Tác giả: Ruben Simon, Fabian Söllner, Florian Seidel, Khalid Al Khalili, Martin Maritsch, and Shukhrat Khodjaev
Ngày phát hành: 30 JAN 2026
Chuyên mục: Amazon Athena, Amazon Bedrock AgentCore, Automotive, AWS Lambda, Industries
BMW Group, có trụ sở chính tại Munich, Đức, sử dụng 159.000 nhân viên tại hơn 30 cơ sở sản xuất và lắp ráp ở 15 quốc gia. Là một nhà lãnh đạo đổi mới trong ngành ô tô, BMW Group đã và đang nỗ lực đi đầu trong chuyển đổi số bằng cách sử dụng dữ liệu và trí tuệ nhân tạo (AI). Năm 2020, BMW Group đã ra mắt Cloud Data Hub (CDH), hiện đang hoạt động như một Data Lakehouse – nền tảng trung tâm của BMW Group để quản lý dữ liệu và các giải pháp dữ liệu toàn công ty trên đám mây. Nền tảng này cung cấp cho nhân viên BMW Group trên tất cả các bộ phận của công ty một điểm khởi đầu trung tâm để triển khai các ứng dụng dựa trên dữ liệu và tạo ra thông tin chi tiết từ dữ liệu.
Ngày nay, CDH lưu trữ 20 PB dữ liệu và tiếp nhận trung bình 110 TB dữ liệu mỗi ngày. Việc trích xuất thông tin chi tiết từ kho dữ liệu khổng lồ này có thể là một thách thức, đặc biệt đối với những người dùng thiếu chuyên môn kỹ thuật và phân tích, vì họ cần xác định các nguồn dữ liệu liên quan, xây dựng các truy vấn phức tạp và diễn giải các đầu ra dạng bảng.
Trong bài đăng này, chúng tôi minh họa cách BMW Group, hợp tác với AWS Professional Services, đã phát triển giải pháp tìm kiếm tác nhân kết hợp khả năng của Amazon S3 Vectors, Amazon Bedrock, và Amazon Bedrock AgentCore. Giải pháp này được thiết kế để giúp người dùng BMW Group, bất kể kỹ năng kỹ thuật của họ, trích xuất thông tin chi tiết dữ liệu có thể hành động từ các tập dữ liệu khổng lồ bằng ngôn ngữ tự nhiên.
Thách thức: Thu hẹp khoảng cách giữa dữ liệu và thông tin chi tiết
Các quy trình phân tích dữ liệu truyền thống phức tạp và tốn thời gian, tạo ra rào cản trong việc nhanh chóng khai thác thông tin chi tiết có giá trị từ dữ liệu doanh nghiệp. Quá trình này bắt đầu bằng việc khám phá, yêu cầu người dùng tìm kiếm qua hàng chục, hàng trăm, hoặc thậm chí hàng nghìn tài sản dữ liệu để tìm ra các nguồn phù hợp. Tiếp theo, người dùng phải viết và thực thi các truy vấn SQL, đòi hỏi kiến thức về schema cho các phép nối và tổng hợp phức tạp. Sau khi tạo ra kết quả truy vấn, việc chuyển đổi đầu ra dạng bảng thô thành thông tin chi tiết có thể hành động thường đòi hỏi chuyên môn miền cụ thể. Những thách thức này, đặc biệt khi kết hợp dữ liệu có cấu trúc và phi cấu trúc, có thể hạn chế nghiêm trọng khả năng của một tổ chức trong việc tận dụng hiệu quả các tài sản dữ liệu của mình.
Tổng quan giải pháp
Giải pháp tìm kiếm tác nhân của BMW Group giải quyết thách thức trích xuất thông tin chi tiết từ các tập dữ liệu khổng lồ bằng cách kết hợp ba phương pháp tìm kiếm bổ sung trong một khung tác nhân AI. Giải pháp này cho phép người dùng truy vấn petabyte dữ liệu có cấu trúc và phi cấu trúc bằng ngôn ngữ tự nhiên, tự động chọn chiến lược tìm kiếm tối ưu dựa trên đặc điểm truy vấn.
