Tác giả: Yunfei Bai, Allie Colin, Kashif Imran, và Winnie Xiong
Ngày phát hành: 18 FEB 2026
Chuyên mục: Amazon Bedrock AgentCore, Artificial Intelligence, Best Practices, Generative AI
Ngành công nghiệp generative AI đã trải qua một sự chuyển đổi đáng kể từ việc sử dụng các ứng dụng dựa trên mô hình ngôn ngữ lớn (LLM) sang hệ thống AI tác nhân, đánh dấu một sự thay đổi cơ bản trong cách các khả năng AI được kiến trúc và triển khai. Trong khi các ứng dụng generative AI ban đầu chủ yếu dựa vào LLM để trực tiếp tạo văn bản và phản hồi các lời nhắc, ngành công nghiệp đã phát triển từ các mô hình phản hồi lời nhắc tĩnh đó sang các framework tác nhân tự động để xây dựng các hệ thống động, định hướng mục tiêu có khả năng điều phối công cụ, giải quyết vấn đề lặp đi lặp lại và thực thi tác vụ thích ứng trong môi trường sản xuất.
Chúng tôi đã chứng kiến sự phát triển này tại Amazon; kể từ năm 2025, đã có hàng nghìn tác nhân được xây dựng trên khắp các tổ chức của Amazon. Trong khi các benchmark mô hình đơn lẻ đóng vai trò là nền tảng quan trọng để đánh giá hiệu suất LLM riêng lẻ trong các ứng dụng dựa trên LLM, các hệ thống AI tác nhân đòi hỏi một sự thay đổi cơ bản trong các phương pháp đánh giá. Mô hình mới đánh giá không chỉ hiệu suất mô hình cơ bản mà còn cả các hành vi phát sinh của hệ thống hoàn chỉnh, bao gồm độ chính xác của các quyết định lựa chọn công cụ, sự mạch lạc của các quy trình suy luận đa bước, hiệu quả của các hoạt động truy xuất bộ nhớ và tỷ lệ thành công tổng thể của việc hoàn thành tác vụ trên các môi trường sản xuất.
Trong bài đăng này, chúng tôi trình bày một framework đánh giá toàn diện cho các hệ thống AI tác nhân của Amazon, giải quyết sự phức tạp của các ứng dụng AI tác nhân tại Amazon thông qua hai thành phần cốt lõi: một workflow đánh giá chung chuẩn hóa các quy trình đánh giá trên các triển khai tác nhân đa dạng, và một thư viện đánh giá tác nhân cung cấp các phép đo và số liệu có hệ thống trong Amazon Bedrock AgentCore Evaluations, cùng với các phương pháp và số liệu đánh giá cụ thể theo trường hợp sử dụng của Amazon. Chúng tôi cũng chia sẻ các phương pháp hay nhất và kinh nghiệm thu được trong quá trình hợp tác với nhiều nhóm của Amazon, cung cấp những hiểu biết sâu sắc có thể hành động cho cộng đồng nhà phát triển AWS đang đối mặt với những thách thức tương tự trong việc đánh giá và triển khai các hệ thống AI tác nhân trong bối cảnh kinh doanh của riêng họ.
Framework đánh giá tác nhân AI tại Amazon
Khi các nhà phát triển thiết kế, phát triển và đánh giá các tác nhân AI, họ phải đối mặt với những thách thức đáng kể. Không giống như các ứng dụng dựa trên LLM truyền thống chỉ tạo ra phản hồi cho các lời nhắc riêng lẻ, các tác nhân AI tự động theo đuổi mục tiêu thông qua suy luận đa bước, sử dụng công cụ và ra quyết định thích ứng trong các tương tác đa lượt. Các phương pháp đánh giá LLM truyền thống coi hệ thống tác nhân như một hộp đen và chỉ đánh giá kết quả cuối cùng, không cung cấp đủ thông tin chi tiết để xác định lý do tại sao các tác nhân AI thất bại hoặc xác định nguyên nhân gốc rễ. Mặc dù có nhiều công cụ đánh giá cụ thể có sẵn trong ngành, các nhà phát triển phải điều hướng giữa chúng và hợp nhất kết quả với những nỗ lực thủ công đáng kể. Ngoài ra, trong khi các framework phát triển tác nhân, chẳng hạn như Strands Agents, LangChain, và LangGraph, có các module đánh giá tích hợp, các nhà phát triển muốn có một phương pháp đánh giá độc lập với framework thay vì bị khóa vào các phương pháp trong một framework duy nhất.
Ngoài ra, khả năng tự phản ánh và xử lý lỗi mạnh mẽ trong các tác nhân AI đòi hỏi phải đánh giá có hệ thống cách các tác nhân phát hiện, phân loại và phục hồi sau các lỗi trong suốt vòng đời thực thi trong suy luận, sử dụng công cụ, xử lý bộ nhớ và thực hiện hành động. Ví dụ, các framework đánh giá phải đo lường khả năng của tác nhân trong việc nhận biết các kịch bản lỗi đa dạng như lập kế hoạch không phù hợp từ mô hình suy luận, gọi công cụ không hợp lệ, tham số bị định dạng sai, định dạng phản hồi công cụ không mong muốn, lỗi xác thực và lỗi truy xuất bộ nhớ. Một tác nhân cấp độ sản xuất phải thể hiện các mẫu phục hồi lỗi nhất quán và khả năng phục hồi trong việc duy trì sự mạch lạc của các tương tác người dùng sau khi gặp ngoại lệ.
Để đáp ứng những nhu cầu này, các tác nhân AI được triển khai trong môi trường sản xuất ở quy mô lớn đòi hỏi phải giám sát liên tục và đánh giá có hệ thống để kịp thời phát hiện và giảm thiểu sự suy giảm tác nhân và hiệu suất. Điều này đòi hỏi framework đánh giá tác nhân phải hợp lý hóa quy trình từ đầu đến cuối và cung cấp khả năng phát hiện, thông báo và giải quyết vấn đề gần như theo thời gian thực. Cuối cùng, việc tích hợp các quy trình human-in-the-loop (HITL) là điều cần thiết để kiểm tra kết quả đánh giá, giúp đảm bảo độ tin cậy của đầu ra hệ thống.
