Tác giả: David Meredith, Josh Zacharias, Monica Raj, Dwaragha Sivalingam, Naman Sharma, Nkechinyere Nneka Agu, Tryambak Gangopadhyay, và Yingwei Yu
Ngày phát hành: 05 FEB 2026
Chuyên mục: Amazon Bedrock, Customer Solutions, Generative AI
Đây là bài đăng của khách đồng tác giả với David Meredith và Josh Zacharias từ Associa.
Associa, công ty quản lý cộng đồng lớn nhất Bắc Mỹ, giám sát khoảng 7,5 triệu chủ nhà với 15.000 nhân viên tại hơn 300 văn phòng chi nhánh. Công ty quản lý khoảng 48 triệu tài liệu trên 26 TB dữ liệu, nhưng hệ thống quản lý tài liệu hiện có của họ thiếu khả năng phân loại tự động hiệu quả, gây khó khăn trong việc tổ chức và truy xuất tài liệu trên nhiều loại tài liệu. Hàng ngày, nhân viên dành vô số giờ để phân loại và sắp xếp tài liệu đến theo cách thủ công—một quy trình tốn thời gian, dễ xảy ra lỗi, tạo ra các nút thắt cổ chai trong hiệu quả hoạt động và có khả năng dẫn đến chậm trễ hoạt động và giảm năng suất.
Associa đã hợp tác với AWS Generative AI Innovation Center để xây dựng một hệ thống phân loại tài liệu được hỗ trợ bởi generative AI, phù hợp với tầm nhìn dài hạn của Associa về việc sử dụng generative AI để đạt được hiệu quả hoạt động trong quản lý tài liệu. Giải pháp này tự động phân loại tài liệu đến với độ chính xác cao, xử lý tài liệu hiệu quả và mang lại khoản tiết kiệm chi phí đáng kể trong khi vẫn duy trì sự xuất sắc trong hoạt động. Hệ thống phân loại tài liệu, được phát triển bằng cách sử dụng Generative AI Intelligent Document Processing (GenAI IDP) Accelerator, được thiết kế để tích hợp liền mạch vào các quy trình làm việc hiện có. Nó cách mạng hóa cách nhân viên tương tác với các hệ thống quản lý tài liệu bằng cách giảm thời gian dành cho các tác vụ phân loại thủ công.
Bài đăng này thảo luận về cách Associa đang sử dụng Amazon Bedrock để tự động phân loại tài liệu của họ và giúp nâng cao năng suất của nhân viên.
Tổng quan giải pháp
GenAI IDP Accelerator là một giải pháp xử lý tài liệu dựa trên đám mây được xây dựng trên AWS, tự động trích xuất và tổ chức thông tin từ nhiều loại tài liệu khác nhau. Hệ thống sử dụng công nghệ OCR và generative AI để chuyển đổi tài liệu phi cấu trúc thành dữ liệu có cấu trúc, có thể sử dụng được, đồng thời mở rộng quy mô liền mạch để xử lý khối lượng tài liệu lớn.
Accelerator được xây dựng với thiết kế linh hoạt, mô-đun sử dụng các mẫu AWS CloudFormation có thể xử lý các loại xử lý tài liệu khác nhau trong khi chia sẻ cơ sở hạ tầng cốt lõi để quản lý công việc, theo dõi tiến độ và giám sát hệ thống. Accelerator hỗ trợ ba mẫu xử lý. Chúng tôi sử dụng Mẫu 2 cho giải pháp này bằng cách sử dụng OCR (Amazon Textract) và phân loại (Amazon Bedrock). Sơ đồ sau minh họa kiến trúc này.