Trong bài đăng này, chúng tôi giới thiệu giải pháp trên một tập dữ liệu từ hệ thống chất lượng sản phẩm, ghi lại chi tiết các vấn đề được báo cáo trong quá trình thử nghiệm xe. Mỗi bản ghi chứa mô tả vấn đề, phân loại và chi tiết kỹ thuật bằng cả tiếng Đức và tiếng Anh, được tích lũy từ các cơ sở sản xuất và trung tâm dịch vụ trên toàn thế giới. Tập dữ liệu này đại diện cho nhiều năm kiến thức kỹ thuật chất lượng, với các vấn đề có ý nghĩa tương tự được mô tả bằng các thuật ngữ khác nhau giữa các nhóm và ngôn ngữ.
Kiến trúc bao gồm ba công cụ chuyên biệt, mỗi công cụ được thiết kế cho các mẫu tìm kiếm cụ thể:
- Tìm kiếm lai (Hybrid Search): Kết hợp tìm kiếm tương đồng ngữ nghĩa với lọc SQL để truy xuất hiệu quả dữ liệu có khái niệm tương tự. Công cụ này trước tiên thực hiện tìm kiếm ngữ nghĩa dựa trên vector để xác định các bản ghi liên quan, sau đó áp dụng các bộ lọc SQL để tinh chỉnh chính xác. Nó lý tưởng cho các truy vấn như “tìm phản hồi hệ thống phanh trong các mẫu xe cụ thể” nơi cả hiểu biết khái niệm và lọc có cấu trúc đều được yêu cầu.
- Tìm kiếm toàn diện (Exhaustive Search): Sử dụng đánh giá được hỗ trợ bởi AI để phân tích toàn diện tất cả các bản ghi phù hợp khi tìm kiếm ngữ nghĩa một mình có thể bỏ lỡ các kết quả liên quan do sự khác biệt về thuật ngữ. Công cụ này thực thi một truy vấn SQL để truy xuất các bản ghi ứng cử viên, sau đó sử dụng một mô hình ngôn ngữ lớn (LLM) để đánh giá từng kết quả, xác định mức độ liên quan với lý do chi tiết. Nó đặc biệt hiệu quả cho các câu hỏi như “Có bao nhiêu vấn đề liên quan đến phanh đã xảy ra?” nơi cần có sự bao phủ hoàn chỉnh.
- Truy vấn SQL (SQL Query): Cung cấp khả năng truy vấn có cấu trúc trực tiếp để truy xuất dữ liệu chính xác khi không cần phân tích ngữ nghĩa. Công cụ này xử lý các truy vấn phân tích thuần túy như tổng hợp, đếm và phân tích thống kê trên các trường dữ liệu có cấu trúc.
Một tác nhân AI điều phối các công cụ này, phân tích từng truy vấn của người dùng để xác định chiến lược tìm kiếm phù hợp nhất. Tác nhân tự động chuyển đổi giữa tìm kiếm ngữ nghĩa cho các truy vấn khái niệm, tìm kiếm toàn diện cho phân tích tổng thể và SQL trực tiếp cho phân tích có cấu trúc—tất cả thông qua một giao diện hội thoại duy nhất. Định tuyến thông minh này cho phép người dùng nhận được kết quả liên quan mà không cần phải hiểu sự phức tạp kỹ thuật cơ bản hoặc tự chọn phương pháp tìm kiếm.
