Tác giả: Haochen Xie, Flora Wang, Hari Prasanna Das, and Yuan Tian
Ngày phát hành: 12 FEB 2026
Chuyên mục: Amazon Bedrock, Amazon Bedrock AgentCore, Amazon Bedrock Agents, Intermediate (200)
Các tác nhân AI đang nhanh chóng phát triển từ các giao diện trò chuyện đơn thuần thành những người lao động tự động tinh vi, xử lý các tác vụ phức tạp, tốn nhiều thời gian. Khi các tổ chức triển khai tác nhân để huấn luyện các mô hình machine learning (ML), xử lý các tập dữ liệu lớn và chạy các mô phỏng kéo dài, Model Context Protocol (MCP) đã nổi lên như một tiêu chuẩn cho các tích hợp tác nhân-máy chủ. Nhưng một thách thức quan trọng vẫn còn: các hoạt động này có thể mất hàng phút hoặc hàng giờ để hoàn thành, vượt xa khung thời gian phiên điển hình. Bằng cách sử dụng Amazon Bedrock AgentCore và Strands Agents để triển khai quản lý trạng thái bền vững, bạn có thể cho phép thực thi tác vụ liền mạch, xuyên phiên trong môi trường sản xuất. Hãy tưởng tượng tác nhân AI của bạn khởi tạo một công việc xử lý dữ liệu kéo dài nhiều giờ, người dùng của bạn đóng máy tính xách tay và hệ thống liền mạch truy xuất kết quả đã hoàn thành khi người dùng quay lại sau vài ngày—với khả năng hiển thị đầy đủ về tiến độ, kết quả và lỗi của tác vụ. Khả năng này biến các tác nhân AI từ trợ lý đàm thoại thành những người lao động tự động đáng tin cậy có thể xử lý các hoạt động quy mô doanh nghiệp. Nếu không có các mẫu kiến trúc này, bạn sẽ gặp lỗi hết thời gian chờ, sử dụng tài nguyên không hiệu quả và mất dữ liệu tiềm ẩn khi kết nối bị chấm dứt bất ngờ.
Trong bài đăng này, chúng tôi cung cấp cho bạn một cách tiếp cận toàn diện để đạt được điều này. Đầu tiên, chúng tôi giới thiệu một chiến lược nhắn tin ngữ cảnh duy trì giao tiếp liên tục giữa máy chủ và máy khách trong các hoạt động kéo dài. Tiếp theo, chúng tôi phát triển một khung quản lý tác vụ bất đồng bộ cho phép các tác nhân AI của bạn khởi tạo các quy trình chạy dài mà không chặn các hoạt động khác. Cuối cùng, chúng tôi trình bày cách kết hợp các chiến lược này với Amazon Bedrock AgentCore và Strands Agents để xây dựng các tác nhân AI sẵn sàng cho sản xuất có thể xử lý các hoạt vụ phức tạp, tốn nhiều thời gian một cách đáng tin cậy.
Các phương pháp phổ biến để xử lý các tác vụ chạy dài hạn
Khi thiết kế máy chủ MCP cho các tác vụ chạy dài hạn, bạn có thể phải đối mặt với một quyết định kiến trúc cơ bản: liệu máy chủ có nên duy trì kết nối hoạt động và cung cấp các bản cập nhật theo thời gian thực, hay nên tách rời việc thực thi tác vụ khỏi yêu cầu ban đầu? Lựa chọn này dẫn đến hai cách tiếp cận riêng biệt: nhắn tin ngữ cảnh và quản lý tác vụ bất đồng bộ.
Sử dụng cơ chế nhắn tin ngữ cảnh
Cách tiếp cận nhắn tin ngữ cảnh duy trì giao tiếp liên tục giữa máy chủ và máy khách MCP trong suốt quá trình thực thi tác vụ. Điều này đạt được bằng cách sử dụng đối tượng ngữ cảnh tích hợp của MCP để gửi thông báo định kỳ đến máy khách. Cách tiếp cận này là tối ưu cho các kịch bản mà các tác vụ thường hoàn thành trong vòng 10–15 phút và kết nối mạng vẫn ổn định. Cách tiếp cận nhắn tin ngữ cảnh mang lại những lợi thế sau:
- Triển khai đơn giản
- Không yêu cầu logic thăm dò bổ sung
- Triển khai máy khách đơn giản
- Chi phí tối thiểu
Sử dụng quản lý tác vụ bất đồng bộ
Cách tiếp cận quản lý tác vụ bất đồng bộ tách biệt việc khởi tạo tác vụ khỏi việc thực thi và truy xuất kết quả. Sau khi thực thi công cụ MCP, công cụ ngay lập tức trả về một thông báo khởi tạo tác vụ trong khi thực thi tác vụ ở chế độ nền. Cách tiếp cận này vượt trội trong các kịch bản doanh nghiệp đòi hỏi khắt khe, nơi các tác vụ có thể chạy hàng giờ, người dùng cần linh hoạt để ngắt kết nối và kết nối lại, và độ tin cậy của hệ thống là tối quan trọng. Cách tiếp cận quản lý tác vụ bất đồng bộ cung cấp những lợi ích sau:
- Hoạt động “fire-and-forget” thực sự
- Ngắt kết nối máy khách an toàn trong khi các tác vụ tiếp tục xử lý
- Ngăn ngừa mất dữ liệu thông qua lưu trữ bền vững
- Hỗ trợ các hoạt động chạy dài (hàng giờ)
- Khả năng phục hồi chống lại sự gián đoạn mạng
- Quy trình làm việc bất đồng bộ
Nhắn tin ngữ cảnh
Hãy bắt đầu bằng cách khám phá cách tiếp cận nhắn tin ngữ cảnh, cung cấp một giải pháp đơn giản để xử lý các hoạt động dài vừa phải trong khi duy trì các kết nối hoạt động. Cách tiếp cận này xây dựng trực tiếp trên các khả năng hiện có của MCP và yêu cầu cơ sở hạ tầng bổ sung tối thiểu, làm cho nó trở thành một điểm khởi đầu tuyệt vời để mở rộng giới hạn thời gian xử lý của tác nhân của bạn. Hãy tưởng tượng bạn đã xây dựng một máy chủ MCP cho một tác nhân AI giúp các nhà khoa học dữ liệu huấn luyện các mô hình ML. Khi người dùng yêu cầu tác nhân huấn luyện một mô hình phức tạp, quy trình cơ bản có thể mất 10–15 phút—vượt xa giới hạn thời gian chờ HTTP điển hình từ 30 giây đến 2 phút trong hầu hết các môi trường. Nếu không có chiến lược phù hợp, kết nối sẽ bị ngắt, hoạt động sẽ thất bại và người dùng sẽ cảm thấy thất vọng. Trong triển khai máy khách MCP sử dụng Streamable HTTP transport, các ràng buộc về thời gian chờ này đặc biệt hạn chế. Khi việc thực thi tác vụ vượt quá giới hạn thời gian chờ, kết nối bị hủy và quy trình làm việc của tác nhân bị gián đoạn. Đây là lúc nhắn tin ngữ cảnh phát huy tác dụng. Sơ đồ sau minh họa quy trình làm việc khi triển khai cách tiếp cận nhắn tin ngữ cảnh. Nhắn tin ngữ cảnh sử dụng đối tượng ngữ cảnh tích hợp của MCP để gửi các tín hiệu định kỳ từ máy chủ đến máy khách MCP, duy trì kết nối hoạt động trong suốt các hoạt động dài hơn. Hãy coi đó là việc gửi các thông điệp “nhịp tim” giúp ngăn kết nối bị hết thời gian chờ.
