Tác giả: Monica Jain, Damien Forthomme, Mihir Gadgil, Muhammad Umar Javed, Norman Braddock, và Sujit Narapareddy
Ngày phát hành: 18 FEB 2026
Chuyên mục: Amazon Bedrock, Artificial Intelligence, Technical How-to
Xây dựng trí tuệ khách hàng gắn kết và thống nhất trong toàn tổ chức của bạn bắt đầu bằng việc giảm bớt những khó khăn mà đại diện bán hàng của bạn gặp phải khi chuyển đổi giữa Salesforce, các phiếu hỗ trợ và Amazon Redshift. Một đại diện bán hàng chuẩn bị cho cuộc họp với khách hàng có thể mất hàng giờ để nhấp qua nhiều bảng điều khiển khác nhau—đề xuất sản phẩm, chỉ số tương tác, phân tích doanh thu, v.v.—trước khi có được bức tranh hoàn chỉnh về tình hình của khách hàng. Tại AWS, tổ chức bán hàng của chúng tôi đã trải nghiệm điều này trực tiếp khi chúng tôi mở rộng quy mô toàn cầu. Chúng tôi cần một cách để hợp nhất dữ liệu khách hàng bị phân mảnh trên các cơ sở dữ liệu chỉ số, kho lưu trữ tài liệu và các nguồn ngành bên ngoài – mà không cần xây dựng cơ sở hạ tầng điều phối tùy chỉnh phức tạp.
Chúng tôi đã xây dựng Customer Agent & Knowledge Engine (CAKE), một tác nhân trò chuyện lấy khách hàng làm trung tâm sử dụng Amazon Bedrock AgentCore để giải quyết thách thức này. CAKE điều phối các công cụ truy xuất chuyên biệt – truy vấn biểu đồ tri thức trong Amazon Neptune, các chỉ số trong Amazon DynamoDB, tài liệu trong Amazon OpenSearch Service, và dữ liệu thị trường bên ngoài bằng cách sử dụng API tìm kiếm web, cùng với việc thực thi bảo mật bằng công cụ Row Level Security (RLS), cung cấp thông tin chi tiết về khách hàng thông qua các truy vấn ngôn ngữ tự nhiên trong vòng chưa đầy 10 giây (theo quan sát trong các thử nghiệm tải tác nhân).
Trong bài viết này, chúng tôi trình bày cách xây dựng các hệ thống trí tuệ thống nhất bằng cách sử dụng Amazon Bedrock AgentCore thông qua việc triển khai CAKE trong thực tế của chúng tôi. Bạn có thể xây dựng các tác nhân tùy chỉnh để mở khóa các tính năng và lợi ích sau:
- Điều phối các công cụ chuyên biệt thông qua phân tích ý định động và thực thi song song
- Tích hợp các kho dữ liệu được xây dựng có mục đích (Neptune, DynamoDB, OpenSearch Service) với điều phối song song
- Triển khai bảo mật cấp hàng (row-level security) và quản trị trong các quy trình làm việc
- Các thực hành kỹ thuật sản xuất để đảm bảo độ tin cậy, bao gồm báo cáo dựa trên mẫu để tuân thủ ngữ nghĩa và phong cách kinh doanh
- Tối ưu hóa hiệu suất thông qua tính linh hoạt của mô hình
Các mẫu kiến trúc này có thể giúp bạn tăng tốc phát triển cho các trường hợp sử dụng khác nhau, bao gồm hệ thống trí tuệ khách hàng, trợ lý AI doanh nghiệp hoặc hệ thống đa tác nhân phối hợp trên các nguồn dữ liệu khác nhau.
Tại sao các hệ thống trí tuệ khách hàng cần sự thống nhất
Khi các tổ chức bán hàng mở rộng quy mô toàn cầu, họ thường đối mặt với ba thách thức quan trọng: dữ liệu phân mảnh trên các công cụ chuyên biệt (đề xuất sản phẩm, bảng điều khiển tương tác, phân tích doanh thu, v.v.) đòi hỏi hàng giờ để thu thập cái nhìn toàn diện về khách hàng, mất ngữ nghĩa kinh doanh trong các cơ sở dữ liệu truyền thống không thể nắm bắt các mối quan hệ ngữ nghĩa giải thích tại sao các chỉ số lại quan trọng, và các quy trình hợp nhất thủ công không thể mở rộng theo khối lượng dữ liệu ngày càng tăng. Bạn cần một hệ thống thống nhất có thể tổng hợp dữ liệu khách hàng, hiểu các mối quan hệ ngữ nghĩa và suy luận về nhu cầu của khách hàng trong bối cảnh kinh doanh, biến CAKE thành xương sống thiết yếu cho các doanh nghiệp ở mọi nơi.