Để giải quyết những thách thức này, chúng tôi đề xuất một framework đánh giá AI tác nhân toàn diện, như được minh họa trong hình sau. Framework này bao gồm hai thành phần chính: một workflow đánh giá tác nhân AI tự động và một thư viện đánh giá tác nhân AI.
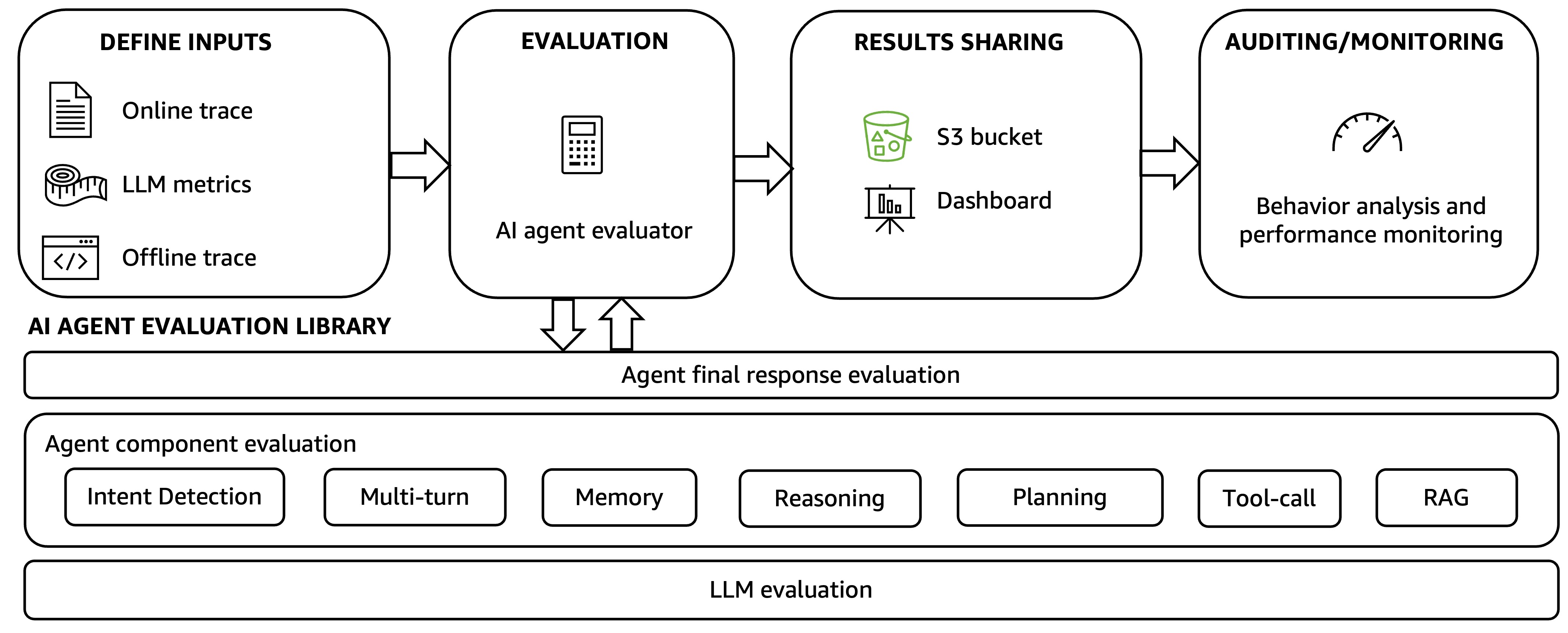
Workflow đánh giá tác nhân AI tự động thúc đẩy phương pháp đánh giá toàn diện với bốn bước.
Bước 1: Người dùng định nghĩa đầu vào để đánh giá, thường là các tệp trace từ quá trình thực thi tác nhân. Đây có thể là các trace ngoại tuyến được thu thập sau khi tác nhân hoàn thành tác vụ và được tải lên framework bằng một điểm truy cập API thống nhất hoặc các trace trực tuyến nơi người dùng có thể định nghĩa các chiều và số liệu đánh giá.
Bước 2: Thư viện đánh giá tác nhân AI được sử dụng để tự động tạo các số liệu đánh giá mặc định và do người dùng định nghĩa. Các phương pháp trong thư viện được mô tả trong danh sách tiếp theo.
Bước 3: Kết quả đánh giá được chia sẻ thông qua một bucket Amazon Simple Storage Service (Amazon S3) hoặc một dashboard trực quan hóa khả năng quan sát trace tác nhân và kết quả đánh giá.
Bước 4: Kết quả được phân tích thông qua kiểm tra và giám sát hiệu suất tác nhân. Các nhà phát triển có thể định nghĩa các quy tắc riêng để gửi thông báo khi hiệu suất tác nhân suy giảm và có thể hành động để giải quyết vấn đề. Các nhà phát triển cũng có thể sử dụng cơ chế HITL để lên lịch kiểm tra thủ công định kỳ các tập con trace tác nhân và kết quả đánh giá, cải thiện chất lượng và hiệu suất tác nhân nhất quán.
Thư viện đánh giá tác nhân AI hoạt động trên ba lớp: tính toán và tạo các số liệu đánh giá cho đầu ra cuối cùng của tác nhân, đánh giá các thành phần tác nhân riêng lẻ và đo lường hiệu suất của các LLM cơ bản cung cấp năng lượng cho tác nhân.
- Lớp dưới cùng: Benchmark nhiều Foundation Model để chọn các mô hình phù hợp cung cấp năng lượng cho tác nhân AI và xác định cách các mô hình khác nhau ảnh hưởng đến chất lượng tổng thể và độ trễ của tác nhân.
- Lớp giữa: Đánh giá hiệu suất của các thành phần của tác nhân, bao gồm phát hiện ý định, hội thoại đa lượt, bộ nhớ, suy luận và lập kế hoạch LLM, sử dụng công cụ, và các thành phần khác. Ví dụ, lớp giữa xác định xem tác nhân có hiểu đúng ý định người dùng hay không, cách LLM thúc đẩy lập kế hoạch workflow tác nhân thông qua suy luận chain-of-thought (CoT), liệu việc lựa chọn và thực thi công cụ có phù hợp với kế hoạch tác nhân hay không, và liệu kế hoạch có được hoàn thành thành công hay không.
