoạt động với cả hai chế độ dung lượng, cho phép các bảng on-demand mở rộng từ một đường cơ sở cao hơn và các bảng provisioned mở rộng lên đến giới hạn thông lượng khởi động mà không gặp phải độ trễ.
Cách thức hoạt động của pre-warming
Pre-warming trong Amazon Keyspaces là một quá trình không đồng bộ cho phép các bảng xử lý thông lượng cao ngay lập tức khi tạo hoặc sửa đổi. Khi bạn tạo hoặc cập nhật một bảng với cài đặt pre-warming, Amazon Keyspaces sẽ cấu hình bảng với các giá trị thông lượng được chỉ định. Khi bạn chủ động pre-warm bảng của mình, về cơ bản bạn đang thiết lập số lượng đọc và ghi mà bảng của bạn có thể hỗ trợ ngay lập tức, đảm bảo rằng nó có thể xử lý một mức lưu lượng truy cập cụ thể ngay từ đầu và các ứng dụng của bạn có thể đạt được thời gian phản hồi nhất quán dưới mili giây cho các mẫu lưu lượng truy cập dự kiến. Bạn có thể theo dõi trạng thái pre-warming bằng cách sử dụng API GetTable, API này trả về thông tin thời gian thực về quá trình pre-warming cùng với các giá trị thông lượng khởi động đã cấu hình. Các chỉ báo trạng thái như AVAILABLE hoặc UPDATING giúp bạn theo dõi khi nào bảng của bạn sẵn sàng cho các hoạt động thông lượng cao.
Đối với các triển khai đa Region, cài đặt pre-warming được tự động truyền đến tất cả các AWS Region, tạo điều kiện cho hiệu suất nhất quán trên toàn bộ nhóm sao chép bảng. Khi sử dụng AddReplica để thêm một Region mới vào một keyspace chứa các bảng đã được pre-warm, cùng một cấu hình được áp dụng cho các bảng trong Region mới được thêm mà không yêu cầu thiết lập bổ sung. Tính năng này tích hợp với các quyền AWS Identity and Access Management (IAM) hiện có, sử dụng các hành động tiêu chuẩn như cassandra:Create, cassandra:Modify và cassandra:Select để quản lý bảng, mà không giới thiệu các quyền cụ thể mới cho pre-warming. Ngoài ra, pre-warming hoạt động với cả chế độ dung lượng provisioned và on-demand, vì vậy bạn có thể duy trì mô hình thanh toán ưa thích của mình trong khi có được khả năng thông lượng cao ngay lập tức, với việc thanh toán dựa trên mô hình phí một lần cho sự khác biệt giữa các giá trị thông lượng khởi động được yêu cầu và các giá trị thông lượng khởi động hiện tại. Pre-warming cũng tích hợp với Amazon CloudWatch để cung cấp khả năng hiển thị về hiệu suất bảng, giúp bạn theo dõi các số liệu Amazon Keyspaces hiện có để xác minh rằng các bảng đã được pre-warm của bạn đang xử lý thông lượng dự kiến.
Ví dụ về trường hợp sử dụng
Để minh họa trường hợp sử dụng pre-warming, hãy xem xét một dịch vụ Internet of Things (IoT) mới ra mắt với 200.000 cảm biến được kết nối lưu trữ các chỉ số cảm biến trong một bảng Amazon Keyspaces được cấu hình ở chế độ on-demand. Ở chế độ on-demand, bảng ban đầu hỗ trợ tối đa 4.000 Đơn vị Dung lượng Ghi (WCU) và 12.000 Đơn vị Dung lượng Đọc (RCU), và các yêu cầu vượt quá dung lượng này sẽ bị điều tiết cho đến khi bảng mở rộng để đáp ứng các yêu cầu thông lượng. Khi tất cả 200.000 cảm biến trực tuyến đồng thời và cố gắng gửi các chỉ số cảm biến của chúng đến bảng Amazon Keyspaces, bảng thiếu dung lượng để xử lý 200.000 yêu cầu ghi mỗi giây, khiến các yêu cầu bị điều tiết cho đến khi bảng tự động mở rộng để phù hợp với khối lượng công việc. Ví dụ sau đây minh họa hành vi điều tiết này và quá trình mở rộng dần dần.