Tổng quan giải pháp
CAKE là một tác nhân trò chuyện lấy khách hàng làm trung tâm, biến dữ liệu phân mảnh thành trí tuệ thống nhất, có thể hành động. Bằng cách hợp nhất các nguồn/bảng dữ liệu nội bộ và bên ngoài vào một điểm cuối hội thoại duy nhất, CAKE cung cấp thông tin chi tiết cá nhân hóa về khách hàng được hỗ trợ bởi các biểu đồ tri thức giàu ngữ cảnh—tất cả chỉ trong vòng chưa đầy 10 giây. Không giống như các công cụ truyền thống chỉ báo cáo số liệu, nền tảng ngữ nghĩa của CAKE nắm bắt ý nghĩa và mối quan hệ giữa các chỉ số kinh doanh, hành vi khách hàng, động lực ngành và bối cảnh chiến lược. Điều này cho phép CAKE giải thích không chỉ điều gì đang xảy ra với khách hàng, mà còn tại sao nó xảy ra và cách thức hành động.
Amazon Bedrock AgentCore cung cấp cơ sở hạ tầng thời gian chạy mà các hệ thống AI đa tác nhân yêu cầu dưới dạng dịch vụ được quản lý, bao gồm giao tiếp giữa các tác nhân, thực thi song song, theo dõi trạng thái hội thoại và định tuyến công cụ. Điều này giúp các nhóm tập trung vào việc xác định hành vi tác nhân và logic kinh doanh thay vì triển khai cơ sở hạ tầng hệ thống phân tán.
Đối với CAKE, chúng tôi đã xây dựng một tác nhân tùy chỉnh trên Amazon Bedrock AgentCore để điều phối năm công cụ chuyên biệt, mỗi công cụ được tối ưu hóa cho các mẫu truy cập dữ liệu khác nhau:
- Công cụ truy xuất Neptune cho các truy vấn mối quan hệ biểu đồ
- Tác nhân DynamoDB để tra cứu chỉ số tức thì
- Công cụ truy xuất OpenSearch cho tìm kiếm tài liệu ngữ nghĩa
- Công cụ tìm kiếm web cho thông tin tình báo ngành bên ngoài
- Công cụ bảo mật cấp hàng (RLS) để thực thi bảo mật
Sơ đồ sau đây cho thấy cách Amazon Bedrock AgentCore hỗ trợ điều phối các thành phần này.
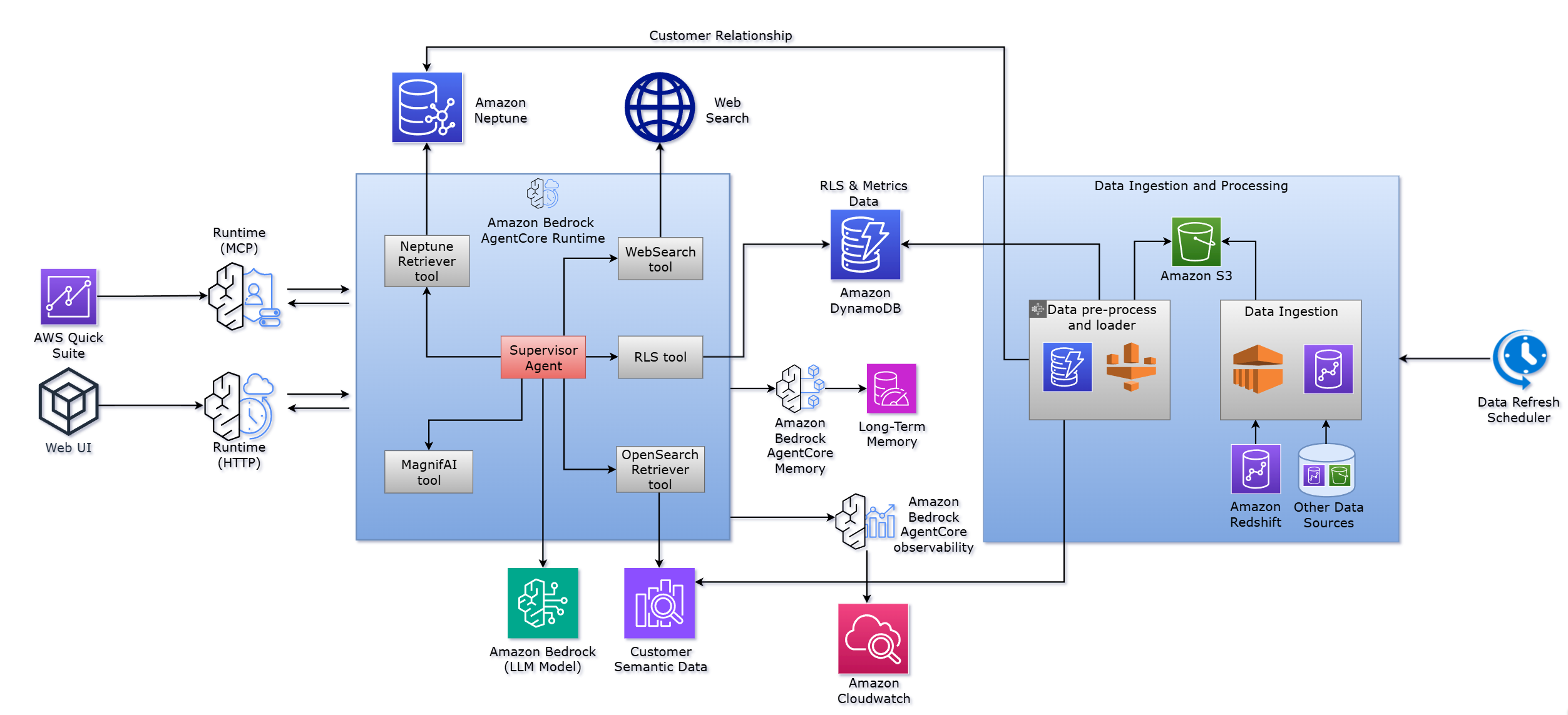
Giải pháp trải qua một số giai đoạn chính để phản hồi một câu hỏi (ví dụ: “Cơ hội mở rộng hàng đầu cho khách hàng này là gì?”):
- Phân tích ý định và định tuyến truy vấn – Tác nhân giám sát, chạy trên Amazon Bedrock AgentCore, phân tích truy vấn ngôn ngữ tự nhiên để xác định ý định của nó. Câu hỏi yêu cầu hiểu biết về khách hàng, dữ liệu mối quan hệ, chỉ số sử dụng và thông tin chi tiết chiến lược. Logic gọi công cụ của tác nhân, sử dụng Amazon Bedrock AgentCore Runtime, xác định các công cụ chuyên biệt nào cần kích hoạt.
- Điều phối công cụ song song – Thay vì thực thi các lệnh gọi công cụ tuần tự, lớp điều phối điều phối nhiều công cụ truy xuất song song, sử dụng môi trường thực thi có thể mở rộng của Amazon Bedrock AgentCore Runtime. Tác nhân quản lý vòng đời thực thi, xử lý thời gian chờ, thử lại và các điều kiện lỗi tự động.