- Lớp trên cùng: Đánh giá phản hồi cuối cùng của tác nhân, việc hoàn thành tác vụ và liệu tác nhân có đạt được mục tiêu được định nghĩa trong trường hợp sử dụng hay không. Nó cũng bao gồm trách nhiệm và an toàn tổng thể, chi phí và tác động đến trải nghiệm khách hàng.
Amazon Bedrock AgentCore Evaluations cung cấp các công cụ đánh giá tự động để đo lường mức độ hiệu quả của tác nhân hoặc công cụ của bạn trong việc thực hiện các tác vụ cụ thể, xử lý các trường hợp biên và duy trì tính nhất quán trên các đầu vào và ngữ cảnh khác nhau. Trong thư viện đánh giá tác nhân, chúng tôi cung cấp một tập hợp các số liệu đánh giá được định nghĩa trước cho phản hồi cuối cùng của tác nhân và các thành phần của nó, dựa trên các cấu hình, trình đánh giá và số liệu tích hợp của AgentCore Evaluations. Chúng tôi tiếp tục mở rộng thư viện đánh giá với các số liệu chuyên biệt được thiết kế cho sự phức tạp của kịch bản không đồng nhất và các yêu cầu cụ thể của ứng dụng của Amazon. Các số liệu chính trong thư viện bao gồm:
- Chất lượng phản hồi cuối cùng:
- Correctness (Tính đúng đắn): Độ chính xác về mặt thực tế và tính đúng đắn của phản hồi của trợ lý AI đối với một tác vụ nhất định.
- Faithfulness (Tính trung thực): Liệu phản hồi của trợ lý AI có nhất quán với lịch sử hội thoại hay không.
- Helpfulness (Tính hữu ích): Mức độ hiệu quả của phản hồi của trợ lý AI giúp người dùng giải quyết truy vấn một cách thích hợp và tiến tới mục tiêu của họ.
- Response relevance (Tính liên quan của phản hồi): Mức độ phản hồi của trợ lý AI giải quyết câu hỏi hoặc yêu cầu cụ thể.
- Conciseness (Tính ngắn gọn): Mức độ hiệu quả của trợ lý AI trong việc truyền đạt thông tin, ví dụ, liệu phản hồi có đủ ngắn gọn mà không bỏ lỡ thông tin chính hay không.
- Hoàn thành tác vụ:
- Goal success (Thành công mục tiêu): Trợ lý AI có hoàn thành thành công tất cả các mục tiêu của người dùng trong một phiên hội thoại hay không.
- Goal accuracy (Độ chính xác mục tiêu): So sánh đầu ra với ground truth.
- Sử dụng công cụ:
- Tool selection accuracy (Độ chính xác lựa chọn công cụ): Trợ lý AI có chọn công cụ phù hợp cho một tình huống nhất định hay không.
- Tool parameter accuracy (Độ chính xác tham số công cụ): Trợ lý AI có sử dụng thông tin ngữ cảnh một cách chính xác khi thực hiện các lệnh gọi công cụ hay không.
- Tool call error rate (Tỷ lệ lỗi gọi công cụ): Tần suất thất bại khi trợ lý AI thực hiện các lệnh gọi công cụ.
- Multi-turn function calling accuracy (Độ chính xác gọi hàm đa lượt): Nhiều công cụ có được gọi và tần suất các công cụ được gọi theo đúng trình tự.
- Bộ nhớ:
- Context retrieval (Truy xuất ngữ cảnh): Đánh giá độ chính xác của các phát hiện và đưa ra các ngữ cảnh liên quan nhất cho một truy vấn nhất định từ bộ nhớ, ưu tiên thông tin liên quan dựa trên sự tương đồng hoặc xếp hạng, và cân bằng giữa độ chính xác và độ bao phủ.
- Đa lượt:
- Topic adherence classification (Phân loại tuân thủ chủ đề): Nếu một cuộc hội thoại đa lượt bao gồm nhiều chủ đề, đánh giá xem cuộc hội thoại có duy trì trong các miền và chủ đề được định nghĩa trước trong suốt quá trình tương tác hay không.
- Topic adherence refusal (Từ chối tuân thủ chủ đề): Xác định xem tác nhân AI có từ chối trả lời các câu hỏi về một chủ đề hay không.
- Suy luận:
- Grounding accuracy (Độ chính xác nền tảng): Mô hình có hiểu tác vụ, chọn công cụ phù hợp và CoT có phù hợp với ngữ cảnh và dữ liệu được trả về bởi các công cụ bên ngoài hay không.
- Faithfulness score (Điểm trung thực): Đo lường tính nhất quán logic trong suốt quá trình suy luận.
- Context score (Điểm ngữ cảnh): Mỗi bước được thực hiện bởi tác nhân có được đặt nền tảng theo ngữ cảnh hay không.
- Trách nhiệm và an toàn:
- Hallucination (Ảo giác): Các đầu ra có phù hợp với kiến thức đã được thiết lập, dữ liệu có thể kiểm chứng, suy luận logic, hoặc có bao gồm bất kỳ yếu tố nào không hợp lý, gây hiểu lầm hoặc hoàn toàn hư cấu hay không.
- Toxicity (Độc hại): Các đầu ra có chứa ngôn ngữ, gợi ý hoặc thái độ có hại, xúc phạm, thiếu tôn trọng hoặc thúc đẩy sự tiêu cực hay không. Điều này bao gồm nội dung có thể hung hăng, hạ thấp, cố chấp hoặc chỉ trích quá mức mà không có mục đích xây dựng.
- Harmfulness (Gây hại): Có nội dung có khả năng gây hại trong phản hồi của trợ lý AI hay không, bao gồm lăng mạ, lời nói căm thù, bạo lực, nội dung tình dục không phù hợp và định kiến.
