Tác giả: Dustin Liu, Frank Tan, James Bland, James Luo, and Melanie Li
Ngày phát hành: 03 FEB 2026
Chuyên mục: Amazon Bedrock AgentCore, Artificial Intelligence, Customer Solutions, Generative BI
Bài viết này được đồng tác giả với James Luo từ BGL.
Phân tích dữ liệu đang nổi lên như một trường hợp sử dụng tác động cao cho các AI agent. Theo Báo cáo Tình trạng AI Agents năm 2026 của Anthropic, 60% tổ chức xếp hạng phân tích dữ liệu và tạo báo cáo là các ứng dụng AI agent có tác động lớn nhất của họ. 65% doanh nghiệp coi đây là ưu tiên hàng đầu. Trên thực tế, các doanh nghiệp phải đối mặt với hai thách thức phổ biến:
- Người dùng doanh nghiệp không có kiến thức kỹ thuật phải dựa vào các nhóm dữ liệu để truy vấn, điều này tốn thời gian và tạo ra nút thắt cổ chai.
- Các giải pháp text-to-SQL truyền thống không cung cấp kết quả nhất quán và chính xác.
Giống như nhiều doanh nghiệp khác, BGL phải đối mặt với những thách thức tương tự với các trường hợp sử dụng phân tích và báo cáo dữ liệu của mình. BGL là nhà cung cấp hàng đầu các giải pháp quản lý quỹ hưu trí tự quản (SMSF) giúp các cá nhân quản lý sự phức tạp trong việc tuân thủ và báo cáo các khoản tiết kiệm hưu trí của chính họ hoặc của khách hàng, phục vụ hơn 12.700 doanh nghiệp tại 15 quốc gia. Giải pháp của BGL xử lý dữ liệu tài chính và tuân thủ phức tạp thông qua hơn 400 bảng phân tích, mỗi bảng đại diện cho một lĩnh vực kinh doanh cụ thể, chẳng hạn như phản hồi tổng hợp của khách hàng, hiệu suất đầu tư, theo dõi tuân thủ và báo cáo tài chính. Khách hàng và nhân viên của BGL cần tìm hiểu thông tin chi tiết từ dữ liệu. Ví dụ: Sản phẩm nào có phản hồi tiêu cực nhất trong quý trước? hoặc Cho tôi xem xu hướng đầu tư cho các tài khoản có giá trị ròng cao. Làm việc với Amazon Web Services (AWS), BGL đã xây dựng một AI agent sử dụng Claude Agent SDK được lưu trữ trên Amazon Bedrock AgentCore. Bằng cách sử dụng AI agent, người dùng doanh nghiệp có thể truy xuất thông tin chi tiết phân tích thông qua ngôn ngữ tự nhiên trong khi vẫn tuân thủ các yêu cầu bảo mật và tuân thủ của dịch vụ tài chính, bao gồm cách ly phiên và kiểm soát truy cập dựa trên danh tính.
Trong bài đăng trên blog này, chúng tôi khám phá cách BGL xây dựng AI agent sẵn sàng sản xuất của mình bằng cách sử dụng Claude Agent SDK và Amazon Bedrock AgentCore. Chúng tôi đề cập đến ba khía cạnh chính trong việc triển khai của BGL:
- Tại sao việc xây dựng một nền tảng dữ liệu vững chắc lại cần thiết cho các giải pháp text-to-SQL dựa trên AI agent đáng tin cậy
- Cách BGL thiết kế AI agent của mình bằng Claude Agent SDK để thực thi mã, quản lý ngữ cảnh và chuyên môn theo lĩnh vực cụ thể
- Cách BGL sử dụng AgentCore để cung cấp các phiên thực thi có trạng thái lý tưởng trong môi trường sản xuất cho một AI agent an toàn hơn, có khả năng mở rộng hơn.
