Tác giả: Ryan Niksch
Ngày phát hành: 30 JAN 2026
Chuyên mục: https://aws.amazon.com/blogs/ibm-redhat/vmware-to-openshift-migration-best-practices-guidance/
Việc di chuyển hoặc tái nền tảng có thể rất đáng sợ, và có lý do chính đáng, thường có nhiều hệ thống phức tạp và khác biệt với các mức độ nợ kỹ thuật khác nhau, nhiều nhóm, các bên liên quan và các đơn vị kinh doanh tham gia. Họ cần được tư vấn, hỗ trợ các hoạt động trước và sau di chuyển, và thường có các mốc thời gian gấp rút với ít sự linh hoạt về thời gian ngừng hoạt động hoặc cửa sổ bảo trì.
Mục tiêu của bài viết này không phải là cung cấp cho bạn một hướng dẫn toàn diện từ A đến Z về cách di chuyển (vì có cả những cuốn sách viết về chủ đề này), mà là một chút hướng dẫn, cái nhìn sâu sắc và một số bài học quan trọng đã học được.
Thách thức và cân nhắc trong ngành
Có lẽ không có gì ngạc nhiên khi nói rằng các tổ chức đang phải đối mặt với những thách thức từ nhiều phía hiện nay khi nói đến công nghệ, chi phí, tốc độ đưa sản phẩm ra thị trường và cạnh tranh. Dưới đây là danh sách không đầy đủ các thách thức mà chúng tôi chứng kiến ở nhiều khách hàng hiện tại và tiềm năng của mình.
Hiện đại hóa ứng dụng
Trước hết, các phòng ban IT và đội ngũ phát triển trên toàn cầu đã cảm nhận được áp lực ngày càng tăng để hiện đại hóa ứng dụng, và chuyển từ cách tiếp cận IT và kiến trúc ứng dụng lấy cơ sở hạ tầng làm trung tâm sang cách tiếp cận lấy ứng dụng làm trung tâm. Chỉ một thập kỷ trước, container và kiến trúc microservice được coi là một điều mới lạ hoặc một bài tập học thuật. Tuy nhiên, ngày nay, chúng ta đang chứng kiến ngày càng nhiều ứng dụng và tổ chức áp dụng kiến trúc cloud-native để đạt được tính di động, tự động hóa và tốc độ phát triển cao hơn. Kiến trúc Model/View/Controller đã lỗi thời, và microservices cùng auto-scaling đang lên ngôi.
Kỳ vọng về tốc độ
Dường như mọi thứ ngày nay đều là một ứng dụng, dù trên thiết bị di động, TV thông minh, hệ thống thông tin giải trí trên ô tô, hay chính những chiếc ô tô. Người tiêu dùng đã quen với việc mong đợi (dù tốt hay xấu) các bản cập nhật thường xuyên và không gây gián đoạn cùng các tính năng mới trong các sản phẩm hiện có của chúng ta; và kỳ vọng đó cũng đã mở rộng sang các hệ thống nội bộ của công ty hoặc tổ chức.
Như bạn có thể thấy, khả năng hỗ trợ tăng tốc độ này mang lại lợi thế cạnh tranh thực sự cho các tổ chức. Một ví dụ giả định: Hai công ty cạnh tranh, Acme Systems và Nadir Corp, hoạt động trong một ngành mà ngày nay mỗi công ty chiếm 50% thị phần. Nếu Acme Systems thành công trong việc áp dụng kiến trúc linh hoạt và nhanh nhẹn hơn sớm hơn hoặc hiệu quả hơn Nadir Corp, thì công ty này sẽ có thể đổi mới nhanh hơn, đạt được thời gian đưa sản phẩm ra thị trường nhanh hơn và mang lại sự hài lòng cho khách hàng với tần suất cao hơn. Acme Systems sẽ nhanh chóng giành được khách hàng của Nadir Corp trong khi vẫn giữ được hoạt động kinh doanh hiện có của mình. Vì vậy, mặc dù có thể được coi là một lập luận theo trào lưu, nhưng trái với sự khó chịu của mẹ bạn, đôi khi việc nhảy cầu khi tất cả bạn bè của bạn đều làm điều đó lại có ý nghĩa.
