Tác giả: Nadeem Bulsara và Deven Atnoor, Ph.D
Ngày phát hành: 26 FEB 2026
Chuyên mục: Amazon Simple Storage Service (S3), AWS HealthOmics, Healthcare, Industries, Life Sciences
Các quy trình công việc tin sinh học tốn kém về mặt tính toán, thường chạy trong nhiều giờ đến nhiều ngày. Khi các quy trình này thất bại giữa chừng hoặc yêu cầu tinh chỉnh lặp đi lặp lại, việc chạy lại từ đầu sẽ lãng phí đáng kể thời gian và tài nguyên tính toán. Tính năng bộ nhớ đệm cuộc gọi (call caching) của AWS HealthOmics giải quyết thách thức này bằng cách lưu và tái sử dụng một cách thông minh các đầu ra tác vụ đã hoàn thành, cho phép các quy trình công việc tiếp tục từ các điểm lỗi thay vì khởi động lại hoàn toàn. Bộ nhớ đệm cuộc gọi mang lại bốn lợi ích: giảm chi phí bằng cách ngăn chặn tính toán lại không cần thiết, tăng tốc chu kỳ phát triển thông qua việc tái sử dụng kết quả đã tính toán, khả năng phục hồi sản xuất thông qua phục hồi lỗi tự động và gỡ lỗi nâng cao thông qua quyền truy cập vào các kết quả được lưu trong bộ nhớ đệm.
Trong bài viết này, bạn sẽ hiểu rõ cách thiết lập và sử dụng tính năng bộ nhớ đệm cuộc gọi của AWS HealthOmics để đạt được những lợi ích này.
Tổng quan
Phân tích bộ gen và đa phương thức ngày càng đóng vai trò quan trọng trong các ứng dụng như khám phá thuốc, y học chính xác, liệu pháp gen và nông nghiệp. Do tính chất phức tạp của dữ liệu trong các ứng dụng này và các công cụ tinh vi cần thiết để xử lý chúng, các quy trình công việc tin sinh học đóng vai trò quan trọng trong việc phân tích và diễn giải chúng. Các quy trình này có thể bao gồm từ một vài đến hàng trăm công cụ tin sinh học được thực thi như một phần của pipeline với các phụ thuộc phức tạp, trong đó một số bước có thể được thực thi song song, trong khi các bước khác cần được thực thi nối tiếp. Các quy trình này thường liên quan đến các tác vụ tính toán chuyên sâu có thể chạy trong thời gian dài từ vài giờ đến nhiều ngày để hoàn thành.
Các quy trình công việc có thể thất bại do nhiều lý do như đầu vào không chính xác, công cụ và phụ thuộc lỗi thời, lỗi cơ sở hạ tầng hoặc chu kỳ phát triển tăng dần. Trong những trường hợp này, việc chạy lại toàn bộ quy trình công việc từ đầu sẽ lãng phí thời gian và tài nguyên tính toán quý giá, đồng thời kéo dài chu kỳ phát triển quy trình công việc và thời gian xử lý. Tính năng bộ nhớ đệm cuộc gọi của AWS HealthOmics giải quyết thách thức này bằng cách lưu và tái sử dụng các đầu ra tác vụ đã hoàn thành, giảm cả thời gian chạy và chi phí.
Các tính năng của bộ nhớ đệm cuộc gọi
Bộ nhớ đệm cuộc gọi có sẵn cho cả ba ngôn ngữ quy trình công việc hiện được HealthOmics hỗ trợ, tức là Nextflow, Workflow Definition Language (WDL) và Common Workflow Language (CWL). HealthOmics sử dụng Amazon Simple Storage Service (S3) làm backend để lưu trữ dữ liệu được lưu trong bộ nhớ đệm cho các lần chạy quy trình công việc nhờ độ bền, tính khả dụng, hiệu quả chi phí và khả năng mở rộng gần như không giới hạn của nó. Có hai hành vi lưu trữ được hỗ trợ:
- Cache on failure (Lưu vào bộ nhớ đệm khi thất bại) – đầu ra tác vụ từ tất cả các tác vụ đã hoàn thành của một lần chạy quy trình công việc chỉ được lưu vào bộ nhớ đệm nếu quy trình công việc thất bại. Điều này được khuyến nghị cho các lần chạy sản xuất khi gặp phải một trường hợp ngoại lệ và cần có sự can thiệp của người dùng để chạy lại từ tác vụ thành công cuối cùng.
