Tác giả: Shiyang Wei và Dongdong Yang
Ngày phát hành: 03 FEB 2026
Chuyên mục: Amazon Elastic Kubernetes Service, Expert (400), Technical How-to
Các công ty chuyên sâu về Machine Learning (ML) phải đối mặt với những thách thức đáng kể trong việc quản lý dữ liệu huấn luyện một cách hiệu quả. Bài viết này giới thiệu một giải pháp để xây dựng một hệ thống tệp hiệu suất cao, đàn hồi, gốc đám mây và có tuổi thọ ngắn. Đến cuối bài viết này, bạn sẽ học cách triển khai hệ thống tệp hiệu suất cao, đàn hồi này bằng cách sử dụng Amazon Elastic Kubernetes Service (Amazon EKS) và CNCF Fluid, thiết lập các cơ chế bộ nhớ đệm dữ liệu hiệu quả và điều phối các quy trình huấn luyện bằng KubeRay. Bài viết này dành cho các kỹ sư DevOps, chuyên gia MLOps và kiến trúc sư hạ tầng, những người chịu trách nhiệm xây dựng và tối ưu hóa hạ tầng huấn luyện ML trong môi trường đám mây, đặc biệt là những người làm việc với Amazon EKS và muốn nâng cao các pipeline huấn luyện học sâu của họ. Bạn sẽ cần một giờ để đọc hết bài viết này và hai giờ để triển khai bản demo. Chi phí cho các tài nguyên là khoảng 4 USD mỗi giờ.
Thách thức và giải pháp tải dữ liệu học sâu
Các phần sau đây phác thảo các thách thức và giải pháp tải dữ liệu học sâu.
Nút thắt cổ chai tải dữ liệu
Tải dữ liệu đặt ra một nút thắt cổ chai hiệu suất lớn trong các hệ thống huấn luyện học sâu, đặc biệt là trong các hoạt động quy mô lớn. Thách thức này xuất phát từ hai vấn đề chính: nhu cầu truy cập lặp đi lặp lại nhiều tệp nhỏ và giao tiếp liên tục giữa hệ thống lưu trữ và hệ thống tính toán. Các hệ thống phân tán, tập dữ liệu phức tạp, các mẫu truy cập dữ liệu ngẫu nhiên và việc tăng cường dữ liệu rộng rãi làm trầm trọng thêm các vấn đề này trong quá trình huấn luyện. Tầm quan trọng của nút thắt cổ chai này thay đổi tùy theo các mô hình và tập dữ liệu khác nhau nhưng luôn là một mối quan tâm quan trọng, đặc biệt là với chi phí cao của tài nguyên tính toán GPU. Điều này làm cho việc tối ưu hóa tải dữ liệu trở nên cần thiết để có hiệu quả phần cứng tốt hơn và thời gian huấn luyện nhanh hơn.
Thách thức trong việc quản lý hệ thống tệp song song
Phần này phác thảo các thách thức trong việc quản lý hệ thống tệp song song, bao gồm mô hình làm việc, thách thức vận hành và sự cần thiết phải triển khai riêng biệt lớp bộ nhớ đệm dữ liệu.
Thách thức về mô hình làm việc
Trong môi trường học sâu, các nhà khoa học dữ liệu và nhà nghiên cứu cần các hệ thống lưu trữ hiệu suất cao để xử lý các tập dữ liệu khổng lồ (ví dụ: khối lượng dữ liệu 100 GB-200 GB cho huấn luyện mô hình CNN/RNN, khối lượng dữ liệu 200 GB+ cho tinh chỉnh mô hình quy mô lớn và khoảng 1 TB dữ liệu cho huấn luyện mô hình học tăng cường), với các nhóm gồm hơn 50 người dùng thường cần truy cập đồng thời có thể yêu cầu thông lượng vượt quá 50 GBps trong thời gian cao điểm. Tuy nhiên, nhu cầu này rất thay đổi, với việc sử dụng giảm đáng kể trong thời gian thấp điểm hoặc khi các nhóm tập trung vào các tác vụ ít chuyên sâu về dữ liệu hơn. Thách thức nằm ở việc không hiệu quả về chi phí khi duy trì các hệ thống tệp hiệu suất cao đắt tiền 24/7 khi chúng chỉ cần thiết không liên tục. Mặc dù giải pháp hợp lý là cung cấp và giải phóng các hệ thống này dựa trên nhu cầu, nhưng các hệ thống tệp hiệu suất cao truyền thống có thời gian thiết lập và gỡ bỏ kéo dài, đặc biệt đối với các khối lượng lớn hơn. Điều này làm cho việc mở rộng quy mô động không thực tế và ngăn các tổ chức tối ưu hóa chi phí lưu trữ của họ một cách hiệu quả.
Thách thức vận hành
Các hệ thống tệp song song đã phát triển đáng kể trong việc thiết lập từ các phương pháp truyền thống sang các phương pháp dựa trên đám mây. Mặc dù các cài đặt tại chỗ truyền thống có thể mất hàng giờ hoặc thậm chí hàng ngày do thiết lập phần cứng và cấu hình thủ công, các dịch vụ đám mây hiện đại như Amazon FSx for Lustre đã rút ngắn đáng kể thời gian này xuống còn vài phút thông qua tự động hóa. Tuy nhiên, việc sẵn sàng hệ thống đầy đủ vẫn có thể cần thêm thời gian, đặc biệt khi nhập một lượng lớn dữ liệu. Với sự phức tạp và đầu tư thời gian này, các tổ chức thường coi việc triển khai hệ thống tệp song song là một quyết định chiến lược dài hạn hơn là một tác vụ vận hành thường xuyên.
Sự cần thiết phải triển khai riêng biệt lớp bộ nhớ đệm dữ liệu
Các máy chủ GPU cấu hình cao, chẳng hạn như dòng Amazon Elastic Compute Cloud (Amazon EC2), có các thẻ NVMe SSD cục bộ có thể được sử dụng làm phương tiện lưu trữ có độ trễ thấp, hiệu suất cao để lưu trữ dữ liệu. Tuy nhiên, trong hầu hết các trường hợp, các người tiêu dùng khác cũng tiêu thụ dữ liệu này, ví dụ: các khối lượng công việc huấn luyện mô hình khác, khối lượng công việc phân tích tương tác và khối lượng công việc HPC. Điều này làm cho việc lưu trữ dữ liệu cần có một triển khai riêng biệt bằng cách sử dụng tài nguyên bộ nhớ mà tất cả các phiên bản EC2 thông thường có thể cung cấp thay vì lưu trữ cụ thể mà chỉ một vài loại phiên bản EC2 có. Khối lượng công việc lưu trữ dữ liệu được tách biệt có thể chạy trên cùng một cluster lưu trữ các khối lượng công việc khác.
Ưu điểm của hệ thống tệp được xây dựng bởi Amazon EKS và CNCF Fluid
- Thông lượng cao mà không cần khối lượng hệ thống tệp lớn: FSx for Lustre—với dung lượng lưu trữ tối thiểu 1.2 TB đối với SSD và tăng thêm 2.4 TB (để biết thông tin chi tiết, hãy tham khảo Hướng dẫn POC FSx for Lustre)—có thể cung cấp thông lượng 50 GBps với khối lượng hệ thống tệp ít nhất 50 TB (sử dụng persistent 1000). Một hệ thống tệp hiệu suất cao, đàn hồi được xây dựng bởi Amazon EKS và CNCF Fluid có thể đạt được thông lượng này bằng cách sử dụng khả năng của chính RAM. Hãy xem xét Amazon EC2 C5: thông số kỹ thuật RAM là DDR4, kênh đôi và 3200MT/s. Thông lượng có thể đạt 51.2 GBps
(3200*64*2/8). Quan sát công thức tính thông lượng sau:Thông lượng = (Tốc độ bộ nhớ tính bằng MT/s) * (Tổng chiều rộng bus tính bằng bit) / 8 (để chuyển đổi bit sang byte) - Cung cấp và giải phóng nhanh chóng: Hệ thống tệp tích hợp hoàn toàn vào Kubernetes. Do đó, nó có thể sử dụng khả năng điều phối tài nguyên nhanh chóng của Kubernetes. Hệ thống tệp có thể được cung cấp và giải phóng trong vài phút. Khả năng này giúp có thể cung cấp cluster lưu trữ dữ liệu khi cần và giải phóng nó khi không cần. Điều này giúp giảm đáng kể chi phí do duy trì một hệ thống tệp hiệu suất cao.
