Tác giả: Xiao Huang
Ngày phát hành: 03 FEB 2026
Chuyên mục: Advanced (300), Amazon Managed Streaming for Apache Kafka (Amazon MSK), Technical How-to
Khi khối lượng công việc phân tích ngày càng đòi hỏi thông tin chi tiết theo thời gian thực, các tổ chức cần dữ liệu kinh doanh phải được đưa vào hồ dữ liệu ngay sau khi được tạo ra. Mặc dù có nhiều phương pháp khác nhau để nhập dữ liệu CDC theo thời gian thực (chẳng hạn như AWS Glue và Amazon EMR Serverless), Amazon MSK Connect với Iceberg Kafka Connect cung cấp một phương pháp hợp lý, được quản lý hoàn toàn giúp giảm độ phức tạp trong vận hành và cho phép đồng bộ hóa dữ liệu liên tục.
Trong bài viết này, chúng tôi trình bày cách sử dụng Iceberg Kafka Connect với Amazon Managed Streaming for Apache Kafka (Amazon MSK) Connect để tăng tốc việc nhập dữ liệu theo thời gian thực vào các hồ dữ liệu, đơn giản hóa quy trình đồng bộ hóa từ cơ sở dữ liệu giao dịch sang các bảng Apache Iceberg.
Tổng quan giải pháp
Trong bài viết này, chúng tôi chỉ cho bạn cách triển khai việc thu thập dữ liệu nhật ký giao dịch từ Amazon Relational Database Service (Amazon RDS) for MySQL và ghi nó vào Amazon Simple Storage Service (Amazon S3) ở định dạng bảng Iceberg bằng chế độ append, bao gồm cả đồng bộ hóa một bảng và nhiều bảng, như được minh họa trong hình sau.

Các consumer downstream sau đó xử lý các bản ghi thay đổi này để tái tạo trạng thái dữ liệu trước khi ghi vào các bảng Iceberg.
Trong giải pháp này, bạn sử dụng Iceberg Kafka Sink Connector để triển khai nghiệp vụ ở phía sink. Iceberg Kafka Sink Connector có các tính năng sau:
- Hỗ trợ phân phối chính xác một lần (exactly-once delivery)
- Hỗ trợ đồng bộ hóa đa bảng
- Hỗ trợ thay đổi lược đồ
- Ánh xạ tên trường thông qua tính năng ánh xạ cột của Iceberg
Điều kiện tiên quyết
Trước khi bắt đầu triển khai, hãy đảm bảo bạn có các thành phần sau:
Amazon RDS for MySQL: Giải pháp này giả định bạn đã có một phiên bản cơ sở dữ liệu Amazon RDS for MySQL đang chạy với dữ liệu bạn muốn đồng bộ hóa vào hồ dữ liệu Iceberg của mình. Đảm bảo rằng binary logging được bật trên phiên bản RDS của bạn để hỗ trợ các hoạt động Change Data Capture (CDC).
Amazon MSK Cluster: Bạn cần một Amazon MSK cluster được cấp phát trong AWS Region mục tiêu của bạn. Cluster này sẽ đóng vai trò là nền tảng streaming giữa cơ sở dữ liệu MySQL của bạn và hồ dữ liệu Iceberg. Đảm bảo cluster được cấu hình đúng cách với các security group và quyền truy cập mạng phù hợp.
Amazon S3 Bucket: Đảm bảo bạn có một Amazon S3 bucket sẵn sàng để lưu trữ các plugin Kafka Connect tùy chỉnh. Bucket này đóng vai trò là vị trí lưu trữ mà từ đó AWS MSK Connect truy xuất và cài đặt các plugin của bạn. Bucket phải tồn tại trong AWS Region mục tiêu của bạn và bạn phải có các quyền thích hợp để tải đối tượng lên đó.
Custom Kafka Connect Plugins: Để bật đồng bộ hóa dữ liệu theo thời gian thực với MSK Connect, bạn cần tạo hai plugin tùy chỉnh. Plugin đầu tiên sử dụng Debezium MySQL Connector để đọc nhật ký giao dịch và tạo các sự kiện Change Data Capture (CDC). Plugin thứ hai sử dụng Iceberg Kafka Connect để đồng bộ hóa dữ liệu từ Amazon MSK sang các bảng Apache Iceberg.
