Tác giả: Yunyi Gao và Sharon Li
Ngày phát hành: 05 FEB 2026
Chuyên mục: Amazon Bedrock, Amazon Machine Learning, Amazon Nova, Artificial Intelligence, Best Practices
Các mô hình nhúng (embedding models) cung cấp sức mạnh cho nhiều ứng dụng hiện đại—từ tìm kiếm ngữ nghĩa và Retrieval-Augmented Generation (RAG) đến hệ thống đề xuất và hiểu nội dung. Tuy nhiên, việc lựa chọn một mô hình nhúng đòi hỏi sự cân nhắc kỹ lưỡng—sau khi bạn đã nhập dữ liệu, việc di chuyển sang một mô hình khác có nghĩa là phải nhúng lại toàn bộ kho dữ liệu của bạn, xây dựng lại các chỉ mục vector và xác thực chất lượng tìm kiếm từ đầu. Mô hình nhúng phù hợp nên mang lại hiệu suất cơ bản mạnh mẽ, thích ứng với trường hợp sử dụng cụ thể của bạn và hỗ trợ các phương thức bạn cần hiện tại và trong tương lai.
Mô hình Amazon Nova Multimodal Embeddings tạo ra các embedding được tùy chỉnh cho trường hợp sử dụng cụ thể của bạn—từ tìm kiếm văn bản hoặc hình ảnh đơn phương thức đến các ứng dụng đa phương thức phức tạp trải rộng trên tài liệu, video và nội dung hỗn hợp.
Trong bài viết này, bạn sẽ tìm hiểu cách sử dụng Amazon Nova Multimodal Embeddings cho các trường hợp sử dụng cụ thể của mình:
- Đơn giản hóa kiến trúc của bạn với tìm kiếm đa phương thức và truy xuất tài liệu trực quan
- Tối ưu hóa hiệu suất bằng cách chọn các tham số embedding phù hợp với khối lượng công việc của bạn
- Triển khai các mẫu phổ biến thông qua các hướng dẫn giải pháp cho tìm kiếm phương tiện, khám phá thương mại điện tử và truy xuất tài liệu thông minh
Hướng dẫn này cung cấp nền tảng thực tế để cấu hình Amazon Nova Multimodal Embeddings cho các hệ thống tìm kiếm tài sản truyền thông, trải nghiệm khám phá sản phẩm và ứng dụng truy xuất tài liệu.
Các trường hợp sử dụng kinh doanh đa phương thức
Bạn có thể sử dụng Amazon Nova Multimodal Embeddings trong nhiều kịch bản kinh doanh khác nhau. Bảng sau cung cấp các trường hợp sử dụng điển hình và ví dụ truy vấn:
| Phương thức | Loại nội dung | Trường hợp sử dụng | Ví dụ truy vấn điển hình |
|---|---|---|---|
| Truy xuất video | Tìm kiếm video ngắn | Thư viện tài sản và quản lý phương tiện | “Trẻ em mở quà Giáng sinh,” “Cá voi xanh vượt lên mặt biển” |
| Truy xuất video | Tìm kiếm phân đoạn video dài | Phim và giải trí, truyền thông phát sóng, giám sát an ninh | “Cảnh cụ thể trong phim,” “Đoạn phim cụ thể trong tin tức,” “Hành vi cụ thể trong giám sát” |
| Truy xuất video | Nhận dạng nội dung trùng lặp | Quản lý nội dung phương tiện | Nhận dạng video tương tự hoặc trùng lặp |
| Truy xuất hình ảnh | Tìm kiếm hình ảnh theo chủ đề | Thư viện tài sản, lưu trữ và quản lý phương tiện | “Xe hơi màu đỏ có cửa sổ trời chạy dọc bờ biển” |
| Truy xuất hình ảnh | Tìm kiếm hình ảnh tham chiếu | Thương mại điện tử, thiết kế | “Giày tương tự như thế này” +<image> |
| Truy xuất hình ảnh | Tìm kiếm hình ảnh ngược | Quản lý nội dung | Tìm nội dung tương tự dựa trên hình ảnh đã tải lên |
