Tác giả: Siddharth Gupta, Ishneet Kaur, Mohan Gandhi, Navneet Srivastava, Shubham Mehta, Amit Sinha, Subrat Das, và Vikramank Singh
Ngày phát hành: 03 FEB 2026
Chuyên mục: Amazon SageMaker Unified Studio, Artificial Intelligence, Best Practices, Customer Solutions
Thực hiện nghiên cứu và phân tích lâm sàng trên lượng lớn dữ liệu lâm sàng có thể gặp nhiều khó khăn. Các nhà khoa học dữ liệu y tế và nhà dịch tễ học sở hữu chuyên môn sâu về chăm sóc bệnh nhân, mô hình bệnh tật và kết quả lâm sàng, nhưng họ thường mất hàng tuần để điều hướng các cơ sở hạ tầng dữ liệu phức tạp, viết mã boilerplate và vật lộn với các rào cản kỹ thuật trước khi có thể trả lời một câu hỏi lâm sàng duy nhất. Điều này làm chậm quá trình nghiên cứu và trì hoãn các quyết định dựa trên bằng chứng, có thể ảnh hưởng đến việc chăm sóc bệnh nhân.
Vào ngày 21 tháng 11 năm 2025, Amazon SageMaker đã giới thiệu một data agent tích hợp trong Amazon SageMaker Unified Studio giúp biến đổi việc phân tích dữ liệu quy mô lớn. Amazon SageMaker Data Agent có tính năng nhận biết ngữ cảnh giúp tiết kiệm thời gian kết nối với dữ liệu lâm sàng trên các cơ sở dữ liệu lâm sàng, nhóm bệnh nhân và siêu dữ liệu tổ chức, đồng thời tự động chia nhỏ các yêu cầu phân tích phức tạp thành các kế hoạch có cấu trúc, có thể thực thi. Ví dụ, khi bạn đặt câu hỏi lâm sàng, “So sánh các mô hình bệnh đồng mắc giữa nhóm bệnh nhân tiểu đường và tăng huyết áp,” data agent sẽ suy nghĩ về vấn đề một cách có hệ thống. Nó tạo ra một kế hoạch phân tích nhiều bước, xác định các bảng lâm sàng liên quan, xác định các phương pháp thống kê phù hợp, tạo mã đã được xác thực bằng ngôn ngữ tối ưu (SQL, Python hoặc PySpark), và thực hiện từng bước với các điểm kiểm tra tích hợp để con người giám sát. SageMaker Data Agent được thiết kế để tuân thủ các kiểm soát bảo mật và chính sách quản trị hiện có của khách hàng, giúp hỗ trợ các yêu cầu tuân thủ của khách hàng bằng cách hoạt động trong khuôn khổ dữ liệu tổ chức của khách hàng.
Trong bài đăng này, chúng tôi trình bày, thông qua một nghiên cứu điển hình chi tiết về một nhà dịch tễ học thực hiện phân tích nhóm bệnh nhân lâm sàng, cách SageMaker Data Agent có thể giúp giảm thời gian chuẩn bị dữ liệu từ hàng tuần xuống còn vài ngày, và thời gian phát triển phân tích từ vài ngày xuống còn vài giờ—cuối cùng đẩy nhanh con đường từ câu hỏi lâm sàng đến kết luận nghiên cứu.
Những thách thức chính trong việc tăng tốc phân tích dữ liệu y tế
Nghiên cứu y tế trong môi trường phòng thí nghiệm, môi trường lâm sàng, trung tâm y tế học thuật, chính phủ và các cơ sở thương mại tạo ra khối lượng lớn dữ liệu lâm sàng. Những thách thức chính bao gồm:
- Điều hướng dữ liệu lâm sàng phức tạp – Các danh mục dữ liệu lâm sàng sử dụng thuật ngữ y tế và hệ thống mã hóa chuyên biệt đòi hỏi chuyên môn để điều hướng. Việc tìm kiếm bảng nào chứa các nhóm bệnh nhân liên quan và hiểu cách các mã điều kiện ánh xạ qua các hệ thống phân loại khác nhau tạo ra một thách thức khám phá đáng kể trước khi phân tích bắt đầu.
- Chuẩn bị dữ liệu kỹ thuật để phân tích – Sau khi dữ liệu được định vị, các nhà phân tích y tế dành một lượng thời gian đáng kể để thực hiện công việc mã hóa chuyên sâu, viết các script Python hoặc PySpark để trích xuất nhóm bệnh nhân, tính toán các chỉ số lâm sàng và thực hiện phân tích thống kê. Gánh nặng kỹ thuật này đặc biệt nghiêm trọng vì các nhà nghiên cứu lâm sàng thường là chuyên gia về dịch tễ học hoặc thống kê sinh học chứ không phải kỹ sư phần mềm.
Cách SageMaker Data Agent tăng tốc phân tích dữ liệu y tế
SageMaker Data Agent cung cấp giao diện dựa trên ngôn ngữ tự nhiên để các chuyên gia y tế tương tác với dữ liệu lâm sàng. Thay vì chỉ tạo các đoạn mã, nó hoạt động như một trợ lý nghiên cứu thông minh, nỗ lực hiểu môi trường dữ liệu cụ thể và mục tiêu lâm sàng của bạn. Nó trực tiếp giải quyết các thách thức chính đã nêu ở trên:
- Điều hướng dữ liệu lâm sàng phức tạp – SageMaker Data Agent được tích hợp với AWS Glue Data Catalog để ánh xạ toàn bộ cảnh quan dữ liệu y tế của bạn. Agent hiểu các bảng lâm sàng thực tế của bạn—thông tin nhân khẩu học bệnh nhân, chẩn đoán, lượt khám, tình trạng, thuốc men, tiêm chủng, thủ tục—bằng tên và mối quan hệ thực tế của chúng, không phải các phần giữ chỗ chung chung. Nó nhận ra các mối quan hệ thời gian giữa các lượt khám, hiểu cách các mã chẩn đoán được cấu trúc và điều hướng các hệ thống phân cấp phức tạp của dữ liệu lâm sàng mà không yêu cầu bạn phải ghi nhớ các lược đồ cơ sở dữ liệu.
- Chuẩn bị dữ liệu kỹ thuật để phân tích – Agent chuyển đổi các câu hỏi lâm sàng bằng ngôn ngữ tự nhiên thành mã phân tích sẵn sàng cho sản xuất, giảm giờ phát triển mã. Nó tạo mã tối ưu trên SQL để trích xuất nhóm bệnh nhân hiệu quả, Python để phân tích thống kê và PySpark để xử lý dữ liệu quy mô lớn, đồng thời giúp các nhà nghiên cứu lâm sàng sử dụng đúng công cụ mà không cần chuyên môn về từng ngôn ngữ. Nó cũng tạo ra một kế hoạch phân tích nhiều bước có cấu trúc phản ánh cách các nhà nghiên cứu lâm sàng có kinh nghiệm tiếp cận vấn đề: định nghĩa nhóm bệnh nhân, sau đó là đặc điểm cơ bản, sau đó là so sánh thống kê và cuối cùng là trực quan hóa. Mỗi bước bao gồm các điểm xác thực để người dùng xem xét quy trình của data agent, điều này sẽ giúp đảm bảo tính hợp lệ lâm sàng, xử lý đúng dữ liệu bị thiếu và sử dụng các phương pháp thống kê phù hợp. Cách tiếp cận theo kiểu agent này giúp bạn chuyển thời gian từ chuẩn bị kỹ thuật sang diễn giải lâm sàng.