Build Environment: Để xây dựng plugin Iceberg Kafka Connect, bạn cần một môi trường xây dựng với Java và Gradle đã được cài đặt. Bạn có thể khởi chạy một phiên bản Amazon EC2 (khuyến nghị: Amazon Linux 2023 hoặc Ubuntu) hoặc sử dụng máy cục bộ của bạn nếu nó đáp ứng các yêu cầu. Đảm bảo bạn có đủ dung lượng đĩa (ít nhất 20GB) và kết nối mạng để clone repository và tải xuống các dependency.
Xây dựng Iceberg Kafka Connect từ mã nguồn mở
Kho lưu trữ ZIP của connector được tạo như một phần của bản dựng Iceberg. Bạn có thể chạy bản dựng bằng cách sử dụng mã sau:
git clone https://github.com/apache/iceberg.gitcd iceberg/./gradlew -x test -x integrationTest clean buildThe ZIP archive will be saved in ./kafka-connect/kafka-connect-runtime/build/distributions.
Tạo plugin tùy chỉnh
Bước tiếp theo là tạo các plugin tùy chỉnh để đọc và đồng bộ hóa dữ liệu.
- Tải lên tệp ZIP plugin tùy chỉnh mà bạn đã biên dịch ở bước trước lên Amazon S3 bucket được chỉ định của bạn.
- Truy cập AWS Management Console và điều hướng đến Amazon MSK rồi chọn Connect trong ngăn điều hướng.
- Chọn Custom plugins, sau đó chọn tệp plugin bạn đã tải lên S3 bằng cách duyệt hoặc nhập S3 URI của nó.
- Chỉ định một tên duy nhất, mô tả cho plugin tùy chỉnh của bạn (ví dụ: my-connector-v1).
- Chọn Create custom plugin.
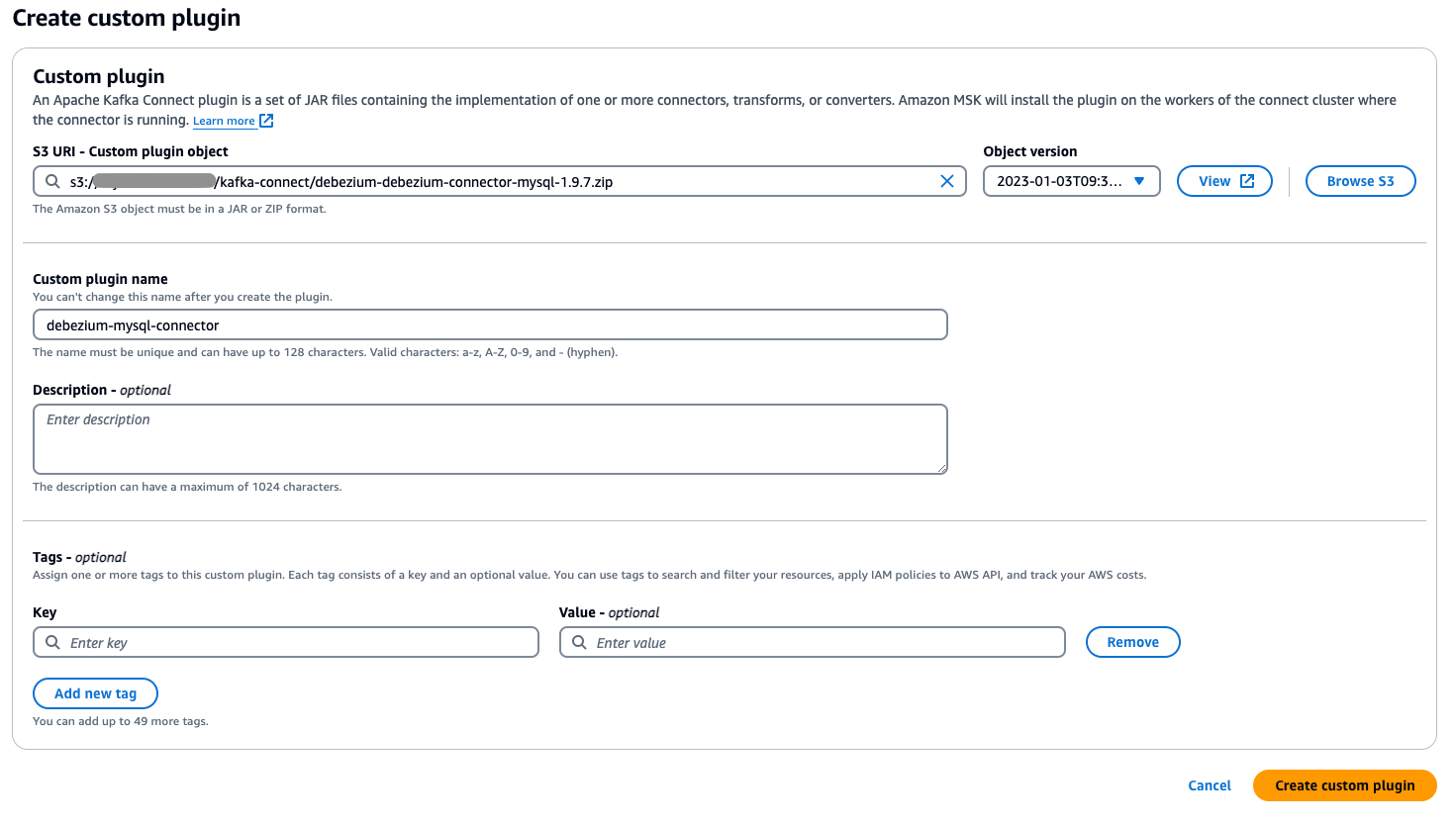
Cấu hình MSK Connect
Với các plugin đã được cài đặt, bạn đã sẵn sàng cấu hình MSK Connect.
Cấu hình quyền truy cập nguồn dữ liệu
Bắt đầu bằng cách cấu hình quyền truy cập nguồn dữ liệu.
- Để tạo cấu hình worker, chọn Worker configurations trong bảng điều khiển MSK Connect.
- Chọn Create worker configuration và sao chép, dán cấu hình sau.
key.converter.schemas.enable=falsevalue.converter.schemas.enable=falsekey.converter=org.apache.kafka.connect.json.JsonConvertervalue.converter=org.apache.kafka.connect.json.JsonConverter# Enable topic creation by the workertopic.creation.enable=true# Default topic creation settings for debezium connectortopic.creation.default.replication.factor=3topic.creation.default.partitions=1topic.creation.default.cleanup.policy=delete