Kiến trúc chuyên sâu
Sơ đồ kiến trúc sau đây minh họa cách các thành phần này tương tác để mang lại trải nghiệm tìm kiếm tác nhân:
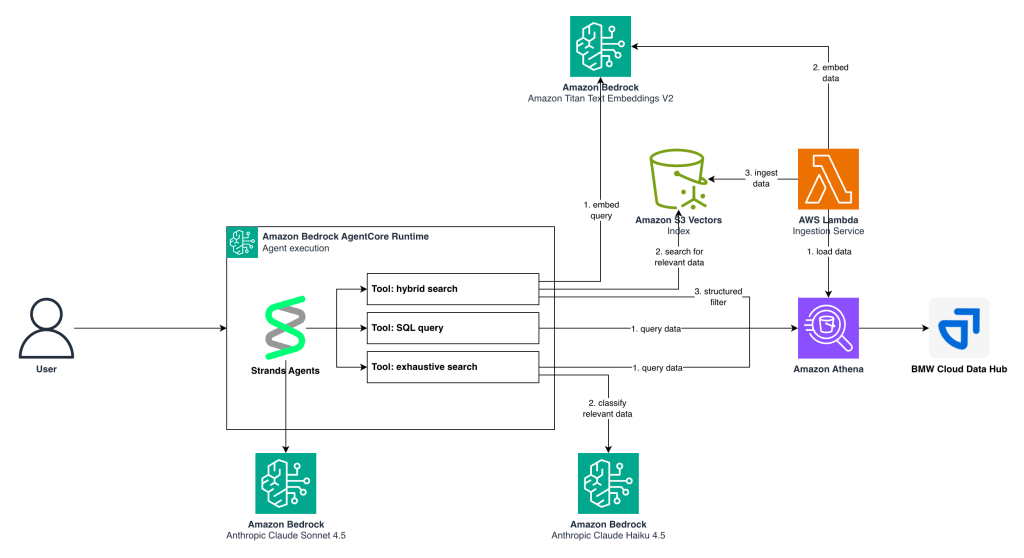
Hình 1. Kiến trúc giải pháp tìm kiếm tác nhân
Các thành phần cốt lõi
Lưu trữ dữ liệu và tìm kiếm vector
Amazon S3 Vectors (S3 Vectors) cho phép tìm kiếm tương đồng ngữ nghĩa trên các nhúng vector, hỗ trợ các truy vấn láng giềng gần nhất hiệu quả trên hàng triệu điểm dữ liệu mà không yêu cầu cơ sở hạ tầng cơ sở dữ liệu vector chuyên dụng. Đối với dữ liệu có cấu trúc trong S3 Vectors, Amazon Athena (Athena) cung cấp khả năng thực thi truy vấn SQL phi máy chủ, cho phép phân tích ad-hoc và lọc có cấu trúc trên dữ liệu nguồn gốc.
LLM và triển khai tác nhân
Amazon Bedrock cung cấp sức mạnh cho giải pháp với nhiều LLM: Amazon Titan Text Embeddings V2 (Titan Text Embeddings) để tạo nhúng vector, Anthropic’s Claude Sonnet 4.5 làm mô hình lý luận chính cho việc điều phối tác nhân, và Anthropic’s Claude Haiku 4.5 cho các tác vụ phân loại hiệu quả về chi phí trong tìm kiếm toàn diện. Strands Agents, khung mã nguồn mở của AWS, điều phối tác nhân AI bằng cách quản lý lựa chọn công cụ, luồng hội thoại và tương tác mô hình trong khi duy trì độ tin cậy cấp độ sản xuất.
Thu nạp dữ liệu và tạo chỉ mục vector
Trước khi giải pháp tìm kiếm tác nhân có thể trả lời các truy vấn, dữ liệu nguồn phải được xử lý và lập chỉ mục để tìm kiếm ngữ nghĩa. Ở đây, chúng tôi đã triển khai một pipeline thu nạp phi máy chủ sử dụng AWS Lambda (Lambda) để chuyển đổi các bản ghi cơ sở dữ liệu có cấu trúc bao gồm các thuộc tính văn bản tự do như tiêu đề hoặc mô tả, thành các nhúng vector có thể tìm kiếm được.
Quá trình thu nạp tuân theo các bước sau:
- Trích xuất dữ liệu: Các hàm Lambda truy vấn các bảng cơ sở dữ liệu nguồn trong Amazon Athena, truy xuất các bản ghi chất lượng sản phẩm bao gồm mô tả vấn đề, tiêu đề và phân loại bằng cả tiếng Đức và tiếng Anh.
- Chuẩn bị văn bản: Đối với mỗi bản ghi, pipeline nối các trường có liên quan về mặt ngữ nghĩa (tên cụm, tiêu đề vấn đề và mô tả) thành một biểu diễn văn bản thống nhất phù hợp để tạo nhúng.
- Tạo nhúng: Văn bản đã chuẩn bị được gửi đến Titan Text Embeddings, nơi tạo ra các nhúng vector 1.024 chiều nắm bắt ý nghĩa ngữ nghĩa của mỗi bản ghi.
- Lưu trữ vector: Các nhúng được lưu trữ trong Amazon S3 bằng định dạng chỉ mục S3 Vectors, với mỗi vector được gắn thẻ ID bản ghi tương ứng để truy xuất trong quá trình tìm kiếm.