- Tổng hợp nhiều kết quả – Khi các công cụ chuyên biệt trả về kết quả, Amazon Bedrock AgentCore truyền các phản hồi một phần này đến tác nhân giám sát, tác nhân này tổng hợp chúng thành một câu trả lời mạch lạc. Tác nhân suy luận về cách các nguồn dữ liệu khác nhau liên quan đến nhau, xác định các mẫu và tạo ra thông tin chi tiết trải rộng trên nhiều miền tri thức.
- Thực thi ranh giới bảo mật – Trước khi bắt đầu truy xuất dữ liệu, tác nhân gọi công cụ RLS để thực thi quyền người dùng một cách xác định. Tác nhân tùy chỉnh sau đó xác minh rằng các lệnh gọi công cụ tiếp theo tuân thủ các ranh giới bảo mật này, tự động lọc kết quả và giúp ngăn chặn truy cập dữ liệu trái phép. Lớp bảo mật này hoạt động ở cấp độ cơ sở hạ tầng, giảm nguy cơ lỗi triển khai.
Kiến trúc này hoạt động trên hai luồng song song: Amazon Bedrock AgentCore cung cấp thời gian chạy cho lớp phục vụ thời gian thực phản hồi các truy vấn của người dùng với độ trễ tối thiểu, và một đường ống dữ liệu ngoại tuyến định kỳ làm mới các kho dữ liệu cơ bản từ kho dữ liệu phân tích. Trong các phần sau, chúng tôi thảo luận về thiết kế khung tác nhân và các thành phần giải pháp cốt lõi, bao gồm biểu đồ tri thức, kho dữ liệu và đường ống dữ liệu.
Thiết kế khung tác nhân
Hệ thống đa tác nhân của chúng tôi tận dụng khung AWS Strands Agents để cung cấp khả năng suy luận có cấu trúc trong khi vẫn duy trì các kiểm soát cấp doanh nghiệp cần thiết cho việc tuân thủ quy định và hiệu suất dự đoán được. Hệ thống đa tác nhân được xây dựng trên khung AWS Strands Agents, cung cấp nền tảng dựa trên mô hình để xây dựng các tác nhân từ nhiều mô hình khác nhau. Tác nhân giám sát phân tích các câu hỏi đến để lựa chọn thông minh các tác nhân và công cụ chuyên biệt nào cần gọi và cách phân tách các truy vấn của người dùng. Khung này hiển thị trạng thái và đầu ra của tác nhân để triển khai đánh giá phi tập trung ở cả cấp tác nhân và giám sát. Dựa trên phương pháp tiếp cận dựa trên mô hình, chúng tôi triển khai suy luận tác nhân thông qua các chuỗi suy luận GraphRAG xây dựng các đường dẫn suy luận xác định bằng cách duyệt qua các mối quan hệ tri thức. Các tác nhân của chúng tôi thực hiện suy luận tự động trong các miền chuyên biệt của chúng, dựa trên các bản thể học được xác định trước trong khi vẫn duy trì các mẫu hành vi có thể dự đoán được và có thể kiểm toán được yêu cầu cho các ứng dụng doanh nghiệp.