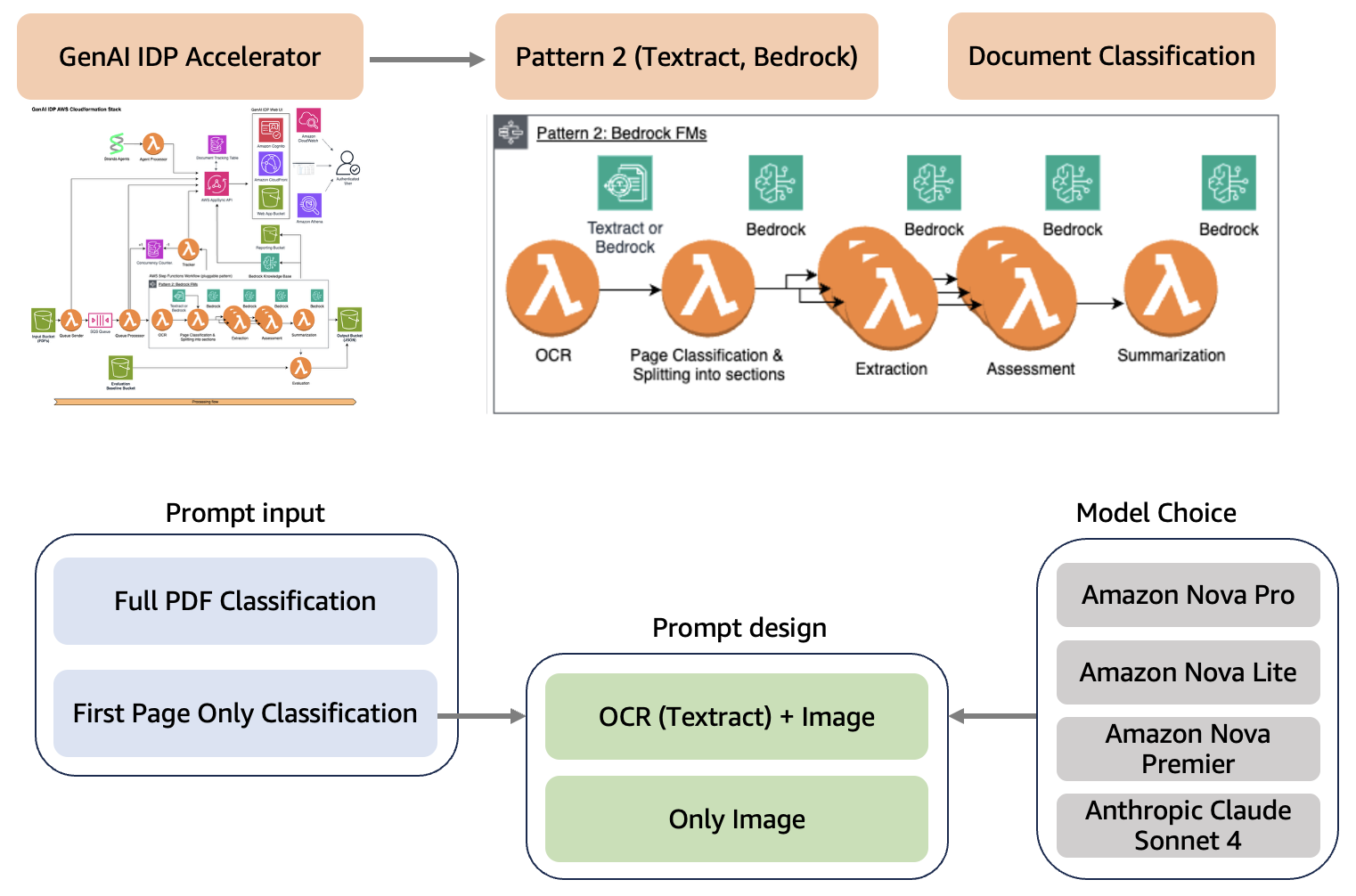
Chúng tôi đã tối ưu hóa quy trình phân loại tài liệu bằng cách đánh giá ba khía cạnh chính:
- Đầu vào Prompt – Toàn bộ tài liệu PDF (tất cả các trang) so với chỉ trang đầu tiên
- Thiết kế Prompt – Prompt đa phương thức với dữ liệu OCR (sử dụng Amazon Textract
analyze_document_layout) so với chỉ hình ảnh tài liệu - Lựa chọn mô hình – Amazon Nova Lite, Amazon Nova Pro, Amazon Nova Premier và Anthropic’s Claude Sonnet 4 trên Amazon Bedrock
Khung đánh giá toàn diện này đã giúp chúng tôi xác định cấu hình mang lại độ chính xác cao nhất đồng thời giảm thiểu chi phí suy luận xử lý cho các loại tài liệu và yêu cầu hoạt động cụ thể của Associa. Bộ dữ liệu đánh giá bao gồm 465 tài liệu PDF thuộc tám loại tài liệu riêng biệt. Bộ dữ liệu bao gồm một số mẫu được xác định là tài liệu nháp hoặc thư từ email. Các mẫu này được phân loại là loại tài liệu Unknown do không đủ tiêu chí phân loại. Sự phân bố các loại tài liệu giữa các lớp không cân bằng, dao động từ 6 mẫu cho Policies and Resolutions đến 155 mẫu cho Minutes.