- Dễ sử dụng và vận hành: Nếu bạn là người vận hành/người dùng, thì bạn cần tạo các pod lưu trữ dữ liệu/pod ứng dụng bằng tệp YAML. Fluid sẽ đảm nhiệm toàn bộ công việc quản lý lưu trữ dữ liệu. Các phần sau của bài viết này sẽ giải thích chi tiết.
Tổng quan giải pháp
Sơ đồ sau đây minh họa kiến trúc Amazon EKS toàn diện tích hợp Ray Cluster cho tính toán phân tán với Fluid để quản lý dữ liệu thông minh. Trong kiến trúc này, Ray Jobs được gửi thông qua cấu hình YAML để tạo các cluster có thể mở rộng được quản lý bởi KubeRay Operator với một Ray Head Pod điều phối nhiều worker node. Đồng thời, hệ thống Fluid cung cấp kiến trúc hai lớp bao gồm một mặt phẳng điều khiển quản lý các plugin CSI và các bộ điều khiển khác nhau cùng với một mặt phẳng dữ liệu xử lý các tập dữ liệu và persistent volume claims với các worker node bộ nhớ đệm phân tán lưu trữ dữ liệu được truy cập thường xuyên từ Amazon Simple Storage Service (Amazon S3). Tất cả điều này được giám sát bởi một Kube-prometheus-stack với Prometheus thu thập các số liệu và Grafana cung cấp các bảng điều khiển trực quan hóa, với các tích hợp bên ngoài bao gồm Amazon ElastiCache for Redis quản lý siêu dữ liệu, Amazon Elastic Container Registry (Amazon ECR) cung cấp các Docker image tùy chỉnh và Cluster Autoscaler tự động điều chỉnh tài nguyên dựa trên nhu cầu khối lượng công việc để cho phép tính toán phân tán hiệu quả với độ trễ giảm thông qua bộ nhớ đệm cục bộ trong khi vẫn duy trì khả năng mở rộng động.
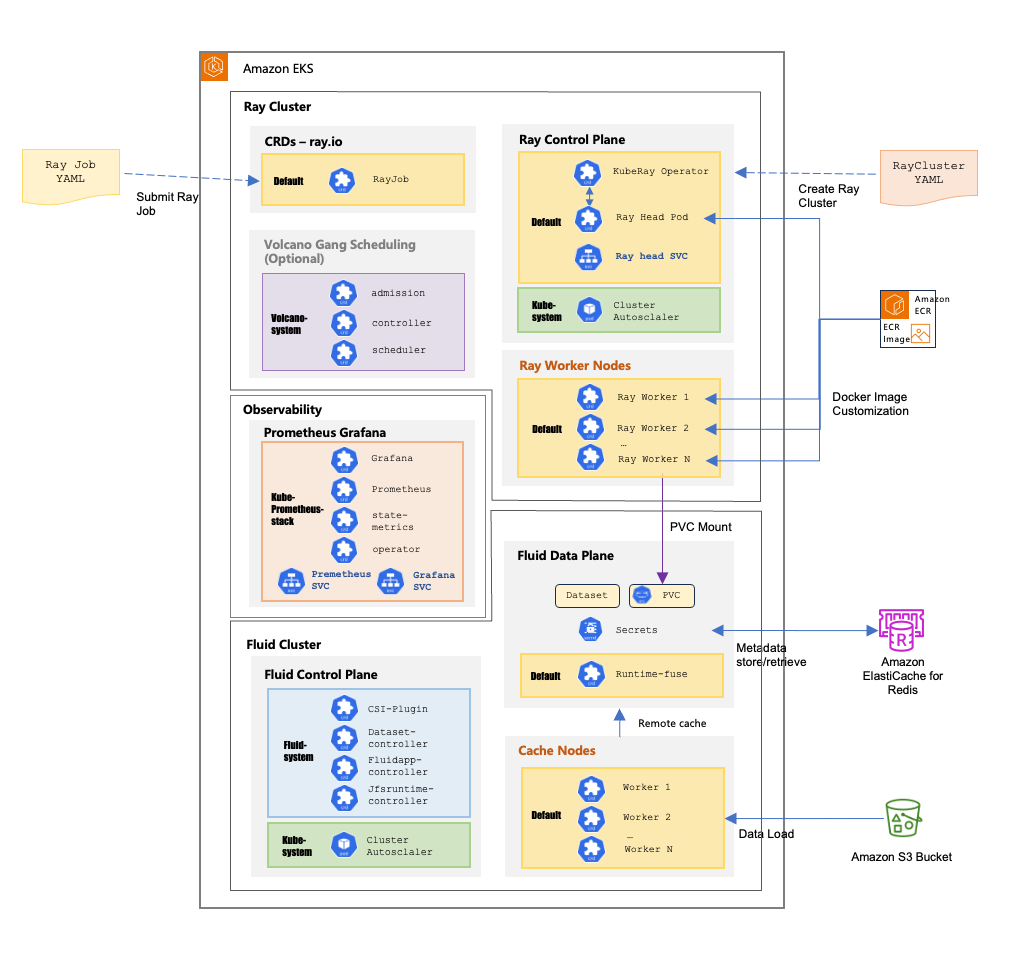
Đạt được bộ nhớ đệm dữ liệu huấn luyện bằng cách sử dụng hệ thống tệp hiệu suất cao, đàn hồi với Amazon EKS và CNCF Fluid
Fluid cung cấp một giải pháp đột phá thông qua tích hợp liền mạch với Kubernetes. Nó cung cấp hỗ trợ toàn diện cho nhiều hệ thống tệp, chẳng hạn như Alluxio, JuiceFS, Curvine, Jindo và Vineyard, đồng thời cho phép mở rộng tài nguyên tùy chỉnh. Tích hợp sâu của Fluid với Kubernetes bao gồm nhiều cơ chế lập lịch khác nhau, chẳng hạn như Cluster Autoscaler (CA), Horizontal Pod Autoscaler (HPA), Custom Pod Autoscaler (CPA) và Kubernetes Event Driven Autoscaler (KEDA). Một đổi mới quan trọng của Fluid là khái niệm Elastic Dataset, trừu tượng hóa các phụ thuộc cụ thể của nền tảng để truy cập dữ liệu ứng dụng. Cách tiếp cận không phụ thuộc vào môi trường này cho phép Fluid hoạt động trên các môi trường đa dạng, chẳng hạn như các cluster Kubernetes gốc, biên, serverless và triển khai đa cluster. Hơn nữa, tính năng Elastic Dataset hỗ trợ định nghĩa đặc điểm dữ liệu chi tiết, chẳng hạn như xử lý tệp nhỏ và thuộc tính đọc/ghi.
