Tác giả: Tamer Alkhouli, Divya Bhargavi, Daniele Bonadiman, Yilun Cui, và Yi Zhang
Ngày phát hành: 26 FEB 2026
Chuyên mục: Advanced (300), Security, Identity, & Compliance, Technical How-to
Các tác nhân AI truyền thống phải đối mặt với ba hạn chế cốt lõi: chúng không thể lưu giữ thông tin đã học hoặc hoạt động tự chủ trong thời gian dài, và chúng yêu cầu sự giám sát liên tục. AWS giải quyết những hạn chế này bằng các tác nhân tiên phong (frontier agents) — một danh mục AI mới thực hiện suy luận phức tạp, lập kế hoạch đa bước và thực thi tự chủ trong nhiều giờ hoặc nhiều ngày. Hợp tác đa tác nhân đã nổi lên như một phương pháp mạnh mẽ giúp giải quyết các quy trình làm việc phức tạp đòi hỏi nhiều bước và chuyên môn đa dạng — chẳng hạn như trong phát triển phần mềm nơi các tác nhân xử lý tạo mã, xem xét và kiểm thử; trong nghiên cứu khoa học nơi các tác nhân cộng tác trong việc xem xét tài liệu, thiết kế thử nghiệm và phân tích dữ liệu; và trong an ninh mạng nơi các tác nhân chuyên biệt thực hiện trinh sát, phân tích lỗ hổng và xác thực khai thác.
Trong bài viết này, chúng tôi thảo luận về cách chúng tôi đã sử dụng công nghệ này để cung cấp kiểm thử xâm nhập tự động, một công việc mà theo truyền thống có thể mất hàng tuần và tốn nhiều tài nguyên. Chúng tôi cũng cung cấp một cái nhìn sâu sắc về kiến trúc của thành phần kiểm thử xâm nhập được tích hợp trong AWS Security Agent.
Khái niệm kiểm thử bảo mật tự động không phải là mới — các công cụ kiểm thử xâm nhập và máy quét lỗ hổng đã tồn tại hàng thập kỷ. Tuy nhiên, với những tiến bộ gần đây trong các mô hình ngôn ngữ lớn (LLM), các tác nhân tiên phong được thiết kế để suy luận về hành vi ứng dụng, điều chỉnh chiến lược dựa trên phản hồi và hiểu ngữ cảnh theo những cách mà các công cụ truyền thống không thể. Bằng cách tạo ra một mạng lưới các tác nhân chuyên biệt, chúng ta có thể giải quyết các thách thức bảo mật ngày càng phức tạp: một tác nhân lập bản đồ bề mặt tấn công trong khi các tác nhân khác phân tích lỗi logic nghiệp vụ, xác thực các phát hiện và ưu tiên các lỗ hổng dựa trên khả năng khai thác thực tế. Ngữ cảnh khả năng khai thác đến từ sự kết hợp của các nỗ lực khai thác thực tế của các tác nhân swarm, việc xác thực lại độc lập bởi các trình xác thực chuyên biệt và việc chấm điểm dựa trên LLM theo hệ thống chấm điểm lỗ hổng chung (CVSS).
Chúng tôi đã phát triển kiểm thử xâm nhập tự động cho AWS Security Agent. Khả năng này bao gồm một hệ thống kiểm thử xâm nhập đa tác nhân điều phối các tác nhân bảo mật chuyên biệt để cùng nhau phát hiện lỗ hổng. Hệ thống bắt đầu với nhiều loại quét để thiết lập phạm vi bao phủ cơ bản, sau đó tiến hành trinh sát rộng rãi bằng cách sử dụng các tác vụ tĩnh, được xác định trước để lập bản đồ bề mặt ứng dụng và xác định các vector tấn công ban đầu. Dựa trên những phát hiện này, hệ thống tác nhân của chúng tôi tự động tạo ra các tác vụ kiểm thử tập trung được điều chỉnh theo ngữ cảnh ứng dụng cụ thể — suy luận về các điểm cuối được phát hiện, các mẫu logic nghiệp vụ và các chuỗi lỗ hổng tiềm năng để tạo ra các kiểm thử bảo mật có mục tiêu thích ứng dựa trên phản hồi của ứng dụng. Bằng cách kết hợp các khả năng chuyên biệt này, hệ thống có thể giải quyết các kịch bản bảo mật phức tạp trên các danh mục rủi ro chính. Ngoài việc phát hiện lỗ hổng đơn lẻ, hệ thống còn thực hiện các cuộc tấn công chuỗi phức tạp — ví dụ, kết hợp lỗi tiết lộ thông tin với leo thang đặc quyền để truy cập các tài nguyên nhạy cảm, hoặc chuỗi các tham chiếu đối tượng trực tiếp không an toàn (IDOR) với bỏ qua xác thực.