Chi phí leo thang
Không có gì bí mật khi gần đây đã có một số thương vụ mua lại và hợp nhất khá lớn trong ngành công nghệ. Và mặc dù điều đó không phải lúc nào cũng dẫn đến việc tăng chi phí (ví dụ: cấp phép và hỗ trợ), nhưng rất thường xuyên là có. Chi phí để vận hành hệ thống của một doanh nghiệp đã tăng vọt lên 3-5 lần trong nhiều trường hợp, đặt ra câu hỏi về các mối quan hệ nhà cung cấp lâu dài hiện có và các khoản đầu tư của tổ chức bạn. Gần như chắc chắn rằng khi đánh giá giá mới, một số tổ chức mới hợp nhất này đang tính đến sự phụ thuộc và bộ kỹ năng hiện có của họ trong một bộ công nghệ cụ thể. Thêm vào đó là chi phí vốn ngày càng tăng (ví dụ: RAM), chúng ta cần tận dụng các tài sản hiện có, chẳng hạn như lưu trữ và máy chủ cho bất kỳ nền tảng nào chúng ta chọn theo đuổi.
Các trường hợp sử dụng Hybrid
Bất kể cách tiếp cận nào chúng ta chọn – tại chỗ, đám mây hoặc kết hợp cả hai – chúng ta cần xem xét tính di động được cung cấp bởi phần mềm hoặc môi trường. Vì chúng ta có nguy cơ phải thực hiện lại toàn bộ quá trình nếu nhà cung cấp hoặc nhà cung cấp đám mây mới được chọn sau này quyết định tăng chi phí. Chúng ta cũng cần nhận thức về các miền lỗi, tính khả dụng, định cỡ tải cao điểm và sự phân tán IT, đảm bảo chúng ta không chi tiêu không cần thiết để chạy “khối lượng công việc zombie” hoặc đầu tư quá nhiều vào phần cứng tại chỗ để định cỡ cho tải cao điểm. Phần mềm mã nguồn mở có thể giúp ích rất nhiều ở đây, nhưng chúng ta cần đảm bảo rằng chúng ta có thể đạt được sự ổn định, hỗ trợ và khả năng tương tác trong kiến trúc đã chọn của mình.
Các khối lượng công việc mới nổi
Khi chọn tái nền tảng, chúng ta muốn đảm bảo có thể hỗ trợ các khối lượng công việc hiện có mà không trì hoãn đến mức sau này chúng ta không thể hỗ trợ các khối lượng công việc mới nổi, chẳng hạn như Trí tuệ nhân tạo (AI) hoặc Học máy (ML). Thực tế là, nhiều mô hình đã xuất hiện trong đó Kubernetes là nền tảng được chọn cho các công nghệ mới này, do khả năng hỗ trợ các khối lượng công việc đa dạng, dễ dàng mở rộng quy mô lên và xuống, và phân bổ khối lượng công việc hiệu quả cho cơ sở hạ tầng.
Bối cảnh mối đe dọa
AI không chỉ mang lại lợi ích cho các tổ chức và người tiêu dùng – nó còn giúp giảm rào cản cho các tác nhân đe dọa thiết kế và thực hiện các cuộc tấn công tinh vi, cho dù đó là đánh cắp dữ liệu, ransomware hay hacktivism chính trị. Bất kỳ nền tảng hoặc kiến trúc nào chúng ta chọn cần phải có tư thế bảo mật ngang bằng hoặc lớn hơn nền tảng hiện tại của chúng ta để giúp bảo vệ tốt hơn bản thân và dữ liệu kinh doanh quan trọng của chúng ta khỏi các cuộc tấn công.
Chuẩn bị di chuyển
Mặc dù không phải là một kết luận đã được định trước, chúng ta sẽ giả định rằng bạn và tổ chức của bạn đã tiến hành thẩm định và kết luận rằng việc tái nền tảng là hợp lý. Với mục đích của blog này, chúng ta sẽ giả định rằng bạn và tổ chức của bạn đã xác định Red Hat OpenShift là nền tảng mục tiêu được chọn, có lẽ ban đầu chỉ cho các khối lượng công việc ảo hóa, nhưng với kế hoạch hiện đại hóa theo cách tiếp cận hybrid, nơi các ứng dụng hiện có được tái kiến trúc hoặc các giải pháp thay thế phù hợp được xác định có thể được triển khai dưới dạng các khối lượng công việc containerized.