- Lưu trữ siêu dữ liệu: Dữ liệu có cấu trúc gốc vẫn còn trong S3, có thể được truy vấn qua Athena, cho phép các công cụ tìm kiếm tác nhân kết hợp tương đồng ngữ nghĩa với lọc dựa trên SQL.
Kiến trúc thu nạp này xử lý dữ liệu một cách tăng dần, cho phép BMW Group liên tục cập nhật chỉ mục vector khi các vấn đề chất lượng sản phẩm mới được báo cáo mà không cần xử lý lại toàn bộ tập dữ liệu.
Tìm kiếm lai (Hybrid Search)
Công cụ tìm kiếm lai kết hợp tương đồng ngữ nghĩa với lọc SQL, cho phép người dùng tìm các bản ghi có liên quan về mặt khái niệm trong khi áp dụng các ràng buộc kinh doanh chính xác. Ví dụ, một truy vấn như “tìm phản hồi hệ thống phanh trong các xe F09 từ quý trước” yêu cầu cả hiểu biết ngữ nghĩa (những gì được coi là “phản hồi hệ thống phanh”) và lọc có cấu trúc (mẫu xe cụ thể và khoảng thời gian).
Cách hoạt động: Khi người dùng gửi một truy vấn, tác nhân gọi công cụ tìm kiếm lai với ba tham số: 1) một truy vấn ngữ nghĩa mô tả khái niệm cần tìm kiếm (ví dụ: “phản hồi hệ thống phanh”), 2) một giá trị top_k chỉ định số lượng bản ghi tương tự cần truy xuất (ví dụ: 100), và 3) một mẫu truy vấn SQL chứa chỗ giữ chỗ {semantic_ids} để lọc. Công cụ sau đó thực hiện một quy trình nhiều bước để cung cấp kết quả liên quan.
Bước 1 – Giai đoạn tìm kiếm ngữ nghĩa: Công cụ trước tiên gửi truy vấn ngữ nghĩa đến Titan Text Embeddings để tạo một vector truy vấn. Vector này sau đó được sử dụng để tìm kiếm chỉ mục S3 Vectors cho top_k bản ghi chất lượng sản phẩm tương tự nhất dựa trên độ tương đồng cosine. API S3 Vectors trả về một danh sách các ID được xếp hạng theo mức độ liên quan ngữ nghĩa với truy vấn.
Ví dụ đầu vào: “phản hồi hệ thống phanh”
Ví dụ đầu ra: ID được xếp hạng theo độ tương đồng: [12847, 9203, 15634, 8821, …] (top 100 bản ghi về mòn má phanh, kiểm tra dầu phanh, hiệu suất phanh, v.v.)
Bước 2 – Giai đoạn lọc SQL: Các ID ngữ nghĩa được chèn vào mẫu truy vấn SQL. Athena sau đó thực thi truy vấn SQL này, có thể bao gồm các mệnh đề WHERE bổ sung, JOIN, tổng hợp hoặc bất kỳ thao tác SQL hợp lệ nào khác để tinh chỉnh thêm kết quả dựa trên các thuộc tính dữ liệu có cấu trúc như ngày, mức độ nghiêm trọng hoặc mẫu xe.
Ví dụ mẫu truy vấn SQL:
SELECT * FROM quality_recordsWHERE record_id IN ({semantic_ids})AND vehicle_model = ‘F09’AND report_date >= DATE ‘2025-10-01’Ví dụ truy vấn đã thực thi:
SELECT * FROM quality_recordsWHERE record_id IN (12847, 9203, 15634, 8821, …)AND vehicle_model = ‘F09’AND report_date >= DATE ‘2025-10-01’Ví dụ đầu ra:
7 bản ghi khớp cả tương đồng ngữ nghĩa VÀ các bộ lọc có cấu trúc
Bước 3 – Tổng hợp kết quả: Các kết quả đã lọc được trả về cho tác nhân, tác nhân sử dụng Anthropic’s Claude Sonnet 4.5 để tổng hợp một phản hồi ngôn ngữ tự nhiên, trình bày các phát hiện ở định dạng thân thiện với người dùng với các chi tiết và thông tin chi tiết liên quan.