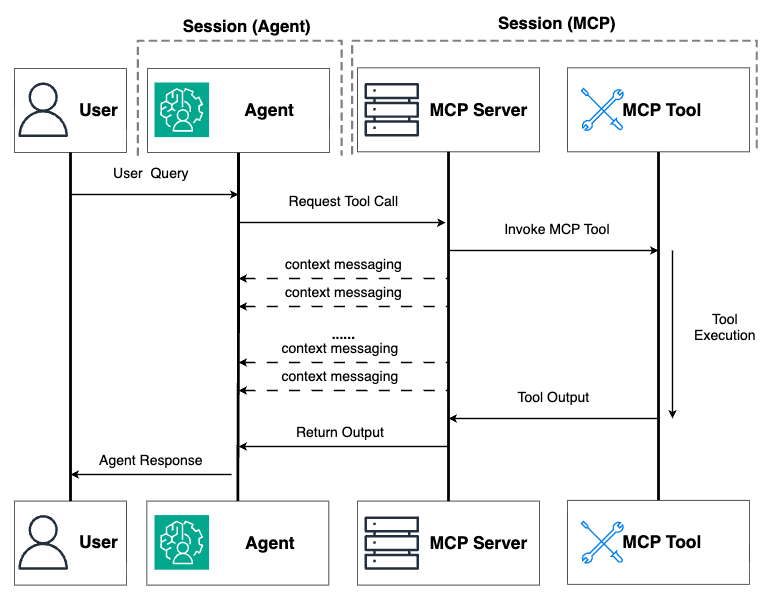
Hình 1: Minh họa quy trình làm việc trong phương pháp nhắn tin ngữ cảnh
Dưới đây là một ví dụ mã để triển khai nhắn tin ngữ cảnh:
from mcp.server.fastmcp import Context, FastMCPimport asynciomcp = FastMCP(host="0.0.0.0", stateless_http=True)@mcp.tool()async def model_training(model_name: str, epochs: int, ctx: Context) -> str: """Execute a task with progress updates.""" for i in range(epochs): # Simulate long running time training work progress = (i + 1) / epochs await asyncio.sleep(5) await ctx.report_progress( progress=progress, total=1.0, message=f"Step {i + 1}/{epochs}", ) return f"{model_name} training completed. The model artifact is stored in s3://templocation/model.pickle . The model training score is 0.87, validation score is 0.82."if __name__ == "__main__": mcp.run(transport="streamable-http")
Yếu tố chính ở đây là tham số Context trong định nghĩa công cụ. Khi bạn bao gồm một tham số với chú thích kiểu Context, FastMCP sẽ tự động inject đối tượng này, cho phép bạn truy cập các phương thức như ctx.info() và ctx.report_progress(). Các phương thức này gửi thông báo đến máy khách được kết nối mà không chấm dứt việc thực thi công cụ.
Các lệnh gọi report_progress() trong vòng lặp huấn luyện đóng vai trò là những thông điệp nhịp tim quan trọng đó, đảm bảo kết nối MCP vẫn hoạt động trong suốt thời gian xử lý kéo dài.
Đối với nhiều kịch bản thực tế, tiến độ chính xác không thể dễ dàng định lượng—chẳng hạn như khi xử lý các tập dữ liệu không thể đoán trước hoặc thực hiện các lệnh gọi API bên ngoài. Trong những trường hợp này, bạn có thể triển khai một hệ thống nhịp tim dựa trên thời gian:
from mcp.server.fastmcp import Context, FastMCPimport timeimport asynciomcp = FastMCP(host="0.0.0.0", stateless_http=True)@mcp.tool()async def model_training(model_name: str, epochs: int, ctx: Context) -> str: """Execute a task with progress updates.""" done_event = asyncio.Event() start_time = time.time() async def timer(): while not done_event.is_set(): elapsed = time.time() - start_time await ctx.info(f"Processing ......: {elapsed:.1f} seconds elapsed") await asyncio.sleep(5) # Check every 5 seconds return timer_task = asyncio.create_task(timer()) ## main task##################################### for i in range(epochs): # Simulate long running time training work progress = (i + 1) / epochs await asyncio.sleep(5) ################################################# # Signal the timer to stop and clean up done_event.set() await timer_task total_time = time.time() - start_time print(f"⏱️ Total processing time: {total_time:.2f} seconds") return f"{model_name} training completed. The model artifact is stored in s3://templocation/model.pickle . The model training score is 0.87, validation score is 0.82."if __name__ == "__main__": mcp.run(transport="streamable-http")
Mẫu này tạo một bộ đếm thời gian bất đồng bộ chạy song song với tác vụ chính của bạn, gửi các bản cập nhật trạng thái thường xuyên sau mỗi vài giây. Sử dụng asyncio.Event() để phối hợp tạo điều kiện cho việc tắt bộ đếm thời gian một cách sạch sẽ khi công việc chính hoàn thành.
