Tác giả: Ankith Ede, Gokhul Srinivasan, Jake Valsamis, Simon Adar, và Daniel Koster
Ngày phát hành: 02 MAR 2026
Chuyên mục: Amazon Bedrock, Amazon Machine Learning, Artificial Intelligence, Best Practices, Healthcare, Life Sciences, Partner solutions
Bởi: Ankith Ede, Solutions Architect – AWS
Bởi: Jake Valsamis, Sr Product Manager – Code Ocean
Bởi: Gokhul Srinivasan, Sr Partner Solutions Architect – AWS
Bởi: Simon Adar, CEO – Code Ocean
Bởi: Daniel Koster, VP of Product – Code Ocean

Giới thiệu
Điện toán đám mây đã thay đổi ngành khoa học đời sống, mang đến cho các nhà khoa học quyền truy cập vào các tài nguyên tính toán khổng lồ: petabyte lưu trữ và tính toán hiệu năng cao. Tuy nhiên, sự chuyển đổi kỹ thuật số này đi kèm với một nghịch lý. Việc sử dụng đám mây một cách hiệu quả và an toàn đòi hỏi các kỹ năng kỹ thuật và DevOps nằm ngoài chuyên môn cốt lõi của hầu hết các nhà khoa học. Khoảng cách này đã tạo áp lực lên các nhóm IT nghiên cứu, những người phải cân bằng giữa các yêu cầu quản lý cơ sở hạ tầng và tuân thủ, đồng thời cho phép các nhà khoa học tập trung vào nghiên cứu.
Khi tốc độ đổi mới AI tăng tốc, những yêu cầu mới đang được đặt ra đối với IT nghiên cứu vì việc sử dụng an toàn và tuân thủ các công nghệ này phụ thuộc vào quản trị do IT dẫn dắt. AI tạo sinh và tác nhân thúc đẩy khám phá khoa học bằng cách cung cấp cho các nhà nghiên cứu công cụ để phân tích các bộ dữ liệu phức tạp và xây dựng quy trình làm việc ở quy mô lớn bằng ngôn ngữ tự nhiên. Mặc dù các nhà khoa học rất muốn áp dụng các công cụ này, IT nghiên cứu phải đảm bảo triển khai an toàn và đáp ứng cả tiêu chuẩn tổ chức và quy định. Nếu không có cơ sở hạ tầng đầy đủ, việc triển khai AI có nguy cơ về bảo mật, lộ IP, khả năng tái tạo không nhất quán và thiếu khả năng kiểm toán.
Trong bài đăng này, chúng tôi khám phá cách các tổ chức có thể áp dụng Code Ocean để trao quyền cho IT nghiên cứu và trang bị cho các nhà khoa học một nền tảng nghiên cứu có thể mở rộng, có thể tái tạo. Chúng tôi cũng sẽ nêu bật một nghiên cứu điển hình thực tế từ Viện Allen và giới thiệu cách IT nghiên cứu cung cấp quyền truy cập an toàn, tuân thủ vào AI tác nhân với Trusted Agents, mà chúng tôi gần đây đã ra mắt trong Code Ocean 4.0.
Mở rộng quy mô IT nghiên cứu với nền tảng khoa học FAIR và có thể tái tạo
Code Ocean là một nền tảng nghiên cứu tính toán tập trung vào đám mây mà các nhà khoa học có thể sử dụng để tự chủ truy cập tài nguyên đám mây trong khi vẫn duy trì bảo mật, tuân thủ và kiểm soát chi phí. Được triển khai trong Amazon Virtual Private Cloud (Amazon VPC) của khách hàng, Code Ocean cung cấp quyền truy cập tích hợp vào dữ liệu và tính toán có thể mở rộng để các nhà nghiên cứu chạy phân tích, giải phóng IT nghiên cứu khỏi việc hỗ trợ hàng ngày. Code Ocean tự động cấp phát điện toán đám mây, có nghĩa là các nhà khoa học có thể tập trung vào khám phá thay vì quản lý cơ sở hạ tầng.