Tác nhân giám sát sử dụng một giao thức lựa chọn đa giai đoạn:
- Phân tích câu hỏi – Phân tích cú pháp và hiểu ý định của người dùng
- Lựa chọn nguồn – Định tuyến thông minh xác định sự kết hợp các công cụ cần thiết
- Phân tách truy vấn – Các câu hỏi gốc được chia thành các câu hỏi phụ chuyên biệt được tối ưu hóa cho từng công cụ được chọn
- Thực thi song song – Các công cụ được chọn thực thi đồng thời thông qua các nhóm hành động AWS Lambda phi máy chủ
Các công cụ được hiển thị thông qua một mẫu cấu trúc phân cấp (tính đến phương thức dữ liệu—có cấu trúc so với không có cấu trúc) nơi các tác nhân và công cụ cấp cao điều phối nhiều công cụ phụ chuyên biệt:
- Công cụ suy luận biểu đồ – Quản lý việc duyệt thực thể, phân tích mối quan hệ và trích xuất tri thức
- Tác nhân thông tin chi tiết khách hàng – Điều phối nhiều mô hình được tinh chỉnh song song để tạo tóm tắt khách hàng từ các bảng
- Công cụ tìm kiếm ngữ nghĩa – Điều phối phân tích văn bản không có cấu trúc (chẳng hạn như ghi chú thực địa)
- Công cụ nghiên cứu web – Điều phối truy xuất web/tin tức
Chúng tôi mở rộng khung AWS Strands Agents cốt lõi với các khả năng cấp doanh nghiệp bao gồm xác thực quyền truy cập của khách hàng, tối ưu hóa token, lựa chọn LLM đa bước để tăng khả năng phục hồi khi bị điều tiết mô hình và các chuỗi suy luận GraphRAG có cấu trúc. Các phần mở rộng này mang lại khả năng ra quyết định tự động của các hệ thống tác nhân hiện đại đồng thời tạo điều kiện cho hiệu suất có thể dự đoán được và sự phù hợp với quy định.
Xây dựng nền tảng biểu đồ tri thức
Biểu đồ tri thức của CAKE trong Neptune đại diện cho các mối quan hệ khách hàng, các mẫu sử dụng sản phẩm và động lực ngành dưới dạng cấu trúc, cho phép các tác nhân AI thực hiện suy luận hiệu quả. Không giống như các cơ sở dữ liệu truyền thống lưu trữ thông tin một cách riêng lẻ, biểu đồ tri thức của CAKE nắm bắt ý nghĩa ngữ nghĩa của các thực thể kinh doanh và các mối quan hệ của chúng.
Xây dựng biểu đồ và mô hình hóa thực thể
Chúng tôi đã thiết kế biểu đồ tri thức xoay quanh bản thể học bán hàng của AWS—các thực thể và mối quan hệ cốt lõi mà các nhóm bán hàng thảo luận hàng ngày:
- Thực thể khách hàng – Với các thuộc tính được trích xuất từ các nguồn dữ liệu bao gồm phân loại ngành, chỉ số doanh thu, giai đoạn áp dụng đám mây và điểm tương tác
- Thực thể sản phẩm – Đại diện cho các dịch vụ AWS, với các kết nối đến các trường hợp sử dụng, ứng dụng ngành và các mẫu áp dụng của khách hàng
- Thực thể giải pháp – Liên kết các sản phẩm với kết quả kinh doanh và các sáng kiến chiến lược
- Thực thể cơ hội – Theo dõi kênh bán hàng, các giai đoạn giao dịch và các bên liên quan
- Thực thể liên hệ – Ánh xạ các mạng lưới mối quan hệ trong các tổ chức khách hàng
Amazon Neptune vượt trội trong việc trả lời các câu hỏi yêu cầu hiểu các kết nối—tìm cách hai thực thể liên quan đến nhau, xác định đường dẫn giữa các tài khoản hoặc khám phá các mối quan hệ gián tiếp trải dài nhiều bước nhảy. Quá trình xây dựng dữ liệu ngoại tuyến chạy các truy vấn theo lịch trình đối với các cụm Redshift để chuẩn bị dữ liệu được tải vào biểu đồ.