Khi triển khai Fluid với các hệ thống lưu trữ khác nhau, nhiều tùy chọn Runtime có sẵn về các hệ thống tệp hiệu suất cao trên Amazon EKS. JuiceFS nổi bật là một lựa chọn hấp dẫn với khả năng tuân thủ POSIX, điều này quan trọng đối với các khối lượng công việc phân tích và xử lý dữ liệu. Việc triển khai POSIX trong JuiceFS cung cấp bốn tính năng thiết yếu: 1/ các hoạt động nguyên tử đảm bảo thành công hoặc thất bại hoàn toàn của các hoạt động tệp, 2/ khả năng hiển thị ngay lập tức của các ghi trên các tiến trình, 3/ tính nhất quán siêu dữ liệu nghiêm ngặt cho các cập nhật thuộc tính tệp ngay lập tức và 4/ tính nhất quán tuần tự duy trì thứ tự hoạt động được lập trình. Những đặc điểm này làm cho nó đặc biệt phù hợp với các quy trình làm việc cần tương tác thường xuyên của con người và các tác vụ xử lý dữ liệu đòi hỏi khắt khe. Hơn nữa, Curvine, một dự án bộ nhớ đệm phân tán hiệu suất cao mới được mở nguồn xây dựng trên ngôn ngữ Rust, tích hợp với Fluid và tương thích POSIX. Dự án hiện đang trong giai đoạn phát triển nhanh chóng và đáng để theo dõi.
Thời gian cung cấp và giải phóng hệ thống tệp này có thể được tối ưu hóa để hoàn thành trong vòng vài phút, điều này có thể giúp hỗ trợ tích hợp vào các quy trình làm việc vận hành hàng ngày và giúp cải thiện hiệu quả hoạt động.
Đạt được điều phối tài nguyên và quy trình huấn luyện mô hình học sâu bằng Amazon EKS, KubeRay và Ray Train
KubeRay là một Kubernetes operator mạnh mẽ tích hợp liền mạch Ray Clusters vào môi trường Kubernetes, cho phép điều phối hiệu quả các khối lượng công việc tính toán phân tán. Nó đóng vai trò là cầu nối giữa khả năng tính toán phân tán của Ray và khả năng điều phối container của Kubernetes để các tổ chức có thể sử dụng sức mạnh của cả hai công nghệ. Người dùng có thể sử dụng KubeRay để triển khai, mở rộng và quản lý Ray Clusters trong hạ tầng Kubernetes của họ bằng cách sử dụng API Kubernetes cho tài nguyên tính toán, mạng và lưu trữ. Operator hỗ trợ nhiều mô hình triển khai khác nhau, chẳng hạn như RayCluster để chạy các ứng dụng phân tán, RayJob cho các tác vụ xử lý hàng loạt và RayService để phục vụ các mô hình ML. KubeRay có các tính năng tích hợp sẵn, chẳng hạn như tự động mở rộng quy mô, khả năng chịu lỗi và quản lý tài nguyên, để nó có thể chạy các khối lượng công việc AI/ML phức tạp trong môi trường sản xuất. Tích hợp này đặc biệt có giá trị đối với các tổ chức muốn chuẩn hóa hạ tầng của họ trên Kubernetes trong khi sử dụng khả năng tính toán phân tán của Ray cho các ứng dụng AI và Python.
Ray Train là một thư viện chuyên biệt trong hệ sinh thái Ray được thiết kế để hợp lý hóa và mở rộng quy mô huấn luyện ML phân tán trên nhiều máy và GPU. Nó trừu tượng hóa sự phức tạp của tính toán phân tán để các nhà phát triển có thể chuyển đổi liền mạch mã huấn luyện một máy của họ để chạy hiệu quả trên các cluster lớn. Thư viện cung cấp hỗ trợ mạnh mẽ cho nhiều framework ML như PyTorch, TensorFlow và XGBoost, điều này làm cho nó rất linh hoạt cho các quy trình làm việc AI khác nhau. Thông qua trừu tượng hóa Trainer của nó, Ray Train xử lý các khía cạnh huấn luyện phân tán như quản lý tiến trình worker, phân bổ tài nguyên và giao tiếp giữa các node. Nó vượt trội trong các kịch bản liên quan đến các mô hình hoặc tập dữ liệu lớn, cung cấp cả khả năng song song dữ liệu và mô hình để tối ưu hóa hiệu suất huấn luyện.
Giải thích thiết kế kiến trúc
Thiết kế kiến trúc trước đó nhằm mục đích đạt được tính song song mô hình phân tán và song song dữ liệu đàn hồi, linh hoạt, hiệu suất cao và tiết kiệm chi phí cho huấn luyện mô hình học sâu.
Triển khai cluster EKS
Đầu tiên, một loạt các script Terraform triển khai một cluster EKS, bao gồm hạ tầng mạng cơ bản: VPC, VPC endpoints, subnets, EIP, NAT Gateway, Security Groups, v.v. Dựa trên hạ tầng mạng này, cluster EKS được triển khai với hai nhóm node:
- Nhóm node Core: Ban đầu bao gồm ba phiên bản EC2 m5.2xlarge, được sử dụng làm head node của Ray Cluster (điểm vào để gửi Ray Jobs).
- Nhóm node GPU: Ban đầu bao gồm hai phiên bản EC2 g6.2xlarge, được sử dụng làm worker node của Ray Cluster, tạo thành nhóm tài nguyên tính toán thực tế để thực thi Ray Jobs.
Cả hai nhóm node đều được quản lý. Nếu bất kỳ máy nào bị lỗi, hệ thống sẽ nhanh chóng khởi động một máy thay thế để đảm bảo các tác vụ cluster tiếp tục với sự gián đoạn tối thiểu hoặc không có.
Định nghĩa Terraform liên quan đến nhóm node core được hiển thị như sau:
core_node_group = { name = "core-node-group" description = "EKS Core node group for hosting system add-ons" subnet_ids = compact([for subnet_id, cidr_block in zipmap(module.vpc.private_subnets, module.vpc.private_subnets_cidr_blocks) : substr(cidr_block, 0, 4) == "100." ? subnet_id : null] ) ami_type = " AL2023_x86_64_NVIDIA" min_size = 3 max_size = 8 desired_size = 3 instance_types = ["m5.2xlarge"] labels = { WorkerType = "ON_DEMAND" NodeGroupType = "core" workload = "rayhead" } tags = merge(local.tags, { Name = "core-node-grp" })}
Định nghĩa Terraform liên quan đến nhóm node GPU được hiển thị như sau:
g6_2xl_ng = { name = "g6-2xl-ng" description = "g6 2xlarge node group for hosting ML workloads" subnet_ids = [module.vpc.private_subnets[2]] ami_type = " AL2023_x86_64_NVIDIA" instance_types = ["g6.2xlarge pre_bootstrap_user_data = <<<-EOT /bin/setup-local-disks raid0 # Install latest version of aws cli mkdir /awscli \ && wget https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip -O /awscli/awscliv2.zip \ && unzip /awscli/awscliv2.zip -d /awscli/ \ && /awscli/aws/install --bin-dir /usr/local/bin --install-dir /usr/local/aws-cli --update \ && rm -rf /awscli EOT min_size = var.g6_2xl_min_size max_size = 2 desired_size = var.g6_2xl_desired_size enable_efa_support = fal labels = { "vpc.amazonaws.com/efa.present" = "false" instance-type = "g6-2xl" provisioner = "cluster-autoscaler"}
Công cụ quan sát
Cluster EKS cũng triển khai các công cụ quan sát thông qua các script Terraform: Prometheus để thu thập số liệu và Grafana cho các bảng điều khiển số liệu.
Định nghĩa Terraform liên quan đến Prometheus stack được hiển thị như sau:
enable_kube_prometheus_stack = truekube_prometheus_stack = { values = [templatefile("${path.module}/helm-values/kube-prometheus.yaml", { storage_class_type = kubernetes_storage_class_v1.default_gp3.id }) ] chart_version = "48.1.1" set_sensitive = [ { name = "grafana.adminPassword" value = data.aws_secretsmanager_secret_version.admin_password_version.secret_string } ],}
Tích hợp JuiceFS và Fluid
Cluster EKS lưu trữ JuiceFS runtime thông qua Fluid và lưu trữ dữ liệu huấn luyện. Toàn bộ triển khai Fluid được triển khai dưới dạng EKS Custom Resource Definitions (CRD).