Tổng quan giải pháp
Trong bài đăng này, chúng tôi khám phá thông qua một ví dụ hư cấu về cách SageMaker Data Agent có thể hỗ trợ nghiên cứu và phân tích lâm sàng. Trong trường hợp sử dụng này, một nhà dịch tễ học tại một trung tâm y tế học thuật thực hiện phân tích chi tiết các tình trạng lâm sàng như viêm xoang, tiểu đường và tăng huyết áp thông qua so sánh nhóm bệnh nhân và phân tích khả năng sống sót. Quy trình làm việc truyền thống của họ bao gồm điều hướng nhiều hệ thống không kết nối để định vị tập dữ liệu, chờ phê duyệt quyền truy cập, hiểu các lược đồ dữ liệu phức tạp và viết mã Python và PySpark mở rộng—một quy trình kéo dài nhiều tuần, trong đó phần lớn thời gian của họ dành cho chuẩn bị dữ liệu thay vì phân tích lâm sàng thực tế. Nút thắt này giới hạn họ chỉ thực hiện 2–3 nghiên cứu toàn diện mỗi quý, trực tiếp làm chậm các hiểu biết phân tích.
Với SageMaker Data Agent được hỗ trợ bởi AI, bạn có thể xem các tập dữ liệu có thể truy cập của mình khi đăng nhập, xác thực chất lượng dữ liệu bằng các bản xem trước nhanh và sử dụng nó để thực hiện phân tích thông qua các lời nhắc bằng ngôn ngữ tự nhiên—giảm nỗ lực mã hóa thủ công. SageMaker Data Agent được thiết kế để tăng tốc năng lực nghiên cứu của bạn, điều này có thể giúp xác định các mô hình điều trị sớm hơn. Bằng cách chuyển phần lớn thời gian của bạn từ chuẩn bị dữ liệu sang phân tích thực tế, SageMaker Data Agent giúp bạn cung cấp kết quả nghiên cứu hiệu quả hơn đồng thời giảm chi phí cơ sở hạ tầng. SageMaker Data Agent có hai chế độ tương tác để hỗ trợ phân tích của bạn:
- Bảng điều khiển Agent để phân tích lâm sàng toàn diện – Lý tưởng cho các dự án nghiên cứu từ đầu đến cuối. Chế độ này chia nhỏ các câu hỏi chăm sóc sức khỏe phức tạp thành các bước phân tích có cấu trúc với các điểm xem xét trung gian, duy trì sự giám sát của con người trong suốt quá trình.
- Hỗ trợ nội tuyến cho các tác vụ tập trung – Lý tưởng cho các nhà nghiên cứu có kinh nghiệm muốn được trợ giúp có mục tiêu với các thách thức mã hóa cụ thể, sửa lỗi hoặc cải tiến mã trong khi vẫn duy trì quyền kiểm soát trực tiếp quy trình làm việc của họ.
Trong cả hai chế độ, SageMaker Data Agent hoạt động an toàn trong môi trường AWS của bạn, tuân thủ các chính sách AWS Identity and Access Management (IAM) và ranh giới dữ liệu tổ chức, giúp bạn duy trì các kiểm soát bảo mật của mình trong khi tăng tốc phân tích lâm sàng.
Trong các phần sau, chúng tôi sẽ hướng dẫn bạn quy trình sử dụng SageMaker Data Agent.
Điều kiện tiên quyết
Chúng tôi đã chọn Synthea làm công cụ để tạo dữ liệu bệnh nhân tổng hợp ở định dạng CSV, bao gồm dữ liệu về bệnh nhân, tình trạng, tiêm chủng, dị ứng, lượt khám và thủ tục. Synthea là một trình tạo bệnh nhân tổng hợp mã nguồn mở (được phân phối và sử dụng theo Giấy phép Apache 2.0) mô hình hóa lịch sử y tế của các bệnh nhân tổng hợp. Không có dữ liệu người thật nào được sử dụng trong bài đăng này.
Là một phần của thiết lập SageMaker, hãy mở bảng điều khiển SageMaker và chọn Get started để tạo một domain dựa trên IAM và một project có tên ClinicalDataProject. Để biết hướng dẫn thiết lập domain dựa trên IAM và tạo project, hãy tham khảo IAM-based domains and projects.
Xem trước dữ liệu lâm sàng bằng SQL
Để xem trước dữ liệu bằng SQL, hãy hoàn thành các bước sau:
- Trên bảng điều khiển SageMaker, chọn Open, sau đó chọn project bạn đã tạo (
ClinicalDataProject).

Bạn sẽ được chuyển hướng đến trang tổng quan của SageMaker Unified Studio.
- Chọn Data trong ngăn điều hướng.
- Mở rộng
AWSDataCatalogđể xem dữ liệu đã được tải trước và lập danh mục mà bạn có quyền truy cập trong tài khoản của mình.
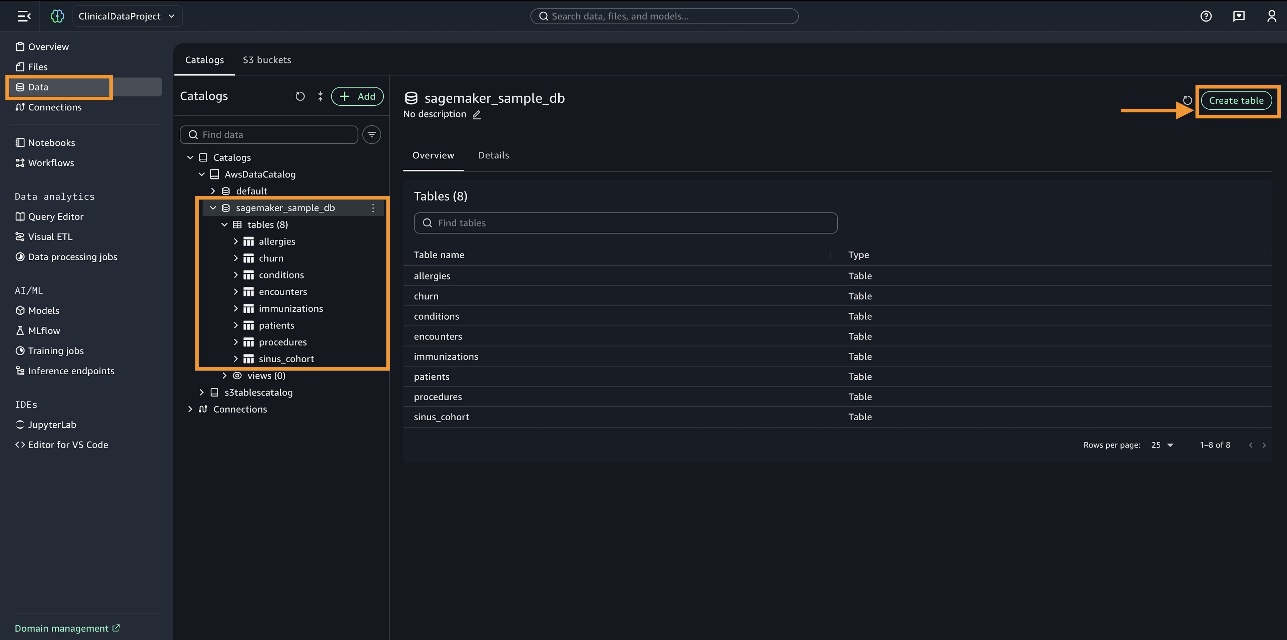
Đối với trường hợp sử dụng này, hãy tạo từng bảng (patients, conditions, immunizations, allergies, encounters, và procedures) dưới sagemaker_sample_db bằng cách sử dụng các tệp CSV mà bạn đã tạo trước đó bằng cách chọn Create table như hình dưới đây.