Ví dụ đầu ra cho người dùng:
“Tìm thấy 7 bản ghi liên quan đến phanh trong các xe F09 từ Q4 2024. Phổ biến nhất: kiểm tra má phanh (3 trường hợp), bảo dưỡng dầu phanh (2 trường hợp), kiểm tra hiệu suất phanh (2 trường hợp).”
Cách tiếp cận lai này đảm bảo kết quả vừa liên quan về mặt ngữ nghĩa (hiểu “phản hồi hệ thống phanh” bao gồm mòn má phanh, bảo dưỡng dầu phanh, v.v.) vừa được lọc chính xác (chỉ F09, chỉ quý gần đây). Cách tiếp cận này cũng được thiết kế để cung cấp cho người dùng các kết quả vừa liên quan về mặt ngữ nghĩa vừa được lọc chính xác theo yêu cầu kinh doanh, kết hợp sự linh hoạt của hiểu ngôn ngữ tự nhiên với độ chính xác của các truy vấn có cấu trúc. Sơ đồ trình tự sau đây minh họa quy trình làm việc hoàn chỉnh:
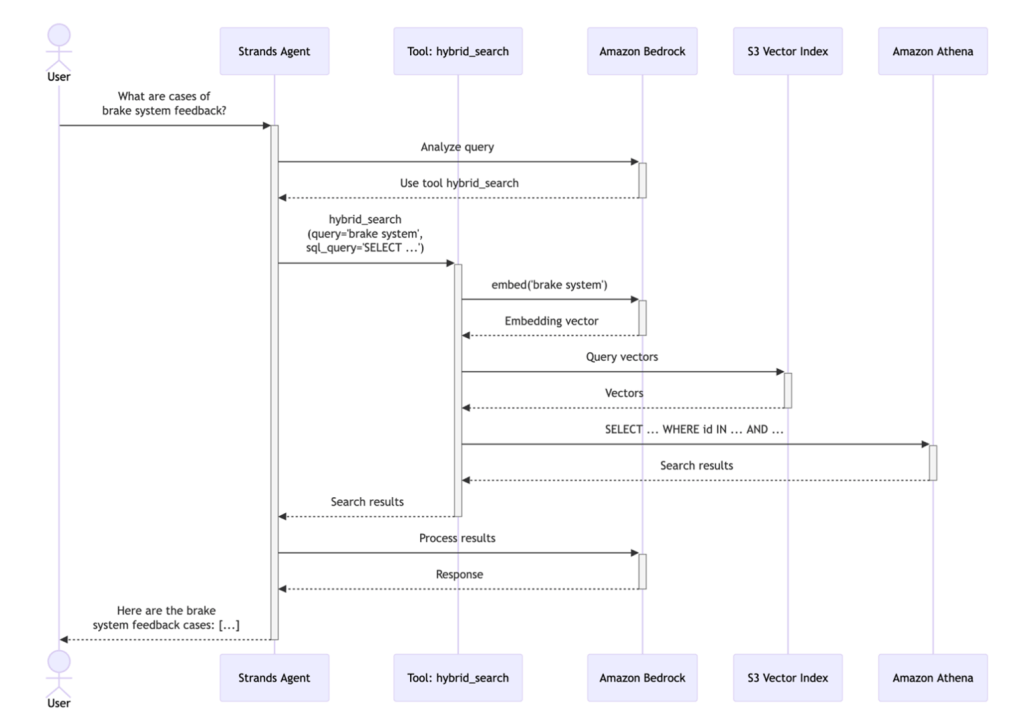
Hình 2. Sơ đồ trình tự tìm kiếm lai
Tìm kiếm toàn diện để phân tích tổng thể
Trong khi tìm kiếm lai xuất sắc trong việc tìm các bản ghi tương tự về mặt ngữ nghĩa, một số truy vấn yêu cầu phân tích toàn diện tất cả các bản ghi phù hợp để đảm bảo bao phủ hoàn chỉnh. Các câu hỏi như “Có bao nhiêu vấn đề liên quan đến phanh đã xảy ra trên mẫu F00?” đòi hỏi đánh giá toàn diện vì các biến thể thuật ngữ (ví dụ: “phanh“, “hệ thống phanh“, “má phanh“, “ABS“) có thể khiến tìm kiếm ngữ nghĩa bỏ lỡ các trường hợp liên quan. Công cụ tìm kiếm toàn diện giải quyết thách thức này bằng cách kết hợp truy xuất ứng cử viên dựa trên SQL với phân loại mức độ liên quan được hỗ trợ bởi AI.