Nắm bắt ngữ cảnh mối quan hệ
Biểu đồ tri thức của CAKE nắm bắt cách các mối quan hệ kết nối các thực thể. Khi biểu đồ kết nối một khách hàng với một sản phẩm thông qua mối quan hệ sử dụng tăng lên, nó cũng lưu trữ các thuộc tính ngữ cảnh: tốc độ tăng, động lực kinh doanh (từ kế hoạch tài khoản) và các mẫu áp dụng sản phẩm liên quan. Sự phong phú về ngữ cảnh này giúp LLM hiểu bối cảnh kinh doanh và cung cấp các giải thích dựa trên các mối quan hệ thực tế chứ không chỉ dựa vào tương quan thống kê.
Kho dữ liệu được xây dựng có mục đích
Thay vì lưu trữ dữ liệu trong một cơ sở dữ liệu duy nhất, CAKE sử dụng các kho dữ liệu chuyên biệt, mỗi kho được thiết kế cho cách nó được truy vấn. Tác nhân tùy chỉnh của chúng tôi, chạy trên Amazon Bedrock AgentCore, quản lý sự điều phối giữa các kho này—gửi truy vấn đến đúng cơ sở dữ liệu, chạy chúng cùng lúc và kết hợp các kết quả—để cả người dùng và nhà phát triển đều làm việc với thứ mà họ cảm thấy như một nguồn dữ liệu duy nhất:
- Neptune cho các mối quan hệ biểu đồ – Neptune lưu trữ mạng lưới kết nối giữa khách hàng, tài khoản, các bên liên quan và các thực thể tổ chức. Neptune vượt trội trong các truy vấn duyệt đa bước yêu cầu các phép nối tốn kém trong các cơ sở dữ liệu quan hệ—tìm đường dẫn mối quan hệ giữa các tài khoản không được kết nối, hoặc khám phá khách hàng trong một ngành đã áp dụng các dịch vụ AWS cụ thể. Khi Amazon Bedrock AgentCore xác định một truy vấn yêu cầu suy luận mối quan hệ, nó sẽ tự động định tuyến đến công cụ truy xuất Neptune.
- DynamoDB cho các chỉ số tức thì – DynamoDB hoạt động như một kho khóa-giá trị cho các tổng hợp được tính toán trước. Thay vì tính toán điểm sức khỏe khách hàng hoặc chỉ số tương tác theo yêu cầu, đường ống ngoại tuyến tính toán trước các giá trị này và lưu trữ chúng được lập chỉ mục theo ID khách hàng. DynamoDB sau đó cung cấp các tra cứu dưới 10ms, cho phép tạo báo cáo tức thì. Chuỗi công cụ trong Amazon Bedrock AgentCore cho phép nó truy xuất các chỉ số từ DynamoDB, chuyển chúng đến tác nhân magnifAI (tác nhân chuyển đổi bảng thành văn bản tùy chỉnh của chúng tôi) để định dạng và trả về các báo cáo đã được trau chuốt—tất cả mà không cần mã tích hợp tùy chỉnh.
- OpenSearch Service cho tìm kiếm tài liệu ngữ nghĩa – OpenSearch Service lưu trữ nội dung không có cấu trúc như kế hoạch tài khoản và ghi chú thực địa. Sử dụng các mô hình nhúng, OpenSearch Service chuyển đổi văn bản thành các biểu diễn vector hỗ trợ khớp ngữ nghĩa. Ví dụ, khi Amazon Bedrock AgentCore nhận được một truy vấn về “chuyển đổi kỹ thuật số”, nó nhận ra nhu cầu tìm kiếm ngữ nghĩa và tự động định tuyến đến công cụ truy xuất OpenSearch Service, công cụ này tìm thấy các đoạn văn liên quan ngay cả khi tài liệu sử dụng thuật ngữ khác.
- S3 để lưu trữ tài liệu – Amazon Simple Storage Service (Amazon S3) cung cấp nền tảng cho OpenSearch Service. Kế hoạch tài khoản được lưu trữ dưới dạng tệp Parquet trong Amazon S3 trước khi được lập chỉ mục vì kho dữ liệu nguồn (Amazon Redshift) có giới hạn cắt bớt có thể cắt bỏ các tài liệu lớn. Quá trình nhiều bước này—lưu trữ Amazon S3, tạo nhúng, lập chỉ mục OpenSearch Service—bảo toàn nội dung hoàn chỉnh trong khi vẫn duy trì độ trễ thấp cần thiết cho các truy vấn thời gian thực.
Building on Amazon Bedrock AgentCore makes these multi-database queries feel like a single, unified data source. When a query requires customer relationships from Neptune, metrics from DynamoDB, and document context from OpenSearch Service, our agent automatically dispatches requests to all three in parallel, manages their execution, and synthesizes their results into a single coherent response.