| Truy xuất tài liệu | Các trang thông tin cụ thể | Dịch vụ tài chính, đánh dấu tiếp thị, tài liệu quảng cáo | Thông tin văn bản, bảng dữ liệu, trang biểu đồ |
| Truy xuất tài liệu | Thông tin toàn diện đa trang | Nâng cao khả năng truy xuất kiến thức | Trích xuất thông tin toàn diện từ văn bản, biểu đồ và bảng đa trang |
| Truy xuất văn bản | Truy xuất thông tin theo chủ đề | Nâng cao khả năng truy xuất kiến thức | “Các bước tiếp theo trong quy trình ngừng hoạt động lò phản ứng” |
| Truy xuất văn bản | Phân tích độ tương đồng văn bản | Quản lý nội dung phương tiện | Phát hiện tiêu đề trùng lặp |
| Truy xuất văn bản | Phân cụm chủ đề tự động | Tài chính, chăm sóc sức khỏe | Phân loại và tóm tắt triệu chứng |
| Truy xuất văn bản | Truy xuất liên kết ngữ cảnh | Tài chính, pháp lý, bảo hiểm | “Số tiền yêu cầu bồi thường tối đa cho các vi phạm tai nạn kiểm tra doanh nghiệp” |
| Truy xuất âm thanh và giọng nói | Truy xuất âm thanh | Thư viện tài sản và quản lý tài sản phương tiện | “Nhạc chuông Giáng sinh,” “Hiệu ứng âm thanh tự nhiên yên tĩnh” |
| Truy xuất âm thanh và giọng nói | Tìm kiếm phân đoạn âm thanh dài | Podcast, ghi âm cuộc họp | “Người dẫn podcast thảo luận về khoa học thần kinh và tác động của giấc ngủ đến sức khỏe não bộ” |
Tối ưu hóa hiệu suất cho các trường hợp sử dụng cụ thể
Mô hình Amazon Nova Multimodal Embeddings tối ưu hóa hiệu suất cho các trường hợp sử dụng cụ thể với cài đặt tham số embeddingPurpose trong schema embedding. Nó có các chiến lược vector hóa khác nhau: chế độ hệ thống truy xuất và chế độ tác vụ ML.
- Chế độ hệ thống truy xuất (bao gồm
GENERIC_INDEXvà các tham số*_RETRIEVALkhác nhau) nhắm mục tiêu các kịch bản truy xuất thông tin, phân biệt giữa hai giai đoạn bất đối xứng: lưu trữ/INDEX và truy vấn/RETRIEVAL. Xem bảng sau để biết các danh mục hệ thống truy xuất và lựa chọn tham số.
| Giai đoạn | Lựa chọn tham số | Lý do |
|---|---|---|
| Giai đoạn lưu trữ (tất cả các loại) | GENERIC_INDEX | Tối ưu hóa cho việc lập chỉ mục và lưu trữ |
| Giai đoạn truy vấn (kho lưu trữ đa phương thức) | GENERIC_RETRIEVAL | Tìm kiếm trong nội dung hỗn hợp |
| Giai đoạn truy vấn (kho lưu trữ chỉ văn bản) | TEXT_RETRIEVAL | Tìm kiếm trong nội dung chỉ văn bản |
| Giai đoạn truy vấn (kho lưu trữ chỉ hình ảnh) | IMAGE_RETRIEVAL | Tìm kiếm trong hình ảnh (ảnh, minh họa, v.v.) |
| Giai đoạn truy vấn (kho lưu trữ chỉ hình ảnh tài liệu) | DOCUMENT_RETRIEVAL | Tìm kiếm trong hình ảnh tài liệu (quét, ảnh chụp màn hình PDF, v.v.) |
| Giai đoạn truy vấn (kho lưu trữ chỉ video) | VIDEO_RETRIEVAL | Tìm kiếm trong video |
| Giai đoạn truy vấn (kho lưu trữ chỉ âm thanh) | AUDIO_RETRIEVAL | Tìm kiếm trong âm thanh |
- Chế độ tác vụ ML (bao gồm các tham số
CLASSIFICATIONvàCLUSTERING) nhắm mục tiêu các kịch bản học máy. Tham số này cho phép mô hình linh hoạt thích ứng với các loại yêu cầu tác vụ hạ nguồn khác nhau.- CLASSIFICATION: Các vector được tạo ra phù hợp hơn để phân biệt ranh giới phân loại, tạo điều kiện thuận lợi cho việc huấn luyện bộ phân loại hạ nguồn hoặc phân loại trực tiếp.