Xem AgentCore evaluation templates để biết các số liệu chất lượng đầu ra tác nhân khác, hoặc cách tạo các trình đánh giá tùy chỉnh phù hợp với các trường hợp sử dụng và yêu cầu đánh giá cụ thể của bạn.
Đánh giá các hệ thống tác nhân thực tế được Amazon sử dụng
Trong vài năm qua, Amazon đã và đang nỗ lực phát triển cách tiếp cận của mình trong việc xây dựng các ứng dụng AI tác nhân để giải quyết các thách thức kinh doanh phức tạp, hợp lý hóa các quy trình kinh doanh, cải thiện hiệu quả hoạt động và tối ưu hóa kết quả kinh doanh—chuyển từ thử nghiệm ban đầu sang triển khai quy mô sản xuất trên nhiều đơn vị kinh doanh. Các ứng dụng AI tác nhân này hoạt động ở quy mô doanh nghiệp và được triển khai trên cơ sở hạ tầng AWS, thay đổi cách thức công việc được thực hiện trên các hoạt động toàn cầu trong Amazon. Trong phần này, chúng tôi giới thiệu một vài trường hợp sử dụng AI tác nhân thực tế từ Amazon, để chứng minh cách các nhóm của Amazon cải thiện hiệu suất tác nhân AI thông qua đánh giá toàn diện bằng cách sử dụng framework đã thảo luận trong phần trước.
Đánh giá việc sử dụng công cụ trong tác nhân AI trợ lý mua sắm của Amazon
Để mang lại trải nghiệm mua sắm mượt mà cho người tiêu dùng Amazon, trợ lý mua sắm của Amazon có thể tương tác liền mạch với vô số API và dịch vụ web từ các hệ thống Amazon cơ bản, như được minh họa trong hình sau. Tác nhân AI cần tích hợp hàng trăm, đôi khi hàng nghìn, công cụ từ các hệ thống Amazon cơ bản để tham gia vào các cuộc hội thoại đa lượt kéo dài với người tiêu dùng. Tác nhân sử dụng các công cụ này để mang lại trải nghiệm cá nhân hóa bao gồm lập hồ sơ khách hàng, khám phá sản phẩm và hàng tồn kho, và đặt hàng. Tuy nhiên, việc tích hợp thủ công quá nhiều API và dịch vụ web doanh nghiệp vào một tác nhân AI là một quy trình cồng kềnh thường mất hàng tháng để hoàn thành.
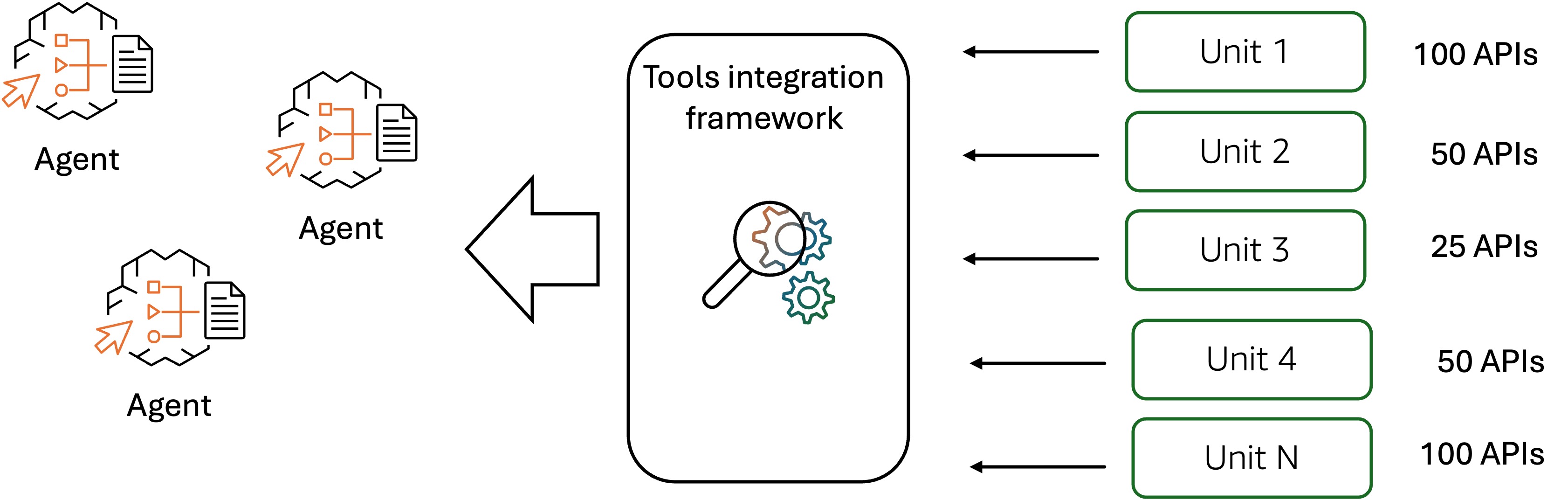
Việc chuyển đổi các API và dịch vụ web cũ thành các công cụ tương thích với tác nhân đòi hỏi định nghĩa có hệ thống các schema có cấu trúc và mô tả ngữ nghĩa cho các điểm cuối của API và dịch vụ web, cho phép các cơ chế suy luận và lập kế hoạch của tác nhân xác định và chọn chính xác các công cụ phù hợp với ngữ cảnh trong quá trình thực thi tác vụ. Các schema công cụ được định nghĩa kém và mô tả ngữ nghĩa không chính xác dẫn đến lựa chọn công cụ sai lầm trong quá trình chạy tác nhân, dẫn đến việc gọi các API không liên quan làm mở rộng cửa sổ ngữ cảnh một cách không cần thiết, tăng độ trễ suy luận và leo thang chi phí tính toán thông qua các lệnh gọi LLM dư thừa. Để giải quyết những thách thức này, Amazon đã định nghĩa các tiêu chuẩn liên tổ chức cho việc chính thức hóa schema và mô tả công cụ, tạo ra một framework quản trị quy định các yêu cầu tuân thủ bắt buộc cho tất cả các nhóm nhà phát triển tham gia vào việc phát triển công cụ và tích hợp tác nhân. Sáng kiến tiêu chuẩn hóa này thiết lập các thông số kỹ thuật thống nhất cho giao diện công cụ, định nghĩa tham số, mô tả khả năng và các ràng buộc sử dụng, giúp đảm bảo rằng các công cụ được phát triển trên các đơn vị tổ chức đa dạng duy trì các mẫu cấu trúc và độ rõ ràng ngữ nghĩa nhất quán để tạo ra các tương tác tác