Đường ống dữ liệu và làm mới liên tục
Đường ống dữ liệu ngoại tuyến của CAKE hoạt động như một quy trình hàng loạt chạy theo lịch trình để giữ cho lớp phục vụ được đồng bộ hóa với dữ liệu kinh doanh mới nhất. Kiến trúc đường ống tách biệt việc xây dựng dữ liệu khỏi việc phục vụ dữ liệu, do đó lớp truy vấn thời gian thực có thể duy trì độ trễ thấp trong khi đường ống hàng loạt xử lý các tổng hợp và xây dựng biểu đồ tốn nhiều tính toán.
Lớp Điều phối Xử lý Dữ liệu điều phối các phép biến đổi trên nhiều cơ sở dữ liệu đích. Đối với mỗi cơ sở dữ liệu, đường ống thực hiện các bước sau:
- Trích xuất dữ liệu liên quan từ Amazon Redshift bằng cách sử dụng các truy vấn được tối ưu hóa
- Áp dụng các phép biến đổi logic nghiệp vụ cụ thể cho yêu cầu của từng kho dữ liệu
- Tải dữ liệu đã xử lý vào cơ sở dữ liệu đích với các chỉ mục và phân vùng thích hợp
Đối với Neptune, điều này liên quan đến việc trích xuất dữ liệu thực thể, xây dựng các nút và cạnh biểu đồ với các thuộc tính, và tải cấu trúc biểu đồ với các loại mối quan hệ ngữ nghĩa. Đối với DynamoDB, đường ống tính toán các tổng hợp và chỉ số, cấu trúc dữ liệu dưới dạng cặp khóa-giá trị được tối ưu hóa cho việc tra cứu ID khách hàng, và áp dụng các cập nhật nguyên tử để duy trì tính nhất quán. Đối với OpenSearch Service, đường ống tuân theo một đường dẫn chuyên biệt: các tài liệu lớn trước tiên được xuất từ Amazon Redshift sang Amazon S3 dưới dạng tệp Parquet, sau đó được xử lý thông qua các mô hình nhúng để tạo ra các biểu diễn vector, cuối cùng được tải vào chỉ mục OpenSearch Service với siêu dữ liệu thích hợp để lọc và truy xuất.
Kỹ thuật cho sản xuất: Độ tin cậy và độ chính xác
Khi chuyển đổi CAKE từ nguyên mẫu sang sản xuất, chúng tôi đã triển khai một số thực hành kỹ thuật quan trọng để tạo điều kiện cho độ tin cậy, độ chính xác và sự tin cậy vào thông tin chi tiết do AI tạo ra.
Tính linh hoạt của mô hình
Kiến trúc Amazon Bedrock AgentCore tách rời lớp điều phối khỏi LLM cơ bản, cho phép lựa chọn mô hình linh hoạt. Chúng tôi đã triển khai tính năng chuyển đổi mô hình (model hopping) để cung cấp khả năng tự động dự phòng sang các mô hình thay thế khi xảy ra tình trạng điều tiết. Khả năng phục hồi này diễn ra minh bạch trong AgentCore Runtime—phát hiện các điều kiện điều tiết, định tuyến yêu cầu đến các mô hình có sẵn và duy trì chất lượng phản hồi mà không làm giảm trải nghiệm người dùng.
Bảo mật cấp hàng (RLS) và Quản trị dữ liệu
Trước khi truy xuất dữ liệu, công cụ RLS thực thi bảo mật cấp hàng dựa trên danh tính người dùng và hệ thống phân cấp tổ chức. Lớp bảo mật này hoạt động minh bạch đối với người dùng trong khi vẫn duy trì quản trị dữ liệu nghiêm ngặt:
- Đại diện bán hàng chỉ truy cập khách hàng được chỉ định cho khu vực của họ
- Quản lý khu vực xem dữ liệu tổng hợp trên các khu vực của họ
- Các giám đốc điều hành có tầm nhìn rộng hơn phù hợp với trách nhiệm của họ
Công cụ RLS định tuyến các truy vấn đến các phân vùng dữ liệu thích hợp và áp dụng các bộ lọc ở cấp độ truy vấn cơ sở dữ liệu, do đó bảo mật có thể được thực thi ở lớp dữ liệu thay vì dựa vào lọc cấp ứng dụng.
Kết quả và tác động
CAKE đã thay đổi cách các nhóm bán hàng của AWS truy cập và hành động dựa trên thông tin tình báo khách hàng. Bằng cách cung cấp quyền truy cập tức thì vào thông tin chi tiết thống nhất thông qua các truy vấn ngôn ngữ tự nhiên, CAKE giảm thời gian tìm kiếm thông tin từ hàng giờ xuống còn vài giây theo khảo sát/phản hồi từ người dùng, giúp các đại diện bán hàng tập trung vào tương tác chiến lược với khách hàng thay vì thu thập dữ liệu.