- Cache always (Luôn lưu vào bộ nhớ đệm) – đầu ra tác vụ từ tất cả các tác vụ của một lần chạy quy trình công việc, bất kể thất bại hay thành công, đều được lưu vào bộ nhớ đệm. Điều này được khuyến nghị khi các nhà phát triển muốn lặp lại nhanh chóng một quy trình công việc và muốn tinh chỉnh mã quy trình công việc, hình ảnh Docker và/hoặc các tham số của một hoặc nhiều tác vụ để đạt được kết quả mong muốn.
Lưu ý rằng các tệp trung gian trong các tác vụ có thể được lưu vào bộ nhớ đệm nếu chúng được khai báo là đầu ra tác vụ.
Yêu cầu lưu vào bộ nhớ đệm cho các tác vụ
HealthOmics lưu vào bộ nhớ đệm các đầu ra tác vụ cho các tác vụ đáp ứng các yêu cầu sau:
- Tác vụ phải định nghĩa một container
- Tác vụ phải tạo ra một hoặc nhiều đầu ra
Ngoài ra, nếu bạn nghi ngờ rằng một tác vụ tạo ra các đầu ra không xác định (chẳng hạn như bộ tạo số ngẫu nhiên hoặc thời gian hệ thống, hoặc các điều kiện tranh chấp có thể gây ra sự thay đổi đầu ra), hãy cân nhắc không lưu vào bộ nhớ đệm các tác vụ cụ thể này.
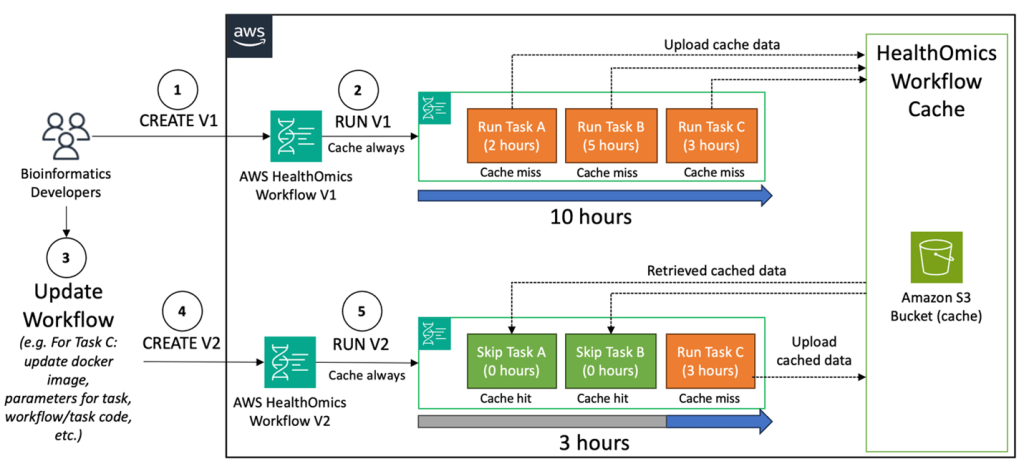
Hình 1: Trong sơ đồ này, chúng tôi trình bày cách hành vi “luôn lưu vào bộ nhớ đệm” trong quá trình phát triển quy trình công việc tích cực có thể giảm thời gian giữa các lần lặp và cải thiện thời gian hoàn thành để có một quy trình công việc cuối cùng.
Mặc dù HealthOmics cung cấp trải nghiệm lưu vào bộ nhớ đệm nhất quán trên cả ba ngôn ngữ quy trình công việc được hỗ trợ và các engine của chúng, nhưng có một số tính năng dành riêng cho engine cho phép tắt tính năng lưu vào bộ nhớ đệm cuộc gọi ở cấp độ tác vụ.