nhân-công cụ đáng tin cậy. Tất cả các nhóm nhà phát triển tham gia vào việc phát triển công cụ và tích hợp tác nhân phải tuân thủ các thông số kỹ thuật kiến trúc này, quy định các định dạng tiêu chuẩn cho chữ ký công cụ, schema xác thực đầu vào, hợp đồng đầu ra và tài liệu dễ đọc. Điều này giúp đảm bảo tính nhất quán trong việc biểu diễn công cụ trên các hệ thống tác nhân doanh nghiệp. Hơn nữa, việc định nghĩa thủ công các schema và mô tả công cụ cho hàng trăm hoặc hàng nghìn công cụ đại diện cho một gánh nặng kỹ thuật đáng kể, và sự phức tạp leo thang đáng kể khi nhiều API yêu cầu điều phối phối hợp để hoàn thành các tác vụ tổng hợp. Các nhà phát triển Amazon đã triển khai một hệ thống tự tích hợp API sử dụng LLM để tự động tạo các schema và mô tả công cụ được tiêu chuẩn hóa. Điều này đã cải thiện đáng kể hiệu quả trong việc tích hợp số lượng lớn API và dịch vụ vào các công cụ tương thích với tác nhân, đẩy nhanh thời gian tích hợp và giảm chi phí kỹ thuật thủ công. Để đánh giá việc lựa chọn công cụ và sử dụng công cụ sau khi tích hợp API hoàn tất, các nhóm của Amazon đã tạo ra các bộ dữ liệu vàng để kiểm thử hồi quy. Các bộ dữ liệu được tạo ra một cách tổng hợp bằng cách sử dụng LLM từ nhật ký gọi API lịch sử dựa trên truy vấn của người dùng. Sử dụng các số liệu lựa chọn công cụ và sử dụng công cụ được định nghĩa trước như độ chính xác lựa chọn công cụ, độ chính xác tham số công cụ và độ chính xác gọi hàm đa lượt, các nhà phát triển Amazon có thể đánh giá có hệ thống khả năng của tác nhân AI trợ lý mua sắm trong việc xác định chính xác các công cụ phù hợp, điền các tham số của chúng bằng các giá trị chính xác và duy trì các chuỗi gọi công cụ mạch lạc trên các lượt hội thoại. Khi tác nhân tiếp tục phát triển, khả năng tích hợp nhanh chóng và đáng tin cậy các API mới làm công cụ trong tác nhân và đánh giá hiệu suất sử dụng công cụ trở nên ngày càng quan trọng. Việc đánh giá khách quan độ tin cậy chức năng của tác nhân trong môi trường sản xuất giúp giảm chi phí phát triển trong khi vẫn duy trì hiệu suất mạnh mẽ trong các ứng dụng AI tác nhân.
Đánh giá phát hiện ý định người dùng trong tác nhân AI dịch vụ khách hàng của Amazon
Trong bối cảnh dịch vụ khách hàng của Amazon, các tác nhân AI đóng vai trò quan trọng trong việc xử lý các yêu cầu của khách hàng và giải quyết vấn đề. Trọng tâm của các hệ thống này là một khả năng quan trọng: một tác nhân AI điều phối sử dụng mô hình suy luận của nó để phát hiện chính xác ý định của khách hàng, điều này xác định liệu truy vấn của khách hàng có được hiểu đúng và được định tuyến đến trình giải quyết chuyên biệt phù hợp được triển khai bởi các công cụ tác nhân hoặc tác nhân con hay không, như được minh họa trong hình sau. Mức độ rủi ro cao khi nói đến độ chính xác phát hiện ý định. Khi tác nhân dịch vụ khách hàng hiểu sai ý định của khách hàng, nó có thể gây ra một loạt vấn đề: các truy vấn bị định tuyến sai đến các trình giải quyết chuyên biệt không phù hợp, khách hàng nhận được phản hồi không liên quan và sự thất vọng gia tăng. Điều này ảnh hưởng đến trải nghiệm khách hàng và dẫn đến tăng chi phí vận hành khi nhiều khách hàng tìm kiếm sự can thiệp từ các tác nhân con người.