Dự án Fluid nhằm mục đích triển khai nhiều phương tiện lưu trữ và lập lịch dựa trên Kubernetes, để phương tiện lưu trữ có thể chia sẻ lợi ích của Kubernetes trong khi làm cho các ứng dụng linh hoạt hơn khi truy cập lưu trữ. Sử dụng Kubernetes CRD để triển khai phương tiện lưu trữ cung cấp khả năng phục hồi, linh hoạt và phân bổ và giải phóng tài nguyên hiệu quả cao. Trong trường hợp này, JuiceFS được sử dụng làm phương tiện lưu trữ. Fluid triển khai các pod jfs-data-worker thông qua JuiceFSRuntime để lưu trữ dữ liệu huấn luyện, đồng thời định nghĩa jfs-dataset làm giao diện dữ liệu duy nhất cho các ứng dụng lớp trên. Siêu dữ liệu JuiceFS được lưu trữ trong một cluster Valkey.
Kiến trúc Fluid cũng như các khái niệm cốt lõi có thể được xem xét như được hiển thị trong liên kết GitHub này. Đối với trường hợp này, định nghĩa tài nguyên Fluid được hiển thị như sau:
Định nghĩa JuiceFS Secret Terraform được hiển thị như sau:
apiVersion: v1kind: Secretmetadata: name: jfs-secrettype: OpaquestringData: name: "jfs" metaurl: "${CACHE_URL}:6379/1"
Định nghĩa JuiceFS Dataset Terraform được hiển thị như sau:
kubectl apply -f - <<EOFapiVersion: data.fluid.io/v1alpha1kind: Datasetmetadata: name: jfs-datasetspec: accessModes: - ReadWriteMany mounts: - name: minio mountPoint: 'juicefs:///' options: bucket: $RAW_DATA_S3_URL storage: "s3" readOnly: false encryptOptions: - name: metaurl valueFrom: secretKeyRef: name: jfs-secret key: metaurl
Định nghĩa JuiceFS Runtime Terraform được hiển thị như sau:
apiVersion: data.fluid.io/v1alpha1kind: JuiceFSRuntimemetadata: name: jfs-datasetspec: replicas: 1 tieredstore: levels: - mediumtype: MEM path: /dev/shm quota: "1Gi" low: "0.1"
Giải thích cơ chế lưu trữ dữ liệu JuiceFS@Fluid
Sơ đồ sau đây cho thấy cách JuiceFS quản lý bộ nhớ đệm dữ liệu:
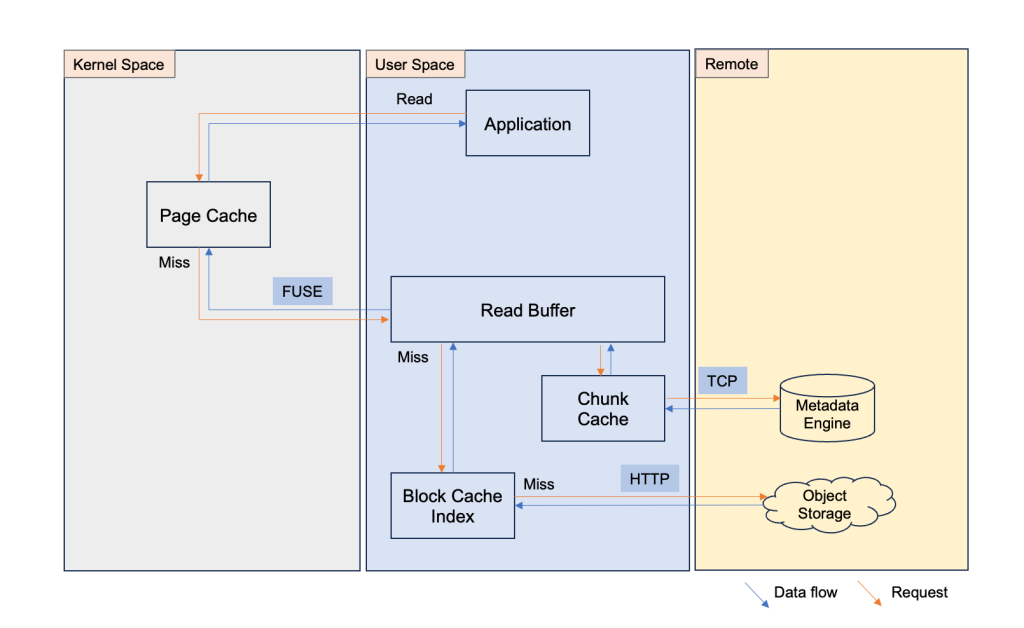
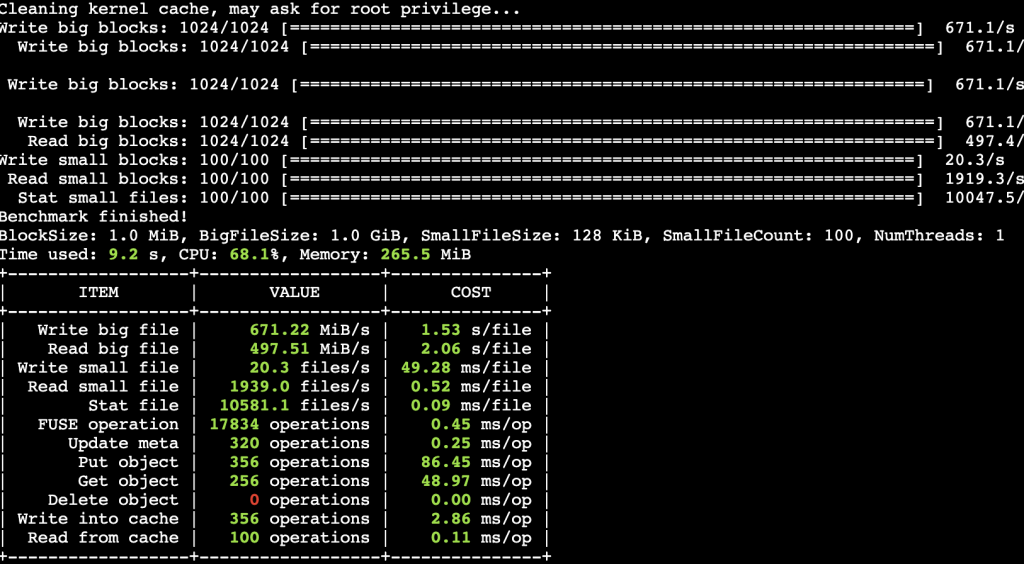
Ban đầu, bạn thiết lập một phiên bản JuiceFS và liên kết S3 bucket làm phương tiện sao lưu dữ liệu thô, và phiên bản ElastiCache for Redis làm công cụ siêu dữ liệu. JuiceFS tự hiển thị dưới dạng một điểm gắn kết trong hệ thống tệp của ứng dụng (ví dụ: thư mục dữ liệu dưới thư mục gốc, /data). Lần đầu tiên, sau khi bạn tải dữ liệu vào page cache, JuiceFS tự động đồng bộ hóa dữ liệu vào read buffer, tạo cấu trúc phân đoạn và lưu trữ siêu dữ liệu trong Redis thông qua TCP và dữ liệu thô được phân đoạn vào Amazon S3. Nếu có một người dùng khác muốn sử dụng dữ liệu mục tiêu cùng lúc, thì họ gắn hệ thống tệp JuiceFS và dữ liệu đã sẵn sàng để sử dụng. Lần tiếp theo nếu bạn sử dụng dữ liệu mục tiêu này (hệ thống tệp JuiceFS đã được giải phóng, vì vậy đó là dữ liệu trong bộ nhớ đệm), sau khi thiết lập hệ thống tệp JuiceFS và gắn nó trong hệ điều hành của ứng dụng, thì bạn có thể thấy dữ liệu mục tiêu ngay dưới điểm gắn kết (/data). Tuy nhiên, dữ liệu không thực sự nằm trong page cache vào thời điểm đó. Khi bạn thao tác dữ liệu mục tiêu (đọc/ghi), JuiceFS sử dụng siêu dữ liệu để tìm dữ liệu mục tiêu phù hợp và tải dữ liệu mục tiêu thông qua chỉ mục block cache, read buffer và cuối cùng là trong page cache. Do đó, hiệu suất của lần đọc đầu tiên dữ liệu hiện có chậm hơn, bởi vì chiến lược phân đoạn của JuiceFS tự động hợp nhất các tệp nhỏ trong lần đồng bộ hóa dữ liệu đầu tiên, hiệu suất tải dữ liệu có thể đạt 300-800 MBps hoặc thậm chí cao hơn, tùy thuộc vào thông số kỹ thuật của phiên bản EC2 đang lưu trữ hệ thống tệp JuiceFS. JuiceFS cung cấp một công cụ benchmark để kiểm tra hiệu suất của hệ thống tệp JuiceFS. Bạn có thể chạy juicefs bench <mount point> để nhận dữ liệu chi tiết về hệ thống tệp JuiceFS của bạn. Sau đây là ảnh chụp nhanh kết quả chạy công cụ benchmark trên một phiên bản EC2 C5.xlarge.