Tạo một bảng với đoạn mã sau:
aws keyspaces create-table \ --keyspace-name iot_demo \ --table-name sensor_readings_fresh \ --schema-definition 'allColumns=[{name=sensor_id,type=text},{name=reading_time,type=timestamp},{name=temperature,type=double},{name=humidity,type=double}],partitionKeys=[{name=sensor_id}],clusteringKeys=[{name=reading_time,orderBy=DESC}]' \ --region us-east-1Sử dụng script sau để chạy một khối lượng công việc mô phỏng. Script tạo ra khoảng 200.000 yêu cầu ghi mỗi giây và sẽ tiếp tục thử lại cho đến khi tất cả các yêu cầu hoàn tất.
from cassandra.cluster import Cluster, ConsistencyLevelfrom cassandra_sigv4.auth import SigV4AuthProviderfrom ssl import SSLContext, PROTOCOL_TLSimport timefrom datetime import datetimefrom concurrent.futures import ThreadPoolExecutor, as_completedimport threadingimport json# ConfigurationKEYSPACE = 'iot_demo'TABLE = 'sensor_readings_fresh'DURATION_MINUTES = 15TARGET_WRITES = 10000000 # High number to ensure we run for full durationWORKERS = 500BATCH_SIZE = 1000# Metrics trackingmetrics_lock = threading.Lock()metrics = { 'consumed_writes': 0, 'throttled_writes': 0, 'total_attempts': 0, 'timeline': []}# Setup Keyspaces connectionssl_context = SSLContext(PROTOCOL_TLS)auth_provider = SigV4AuthProvider()cluster = Cluster( ['cassandra.us-east-1.amazonaws.com'], ssl_context=ssl_context, auth_provider=auth_provider, port=9142)session = cluster.connect(KEYSPACE)insert_stmt = session.prepare( f"INSERT INTO {TABLE} (sensor_id, reading_time, temperature, humidity) VALUES (?, ?, ?, ?)")insert_stmt.consistency_level = ConsistencyLevel.LOCAL_QUORUMdef is_throttle_error(error_str): """Check if error indicates throttling""" throttle_indicators = ['throttl', 'overload', 'exceeded', 'unavailable', 'timeout'] return any(indicator in error_str.lower() for indicator in throttle_indicators)def write_with_retry(sensor_id): """Write with retry logic to handle throttling""" import random import uuid max_retries = 100 retry_count = 0 # Generate highly randomized sensor_id to ensure even partition distribution random_uuid = str(uuid.uuid4())[:8] # Use UUID for better randomization random_number = random.randint(1, 10000000) # Larger range random_sensor_id = f"{random_uuid}_{random_number}" while retry_count < max_retries: try: session.execute(insert_stmt, ( random_sensor_id, datetime.utcnow(), 20.0 + (random_number % 10), 50.0 + (random_number % 20) )) with metrics_lock: metrics['consumed_writes'] += 1 metrics['total_attempts'] += retry_count + 1 return {'success': True, 'retries': retry_count} except Exception as e: retry_count += 1 with metrics_lock: if is_throttle_error(str(e)): metrics['throttled_writes'] += 1 metrics['total_attempts'] += 1 if retry_count < max_retries: time.sleep(0.01) # Minimal backoff return {'success': False, 'retries': max_retries}def collect_metrics(start_time): """Collect timeline metrics for analysis""" end_time = start_time + (DURATION_MINUTES * 60) while True: time.sleep(0.5) current_time = time.time() with metrics_lock: elapsed = current_time - start_time metrics['timeline'].append({ 'timestamp': elapsed, 'consumed_writes': metrics['consumed_writes'], 'throttled_writes': metrics['throttled_writes'], 'total_attempts': metrics['total_attempts'] }) if current_time >= end_time: breakprint(f"\n{'='*70}")print(f"KEYSPACES 15-MINUTE PREWARMED BURST TEST")print(f"{'='*70}\n")print(f"Table: {KEYSPACE}.