Đánh giá: Đầu vào Prompt
Chúng tôi bắt đầu đánh giá ban đầu bằng cách sử dụng toàn bộ tài liệu PDF, trong đó tất cả các trang của PDF được sử dụng làm đầu vào cho prompt để phân loại. Bảng sau đây cho thấy độ chính xác cho việc phân loại toàn bộ PDF bằng Amazon Nova Pro với OCR và hình ảnh. Chúng tôi quan sát thấy độ chính xác phân loại trung bình là 91% khi xem xét các loại tài liệu khác nhau với chi phí trung bình là 1,10 cent cho mỗi tài liệu.
| Loại tài liệu | Số lượng mẫu | Số lượng mẫu được phân loại chính xác | Độ chính xác phân loại | Chi phí phân loại (tính bằng Cent) |
|---|---|---|---|---|
| Bylaws | 46 | 42 | 91% | 1.52c |
| CCR Declarations | 22 | 19 | 86% | 1.55c |
| Certificate of Insurance | 74 | 74 | 100% | 1.49c |
| Contracts | 71 | 66 | 93% | 1.48c |
| Minutes | 155 | 147 | 95% | 1.47c |
| Plat Map | 21 | 20 | 95% | 1.45c |
| Policies and Resolutions | 6 | 5 | 83% | 0.35c |
| Rules and Regulations | 50 | 44 | 88% | 0.36c |
| Unknown | 20 | 8 | 40% | 0.24c |
| Overall | 465 | 425 | 91% | 1.10c |
Việc sử dụng toàn bộ PDF để phân loại tài liệu cho thấy độ chính xác 100% đối với Certificate of Insurance và 95% đối với Minutes. Hệ thống đã phân loại chính xác 425 trong số 465 tài liệu. Tuy nhiên, đối với loại tài liệu Unknown, nó chỉ đạt độ chính xác 40%, phân loại chính xác 8 trong số 20 tài liệu.
Tiếp theo, chúng tôi đã thử nghiệm chỉ sử dụng trang đầu tiên của tài liệu PDF để phân loại, như được hiển thị trong bảng sau. Cách tiếp cận này đã cải thiện độ chính xác tổng thể từ 91% lên 95% với 443 trong số 465 tài liệu được phân loại chính xác, đồng thời giảm chi phí phân loại trên mỗi tài liệu từ 1,10 cent xuống 0,55 cent.
