Tác giả: Muthu Pitchaimani và Jon Handler
Ngày phát hành: 05 FEB 2026
Chuyên mục: Advanced (300), Amazon Bedrock AgentCore, Amazon OpenSearch Service, Best Practices
Khách hàng ở mọi quy mô đã và đang sử dụng thành công Amazon OpenSearch Service để cung cấp năng lượng cho các quy trình làm việc quan sát (observability workflows) và có được khả năng hiển thị vào các ứng dụng và cơ sở hạ tầng của họ. Trong quá trình điều tra sự cố, các Kỹ sư Độ tin cậy Trang web (SREs) và nhân viên trung tâm vận hành dựa vào OpenSearch Service để truy vấn nhật ký (logs), kiểm tra các hình ảnh trực quan, phân tích các mẫu, tương quan các dấu vết (traces) để tìm ra nguyên nhân gốc rễ của sự cố và giảm Thời gian trung bình để khắc phục sự cố (MTTR). Khi một sự cố xảy ra kích hoạt cảnh báo, SREs thường phải chuyển đổi giữa nhiều bảng điều khiển, viết các truy vấn cụ thể, kiểm tra các triển khai gần đây và tương quan giữa nhật ký và dấu vết để ghép nối một dòng thời gian của các sự kiện. Quá trình này không chỉ phần lớn là thủ công mà còn tạo ra gánh nặng nhận thức (cognitive load) cho những nhân viên này, ngay cả khi tất cả dữ liệu đã có sẵn. Đây là lúc AI tác nhân (agentic AI) có thể giúp ích, bằng cách trở thành một trợ lý thông minh có thể hiểu cách truy vấn, diễn giải các tín hiệu đo từ xa khác nhau và điều tra sự cố một cách có hệ thống.