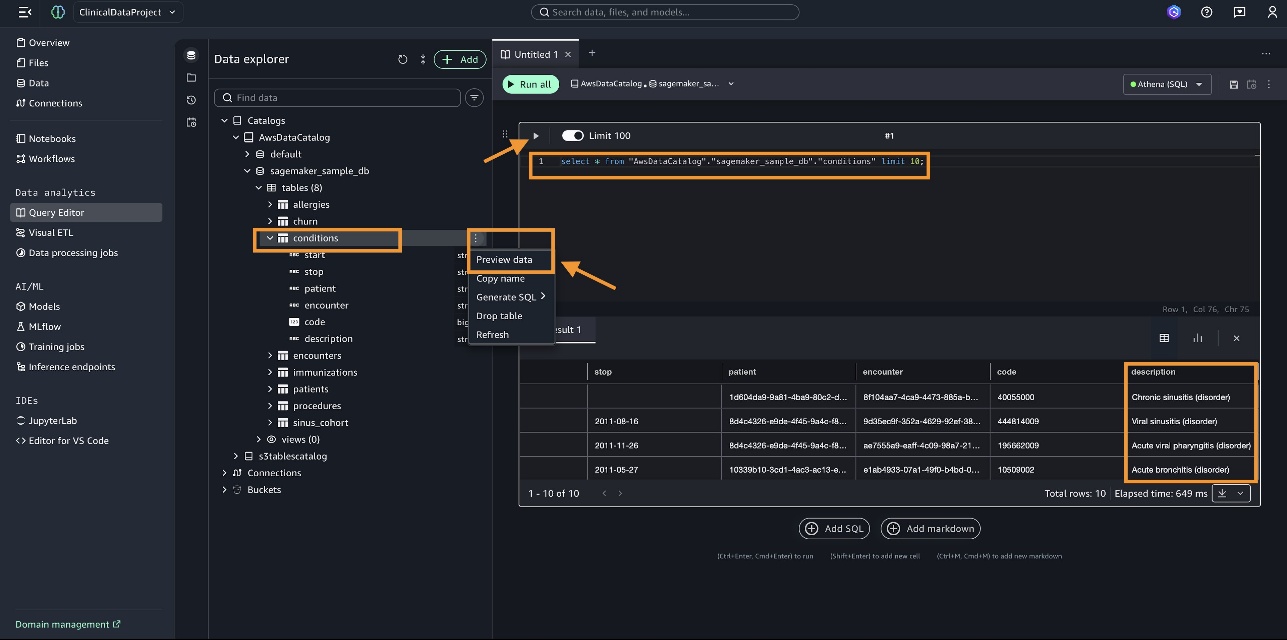
Trước khi bạn thực hiện phân tích lâm sàng phức tạp, hãy chạy một truy vấn cơ bản trên bảng conditions.
- Chọn bảng
conditionsvà chọn Preview data trên menu tùy chọn. - Thực hiện một thao tác SQL, ví dụ:
select * from "AwsDataCatalog"."sagemaker_sample_db"."conditions" limit 10
Tạo notebook
Để thực hiện phân tích chi tiết, bạn nên tạo một notebook. Hoàn thành các bước sau:
- Chọn Notebooks trong ngăn điều hướng.
- Chọn Create notebook.
Tương tác với dữ liệu
Sau khi bạn tạo notebook, bạn có thể tương tác với dữ liệu theo hai cách:
- Mã hóa trực tiếp trong các ô notebook bằng cách sử dụng giao diện nhắc lệnh nội tuyến. Ví dụ, nhập “Code to find patient records in conditions table who suffer from Sinusitis,” chọn Generate code, và chạy ô để hiển thị kết quả.
- Sử dụng bảng điều khiển Data Agent, hỗ trợ các tác vụ phân tích toàn diện bằng cách chia nhỏ chúng thành các bước có cấu trúc, mỗi bước với mã được tạo dựa trên kết quả trước đó.
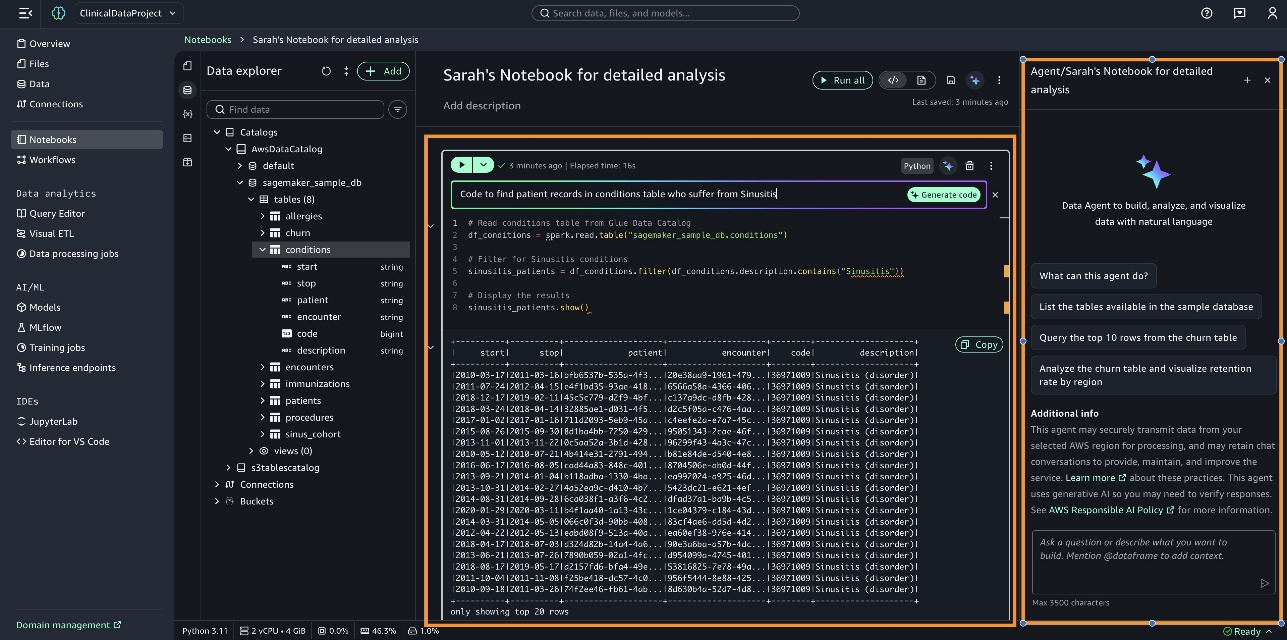
Trong các phần sau, chúng tôi cung cấp các ví dụ về việc sử dụng bảng điều khiển Data Agent.
Sử dụng SageMaker Data Agent để phân tích chi tiết dữ liệu lâm sàng
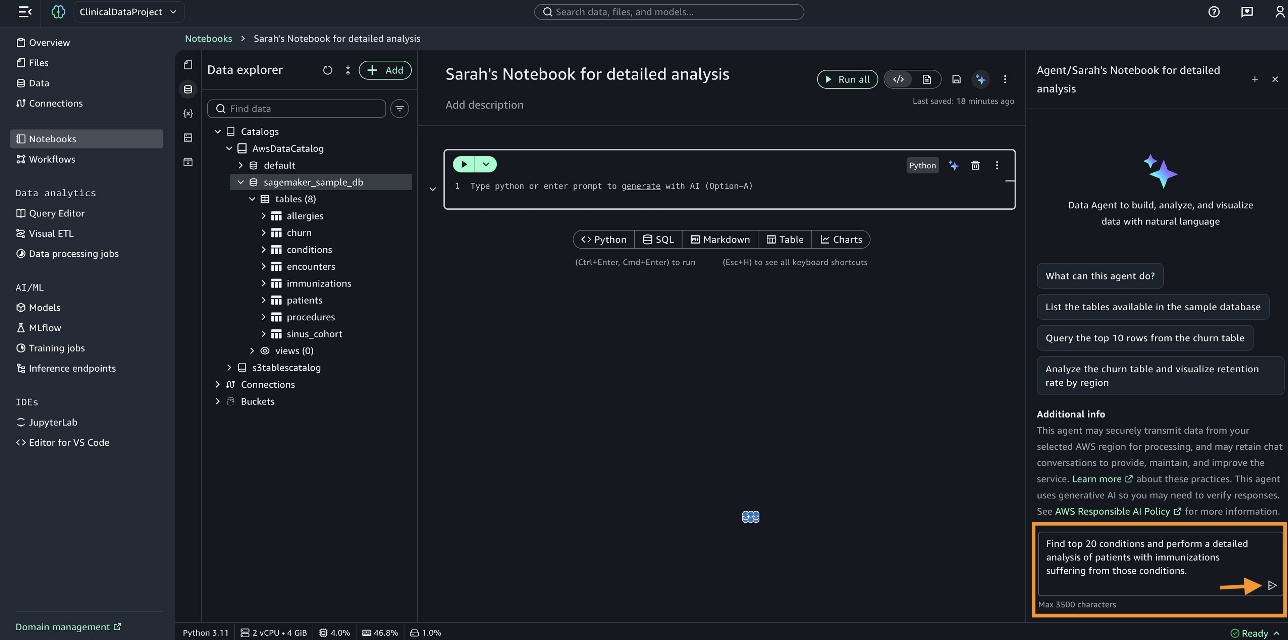
Trong bảng điều khiển Data Agent, chúng tôi nhập truy vấn “Find top 20 conditions and perform a detailed analysis of patients with immunizations suffering from those conditions” và tạo mã.