Khi nào nên sử dụng cơ chế nhắn tin ngữ cảnh
Nhắn tin ngữ cảnh hoạt động tốt nhất khi:
- Các tác vụ mất 1–15 phút để hoàn thành*
- Kết nối mạng thường ổn định
- Phiên máy khách có thể duy trì hoạt động trong suốt quá trình hoạt động
- Bạn cần cập nhật tiến độ theo thời gian thực trong quá trình xử lý
- Các tác vụ có thời gian thực thi có thể dự đoán được, hữu hạn với các điều kiện chấm dứt rõ ràng
*Lưu ý: “15 phút” dựa trên thời gian tối đa cho các yêu cầu đồng bộ mà Amazon Bedrock AgentCore cung cấp. Thông tin chi tiết hơn về hạn ngạch dịch vụ của Bedrock AgentCore có thể được tìm thấy tại Hạn ngạch cho Amazon Bedrock AgentCore. Nếu cơ sở hạ tầng lưu trữ tác nhân không triển khai giới hạn thời gian cứng, hãy cực kỳ thận trọng khi sử dụng cách tiếp cận này cho các tác vụ có thể bị treo hoặc chạy vô thời hạn. Nếu không có các biện pháp bảo vệ phù hợp, một tác vụ bị kẹt có thể duy trì kết nối mở vô thời hạn, dẫn đến cạn kiệt tài nguyên, các quy trình không phản hồi và có khả năng gây ra các vấn đề ổn định trên toàn hệ thống.
Dưới đây là một số hạn chế quan trọng cần xem xét:
- Yêu cầu kết nối liên tục – Phiên máy khách phải duy trì hoạt động trong suốt quá trình hoạt động. Nếu người dùng đóng trình duyệt hoặc mạng bị ngắt, công việc sẽ bị mất.
- Tiêu thụ tài nguyên – Giữ các kết nối mở tiêu thụ tài nguyên máy chủ và máy khách, có khả năng làm tăng chi phí cho các hoạt động chạy dài.
- Phụ thuộc mạng – Sự không ổn định của mạng vẫn có thể làm gián đoạn quy trình, yêu cầu khởi động lại hoàn toàn.
- Giới hạn thời gian chờ cuối cùng – Hầu hết các cơ sở hạ tầng đều có giới hạn thời gian chờ cứng không thể vượt qua bằng các thông điệp nhịp tim.
Do đó, đối với các hoạt động thực sự chạy dài có thể mất hàng giờ hoặc đối với các kịch bản mà người dùng cần ngắt kết nối và kết nối lại sau, bạn sẽ cần cách tiếp cận quản lý tác vụ bất đồng bộ mạnh mẽ hơn.
Quản lý tác vụ bất đồng bộ
Không giống như cách tiếp cận nhắn tin ngữ cảnh, nơi máy khách phải duy trì kết nối liên tục, mẫu quản lý tác vụ bất đồng bộ tuân theo mô hình “fire and forget”:
- Khởi tạo tác vụ – Máy khách gửi yêu cầu để bắt đầu một tác vụ và ngay lập tức nhận được một ID tác vụ
- Xử lý nền – Máy chủ thực thi công việc bất đồng bộ, không yêu cầu kết nối máy khách
- Kiểm tra trạng thái – Máy khách có thể kết nối lại bất cứ lúc nào để kiểm tra tiến độ bằng cách sử dụng ID tác vụ
- Truy xuất kết quả – Khi hoàn thành, kết quả vẫn có sẵn để truy xuất bất cứ khi nào máy khách kết nối lại
Hình sau minh họa quy trình làm việc trong cách tiếp cận quản lý tác vụ bất đồng bộ.