Cốt lõi của nền tảng Code Ocean là các phương pháp hay nhất về tính toán tích hợp. Mã được tự động kiểm soát phiên bản với Git, để mọi thay đổi đều được theo dõi và có thể đảo ngược. Tất cả các phân tích và pipeline được thiết kế để bất biến và hoàn toàn có thể tái tạo, đảm bảo rằng bất kỳ kết quả nào cũng có thể được tạo lại chính xác như ban đầu. Dòng dữ liệu được ghi lại cho mọi kết quả, cung cấp một bản ghi minh bạch về cách mỗi output được tạo ra từ các input nguồn của nó. Bằng cách làm việc trong Code Ocean, tất cả dữ liệu, phân tích và pipeline đều tự động có thể tìm thấy, truy cập, tương tác và tái sử dụng (FAIR). Code Ocean cũng hỗ trợ các công cụ mà các nhà khoa học đã sử dụng, bao gồm RStudio, Jupyter, Code Server, Nextflow và MLflow, có nghĩa là người dùng doanh nghiệp có thể hoạt động mà không phụ thuộc vào IT nghiên cứu. Nền tảng này tích hợp các tối ưu hóa chi phí theo mặc định: lưu trữ được phân tầng tự động, tài nguyên tính toán nhàn rỗi được phát hiện và tắt, và giám sát ngân sách độ phân giải cao cung cấp khả năng hiển thị rõ ràng về chi tiêu. Bằng cách nhúng các khả năng này vào nền tảng của mình, Code Ocean giảm gánh nặng vận hành cho IT nghiên cứu trong khi mang lại cho các nhà khoa học sự linh hoạt để đổi mới và cộng tác ở quy mô lớn.
Từ rủi ro đến sẵn sàng với Trusted Agents
Các tổ chức ngày càng khám phá sức mạnh của AI tác nhân để tự động hóa và tăng tốc quá trình khám phá. Tuy nhiên, các tổ chức vẫn phải xem xét việc sử dụng an toàn, tuân thủ và có tài liệu trước khi áp dụng các quy trình làm việc của tác nhân trong một ngành được quản lý chặt chẽ như khoa học đời sống. Chính những lo ngại này đã thúc đẩy bản phát hành mới nhất của Code Ocean, Trusted Agents trong phiên bản 4.0, hiện cho phép IT nghiên cứu mang AI an toàn, có thể kiểm toán đến tổ chức của họ. Với bản phát hành lớn này, Code Ocean cấp phát và quản lý cơ sở hạ tầng AI một cách an toàn trong virtual private cloud (VPC) của khách hàng, giữ dữ liệu nhạy cảm trong môi trường của khách hàng.
Code Ocean sử dụng AWS Batch để chạy các pipeline quy trình làm việc và các tác vụ hệ thống, và các phiên bản Amazon Elastic Compute Cloud (Amazon EC2) cho các dịch vụ hệ thống và worker. Điều này cung cấp các hàng rào bảo vệ tích hợp để các nhà khoa học có thể tự tin sử dụng AI tạo sinh trong một khuôn khổ tuân thủ, được kiểm soát và làm việc độc lập hơn với các tác nhân thông minh hướng dẫn phân tích và hỗ trợ khắc phục sự cố.
Cơ sở hạ tầng AI bảo mật
Được xây dựng trên Amazon Bedrock, Code Ocean 4.0 sử dụng các mô hình ngôn ngữ lớn (LLM) như Amazon Nova Pro và Claude Sonnet của Anthropic trong Amazon Bedrock, và hỗ trợ các tác nhân được xây dựng bằng các framework tác nhân như Strands Agents. Cách tiếp cận này có nghĩa là các nhà phát triển và nhà khoa học có thể sử dụng an toàn các khả năng AI mới nhất mà không ảnh hưởng đến bảo mật hoặc tuân thủ.
Sơ đồ kiến trúc sau đây cho thấy hai phiên bản EC2 với Amazon Machine Image (AMI) của Code Ocean xử lý các dịch vụ hệ thống và tác vụ worker. Các luồng LLM đi đến Amazon Bedrock. AWS Batch quản lý các pipeline và tác vụ hệ thống, tương tác với Amazon Elastic Container Service (Amazon ECS). Dữ liệu được lưu trữ trên các dịch vụ lưu trữ dữ liệu AWS khác nhau.