- CLUSTERING: Các vector được tạo ra phù hợp hơn để hình thành các trung tâm cụm, tạo điều kiện thuận lợi cho các thuật toán phân cụm hạ nguồn.
Hướng dẫn xây dựng giải pháp tìm kiếm và truy xuất đa phương thức
Amazon Nova Multimodal Embeddings được xây dựng có mục đích cho tìm kiếm và truy xuất đa phương thức, đây là nền tảng của các hệ thống RAG dựa trên tác nhân đa phương thức. Các sơ đồ sau đây cho thấy cách xây dựng giải pháp tìm kiếm và truy xuất đa phương thức.
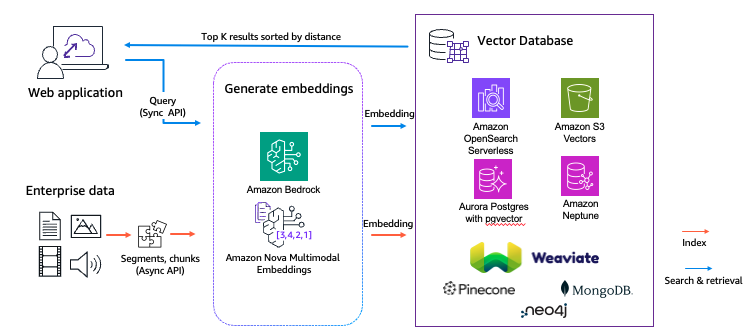
Trong một giải pháp tìm kiếm và truy xuất đa phương thức, được thể hiện trong sơ đồ trên, nội dung thô—bao gồm văn bản, hình ảnh, âm thanh và video—ban đầu được chuyển đổi thành các biểu diễn vector thông qua một mô hình embedding để đóng gói các đặc điểm ngữ nghĩa. Sau đó, các vector này được lưu trữ trong một cơ sở dữ liệu vector. Các truy vấn của người dùng cũng được chuyển đổi tương tự thành các vector truy vấn trong cùng một không gian vector. Việc truy xuất K mục liên quan nhất được thực hiện bằng cách tính toán độ tương đồng giữa vector truy vấn và các vector đã được lập chỉ mục. Giải pháp tìm kiếm và truy xuất đa phương thức này có thể được đóng gói dưới dạng một công cụ Model Context Protocol (MCP), từ đó tạo điều kiện truy cập trong một giải pháp RAG dựa trên tác nhân đa phương thức, được thể hiện trong sơ đồ sau.