Sau khi đã quyết định sử dụng OpenShift với OpenShift Virtualization, điều quan trọng là phải xác định những công cụ, quy trình và công nghệ hiện có nào có thể được tận dụng cho nền tảng mới và những gì cần thay đổi. Điều này có thể bao gồm việc quyết định tận dụng phần cứng hiện có hoặc mua tất cả thiết bị mới, nâng cấp các tích hợp như ITSM của tổ chức bạn để cung cấp cơ sở hạ tầng, và đánh giá các công cụ sao lưu và phục hồi thảm họa hiện tại của bạn. Bạn phải xác định liệu chúng có thể được sử dụng trên nền tảng mới hay liệu một giải pháp mới hoặc bổ sung là phù hợp. Ngoài ra, điều quan trọng là bắt đầu chuẩn bị các nhóm và chuyên gia với đào tạo và tài nguyên để học cách thiết kế, xây dựng, di chuyển và vận hành một giải pháp OpenShift. Theo kinh nghiệm cá nhân của tôi, khi làm việc cho một Global System Integrator (GSI) lớn, sự thành công của kiến trúc mới và quy trình di chuyển tổng thể gần như luôn được quyết định không phải bởi công nghệ hoặc kiến trúc được chọn, mà bởi mức độ sẵn sàng của các nhóm vận hành của tổ chức để quản lý, khắc phục sự cố và mở rộng quy mô nền tảng mới. Trong một số trường hợp, điều này đòi hỏi nhiều tháng đào tạo trên các nhóm và lĩnh vực, đôi khi dẫn đến việc tái cấu trúc tổ chức để đáp ứng tốt hơn nhu cầu của nền tảng mới.
Một lĩnh vực phổ biến khác có tác động đáng kể đến sự thành công hay thất bại của dự án tái nền tảng là giao tiếp hiệu quả. Các tổ chức chọn một kế hoạch giao tiếp được xác định rõ ràng, kỹ lưỡng và liên tục thường thành công hơn nhiều so với những tổ chức cố gắng thực hiện một hoạt động chuyển đổi “chớp nhoáng”. Việc giao tiếp cởi mở và trung thực giữa các nhóm kỹ thuật và kinh doanh là vô cùng quan trọng, để thiết lập lòng tin, xây dựng sự hiểu biết và giúp ngăn chặn bất kỳ bất ngờ không mong muốn nào khi quá trình di chuyển xảy ra.
Có lẽ bước quan trọng nhất trước khi di chuyển là thực hiện kiểm kê kỹ lưỡng các tài sản sẽ được di chuyển, bao gồm xác định các VMs, các phụ thuộc của chúng, yêu cầu tài nguyên của chúng, tầm quan trọng của chúng đối với doanh nghiệp và bất kỳ yêu cầu cụ thể nào của ứng dụng để đảm bảo tác động tối thiểu trong quá trình di chuyển. Các cân nhắc về dữ liệu, mạng và dịch vụ chia sẻ đặc biệt quan trọng, vì các khối lượng công việc thường không thể chỉ đơn giản là nâng và chuyển mà không có một số thay đổi cấu hình giữa các dịch vụ chia sẻ (ví dụ: IPAM và DNS, Active Directory, load balancers, v.v.).
Chúng tôi thường thực hiện nhiều cuộc phỏng vấn với các nhân viên khác nhau, bao gồm chủ sở hữu ứng dụng, các bên liên quan kinh doanh và quản trị viên cơ sở dữ liệu để có được bức tranh đầy đủ về các khối lượng công việc mà chúng tôi đang di chuyển và cách tốt nhất để di chuyển chúng. Chúng tôi sẽ xác định các kế hoạch kiểm tra trước và sau di chuyển và có các kế hoạch khôi phục được xác định rõ ràng trong trường hợp di chuyển thất bại hoặc tác động kinh doanh vượt quá ngưỡng đã định.