- Đối với Nextflow, bạn có thể tắt tính năng lưu vào bộ nhớ đệm cho từng tác vụ bằng cách sử dụng chỉ thị
cache false. Để biết thông tin về chỉ thị này, hãy xem mục Processes trong thông số kỹ thuật của Nextflow. - Đối với CWL, bạn có thể kiểm soát việc lưu vào bộ nhớ đệm cho từng tác vụ bằng cách sử dụng tính năng WorkReuse. Để biết thông tin về chỉ thị này, hãy xem chỉ thị WorkReuse trong tài liệu CWL.
- Đối với WDL, bạn có thể tắt tính năng lưu vào bộ nhớ đệm cho từng tác vụ bằng cách sử dụng thuộc tính
volatile. Để biết thông tin về chỉ thị này, hãy xem tài liệu trên trang web Cromwell mô tả tối ưu hóa Volatile.
Để biết thêm các cân nhắc cụ thể về engine, bạn có thể truy cập tài liệu HealthOmics.
Nhiều bộ nhớ đệm có thể được tạo và sử dụng theo nhu cầu của tổ chức. Lưu ý rằng người dùng chịu trách nhiệm về chi phí, quản lý dữ liệu và các hoạt động vòng đời của dữ liệu được lưu trong bộ nhớ đệm trong S3. Hướng dẫn bổ sung về cách quản lý bộ nhớ đệm chạy của bạn có sẵn trong tài liệu HealthOmics.
Ngoài ra, HealthOmics cung cấp trạng thái cache hit/miss trong chế độ xem chi tiết chạy cũng như nhật ký CloudWatch tích hợp, giúp người dùng hiểu cách các thay đổi của họ đối với quy trình công việc hoặc đầu vào đã ảnh hưởng đến các tác vụ cơ bản. Người dùng có thể truy cập dữ liệu bộ nhớ đệm trong S3 để kiểm tra các tệp trung gian, nhật ký engine và các artifact để gỡ lỗi và tìm hiểu sâu hơn. Các chi tiết và cân nhắc bổ sung có sẵn trong hướng dẫn sử dụng HealthOmics.
Cách sử dụng bộ nhớ đệm cuộc gọi trong AWS HealthOmics
Các bước sau đây mô tả cách bạn có thể thiết lập và sử dụng tính năng bộ nhớ đệm cuộc gọi trong các quy trình công việc của AWS HealthOmics:
- Người dùng tạo một bộ nhớ đệm và cung cấp một bucket Amazon S3 hiện có làm bộ lưu trữ backend cho bộ nhớ đệm. Người dùng chỉ định hành vi bộ nhớ đệm mặc định – “Cache Always” (Luôn lưu vào bộ nhớ đệm) hoặc “Cache on failure” (Lưu vào bộ nhớ đệm khi thất bại). Lưu ý rằng hành vi này có thể được thay đổi ở cấp độ chạy khi một quy trình công việc được khởi chạy.
- Sau khi các bộ nhớ đệm được tạo, người dùng có thể làm theo quy trình thông thường của họ để chạy một quy trình công việc với HealthOmics. Người dùng có thể chỉ định liệu lần chạy có nên sử dụng bộ nhớ đệm hay không và có thể chọn hành vi bộ nhớ đệm cho lần chạy này.
- Nếu lần chạy quy trình công việc thất bại, người dùng có thể xem lý do thất bại trong HealthOmics hoặc kiểm tra nhật ký có sẵn trong HealthOmics thông qua Amazon CloudWatch để tìm lý do thất bại. Thông tin chi tiết hơn về các cách khắc phục sự cố chạy quy trình công việc có sẵn trong tài liệu HealthOmics. Ngoài ra, người dùng có thể truy cập các đầu ra tác vụ được lưu trong bộ nhớ đệm trong S3 để giúp gỡ lỗi hoặc tìm hiểu sâu hơn về chi tiết thực thi tác vụ.
- Người dùng cập nhật thành phần quy trình công việc gây ra lỗi, chẳng hạn như hình ảnh Docker của một tác vụ cụ thể, tài nguyên của một tác vụ cụ thể, mã quy trình công việc cho tác vụ gây lỗi, các tham số chạy nếu đầu vào không chính xác, v.v. Sau khi quy trình công việc được cập nhật, người dùng có thể tạo một phiên bản quy trình công việc HealthOmics mới.