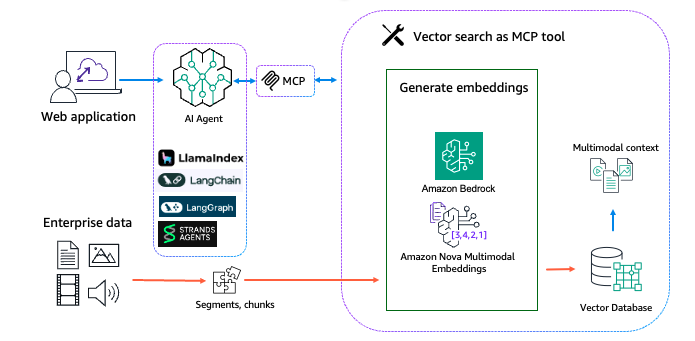
Giải pháp tìm kiếm và truy xuất đa phương thức có thể được chia thành hai luồng dữ liệu riêng biệt:
- Thu nạp dữ liệu
- Tìm kiếm và truy xuất thời gian chạy
Sau đây liệt kê các module phổ biến trong mỗi luồng dữ liệu, cùng với các công cụ và công nghệ liên quan:
| Luồng dữ liệu | Module | Mô tả | Công cụ và công nghệ phổ biến |
|---|---|---|---|
| Thu nạp dữ liệu | Tạo embedding | Chuyển đổi đầu vào (văn bản, hình ảnh, âm thanh, video, v.v.) thành các biểu diễn vector | Mô hình embedding. |
| Thu nạp dữ liệu | Lưu trữ embedding trong kho vector | Lưu trữ các vector đã tạo trong cơ sở dữ liệu vector hoặc cấu trúc lưu trữ để truy xuất sau này | Các cơ sở dữ liệu vector phổ biến |
| Tìm kiếm và truy xuất thời gian chạy | Thuật toán truy xuất độ tương đồng | Tính toán độ tương đồng và khoảng cách giữa các vector truy vấn và các vector đã lập chỉ mục, truy xuất các mục gần nhất | Các khoảng cách phổ biến: độ tương đồng cosine, tích vô hướng, khoảng cách Euclidean. Hỗ trợ cơ sở dữ liệu cho k-NN và ANN, chẳng hạn như Amazon OpenSearch k-NN |
| Tìm kiếm và truy xuất thời gian chạy | Truy xuất Top K và Cơ chế bỏ phiếu | Chọn K láng giềng gần nhất từ kết quả truy xuất, sau đó có thể kết hợp nhiều chiến lược (bỏ phiếu, xếp hạng lại, hợp nhất) | Ví dụ: K láng giềng gần nhất hàng đầu, hợp nhất truy xuất từ khóa và truy xuất vector (tìm kiếm lai) |
| Tìm kiếm và truy xuất thời gian chạy | Chiến lược tích hợp và Truy xuất lai | Kết hợp nhiều cơ chế truy xuất hoặc kết quả phương thức, chẳng hạn như từ khóa và vector hoặc, hợp nhất truy xuất văn bản và hình ảnh | Tìm kiếm lai (chẳng hạn như Amazon OpenSearch hybrid) |
Chúng ta sẽ khám phá một số trường hợp sử dụng kinh doanh đa phương thức và cung cấp tổng quan cấp cao về cách giải quyết chúng bằng Amazon Nova Multimodal Embeddings.
Trường hợp sử dụng: Truy xuất và phân loại sản phẩm
Các ứng dụng thương mại điện tử yêu cầu khả năng tự động phân loại hình ảnh sản phẩm và xác định các mặt hàng tương tự mà không cần gắn thẻ thủ công. Sơ đồ sau minh họa một giải pháp cấp cao:
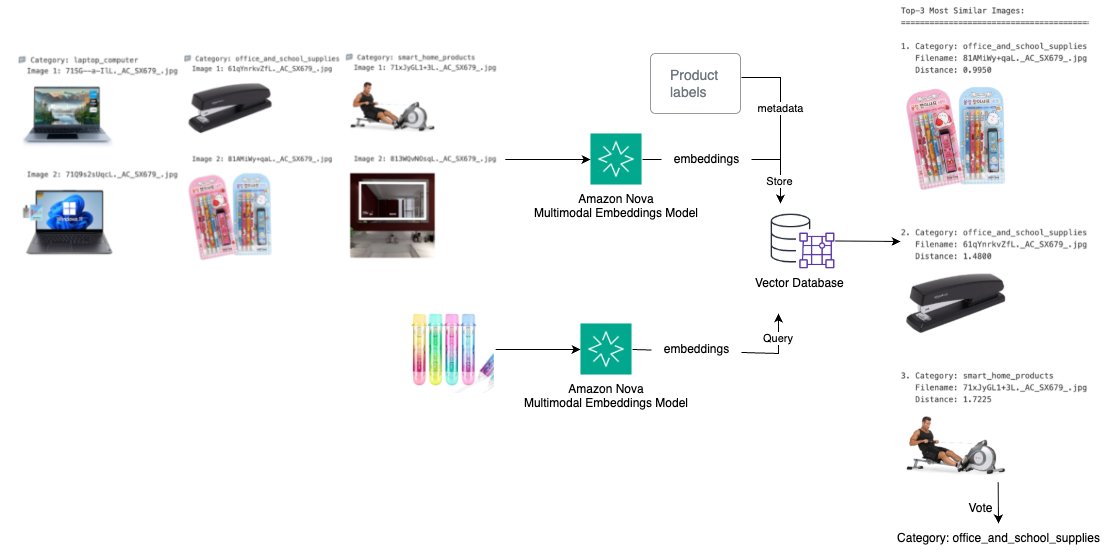
- Chuyển đổi hình ảnh sản phẩm thành embedding bằng cách sử dụng Amazon Nova Multimodal Embeddings
- Lưu trữ embedding và nhãn dưới dạng metadata trong cơ sở dữ liệu vector
- Truy vấn hình ảnh sản phẩm mới và tìm K sản phẩm tương tự hàng đầu
- Sử dụng cơ chế bỏ phiếu trên các kết quả truy xuất để dự đoán danh mục
Các tham số embedding chính:
| Tham số | Giá trị | Mục đích |
|---|---|---|
embeddingPurpose | GENERIC_INDEX (lập chỉ mục) và IMAGE_RETRIEVAL (truy vấn) | Tối ưu hóa cho việc truy xuất hình ảnh sản phẩm |
embeddingDimension | 1024 | Cân bằng độ chính xác và hiệu suất |
detailLevel | STANDARD_IMAGE | Phù hợp cho ảnh sản phẩm |
Trường hợp sử dụng: Truy xuất tài liệu thông minh
Các nhà phân tích tài chính, nhóm pháp lý và nhà nghiên cứu cần nhanh chóng tìm thông tin cụ thể (bảng, biểu đồ, điều khoản) trong các tài liệu đa trang phức tạp mà không cần xem xét thủ công. Sơ đồ sau minh họa một giải pháp cấp cao:
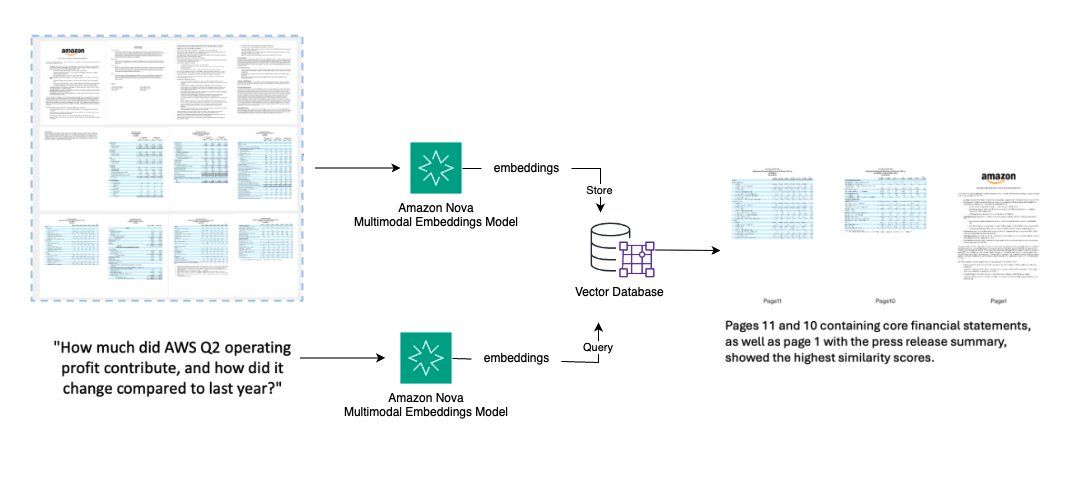
- Chuyển đổi mỗi trang PDF thành một hình ảnh độ phân giải cao
- Tạo embedding cho tất cả các trang tài liệu
- Lưu trữ embedding trong cơ sở dữ liệu vector
- Chấp nhận các truy vấn ngôn ngữ tự nhiên và chuyển đổi thành embedding
- Truy xuất K trang liên quan nhất dựa trên sự tương đồng ngữ nghĩa
- Trả về các trang có bảng tài chính, biểu đồ hoặc nội dung cụ thể
Các tham số embedding chính:
| Tham số | Giá trị | Mục đích |
|---|---|---|
embeddingPurpose | GENERIC_INDEX (lập chỉ mục) và DOCUMENT_RETRIEVAL (truy vấn) | Tối ưu hóa cho việc hiểu nội dung tài liệu |
embeddingDimension | 3072 | Độ chính xác cao nhất cho các cấu trúc tài liệu phức tạp |
detailLevel | DOCUMENT_IMAGE | Bảo toàn bảng, biểu đồ và bố cục văn bản |
Khi xử lý các tài liệu dựa trên văn bản không có yếu tố hình ảnh, bạn nên trích xuất nội dung văn bản và áp dụng chiến lược phân đoạn (chunking) và sử dụng GENERIC_INDEX để lập chỉ mục và TEXT_RETRIEVAL để truy vấn.