Kiến trúc đa tác nhân cung cấp phản hồi truy vấn trong vài giây cho hầu hết các truy vấn, với mô hình thực thi song song hỗ trợ truy xuất dữ liệu đồng thời từ nhiều nguồn. Biểu đồ tri thức cho phép suy luận phức tạp vượt xa việc tổng hợp dữ liệu đơn giản—CAKE giải thích tại sao các xu hướng xảy ra, xác định các mẫu trên các điểm dữ liệu dường như không liên quan và tạo ra các khuyến nghị dựa trên các mối quan hệ kinh doanh. Có lẽ quan trọng nhất, CAKE dân chủ hóa quyền truy cập vào thông tin tình báo khách hàng trong toàn tổ chức. Đại diện bán hàng, quản lý tài khoản, kiến trúc sư giải pháp và giám đốc điều hành tương tác với cùng một hệ thống thống nhất, cung cấp thông tin chi tiết khách hàng nhất quán trong khi vẫn duy trì các kiểm soát bảo mật và truy cập thích hợp.
Kết luận
Trong bài viết này, chúng tôi đã trình bày cách Amazon Bedrock AgentCore hỗ trợ kiến trúc đa tác nhân của CAKE. Xây dựng các hệ thống AI đa tác nhân theo truyền thống đòi hỏi đầu tư cơ sở hạ tầng đáng kể, bao gồm triển khai các giao thức điều phối tác nhân tùy chỉnh, quản lý các khung thực thi song song, theo dõi trạng thái hội thoại, xử lý các chế độ lỗi và xây dựng các lớp thực thi bảo mật. Amazon Bedrock AgentCore giảm bớt gánh nặng không khác biệt này bằng cách cung cấp các khả năng này dưới dạng dịch vụ được quản lý trong Amazon Bedrock.
Amazon Bedrock AgentCore cung cấp cơ sở hạ tầng thời gian chạy cho việc điều phối, và các kho dữ liệu chuyên biệt vượt trội trong các mẫu truy cập cụ thể của chúng. Neptune xử lý việc duyệt mối quan hệ, DynamoDB cung cấp tra cứu chỉ số tức thì, và OpenSearch Service hỗ trợ tìm kiếm tài liệu ngữ nghĩa, nhưng tác nhân tùy chỉnh của chúng tôi, được xây dựng trên Amazon Bedrock AgentCore, điều phối các thành phần này, tự động định tuyến các truy vấn đến đúng công cụ, thực thi chúng song song, tổng hợp kết quả của chúng và duy trì các ranh giới bảo mật trong suốt quy trình làm việc. Trải nghiệm CAKE chứng minh cách Amazon Bedrock AgentCore có thể giúp các nhóm xây dựng hệ thống AI đa tác nhân, tăng tốc quá trình từ hàng tháng phát triển cơ sở hạ tầng xuống còn vài tuần triển khai logic kinh doanh. Bằng cách cung cấp cơ sở hạ tầng điều phối dưới dạng dịch vụ được quản lý, Amazon Bedrock AgentCore giúp các nhóm tập trung vào chuyên môn miền và giá trị khách hàng thay vì xây dựng cơ sở hạ tầng hệ thống phân tán từ đầu.
Để tìm hiểu thêm về Amazon Bedrock AgentCore và xây dựng các hệ thống AI đa tác nhân, hãy tham khảo Hướng dẫn sử dụng Amazon Bedrock, Workshop Amazon Bedrock, và Tác nhân Amazon Bedrock. Để biết tin tức mới nhất về AWS, hãy xem Có gì mới với AWS.
Lời cảm ơn
Chúng tôi xin gửi lời cảm ơn chân thành đến các nhà tài trợ điều hành và cố vấn của chúng tôi, những người có tầm nhìn và sự hướng dẫn đã giúp sáng kiến này thành hiện thực: Aizaz Manzar, Giám đốc AWS Global Sales; Ali Imam, Trưởng bộ phận Startup Segment; và Akhand Singh, Trưởng bộ phận Kỹ thuật Dữ liệu.
Chúng tôi cũng cảm ơn các thành viên tận tâm trong nhóm, những người có chuyên môn kỹ thuật và đóng góp đã đóng vai trò quan trọng trong việc đưa sản phẩm này vào cuộc sống: Aswin Palliyali Venugopalan, Giám đốc Phát triển Phần mềm; Alok Singh, Kỹ sư Phát triển Phần mềm Cấp cao; Muruga Manoj Gnanakrishnan, Kỹ sư Dữ liệu Chính; Sai Meka, Kỹ sư Học máy; Bill Tran, Kỹ sư Dữ liệu; và Rui Li, Nhà khoa học Ứng dụng.