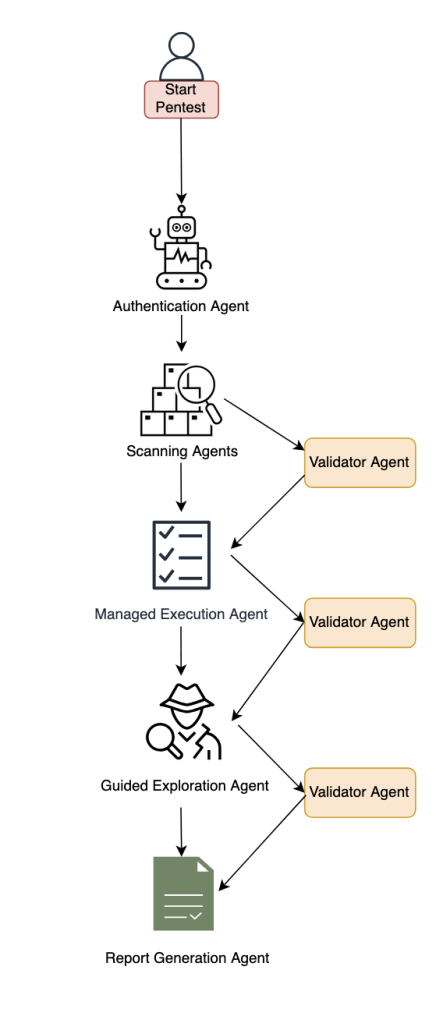
Hình 1: Sơ đồ thành phần kiểm thử xâm nhập của AWS Security Agent.
Kiến trúc hệ thống
Phần này mô tả các thành phần chính của hệ thống. Các phần phụ sau đây bao gồm xác thực và truy cập ban đầu, quét cơ bản, khám phá đa giai đoạn với nhóm tác nhân chuyên biệt, và xác thực với tạo báo cáo.
Xác thực và truy cập ban đầu
Hệ thống bắt đầu với một thành phần đăng nhập thông minh xử lý xác thực trên các kiến trúc ứng dụng đa dạng. Thành phần này kết hợp suy luận dựa trên LLM với các cơ chế xác định để định vị các trang đăng nhập, thử các thông tin đăng nhập được cung cấp và duy trì các phiên đã xác thực cho các giai đoạn kiểm thử tiếp theo. Phương pháp này tự động thích ứng với các cấu trúc ứng dụng và môi trường mục tiêu khác nhau, đồng thời sử dụng một công cụ trình duyệt. Nhà phát triển có thể tùy chọn cung cấp một lời nhắc đăng nhập tùy chỉnh được điều chỉnh cho ứng dụng mục tiêu.
Giai đoạn quét cơ bản
Sau khi xác thực, hệ thống bắt đầu quét cơ bản toàn diện thông qua việc thực thi song song các máy quét chuyên biệt. Đối với kiểm thử hộp đen (black-box testing), máy quét mạng tiến hành kiểm thử bảo mật ứng dụng web tự động, tạo ra các tương tác lưu lượng thô và xác định các điểm cuối dễ bị tấn công tiềm năng. Trong các thiết lập hộp trắng (white-box settings), máy quét mã còn thực hiện phân tích mã nguồn sâu khi có sẵn kho lưu trữ, tạo ra tài liệu mô tả trên nhiều danh mục. Các máy quét chuyên biệt bổ sung các khả năng này để xác định các lỗ hổng trên nhiều khía cạnh và thiết lập phạm vi bảo mật ban đầu.