Trường hợp sử dụng: Tìm kiếm video clip
Các ứng dụng truyền thông yêu cầu các phương pháp hiệu quả để định vị các video clip cụ thể từ các thư viện video mở rộng bằng cách sử dụng mô tả ngôn ngữ tự nhiên. Bằng cách chuyển đổi video và truy vấn văn bản thành embedding trong một không gian ngữ nghĩa thống nhất, việc khớp độ tương đồng có thể được sử dụng để truy xuất các phân đoạn video liên quan. Sơ đồ sau minh họa một giải pháp cấp cao:
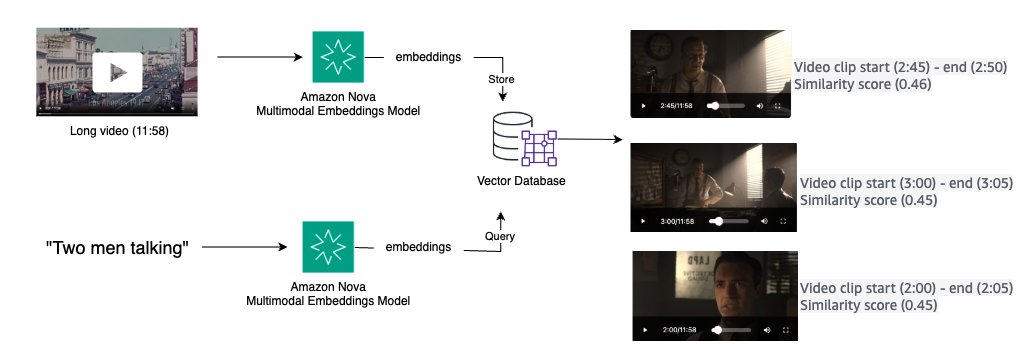
- Tạo embedding với Amazon Nova Multimodal Embeddings bằng cách sử dụng API
invoke_modelcho video ngắn hoặc APIstart_async_invokecho video dài có phân đoạn - Lưu trữ embedding trong cơ sở dữ liệu vector
- Chấp nhận các truy vấn ngôn ngữ tự nhiên và chuyển đổi thành embedding
- Truy xuất K video clip hàng đầu từ cơ sở dữ liệu vector để xem xét hoặc chỉnh sửa thêm
Các tham số embedding chính:
| Tham số | Giá trị | Mục đích |
|---|---|---|
EmbeddingPurpose | GENERIC_INDEX (lập chỉ mục) và VIDEO_RETRIEVAL (truy vấn) | Tối ưu hóa cho việc lập chỉ mục và truy xuất video |
embeddingDimension | 1024 | Cân bằng độ chính xác và chi phí |
embeddingMode | AUDIO_VIDEO_COMBINED | Hợp nhất nội dung hình ảnh và âm thanh. |
Trường hợp sử dụng: Nhận dạng dấu vân tay âm thanh
Các ứng dụng âm nhạc và hệ thống quản lý bản quyền cần xác định nội dung âm thanh trùng lặp hoặc tương tự, và khớp các phân đoạn âm thanh với các bản nhạc gốc để phát hiện bản quyền và nhận dạng nội dung. Sơ đồ sau minh họa một giải pháp cấp cao:
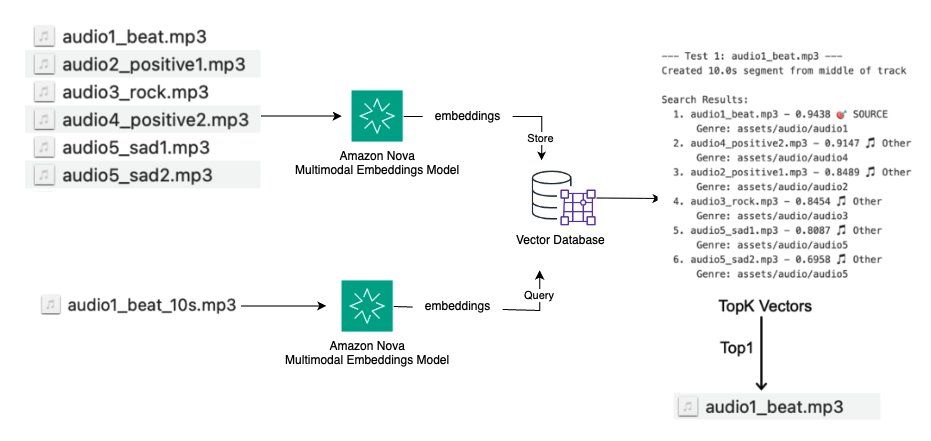
- Chuyển đổi tệp âm thanh thành embedding bằng cách sử dụng Amazon Nova Multimodal Embeddings
- Lưu trữ embedding trong cơ sở dữ liệu vector cùng với thể loại và các metadata khác
- Truy vấn bằng các phân đoạn âm thanh và tìm K bản nhạc tương tự hàng đầu