Thiết lập nền tảng dữ liệu vững chắc cho giải pháp text-to-SQL dựa trên AI agent
Khi các nhóm kỹ thuật triển khai một AI agent cho các trường hợp sử dụng phân tích, một anti-pattern phổ biến là để agent xử lý mọi thứ bao gồm hiểu schema cơ sở dữ liệu, chuyển đổi các tập dữ liệu phức tạp, sắp xếp logic nghiệp vụ cho các phân tích và diễn giải kết quả. AI agent có khả năng tạo ra kết quả không nhất quán và thất bại do nối các bảng không chính xác, bỏ sót các trường hợp biên hoặc tạo ra các tổng hợp sai.
BGL đã sử dụng giải pháp dữ liệu lớn trưởng thành hiện có của mình được cung cấp bởi Amazon Athena và dbt Labs, để xử lý và chuyển đổi hàng terabyte dữ liệu thô từ nhiều nguồn dữ liệu kinh doanh khác nhau. Quá trình trích xuất, chuyển đổi và tải (ETL) xây dựng các bảng phân tích và mỗi bảng trả lời một loại câu hỏi kinh doanh cụ thể. Các bảng đó là các tập dữ liệu tổng hợp, phi chuẩn hóa (với các chỉ số và tóm tắt) đóng vai trò là nguồn sự thật duy nhất sẵn sàng cho kinh doanh cho các công cụ Business Intelligence (BI), AI agent và ứng dụng. Để biết chi tiết về cách xây dựng kiến trúc chuyển đổi dữ liệu phi máy chủ với Athena và dbt, hãy xem Cách BMW Group xây dựng kiến trúc chuyển đổi dữ liệu quy mô terabyte phi máy chủ với dbt và Amazon Athena.
Vai trò của AI agent là xử lý chuyển đổi dữ liệu phức tạp trong hệ thống dữ liệu bằng cách tập trung vào việc diễn giải các câu hỏi ngôn ngữ tự nhiên của người dùng, dịch chúng và tạo các truy vấn SQL SELECT chống lại các bảng phân tích có cấu trúc tốt. Khi cần, AI agent viết các script Python để xử lý thêm kết quả và tạo hình ảnh trực quan. Sự tách biệt các mối quan tâm này làm giảm đáng kể nguy cơ ảo giác và mang lại một số lợi ích chính:
- Tính nhất quán: Hệ thống dữ liệu xử lý logic nghiệp vụ phức tạp theo cách xác định hơn: các phép nối, tổng hợp và quy tắc nghiệp vụ được nhóm dữ liệu xác thực trước. Nhiệm vụ của AI agent trở nên đơn giản: diễn giải các câu hỏi và tạo các truy vấn SELECT cơ bản chống lại các bảng đó.
- Hiệu suất: Các bảng phân tích được tổng hợp trước và tối ưu hóa với các chỉ mục phù hợp. Agent thực hiện các truy vấn cơ bản thay vì các phép nối phức tạp trên các bảng thô, dẫn đến thời gian phản hồi nhanh hơn ngay cả đối với các tập dữ dữ liệu lớn.
- Khả năng bảo trì và quản trị: Logic nghiệp vụ nằm trong hệ thống dữ liệu, không nằm trong cửa sổ ngữ cảnh của AI. Điều này giúp đảm bảo rằng AI agent dựa vào cùng một nguồn sự thật duy nhất như các người tiêu dùng khác, chẳng hạn như các công cụ BI. Nếu một quy tắc nghiệp vụ thay đổi, nhóm dữ liệu sẽ cập nhật logic chuyển đổi dữ liệu trong dbt và AI agent tự động tiêu thụ các bảng phân tích được cập nhật phản ánh những thay đổi đó.