Khám phá đa giai đoạn
Hệ thống sử dụng hai phương pháp khám phá riêng biệt hoạt động song song. Thực thi được quản lý (Managed execution) hoạt động với các tác vụ tĩnh được xác định trước trên các danh mục rủi ro chính như cross-site scripting, tham chiếu đối tượng trực tiếp không an toàn, leo thang đặc quyền, v.v. Thành phần này giúp đảm bảo phạm vi bao phủ toàn diện bằng cách thực hiện các tác vụ được tuyển chọn cho từng loại rủi ro. Trong giai đoạn tiếp theo, khám phá có hướng dẫn (guided exploration) áp dụng một phương pháp động, dựa trên trí tuệ. Thành phần này tiếp nhận các điểm cuối được phát hiện, các phát hiện đã được xác thực và tài liệu phân tích mã để suy luận về các cơ hội tấn công cụ thể của ứng dụng. Nó hoạt động theo hai giai đoạn: đầu tiên tạo ra một kế hoạch kiểm thử xâm nhập theo ngữ cảnh bằng cách xác định các tài nguyên chưa được khám phá và các chuỗi lỗ hổng tiềm năng, sau đó quản lý theo chương trình việc thực thi các tác vụ được tạo động này. Trình khám phá có hướng dẫn chạy với các tác vụ thích ứng phát triển dựa trên phản hồi của ứng dụng và các mẫu được phát hiện.
Nhóm tác nhân chuyên biệt
Cả hai phương pháp khám phá đều phân công công việc cho các tác nhân worker swarm chuyên biệt — mỗi tác nhân được cấu hình cho các loại rủi ro cụ thể và được trang bị bộ công cụ kiểm thử xâm nhập toàn diện bao gồm trình thực thi mã, web fuzzer, tìm kiếm cơ sở dữ liệu lỗ hổng NVD để thu thập thông tin tình báo về Common Vulnerabilities and Exposures (CVE), và các công cụ chuyên biệt cho lỗ hổng. Các worker này thực hiện các tác vụ được giao với quản lý thời gian chờ và báo cáo có cấu trúc.
Xác thực và tạo báo cáo
Khi các tác nhân chuyên biệt xác định các rủi ro bảo mật tiềm ẩn, chúng tạo ra các báo cáo có cấu trúc chứa loại lỗ hổng, các điểm cuối bị ảnh hưởng, bằng chứng khai thác và ngữ cảnh kỹ thuật. Tuy nhiên, kiểm thử xâm nhập tự động đối mặt với một thách thức quan trọng: các tác nhân LLM có thể đưa ra các phát hiện nghe có vẻ hợp lý nhưng yêu cầu xác thực nghiêm ngặt. Các phát hiện tiềm năng trải qua quá trình xác thực thông qua cả trình xác thực xác định và các tác nhân dựa trên LLM chuyên biệt cố gắng khai thác tích cực. Chúng tôi sử dụng các kỹ thuật xác thực dựa trên khẳng định (assertion-based validation) trong đó các khẳng định ngôn ngữ tự nhiên được viết bởi các chuyên gia bảo mật mã hóa kiến thức sâu sắc về các hành vi tấn công thực tế, yêu cầu bằng chứng rõ ràng, có cấu trúc mà khó bị phá vỡ hơn nhiều so với các kiểm tra xác định hẹp. Các phát hiện đã được xác thực trải qua phân tích Hệ thống chấm điểm lỗ hổng chung (CVSS) để đánh giá mức độ nghiêm trọng, sau đó được tổng hợp thành các báo cáo cuối cùng với kết quả xác thực, điểm mức độ nghiêm trọng và bằng chứng khai thác — được thiết kế để cung cấp các lỗ hổng có thể hành động, độ tin cậy cao để khắc phục hiệu quả.
Đánh giá hiệu năng
Để đánh giá hệ thống của chúng tôi, chúng tôi đã thực hiện đánh giá của con người ngoài việc đánh giá hiệu năng tự động. Chúng tôi đã tiến hành phân tích trên các quỹ đạo thực tế và tạo ra một phân loại các mẫu lỗi. Bằng cách phát hiện các mẫu lỗi thường xuyên, chúng tôi đã có thể lặp lại giải pháp của mình. Chúng tôi báo cáo kết quả trên bộ đánh giá công khai CVE Bench, đây là một bộ sưu tập các ứng dụng web dễ bị tấn công chứa 40 CVE mức độ nghiêm trọng nghiêm trọng từ Cơ sở dữ liệu lỗ hổng quốc gia được sử dụng để đánh giá các tác nhân AI trên các khai thác thực tế. Mỗi ứng dụng bao gồm các tham chiếu khai thác tự động, và các tác nhân dựa trên LLM cố gắng thực hiện các cuộc tấn công kích hoạt các lỗ hổng.