JuiceFS@Fluid tuân theo chính xác cơ chế hoạt động như được hiển thị trong hình này. Sự khác biệt là có các CRD secret, dataset, runtime, cũng như pvc (được tạo tự động). Hơn nữa, tất cả các tài nguyên đều chạy dưới dạng pod trong cluster EKS. Quá trình cung cấp JuiceFS@Fluid đã được trình bày trước đó.
Lập lịch nhóm Volcano (tùy chọn)
Lập lịch nhóm chủ yếu phản ánh vai trò của Volcano trong kiến trúc này. Trong môi trường sản xuất, nhiều nhóm thường có nhu cầu tính toán trong khi chỉ có một nhóm tài nguyên. Lập lịch nhóm của Volcano cung cấp khả năng quản lý tài nguyên và lập lịch công việc chi tiết trong các môi trường đa người thuê, đa khối lượng công việc phức tạp. Điều này thiết lập rằng các tác vụ phân tán chạy an toàn và hiệu quả. Đối với nguyên mẫu được trình bày trong bài viết này, Lập lịch nhóm Volcano không phải là điều kiện tiên quyết. Cụ thể, lập lịch nhóm Volcano có thể:
- Phân bổ các nhóm tài nguyên chuyên dụng cho các nhóm/ứng dụng khác nhau
- Ngăn chặn các công việc/người dùng đơn lẻ độc chiếm tài nguyên cluster
- Hỗ trợ cơ chế mượn và chia sẻ tài nguyên giữa các hàng đợi
Các hàng đợi Volcano là các nhóm logic được tạo và cấu hình thông qua CRD hàng đợi của Volcano. Lập lịch nhóm tuân theo nguyên tắc “tất cả hoặc không có gì”: hoặc tất cả các tác vụ trong một công việc được lập lịch cùng nhau, hoặc không có tác vụ nào được lập lịch, điều này tránh lãng phí tài nguyên khi chỉ một số tác vụ có thể bắt đầu.
Định nghĩa Terraform của Volcano Queue CRD được hiển thị như sau:
apiVersion: scheduling.volcano.sh/v1beta1kind: Queuemetadata: name: ml-trainingspec: weight: 10 capability: cpu: 100 memory: 1000Gi nvidia.com/gpu: 16 reclaimable: true guarantee: cpu: 50 memory: 500Gi nvidia.com/gpu: 8
Triển khai Ray Cluster
Sau khi cluster EKS được thiết lập, một Ray Cluster CRD được tạo bằng cách chạy tệp YAML kubectl create -f raycluster-with-jfs.yaml. Là các CRD của cluster EKS, Amazon EKS lưu trữ chúng dưới dạng các pod đang chạy, bao gồm các Ray head node và worker node trong namespace mặc định. Hơn nữa, các pod volcano-admission, volcano-controller và volcano-scheduler trong namespace volcano-system nếu Volcano được sử dụng. Lợi ích của việc sử dụng CRD cho các node Ray bao gồm:
- Môi trường runtime của pod có thể được định nghĩa linh hoạt thông qua Docker image và chúng không bị giới hạn bởi hệ điều hành được cài đặt trên Amazon EC2.
- Nếu các pod bị lỗi, hệ thống sẽ tự động thử lại, đảm bảo việc thực thi tác vụ tiếp tục với sự gián đoạn tối thiểu.
Gửi và giám sát công việc
Sau khi Ray Cluster đang chạy, các Ray Jobs được định nghĩa dưới dạng CRD định dạng YAML và được gửi đến Ray Cluster thông qua kubectl create -f rayjob-training.yaml. Các công việc đã gửi có thể được giám sát thông qua Ray dashboard để xem trạng thái chạy và nhật ký chi tiết để gỡ lỗi tiềm năng và các bảng điều khiển Prometheus và Grafana để xem và giám sát trạng thái hoạt động của hệ thống.
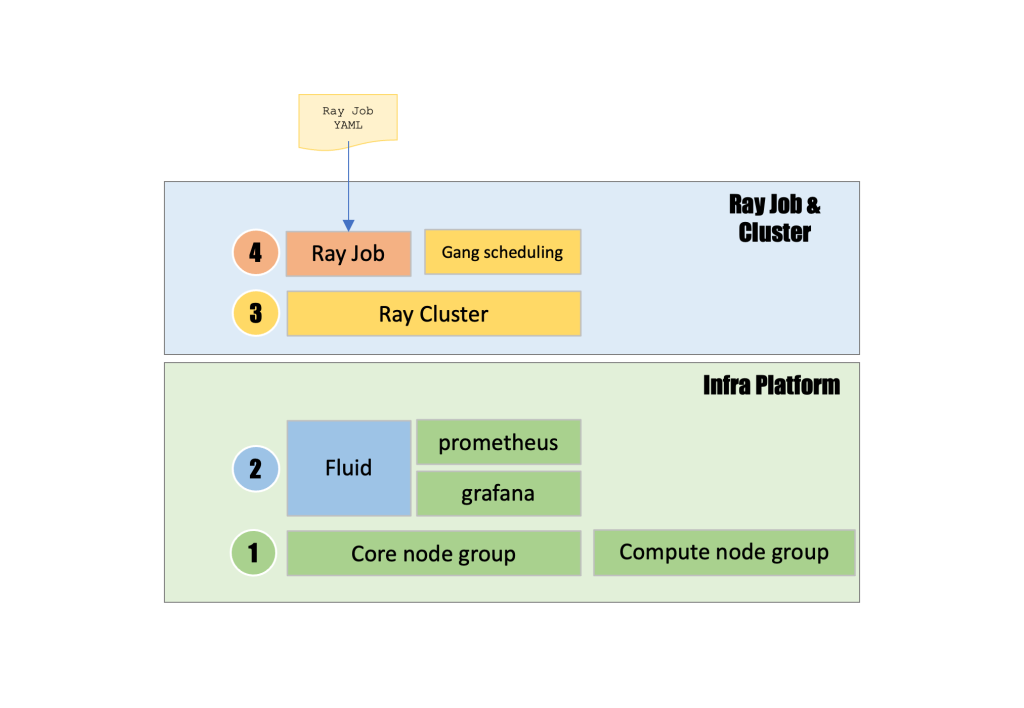
Sơ đồ kiến trúc này mô tả một hệ thống tính toán phân tán phân lớp, nơi các khả năng của Ray Job và Cluster được xây dựng trên nền tảng Infra Platform. Điều này thể hiện một hệ thống phân cấp bốn lớp bắt đầu bằng việc gửi Ray Job YAML ở trên cùng (lớp 4), kích hoạt thực thi Ray Job cùng với chức năng lập lịch nhóm, tiếp theo là tạo Ray Cluster (lớp 3) điều phối các khối lượng công việc tính toán phân tán, tất cả đều chạy trên một Infra Platform cơ bản bao gồm Fluid (lớp 2) quản lý bộ nhớ đệm dữ liệu thông minh và luồng tài nguyên giữa lưu trữ và tính toán. Đồng thời, Prometheus thu thập các số liệu và Grafana cung cấp các bảng điều khiển giám sát, với lớp nền tảng (lớp 1) bao gồm các nhóm node core và nhóm node tính toán cung cấp hạ tầng Kubernetes cơ bản. Điều này tạo ra một stack hoàn chỉnh cho phép tính toán phân tán có thể mở rộng với quản lý dữ liệu hiệu quả, lập lịch tài nguyên nâng cao và khả năng quan sát toàn diện trên toàn bộ nền tảng.