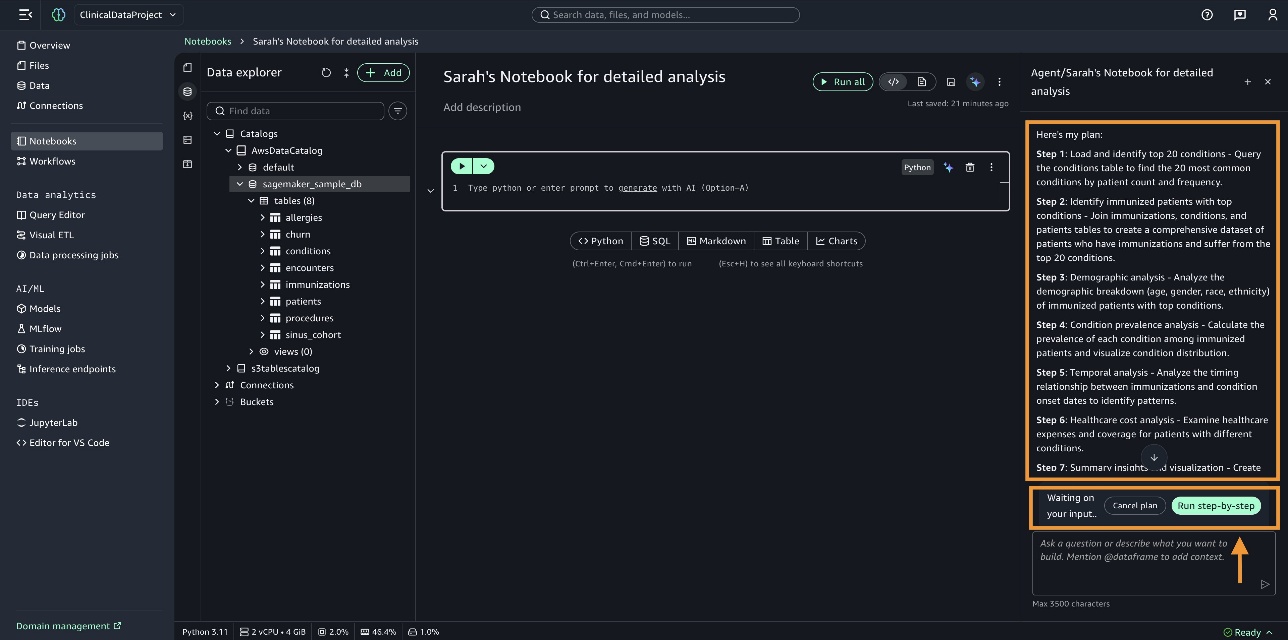
SageMaker Data Agent kiểm tra trạng thái hiện tại của notebook để hiểu dữ liệu chúng ta đang làm việc. Nó xác định các bảng conditions, immunizations, và patients trong cơ sở dữ liệu sagemaker_sample_db. Nó chuẩn bị một kế hoạch toàn diện và liệt kê chúng để bạn xem xét. Bạn có thể xem xét kế hoạch, thực hiện các thay đổi cần thiết nếu cần, sau đó chọn Run step-by-step.
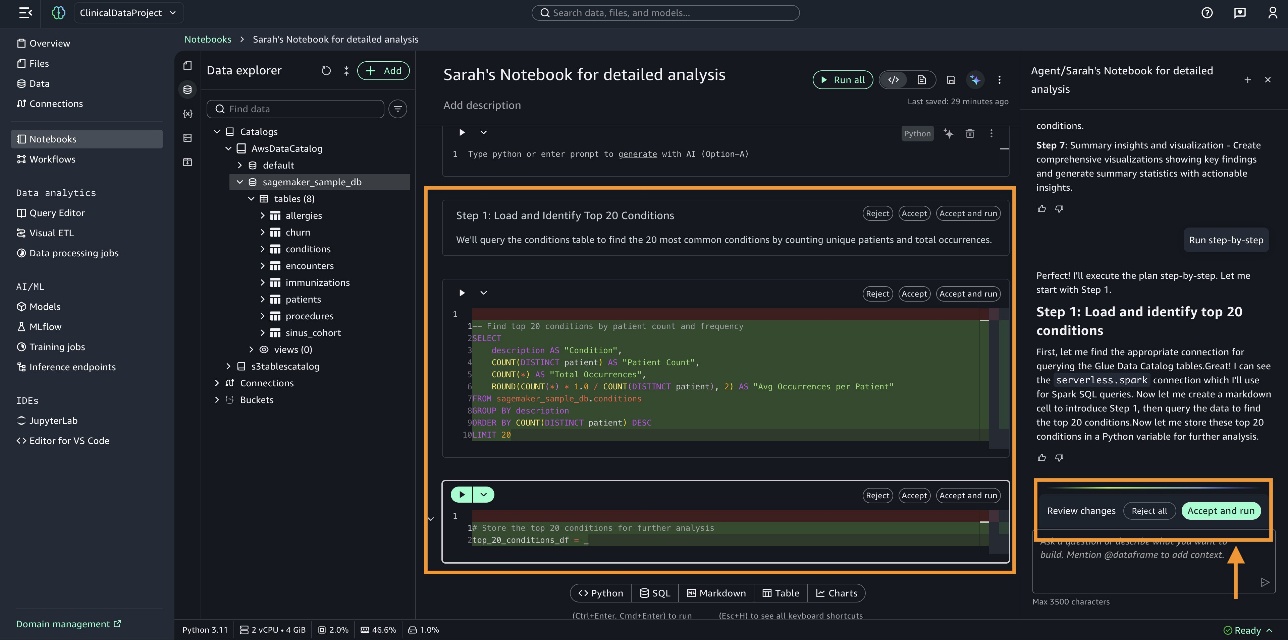
SageMaker Data Agent viết mã vào các ô notebook. Bạn có thể xem xét mã, sau đó chọn Accept and run.
Một số bước có thể không thực thi được. Trong trường hợp này, bạn có thể chọn Fix with AI để tiếp tục.