| Loại tài liệu | Số lượng mẫu | Số lượng mẫu được phân loại chính xác | Độ chính xác phân loại | Chi phí phân loại (tính bằng Cent) |
|---|---|---|---|---|
| Bylaws | 46 | 44 | 96% | 0.55c |
| CCR Declarations | 22 | 21 | 95% | 0.55c |
| Certificate of Insurance | 74 | 74 | 100% | 0.59c |
| Contracts | 71 | 64 | 90% | 0.56c |
| Minutes | 155 | 153 | 99% | 0.55c |
| Plat Map | 21 | 17 | 81% | 0.56c |
| Policies and Resolutions | 6 | 4 | 67% | 0.57c |
| Rules and Regulations | 50 | 49 | 98% | 0.56c |
| Unknown | 20 | 17 | 85% | 0.55c |
| Overall | 465 | 443 | 95% | 0.55c |
Ngoài việc cải thiện độ chính xác và giảm chi phí, cách tiếp cận chỉ sử dụng trang đầu tiên đã cải thiện đáng kể độ chính xác phân loại tài liệu Unknown từ 40% lên 85%. Các trang đầu tiên thường chứa các đặc điểm tài liệu đặc trưng nhất, trong khi các trang sau trong bản nháp hoặc chuỗi email có thể gây nhiễu làm lẫn lộn bộ phân loại. Kết hợp với tốc độ xử lý nhanh hơn và chi phí cơ sở hạ tầng thấp hơn, chúng tôi đã chọn cách tiếp cận chỉ sử dụng trang đầu tiên cho các đánh giá tiếp theo.
Đánh giá: Thiết kế Prompt
Tiếp theo, chúng tôi đã thử nghiệm về thiết kế prompt để đánh giá xem dữ liệu OCR có cần thiết cho việc phân loại tài liệu hay chỉ sử dụng hình ảnh tài liệu là đủ. Chúng tôi đã đánh giá bằng cách loại bỏ dữ liệu trích xuất văn bản OCR khỏi prompt và chỉ sử dụng hình ảnh trong một prompt đa phương thức. Cách tiếp cận này loại bỏ chi phí Amazon Textract và hoàn toàn dựa vào khả năng hiểu các đặc điểm hình ảnh của mô hình. Bảng sau đây cho thấy độ chính xác cho việc phân loại chỉ trang đầu tiên bằng Amazon Nova Pro chỉ với hình ảnh.
| Loại tài liệu | Số lượng mẫu | Số lượng mẫu được phân loại chính xác | Độ chính xác phân loại | Chi phí phân loại (tính bằng Cent) |
|---|---|---|---|---|
| Bylaws | 46 | 45 | 98% | 0.19c |
| CCR Declarations | 22 | 20 | 91% | 0.19c |
| Certificate of Insurance | 74 | 74 | 100% | 0.18c |
| Contracts | 71 | 63 | 89% | 0.18c |
| Minutes | 155 | 151 | 97% | 0.18c |
| Plat Map | 21 | 18 | 86% | 0.19c |
| Policies and Resolutions | 6 | 4 | 67% | 0.18c |
| Rules and Regulations | 50 | 48 | 96% | 0.18c |
| Unknown | 20 | 10 | 50% | 0.18c |
| Overall | 465 | 433 | 93% | 0.18c |
Cách tiếp cận phân loại chỉ bằng hình ảnh cho thấy các vấn đề tương tự như cách tiếp cận phân loại toàn bộ PDF. Mặc dù phương pháp này đạt độ chính xác tổng thể là 93%, nhưng đối với các loại tài liệu Unknown, nó chỉ có thể phân loại chính xác 10 trong số 20 tài liệu với độ chính xác 50%. Bảng sau đây tóm tắt đánh giá của chúng tôi về cách tiếp cận chỉ bằng hình ảnh.
| Độ chính xác phân loại tổng thể (Tất cả các loại tài liệu, bao gồm Unknown) | Độ chính xác phân loại (Loại tài liệu: Unknown) | Chi phí phân loại (tính bằng Cent) | |
|---|---|---|---|
| First page only classification (OCR + Image) | 95% | 85% | 0.55c |
| First page only classification (Only Image) | 93% | 50% | 0.18c |
Cách tiếp cận chỉ bằng hình ảnh loại bỏ chi phí OCR nhưng làm giảm độ chính xác tổng thể từ 95% xuống 93% và độ chính xác của tài liệu Unknown từ 85% xuống 50%. Việc phân loại tài liệu Unknown chính xác là rất quan trọng đối với việc xem xét thủ công sau này và hiệu quả hoạt động tại Associa. Chúng tôi đã chọn cách tiếp cận kết hợp OCR và hình ảnh để duy trì khả năng này.