- So sánh điểm tương đồng để xác định các bản gốc phù hợp và phát hiện trùng lặp
Các tham số embedding chính:
| Tham số | Giá trị | Mục đích |
|---|---|---|
embeddingPurpose | GENERIC_INDEX (lập chỉ mục) và AUDIO_RETRIEVAL (truy vấn) | Tối ưu hóa cho việc nhận dạng dấu vân tay âm thanh và khớp nối |
embeddingDimension | 1024 | Cân bằng độ chính xác và hiệu suất cho độ tương đồng âm thanh |
Kết luận
Bạn có thể sử dụng Amazon Nova Multimodal Embeddings để làm việc với các loại dữ liệu đa dạng trong một không gian ngữ nghĩa thống nhất. Bằng cách hỗ trợ văn bản, hình ảnh, tài liệu, video và âm thanh thông qua các tham số API embedding linh hoạt được tối ưu hóa theo mục đích, bạn có thể xây dựng các hệ thống truy xuất, quy trình phân loại và ứng dụng tìm kiếm ngữ nghĩa hiệu quả hơn. Cho dù bạn đang triển khai tìm kiếm đa phương thức, thông minh tài liệu hay phân loại sản phẩm, Amazon Nova Multimodal Embeddings cung cấp nền tảng để trích xuất thông tin chi tiết từ dữ liệu phi cấu trúc ở quy mô lớn. Hãy bắt đầu khám phá Amazon Nova Multimodal Embeddings: Mô hình embedding tiên tiến cho RAG dựa trên tác nhân và tìm kiếm ngữ nghĩa và các mẫu GitHub để tích hợp Amazon Nova Multimodal Embeddings vào các ứng dụng của bạn ngay hôm nay.
Về tác giả

Yunyi Gao là Kiến trúc sư Giải pháp Chuyên gia AI Tạo sinh (Generative AI) tại Amazon Web Services (AWS), chịu trách nhiệm tư vấn về thiết kế các giải pháp và kiến trúc AI/ML và GenAI của AWS.

Sharon Li là Kiến trúc sư Giải pháp Chuyên gia AI/ML tại Amazon Web Services (AWS) có trụ sở tại Boston, Massachusetts. Với niềm đam mê tận dụng công nghệ tiên tiến, Sharon đi đầu trong việc phát triển và triển khai các giải pháp AI tạo sinh (generative AI) đổi mới trên nền tảng đám mây AWS.