Chúng tôi thường nhóm các cuộc di chuyển thành các đợt, bắt đầu với các khối lượng công việc có tác động thấp, chẳng hạn như môi trường phát triển, thử nghiệm hoặc staging, sau đó dần dần chuyển sang các khối lượng công việc quan trọng hơn. Kích thước đợt thường thay đổi, thường bắt đầu nhỏ, sau đó dần dần lớn hơn, và sau đó cuối cùng lại thu nhỏ khi chúng tôi tiếp cận các khối lượng công việc quan trọng nhất. Làm việc với doanh nghiệp, chúng tôi sẽ xác định những gì có thể được di chuyển “cold” (ngừng hoạt động) so với “live” (trực tiếp). Đối với các ứng dụng kinh doanh quan trọng nhất, chúng tôi thường nhóm các thành phần được mở rộng quy mô trên các nền tảng tạm thời, trong đó một phần của khối lượng công việc sẽ chạy trong môi trường truyền thống và một phần trong môi trường mới.
Các phương pháp hay nhất để di chuyển từ VMware vSphere sang Red Hat OpenShift
Sau nhiều tháng lập kế hoạch, phỏng vấn, phân tích, thử nghiệm và chuẩn bị, chúng tôi sẽ bắt đầu quá trình di chuyển. Có một số cách để di chuyển; tuy nhiên, nền tảng để giúp đơn giản hóa và tự động hóa quá trình di chuyển là Red Hat OpenShift Migration Toolkit for Virtualization (MTV) miễn phí. Sử dụng MTV, các VMs có thể được nhóm theo kế hoạch di chuyển theo đợt của chúng và được di chuyển theo yêu cầu về tính khả dụng của chúng (ví dụ: di chuyển cold so với warm).
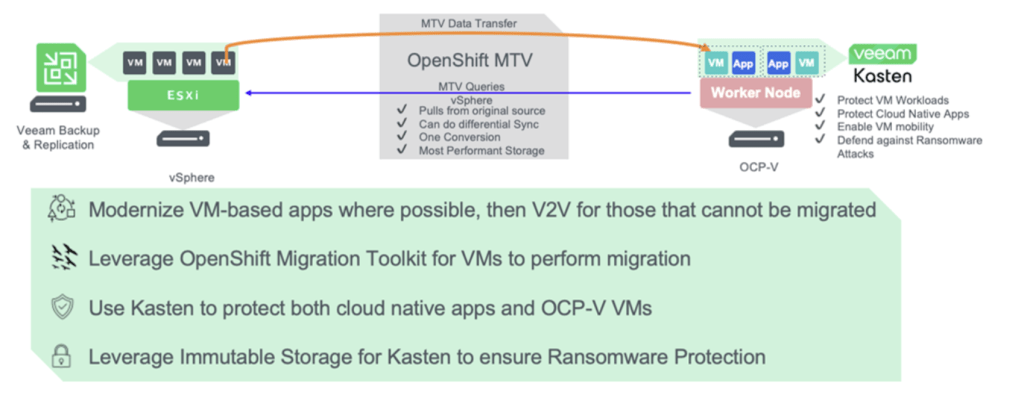
Hình 1: MTV và Veeam cho các cuộc di chuyển
Không theo thứ tự cụ thể nào, đây là một số phương pháp hay nhất mà chúng tôi đã quan sát để đảm bảo quá trình di chuyển suôn sẻ với tác động kinh doanh tối thiểu:
- Loại bỏ những gì không cần thiết – xác định bất kỳ VMs nào có thể được ngừng hoạt động hoặc hợp nhất để tránh phải di chuyển các khối lượng công việc không cần thiết. Trong trường hợp không thể xác định mục đích hoặc chủ sở hữu của một VM, và sau khi đã thử mọi kênh khác, một giải pháp “tổng quát” tốt mà chúng tôi thường sử dụng là tắt VM không xác định vào tối thứ Hai sau giờ làm việc và để nó tắt qua đêm. Chúng tôi thường biết ngay vào sáng thứ Ba thông qua một phiếu yêu cầu hỗ trợ nếu VM đó cần được di chuyển và mục đích của nó là gì. Ngoài ra, hãy xác định bất kỳ phần mềm có sẵn nào có thể đang chạy một VM ngày nay và có thể dễ dàng chuyển đổi sang kiến trúc cloud-native, containerized. Những thứ như load balancers, web servers và proxies thường là những ví dụ điển hình về các khối lượng công việc có thể là VMs ngày nay nhưng có thể dễ dàng chuyển đổi sang các phiên bản containerized tương đương trên nền tảng mới.