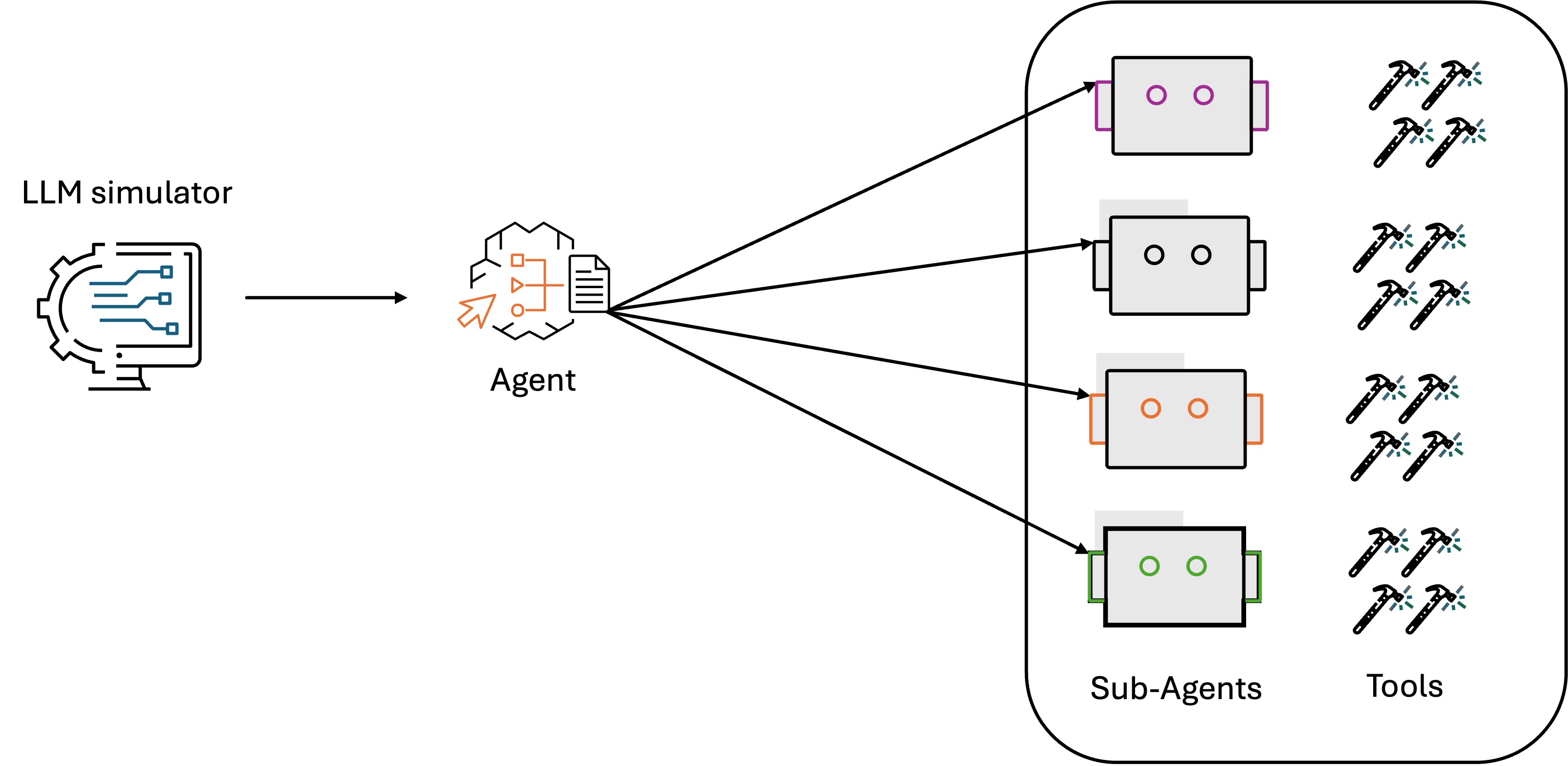
Để đánh giá khả năng suy luận của tác nhân trong việc phát hiện ý định, nhóm Amazon đã phát triển một trình mô phỏng LLM sử dụng các persona khách hàng ảo dựa trên LLM để mô phỏng các kịch bản và tương tác người dùng đa dạng. Việc đánh giá chủ yếu tập trung vào tính đúng đắn của ý định được tạo ra bởi tác nhân điều phối và định tuyến đến tác nhân con chính xác. Bộ dữ liệu mô phỏng chứa một tập hợp các cặp truy vấn người dùng và ý định ground truth được thu thập từ các tương tác khách hàng lịch sử đã được ẩn danh. Sử dụng trình mô phỏng, tác nhân điều phối tạo ra các ý định dựa trên các truy vấn người dùng trong bộ dữ liệu mô phỏng. Bằng cách so sánh ý định phản hồi của tác nhân với ý định ground truth, chúng tôi có thể xác thực xem các ý định do tác nhân tạo ra có tuân thủ ground truth hay không.
Ngoài tính đúng đắn của ý định, việc đánh giá còn bao gồm việc hoàn thành tác vụ—phản hồi cuối cùng của tác nhân và giải quyết ý định—như mục tiêu cuối cùng của các tác vụ dịch vụ khách hàng. Đối với hội thoại đa lượt, chúng tôi cũng bao gồm các số liệu phân loại tuân thủ chủ đề và từ chối tuân thủ chủ đề để giúp đảm bảo tính mạch lạc của hội thoại và chất lượng trải nghiệm người dùng. Khi các hệ thống dịch vụ khách hàng AI tiếp tục phát triển, tầm quan trọng của việc đánh giá suy luận tác nhân mạnh mẽ để phát hiện ý định người dùng chỉ tăng lên, tác động của nó vượt ra ngoài sự hài lòng của khách hàng ngay lập tức. Nó cũng tối ưu hóa hiệu quả hoạt động dịch vụ khách hàng và chi phí cung cấp dịch vụ, và do đó tối đa hóa lợi tức đầu tư AI.
Đánh giá hệ thống đa tác nhân tại Amazon
Khi các doanh nghiệp ngày càng đối mặt với những thách thức đa diện trong môi trường kinh doanh phức tạp, từ điều phối workflow đa chức năng đến ra quyết định theo thời gian thực trong điều kiện không chắc chắn, các nhóm của Amazon đang dần áp dụng kiến trúc hệ thống đa tác nhân phân tách các giải pháp AI nguyên khối thành các tác nhân chuyên biệt, hợp tác có khả năng suy luận phân tán, phân bổ tác vụ động và giải quyết vấn đề thích ứng ở quy mô lớn. Một ví dụ là tác nhân AI trợ lý người bán của Amazon bao gồm sự hợp tác giữa nhiều tác nhân AI, được mô tả trong biểu đồ luồng sau.