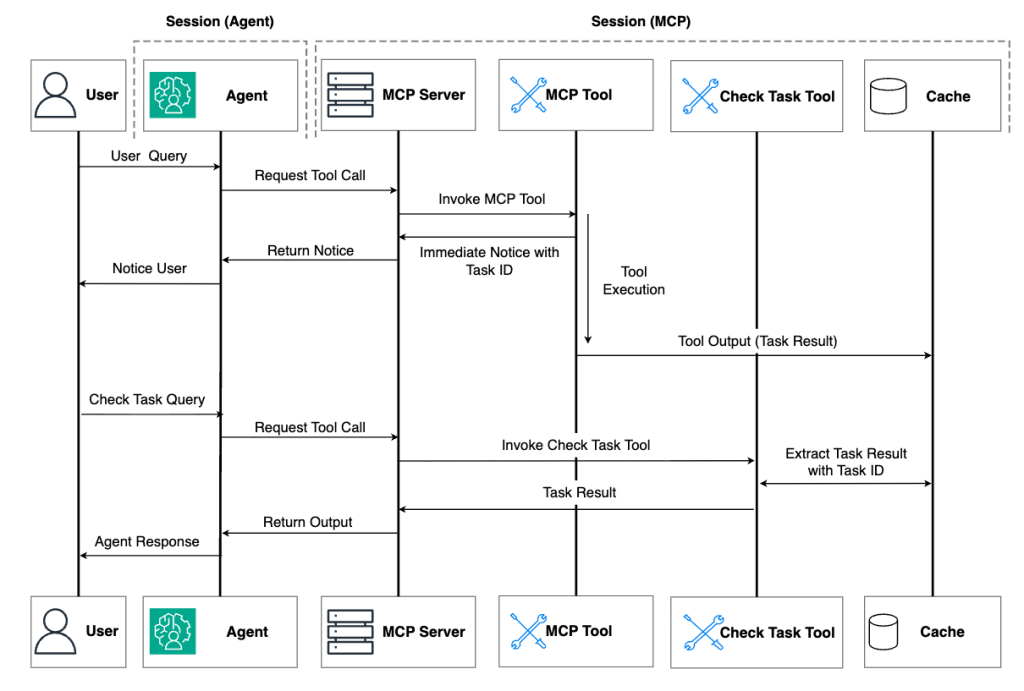
Hình 2: Minh họa quy trình làm việc trong phương pháp quản lý tác vụ bất đồng bộ
Mẫu này phản ánh cách bạn tương tác với các hệ thống xử lý hàng loạt trong môi trường doanh nghiệp—gửi một công việc, ngắt kết nối và kiểm tra lại sau khi thuận tiện. Dưới đây là một triển khai thực tế minh họa các nguyên tắc này:
from mcp.server.fastmcp import Context, FastMCPimport asyncioimport uuidfrom typing import Dict, Anymcp = FastMCP(host="0.0.0.0", stateless_http=True)# task storagetasks: Dict[str, Dict[str, Any]] = {}async def _execute_model_training( task_id: str, model_name: str, epochs: int ): """Background task execution.""" tasks[task_id]["status"] = "running" for i in range(epochs): tasks[task_id]["progress"] = (i + 1) / epochs await asyncio.sleep(2) tasks[task_id]["result"] = f"{model_name} training completed. The model artifact is stored in s3://templocation/model.pickle . The model training score is 0.87, validation score is 0.82." tasks[task_id]["status"] = "completed"@mcp.tool()def model_training( model_name: str, epochs: int = 10 ) -> str: """Start model training task.""" task_id = str(uuid.uuid4()) tasks[task_id] = { "status": "started", "progress": 0.0, "task_type": "model_training" } asyncio.create_task(_execute_model_training(task_id, model_name, epochs)) return f"Model Training task has been initiated with task ID: {task_id}. Please check back later to monitor completion status and retrieve results."@mcp.tool()def check_task_status(task_id: str) -> Dict[str, Any]: """Check the status of a running task.""" if task_id not in tasks: return {"error": "task not found"} task = tasks[task_id] return { "task_id": task_id, "status": task["status"], "progress": task["progress"], "task_type": task.get("task_type", "unknown") }@mcp.tool()def get_task_results(task_id: str) -> Dict[str, Any]: """Get results from a completed task.""" if task_id not in tasks: return {"error": "task not found"} task = tasks[task_id] if task["status"] != "completed": return {"error": f"task not completed. Current status: {task['status']}"} return { "task_id": task_id, "status": task["status"], "result": task["result"] }if __name__ == "__main__": mcp.run(transport="streamable-http")
Triển khai này tạo một hệ thống quản lý tác vụ với ba công cụ MCP riêng biệt:
model_training()– Điểm vào khởi tạo một tác vụ mới. Thay vì thực hiện công việc trực tiếp, nó:- Tạo một định danh tác vụ duy nhất bằng cách sử dụng Universally Unique Identifier (UUID)
- Tạo một bản ghi tác vụ ban đầu trong từ điển lưu trữ
- Khởi chạy quá trình xử lý thực tế dưới dạng tác vụ nền bằng cách sử dụng
asyncio.create_task() - Trả về ngay lập tức với ID tác vụ, cho phép máy khách ngắt kết nối
check_task_status()– Cho phép máy khách theo dõi tiến độ một cách thuận tiện bằng cách:- Tra cứu tác vụ theo ID trong từ điển lưu trữ
- Trả về trạng thái hiện tại và thông tin tiến độ
- Cung cấp xử lý lỗi thích hợp cho các tác vụ bị thiếu
get_task_results()– Truy xuất kết quả đã hoàn thành khi sẵn sàng bằng cách:- Xác minh tác vụ tồn tại và đã hoàn thành
- Trả về kết quả được lưu trữ trong quá trình xử lý nền
- Cung cấp thông báo lỗi rõ ràng khi kết quả chưa sẵn sàng
Công việc thực tế diễn ra trong hàm riêng tư _execute_model_training(), chạy độc lập ở chế độ nền sau khi yêu cầu máy khách ban đầu hoàn thành. Nó cập nhật trạng thái và tiến độ của tác vụ trong bộ nhớ dùng chung khi nó tiến triển, làm cho thông tin này có sẵn cho các lần kiểm tra trạng thái tiếp theo.
Những hạn chế cần xem xét
Mặc dù cách tiếp cận quản lý tác vụ bất đồng bộ giúp giải quyết các vấn đề kết nối, nhưng nó cũng đưa ra một số hạn chế riêng:
- Ma sát trải nghiệm người dùng – Cách tiếp cận yêu cầu người dùng phải kiểm tra trạng thái tác vụ thủ công, ghi nhớ ID tác vụ giữa các phiên và yêu cầu kết quả một cách rõ ràng, làm tăng độ phức tạp tương tác.
- Lưu trữ bộ nhớ dễ bay hơi – Sử dụng bộ nhớ trong (như trong ví dụ của chúng tôi) có nghĩa là các tác vụ và kết quả sẽ bị mất nếu máy chủ khởi động lại, làm cho giải pháp không phù hợp cho sản xuất nếu không có bộ nhớ bền vững.
- Ràng buộc môi trường serverless – Trong các môi trường serverless tạm thời, các instance tự động bị chấm dứt sau một thời gian không hoạt động, khiến trạng thái tác vụ trong bộ nhớ bị mất vĩnh viễn. Điều này tạo ra một tình huống nghịch lý, trong đó giải pháp được thiết kế để xử lý các hoạt động chạy dài lại dễ bị tổn thương bởi chính thời lượng mà nó nhằm hỗ trợ. Trừ khi người dùng duy trì việc kiểm tra thường xuyên để giúp ngăn chặn giới hạn thời gian phiên, cả tác vụ và kết quả đều có thể biến mất.