Triển khai kỹ thuật
Các phần sau đây phác thảo việc triển khai kỹ thuật cho giải pháp này.
Điều kiện tiên quyết
Trước khi bắt đầu, bạn cần những điều sau:
- Một tài khoản Amazon Web Services (AWS) với quyền quản trị viên
- AWS Command Line Interface (AWS CLI) phiên bản 2.0 trở lên đã được cài đặt và cấu hình
- kubectl phiên bản 1.30.4 trở lên đã được cài đặt
- eksctl phiên bản 0.212.0 trở lên đã được cài đặt
- Helm phiên bản 3.18.5 trở lên đã được cài đặt
- Terraform phiên bản 1.12.2 trở lên đã được cài đặt
- Đảm bảo rằng máy tính xách tay đã cài đặt ứng dụng docker.desktop
- Tạo hai S3 bucket trong AWS Region mục tiêu. Một để lưu trữ dữ liệu thô của JuiceFS và một để lưu trữ kết quả huấn luyện của Ray Cluster
Đảm bảo rằng tài khoản của bạn có ít nhất một VPC và một EIP có sẵn để cung cấp cluster EKS. Đảm bảo rằng AWS CLI, kubectl, eksctl, Helm và Terraform đã được cài đặt.
Cung cấp hạ tầng trên Amazon EKS
Clone repo GitHub bằng cách chạy các lệnh sau:
git clone https://github.com/aws-samples/sample-cap-quant.gitcd sample-cap-quant/quant-research/vit_tr_ray_on_gpu/infra
Cập nhật các biến sau trong 00_init_variables.sh theo ngữ cảnh cụ thể của bạn và lưu tệp.
# Basic configurationexport TF_VAR_name="<eks-cluster-name>"export TF_VAR_region="<region-id>"export TF_VAR_s3_bucket_name1="<amzn-s3-demo-bucket*, name-of-the-bucket-for-filesystem-metadata-storage>"export TF_VAR_s3_bucket_name2="<amzn-s3-demo-bucket*, name-of-the-bucket-for-storing-ray-training-result>"export TF_VAR_aws_account_id="<your-aws-account-id>"export TF_VAR_prefix_name="ray-results"
Tiếp theo, chạy lệnh sau:
chmod +x 00_init_variables.shsource ./00_init_variables.sh
Sau đó, chạy 01_install_platform.sh để thiết lập nền tảng hạ tầng bao gồm VPC, subnet, NAT Gateway, v.v., cluster EKS bao gồm nhóm node core và nhóm node tính toán.
chmod +x 01_install_platform.sh./01_install_platform.sh
Mất hơn 20 phút để tài nguyên được cung cấp và thiết lập. Sau khi bạn cung cấp cluster, hãy thêm ngữ cảnh cluster EKS vào jumpserver MacOS, để jumpserver có thể truy cập cluster EKS.
aws eks --region <region id> update-kubeconfig --name <eks cluster name> # region id like us-east-1
Kiểm tra trạng thái của tài nguyên bằng lệnh sau:
kubectl get nodes # there should be 5 nodes: 3 core nodes, 2 g6 2xlarge GPU nodes
Đầu ra lệnh kubectl get nodes hiển thị năm node; ba node core m5.2xlarge và hai node GPU g6.2xlarge, tất cả đều ở trạng thái Ready:

Thiết lập Fluid với JuiceFSRuntime trên Amazon EKS
chmod +x 02_install_fluid.sh./02_install_fluid.sh
Kiểm tra trạng thái của Fluid. Hơn nữa, kiểm tra trạng thái của jfs-secret, trạng thái của jfs-dataset, trạng thái của jfs runtime và trạng thái của jfs pvc. Sử dụng lệnh sau để kiểm tra trạng thái của jfs-secret: kubectl get secrets
Bảng điều khiển terminal hiển thị trạng thái của JFS Secret jfs-secret:

Sử dụng lệnh sau để kiểm tra trạng thái của jfs-dataset: kubectl get datasets
Bảng điều khiển terminal hiển thị trạng thái của JFS Dataset jfs-dataset:

Sử dụng lệnh sau để kiểm tra trạng thái của JFS Runtime: kubectl get juicefsruntime
Bảng điều khiển terminal hiển thị trạng thái của JFS Runtime jfs-dataset:

Sử dụng lệnh sau để kiểm tra trạng thái của JFS PVC: kubectl get pvc
Bảng điều khiển terminal hiển thị trạng thái của PVC jfs-dataset:

Chuẩn bị và lưu trữ dữ liệu huấn luyện
chmod +x 03_load_data.sh./03_load_data.sh
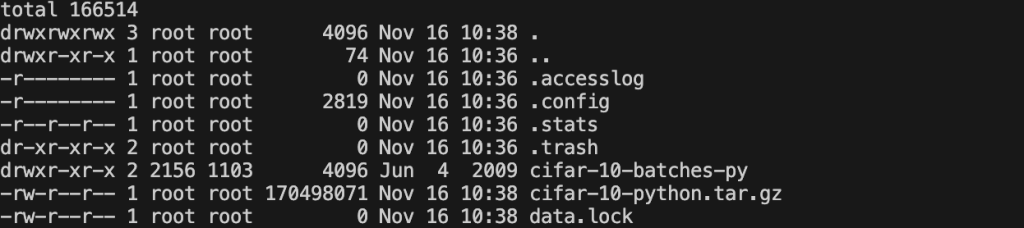
Bạn có thể kiểm tra trạng thái của dữ liệu huấn luyện bằng lệnh sau: kubectl exec -it data-load-pod -- /bin/bash -c "cd /data && ls -la" Bảng điều khiển terminal hiển thị tất cả các tệp dưới /data của pod data-load-pod:
Tạo Amazon ECR image
Đảm bảo rằng ứng dụng docker.desktop đã được mở. Xây dựng ECR image bằng cách chạy 00_build_image.sh:
cd ../appchmod +x 00_build_image.sh./00_build_image.sh
Ban đầu, mất 40–60 phút để tạo ECR image.
Tạo Ray Cluster
Tạo Ray Cluster bằng cách chạy lệnh sau:
chmod +x 01_deploy_ray_cluster.sh./01_deploy_ray_cluster.sh
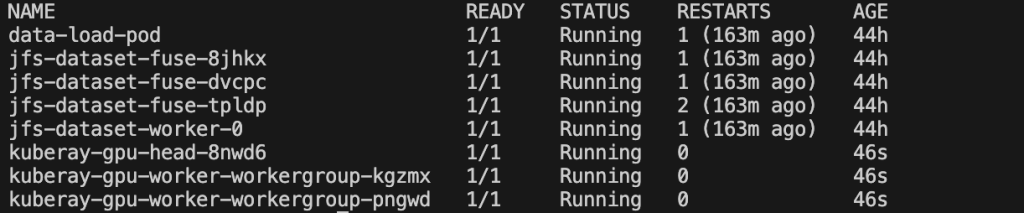
Chờ 5–6 phút để các pod Ray Cluster khởi tạo trong lần tạo đầu tiên. ECR image 14 GB cần thời gian để tải xuống. Bạn có thể chạy kubectl get pods và sẽ nhận được ảnh chụp nhanh sau. Bảng điều khiển terminal hiển thị tất cả các pod dưới namespace mặc định.