- Sao chép ứng dụng và cơ sở dữ liệu có thể giảm đáng kể gánh nặng – trong trường hợp các khối lượng công việc như SQL servers hoặc Active Directory, việc chuyển sang các dịch vụ được quản lý cloud-native như Amazon Relational Database (RDS) là phổ biến, với Amazon Database Migration Service (DMS) được sử dụng để hỗ trợ tái nền tảng các khối lượng công việc đó, và Amazon managed Directory Service. Các dịch vụ này cung cấp khả năng mở rộng và khả năng phục hồi, và chúng tôi sau đó có thể ngừng hoạt động các node cluster nằm trên cluster vSphere cũ.
- Đừng quên các drivers – các drivers virtiOo và qemu tools rất quan trọng để cài đặt trước, để sau khi di chuyển, các VMs có thể khởi động vào các ổ đĩa đã được chuyển đổi mới của chúng. Điều này đặc biệt quan trọng đối với các Windows VMs. Các giải pháp quản lý endpoint như Microsoft Intune hoặc ManageEngine Endpoint Central có thể rất hữu ích trong việc triển khai các drivers và guest tools cho các endpoint VM trước thời hạn.
- Bắt đầu nhỏ và mở rộng quy mô – như đã đề cập ở trên. Xác định các đợt di chuyển trước, bắt đầu nhỏ với các khối lượng công việc không quan trọng và dần dần chuyển sang các khối lượng công việc lớn hơn và quan trọng hơn. Lên kế hoạch có một tập hợp các đợt nhỏ ở cuối cho các khối lượng công việc quan trọng nhất. Ngoài ra, chúng tôi thường có 2-4 “đợt” trống được xác định ở cuối kế hoạch di chuyển của chúng tôi cho bất kỳ khối lượng công việc cứng đầu nào.
- Có một kế hoạch khôi phục được xác định và ghi lại rõ ràng. Bất kể có bao nhiêu kế hoạch, giao tiếp, thử nghiệm và suy nghĩ trước được thực hiện, sẽ có một số khối lượng công việc đơn giản là không thể di chuyển thành công ngay lần đầu. Tận dụng MTV sẽ giúp ích cho việc này, tuy nhiên chúng ta vẫn có thể gặp phải 20% VMs được di chuyển cần thêm một số nỗ lực. Mặc dù đáng thất vọng (đặc biệt là khi nó xảy ra vào những giờ khuya), những lần di chuyển thất bại này có thể được xử lý suôn sẻ bằng cách đơn giản là hoàn tác quá trình di chuyển và thử lại vào một ngày sau đó. Một giải pháp thực tế tốt là sử dụng giải pháp sao lưu hiện có của bạn, nếu bạn đang sử dụng công nghệ tốt nhất, đó sẽ là Veeam Data Platform. Trong trường hợp xảy ra lỗi nghiêm trọng mà bạn không thể khởi động VM nguồn ban đầu, bạn có thể nhanh chóng khôi phục thông qua Veeam Backup and Replication.
Hãy xem webinar sau: Mapping your Migration: Explore The Path to OpenShift Virtualization để có thêm hướng dẫn. Và tất nhiên, nếu bạn muốn được hỗ trợ chuyên nghiệp trong quá trình di chuyển của mình, cả Red Hat Services và các đối tác GSI của chúng tôi đều có rất nhiều kinh nghiệm để hỗ trợ.