Đánh giá: Lựa chọn mô hình
Sử dụng cấu hình tối ưu là phân loại chỉ trang đầu tiên với OCR và hình ảnh, chúng tôi đã đánh giá các mô hình khác nhau để xác định sự cân bằng tối ưu giữa độ chính xác và chi phí, như được tóm tắt trong bảng sau. Chúng tôi tập trung vào hiệu suất phân loại tổng thể, phân loại tài liệu không xác định và chi phí phân loại trên mỗi tài liệu.
| Độ chính xác phân loại tổng thể (Tất cả các loại tài liệu, bao gồm Unknown) | Độ chính xác phân loại (Loại tài liệu: Unknown) | Chi phí phân loại (tính bằng Cent) | |
|---|---|---|---|
| Amazon Nova Pro | 95% | 85% | 0.55c |
| Amazon Nova Lite | 95% | 50% | 0.41c |
| Amazon Nova Premier | 96% | 90% | 1.12c |
| Anthropic Claude Sonnet 4 | 95% | 95% | 1.21c |
Độ chính xác phân loại tổng thể dao động từ 95–96% trên các mô hình, với sự khác biệt về hiệu suất loại tài liệu Unknown. Certificate of Insurance, Plat Map và Minutes đạt độ chính xác 98–100% trên các mô hình. Anthropic’s Claude Sonnet 4 đạt độ chính xác tài liệu Unknown cao nhất (95%), tiếp theo là Amazon Nova Premier (90%) và Amazon Nova Pro (85%). Tuy nhiên, Anthropic’s Claude Sonnet 4 đã tăng chi phí phân loại từ 0,55 cent lên 1,21 cent cho mỗi tài liệu. Amazon Nova Premier đạt độ chính xác phân loại tổng thể tốt nhất ở mức 1,12 cent cho mỗi tài liệu. Xem xét sự đánh đổi giữa độ chính xác và chi phí, chúng tôi đã chọn Amazon Nova Pro làm lựa chọn mô hình tối ưu.
Kết luận
Associa đã xây dựng một hệ thống phân loại tài liệu được hỗ trợ bởi generative AI sử dụng Amazon Nova Pro trên Amazon Bedrock, đạt độ chính xác 95% với chi phí trung bình 0,55 cent cho mỗi tài liệu. GenAI IDP Accelerator tạo điều kiện thuận lợi cho việc mở rộng hiệu suất đáng tin cậy để xử lý khối lượng tài liệu lớn trên các chi nhánh của họ. Andrew Brock, Chủ tịch Dịch vụ Kỹ thuật số & Công nghệ & Giám đốc Thông tin tại Associa, cho biết: “Giải pháp được phát triển bởi AWS Generative AI Innovation Center cải thiện cách nhân viên của chúng tôi quản lý và tổ chức tài liệu, và chúng tôi dự đoán sẽ giảm đáng kể công sức thủ công trong xử lý tài liệu. Hệ thống phân loại tài liệu mang lại khoản tiết kiệm chi phí đáng kể và cải thiện hoạt động, đồng thời duy trì các tiêu chuẩn chính xác cao của chúng tôi trong việc phục vụ các cộng đồng dân cư.”
Tham khảo kho lưu trữ GitHub của GenAI IDP Accelerator để biết các ví dụ chi tiết và chọn Watch để luôn được thông báo về các bản phát hành mới. Nếu bạn muốn làm việc với AWS GenAI Innovation Center, vui lòng liên hệ với chúng tôi hoặc để lại bình luận.
Lời cảm ơn
Chúng tôi xin cảm ơn Mike Henry, Bob Strahan, Marcelo Silva và Mofijul Islam vì những đóng góp đáng kể, các quyết định chiến lược và sự hướng dẫn của họ trong suốt quá trình.