Gửi Ray Job
Chạy lệnh sau để gửi Ray Job đến Ray Cluster vừa tạo:
chmod +x 02_create_rayjob.sh./02_create_rayjob.sh
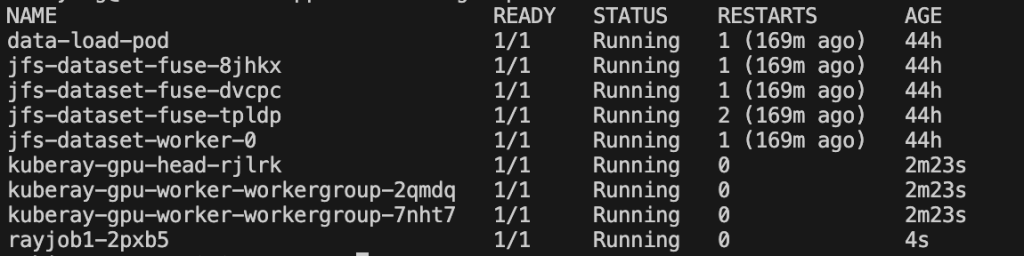
Bạn có thể chạy kubectl get pods và nhận được ảnh chụp nhanh sau. Bảng điều khiển terminal hiển thị tất cả các pod dưới namespace mặc định:
Giám sát Ray Job
Bật Ray Cluster dashboard bằng lệnh sau: kubectl port-forward service/kuberay-gpu-head-svc 8265:8265
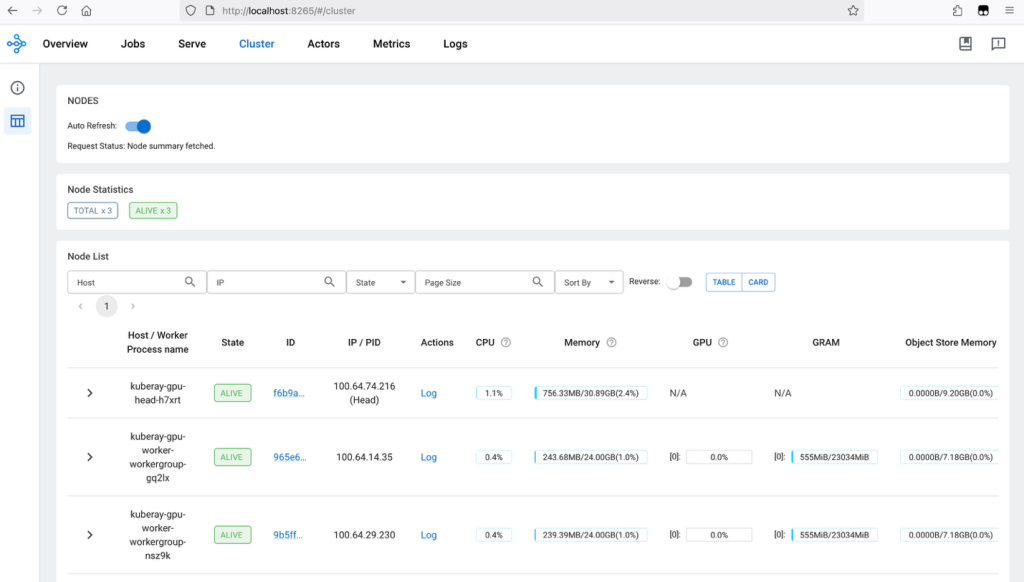
Truy cập localhost:8265 trên trình duyệt cục bộ. Dashboard mặc định là dashboard Overview. Chuyển sang dashboard Cluster để lấy thông tin của Ray Cluster. Hình sau cho thấy Ray Cluster dashboard hiển thị ba worker node đang hoạt động:
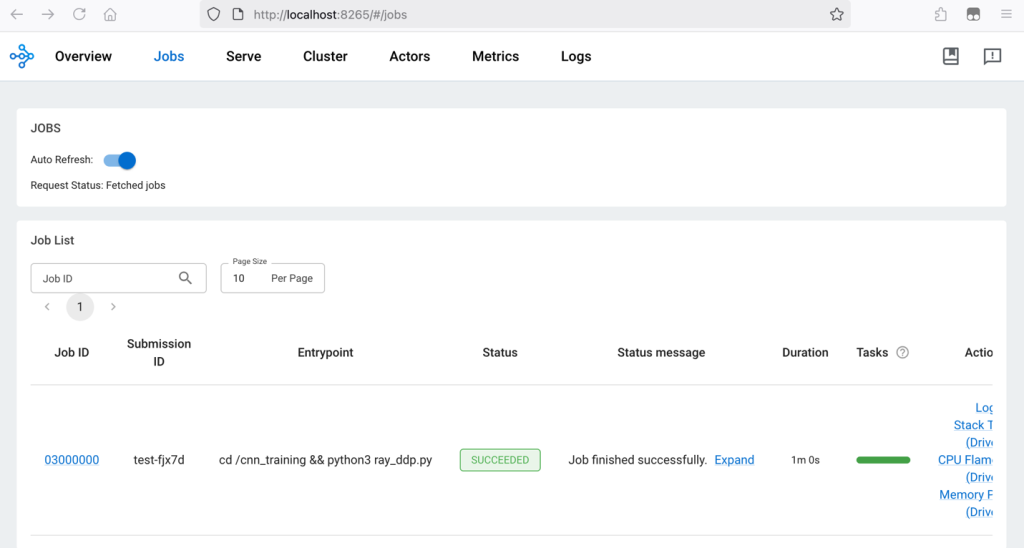
Truy cập localhost:8265 trên trình duyệt cục bộ và chuyển sang tab Job. Ray Cluster dashboard cho thấy Ray Job đã hoàn thành thành công:
Khả năng quan sát (tùy chọn)
Bật Prometheus dashboard bằng lệnh sau: kubectl port-forward svc/kube-prometheus-stack-prometheus 9090:9090 -n kube-prometheus-stack
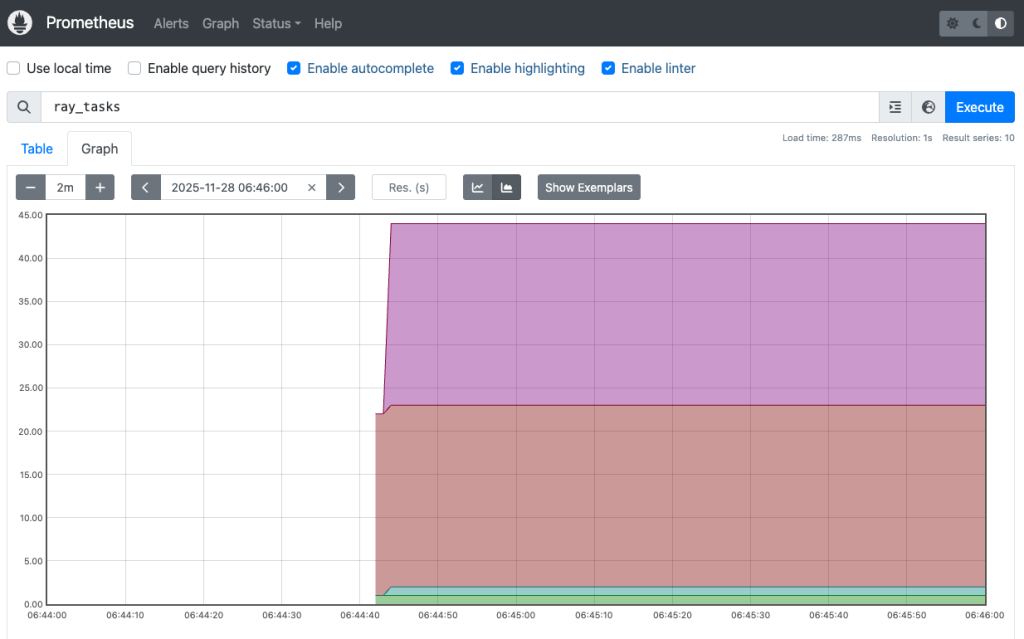
Truy cập localhost:9090 trên trình duyệt cục bộ, và sau đó chuyển sang trang Graph. Tìm query ray_tasks trong danh sách thả xuống  để hiển thị trạng thái tác vụ Ray. Prometheus dashboard, được hiển thị trong hình sau, cho thấy dòng thời gian chạy của các tác vụ Ray:
để hiển thị trạng thái tác vụ Ray. Prometheus dashboard, được hiển thị trong hình sau, cho thấy dòng thời gian chạy của các tác vụ Ray:
Bật Grafana dashboard bằng lệnh sau: kubectl port-forward svc/kube-prometheus-stack-grafana 3000:80 -n kube-prometheus-stack Truy cập localhost:3000 trên trình duyệt cục bộ. Tên người dùng và mật khẩu đăng nhập mặc định có thể được truy xuất bằng các lệnh sau: kubectl get secret kube-prometheus-stack-grafana -n kube-prometheus-stack -o jsonpath='{.data.admin-user}' | base64 -dkubectl get secret kube-prometheus-stack-grafana -n kube-prometheus-stack -o jsonpath='{.data.admin-password}' | base64 -d
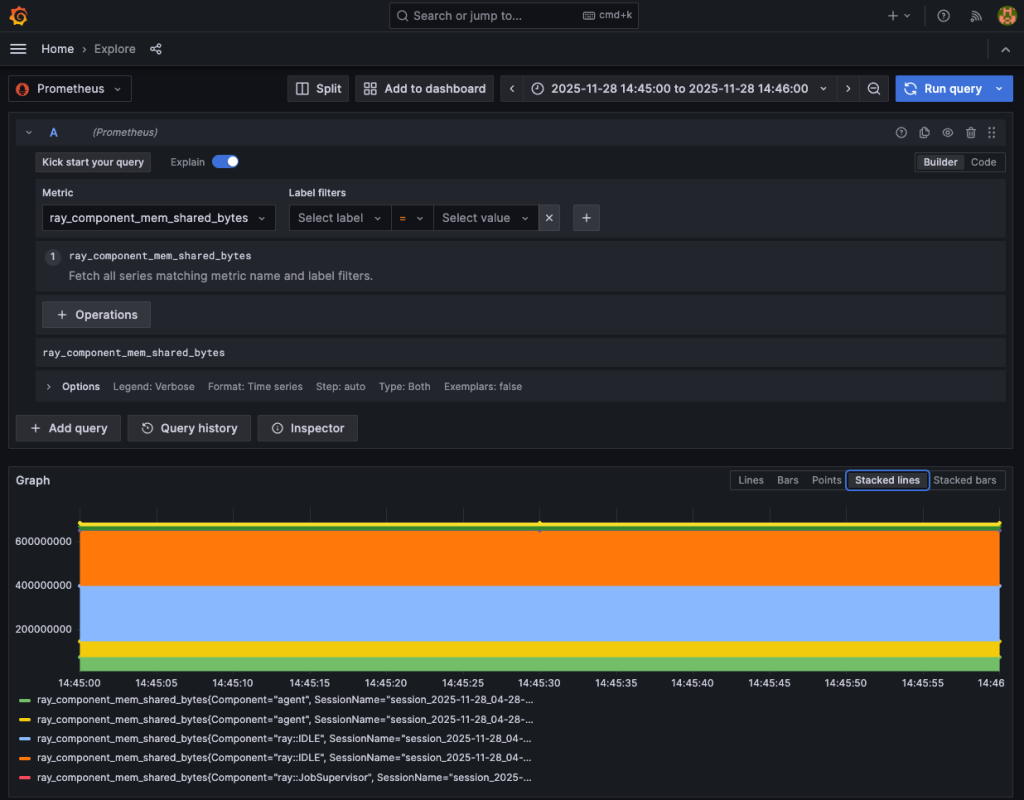
Tạo một dashboard mới bằng cách chọn Dashboards hoặc Explore. Chọn Prometheus làm nguồn dữ liệu, sau đó tìm ray_component_mem_shared_bytes trong danh sách thả xuống Metric. Grafana dashboard hiển thị trạng thái sử dụng bộ nhớ của các thành phần Ray Cluster:
Dọn dẹp