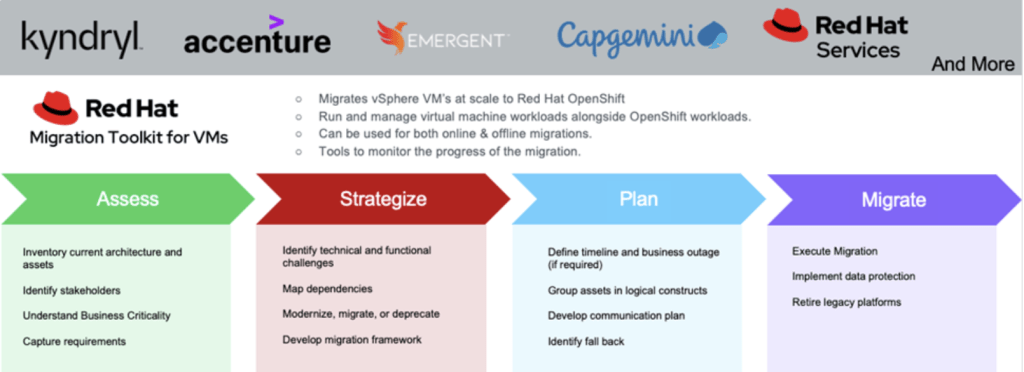
Hình 2: Hệ sinh thái đối tác phong phú
Các cân nhắc sau di chuyển
Sau khi làm theo hướng dẫn của blog này, hầu hết nỗ lực cho quá trình di chuyển được tập trung vào giai đoạn đầu; trong đó giai đoạn sau di chuyển chủ yếu liên quan đến việc dọn dẹp và ngừng hoạt động các hệ thống vật lý và ảo cũ. Các mục phổ biến bao gồm đảm bảo IPAM được cập nhật, loại bỏ bất kỳ mục nhập nào cho các VMs không còn tồn tại, kiểm tra chính sách bảo mật hiện có và đảm bảo nguyên tắc đặc quyền tối thiểu được thực thi. Đánh giá hiệu suất thường là một ý tưởng hay để hiểu cách các khối lượng công việc đang hoạt động sau di chuyển và điều chỉnh phân bổ tài nguyên khi cần thiết. Khi làm việc cho GSI lớn, thường thì ba tháng cuối của các dự án của chúng tôi được dành để viết tài liệu và chuyển giao kiến thức, để đảm bảo hệ thống mới có thể được duy trì và mở rộng khi cần. Và tất nhiên, điều quan trọng là phải triển khai sao lưu và phục hồi thảm họa cho OpenShift Virtualization, điều này dẫn tôi đến phần cuối cùng của blog này: Bảo vệ các khối lượng công việc Red Hat OpenShift bằng Veeam Kasten.
Vai trò của Veeam Kasten trong việc hỗ trợ các khối lượng công việc đã di chuyển
Mặc dù chúng tôi đặt phần này ở cuối bài viết, nhưng nó thực sự nên được xem xét sớm hơn nhiều trong quá trình – thực sự là trong các giai đoạn lựa chọn nền tảng và lập kế hoạch trước khi di chuyển. Hãy nhớ lại cách chúng tôi đã nhấn mạnh trong phần Thách thức ngành rằng một số phần mềm, công cụ và quy trình có thể được tận dụng trong nền tảng mới, và một số sẽ cần được cấu hình lại hoặc xác định lại? Bảo vệ dữ liệu chắc chắn là một trong số đó. Và tin tốt là bất kể bạn chọn con đường hay nền tảng nào, Veeam đều hỗ trợ bạn.
Nếu Red Hat OpenShift là một phần trong chiến lược hiện đại hóa VM và ứng dụng của bạn, bạn có thể sẽ muốn xem xét Veeam Kasten như một phương tiện để bảo vệ các khối lượng công việc đa dạng này. Và giống như Veeam Data Platform, Veeam Kasten là một công ty dẫn đầu trong lĩnh vực này, gần đây đã đạt được trạng thái “Outperformer” trong GigaOm Radar for Kubernetes Data Protection trong năm thứ sáu liên tiếp!