{TABLE}")print(f"Duration: {DURATION_MINUTES} minutes")print(f"Workers: {WORKERS}")print(f"Purpose: Demonstrate sustained high throughput with prewarming\n")start_time = time.time()end_time = start_time + (DURATION_MINUTES * 60)# Start metrics collectionmetrics_thread = threading.Thread(target=collect_metrics, args=(start_time,))metrics_thread.daemon = Truemetrics_thread.start()completed = 0failed_final = 0total_retries = 0batch_count = 0while time.time() < end_time: batch_start = batch_count * BATCH_SIZE batch_end = batch_start + BATCH_SIZE with ThreadPoolExecutor(max_workers=WORKERS) as executor: futures = [executor.submit(write_with_retry, i) for i in range(batch_start, batch_end)] for future in as_completed(futures): if time.time() >= end_time: break result = future.result() completed += 1 if result['success']: total_retries += result['retries'] else: failed_final += 1 # Progress update every 2000 writes if completed % 2000 == 0: elapsed = time.time() - start_time remaining = (end_time - time.time()) / 60 with metrics_lock: consumed = metrics['consumed_writes'] throttled = metrics['throttled_writes'] attempts = metrics['total_attempts'] throttle_rate = throttled / max(1, attempts) * 100 print(f" Progress: {completed:,} writes | " f"Success: {consumed:,} | Throttled: {throttled:,} ({throttle_rate:.1f}%) | " f"Rate: {consumed/elapsed:.1f}/sec | Remaining: {remaining:.1f}min") batch_count += 1time.sleep(2) # Allow metrics collection to completeelapsed = time.time() - start_timeprint(f"\n{'='*70}")print(f"15-MINUTE PREWARMED BURST TEST RESULTS")print(f"{'='*70}")print(f"Duration: {DURATION_MINUTES} minutes ({elapsed:.1f}s)")print(f"Total writes: {metrics['consumed_writes']:,}")print(f"Successful: {metrics['consumed_writes']:,} ({metrics['consumed_writes']/(metrics['consumed_writes']+failed_final)*100:.1f}%)")print(f"Failed: {failed_final:,}")print(f"Throttled attempts: {metrics['throttled_writes']:,}")print(f"Total attempts: {metrics['total_attempts']:,}")print(f"Retry overhead: {(metrics['total_attempts']-metrics['consumed_writes'])/metrics['consumed_writes']*100:.1f}%")print(f"Average rate: {metrics['consumed_writes']/elapsed:.1f} writes/sec")print(f"Peak capacity used: {max(5000, metrics['consumed_writes']/elapsed):.0f} WCU/sec")# Save metricsmetrics_file = f'prewarmed_15min_metrics_{int(start_time)}.json'with open(metrics_file, 'w') as f: json.dump({ 'test_config': { 'duration_minutes': DURATION_MINUTES, 'workers': WORKERS, 'batch_size': BATCH_SIZE, 'table': f'{KEYSPACE}.{TABLE}', 'warm_throughput': '40,000 WCU / 40,000 RCU' }, 'summary': { 'duration_seconds': elapsed, 'total_writes': metrics['consumed_writes'], 'consumed_writes': metrics['consumed_writes'], 'throttled_writes': metrics['throttled_writes'], 'total_attempts': metrics['total_attempts'], 'failed_writes': failed_final, 'average_rate_per_sec': metrics['consumed_writes']/elapsed, 'retry_overhead_percent': (metrics['total_attempts']-metrics['consumed_writes'])/max(1,metrics['consumed_writes'])*100, 'throttle_percentage': metrics['throttled_writes']/max(1, metrics['total_attempts'])*100, 'success_rate': metrics['consumed_writes']/(metrics['consumed_writes']+failed_final)*100 }, 'timeline': metrics['timeline'] }, f, indent=2)print(f"\nMetrics saved to: {metrics_file}")print(f"Use this data for your blog post about prewarming effectiveness")print(f"{'='*70}\n")cluster.shutdown()Các biểu đồ CloudWatch sau đây cho thấy rằng nếu không có pre-warming, việc điều tiết bắt đầu khi bảng đạt đến 4.000 WRU ban đầu hoặc khi cần phân chia lưu trữ để thêm nhiều phân vùng hơn.