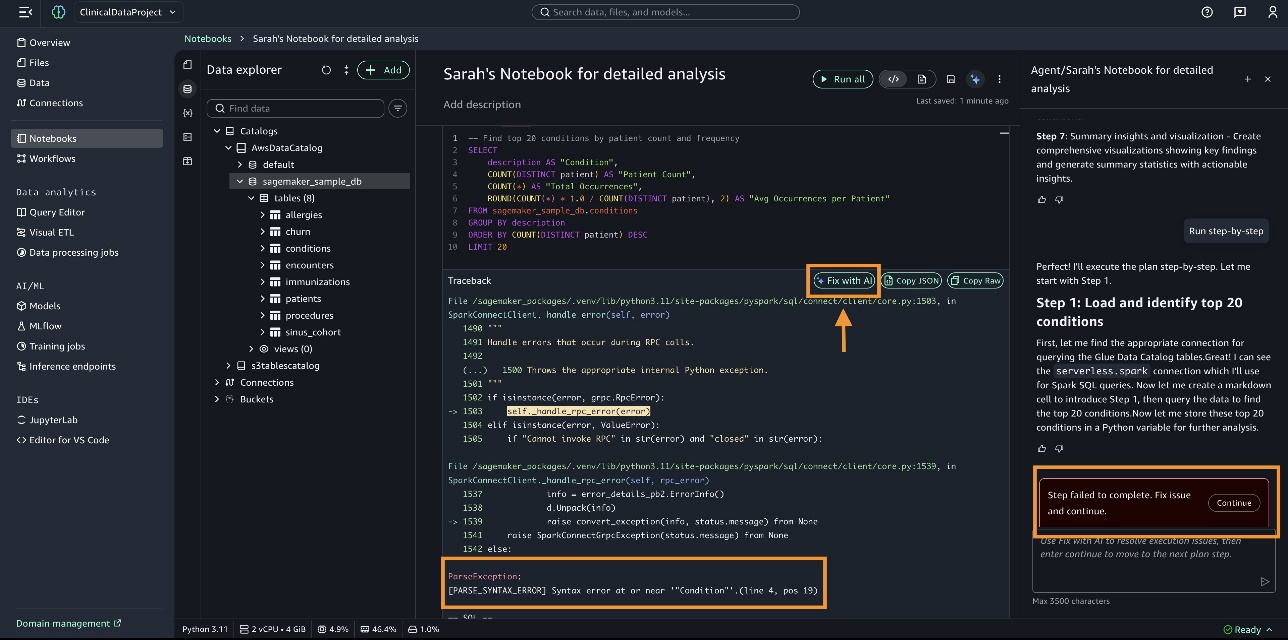
Khi truy vấn hoàn tất, kết quả sẽ được hiển thị, như trong ảnh chụp màn hình sau.
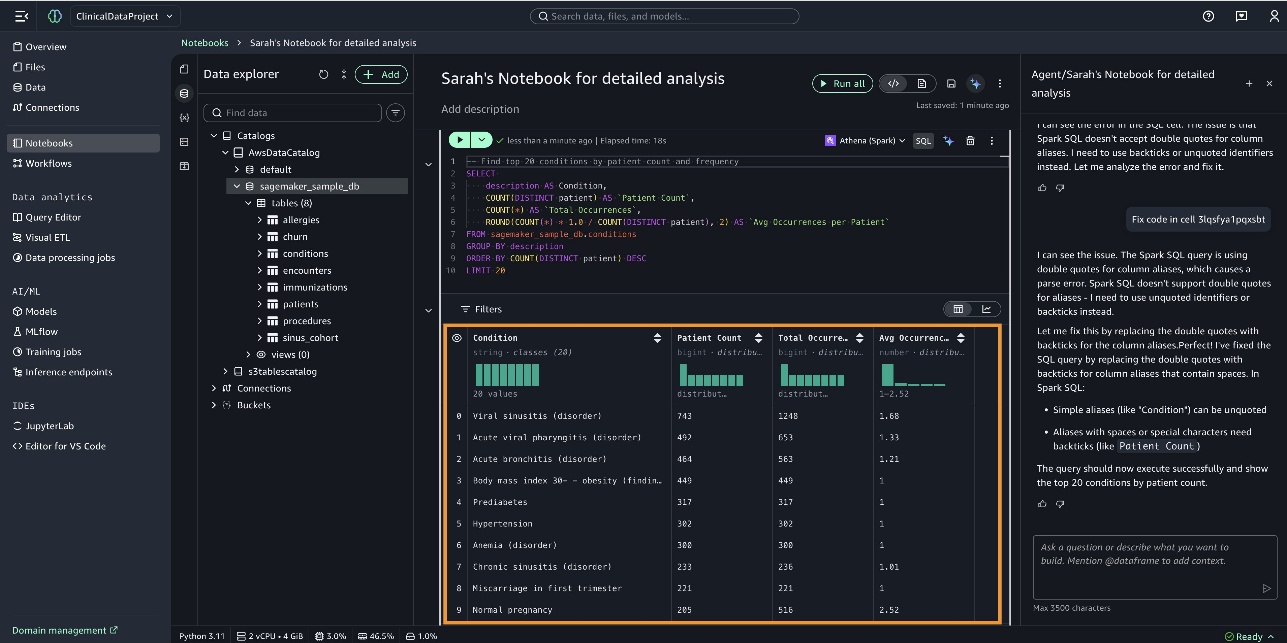
Bạn có thể thấy biểu đồ cột được tạo bởi SageMaker Data Agent trong notebook có tiêu đề Demographics Analysis of Immunized Patients with Top 20 Conditions, như trong ảnh chụp màn hình sau.
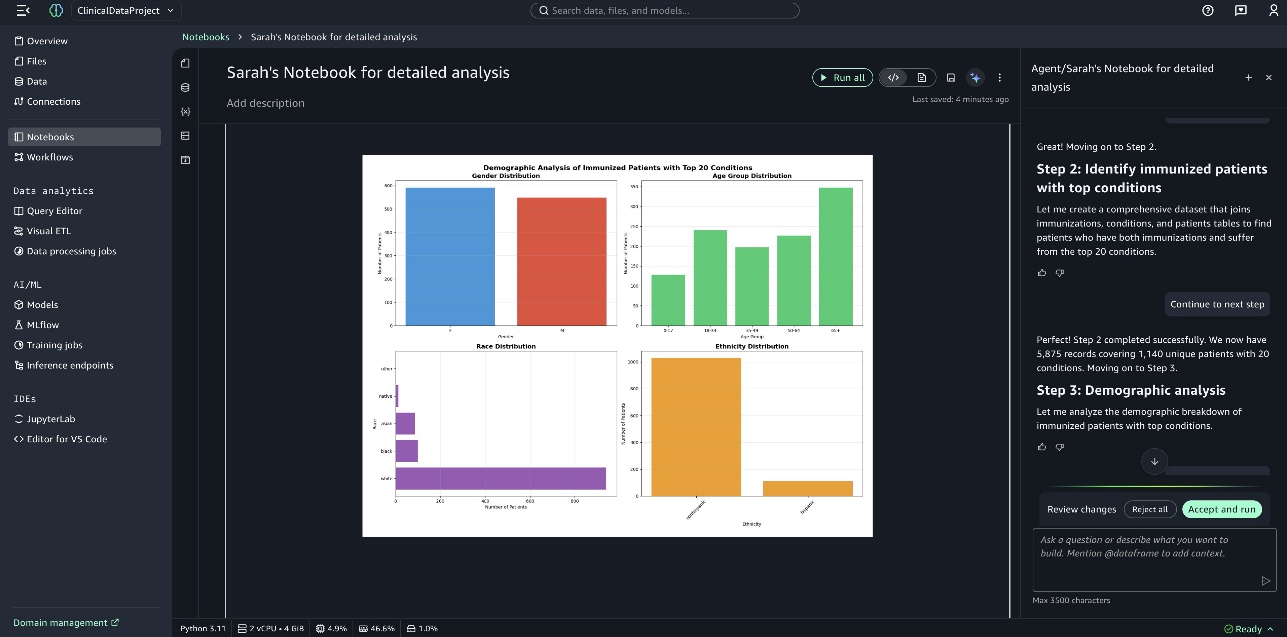
Ảnh chụp màn hình sau đây hiển thị biểu đồ Condition Prevalence Analysis of Immunized Patients with Top 20 Conditions.