Nếu bạn là khách hàng hiện tại của Veeam Data Platform, bạn có thể tận dụng VBR server và các kho lưu trữ sao lưu hiện có của mình trong Kasten; ngoài ra, nó hỗ trợ object lock cho bất kỳ bộ lưu trữ tương thích S3 nào. Cuối năm nay, Veeam Backup & Replication sẽ phát hành hỗ trợ cho các OpenShift Virtualization VMs, như một tùy chọn cho các khách hàng Veeam hiện tại muốn đơn giản là nâng và chuyển các khối lượng công việc VM mà không cần sao lưu khối lượng công việc containerized hoặc kế hoạch hiện đại hóa ứng dụng thành kiến trúc cloud-native. Cuối cùng, nhưng không kém phần quan trọng, Kasten có thể tận dụng hoàn toàn Veeam Vault làm mục tiêu sao lưu, để đảm bảo dữ liệu VM và container của tổ chức bạn an toàn khỏi các cuộc tấn công ransomware. Đối với bộ lưu trữ chính, Kasten hỗ trợ bất kỳ mảng lưu trữ hoặc kiến trúc siêu hội tụ nào có CSI driver hỗ trợ khả năng volumeSnapshot.
Điều đáng nói là Kasten là một trong số ít các giải pháp sao lưu OpenShift Virtualization cung cấp sao lưu đĩa chế độ block, cho phép bạn và tổ chức của bạn tận dụng bộ lưu trữ VM hiệu suất cao nhất, thay vì phải thiết kế xung quanh việc sử dụng đĩa chế độ Filesystem cho các OpenShift Virtualization VMs của bạn. Hơn nữa, không giống như các giải pháp sao lưu khác, Kasten cung cấp khả năng sao lưu gia tăng cùng với tính năng deduplication và mã hóa tích hợp cho các VMs, giúp tối ưu hóa hiệu suất sao lưu và phục hồi cũng như giảm thiểu dung lượng lưu trữ sao lưu.
Ngoài việc bảo vệ dữ liệu, Kasten còn cung cấp khả năng di chuyển ứng dụng và VM, cho phép bạn di chuyển một VM hoặc ứng dụng containerized từ cluster này sang cluster khác, ngay cả khi các cluster sử dụng bộ lưu trữ cơ bản khác nhau. Một ví dụ tuyệt vời về điều này trong trường hợp sử dụng Disaster Recovery hot/warm được nêu bật trong Kiến trúc tham chiếu Veeam Kasten và Red Hat OpenShift Virtualization, trong đó một cluster OpenShift Bare Metal tại chỗ đóng vai trò là trang web chính và một cluster Red Hat OpenShift in AWS (ROSA) được thu nhỏ đóng vai trò là trang web phục hồi thảm họa.
Hình 3: Di chuyển các VM VMware sang OpenShift
Kết luận
Red Hat OpenShift Virtualization đang nổi lên như một nền tảng thế hệ tiếp theo hàng đầu. Với khả năng lưu trữ cả khối lượng công việc VM và cloud-native, nó có thể đóng vai trò là một nền tảng duy nhất cho tất cả các khối lượng công việc. Các tổ chức có thể giảm thiểu chi phí cấp phép, hợp nhất các hoạt động và áp dụng kiến trúc cloud-native tốt hơn – tất cả đều với sự hỗ trợ cấp doanh nghiệp. Với operator OpenShift Virtualization và Migration Toolkit for Virtualization của Red Hat, các tổ chức có thể dễ dàng di chuyển VMware vSphere của họ sang Red Hat OpenShift sau một chút lập kế hoạch và chuẩn bị. Và đối với những doanh nghiệp đang tìm kiếm sự giúp đỡ, Red Hat Services hoặc Global System Integrators luôn sẵn sàng hỗ trợ.
Và sau khi di chuyển, Veeam sẽ hỗ trợ bạn với một giải pháp bảo vệ dữ liệu cấp doanh nghiệp và có khả năng chống chịu trong tương lai.
Về tác giả

Ryan Niksch
Ryan Niksch là Kiến trúc sư giải pháp đối tác tập trung vào các nền tảng ứng dụng, giải pháp ứng dụng hybrid và hiện đại hóa. Ryan đã đảm nhiệm nhiều vai trò trong cuộc đời mình và có niềm đam mê mày mò cùng mong muốn để lại mọi thứ anh chạm vào tốt hơn một chút so với khi anh tìm thấy nó.