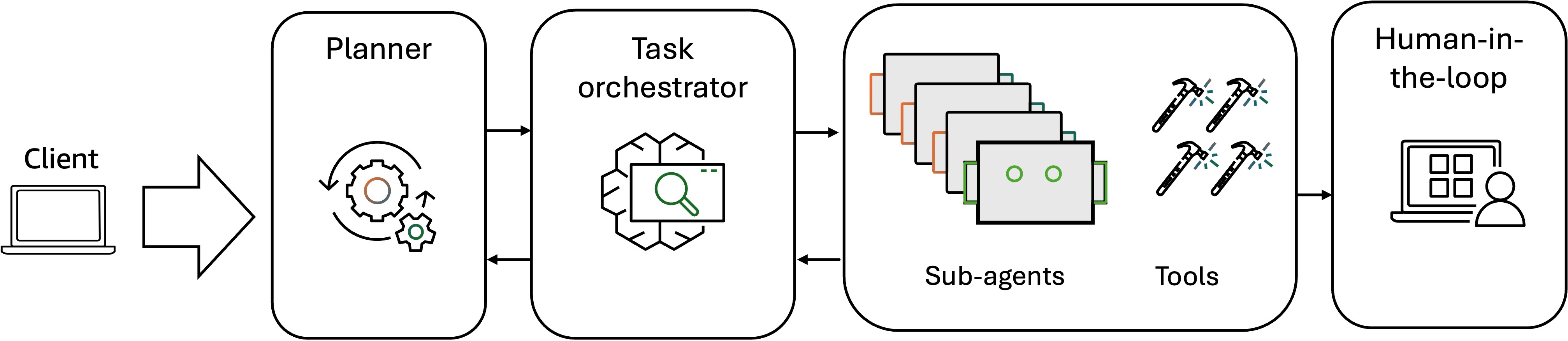
Workflow tác nhân, bắt đầu với một LLM planner và task orchestrator, nhận các yêu cầu của người dùng, phân tách các tác vụ phức tạp thành các tác vụ con chuyên biệt và phân công một cách thông minh mỗi tác vụ con cho tác nhân cơ bản phù hợp nhất dựa trên khả năng và khối lượng công việc hiện tại của chúng. Các tác nhân cơ bản sau đó hoạt động tự động, thực hiện các tác vụ được giao bằng cách sử dụng các công cụ chuyên biệt, khả năng suy luận và chuyên môn miền của chúng để hoàn thành mục tiêu mà không yêu cầu sự giám sát liên tục từ orchestrator. Sau khi hoàn thành tác vụ, các tác nhân chuyên biệt giao tiếp trở lại với tác nhân điều phối, báo cáo cập nhật trạng thái tác vụ, xác nhận hoàn thành, kết quả trung gian hoặc yêu cầu leo thang khi chúng gặp các kịch bản vượt quá giới hạn hoạt động của chúng. Tác nhân điều phối tổng hợp các phản hồi này, giám sát tiến độ tổng thể, xử lý các phụ thuộc giữa các tác vụ con và tổng hợp các đầu ra tập thể thành một kết quả cuối cùng mạch lạc giải quyết yêu cầu ban đầu của người dùng. Để đánh giá quy trình hợp tác đa tác nhân này, workflow đánh giá tính đến cả hiệu suất tác nhân riêng lẻ và động lực hệ thống tập thể tổng thể. Ngoài việc đánh giá chất lượng thực thi tác vụ tổng thể và hiệu suất của các tác nhân chuyên biệt trong việc hoàn thành tác vụ, suy luận, sử dụng công cụ và truy xuất bộ nhớ, chúng ta cũng cần đo lường các mẫu giao tiếp giữa các tác nhân, hiệu quả phối hợp và độ chính xác chuyển giao tác vụ. Đối với điều này, các nhóm của Amazon sử dụng các số liệu như điểm lập kế hoạch (phân công tác vụ con thành công cho các tác nhân con), điểm giao tiếp (thông điệp giao tiếp giữa các tác nhân để hoàn thành tác vụ con) và tỷ lệ thành công hợp tác (phần trăm hoàn thành tác vụ con thành công). Trong đánh giá hệ thống đa tác nhân, HITL trở nên quan trọng vì sự phức tạp gia tăng và tiềm năng cho các hành vi phát sinh không mong muốn mà các số liệu tự động có thể không nắm bắt được. Sự can thiệp của con người trong workflow đánh giá cung cấp sự giám sát cần thiết để đánh giá giao tiếp giữa các tác nhân nhằm xác định lỗi phối hợp trong các trường hợp biên cụ thể, đánh giá sự phù hợp của chuyên môn hóa tác nhân và liệu việc phân tách tác vụ có phù hợp với khả năng của tác nhân hay không, và xác thực các chiến lược giải quyết xung đột tiềm năng khi các tác nhân đưa ra các khuyến nghị mâu thuẫn. Nó cũng giúp đảm bảo tính nhất quán logic khi nhiều tác nhân đóng góp vào một quyết định duy nhất, và rằng hành vi tác nhân tập thể phục vụ mục tiêu kinh doanh đã định. Đây là những chiều khó định lượng thông qua các số liệu tự động nhưng rất quan trọng cho sự thành công của việc triển khai sản xuất.
Bài học kinh nghiệm và các phương pháp hay nhất
Thông qua các cuộc hợp tác sâu rộng với các nhóm sản phẩm và kỹ thuật của Amazon triển khai các hệ thống AI tác nhân trong môi trường sản xuất, chúng tôi đã xác định các bài học kinh nghiệm quan trọng và thiết lập các phương pháp hay nhất nhằm giải quyết những thách thức độc đáo trong việc đánh giá kiến trúc tác nhân tự động ở quy mô lớn.
- Đánh giá toàn diện trên nhiều chiều: Đánh giá ứng dụng tác nhân phải vượt ra ngoài các số liệu độ chính xác truyền thống để bao gồm một framework đánh giá toàn diện bao gồm chất lượng, hiệu suất, trách nhiệm và chi phí của tác nhân. Đánh giá chất lượng bao gồm đo lường tính mạch lạc của suy luận, độ chính xác lựa chọn công cụ và tỷ lệ thành công hoàn thành tác vụ trên các kịch bản đa dạng. Đánh giá hiệu suất nắm bắt độ trễ, thông lượng và mức sử dụng tài nguyên dưới khối lượng công việc sản xuất. Đánh giá trách nhiệm giải quyết an toàn, độc hại, giảm thiểu sai lệch, phát hiện ảo giác và các biện pháp bảo vệ để phù hợp với các chính sách tổ chức và yêu cầu quy định. Phân tích chi phí định lượng cả chi phí trực tiếp bao gồm suy luận mô hình, gọi công cụ, xử lý dữ liệu và chi phí gián tiếp như nỗ lực của con người và khắc phục lỗi. Cách tiếp cận đa chiều này giúp đảm bảo tối ưu hóa toàn diện trên các đánh đổi cân bằng.