Quy trình tìm kiếm toàn diện bắt đầu khi tác nhân xác định rằng một truy vấn yêu cầu bao phủ toàn diện thay vì truy xuất dựa trên độ tương đồng. Công cụ chấp nhận hai tham số: một truy vấn SQL SELECT truy xuất các bản ghi ứng cử viên từ cơ sở dữ liệu, và một mô tả vấn đề tìm kiếm định nghĩa những gì cấu thành một kết quả liên quan.
Truy xuất ứng cử viên: Tác nhân tạo một truy vấn SQL chỉ sử dụng bộ lọc có cấu trúc – không phải các khái niệm ngữ nghĩa – để tránh sự không khớp thuật ngữ. Ví dụ, thay vì lọc theo các thuật ngữ ngữ nghĩa như “các vấn đề liên quan đến phanh”, truy vấn sử dụng các giá trị cột chính xác:
SELECT * FROM quality_recordsWHERE vehicle_model = ‘F00’Điều này truy xuất tất cả các bản ghi khớp với tiêu chí có cấu trúc (có thể hàng nghìn ứng cử viên) mà không cần dựa vào LLM để đoán thuật ngữ chính xác từ tập dữ liệu. Công cụ bao gồm một cơ chế thử lại: nếu Athena trả về lỗi (tên cột không hợp lệ, lỗi cú pháp hoặc các lỗi SQL khác), thông báo lỗi sẽ được trả về cho tác nhân, tác nhân có thể tạo lại một truy vấn đã sửa. Điều này giúp ngăn chặn SQL bị “ảo giác” âm thầm thất bại và hỗ trợ tác nhân có thể tự sửa dựa trên thông tin schema thực tế.
Phân loại LLM theo lô: Thay vì xử lý tất cả các ứng cử viên cùng một lúc, công cụ chia chúng thành các lô 20 bản ghi để xử lý hiệu quả. Mỗi lô được định dạng dưới dạng bảng markdown và gửi đến một LLM nhỏ hơn (Anthropic’s Claude Haiku 4.5) qua Bedrock. Mô hình đánh giá từng bản ghi dựa trên vấn đề tìm kiếm, xác định xem nó có liên quan hay không và cung cấp một lý do ngắn gọn cho quyết định của nó. Chúng tôi nhận thấy 20 là một sự đánh đổi tốt giữa số lần gọi mô hình và context rot (khi số lượng token trong cửa sổ ngữ cảnh tăng lên, khả năng của mô hình để nhớ lại thông tin từ ngữ cảnh đó một cách chính xác sẽ giảm). Các lô được xử lý song song, giảm đáng kể tổng thời gian xử lý. Việc song song hóa này cho phép công cụ đánh giá hàng nghìn bản ghi trong vài giây trong khi vẫn duy trì hiệu quả chi phí bằng cách sử dụng một mô hình nhỏ hơn, nhanh hơn cho các tác vụ phân loại.
Tổng hợp kết quả: Sau khi tất cả các lô hoàn thành, công cụ tổng hợp các kết quả liên quan, làm phong phú mỗi bản ghi với một trường _reason_for_match chứa lý do của LLM. Sự minh bạch này giúp người dùng hiểu tại sao các bản ghi cụ thể được đưa vào và xây dựng niềm tin vào việc lọc được hỗ trợ bởi LLM.