“Nhiều người nghĩ rằng AI agent mạnh mẽ đến mức họ có thể bỏ qua việc xây dựng nền tảng dữ liệu; họ muốn agent làm mọi thứ. Nhưng bạn không thể đạt được kết quả nhất quán và chính xác theo cách đó. Mỗi lớp nên giải quyết sự phức tạp ở cấp độ phù hợp”
– James Luo, Trưởng phòng Dữ liệu và AI của BGL
Cách BGL xây dựng AI agent sử dụng Claude Agent SDK với Amazon Bedrock
Nhóm phát triển của BGL đã sử dụng Claude Code được cung cấp bởi Amazon Bedrock làm trợ lý mã hóa AI của mình. Tích hợp này sử dụng quyền truy cập tạm thời, dựa trên phiên để giảm thiểu rủi ro lộ thông tin xác thực và tích hợp với các nhà cung cấp danh tính hiện có để phù hợp với các yêu cầu tuân thủ dịch vụ tài chính. Để biết chi tiết về tích hợp, hãy xem Hướng dẫn cho Claude Code với Amazon Bedrock
Thông qua việc sử dụng Claude Code hàng ngày, BGL nhận ra rằng các khả năng cốt lõi của nó vượt xa việc mã hóa. BGL đã sử dụng khả năng của nó để suy luận các vấn đề phức tạp, viết và thực thi mã, cũng như tương tác với các tệp và hệ thống một cách tự động. Claude Agent SDK đóng gói các khả năng agentic tương tự vào một SDK Python và TypeScript, để các nhà phát triển có thể xây dựng các AI agent tùy chỉnh trên Claude Code. Đối với BGL, điều này có nghĩa là họ có thể xây dựng một AI agent phân tích với:
- Thực thi mã: Agent viết và chạy mã Python để xử lý các tập dữ liệu được trả về từ các bảng phân tích và tạo hình ảnh trực quan
- Quản lý ngữ cảnh tự động: Các phiên chạy dài không làm quá tải giới hạn token
- Thực thi trong sandbox: Cách ly cấp độ sản xuất và kiểm soát quyền
- Bộ nhớ và kiến thức mô-đun: Một tệp
CLAUDE.mdcho ngữ cảnh dự án và Agent Skills cho chuyên môn theo lĩnh vực sản phẩm cụ thể
Tại sao việc thực thi mã lại quan trọng đối với phân tích dữ liệu
Các truy vấn phân tích thường trả về hàng nghìn hàng và đôi khi vượt quá megabyte dữ liệu. Các mẫu sử dụng công cụ, gọi hàm và Giao thức Ngữ cảnh Mô hình (MCP) tiêu chuẩn thường truyền dữ liệu đã truy xuất trực tiếp vào cửa sổ ngữ cảnh, điều này nhanh chóng đạt đến giới hạn cửa sổ ngữ cảnh của mô hình. BGL đã triển khai một cách tiếp cận khác: agent viết SQL để truy vấn Athena, sau đó viết mã Python để xử lý trực tiếp các tệp CSV kết quả trong hệ thống tệp của nó. Điều này cho phép agent xử lý các tập kết quả lớn, thực hiện các tổng hợp phức tạp và tạo biểu đồ mà không đạt đến giới hạn cửa sổ ngữ cảnh. Bạn có thể tìm hiểu thêm về các mẫu thực thi mã trong Thực thi mã với MCP: Xây dựng các agent hiệu quả hơn.
Kiến trúc tri thức mô-đun
Để xử lý các dòng sản phẩm đa dạng và kiến thức miền phức tạp của BGL, việc triển khai sử dụng phương pháp mô-đun với hai loại cấu hình chính hoạt động liền mạch với nhau.