Hướng tới một giải pháp mạnh mẽ
Để giải quyết những hạn chế quan trọng này, bạn cần bao gồm tính bền vững bên ngoài tồn tại cả khi máy chủ khởi động lại và khi instance bị chấm dứt. Đây là lúc tích hợp với các dịch vụ lưu trữ chuyên dụng trở nên thiết yếu. Bằng cách sử dụng các hệ thống lưu trữ bộ nhớ tác nhân bên ngoài, bạn có thể thay đổi cơ bản nơi và cách thông tin tác vụ được duy trì. Thay vì dựa vào bộ nhớ dễ bay hơi của máy chủ MCP, cách tiếp cận này sử dụng các dịch vụ lưu trữ bộ nhớ tác nhân bên ngoài bền vững vẫn có sẵn bất kể trạng thái máy chủ.
Sự đổi mới chính trong cách tiếp cận nâng cao này là khi máy chủ MCP chạy một tác vụ dài hạn, nó ghi các kết quả tạm thời hoặc cuối cùng trực tiếp vào bộ nhớ ngoài, chẳng hạn như Amazon Bedrock AgentCore Memory mà tác nhân có thể truy cập, như minh họa trong hình sau. Điều này giúp tạo ra khả năng phục hồi chống lại hai loại lỗi thời gian chạy:
- Instance chạy máy chủ MCP có thể bị chấm dứt do không hoạt động sau khi tác vụ hoàn thành
- Instance lưu trữ tác nhân có thể được tái chế trong các môi trường serverless tạm thời
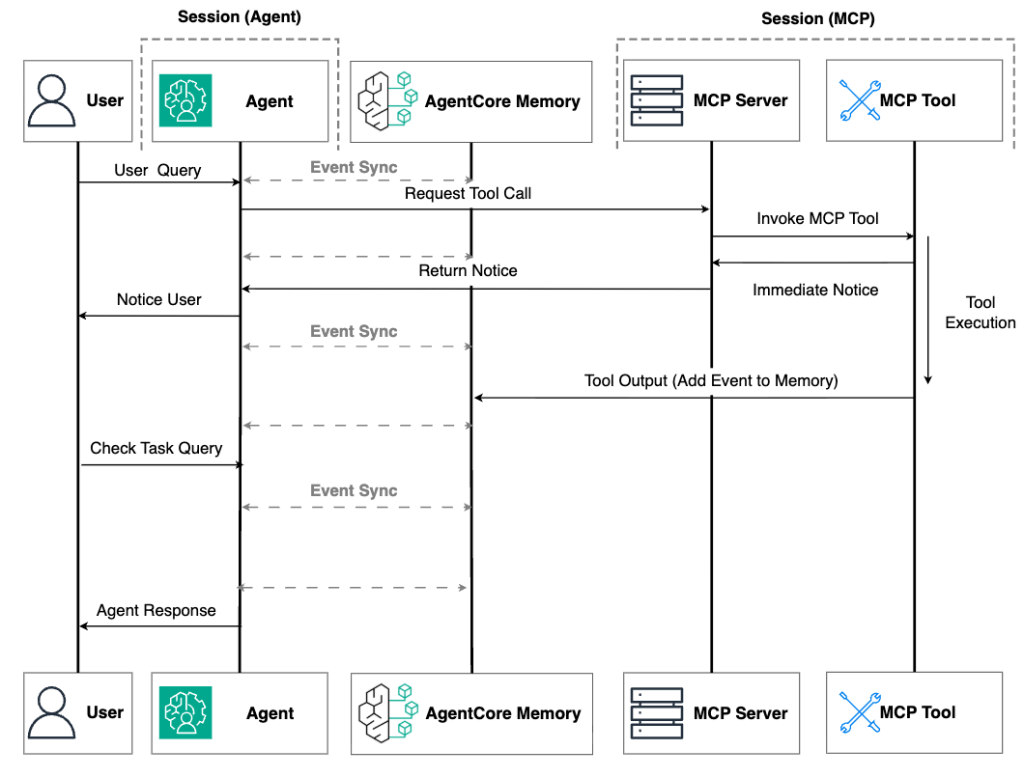
Hình 3: Tích hợp MCP với bộ nhớ ngoài
Với bộ nhớ ngoài, khi người dùng quay lại tương tác với tác nhân—dù là vài phút, vài giờ hay vài ngày sau—tác nhân có thể truy xuất kết quả tác vụ đã hoàn thành từ bộ nhớ bền vững. Cách tiếp cận này giảm thiểu sự phụ thuộc vào thời gian chạy: ngay cả khi cả máy chủ MCP và các instance tác nhân bị chấm dứt, kết quả tác vụ vẫn được bảo toàn an toàn và có thể truy cập khi cần.
Phần tiếp theo sẽ khám phá cách triển khai giải pháp mạnh mẽ này bằng cách sử dụng Amazon Bedrock AgentCore Runtime làm môi trường lưu trữ serverless, AgentCore Memory để lưu trữ bộ nhớ tác nhân bền vững và khung Strands Agents để điều phối các thành phần này thành một hệ thống gắn kết duy trì trạng thái tác vụ trên các ranh giới phiên.