Cách tiếp cận tìm kiếm toàn diện cung cấp phạm vi bao phủ hoàn chỉnh cho các truy vấn quan trọng mà việc bỏ lỡ các trường hợp liên quan có thể ảnh hưởng đến các quyết định kinh doanh. Bằng cách kết hợp lọc có cấu trúc của SQL với hiểu biết ngữ nghĩa của LLM, công cụ đạt được cả độ chính xác và độ bao phủ mà không phương pháp nào có thể cung cấp độc lập. Sơ đồ trình tự sau đây minh họa quy trình làm việc hoàn chỉnh:
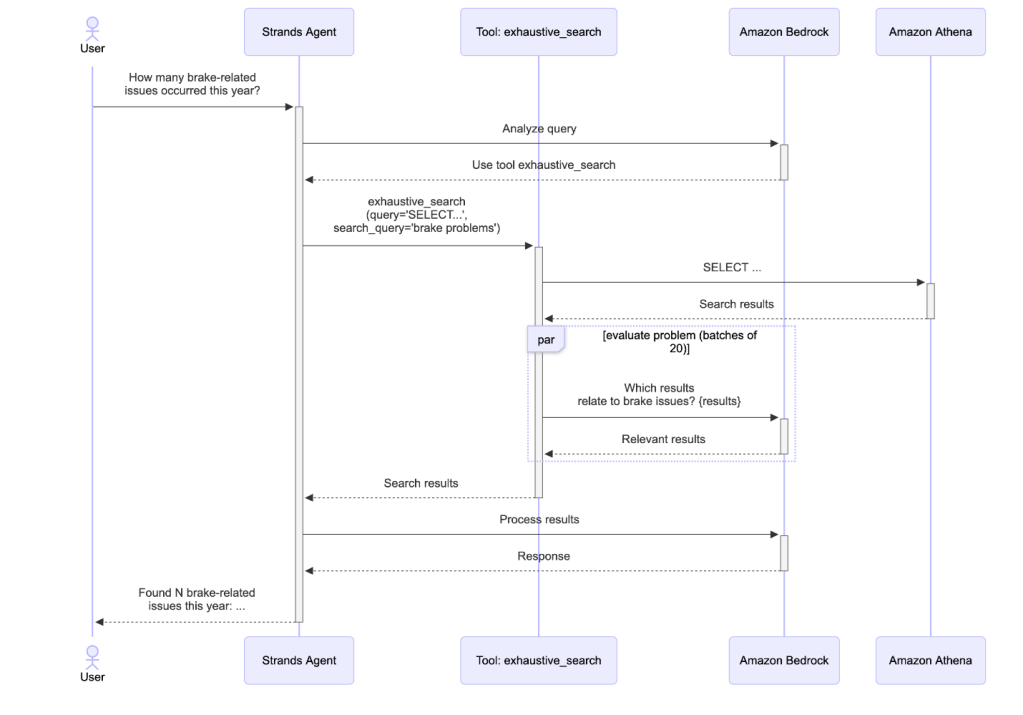
Hình 3. Sơ đồ trình tự tìm kiếm toàn diện
Lợi ích và kết quả chính
Cách tiếp cận thống nhất đối với dữ liệu có cấu trúc và phi cấu trúc
Sự kết hợp giữa tìm kiếm lai, tìm kiếm toàn diện và truy vấn SQL cho phép giải pháp xử lý liền mạch cả dữ liệu có cấu trúc và phi cấu trúc trong một giao diện hội thoại duy nhất. Người dùng có thể đặt các câu hỏi yêu cầu hiểu biết khái niệm (“tìm phản hồi hệ thống phanh tương tự”), lọc chính xác (“đếm các vấn đề về phanh từ quý trước”), hoặc phân tích toàn diện (“đánh giá tất cả các sự cố liên quan đến an toàn”) mà không cần chuyển đổi công cụ hoặc định dạng lại truy vấn. Việc lựa chọn công cụ thông minh của tác nhân giúp đảm bảo rằng mỗi loại truy vấn được xử lý bằng phương pháp phù hợp nhất, mang lại kết quả chính xác trong khi duy trì trải nghiệm người dùng ngôn ngữ tự nhiên nhất quán.
Kiến trúc phi máy chủ hiệu quả về chi phí
Được xây dựng hoàn toàn trên các dịch vụ AWS phi máy chủ, các thành phần giải pháp sẽ tự động giảm về 0 khi không sử dụng, tài nguyên tính toán được phân bổ theo yêu cầu và bạn chỉ trả tiền cho việc sử dụng thực tế. Kiến trúc phi máy chủ cho phép phát triển các nền tảng phân tích dữ liệu phức tạp được hỗ trợ bởi AI mà không phải chịu chi phí vận hành và chi phí cố định của cơ sở hạ tầng truyền thống.