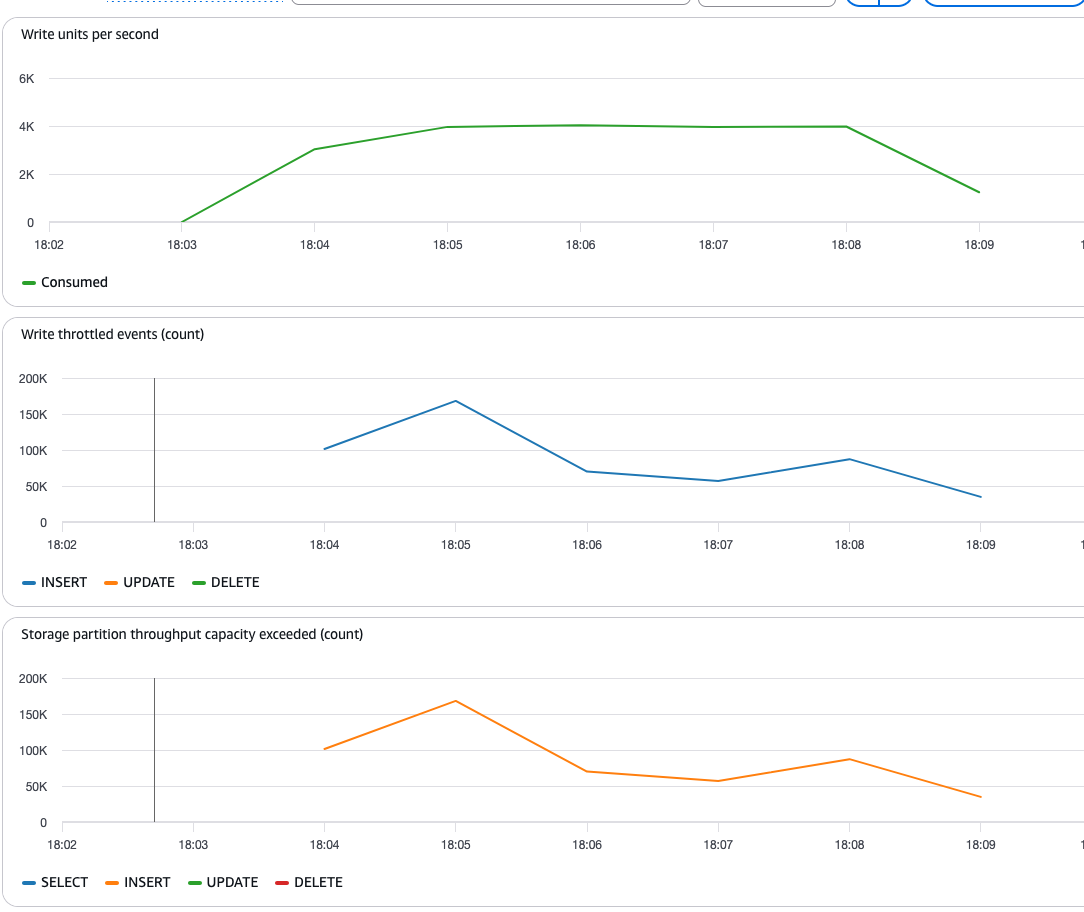
Bây giờ, hãy tạo bảng với pre-warming và chạy cùng một tải để quan sát hành vi xem có xảy ra điều tiết hay không:
aws keyspaces create-table \--keyspace-name iot_demo \--table-name sensor_readings_fresh \--schema-definition 'allColumns=[{name=sensor_id,type=text},{name=reading_time,type=timestamp},{name=temperature,type=double},{name=humidity,type=double}],partitionKeys=[{name=sensor_id}],clusteringKeys=[{name=reading_time,orderBy=DESC}]' \--warm-throughput-specification 'readUnitsPerSecond=40000,writeUnitsPerSecond=40000' \--region us-east-1Sau khi bảng được tạo, Amazon Keyspaces tạo các phân vùng lưu trữ và sẵn sàng phục vụ lưu lượng truy cập đến mà không bị điều tiết. Các biểu đồ CloudWatch sau đây cho thấy bạn có thể hỗ trợ lưu lượng truy cập tăng đột biến mà không gặp vấn đề gì.