CLAUDE.md (ngữ cảnh dự án)
Tệp CLAUDE.md cung cấp cho agent ngữ cảnh toàn cầu—cấu trúc dự án, cấu hình môi trường (kiểm thử, sản xuất, v.v.) và quan trọng là cách thực thi các truy vấn SQL. Nó định nghĩa các thư mục nào lưu trữ kết quả trung gian và đầu ra cuối cùng, đảm bảo các tệp nằm trong một đường dẫn tệp được xác định mà người dùng có thể truy cập. Sơ đồ sau đây cho thấy cấu trúc của tệp CLAUDE.md:

SKILL.md (Chuyên môn theo lĩnh vực sản phẩm)
BGL tổ chức kiến thức miền của agent theo dòng sản phẩm bằng cách sử dụng các tệp cấu hình SKILL.md. Mỗi skill hoạt động như một nhà phân tích dữ liệu chuyên biệt cho một sản phẩm cụ thể. Ví dụ, sản phẩm BGL CAS 360 có một skill gọi là CAS360 Data Analyst agent, xử lý quản lý công ty và quỹ tín thác với sự tuân thủ ASIC; trong khi sản phẩm Simple Fund 360 của BGL có một skill gọi là Simple Fund 360 Data Analyst agent, được trang bị các skill miền liên quan đến quản lý và tuân thủ SMSF. Một tệp SKILL.md định nghĩa ba điều:
- Khi nào kích hoạt: Loại câu hỏi nào nên kích hoạt skill này
- Bảng nào để sử dụng hoặc ánh xạ: Tham chiếu đến các bảng phân tích liên quan trong thư mục dữ liệu (như trong hình trên)
- Cách xử lý các kịch bản phức tạp: Hướng dẫn từng bước cho các truy vấn đa bảng hoặc các câu hỏi kinh doanh cụ thể nếu được yêu cầu
Bằng cách sử dụng các tệp SKILL.md, agent có thể tự động khám phá và tải skill phù hợp để có được chuyên môn theo miền cụ thể cho các tác vụ tương ứng.
- Ngữ cảnh thống nhất: Khi một skill được kích hoạt, Claude Agent SDK tự động hợp nhất các hướng dẫn chuyên biệt của nó với tệp
CLAUDE.mdtoàn cầu thành một lời nhắc duy nhất. Điều này cho phép agent đồng thời áp dụng các tiêu chuẩn toàn dự án (ví dụ: luôn lưu vào đĩa) trong khi sử dụng kiến thức theo miền cụ thể (chẳng hạn như ánh xạ các câu hỏi của người dùng tới một nhóm bảng). - Khám phá dần dần: Không phải tất cả các skill đều cần được tải vào cửa sổ ngữ cảnh cùng một lúc. Agent trước tiên đọc truy vấn để xác định skill nào cần được kích hoạt. Nó tải nội dung skill và các tham chiếu để hiểu siêu dữ liệu của bảng phân tích nào được yêu cầu. Sau đó, nó khám phá thêm các thư mục dữ liệu tương ứng. Điều này giúp sử dụng ngữ cảnh hiệu quả trong khi cung cấp phạm vi bao phủ toàn diện.
- Tinh chỉnh lặp đi lặp lại: Nếu AI agent không thể xử lý một số kiến thức nghiệp vụ do thiếu kiến thức miền mới, nhóm sẽ thu thập phản hồi từ người dùng, xác định các khoảng trống và thêm kiến thức mới vào các skill hiện có bằng quy trình human-in-the-loop để các skill được cập nhật và tinh chỉnh lặp đi lặp lại.

Như trong hình trên, các skill của agent được tổ chức theo dòng sản phẩm. Mỗi thư mục sản phẩm chứa một tệp định nghĩa SKILL.md và một thư mục references với nhiều kiến thức miền và tài liệu hỗ trợ hơn mà agent tải theo yêu cầu.
Để biết chi tiết về Anthropic Agent Skills, hãy xem bài đăng trên blog của Anthropic, agents for the real world with Agent Skills
Kiến trúc giải pháp cấp cao
Để mang lại trải nghiệm text-to-SQL an toàn và có khả năng mở rộng hơn, BGL sử dụng Amazon Bedrock AgentCore để lưu trữ Claude Agent SDK trong khi vẫn giữ chuyển đổi dữ liệu trong giải pháp dữ liệu lớn hiện có.