Kết luận
Giải pháp tìm kiếm tác nhân này chứng minh cách các dịch vụ AI tạo sinh của AWS có thể thay đổi cách người dùng tương tác với dữ liệu của họ. Bằng cách giúp giảm các rào cản truyền thống giữa người dùng và thông tin chi tiết, cách tiếp cận này cho phép tất cả người dùng tạo ra thông tin chi tiết từ dữ liệu trong khi vẫn duy trì độ chính xác và quy mô cần thiết cho các ứng dụng doanh nghiệp. Khi các tổ chức tiếp tục tạo ra khối lượng dữ liệu ngày càng tăng, các giải pháp như thế này trở nên thiết yếu để khai thác toàn bộ giá trị của tài sản dữ liệu doanh nghiệp.
Để tìm hiểu thêm về việc xây dựng các giải pháp dữ liệu được hỗ trợ bởi AI trên AWS, hãy khám phá tài nguyên AI tạo sinh của chúng tôi.
Về tác giả

Ruben Simon
Ruben Simon là Giám đốc sản phẩm dày dặn kinh nghiệm cho Cloud Data Hub của BMW, nền tảng dữ liệu lớn nhất của công ty. Anh ấy đam mê thúc đẩy chuyển đổi số trong dữ liệu, phân tích và AI, và phát triển mạnh mẽ khi hợp tác với các nhóm quốc tế. Ngoài công việc, Ruben trân trọng thời gian dành cho gia đình và có niềm yêu thích đặc biệt với việc học hỏi không ngừng.

Fabian Söllner
Fabian Söllner là Kỹ sư phần mềm trong nhóm Cloud Data Hub của BMW. Anh ấy tận tâm trao quyền cho các đồng nghiệp trong toàn tổ chức bằng cách cung cấp các giải pháp Business Intelligence và Trí tuệ nhân tạo tiên tiến. Ngoài công việc chuyên môn, Fabian khéo léo cân bằng sự nghiệp với niềm đam mê nhiều môn thể thao khác nhau, đặc biệt là đạp xe đường trường và ba môn phối hợp, thể hiện sự nỗ lực không ngừng để cải thiện bản thân cả về cá nhân và chuyên môn.

Florian Seidel
Florian Seidel là Kiến trúc sư giải pháp toàn cầu chuyên về lĩnh vực ô tô tại AWS. Anh ấy hướng dẫn các khách hàng chiến lược khai thác toàn bộ tiềm năng của công nghệ đám mây để thúc đẩy đổi mới trong ngành ô tô. Với niềm đam mê phân tích, học máy, AI và các hệ thống phân tán mạnh mẽ, Florian giúp biến các khái niệm tiên tiến thành các giải pháp thực tế. Khi không thiết kế các chiến lược đám mây, anh ấy thích nấu ăn cho gia đình và bạn bè cũng như thử nghiệm sản xuất nhạc điện tử.

Khalid Al Khalili
Khalid Al Khalili là Kiến trúc sư dữ liệu tại BMW Group, dẫn dắt kiến trúc của Cloud Data Hub, nền tảng trung tâm của BMW cho đổi mới dữ liệu. Anh ấy là người ủng hộ mạnh mẽ việc tạo ra trải nghiệm dữ liệu liền mạch, biến các yêu cầu phức tạp thành các giải pháp hiệu quả, thân thiện với người dùng. Khi không xây dựng các tính năng mới, Khalid thích hợp tác với các đồng nghiệp và các nhóm đa chức năng để thúc đẩy và định hình chiến lược dữ liệu của BMW, đảm bảo nó luôn dẫn đầu trong một bối cảnh đang phát triển nhanh chóng.

Martin Maritsch
Martin Maritsch là Kiến trúc sư AI tạo sinh cấp cao tại AWS ProServe, tập trung vào AI tạo sinh và MLOps. Anh ấy giúp các khách hàng doanh nghiệp đạt được kết quả kinh doanh bằng cách khai thác toàn bộ tiềm năng của các dịch vụ AI/ML trên AWS Cloud.

Shukhrat Khodjaev
Shukhrat Khodjaev là Giám đốc quản lý cấp cao tại AWS ProServe chuyên về AI. Anh ấy giúp khách hàng tăng tốc chuyển đổi AI, thúc đẩy đổi mới và vượt qua giới hạn của ứng dụng AI để tạo ra kết quả kinh doanh hữu hình.