- Trong bảng điều khiển Amazon MSK, chọn Connectors dưới Amazon MSK Connect và chọn Create connector.
- Trong trình hướng dẫn thiết lập, chọn plugin Debezium MySQL Connector đã tạo ở bước trước, nhập tên connector và chọn MSK cluster của mục tiêu đồng bộ hóa. Sao chép và dán nội dung sau vào cấu hình:
connector.class=io.debezium.connector.mysql.MySqlConnectortasks.max=1include.schema.changes=falsedatabase.server.id=100000database.server.name=database.port=3306database.hostname=database.password=database.user=topic.creation.default.partitions=1topic.creation.default.replication.factor=3topic.prefix=mysqlserverdatabase.include.list=## routetransforms=Reroutetransforms.Reroute.type=io.debezium.transforms.ByLogicalTableRoutertransforms.Reroute.topic.regex=(.*)(.*)transforms.Reroute.topic.replacement=$1all_records# schema.historyschema.history.internal.kafka.topicschema.history.internal.kafka.bootstrap.servers=# IAM/SASLschema.history.internal.consumer.sasl.mechanism=AWS_MSK_IAMschema.history.internal.consumer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandlerschema.history.internal.consumer.security.protocol=SASL_SSLschema.history.internal.consumer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;schema.history.internal.producer.security.protocol=SASL_SSLschema.history.internal.producer.sasl.mechanism=AWS_MSK_IAMschema.history.internal.producer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandlerschema.history.internal.producer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
Lưu ý rằng trong cấu hình, Route được sử dụng để ghi nhiều bản ghi vào cùng một topic. Trong tham số transforms.Reroute.topic.regex, biểu thức chính quy được cấu hình để lọc các tên bảng cần được ghi vào cùng một topic. Trong ví dụ sau, dữ liệu chứa trong tên bảng được ghi vào cùng một topic.