Trong bài đăng này, chúng tôi trình bày một tác nhân quan sát (observability agent) sử dụng OpenSearch Service và Amazon Bedrock AgentCore có thể giúp làm rõ nguyên nhân gốc rễ và thu thập thông tin chi tiết nhanh hơn, xử lý nhiều chu kỳ truy vấn-tương quan và cuối cùng giảm MTTR hơn nữa.
Tổng quan giải pháp
Sơ đồ sau đây cho thấy kiến trúc tổng thể cho tác nhân quan sát.
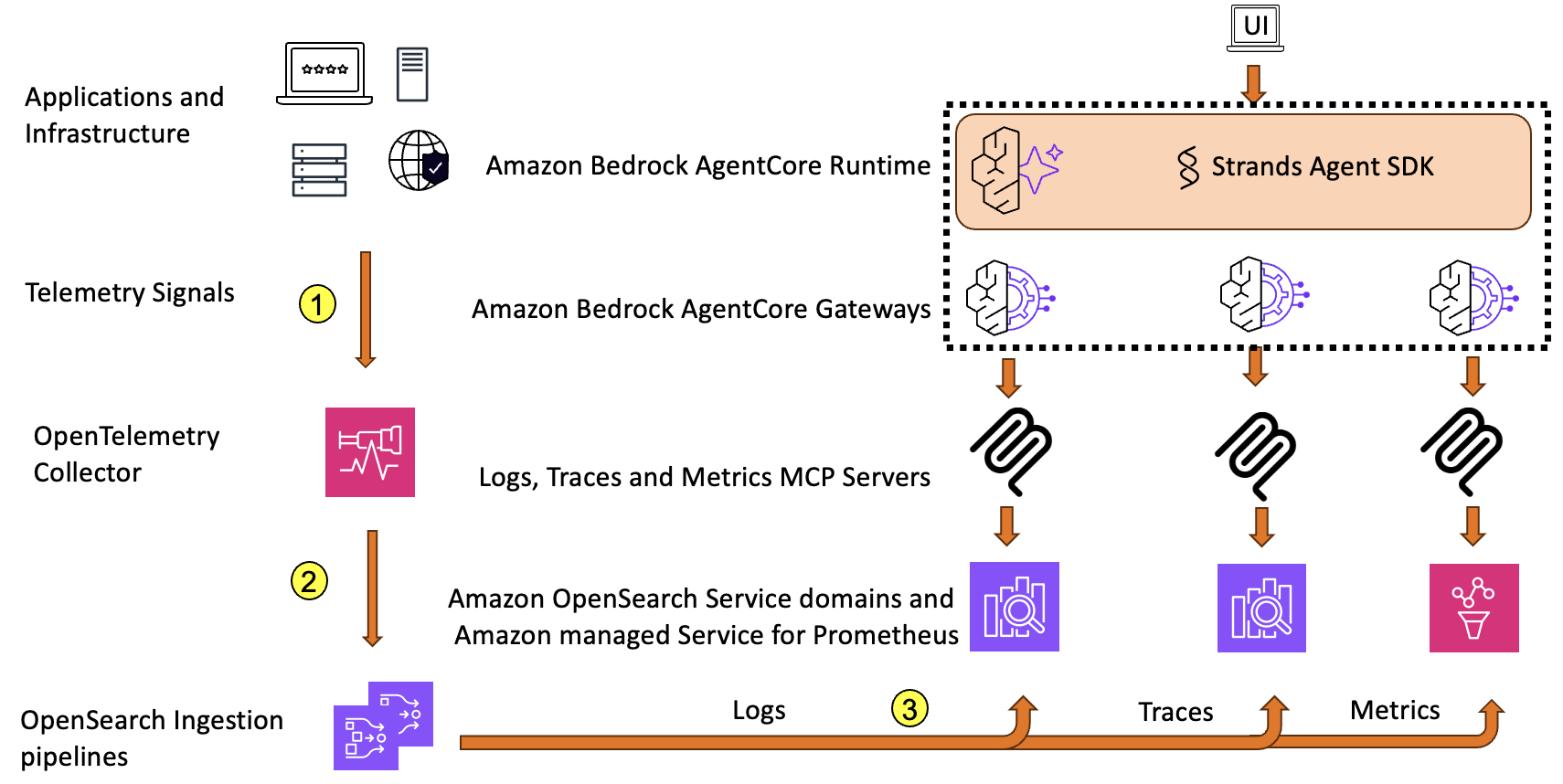
Các ứng dụng và cơ sở hạ tầng phát ra các tín hiệu đo từ xa dưới dạng nhật ký (logs), dấu vết (traces) và số liệu (metrics). Các tín hiệu này sau đó được thu thập bởi OpenTelemetry Collector (Bước 1) và xuất sang Amazon OpenSearch Ingestion bằng cách sử dụng các pipeline riêng cho từng tín hiệu: logs, traces và metrics (Bước 2). Các pipeline này cung cấp dữ liệu tín hiệu đến một miền OpenSearch Service và Amazon Managed Service for Prometheus (Bước 3).
OpenTelemetry là tiêu chuẩn cho việc đo lường (instrumentation) và cung cấp khả năng thu thập dữ liệu độc lập với nhà cung cấp trên nhiều ngôn ngữ và framework. Các doanh nghiệp ở nhiều quy mô khác nhau đang áp dụng mô hình kiến trúc này sử dụng OpenTelemetry cho nhu cầu quan sát của họ, đặc biệt là những doanh nghiệp cam kết với các công cụ mã nguồn mở. Đáng chú ý hơn, kiến trúc này được xây dựng trên nền tảng mã nguồn mở, giúp các doanh nghiệp tránh bị khóa nhà cung cấp (vendor lock-in), hưởng lợi từ cộng đồng mã nguồn mở và triển khai nó trên các môi trường tại chỗ (on-premises) và các môi trường đám mây khác nhau.