Triển khai Amazon Bedrock AgentCore và Strands Agents
Trước khi đi sâu vào chi tiết triển khai, điều quan trọng là phải hiểu các tùy chọn triển khai có sẵn cho máy chủ MCP trên Amazon Bedrock AgentCore. Có hai cách tiếp cận chính: Amazon Bedrock AgentCore Gateway và AgentCore Runtime. AgentCore Gateway có thời gian chờ 5 phút cho các lệnh gọi, làm cho nó không phù hợp để lưu trữ các máy chủ MCP cung cấp các công cụ yêu cầu thời gian phản hồi kéo dài hoặc các hoạt động chạy dài. AgentCore Runtime cung cấp tính linh hoạt đáng kể hơn với thời gian chờ yêu cầu 15 phút (đối với các yêu cầu đồng bộ) và thời lượng phiên tối đa có thể điều chỉnh (đối với các quy trình bất đồng bộ; thời lượng mặc định là 8 giờ) và thời gian chờ phiên không hoạt động. Mặc dù bạn có thể lưu trữ một máy chủ MCP trong môi trường serverful truyền thống để có thời gian thực thi không giới hạn, AgentCore Runtime cung cấp sự cân bằng tối ưu cho hầu hết các kịch bản sản xuất. Bạn có được các lợi ích serverless như tự động mở rộng quy mô, định giá trả theo mức sử dụng và không cần quản lý cơ sở hạ tầng, trong khi thời lượng phiên tối đa có thể điều chỉnh bao gồm hầu hết các tác vụ chạy dài trong thế giới thực—từ xử lý dữ liệu và huấn luyện mô hình đến tạo báo cáo và mô phỏng phức tạp. Bạn có thể sử dụng cách tiếp cận này để xây dựng các tác nhân AI tinh vi mà không phải chịu chi phí vận hành quản lý máy chủ trong khi chỉ dành các triển khai serverful cho những trường hợp hiếm hoi thực sự yêu cầu thực thi nhiều ngày. Để biết thêm thông tin về hạn ngạch dịch vụ của AgentCore Runtime và AgentCore Gateway, hãy tham khảo Hạn ngạch cho Amazon Bedrock AgentCore.
Tiếp theo, chúng ta sẽ xem xét việc triển khai, được minh họa trong sơ đồ sau. Triển khai này bao gồm hai thành phần được kết nối với nhau: máy chủ MCP thực thi các tác vụ chạy dài và ghi kết quả vào AgentCore Memory, và tác nhân quản lý luồng hội thoại và truy xuất các kết quả đó khi cần. Kiến trúc này tạo ra trải nghiệm liền mạch, nơi người dùng có thể ngắt kết nối trong các quy trình dài và quay lại sau để tìm thấy kết quả của họ đang chờ.
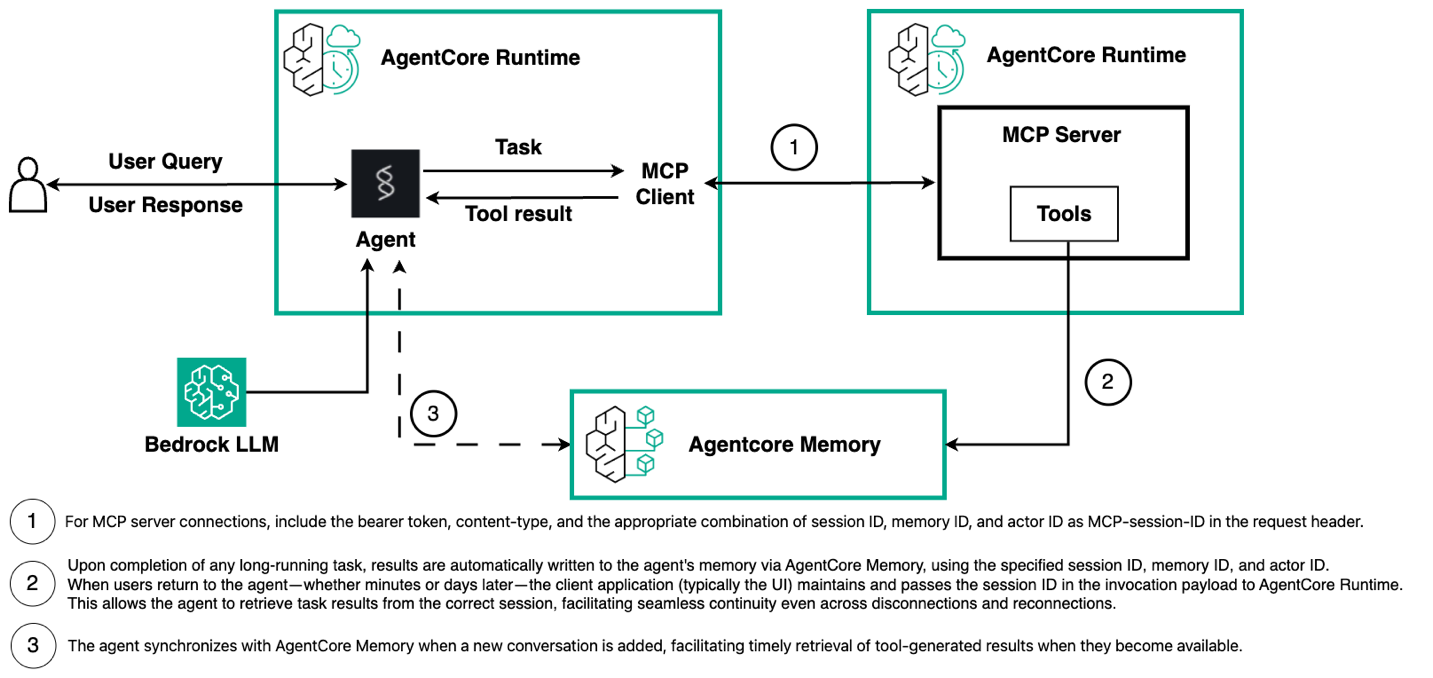
Triển khai máy chủ MCP
Hãy cùng xem xét cách triển khai máy chủ MCP của chúng tôi sử dụng AgentCore Memory để đạt được tính bền vững:
from mcp.server.fastmcp import Context, FastMCPimport asyncioimport uuidfrom typing import Dict, Anyimport jsonfrom bedrock_agentcore.memory import MemoryClientmcp = FastMCP(host="0.0.0.0", stateless_http=True)agentcore_memory_client = MemoryClient()async def _execute_model_training( model_name: str, epochs: int, session_id: str, actor_id: str, memory_id: str ): """Background task execution.""" for i in range(epochs): await asyncio.sleep(2) try: response = agentcore_memory_client.create_event( memory_id=memory_id, actor_id=actor_id, session_id=session_id, messages=[ ( json.dumps({ "message": { "role": "user", "content": [ { "text": f"{model_name} training completed. The model artifact is stored in s3://templocation/model.pickle . The model training score is 0.87, validation score is 0.82." } ] }, "message_id": 0 }), 'USER' ) ] ) print(response) except Exception as e: print(f"Memory save error: {e}") return@mcp.tool()def model_training( model_name: str, epochs: int, ctx: Context ) -> str: """Start model training task.""" print(ctx.request_context.request.headers) mcp_session_id = ctx.request_context.request.headers.get("mcp-session-id", "") temp_id_list = mcp_session_id.split("@@@") session_id = temp_id_list[0] memory_id= temp_id_list[1] actor_id = temp_id_list[2] asyncio.create_task(_execute_model_training( model_name, epochs, session_id, actor_id, memory_id ) ) return f"Model {model_name}Training task has been initiated. Total training epochs are {epochs}. The results will be updated once the training is completed."if __name__ == "__main__": mcp.run(transport="streamable-http")
Việc triển khai dựa vào hai thành phần chính cho phép tính bền vững và quản lý phiên.