## routetransforms=Reroutetransforms.Reroute.type=io.debezium.transforms.ByLogicalTableRoutertransforms.Reroute.topic.regex=(.*)(.*)transforms.Reroute.topic.replacement=$1all_records
Ví dụ, sau khi transforms.Reroute.topic.replacement được chỉ định là $1all_records, tên topic được tạo trong MSK là < database.server.name>.all_records.
- Sau khi bạn chọn Create, MSK Connect sẽ tạo một tác vụ đồng bộ hóa cho bạn.
Đồng bộ hóa dữ liệu (chế độ một bảng)
Bây giờ, bạn có thể tạo một tác vụ đồng bộ hóa thời gian thực cho bảng Iceberg. Bắt đầu bằng cách tạo một tác vụ đồng bộ hóa thời gian thực cho một bảng duy nhất.
- Trong bảng điều khiển Amazon MSK, chọn Connectors dưới MSK Connect.
- Chọn Create connector.
- Trên trang tiếp theo, chọn plugin Iceberg Kafka Connect đã tạo trước đó.
- Nhập tên connector và chọn MSK cluster của mục tiêu đồng bộ hóa.
- Dán mã sau vào cấu hình.
connector.class=org.apache.iceberg.connect.IcebergSinkConnectortasks.max=1topics=iceberg.tables=iceberg.catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalogiceberg.catalog.warehouse=iceberg.catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIOiceberg.catalog.client.region=iceberg.tables.auto-create-enabled=trueiceberg.tables.evolve-schema-enabled=trueiceberg.control.commit.interval-ms=120000transforms=debeziumtransforms.debezium.type=org.apache.iceberg.connect.transforms.DebeziumTransformkey.converter=org.apache.kafka.connect.json.JsonConvertervalue.converter=org.apache.kafka.connect.json.JsonConvertervalue.converter.schemas.enable=falsekey.converter.schemas.enable=falseiceberg.control.topic=control-iceberg
Đối với Iceberg Connector, nó sẽ tạo một topic có tên control-iceberg theo mặc định để ghi lại offset. Chọn cấu hình worker đã tạo trước đó bao gồm topic.creation.enable = true. Nếu bạn sử dụng cấu hình worker mặc định và tính năng tự động tạo topic không được bật ở cấp độ MSK broker, connector sẽ không thể tự động tạo topic.
Bạn cũng có thể chỉ định tên topic này bằng cách đặt tham số iceberg.control.topic = <offset-topic>. Nếu bạn muốn sử dụng một topic tùy chỉnh, bạn có thể sử dụng mã sau.
$KAFKA_HOME/bin/kafka-topics.sh --bootstrap-server $MYBROKERS --create --topic <my-iceberg-offset-topic> --partitions 3 --replication-factor 2 --config cleanup.policy=compact
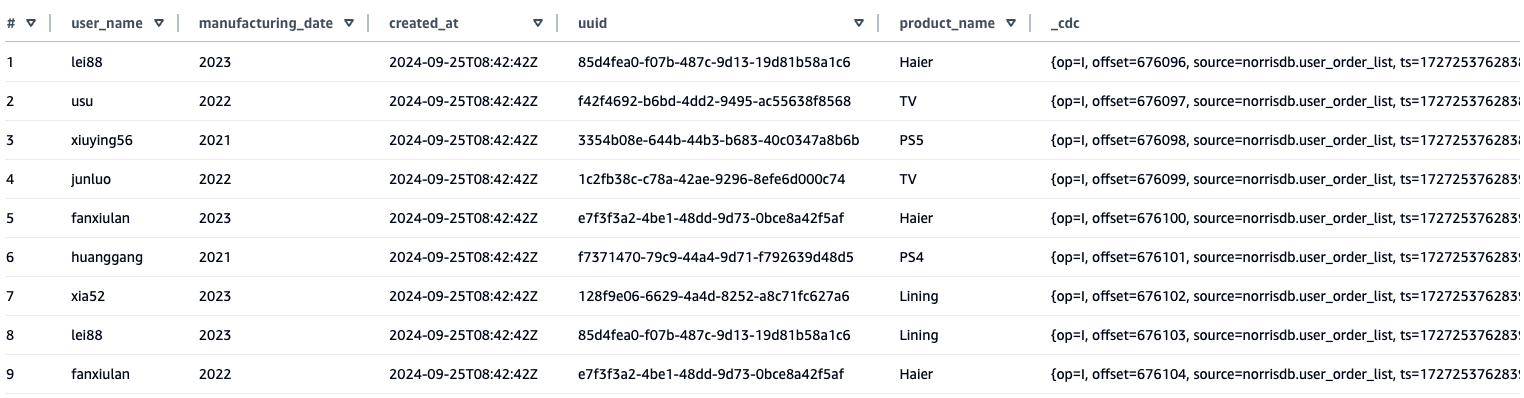
- Truy vấn kết quả dữ liệu đã đồng bộ hóa thông qua Amazon Athena. Từ bảng đã đồng bộ hóa sang Athena, bạn có thể thấy rằng, ngoài trường bảng nguồn, một trường
_cdcbổ sung đã được thêm vào để lưu trữ nội dung metadata của CDC.