Đối với bài đăng này, chúng tôi sử dụng ứng dụng OpenTelemetry Demo để minh họa trường hợp sử dụng quan sát của chúng tôi. Đây là một ứng dụng thương mại điện tử được hỗ trợ bởi khoảng 20 microservice khác nhau và tạo ra dữ liệu đo từ xa thực tế cùng với các bộ tính năng để tạo tải và mô phỏng lỗi.
Máy chủ Model Context Protocol cho dữ liệu tín hiệu quan sát
Model Context Protocol (MCP) cung cấp một cơ chế tiêu chuẩn hóa để kết nối các tác nhân với các nguồn dữ liệu và công cụ bên ngoài. Trong giải pháp này, chúng tôi đã xây dựng ba máy chủ MCP riêng biệt, mỗi máy chủ cho một loại tín hiệu.
Máy chủ Logs MCP hiển thị các chức năng công cụ để tìm kiếm, lọc và chọn dữ liệu nhật ký được lưu trữ trong một miền OpenSearch Service cho dữ liệu nhật ký. Điều này cho phép tác nhân truy vấn nhật ký bằng cách sử dụng các tiêu chí khác nhau như khớp từ khóa đơn giản, bộ lọc tên dịch vụ, cấp độ nhật ký hoặc phạm vi thời gian. Điều này mô phỏng các truy vấn điển hình mà bạn sẽ chạy trong quá trình điều tra. Đoạn mã sau đây cho thấy một mã giả của chức năng công cụ có thể trông như thế nào:
# Logs MCP Server - Key Functionssearch_otel_logs( query: string, # Text search query for log messages service: string, # Service name to filter logs severity: string, # Log level (INFO, WARN, ERROR) startTime: string, # Start time (ISO format or relative e.g., 'now-1h') endTime: string, # End time (ISO format or relative e.g., 'now') size: number # Number of results to return)get_logs_by_trace_id( traceId: string, # Trace ID to retrieve all correlated logs size: number # Maximum number of logs to return)
Máy chủ Traces MCP hiển thị các chức năng công cụ để tìm kiếm và truy xuất thông tin về các dấu vết phân tán (distributed traces). Các chức năng này có thể giúp tra cứu dấu vết theo ID dấu vết và tìm dấu vết cho một dịch vụ cụ thể, các span thuộc về một dấu vết, thông tin bản đồ dịch vụ được xây dựng dựa trên các span, và các số liệu về tỷ lệ, lỗi và thời lượng (còn gọi là RED metrics). Điều này cho phép tác nhân theo dõi đường dẫn của một yêu cầu qua các dịch vụ và xác định chính xác nơi xảy ra lỗi hoặc nơi phát sinh độ trễ.
# Traces MCP Server - Key Functionsget_otel_spans( serviceName: string, # Service name to filter spans traceId: string, # Trace ID to filter spans spanId: string, # Span ID to retrieve a specific span operationName: string, # Operation/span name to filter startTime: string, # Start time (ISO format or relative) endTime: string, # End time (ISO format or relative) size: number # Number of results to return)get_spans_by_trace_id( traceId: string, # Trace ID to retrieve all spans for size: number # Maximum number of spans to return)get_otel_service_map( serviceName: string, # Service name to filter service map startTime: string, # Start time endTime: string, # End time size: number # Number of results to return)get_otel_rate_error_duration_metrics( startTime: string, # Start time (default: 'now-5m') endTime: string # End time (default: 'now'))
Máy chủ Metrics MCP hiển thị các chức năng công cụ để truy vấn các số liệu chuỗi thời gian (time series metrics). Tác nhân có thể sử dụng các chức năng này để kiểm tra phần trăm tỷ lệ lỗi và mức sử dụng tài nguyên, đây là những tín hiệu chính để hiểu tình trạng tổng thể của hệ thống và xác định hành vi bất thường.