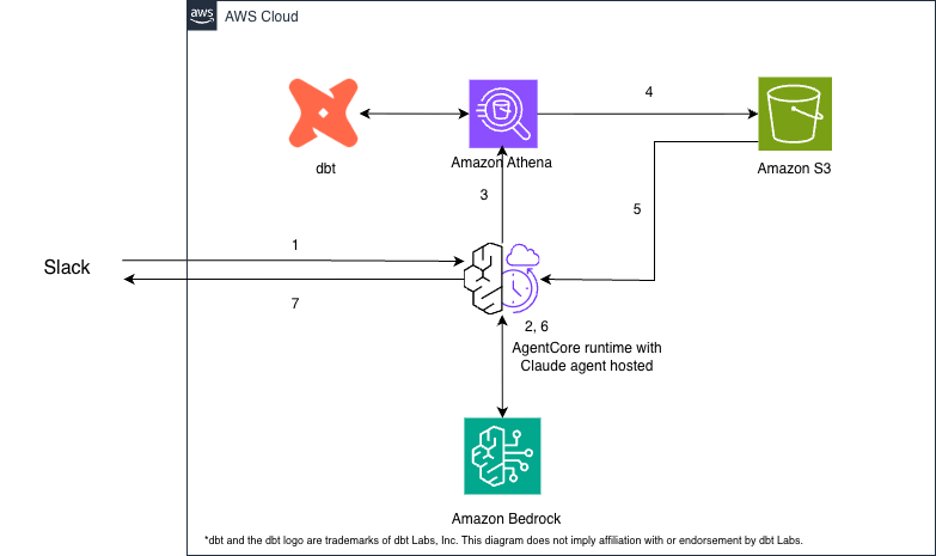
Hình trên minh họa kiến trúc và quy trình làm việc cấp cao. Các bảng phân tích được xây dựng trước hàng ngày bằng Athena và dbt, và đóng vai trò là nguồn sự thật duy nhất. Một tương tác người dùng điển hình diễn ra qua các giai đoạn sau:
- Yêu cầu của người dùng: Người dùng đặt câu hỏi kinh doanh bằng Slack (ví dụ: Sản phẩm nào có phản hồi tiêu cực nhất trong quý trước?).
- Khám phá Schema và tạo SQL: Agent xác định các bảng liên quan bằng cách sử dụng các skill và viết các truy vấn SQL.
- Xác thực bảo mật SQL: Để giúp ngăn chặn sửa đổi dữ liệu không mong muốn, một lớp bảo mật chỉ cho phép các truy vấn SELECT và chặn các hoạt động DELETE, UPDATE và DROP.
- Thực thi truy vấn: Athena thực thi truy vấn và lưu trữ kết quả vào Amazon Simple Storage Service (Amazon S3).
- Tải xuống kết quả: Agent tải xuống tệp CSV kết quả vào hệ thống tệp trên AgentCore, hoàn toàn bỏ qua cửa sổ ngữ cảnh để tránh giới hạn token.
- Phân tích và trực quan hóa: Agent viết mã Python để phân tích tệp CSV và tạo hình ảnh trực quan hoặc các tập dữ liệu tinh chỉnh tùy thuộc vào câu hỏi kinh doanh.
- Phân phối phản hồi: Thông tin chi tiết và hình ảnh trực quan cuối cùng được định dạng và trả về cho người dùng trong Slack.
Tại sao nên sử dụng Amazon Bedrock AgentCore để lưu trữ Claude Agent SDK
Triển khai một AI agent thực thi mã Python tùy ý đòi hỏi những cân nhắc đáng kể về cơ sở hạ tầng. Ví dụ, bạn cần cách ly để giúp đảm bảo không có quyền truy cập chéo phiên vào dữ liệu hoặc thông tin xác thực. Amazon Bedrock AgentCore cung cấp các phiên thực thi có trạng thái được quản lý hoàn toàn, mỗi phiên có microVM riêng biệt được cách ly với CPU, bộ nhớ và hệ thống tệp riêng. Khi một phiên kết thúc, microVM sẽ chấm dứt hoàn toàn và làm sạch bộ nhớ, giúp đảm bảo không còn dấu vết nào tồn tại cho các phiên sau. BGL nhận thấy dịch vụ này đặc biệt có giá trị:
- Phiên thực thi có trạng thái: AgentCore duy trì trạng thái phiên trong tối đa 8 giờ. Người dùng có thể có các cuộc trò chuyện liên tục với agent, tham chiếu lại các truy vấn trước đó mà không mất ngữ cảnh.
- Tính linh hoạt của Framework: Nó không phụ thuộc vào framework. Nó hỗ trợ triển khai các AI agent như Strands Agents SDK, Claude Agent SDK, LangGraph và CrewAI chỉ với vài dòng mã.