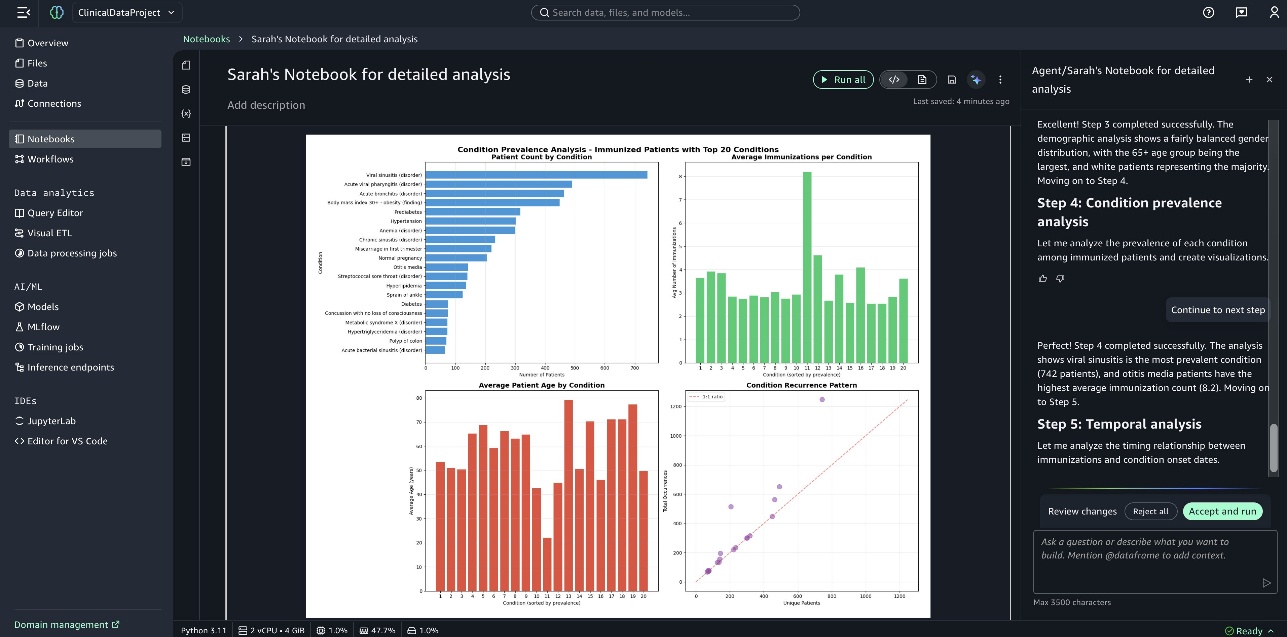
Ảnh chụp màn hình sau đây hiển thị biểu đồ Temporal Analysis of Condition Onset.
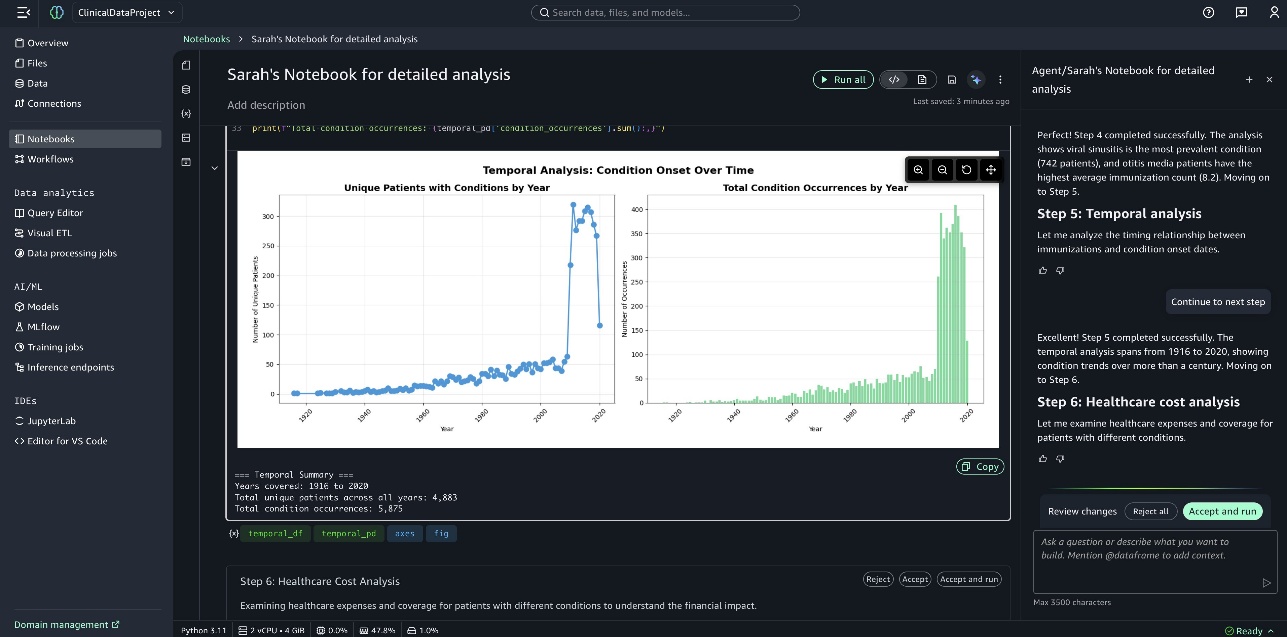
Một bảng điều khiển toàn diện được trình bày ở cuối notebook.
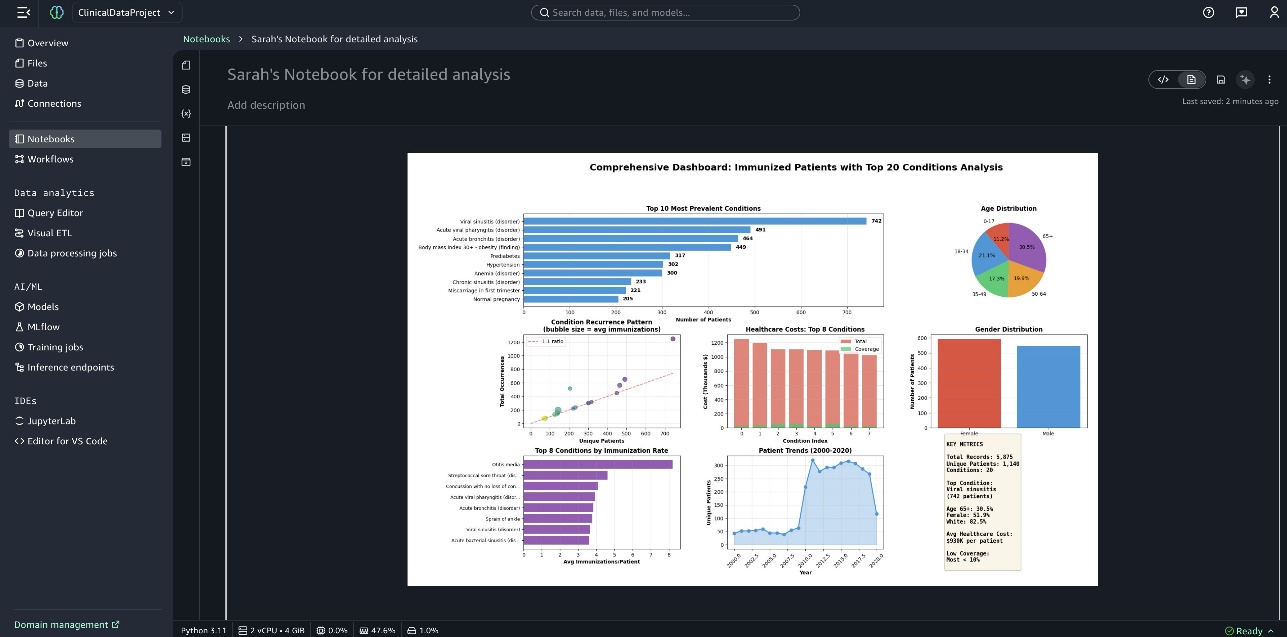
Sử dụng SageMaker Data Agent để so sánh nhóm bệnh nhân và phân tích khả năng sống sót
Viêm xoang do virus là tình trạng hàng đầu đối với bệnh nhân. Để thực hiện so sánh nhóm bệnh nhân và phân tích khả năng sống sót, chúng tôi nhập truy vấn sau vào bảng điều khiển Data Agent: “Build two cohorts 1/ Cohort for Male patients who are suffering from viral sinusitis 2/ Cohort for Female patients who are suffering from viral sinusitis. Run a detailed cohort comparison and survival analysis.”