# Metrics MCP Server - Key Functionsquery_instant( query: string, # PromQL query expression time: string, # Evaluation timestamp (optional) timeout: string # Evaluation timeout (optional))query_range( query: string, # PromQL query expression start: string, # Start timestamp end: string, # End timestamp step: string, # Query resolution step (e.g., '15s', '1m') timeout: string # Evaluation timeout (optional))get_timeseries( metric: string, # Metric name or PromQL expression duration: string, # Time duration to look back (e.g., '1h', '6h') step: string # Step size (optional))search_metrics( pattern: string # Search pattern (supports regex e.g., 'http.*'))explore_metric( metric: string # Metric name to explore (metadata + samples))
Ba máy chủ MCP này trải rộng trên các loại dữ liệu khác nhau được sử dụng bởi các kỹ sư điều tra, cung cấp một bộ công cụ làm việc hoàn chỉnh để một tác nhân tiến hành điều tra với khả năng tương quan tự động giữa nhật ký, dấu vết và số liệu để xác định các nguyên nhân gốc rễ có thể có của một vấn đề. Ngoài ra, một máy chủ MCP tùy chỉnh hiển thị các chức năng công cụ trên dữ liệu kinh doanh về doanh thu, bán hàng và các số liệu kinh doanh khác. Đối với ứng dụng demo OpenTelemetry, bạn có thể phát triển dữ liệu tổng hợp để hỗ trợ cung cấp ngữ cảnh cho tác động và các số liệu cấp độ kinh doanh khác. Để ngắn gọn, chúng tôi không hiển thị máy chủ đó như một phần của kiến trúc này.
Tác nhân quan sát
Tác nhân quan sát là trung tâm của giải pháp. Nó được xây dựng để giúp điều tra sự cố. Các tự động hóa truyền thống và runbook thủ công thường tuân theo các quy trình vận hành được xác định trước, nhưng với một tác nhân quan sát, bạn không cần phải xác định chúng. Tác nhân có thể phân tích, suy luận dựa trên dữ liệu có sẵn và điều chỉnh chiến lược của nó dựa trên những gì nó khám phá. Nó tương quan các phát hiện giữa nhật ký, dấu vết và số liệu để đi đến nguyên nhân gốc rễ.
Tác nhân quan sát được xây dựng bằng Strands Agent SDK, một framework mã nguồn mở giúp đơn giản hóa việc phát triển các tác nhân AI. SDK cung cấp một cách tiếp cận dựa trên mô hình với sự linh hoạt để xử lý việc điều phối và suy luận cơ bản (vòng lặp tác nhân) bằng cách gọi các công cụ được hiển thị và duy trì các tương tác mạch lạc, theo lượt. Việc triển khai này cũng tự động khám phá các công cụ, vì vậy nếu có sự thay đổi về khả năng, tác nhân có thể đưa ra quyết định dựa trên thông tin cập nhật.
Tác nhân chạy trên Amazon Bedrock AgentCore Runtime, cung cấp cơ sở hạ tầng được quản lý hoàn toàn để lưu trữ và chạy các tác nhân. Runtime hỗ trợ các framework tác nhân phổ biến, bao gồm Strands, LangGraph và CrewAI. Runtime cũng cung cấp khả năng mở rộng và tính toán mà nhiều doanh nghiệp yêu cầu để chạy các tác nhân cấp độ sản xuất.
Chúng tôi sử dụng Amazon Bedrock AgentCore Gateway để kết nối với cả ba máy chủ MCP. Khi triển khai các tác nhân ở quy mô lớn, gateway là các thành phần không thể thiếu để giảm các tác vụ quản lý như phát triển mã tùy chỉnh, cung cấp cơ sở hạ tầng, bảo mật ingress và egress toàn diện, và truy cập hợp nhất. Đây là các chức năng doanh nghiệp thiết yếu cần thiết khi đưa một khối lượng công việc vào sản xuất. Trong ứng dụng này, chúng tôi tạo các gateway kết nối cả ba máy chủ MCP làm mục tiêu bằng cách sử dụng server-sent events. Các gateway hoạt động cùng với Amazon Bedrock AgentCore Identities để cung cấp quản lý thông tin xác thực an toàn và truyền danh tính an toàn từ người dùng đến các thực thể giao tiếp. Ứng dụng mẫu sử dụng AWS Identity and Access Management (IAM) để quản lý và truyền danh tính.