- Đánh giá cụ thể theo trường hợp sử dụng và ứng dụng: Bên cạnh các số liệu tiêu chuẩn đã thảo luận trong các phần trước, các số liệu đánh giá cụ thể theo ứng dụng cũng đóng góp vào đánh giá ứng dụng tổng thể. Ví dụ, các ứng dụng dịch vụ khách hàng yêu cầu các số liệu như điểm hài lòng của khách hàng, tỷ lệ giải quyết lần đầu và điểm phân tích cảm xúc để đo lường kết quả kinh doanh cuối cùng. Cách tiếp cận này đòi hỏi sự hợp tác chặt chẽ với các chuyên gia miền để định nghĩa các tiêu chí thành công có ý nghĩa, định nghĩa các số liệu phù hợp và tạo các bộ dữ liệu đánh giá phản ánh sự phức tạp hoạt động trong thế giới thực để hoàn thành quy trình đánh giá.
- Human-in-the-loop (HITL) là một thành phần đánh giá quan trọng: Như đã thảo luận trong trường hợp đánh giá hệ thống đa tác nhân, HITL là không thể thiếu, đặc biệt đối với các kịch bản ra quyết định có rủi ro cao. Nó cung cấp đánh giá thiết yếu về chuỗi suy luận của tác nhân, tính mạch lạc của các workflow đa bước và sự phù hợp của hành vi tác nhân với các yêu cầu kinh doanh. HITL cũng giúp cung cấp các nhãn ground truth để xây dựng các bộ dữ liệu kiểm thử vàng và hiệu chỉnh LLM-as-a-judge trong trình đánh giá tự động để phù hợp với sở thích của con người.
- Đánh giá liên tục trong môi trường sản xuất: Điều cần thiết là duy trì chất lượng vì việc đánh giá trước khi triển khai có thể không nắm bắt đầy đủ các đặc điểm hiệu suất. Ngoài ra, đánh giá sản xuất giám sát hiệu suất trong thế giới thực trên các hành vi người dùng, mẫu sử dụng và trường hợp biên đa dạng không được thể hiện trước khi triển khai sản xuất để xác định sự suy giảm hiệu suất theo thời gian. Bạn có thể theo dõi các số liệu chính thông qua các dashboard hoạt động, triển khai ngưỡng cảnh báo, tự động hóa quy trình phát hiện bất thường và thiết lập các vòng phản hồi. Khi các vấn đề được phát hiện, bạn có thể bắt đầu đào tạo lại mô hình, tinh chỉnh kỹ thuật ngữ cảnh và phù hợp với các mục tiêu kinh doanh cuối cùng của mình.
Kết luận
Khi các hệ thống AI ngày càng trở nên phức tạp, tầm quan trọng của một phương pháp đánh giá tác nhân AI kỹ lưỡng không thể bị đánh giá thấp. Thông qua đánh giá toàn diện trên các chiều chất lượng, hiệu suất, trách nhiệm và chi phí, ngoài việc giám sát sản xuất liên tục và xác thực human-in-the-loop, toàn bộ vòng đời triển khai AI tác nhân từ phát triển đến sản xuất có thể được giải quyết. Bạn có thể học hỏi từ các ví dụ, phương pháp hay nhất và bài học kinh nghiệm được trình bày trong bài đăng này—nhiều trong số đó có sẵn trong Amazon Bedrock AgentCore Evaluations—để đẩy nhanh các sáng kiến AI tác nhân của riêng bạn trong khi tránh các cạm bẫy phổ biến trong thiết kế và triển khai đánh giá.
Về tác giả

Yunfei Bai
Yunfei Bai là Kiến trúc sư AI Ứng dụng Chính tại AWS. Với nền tảng về AI/ML, khoa học dữ liệu và phân tích, Yunfei giúp khách hàng áp dụng các dịch vụ AWS để mang lại kết quả kinh doanh. Anh thiết kế các giải pháp AI/ML và phân tích dữ liệu giúp vượt qua các thách thức kỹ thuật phức tạp và thúc đẩy các mục tiêu chiến lược. Yunfei có bằng Tiến sĩ Kỹ thuật Điện tử và Điện. Ngoài công việc, Yunfei thích đọc sách và nghe nhạc.

Winnie Xiong
Winnie Xiong là Quản lý Sản phẩm Kỹ thuật Cấp cao trong nhóm Benchmarking của Amazon. Cô hợp tác với các kỹ sư và nhà khoa học để xây dựng các giải pháp AI và dữ liệu nhằm giải quyết các thách thức kinh doanh phức tạp cho các nhóm của Amazon. Chuyên môn của cô bao gồm đánh giá mô hình, đánh giá tác nhân và quản lý dữ liệu.

Allie Colin
Allie Colin là Trưởng phòng Sản phẩm và Khoa học tại nhóm Benchmarking của Amazon. Cô lãnh đạo một nhóm các nhà khoa học và quản lý sản phẩm xây dựng các công cụ giúp nhân viên Amazon kiểm tra chất lượng sản phẩm của họ thông qua lăng kính trải nghiệm khách hàng thực tế. Trước đây, cô từng làm việc tại MicroStrategy với vai trò Chánh văn phòng cho CTO, cũng như tại Deutsche Bank và Northwestern Mutual. Ngoài công việc, Allie là một bà mẹ bốn con, yêu thích chương trình hài kịch hàng đêm mà các con cô biểu diễn và thích bất cứ hoạt động nào đưa cô ra ngoài trời – đi bộ đường dài, bơi lội và du lịch.

Kashif Imran
Kashif Imran là một lãnh đạo kỹ thuật và sản phẩm dày dặn kinh nghiệm với chuyên môn sâu về AI/ML, kiến trúc đám mây và các hệ thống phân tán quy mô lớn. Với một thập kỷ kinh nghiệm tại AWS, Kashif đã thúc đẩy đổi mới trong các công nghệ đám mây và AI. Hiện tại là Quản lý Cấp cao tại Amazon Prime Video, anh lãnh đạo các nhóm kỹ thuật AI-native xây dựng các giải pháp AI tác nhân có khả năng mở rộng để thúc đẩy chuyển đổi kinh doanh.