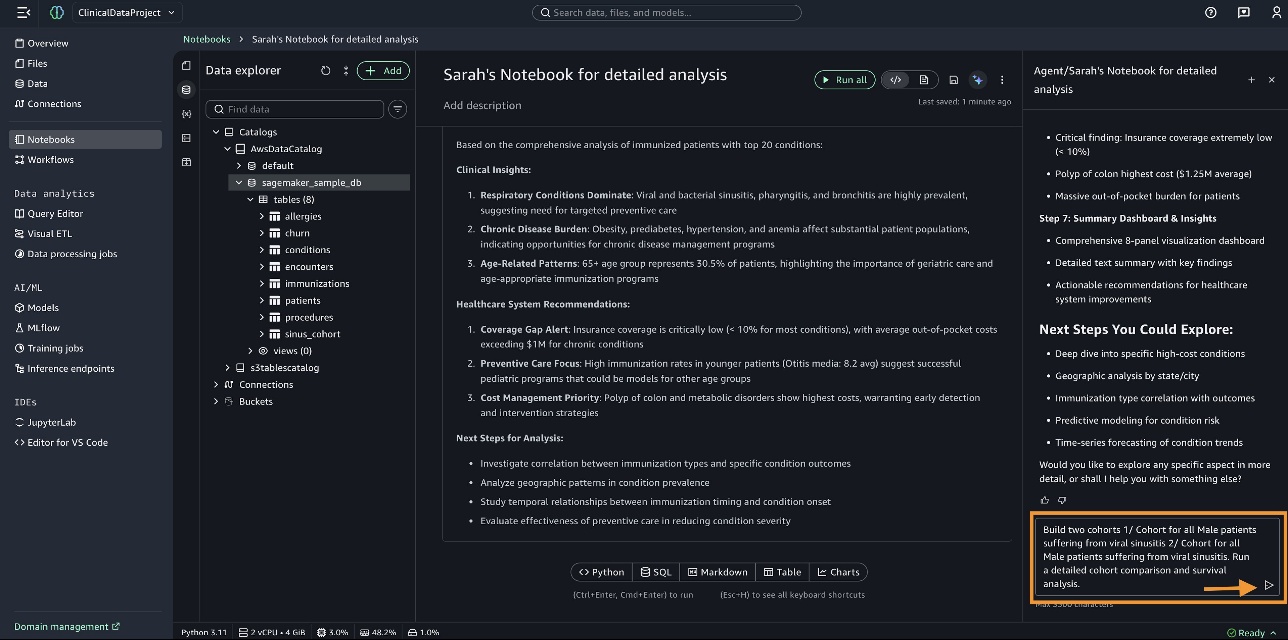
SageMaker Data Agent chuẩn bị một kế hoạch toàn diện để tạo nhóm bệnh nhân, phân tích so sánh nhóm bệnh nhân và phân tích khả năng sống sót. Bạn có thể xem xét kế hoạch và sau đó chọn Run step-by-step.
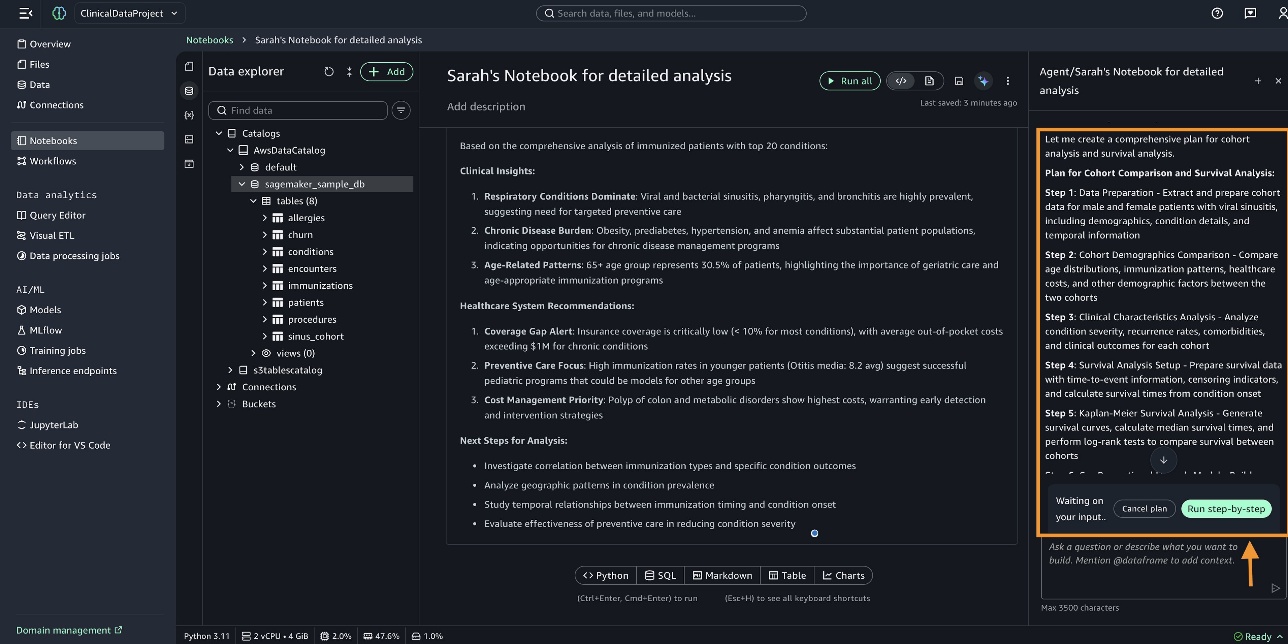
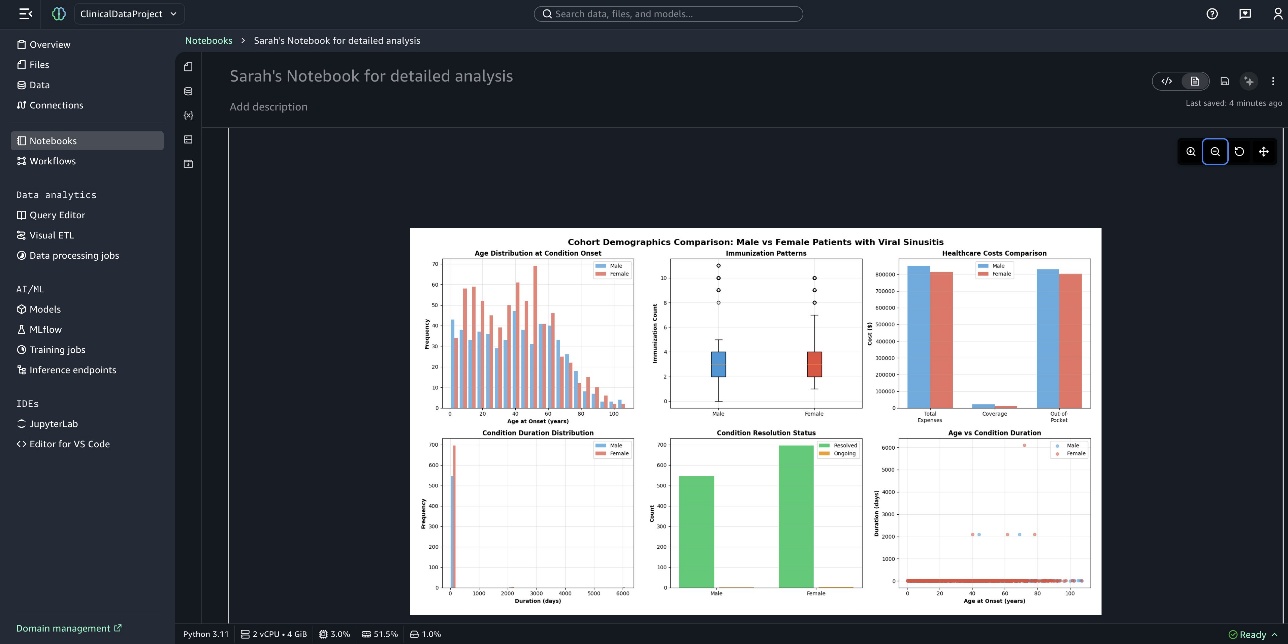
Ảnh chụp màn hình sau đây hiển thị biểu đồ Cohort Demographics Comparison: Male vs Female Patients with Viral Sinusitis.