- Phù hợp với các phương pháp bảo mật tốt nhất: Nó cung cấp cách ly phiên, hỗ trợ VPC, AWS Identity and Access Management (IAM) hoặc danh tính dựa trên OAuth để tạo điều kiện cho các hoạt động agent được quản lý, tuân thủ ở quy mô lớn.
- Tích hợp hệ thống: Đây là một cân nhắc mang tính tương lai.
“Có Gateway, Memory, các công cụ trình duyệt, một hệ sinh thái hoàn chỉnh được xây dựng xung quanh nó. Tôi biết AWS đang đầu tư theo hướng này, vì vậy mọi thứ chúng tôi xây dựng bây giờ đều có thể tích hợp với các dịch vụ này trong tương lai.”
– James Luo, Trưởng phòng Dữ liệu và AI của BGL.
BGL đã lên kế hoạch tích hợp AgentCore Memory để lưu trữ tùy chọn người dùng và các mẫu truy vấn.
Kết quả và tác động
Đối với hơn 200 nhân viên của BGL, điều này thể hiện một sự thay đổi đáng kể trong cách họ trích xuất thông tin kinh doanh. Các nhà quản lý sản phẩm giờ đây có thể xác thực các giả thuyết ngay lập tức mà không cần chờ đợi nhóm dữ liệu. Các nhóm tuân thủ có thể phát hiện các xu hướng rủi ro mà không cần học SQL. Các nhà quản lý thành công của khách hàng có thể kéo các phân tích cụ thể theo tài khoản theo thời gian thực trong các cuộc gọi với khách hàng. Việc dân chủ hóa quyền truy cập dữ liệu này giúp biến phân tích từ một nút thắt cổ chai thành một lợi thế cạnh tranh, cho phép ra quyết định nhanh hơn trên toàn tổ chức đồng thời giải phóng nhóm dữ liệu để tập trung vào các sáng kiến chiến lược thay vì các yêu cầu truy vấn một lần.
Kết luận và những điểm chính cần lưu ý
Hành trình của BGL chứng minh cách kết hợp nền tảng dữ liệu vững chắc với AI agentic có thể dân chủ hóa Business Intelligence. Bằng cách sử dụng Amazon Bedrock AgentCore và Claude Agent SDK, BGL đã xây dựng một AI agent an toàn và có khả năng mở rộng hơn, trao quyền cho nhân viên khai thác dữ liệu của họ để trả lời các câu hỏi kinh doanh. Dưới đây là một số điểm chính cần lưu ý:
- Đầu tư vào nền tảng dữ liệu vững chắc: Độ chính xác bắt đầu từ nền tảng dữ liệu vững chắc. Bằng cách sử dụng hệ thống dữ liệu và đường ống dữ liệu để xử lý logic nghiệp vụ phức tạp (các phép nối và tổng hợp), agent có thể tập trung vào logic cơ bản, đáng tin cậy.
- Tổ chức kiến thức theo miền: Sử dụng Agent Skills để đóng gói chuyên môn theo miền cụ thể (ví dụ: Luật Thuế hoặc Hiệu suất Đầu tư). Điều này giữ cho cửa sổ ngữ cảnh sạch sẽ và dễ quản lý. Hơn nữa, thiết lập một vòng lặp phản hồi: liên tục giám sát các truy vấn của người dùng để xác định các khoảng trống và cập nhật lặp đi lặp lại các skill này.
- Sử dụng thực thi mã để xử lý dữ liệu: Tránh sử dụng agent để xử lý các tập dữ liệu lớn bằng cách sử dụng ngữ cảnh mô hình ngôn ngữ lớn (LLM). Thay vào đó, hướng dẫn agent viết và thực thi mã để lọc, tổng hợp và trực quan hóa dữ liệu.
- Chọn cơ sở hạ tầng có trạng thái, dựa trên phiên để lưu trữ agent: Phân tích hội thoại yêu cầu ngữ cảnh liên tục. Amazon Bedrock AgentCore đơn giản hóa điều này bằng cách cung cấp khả năng duy trì trạng thái tích hợp (các phiên lên đến 8 giờ), giảm bớt nhu cầu xây dựng các lớp xử lý trạng thái tùy chỉnh trên nền tảng tính toán phi trạng thái.