- Người dùng hiện có thể chạy phiên bản quy trình công việc mới với bộ nhớ đệm được sử dụng bởi lần chạy quy trình công việc trước đó.
- Khi hoàn thành lần chạy, các tác vụ đã hoàn thành trước đó trong quy trình công việc gốc và không được cập nhật trong phiên bản này sẽ không được thực thi. Thay vào đó, kết quả của chúng sẽ được truy xuất từ bộ nhớ đệm và quy trình công việc sẽ chỉ chạy các tác vụ bị ảnh hưởng bởi thay đổi. Hình ảnh bên dưới hiển thị cột “Cache hit” liên kết đến vị trí S3 cho dữ liệu được lưu trong bộ nhớ đệm cho tác vụ có cache hit.
Các phương pháp hay nhất
- Cấu trúc và tổ chức bộ nhớ đệm: Thiết kế bộ nhớ đệm xung quanh các ranh giới dự án logic (ví dụ: một bộ nhớ đệm cho mỗi dự án), đơn giản hóa việc quản lý và tối đa hóa việc tái sử dụng trên các quy trình công việc và các phiên bản quy trình công việc.
- Thiết kế các tác vụ xác định: Đảm bảo các tác vụ quy trình công việc của bạn là idempotent – tạo ra các đầu ra giống hệt nhau khi được cung cấp đầu vào giống hệt nhau. Tránh các phụ thuộc vào thời gian hệ thống, bộ tạo số ngẫu nhiên không có hạt giống cố định và các điều kiện tranh chấp liên quan đến đồng thời, đảm bảo bộ nhớ đệm cuộc gọi được sử dụng một cách thích hợp.
- Tối ưu hóa quản lý lưu trữ bộ nhớ đệm: Thiết lập lịch trình dọn dẹp thường xuyên (ví dụ: kết thúc dự án phát triển lớn), theo dõi kích thước bộ nhớ đệm thường xuyên và dọn dẹp các mục bộ nhớ đệm lỗi thời, tự động hóa quản lý bộ nhớ đệm thông qua các chính sách vòng đời S3 để lưu giữ, lưu trữ hoặc xóa dựa trên chu kỳ phát triển của bạn.
- Lưu trữ các tệp trung gian một cách chiến lược: Khai báo các tệp trung gian quan trọng làm đầu ra tác vụ để cho phép gỡ lỗi nâng cao.
Lợi ích chính
- Tối ưu hóa chi phí: Các quy trình công việc bộ gen có thể tiêu thụ tài nguyên tính toán đáng kể. Bộ nhớ đệm cuộc gọi loại bỏ tính toán dư thừa bằng cách tái sử dụng kết quả từ các lần chạy trước, trực tiếp giảm chi phí tính toán của bạn.
- Chu kỳ phát triển tăng tốc: Trong quá trình phát triển quy trình công việc, các nhà nghiên cứu thường cần sửa đổi và kiểm tra các thành phần pipeline cụ thể. Thay vì chạy lại toàn bộ quy trình công việc, bộ nhớ đệm cuộc gọi cho phép bạn lặp lại các tác vụ riêng lẻ trong khi tái sử dụng đầu ra từ các thành phần không thay đổi, tăng tốc đáng kể quá trình phát triển.
- Quy trình công việc sản xuất linh hoạt: Các quy trình công việc bộ gen sản xuất xử lý các mẫu quan trọng có thể thất bại do nhiều yếu tố – sự cố cơ sở hạ tầng, vấn đề dữ liệu hoặc hạn chế tài nguyên. Bộ nhớ đệm cuộc gọi cho phép tự động tiếp tục từ điểm thất bại, đảm bảo rằng các tác vụ đã hoàn thành thành công không cần phải tính toán lại.
- Gỡ lỗi và khắc phục sự cố: Bằng cách lưu trữ các tệp trung gian làm đầu ra tác vụ, các nhà nghiên cứu có quyền truy cập vào các artifact thực thi để gỡ lỗi. Khả năng hiển thị này vào các bước xử lý trung gian rất hữu ích để khắc phục sự cố các pipeline phân tích bộ gen phức tạp.