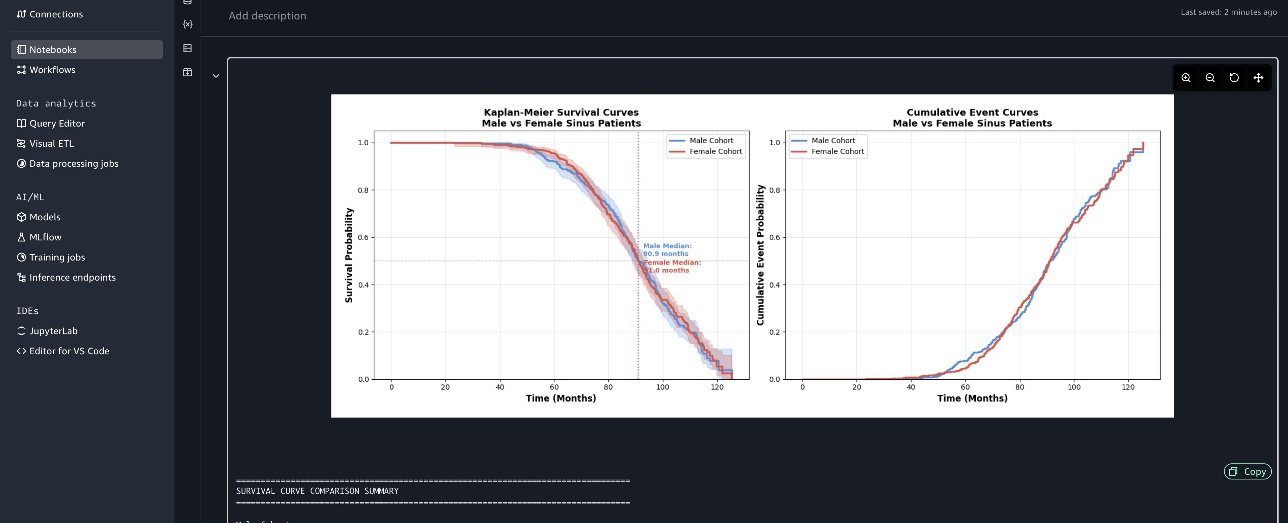
Ảnh chụp màn hình sau đây hiển thị các đường cong sống sót Kaplan-Meier và đường cong sự kiện tích lũy.
Dọn dẹp tài nguyên
Để xóa các tài nguyên AWS đã tạo trong quá trình hướng dẫn này, hãy hoàn thành các bước sau. Đầu tiên, xóa project SageMaker Unified Studio bằng cách điều hướng đến bảng điều khiển Amazon SageMaker Unified Studio, chọn project của bạn từ danh sách project, chọn Delete và xác nhận xóa. Thao tác này sẽ xóa tất cả các notebook, kết nối dữ liệu và tài nguyên project liên quan. Thứ hai, xóa các tài nguyên AWS Glue Data Catalog bằng cách mở bảng điều khiển AWS Glue, điều hướng đến Databases và xóa cơ sở dữ liệu mẫu đã được tạo cho hướng dẫn này. Thứ ba, xóa các S3 bucket và dữ liệu bằng cách mở bảng điều khiển Amazon S3, định vị S3 bucket nơi dữ liệu chăm sóc sức khỏe được lưu trữ, làm trống nội dung bucket và xóa bucket.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách SageMaker Data Agent tăng tốc độ làm việc phân tích dữ liệu, giúp bạn trích xuất những hiểu biết sâu sắc có tác động từ dữ liệu. SageMaker Data Agent giúp giảm thời gian dành cho quản lý dữ liệu, để bạn có thể dành nhiều thời gian hơn để xác định các mô hình điều trị và đưa ra các khuyến nghị dựa trên bằng chứng. Bằng cách đơn giản hóa quyền truy cập vào phân tích dữ liệu phức tạp thông qua tương tác ngôn ngữ tự nhiên, SageMaker Data Agent có thể giúp bạn tăng năng lực nghiên cứu đồng thời giảm chi phí cơ sở hạ tầng. Các phân tích được ghi lại trong các notebook có thể tái tạo, có thể được xác thực và kiểm toán bởi các bên liên quan lâm sàng, hỗ trợ tính minh bạch đồng thời đẩy nhanh con đường từ dữ liệu đến phân tích có tác động.
Về tác giả

Siddharth đang dẫn dắt Generative AI trong SageMaker’s Unified Experiences. Trọng tâm của anh là thúc đẩy các trải nghiệm agentic, nơi các hệ thống AI hoạt động tự chủ thay mặt người dùng để hoàn thành các tác vụ phức tạp. Là cựu sinh viên của Đại học Illinois tại Urbana-Champaign, anh mang đến kinh nghiệm sâu rộng từ các vai trò của mình tại Yahoo, Glassdoor và Twitch.

Navneet Srivastava là Chuyên gia chính và Trưởng nhóm Chiến lược Phân tích, phát triển các kế hoạch chiến lược để xây dựng chiến lược phân tích đầu cuối cho các tổ chức dược phẩm sinh học, chăm sóc sức khỏe và khoa học đời sống lớn. Chuyên môn của anh bao gồm phân tích dữ liệu, quản trị dữ liệu, AI, ML, dữ liệu lớn và các công nghệ liên quan đến chăm sóc sức khỏe.

Subrat Das là Kiến trúc sư Giải pháp chính và là một phần của bộ phận công nghiệp Chăm sóc sức khỏe và Khoa học đời sống toàn cầu tại AWS. Anh đam mê hiện đại hóa và kiến trúc các khối lượng công việc phức tạp của khách hàng. Khi không làm việc với các giải pháp công nghệ, anh thích đi bộ đường dài và du lịch vòng quanh thế giới.

Ishneet Kaur là Giám đốc Phát triển Phần mềm trong nhóm Amazon SageMaker Unified Studio. Cô dẫn dắt nhóm kỹ thuật thiết kế và xây dựng các khả năng AI tạo sinh trong SageMaker Unified Studio.

Mohan Gandhi là Kỹ sư Phần mềm chính tại AWS. Anh đã làm việc tại AWS trong 10 năm qua và đã làm việc trên nhiều dịch vụ AWS khác nhau như Amazon EMR, Amazon EFA và Amazon RDS. Hiện tại, anh tập trung vào việc cải thiện trải nghiệm suy luận của Amazon SageMaker. Trong thời gian rảnh rỗi, anh thích đi bộ đường dài và chạy marathon.

Vikramank Singh là Nhà khoa học ứng dụng cấp cao trong tổ chức Agentic AI tại AWS, làm việc trên các sản phẩm bao gồm Amazon SageMaker Unified Studio, Amazon RDS và Amazon Redshift. Lĩnh vực nghiên cứu của anh nằm ở giao điểm của AI, hệ thống điều khiển và RL, đặc biệt là sử dụng chúng để xây dựng các hệ thống cho các ứng dụng trong thế giới thực có thể tự động nhận thức môi trường, mô hình hóa chúng và đưa ra các quyết định tối ưu ở quy mô lớn.

Shubham Mehta là Giám đốc Sản phẩm cấp cao tại AWS Analytics. Anh dẫn dắt việc phát triển tính năng AI tạo sinh trên các dịch vụ như AWS Glue, Amazon EMR và Amazon MWAA, sử dụng AI/ML để đơn giản hóa và nâng cao trải nghiệm của các chuyên gia dữ liệu xây dựng ứng dụng dữ liệu trên AWS.

Amit Sinha là Giám đốc cấp cao dẫn dắt các bộ sản phẩm GenAI và ML của SageMaker Unified Studio. Anh có hơn một thập kỷ kinh nghiệm trong các sản phẩm AI/ML, quản lý cơ sở hạ tầng và các dịch vụ xử lý dữ liệu lớn của AWS. Là cựu sinh viên của Đại học Columbia, trong thời gian rảnh rỗi Amit thích đi bộ đường dài và xem các bộ phim tài liệu về lịch sử Hoa Kỳ.