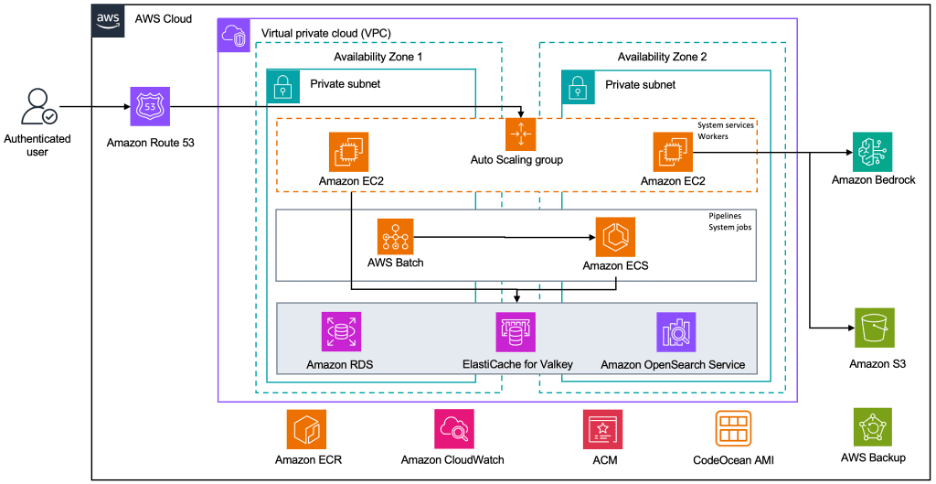
Hình 1: Kiến trúc AWS của Code Ocean cho các khối lượng công việc có thể mở rộng
Aqua: AI đáng tin cậy cho khoa học có thể tái tạo
Bản phát hành giới thiệu Aqua, một tác nhân AI ngôn ngữ tự nhiên được thiết kế đặc biệt cho các nhà khoa học. Được xây dựng có mục đích để hoạt động trong ngữ cảnh của Code Ocean, Aqua kết hợp sức mạnh suy luận của các mô hình Claude Sonnet của Anthropic trong Amazon Bedrock với khả năng truy xuất kiến thức cụ thể của nền tảng và thực hiện các hành động trực tiếp. Sử dụng Model Context Protocol (MCP) của Code Ocean, Aqua được trang bị 18 công cụ chuyên biệt để quản lý, tìm kiếm và thực hiện các tác vụ trên các tài nguyên nền tảng. Để đảm bảo tuân thủ và khả năng tái tạo, Aqua hoạt động hoàn toàn trong môi trường được kiểm soát của Code Ocean, với một số yếu tố nhấn mạnh khả năng của Aqua trong việc tạo ra các kết quả được theo dõi đầy đủ, có thể tái tạo và có trách nhiệm giải trình:
- Các tài sản dữ liệu được Aqua truy cập hoặc tạo ra là bất biến.
- Mã được Aqua tạo ra được thực thi trong một Capsule để kiểm soát phiên bản và khả năng tái tạo.
- Kết quả bao gồm đầy đủ nguồn gốc, làm cho output do AI tạo ra có thể truy nguyên đến mã, dữ liệu và môi trường cơ bản của nó.
- Các hành động mà Aqua thực hiện được gán cho người dùng cụ thể mà nó hoạt động thay mặt, duy trì một lịch sử toàn diện, có thể kiểm toán.
Ảnh chụp màn hình sau đây cho thấy giao diện người dùng nền tảng Code Ocean. Ở bên trái, người dùng hỏi Aqua câu hỏi sau về cấu trúc protein được hiển thị ở bên phải:
“Diện tích bề mặt tiếp xúc với dung môi của protein 1GFL mà tôi đang xem là bao nhiêu?”
Với nhận thức về những gì được hiển thị trong giao diện người dùng nền tảng, Aqua có tất cả ngữ cảnh cần thiết để trả lời câu hỏi.