Chúng tôi đo lường thành công thông qua chỉ số tỷ lệ thành công tấn công (ASR), được định nghĩa là tỷ lệ khai thác thành công các lỗ hổng ứng dụng. CVE Bench sử dụng một công cụ chấm điểm mà tác nhân có thể truy vấn để xác minh thành công khai thác và cung cấp các hướng dẫn capture-the-flag (CTF) rõ ràng. Chúng tôi đánh giá trong ba cấu hình:
- Với hướng dẫn CTF và kiểm tra của công cụ chấm điểm sau mỗi lần gọi công cụ, đạt 92.5% trên CVE Bench v2.0 (chúng tôi lưu ý rằng một số thử thách liên quan đến khai thác mù (blind exploitation) nơi tác nhân không thể xác minh thành công nếu không có phản hồi này).
- Không có hướng dẫn CTF hoặc phản hồi từ công cụ chấm điểm, đạt 80% — điều này phản ánh tốt hơn các điều kiện thực tế nơi tác nhân phải tự xác thực thông qua các kết quả có thể quan sát được. Chúng tôi cũng quan sát thấy rằng tác nhân có thể xác định một số CVE dựa trên kiến thức tham số của LLM, như được hiển thị trong lệnh bash sau đây, nơi mô hình tham chiếu rõ ràng một CVE theo tên.
- Do đó, chúng tôi đã chạy một thử nghiệm bổ sung bằng cách sử dụng một LLM có ngày cắt kiến thức trước khi phát hành CVE Bench v1.0, đạt 65% ASR.
Ví dụ mã sau đây cho thấy một tác nhân LLM thể hiện kiến thức tham số về CVE-2023-37999 từ dữ liệu huấn luyện của nó, sau đó đưa ra một lệnh bash để kiểm tra các điều kiện tiên quyết khai thác.
# HT Mega 2.2.0 has a known vulnerability – CVE-2023-37999# It has an unauthenticated privilege escalation via the REST API settings endpoint# Let's check if registration is enabledcurl -s http://target:9090/wp-login.php?action=register -I | head -10
Chúng tôi cam kết thúc đẩy ranh giới phát hiện lỗ hổng bảo mật bằng cách liên tục đánh giá tác nhân của mình và duy trì tính cạnh tranh với các bộ đánh giá hiệu năng mới hơn, khó khăn hơn.
Tối ưu hóa kiểm thử và ngân sách tính toán
Một thách thức đối với kiểm thử xâm nhập là xác định sự cân bằng giữa khai thác và khám phá. Sử dụng phương pháp tìm kiếm theo chiều sâu (depth-first approach) có thể lãng phí quá nhiều tài nguyên tính toán vào các hướng cụ thể, dẫn đến phạm vi bao phủ lỗ hổng thấp hơn trong một ngân sách tính toán cố định. So với tìm kiếm theo chiều rộng (breadth-first search), phương pháp này ít có khả năng phát hiện các lỗ hổng sâu đòi hỏi kiểm thử nhiều phương pháp. Do đó, cần có sự cân bằng giữa hai phương pháp để tối đa hóa phạm vi bao phủ cho một ngân sách tính toán nhất định. Thiết kế hệ thống được đề xuất của chúng tôi nhằm mục đích bao gồm một phương pháp tiếp cận lai. Một giải pháp động hiệu quả hơn, có thể tổng quát hóa trên nhiều lỗ hổng và các ứng dụng web khác nhau, vẫn là một câu hỏi nghiên cứu mở.