Nén dữ liệu (Compaction)
Compaction là một hoạt động bảo trì thiết yếu cho các bảng Iceberg. Mặc dù việc nhập thường xuyên các tệp nhỏ có thể ảnh hưởng tiêu cực đến hiệu suất truy vấn, nhưng compaction thường xuyên sẽ giảm thiểu vấn đề này bằng cách hợp nhất các tệp nhỏ, giảm thiểu chi phí metadata và cải thiện đáng kể hiệu quả truy vấn. Để duy trì hiệu suất bảng tối ưu, bạn nên triển khai các quy trình compaction chuyên dụng. AWS Glue cung cấp một giải pháp tuyệt vời cho mục đích này, cung cấp khả năng compaction tự động giúp hợp nhất các tệp nhỏ một cách thông minh và tái cấu trúc bố cục bảng để nâng cao hiệu suất truy vấn.
Minh họa tiến hóa lược đồ
Để minh họa khả năng tiến hóa lược đồ của giải pháp này, chúng tôi đã tiến hành một thử nghiệm để cho thấy cách các thay đổi trường tại cơ sở dữ liệu nguồn được tự động đồng bộ hóa với các bảng Iceberg thông qua MSK Connect và Iceberg Kafka Connect.
Thiết lập ban đầu:
Đầu tiên, chúng tôi đã tạo một cơ sở dữ liệu RDS MySQL với bảng thông tin khách hàng (tb_customer_info) chứa lược đồ sau:
+----------------+--------------+------+-----+-------------------+-----------------------------------------------+| Field | Type | Null | Key | Default | Extra |+----------------+--------------+------+-----+-------------------+-----------------------------------------------+| id | int unsigned | NO | PRI | NULL | auto_increment || user_name | varchar(64) | YES | | NULL | || country | varchar(64) | YES | | NULL | || province | mediumtext | NO | | NULL | || city | int | NO | | NULL | || street_address | varchar(20) | NO | | NULL | || street_name | varchar(20) | NO | | NULL | || created_at | timestamp | NO | | CURRENT_TIMESTAMP | DEFAULT_GENERATED || updated_at | timestamp | YES | | CURRENT_TIMESTAMP | DEFAULT_GENERATED on update CURRENT_TIMESTAMP |+----------------+--------------+------+-----+-------------------+-----------------------------------------------+
Sau đó, chúng tôi đã cấu hình MSK Connect bằng Debezium MySQL Connector để thu thập các thay đổi từ bảng này và truyền chúng đến Amazon MSK theo thời gian thực. Tiếp theo, chúng tôi đã thiết lập Iceberg Kafka Connect để tiêu thụ dữ liệu từ MSK và ghi nó vào các bảng Iceberg.