Về tác giả

Monica Jain là Giám đốc Sản phẩm Kỹ thuật Cấp cao tại AWS Global Sales và là một chuyên gia phân tích thúc đẩy thông tin tình báo bán hàng được hỗ trợ bởi AI ở quy mô lớn. Cô dẫn đầu việc phát triển các sản phẩm dữ liệu được hỗ trợ bởi AI tạo sinh và ML—bao gồm biểu đồ tri thức, phân tích tăng cường AI, hệ thống truy vấn ngôn ngữ tự nhiên và công cụ đề xuất, giúp cải thiện năng suất người bán và ra quyết định. Công việc của cô cho phép các giám đốc điều hành và người bán của AWS trên toàn thế giới truy cập thông tin chi tiết theo thời gian thực và tăng tốc tương tác với khách hàng dựa trên dữ liệu cũng như tăng trưởng doanh thu.

M. Umar Javed là Nhà khoa học Ứng dụng Cấp cao tại AWS, với hơn 8 năm kinh nghiệm trong giới học thuật và công nghiệp cùng bằng Tiến sĩ về lý thuyết ML. Tại AWS, anh xây dựng các giải pháp AI tạo sinh và học máy cấp sản xuất, với công việc trải rộng trên các kiến trúc LLM đa tác nhân, nghiên cứu về các mô hình ngôn ngữ nhỏ, biểu đồ tri thức, hệ thống đề xuất, học tăng cường và học sâu đa phương thức. Trước khi gia nhập AWS, Umar đã đóng góp vào nghiên cứu ML tại NREL, CISCO, Oxford và UCSD. Anh là người nhận Giải thưởng Xuất sắc ECEE (2021) và đã đóng góp vào hai Giải thưởng Donald P. Eckman (2021, 2023).

Damien Forthomme là Nhà khoa học Ứng dụng Cấp cao tại AWS, dẫn dắt một nhóm Khoa học Dữ liệu trong AWS Sales, Marketing, and Global Services (SMGS). Với hơn 10 năm kinh nghiệm và bằng Tiến sĩ Vật lý, anh tập trung vào việc sử dụng và xây dựng các công cụ học máy và AI tạo sinh tiên tiến để đưa dữ liệu phù hợp đến đúng người vào đúng thời điểm. Công việc của anh bao gồm các sáng kiến như dự báo, hệ thống đề xuất, tạo bộ dữ liệu nền tảng cốt lõi và xây dựng các sản phẩm AI tạo sinh giúp tăng cường năng suất bán hàng cho tổ chức.

Mihir Gadgil là Kỹ sư Dữ liệu Cấp cao trong AWS Sales, Marketing, and Global Services (SMGS), chuyên về các giải pháp dữ liệu quy mô doanh nghiệp và ứng dụng AI tạo sinh. Với hơn 9 năm kinh nghiệm và bằng Thạc sĩ về Công nghệ & Quản lý Thông tin, anh tập trung vào việc xây dựng các đường ống dữ liệu mạnh mẽ, mô hình hóa dữ liệu phức tạp và các quy trình ETL/ELT. Chuyên môn của anh thúc đẩy chuyển đổi kinh doanh thông qua các giải pháp kỹ thuật dữ liệu đổi mới và khả năng phân tích nâng cao.

Sujit Narapareddy, Trưởng bộ phận Dữ liệu & Phân tích tại AWS Global Sales, là một nhà lãnh đạo công nghệ thúc đẩy chuyển đổi doanh nghiệp toàn cầu. Anh dẫn dắt các nhóm sản phẩm và nền tảng dữ liệu cung cấp sức mạnh cho chiến lược Go-to-Market của AWS thông qua phân tích tăng cường AI và tự động hóa thông minh. Với thành tích đã được chứng minh trong các giải pháp doanh nghiệp, anh đã chuyển đổi năng suất bán hàng, quản trị dữ liệu và xuất sắc trong vận hành. Trước đây tại JPMorgan Chase Business Banking, anh đã định hình các khả năng FinTech thế hệ tiếp theo thông qua đổi mới dữ liệu.

Norman Braddock, Giám đốc Cấp cao Quản lý Sản phẩm AI tại AWS, là một nhà lãnh đạo sản phẩm thúc đẩy chuyển đổi thông tin tình báo kinh doanh thông qua AI tác nhân. Anh dẫn dắt nhóm Quản lý Sản phẩm Phân tích & Thông tin chi tiết trong Sales, Marketing, and Global Services (SMGS), cung cấp các sản phẩm kết nối hiệu suất mô hình AI với tác động kinh doanh có thể đo lường được. Với nền tảng trải rộng từ mua sắm, sản xuất và vận hành bán hàng, anh kết hợp chuyên môn vận hành sâu sắc với đổi mới sản phẩm để định hình tương lai của quản lý kinh doanh tự động.