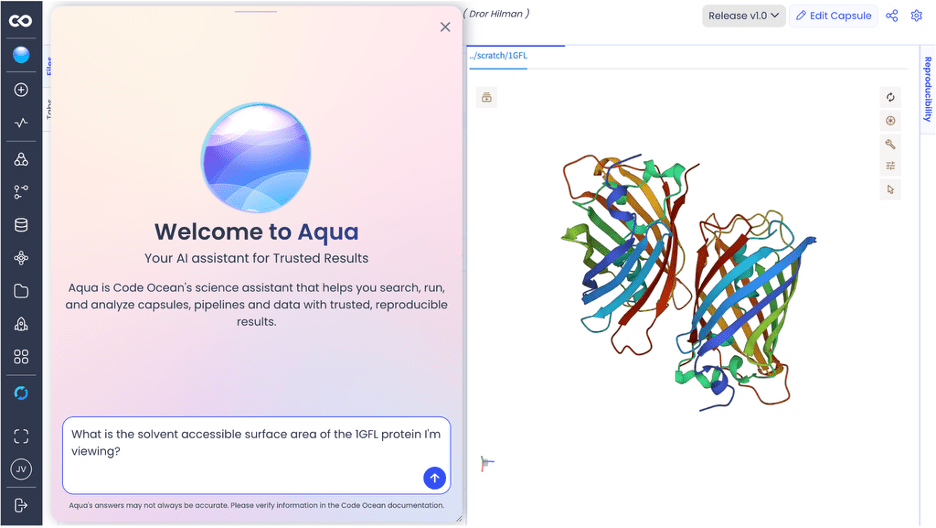
Hình 2: Aqua, trợ lý AI của Code Ocean, được nhúng vào giao diện người dùng nền tảng
Ảnh chụp màn hình sau đây cho thấy giao diện người dùng Aqua. Ở bên trái, kết quả phân tích tế bào đơn do AI tạo ra được hiển thị. Phía bên phải hiển thị biểu đồ dòng dõi của kết quả, theo dõi luồng dữ liệu từ input, thông qua thực thi capsule, đến kết quả cuối cùng có thể tái tạo.
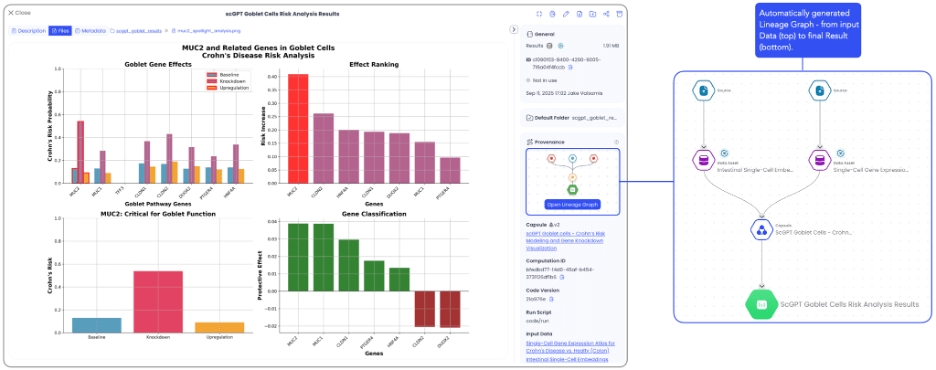
Hình 3: Khả năng theo dõi nguồn gốc và dòng dõi tự động của Aqua cho các kết quả do AI tạo ra
Đối với các nhà phát triển, bản phát hành giới thiệu Cline, một tác nhân mã hóa an toàn, nhận biết ngữ cảnh được nhúng trực tiếp vào Visual Studio Code (VSCode). Được cấu hình sẵn thông qua Amazon Bedrock, Cline cung cấp hỗ trợ mã hóa dựa trên LLM trong một môi trường phát triển quen thuộc và cho phép tích hợp các máy chủ MCP tùy chỉnh vào nền tảng Code Ocean.
Viện Allen mở rộng quy mô nghiên cứu có thể tái tạo với Code Ocean
Được thúc đẩy bởi nhu cầu về một nền tảng nghiên cứu an toàn, có thể tái tạo, Viện Allen, một viện nghiên cứu có trụ sở tại Seattle, đã áp dụng Code Ocean. Code Ocean đã tăng tốc quá trình chuyển đổi sang AWS của Viện Allen và cung cấp cho các nhà khoa học quyền truy cập vào một môi trường tính toán có thể mở rộng. Bằng cách sử dụng tích hợp của Code Ocean với các dịch vụ AWS, các nhà nghiên cứu hiện tiêu thụ hơn 1,75 triệu giờ CPU và tạo ra hơn 150 TB kết quả có thể tái tạo mỗi tháng. Sử dụng Code Ocean để quản lý khả năng mở rộng, kiểm soát chi phí và tuân thủ, viện đã mở rộng quy mô xử lý dữ liệu từ terabyte lên petabyte hàng năm.