Kiểm tra sửa đổi lược đồ:
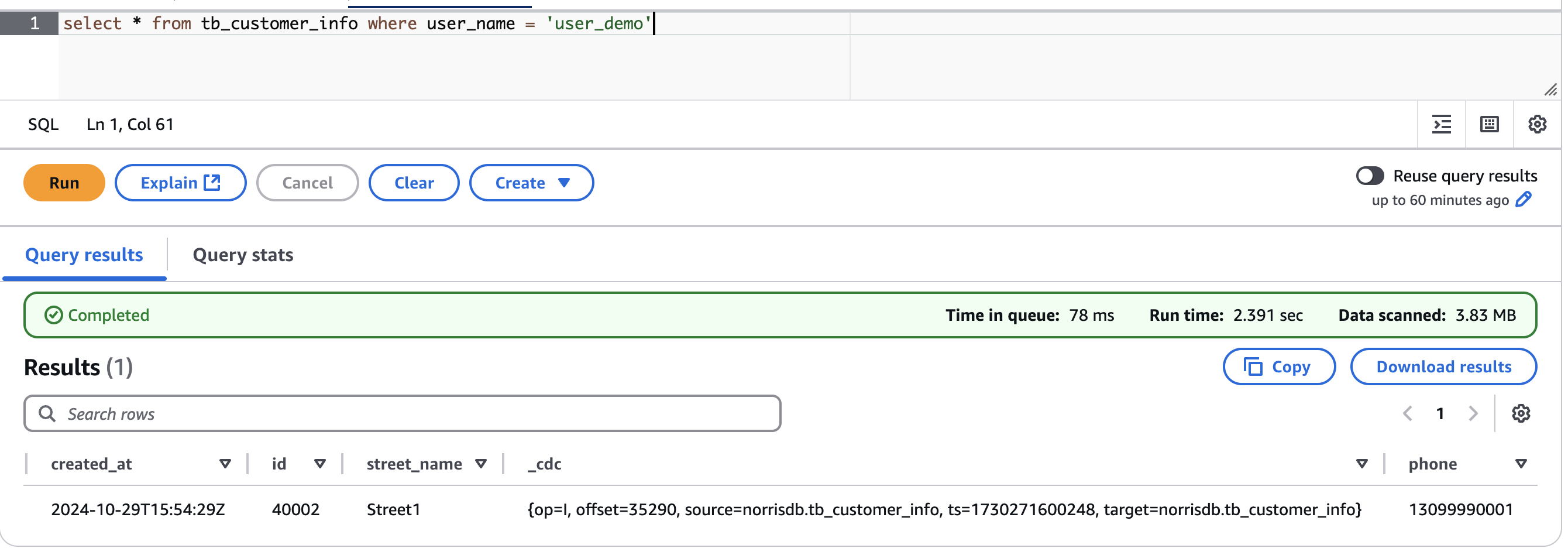
Để kiểm tra khả năng tiến hóa lược đồ, chúng tôi đã thêm một trường mới có tên phone vào bảng nguồn:
ALTER TABLE tb_customer_info ADD COLUMN phone VARCHAR(20) NULL;
Sau đó, chúng tôi đã chèn một bản ghi mới với trường phone được điền:
INSERT INTO tb_customer_info (user_name,country,province,city,street_address,street_name,phone) values ('user_demo','China','Guangdong',755,'Street1 No.369','Street1','13099990001');
Kết quả:
Khi chúng tôi truy vấn bảng Iceberg trong Amazon Athena, chúng tôi nhận thấy rằng trường phone đã được tự động thêm vào làm cột cuối cùng, và bản ghi mới đã được đồng bộ hóa thành công với tất cả các giá trị trường còn nguyên vẹn. Điều này chứng minh rằng khả năng lược đồ tự thích ứng của Iceberg Kafka Connect xử lý liền mạch các thay đổi DDL tại nguồn, loại bỏ nhu cầu cập nhật lược đồ thủ công trong hồ dữ liệu.
Đồng bộ hóa dữ liệu (chế độ đa bảng)
Thông thường, các quản trị viên dữ liệu muốn sử dụng một connector duy nhất để di chuyển dữ liệu trong nhiều bảng. Ví dụ, bạn có thể sử dụng công cụ thu thập CDC để ghi dữ liệu từ nhiều bảng vào một topic và sau đó ghi dữ liệu từ một topic vào nhiều bảng Iceberg thông qua phía consumer. Trong phần Cấu hình quyền truy cập nguồn dữ liệu, bạn đã cấu hình một MySQL synchronization Connector để đồng bộ hóa các bảng với các quy tắc được chỉ định vào một topic bằng cách sử dụng Route. Bây giờ hãy xem xét cách phân phối dữ liệu từ topic này đến nhiều bảng Iceberg.