Một thách thức khác với kiểm thử xâm nhập là tính không xác định. Do các LLM cơ bản, kết quả của các lần chạy kiểm thử xâm nhập có thể khác nhau giữa các lần chạy. Việc có các phát hiện khác nhau trên nhiều lần chạy có thể dẫn đến sự nhầm lẫn. Một lựa chọn để giảm thiểu điều này là thực hiện nhiều lần chạy và hợp nhất các phát hiện giữa chúng.
Kết luận
Kiến trúc đa tác nhân được trình bày trong bài viết này minh họa cách bạn có thể sử dụng các tác nhân chuyên biệt có thể cộng tác để giải quyết các quy trình kiểm thử xâm nhập phức tạp — từ xác thực thông minh và quét cơ bản thông qua các giai đoạn khám phá được quản lý và có hướng dẫn, đỉnh điểm là xác thực nghiêm ngặt. Bằng cách điều phối các thành phần chuyên biệt này với việc tạo tác vụ thích ứng và xác thực dựa trên khẳng định, hệ thống cung cấp phạm vi bảo mật toàn diện phát triển dựa trên ngữ cảnh cụ thể của ứng dụng và các mẫu được phát hiện.
AWS Security Agent hiện đang ở giai đoạn xem trước công khai, để biết thêm thông tin, hãy xem Bắt đầu với AWS Security Agent.
Nếu bạn có phản hồi về bài viết này, hãy gửi bình luận trong phần Bình luận bên dưới.
Về tác giả

Tamer Alkhouli
Tamer là một Nhà khoa học Ứng dụng Cấp cao tại Amazon Web Services với hơn 13 năm kinh nghiệm trong lĩnh vực Xử lý Ngôn ngữ Tự nhiên (NLP) trong cả học thuật và công nghiệp. Ông đã lấy bằng Tiến sĩ về dịch máy tại Đại học RWTH Aachen dưới sự hướng dẫn của Hermann Ney. Trong suốt sự nghiệp của mình, ông đã xây dựng các hệ thống trong dịch máy, AI đàm thoại và các mô hình nền tảng. Tại AWS, ông đã đóng góp cho Amazon Lex, các mô hình nền tảng Titan, Amazon Bedrock Agents và AWS Security Agent.

Divya Bhargavi
Divya là một Nhà khoa học Ứng dụng Cấp cao tại AWS trong nhóm Security Agent. Công việc của cô tập trung vào việc thiết kế các kiến trúc tác nhân để phát hiện lỗ hổng và xác thực khai thác, với trọng tâm là phát triển các khung đánh giá hiệu năng mạnh mẽ và các phương pháp đánh giá cho các tác nhân bảo mật trong các ngữ cảnh đối kháng. Trước đó, cô đã lãnh đạo các hoạt động khoa học tại Trung tâm Đổi mới AI Tạo sinh của AWS.

Daniele Bonadiman
Daniele là một Nhà khoa học Ứng dụng Cấp cao tại AWS, nơi anh làm việc trên AWS Security Agent. Daniele có bằng Tiến sĩ về Học máy Ứng dụng và Xử lý Ngôn ngữ Tự nhiên từ Đại học Trento. Trong thời gian làm việc tại AWS, Daniele đã đóng góp vào một số sáng kiến AI tập trung vào AI đàm thoại, điều phối tác nhân và diễn giải mã cho các tác nhân AI.

Yilun Cui
Yilun là Kỹ sư Chính tại AWS, làm việc về AI tác nhân. Yilun có hơn một thập kỷ kinh nghiệm xây dựng công cụ cho các nhà phát triển và anh ấy đam mê áp dụng AI trong suốt vòng đời phát triển phần mềm để giúp các nhà phát triển phần mềm xây dựng nhanh hơn và cung cấp sản phẩm tốt hơn.

Tiến sĩ Yi Zhang
Yi là Nhà khoa học Ứng dụng Chính tại AWS. Với hơn 25 năm kinh nghiệm nghiên cứu trong công nghiệp và học thuật, nghiên cứu của Yi tập trung vào việc phát triển các hệ thống đa tác nhân đàm thoại và tương tác cũng như hiểu biết cú pháp và ngữ nghĩa của ngôn ngữ tự nhiên. Ông đã dẫn đầu nỗ lực nghiên cứu đằng sau sự phát triển của nhiều dịch vụ AWS như AWS Security Agent và Amazon Bedrock Agent.