“Code Ocean giúp các nhà khoa học của chúng tôi dễ dàng thực hiện công việc của họ một cách có thể tái tạo. Người dùng mới trên nền tảng có thể tiến xa chỉ với một chút hỗ trợ; điều này giúp các kỹ sư của chúng tôi có thời gian tập trung vào các thách thức chuyên biệt.”
– Tiến sĩ David Feng, Giám đốc cấp cao về Tính toán Khoa học, Viện Allen về Động lực học Thần kinh
Ba năm sau khi hợp tác, Viện Allen đã tạo ra một kho dữ liệu trên Code Ocean với hơn hai petabyte, chạy hơn 450.000 phép tính với tổng số hơn 1.500.000 giờ. Hiện tại, họ hỗ trợ hơn 250 nhà nghiên cứu trên các lĩnh vực với nỗ lực bán thời gian của chỉ năm thành viên trong nhóm IT nghiên cứu.
Code Ocean: Nền tảng đáng tin cậy cho khoa học dựa trên AI
Sự hội tụ của điện toán đám mây và AI mang đến cả cơ hội chuyển đổi và thách thức ngày càng tăng cho các tổ chức khoa học đời sống. Khi các nhà nghiên cứu cố gắng khai thác sức mạnh của các công nghệ này, IT nghiên cứu cần đảm bảo bảo mật, tuân thủ và khả năng tái tạo ở quy mô lớn. Code Ocean thu hẹp khoảng cách này, trao quyền cho các nhà khoa học đổi mới độc lập trong khi cho phép IT nghiên cứu duy trì toàn quyền quản trị và kiểm soát. Kinh nghiệm của Viện Allen cho thấy cách IT nghiên cứu có thể sử dụng Code Ocean để hỗ trợ hàng trăm nhà nghiên cứu và khối lượng công việc quy mô petabyte thông qua tự động hóa và dễ dàng truy cập vào cơ sở hạ tầng có thể mở rộng.
Code Ocean Trusted Agents mở rộng nền tảng này, cung cấp cho các nhà khoa học quyền truy cập an toàn, có thể kiểm toán vào các khả năng AI trong môi trường AWS của riêng họ. Trợ lý nghiên cứu thông minh Aqua tăng tốc khám phá với phân tích tác nhân có thể truy nguyên và tái tạo. Nó cũng hoạt động như một tác nhân hỗ trợ thời gian thực, chẩn đoán các vấn đề xây dựng, diễn giải lỗi AWS và hướng dẫn người dùng thông qua các quy trình làm việc phức tạp mà không cần sự can thiệp của IT. Aqua giải phóng các nhóm IT để tập trung vào mở rộng quy mô cơ sở hạ tầng và đổi mới khoa học bằng cách cắt giảm chi phí vận hành và tăng cường khả năng tự chủ.
Code Ocean mang đến một tương lai nơi mọi đột phá khoa học đều có thể tái tạo, nơi các nhà nghiên cứu dành 100% thời gian của họ cho khám phá, và AI tăng tốc chứ không làm phức tạp quá trình khoa học.
Trải nghiệm tương lai của khoa học bảo mật, có thể mở rộng
Khám phá cách Code Ocean trao quyền cho IT nghiên cứu và các nhà khoa học đổi mới nhanh hơn với Trusted Agents. Đặt lịch demo ngay hôm nay hoặc truy cập www.codeocean.com để tìm hiểu thêm.

Code Ocean – Tiêu điểm Đối tác AWS
Code Ocean là Đối tác Công nghệ Nâng cao của AWS cung cấp nền tảng Khoa học Tính toán cho các nhóm Nghiên cứu và Phát triển khoa học đời sống muốn có một cách nhanh chóng và hiệu quả để bắt đầu, mở rộng, cộng tác và tái tạo nghiên cứu tính toán.