Về tác giả

David Meredith là Giám đốc Phát triển Phần mềm Nhân viên tại Associa. Ông giám sát các nỗ lực của nhóm Associa để tạo ra phần mềm cho 15.000 nhân viên của họ sử dụng hàng ngày. Ông có gần 20 năm kinh nghiệm với phần mềm trong ngành quản lý tài sản dân cư và sống ở khu vực Vancouver của BC, Canada.

Josh Zacharias là một Kỹ sư Phần mềm tại Associa, nơi ông là kỹ sư trưởng cho nhóm phần mềm nội bộ. Công việc của ông bao gồm kiến trúc các giải pháp full stack cho các phòng ban khác nhau trong công ty cũng như trao quyền cho các nhà phát triển khác trở thành những chuyên gia hiệu quả hơn trong việc phát triển phần mềm.

Monica Raj là Kiến trúc sư Deep Learning tại AWS Generative AI Innovation Center, nơi cô làm việc với các tổ chức thuộc nhiều ngành khác nhau để phát triển các giải pháp AI. Công việc của cô tập trung vào việc xây dựng và triển khai các giải pháp AI tác nhân, xử lý ngôn ngữ tự nhiên, tự động hóa trung tâm liên lạc và xử lý tài liệu thông minh. Monica có kinh nghiệm sâu rộng trong việc xây dựng các giải pháp AI có khả năng mở rộng cho khách hàng doanh nghiệp.

Tryambak Gangopadhyay là Nhà khoa học Ứng dụng cấp cao tại AWS Generative AI Innovation Center, nơi ông hợp tác với các tổ chức thuộc nhiều ngành công nghiệp đa dạng. Vai trò của ông bao gồm nghiên cứu và phát triển các giải pháp generative AI để giải quyết các thách thức kinh doanh quan trọng và đẩy nhanh việc áp dụng AI. Trước khi gia nhập AWS, Tryambak đã hoàn thành bằng Tiến sĩ tại Đại học bang Iowa.

Nkechinyere Agu là Nhà khoa học Ứng dụng tại AWS Generative AI Innovation Center, nơi cô làm việc với các tổ chức thuộc nhiều ngành khác nhau để phát triển các giải pháp AI. Công việc của cô tập trung vào việc phát triển các giải pháp AI đa phương thức, giải pháp AI tác nhân và xử lý ngôn ngữ tự nhiên. Trước khi gia nhập AWS, Nkechinyere đã hoàn thành bằng Tiến sĩ tại Học viện Bách khoa Rensselaer, Troy NY.

Naman Sharma là Chiến lược gia Generative AI tại AWS Generative AI Innovation Center, nơi ông hợp tác với các tổ chức để thúc đẩy việc áp dụng generative AI nhằm giải quyết các vấn đề kinh doanh ở quy mô lớn. Công việc của ông tập trung vào việc dẫn dắt khách hàng từ việc xác định phạm vi, triển khai và mở rộng các giải pháp tiên phong với các nhóm Chiến lược và Khoa học Ứng dụng của GenAIIC.

Yingwei Yu là Giám đốc Khoa học Ứng dụng tại Generative AI Innovation Center, có trụ sở tại Houston, Texas. Với kinh nghiệm sâu rộng trong học máy ứng dụng và generative AI, Yingwei dẫn dắt việc phát triển các giải pháp đổi mới trên nhiều ngành công nghiệp khác nhau.

Dwaragha Sivalingam là Kiến trúc sư Giải pháp cấp cao chuyên về generative AI tại AWS, đóng vai trò là cố vấn đáng tin cậy cho khách hàng về chuyển đổi đám mây và chiến lược AI. Với tám chứng chỉ AWS, bao gồm ML Specialty, ông đã giúp đỡ khách hàng trong nhiều ngành, bao gồm bảo hiểm, viễn thông, tiện ích, kỹ thuật, xây dựng và bất động sản. Là một người đam mê học máy, ông cân bằng cuộc sống chuyên nghiệp với thời gian dành cho gia đình, thích những chuyến đi đường dài, xem phim và chụp ảnh bằng drone.