Điều tra sự cố thường là một quy trình nhiều bước. Nó liên quan đến việc kiểm tra giả thuyết lặp đi lặp lại, nhiều vòng truy vấn và xây dựng ngữ cảnh theo thời gian. Chúng tôi sử dụng Amazon Bedrock AgentCore Memory cho mục đích này. Trong giải pháp này, chúng tôi sử dụng các namespace dựa trên phiên để duy trì các luồng hội thoại riêng biệt cho các cuộc điều tra khác nhau. Ví dụ, khi người dùng hỏi “What about Payment service?” trong quá trình điều tra, tác nhân sẽ truy xuất lịch sử hội thoại gần đây từ bộ nhớ để duy trì nhận thức về các phát hiện trước đó. Chúng tôi lưu trữ cả câu hỏi của người dùng và phản hồi của tác nhân với dấu thời gian để giúp tác nhân tái tạo cuộc hội thoại theo thứ tự thời gian và suy luận về các phát hiện đã hoàn thành.
Chúng tôi đã cấu hình tác nhân quan sát để sử dụng Claude Sonnet v4.5 của Anthropic trong Amazon Bedrock để suy luận. Mô hình diễn giải các câu hỏi, quyết định công cụ MCP nào sẽ gọi, phân tích kết quả và đưa ra tập hợp các câu hỏi hoặc kết luận. Chúng tôi sử dụng một system prompt để hướng dẫn mô hình suy nghĩ như một SRE có kinh nghiệm hoặc một kỹ sư trung tâm vận hành: “Bắt đầu với kiểm tra cấp cao, thu hẹp các thành phần bị ảnh hưởng, tương quan giữa các loại tín hiệu đo từ xa và đưa ra kết luận có bằng chứng. Bạn yêu cầu mô hình cũng đề xuất các bước tiếp theo hợp lý như thực hiện drill down để điều tra các phụ thuộc giữa các dịch vụ.” Điều này làm cho tác nhân trở nên linh hoạt để phân tích và suy luận về các loại điều tra sự cố phổ biến.