- Khi sử dụng Iceberg Kafka Connect để đồng bộ hóa nhiều bảng với các bảng Iceberg bằng cách sử dụng AWS Glue Data Catalog, bạn phải tạo trước một cơ sở dữ liệu trong Data Catalog trước khi bắt đầu quá trình đồng bộ hóa. Tên cơ sở dữ liệu trong AWS Glue phải khớp chính xác với tên cơ sở dữ liệu nguồn, vì connector Iceberg Kafka Connect tự động sử dụng tên cơ sở dữ liệu nguồn làm tên cơ sở dữ liệu đích trong các kịch bản đồng bộ hóa đa bảng. Tính nhất quán về tên này là bắt buộc vì connector không cung cấp tùy chọn để ánh xạ tên cơ sở dữ liệu nguồn sang các tên cơ sở dữ liệu đích khác nhau trong các kịch bản đa bảng.
- Nếu bạn muốn sử dụng tên topic tùy chỉnh của mình, bạn có thể tạo một topic mới để lưu trữ offset bản ghi MSK Connect, xem Đồng bộ hóa dữ liệu (chế độ một bảng).
- Trong bảng điều khiển Amazon MSK, tạo một connector khác bằng cách sử dụng cấu hình sau.
connector.class= org.apache.iceberg.connect.IcebergSinkConnectortasks.max=2topics=iceberg.catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalogiceberg.catalog.warehouse=iceberg.catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIOiceberg.catalog.client.region=iceberg.tables.auto-create-enabled=trueiceberg.tables.evolve-schema-enabled=trueiceberg.control.commit.interval-ms=120000transforms=debeziumtransforms.debezium.type=org.apache.iceberg.connect.transforms.DebeziumTransformiceberg.tables.route-field=_cdc.sourceiceberg.tables.dynamic-enabled=truekey.converter=org.apache.kafka.connect.json.JsonConvertervalue.converter=org.apache.kafka.connect.json.JsonConvertervalue.converter.schemas.enable=falsekey.converter.schemas.enable=falseiceberg.control.topic=control-iceberg
Trong cấu hình này, hai tham số đã được thêm vào:
iceberg.tables.route-field: Chỉ định trường định tuyến phân biệt giữa các bảng khác nhau, được chỉ định làcdc.sourcecho dữ liệu CDC được phân tích cú pháp bởi Debezium.iceberg.tables.dynamic-enabled: Nếu tham sốiceberg.tableskhông được đặt, nó phải được chỉ định làtrueở đây.
- Sau khi hoàn thành, MSK Connect sẽ tạo một sink connector cho bạn.
- Sau khi quá trình hoàn tất, bạn có thể xem bảng mới được tạo thông qua Athena.
Các mẹo khác
Trong phần này, chúng tôi chia sẻ một số điều khác mà bạn có thể sử dụng để tùy chỉnh triển khai của mình cho phù hợp với trường hợp sử dụng của bạn.
- Đồng bộ hóa bảng được chỉ định
Trong phần Đồng bộ hóa dữ liệu (chế độ đa bảng), bạn chỉ địnhiceberg.tables.route-field = _cdc.Sourcevàiceberg.tables.dynamic-enabled=true, hai cài đặt tham số này có thể ghi nhiều bảng được lưu trữ trong bảng Iceberg. Nếu bạn muốn chỉ đồng bộ hóa các bảng được chỉ định, bạn có thể chỉ định tên bảng bạn muốn đồng bộ hóa bằng cách đặticeberg.tables.dynamic-enabled = falsevà sau đó đặt tham sốiceberg.tables. Ví dụ,
iceberg.tables.dynamic-enabled = falseiceberg.tables = default.tablename1,default.tablename2iceberg.table.default.tablename1.route-regex = tablename1iceberg.table.default.tablename2.route-regex = tablename2
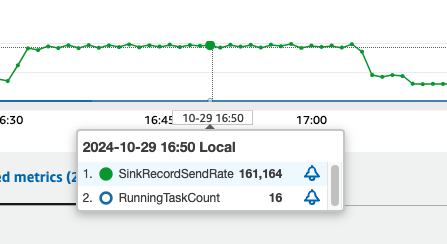
- Kết quả kiểm tra hiệu suất Chúng tôi đã tiến hành một thử nghiệm hiệu suất bằng cách sử dụng sysbench để đánh giá khả năng đồng bộ hóa dữ liệu của giải pháp này. Thử nghiệm đã mô phỏng một kịch bản ghi khối lượng lớn để chứng minh thông lượng và khả năng mở rộng của hệ thống. Cấu hình kiểm tra:
- Thiết lập cơ sở dữ liệu: Đã tạo 25 bảng trong cơ sở dữ liệu MySQL bằng sysbench.Tải dữ liệu: Đã ghi 20 triệu bản ghi vào mỗi bảng (tổng cộng 500 triệu bản ghi).Streaming thời gian thực: Đã cấu hình MSK Connect để truyền dữ liệu từ MySQL đến Amazon MSK theo thời gian thực trong quá trình ghi.Cấu hình Kafka Connect:
- Đã khởi động Kafka Iceberg Connect.Số worker tối thiểu: 1.Số worker tối đa: 8.Đã cấp phát hai MCU cho mỗi worker.