- Phương thức
agentcore_memory_client.create_event()đóng vai trò là cầu nối giữa việc thực thi công cụ và lưu trữ bộ nhớ bền vững. Khi một tác vụ nền hoàn thành, phương thức này lưu kết quả trực tiếp vào bộ nhớ của tác nhân trong AgentCore Memory bằng cách sử dụng ID bộ nhớ, ID tác nhân và ID phiên được chỉ định. Không giống như các cách tiếp cận truyền thống, nơi kết quả có thể được lưu trữ tạm thời hoặc yêu cầu truy xuất thủ công, tích hợp này cho phép kết quả tác vụ trở thành một phần vĩnh viễn của bộ nhớ hội thoại của tác nhân. Tác nhân sau đó có thể tham chiếu các kết quả này trong các tương tác trong tương lai, tạo ra trải nghiệm xây dựng kiến thức liên tục trên nhiều phiên. - Thành phần quan trọng thứ hai liên quan đến việc trích xuất ngữ cảnh phiên thông qua
ctx.request_context.request.headers.get("mcp-session-id", "").“Mcp-Session-Id”là một phần của giao thức MCP tiêu chuẩn. Bạn có thể sử dụng tiêu đề này để truyền một định danh tổng hợp chứa ba thông tin thiết yếu ở định dạng phân tách:session_id@@@memory_id@@@actor_id. Cách tiếp cận này cho phép triển khai của chúng tôi truy xuất các định danh ngữ cảnh cần thiết từ một giá trị tiêu đề duy nhất. Tiêu đề được sử dụng thay vì biến môi trường do cần thiết—các định danh này thay đổi động với mỗi cuộc hội thoại, trong khi biến môi trường vẫn tĩnh từ khi khởi động container. Lựa chọn thiết kế này đặc biệt quan trọng trong các kịch bản đa người thuê, nơi một máy chủ MCP duy nhất đồng thời xử lý các yêu cầu từ nhiều người dùng, mỗi người có ngữ cảnh phiên riêng biệt.
Một khía cạnh quan trọng khác trong ví dụ này liên quan đến định dạng thông báo phù hợp khi lưu trữ các sự kiện. Mỗi thông báo được lưu vào AgentCore Memory yêu cầu hai thành phần: nội dung và định danh vai trò. Hai thành phần này cần được định dạng theo cách mà khung tác nhân có thể nhận ra. Dưới đây là một ví dụ cho khung Strands Agents:
messages=[ ( json.dumps({ "message": { "role": "user", "content": [ { "text": <message to the memory> } ] }, "message_id": 0 }), 'USER' )]
Nội dung là một đối tượng JSON bên trong (được serialize bằng json.dumps()) chứa các chi tiết thông báo, bao gồm vai trò, nội dung văn bản và ID thông báo. Định danh vai trò bên ngoài (USER trong ví dụ này) giúp AgentCore Memory phân loại nguồn thông báo.
Triển khai Strands Agents
Tích hợp Amazon Bedrock AgentCore Memory với Strands Agents cực kỳ đơn giản bằng cách sử dụng lớp AgentCoreMemorySessionManager từ Bedrock AgentCore SDK. Như được hiển thị trong ví dụ mã sau, việc triển khai yêu cầu cấu hình tối thiểu—tạo một AgentCoreMemoryConfig với các định danh phiên của bạn, khởi tạo trình quản lý phiên với cấu hình này và truyền nó trực tiếp vào hàm tạo tác nhân của bạn. Trình quản lý phiên xử lý các hoạt động bộ nhớ một cách minh bạch phía sau hậu trường, duy trì lịch sử hội thoại và ngữ cảnh giữa các tương tác trong khi tổ chức bộ nhớ bằng cách kết hợp session_id, memory_id và actor_id. Để biết thêm thông tin, hãy tham khảo AgentCore Memory Session Manager.