Tác nhân quan sát trong thực tế
Chúng tôi đã xây dựng các bảng điều khiển số liệu RED (tỷ lệ, lỗi, thời lượng) theo thời gian thực cho toàn bộ ứng dụng, như được hiển thị trong hình sau.
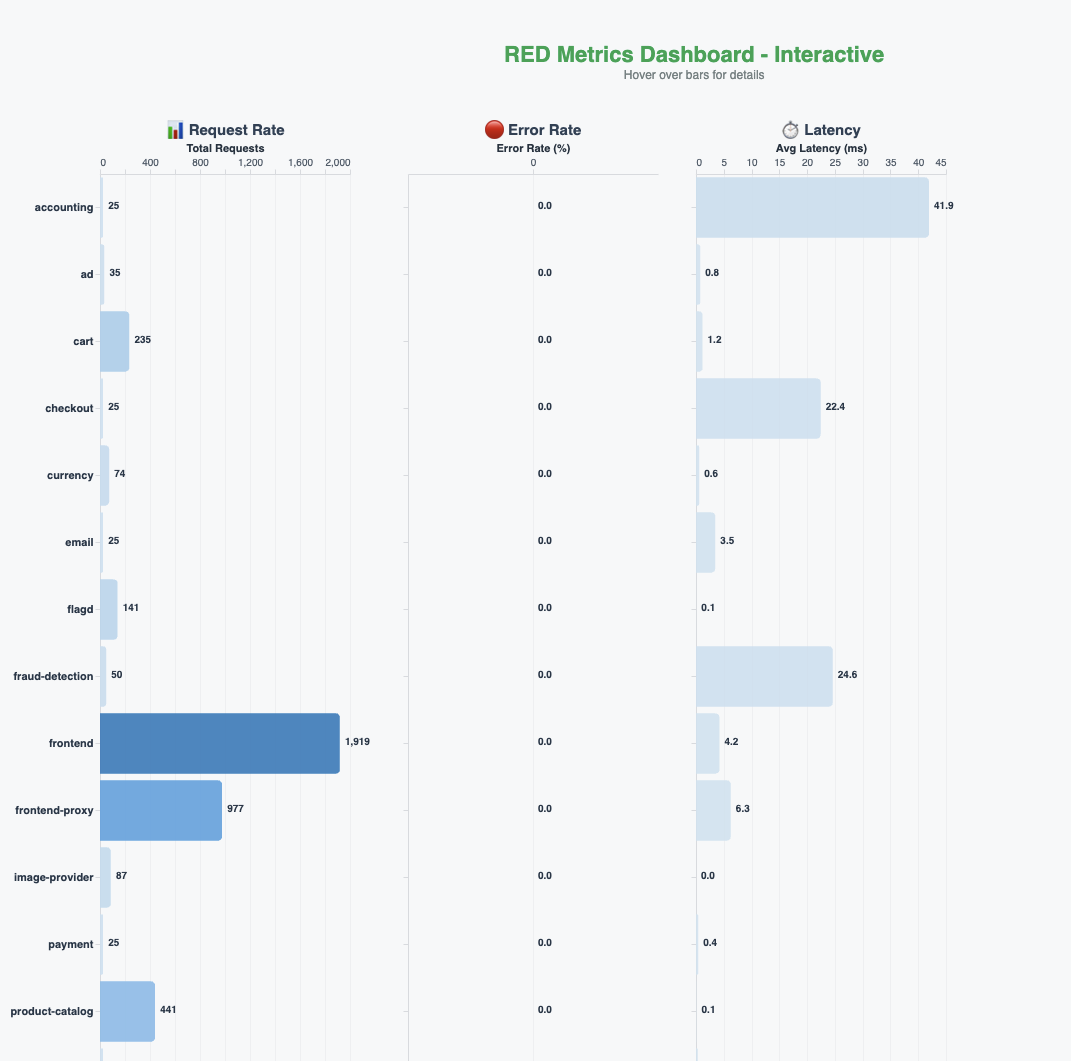
Để thiết lập một đường cơ sở, chúng tôi đã hỏi tác nhân câu hỏi sau: “Are there any errors in my application in the last five minutes?” (Có lỗi nào trong ứng dụng của tôi trong năm phút qua không?). Tác nhân truy vấn các dấu vết và số liệu, phân tích kết quả và phản hồi rằng không có lỗi nào trong hệ thống. Nó lưu ý rằng tất cả các dịch vụ đều hoạt động, các dấu vết khỏe mạnh và hệ thống đang xử lý các yêu cầu bình thường. Tác nhân cũng chủ động đề xuất các bước tiếp theo có thể hữu ích cho việc điều tra thêm.
Giới thiệu lỗi
Ứng dụng demo OpenTelemetry có một feature flag mà chúng ta có thể sử dụng để đưa vào các lỗi cố ý trong hệ thống. Nó cũng bao gồm việc tạo tải để những lỗi này có thể nổi bật. Chúng tôi sử dụng các tính năng này để đưa vào một vài lỗi với dịch vụ thanh toán. Các bảng điều khiển số liệu RED theo thời gian thực trong hình trước phản ánh tác động và cho thấy tỷ lệ lỗi đang tăng lên.