Nếu bạn đã sẵn sàng xây dựng các khả năng tương tự cho tổ chức của mình, hãy bắt đầu bằng cách khám phá Claude Agent SDK và một bản demo ngắn về Triển khai Claude Agent SDK trên Amazon Bedrock AgentCore Runtime. Nếu bạn có trường hợp sử dụng tương tự hoặc cần hỗ trợ thiết kế kiến trúc của mình, hãy liên hệ với nhóm tài khoản AWS của bạn.
Tài liệu tham khảo:
- Amazon Bedrock AgentCore
- Claude Agent SDK
- Amazon Bedrock
- Amazon Athena
- Triển khai Claude Agent SDK trên Amazon Bedrock AgentCore Runtime
Về tác giả

Dustin Liu là kiến trúc sư giải pháp tại AWS, tập trung hỗ trợ các công ty khởi nghiệp và SaaS trong lĩnh vực dịch vụ tài chính và bảo hiểm (FSI). Anh có nền tảng đa dạng về kỹ thuật dữ liệu, khoa học dữ liệu và học máy, đồng thời đam mê tận dụng AI/ML để thúc đẩy đổi mới và chuyển đổi kinh doanh.

Melanie Li, Tiến sĩ, là Kiến trúc sư giải pháp chuyên gia AI tạo sinh cấp cao tại AWS có trụ sở tại Sydney, Úc, nơi cô tập trung làm việc với khách hàng để xây dựng các giải pháp tận dụng các công cụ AI và học máy tiên tiến. Cô đã tích cực tham gia vào nhiều sáng kiến AI tạo sinh trên APJ, khai thác sức mạnh của các Mô hình Ngôn ngữ Lớn (LLM). Trước khi gia nhập AWS, Tiến sĩ Li đã giữ các vai trò khoa học dữ liệu trong ngành tài chính và bán lẻ.

Frank Tan là Kiến trúc sư giải pháp cấp cao tại AWS với sự quan tâm đặc biệt đến AI ứng dụng. Xuất thân từ nền tảng phát triển sản phẩm, anh được thúc đẩy để kết nối công nghệ và thành công kinh doanh.

James Luo là Trưởng phòng Dữ liệu & AI tại BGL Corporate Solutions, nhà cung cấp phần mềm tuân thủ hàng đầu thế giới cho các kế toán viên và chuyên gia tài chính. Kể từ khi gia nhập BGL vào năm 2008, James đã thăng tiến từ nhà phát triển lên kiến trúc sư đến vai trò lãnh đạo hiện tại của mình, dẫn đầu các sáng kiến Nền tảng Dữ liệu và Roni AI Agent. Năm 2015, anh thành lập nhóm BigData của BGL, triển khai mô hình học sâu đầu tiên trong ngành SMSF (2017), hiện xử lý hơn 200 triệu giao dịch hàng năm. Anh đã phát biểu tại Big Data & AI World và AWS Summit, và công việc AI của BGL đã được giới thiệu trong nhiều nghiên cứu điển hình của AWS.

Tiến sĩ James Bland là một Nhà lãnh đạo Công nghệ với hơn 30 năm kinh nghiệm thúc đẩy chuyển đổi AI ở quy mô lớn. Ông có bằng Tiến sĩ Khoa học Máy tính với trọng tâm là học máy và dẫn đầu các sáng kiến AI chiến lược tại AWS, giúp các doanh nghiệp áp dụng vòng đời phát triển được hỗ trợ bởi AI và các khả năng agentic. Tiến sĩ Bland đã đi tiên phong trong sáng kiến AI-SDLC, là tác giả của các hướng dẫn toàn diện về AI tạo sinh trong SDLC, và giúp các doanh nghiệp kiến trúc các giải pháp AI quy mô sản xuất nhằm thay đổi cơ bản cách các tổ chức hoạt động trong một thế giới ưu tiên AI.