from bedrock_agentcore.memory.integrations.strands.config import AgentCoreMemoryConfigfrom bedrock_agentcore.memory.integrations.strands.session_manager import AgentCoreMemorySessionManager@app.entrypointasync def strands_agent_main(payload, context): session_id = context.session_id if not session_id: session_id = str(uuid.uuid4()) print(f"Session ID: {session_id}") memory_id = payload.get("memory_id") if not memory_id: memory_id = "" print(f"? Memory ID: {memory_id}") actor_id = payload.get("actor_id") if not actor_id: actor_id = "default" agentcore_memory_config = AgentCoreMemoryConfig( memory_id=memory_id, session_id=session_id, actor_id=actor_id ) session_manager = AgentCoreMemorySessionManager( agentcore_memory_config=agentcore_memory_config ) user_input = payload.get("prompt") headers = { "authorization": f"Bearer {bearer_token}", "Content-Type": "application/json", "Mcp-Session-Id": session_id + "@@@" + memory_id + "@@@" + actor_id } # Connect to an MCP server using SSE transport streamable_http_mcp_client = MCPClient( lambda: streamablehttp_client( mcp_url, headers, timeout=30 ) ) with streamable_http_mcp_client: # Get the tools from the MCP server tools = streamable_http_mcp_client.list_tools_sync() # Create an agent with these tools agent = Agent( tools = tools, callback_handler=call_back_handler, session_manager=session_manager )
Việc quản lý ngữ cảnh phiên đặc biệt tinh tế ở đây. Tác nhân nhận các định danh phiên thông qua các tham số payload và context được cung cấp bởi AgentCore Runtime. Các định danh này tạo thành một cầu nối ngữ cảnh quan trọng kết nối các tương tác người dùng trên nhiều phiên. session_id có thể được trích xuất từ đối tượng context (tạo một cái mới nếu cần), và memory_id và actor_id có thể được truy xuất từ payload. Các định danh này sau đó được đóng gói vào một tiêu đề HTTP tùy chỉnh (Mcp-Session-Id) được truyền đến máy chủ MCP trong quá trình thiết lập kết nối.
Để duy trì trải nghiệm bền vững này trên nhiều tương tác, máy khách phải luôn cung cấp cùng các định danh khi gọi tác nhân:
# invoke agentcore through boto3boto3_response = agentcore_client.invoke_agent_runtime( agentRuntimeArn=agent_arn, qualifier="DEFAULT", payload=json.dumps( { "prompt": user_input, "actor_id": actor_id, "memory_id": memory_id } ), runtimeSessionId = session_id,)
Bằng cách liên tục cung cấp cùng memory_id, actor_id và runtimeSessionId trên các lệnh gọi, người dùng có thể tạo ra trải nghiệm hội thoại liên tục, nơi kết quả tác vụ tồn tại độc lập với ranh giới phiên. Khi người dùng quay lại sau vài ngày, tác nhân có thể tự động truy xuất cả lịch sử hội thoại và kết quả tác vụ đã hoàn thành trong thời gian họ vắng mặt.
Kiến trúc này đại diện cho một bước tiến đáng kể trong khả năng của tác nhân AI—biến các hoạt động chạy dài từ các quy trình dễ bị tổn thương, phụ thuộc vào kết nối thành các tác vụ mạnh mẽ, bền vững tiếp tục hoạt động bất kể trạng thái kết nối. Kết quả là một hệ thống có thể cung cấp hỗ trợ AI thực sự bất đồng bộ, nơi công việc phức tạp tiếp tục ở chế độ nền và kết quả được tích hợp liền mạch bất cứ khi nào người dùng quay lại cuộc hội thoại.
Kết luận
Trong bài đăng này, chúng tôi đã khám phá các cách thực tế để giúp các tác nhân AI xử lý các tác vụ mất vài phút hoặc thậm chí vài giờ để hoàn thành. Cho dù sử dụng cách tiếp cận đơn giản hơn là giữ kết nối hoạt động hay phương pháp nâng cao hơn là đưa kết quả tác vụ vào bộ nhớ của tác nhân, các kỹ thuật này cho phép tác nhân AI của bạn giải quyết công việc phức tạp có giá trị mà không bị giới hạn thời gian gây khó chịu hoặc mất kết quả.
Chúng tôi mời bạn thử các cách tiếp cận này trong các dự án tác nhân AI của riêng bạn. Bắt đầu với nhắn tin ngữ cảnh cho các tác vụ vừa phải, sau đó chuyển sang quản lý bất đồng bộ khi nhu cầu của bạn tăng lên. Các giải pháp chúng tôi đã chia sẻ có thể nhanh chóng được điều chỉnh theo nhu cầu cụ thể của bạn, giúp bạn xây dựng AI mang lại kết quả đáng tin cậy—ngay cả khi người dùng ngắt kết nối và quay lại sau vài ngày. Những tác vụ chạy dài nào mà trợ lý AI của bạn có thể xử lý tốt hơn với các kỹ thuật này?
Để tìm hiểu thêm, hãy xem tài liệu Amazon Bedrock AgentCore và khám phá sổ tay mẫu của chúng tôi.
Về tác giả

Haochen Xie là Kỹ sư Khoa học Dữ liệu cấp cao tại AWS Generative AI Innovation Center. Anh ấy là một người bình thường.

Flora Wang là Nhà khoa học ứng dụng tại AWS Generative AI Innovation Center, nơi cô làm việc với khách hàng để kiến trúc và triển khai các giải pháp AI tạo sinh có thể mở rộng nhằm giải quyết các thách thức kinh doanh độc đáo của họ. Cô chuyên về các kỹ thuật tùy chỉnh mô hình và hệ thống AI dựa trên tác nhân, giúp các tổ chức khai thác toàn bộ tiềm năng của công nghệ AI tạo sinh.

Yuan Tian là Nhà khoa học ứng dụng tại AWS Generative AI Innovation Center, nơi anh làm việc với khách hàng trong nhiều ngành khác nhau—bao gồm chăm sóc sức khỏe, khoa học đời sống, tài chính và năng lượng—để kiến trúc và triển khai các giải pháp AI tạo sinh như hệ thống tác nhân. Anh mang đến một góc nhìn liên ngành độc đáo, kết hợp chuyên môn về machine learning với sinh học tính toán.

Hari Prasanna Das là Nhà khoa học ứng dụng tại AWS Generative AI Innovation Center, nơi anh làm việc với khách hàng AWS trên các lĩnh vực khác nhau để đẩy nhanh việc sử dụng AI tạo sinh của họ. Hari có bằng Tiến sĩ Kỹ thuật Điện và Khoa học Máy tính từ Đại học California, Berkeley. Lĩnh vực nghiên cứu của anh bao gồm AI tạo sinh, Học sâu, Thị giác máy tính và Machine Learning hiệu quả dữ liệu.