Việc không hoàn thành các bước dọn dẹp này sẽ dẫn đến các khoản phí AWS liên tục. Mặt phẳng điều khiển cluster EKS có giá khoảng 0.10 USD/giờ, các phiên bản EC2 có giá khoảng 5-10 USD/giờ tổng cộng và các tài nguyên khác sẽ thêm chi phí. Hoàn thành tất cả các bước dọn dẹp để tránh các chi phí không cần thiết. Chạy cleanup.sh trong thư mục vit_tr_ray_on_gpu/infra để giải phóng tất cả tài nguyên.
cd ../infrachmod +x cleanup.sh./cleanup.sh
Xóa các S3 bucket (TF_VAR_s3_bucket_name1 và TF_VAR_s3_bucket_name2) bằng các lệnh sau:
# First, delete all objects in bucket 1aws s3 rm s3://TF_VAR_s3_bucket_name1 --recursive# Then delete the empty bucket 1aws s3api delete-bucket --bucket TF_VAR_s3_bucket_name1# First, delete all objects in bucket 2aws s3 rm s3://TF_VAR_s3_bucket_name2 --recursive# Then delete the empty bucket 2aws s3api delete-bucket --bucket TF_VAR_s3_bucket_name2
Nếu việc xóa không thành công do phiên bản, hãy thêm cờ --delete-markers và --versions vào lệnh rm. Đối với các bucket được bảo vệ bằng MFA, bạn cần tham số --mfa. Kiểm tra các chính sách bucket có thể ngăn việc xóa.
Kết luận
Bài viết này giải thích và trình bày cách xây dựng một hệ thống tệp hiệu suất cao, đàn hồi bằng Fluid và Amazon EKS. Hệ thống tệp này có thông lượng cao và có thể cung cấp khả năng cung cấp và giải phóng bộ nhớ đệm dữ liệu nhanh chóng. Điều này làm cho nó lý tưởng cho các tổ chức muốn tìm một hệ thống tệp hiệu suất cao và tiết kiệm chi phí. Hơn nữa, bài viết này trình bày cách xây dựng một ứng dụng huấn luyện DL end-to-end bằng KubeRay và Fluid trên Amazon EKS. Toàn bộ stack là một cách tiếp cận được khuyến nghị cho các kỹ sư DevOps, chuyên gia MLOps và kiến trúc sư hạ tầng AI.
Về tác giả

Shiyang Wei là Kiến trúc sư Giải pháp Cấp cao tại AWS. Anh chuyên về kiến trúc hệ thống đám mây và thiết kế giải pháp cho ngành tài chính. Đặc biệt, anh tập trung vào các ứng dụng dữ liệu và AI cũng như tác động của việc tuân thủ quy định đối với thiết kế kiến trúc đám mây trong lĩnh vực tài chính. Anh có hơn 15 năm kinh nghiệm trong phát triển và thiết kế kiến trúc miền dữ liệu.

Dongdong Yang là Kiến trúc sư Giải pháp Chuyên gia về Container tại AWS, nơi anh tập trung vào các khách hàng đang xây dựng các nền tảng AI/ML và dữ liệu hiện đại trên Amazon EKS. Anh đã dành nhiều năm trong không gian Kubernetes, container và hạ tầng đám mây mã nguồn mở.