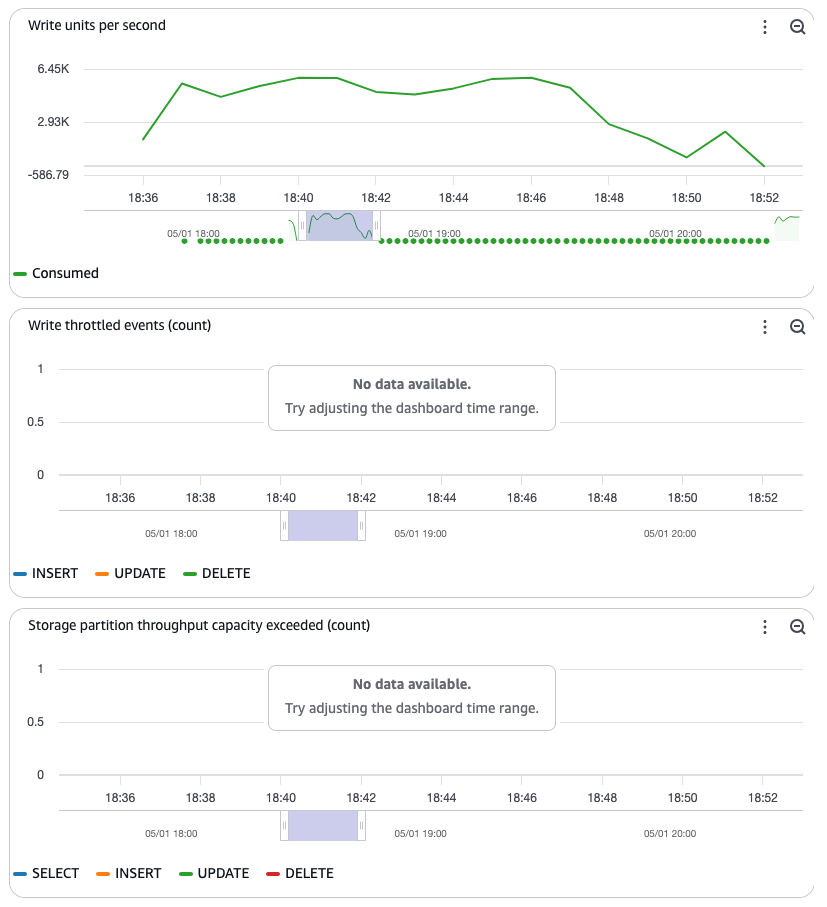
Định giá
Giá cho pre-warming dựa trên chi phí của WCU và RCU được cấp phát trong Region cụ thể nơi bảng của bạn được đặt. Khi bạn pre-warm một bảng, chi phí được tính là phí một lần dựa trên sự khác biệt giữa các giá trị mới và thông lượng khởi động hiện tại mà bảng hoặc chỉ mục có thể hỗ trợ.