Điều tra và phân tích nguyên nhân gốc rễ
Bây giờ chúng ta đang tạo ra lỗi, chúng ta lại tương tác với tác nhân. Đây thường là khởi đầu của phiên điều tra. Ngoài ra, chúng ta có các quy trình làm việc như kích hoạt báo động hoặc gửi thông báo sẽ kích hoạt việc bắt đầu một cuộc điều tra.
Chúng tôi đặt câu hỏi “Users are complaining that it is taking a long time to buy items. Can you check to see what is going on?” (Người dùng đang phàn nàn rằng mất nhiều thời gian để mua hàng. Bạn có thể kiểm tra xem chuyện gì đang xảy ra không?)
Tác nhân truy xuất lịch sử hội thoại từ bộ nhớ (nếu có), gọi các công cụ để truy vấn các số liệu RED trên các dịch vụ và phân tích kết quả. Nó xác định một vấn đề hiệu suất luồng mua hàng quan trọng: dịch vụ thanh toán đang trong tình trạng khủng hoảng kết nối và hoàn toàn không khả dụng, với độ trễ cực cao được quan sát thấy trong phát hiện gian lận, dịch vụ quảng cáo và dịch vụ đề xuất. Tác nhân cung cấp các khuyến nghị hành động ngay lập tức—khôi phục kết nối dịch vụ thanh toán là ưu tiên hàng đầu—và đề xuất các bước tiếp theo, bao gồm điều tra nhật ký dịch vụ thanh toán.
Theo gợi ý của tác nhân, chúng tôi yêu cầu nó điều tra nhật ký: “Investigate payment service logs to understand the connectivity issue.” (Điều tra nhật ký dịch vụ thanh toán để hiểu vấn đề kết nối.)
Tác nhân tìm kiếm nhật ký cho các dịch vụ thanh toán và thanh toán, tương quan chúng với dữ liệu dấu vết và phân tích các phụ thuộc dịch vụ từ bản đồ dịch vụ. Nó xác nhận rằng mặc dù dịch vụ giỏ hàng, dịch vụ danh mục sản phẩm và dịch vụ tiền tệ đều khỏe mạnh, dịch vụ thanh toán hoàn toàn không thể truy cập được, thành công xác định nguyên nhân gốc rễ của lỗi mà chúng tôi đã cố ý đưa vào.
Vượt ra ngoài nguyên nhân gốc rễ: Phân tích tác động kinh doanh
Như đã đề cập trước đó, chúng tôi có dữ liệu doanh số và doanh thu kinh doanh tổng hợp trong một máy chủ MCP riêng biệt, vì vậy khi người dùng hỏi tác nhân “Analyze the business impact of the checkout and payment service failures,” (Phân tích tác động kinh doanh của các lỗi dịch vụ thanh toán và thanh toán), tác nhân sử dụng dữ liệu kinh doanh này, kiểm tra dữ liệu giao dịch từ các dấu vết, tính toán tác động doanh thu ước tính và đánh giá tỷ lệ khách hàng bỏ ngang do lỗi thanh toán. Điều này cho thấy cách tác nhân có thể vượt ra ngoài việc xác định nguyên nhân gốc rễ và cung cấp trợ giúp với các hoạt động vận hành như tạo một runbook để giải quyết vấn đề trong tương lai, đây có thể là bước đầu tiên để cung cấp khắc phục tự động mà không cần sự tham gia của SREs.
Lợi ích và kết quả
Mặc dù kịch bản lỗi trong bài đăng này được đơn giản hóa để minh họa, nó làm nổi bật một số lợi ích chính góp phần trực tiếp vào việc giảm MTTR.
Chu kỳ điều tra được tăng tốc
Các quy trình làm việc truyền thống để khắc phục sự cố liên quan đến nhiều lần lặp lại giả thuyết, xác minh, truy vấn và phân tích dữ liệu ở mỗi bước, đòi hỏi chuyển đổi ngữ cảnh và tiêu tốn hàng giờ công sức. Tác nhân quan sát giảm đáng kể những điều này xuống còn vài phút bằng cách suy luận, tương quan và hành động tự động, từ đó giảm MTTR.