Kết luận
Bằng cách loại bỏ nhu cầu chạy lại hoàn toàn các tác vụ quy trình công việc đã thực thi trước đó, bộ nhớ đệm cuộc gọi trong AWS HealthOmics giúp khách hàng đẩy nhanh các đột phá khoa học bằng cách giảm cả chi phí tính toán và thời gian thu thập thông tin chi tiết cho các phân tích omics. Các nhà tin sinh học có thể lặp lại nhanh chóng để phát triển các quy trình công việc chính xác và hiệu quả trong khi vẫn tiết kiệm chi phí. Hãy cân nhắc tận dụng bộ nhớ đệm cuộc gọi trong AWS HealthOmics để tăng tốc nhu cầu phân tích tin sinh học của bạn. Liên hệ với đại diện tài khoản AWS của bạn hoặc truy cập trang web AWS HealthOmics để tìm hiểu thêm về AWS HealthOmics và các tài nguyên liên quan.
Tài nguyên bổ sung
- Tài liệu chính thức của AWS HealthOmics – Hướng dẫn toàn diện bao gồm các khái niệm, tính năng, lưu trữ, phân tích và quy trình công việc của HealthOmics với các hướng dẫn bắt đầu.
- Hướng dẫn và ví dụ về AWS HealthOmics – Các hướng dẫn thực hành và mẫu mã để làm việc với các quy trình công việc, lưu trữ và phân tích của HealthOmics.
- Blog Tối ưu hóa chạy và phân tích chi phí – Hướng dẫn chuyên sâu về cách sử dụng HealthOmics Run Analyzer để tối ưu hóa hiệu suất quy trình công việc và giảm chi phí.
- Hướng dẫn phân tích dữ liệu đa phương thức – Khung làm việc end-to-end cho thấy cách tích hợp HealthOmics với các dịch vụ AWS Health và ML khác.
- Tài liệu về bộ nhớ đệm cuộc gọi của AWS HealthOmics – Hướng dẫn đầy đủ về các khái niệm, triển khai và các phương pháp hay nhất về bộ nhớ đệm cuộc gọi để tối ưu hóa việc chạy lại quy trình công việc.
- AWS HealthOmics MCP Server – Tài liệu cho máy chủ Giao thức ngữ cảnh mô hình (Model Context Protocol) được thiết kế đặc biệt để tích hợp AWS HealthOmics.
Về tác giả

Nadeem Bulsara
Nadeem Bulsara là Kiến trúc sư Giải pháp Chính tại AWS, chuyên về Genomics và Khoa học Đời sống. Ông mang đến hơn 13 năm kinh nghiệm về Tin sinh học, Kỹ thuật Phần mềm và Phát triển Đám mây, cũng như kinh nghiệm trong nghiên cứu bộ gen lâm sàng và đa omics để giúp các tổ chức Chăm sóc sức khỏe và Khoa học Đời sống trên toàn cầu. Ông được thúc đẩy bởi sứ mệnh của ngành nhằm giúp mọi người có một cuộc sống lâu dài và khỏe mạnh.

Deven Atnoor, Ph.D
Tận dụng kiến thức chuyên môn và hiểu biết vận hành trong lĩnh vực chăm sóc sức khỏe và khoa học đời sống, Deven xây dựng các giải pháp chuyển đổi kỹ thuật số để khai thác sức mạnh của dữ liệu. Điều này cho phép khách hàng trong lĩnh vực chăm sóc sức khỏe và khoa học đời sống tạo ra thông tin chi tiết để thúc đẩy đổi mới nhằm mang lại kết quả tốt hơn cho bệnh nhân. Kể từ khi bắt đầu với tư cách là nhà khoa học tin sinh học tại Whitehead Institute/MIT, Deven đã làm việc trực tiếp với khách hàng trong 20 năm qua để mang lại kết quả kinh doanh, giải quyết các cơ hội chiến lược trong tin học, nghiên cứu khám phá, phòng thí nghiệm tương lai, thử nghiệm lâm sàng, bằng chứng thực tế và dữ liệu thực tế.