- Thiết lập cơ sở dữ liệu: Đã tạo 25 bảng trong cơ sở dữ liệu MySQL bằng sysbench.Tải dữ liệu: Đã ghi 20 triệu bản ghi vào mỗi bảng (tổng cộng 500 triệu bản ghi).Streaming thời gian thực: Đã cấu hình MSK Connect để truyền dữ liệu từ MySQL đến Amazon MSK theo thời gian thực trong quá trình ghi.Cấu hình Kafka Connect:
Dọn dẹp tài nguyên
Để dọn dẹp tài nguyên của bạn, hãy hoàn thành các bước sau:
- Xóa các connector MSK Connect: Xóa cả Debezium MySQL Connector và Iceberg Kafka Connect connector đã tạo cho giải pháp này.
- Xóa Amazon MSK cluster: Nếu bạn đã tạo một MSK cluster mới dành riêng cho bản trình diễn này, hãy xóa nó để ngừng phát sinh chi phí.
- Xóa các S3 bucket: Xóa các S3 bucket được sử dụng để lưu trữ các plugin Kafka Connect tùy chỉnh và dữ liệu bảng Iceberg. Đảm bảo bạn đã sao lưu bất kỳ dữ liệu nào bạn cần trước khi xóa.
- Xóa phiên bản EC2: Nếu bạn đã khởi chạy một phiên bản EC2 để xây dựng plugin Iceberg Kafka Connect, hãy chấm dứt nó.
- Xóa phiên bản RDS MySQL (tùy chọn): Nếu bạn đã tạo một phiên bản RDS mới dành riêng cho bản trình diễn này, hãy xóa nó. Nếu bạn đang sử dụng cơ sở dữ liệu sản xuất hiện có, hãy bỏ qua bước này.
- Xóa các IAM role và policy (nếu được tạo): Xóa bất kỳ IAM role và policy nào được tạo dành riêng cho giải pháp này để duy trì các phương pháp bảo mật tốt nhất.
Kết luận
Trong bài viết này, chúng tôi đã trình bày một giải pháp để đạt được đồng bộ hóa dữ liệu theo thời gian thực, hiệu quả từ các cơ sở dữ liệu giao dịch đến các hồ dữ liệu bằng cách sử dụng Amazon MSK Connect và Iceberg Kafka Connect. Giải pháp này cung cấp một mô hình đồng bộ hóa dữ liệu chi phí thấp và hiệu quả cho phân tích dữ liệu lớn cấp doanh nghiệp. Cho dù bạn đang làm việc với các giao dịch thương mại điện tử, giao dịch tài chính hay nhật ký thiết bị IoT, giải pháp này có thể giúp bạn truy cập nhanh chóng vào hồ dữ liệu, cho phép các doanh nghiệp phân tích nhanh chóng có được dữ liệu kinh doanh mới nhất. Chúng tôi khuyến khích bạn thử giải pháp này trong môi trường của riêng mình và chia sẻ kinh nghiệm của bạn trong phần bình luận. Để biết thêm thông tin, hãy truy cập Amazon MSK Connect.
Về tác giả

Huang Xiao
Huang là Kiến trúc sư Giải pháp Chuyên gia Cấp cao về Phân tích tại AWS. Anh tập trung vào thiết kế kiến trúc giải pháp dữ liệu lớn, với nhiều năm kinh nghiệm trong phát triển và thiết kế kiến trúc trong lĩnh vực dữ liệu lớn.