Xử lý các quy trình làm việc phức tạp
Các kịch bản sản xuất trong thế giới thực thường liên quan đến các lỗi dây chuyền (cascading failures) và nhiều lỗi hệ thống. Khả năng của tác nhân quan sát có thể mở rộng đến các kịch bản này bằng cách sử dụng dữ liệu lịch sử và nhận dạng mẫu. Ví dụ, nó có thể phân biệt các vấn đề liên quan với các dương tính giả (false positives) bằng cách sử dụng tương quan dựa trên thời gian hoặc danh tính, biểu đồ phụ thuộc và các kỹ thuật khác, giúp SREs tránh lãng phí nỗ lực điều tra vào các bất thường không liên quan.
Thay vì cung cấp một câu trả lời duy nhất, tác nhân có thể cung cấp phân phối xác suất trên các nguyên nhân gốc rễ tiềm năng, giúp SREs ưu tiên các phương pháp khắc phục; ví dụ:
- Vấn đề kết nối mạng dịch vụ thanh toán: 75%
- Hết thời gian chờ cổng thanh toán hạ nguồn: 15%
- Cạn kiệt nhóm kết nối cơ sở dữ liệu: 8%
- Khác/Không xác định: 2%
Tác nhân có thể so sánh các triệu chứng hiện tại với các sự cố trong quá khứ, xác định xem các mẫu tương tự đã xảy ra trong quá khứ hay chưa, từ đó phát triển từ một công cụ truy vấn phản ứng thành một trợ lý chẩn đoán chủ động.
Kết luận
Điều tra sự cố vẫn phần lớn là thủ công. SREs phải xử lý nhiều bảng điều khiển, tạo truy vấn và tương quan các tín hiệu dưới áp lực, ngay cả khi tất cả dữ liệu đã có sẵn. Trong bài đăng này, chúng tôi đã chỉ ra cách một tác nhân quan sát được xây dựng bằng Amazon Bedrock AgentCore và OpenSearch Service có thể giảm bớt gánh nặng nhận thức này bằng cách tự động truy vấn nhật ký, dấu vết và số liệu; tương quan các phát hiện; và hướng dẫn SREs đến nguyên nhân gốc rễ nhanh hơn. Mặc dù mô hình này đại diện cho một cách tiếp cận, sự linh hoạt của Amazon Bedrock AgentCore kết hợp với khả năng tìm kiếm và phân tích của OpenSearch Service cho phép các tác nhân được thiết kế và triển khai theo nhiều cách khác nhau—ở các giai đoạn khác nhau của vòng đời sự cố, với các mức độ tự chủ khác nhau hoặc tập trung vào các tác vụ điều tra cụ thể—để phù hợp với nhu cầu vận hành độc đáo của tổ chức bạn. AI tác nhân không thay thế khoản đầu tư quan sát hiện có, mà khuếch đại chúng bằng cách cung cấp một cách hiệu quả để sử dụng dữ liệu của bạn trong quá trình điều tra sự cố.
Về tác giả

Muthu Pitchaimani
Muthu là Chuyên gia Tìm kiếm của Amazon OpenSearch Service. Anh ấy xây dựng các ứng dụng và giải pháp tìm kiếm quy mô lớn. Muthu quan tâm đến các chủ đề mạng và bảo mật, và hiện đang làm việc tại Austin, Texas.

Jon Handler
Jon là Giám đốc Kiến trúc Giải pháp cho Dịch vụ Tìm kiếm tại AWS. Làm việc tại Palo Alto, CA. Jon hợp tác chặt chẽ với OpenSearch và Amazon OpenSearch Service, cung cấp trợ giúp và hướng dẫn cho nhiều khách hàng có khối lượng công việc AI tạo sinh, tìm kiếm và phân tích nhật ký cho OpenSearch.