Theo mặc định, các bảng on-demand có thông lượng khởi động cơ bản là 4.000 WCU và 12.000 RCU. Khi pre-warm một bảng on-demand mới được tạo, bạn chỉ bị tính phí cho sự khác biệt giữa các giá trị được chỉ định của bạn và các giá trị cơ bản này. Ví dụ IoT trong bài viết này minh họa việc pre-warm các bảng lên 40.000 WCU và 40.000 RCU. Điều này phát sinh một khoản phí một lần áp dụng cho 36.000 (40.000 – 4.000) WCU và 28.000 (40.000 – 12.000) RCU bổ sung cần thiết.
Tính toán chi phí pre-warming cho us-east-1 như sau:
- Đơn vị Dung lượng Đọc: 28.000 RCU × $0.00013 = $3.64
- Đơn vị Dung lượng Ghi: 36.000 WCU × $0.00065 = $23.40
- Tổng chi phí một lần: $27.04
Bằng cách pre-warm các bảng, bạn giảm thiểu rủi ro vận hành và đảm bảo ứng dụng của bạn có thể xử lý lưu lượng truy cập tăng đột biến mà không bị điều tiết, mang lại trải nghiệm khách hàng mượt mà trong các sự kiện bán hàng quan trọng.
Kết luận
Pre-warming cung cấp một khả năng mạnh mẽ trong Amazon Keyspaces để chuẩn bị các bảng của bạn cho các khối lượng công việc thông lượng cao ngay lập tức. Cho dù bạn đang điều phối một đợt phát hành sản phẩm lớn hay chuẩn bị cho các đợt tăng lưu lượng truy cập dự kiến, hãy sử dụng pre-warming để chuẩn bị các bảng của bạn với dung lượng cần thiết ngay từ đầu, giảm thiểu việc điều tiết và mang lại hiệu suất nhất quán, dưới mili giây mà các ứng dụng của bạn yêu cầu.
Để tìm hiểu thêm về tính năng pre-warming, vui lòng tham khảo tài liệu Amazon Keyspaces.
Về tác giả

Rajesh Kantamani
Rajesh Kantamani [Rajesh là Kiến trúc sư Giải pháp Chuyên gia Cơ sở dữ liệu cấp cao tại AWS. Anh hợp tác với khách hàng để thiết kế, di chuyển và tối ưu hóa các giải pháp cơ sở dữ liệu của họ, tập trung vào khả năng mở rộng, bảo mật và hiệu suất cao nhất. Với niềm đam mê cơ sở dữ liệu phân tán, anh giúp các tổ chức chuyển đổi cơ sở hạ tầng dữ liệu của họ. Khi không thiết kế các giải pháp cơ sở dữ liệu, anh thích các hoạt động ngoài trời cùng gia đình và bạn bè.

Vijaykumar
Vijaykumar là Kỹ sư Phát triển Phần mềm tại AWS trong nhóm Amazon Keyspaces và là nhà phát triển chính cho khả năng pre-warming được giới thiệu trong blog này. Với hơn 6 năm làm việc tại Amazon và hơn 2 năm tập trung vào Keyspaces, anh làm việc chặt chẽ với khách hàng để hiểu nhu cầu của họ và xây dựng các giải pháp giúp các tổ chức tận dụng Amazon Keyspaces cho các khối lượng công việc Cassandra có khả năng mở rộng, đáng tin cậy và hiệu suất cao trên đám mây.

Siva Palli
Siva là Giám đốc Sản phẩm cấp cao cho Amazon Keyspaces. Anh làm việc với khách hàng và các nhóm kỹ thuật để xác định và cung cấp các tính năng giúp các tổ chức xây dựng các ứng dụng có khả năng mở rộng, hiệu suất cao trên Amazon Web Services. Với niềm đam mê cơ sở dữ liệu NoSQL và kiến trúc phi máy chủ, anh giúp định hình tương lai của các dịch vụ cơ sở dữ liệu được quản lý. Khi không xây dựng sản phẩm, anh thích đi du lịch, khám phá những địa điểm mới và chơi tennis.
