Tác giả: Sri Potluri và Luis Felipe Yepez Barrios
Ngày phát hành: 02 MAR 2026
Chuyên mục: Amazon Bedrock, Amazon DynamoDB, Amazon SageMaker AI, Generative AI, Intermediate (200), Technical How-to
Các nhóm dịch vụ khách hàng phải đối mặt với một thách thức dai dẳng. Các trợ lý dựa trên trò chuyện hiện có làm người dùng thất vọng với các phản hồi cứng nhắc, trong khi các triển khai mô hình ngôn ngữ lớn (LLM) trực tiếp lại thiếu cấu trúc cần thiết cho các hoạt động kinh doanh đáng tin cậy. Khi khách hàng cần trợ giúp về các yêu cầu đặt hàng, hủy đơn hàng hoặc cập nhật trạng thái, các phương pháp truyền thống hoặc không hiểu ngôn ngữ tự nhiên hoặc không thể duy trì ngữ cảnh trong các cuộc hội thoại nhiều bước.
Bài đăng này khám phá cách xây dựng một tác nhân đàm thoại thông minh bằng cách sử dụng Amazon Bedrock, LangGraph và MLflow được quản lý trên Amazon SageMaker AI.
Tổng quan giải pháp
Tác nhân AI đàm thoại được trình bày trong bài đăng này minh họa một triển khai thực tế để xử lý các yêu cầu đặt hàng của khách hàng, một trường hợp sử dụng phổ biến nhưng thường đầy thách thức đối với các giải pháp tự động hóa dịch vụ khách hàng hiện có. Chúng tôi triển khai một tác nhân quản lý đơn hàng thông minh giải quyết những thách thức này bằng cách giúp khách hàng tìm thông tin về đơn hàng của họ và thực hiện các hành động như hủy đơn hàng thông qua cuộc trò chuyện tự nhiên. Hệ thống sử dụng luồng hội thoại dựa trên đồ thị với ba giai đoạn chính:
- Ý định ban đầu – Xác định mong muốn của khách hàng và thu thập thông tin cần thiết
- Xác nhận đơn hàng – Trình bày chi tiết đơn hàng đã tìm thấy và xác minh ý định của khách hàng
- Giải quyết – Thực hiện yêu cầu của khách hàng và cung cấp kết thúc
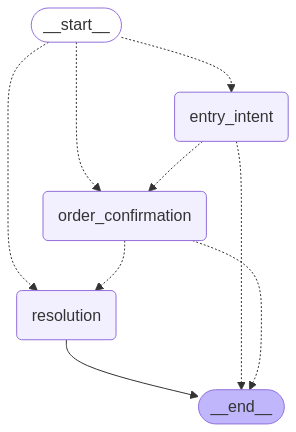
Luồng tác nhân này được minh họa trong đồ họa sau.
Tuyên bố vấn đề
Hầu hết các giải pháp tự động hóa dịch vụ khách hàng thuộc hai loại, mỗi loại đều có những hạn chế đáng kể.
Trợ lý trò chuyện dựa trên quy tắc thường thất bại trong việc hiểu ngôn ngữ tự nhiên, dẫn đến trải nghiệm người dùng gây khó chịu. Chúng thường tuân theo các cây quyết định cứng nhắc không thể xử lý các sắc thái của cuộc trò chuyện của con người. Khi người dùng đi chệch khỏi các đầu vào dự kiến, các hệ thống này sẽ thất bại, buộc người dùng phải thích nghi với trợ lý thay vì ngược lại. Ví dụ, một trợ lý trò chuyện dựa trên quy tắc có thể nhận ra “Tôi muốn hủy đơn hàng của mình” nhưng lại thất bại với “Tôi cần trả lại thứ gì đó tôi vừa mua” vì nó không khớp với các mẫu được xác định trước.
Trong khi đó, các LLM hiện đại vượt trội trong việc hiểu ngôn ngữ tự nhiên nhưng lại đặt ra những thách thức riêng khi được sử dụng trực tiếp. LLM không duy trì trạng thái hoặc tuân theo các quy trình nhiều bước một cách cố hữu, khiến việc quản lý cuộc trò chuyện trở nên khó khăn. Việc kết nối LLM với các hệ thống backend đòi hỏi sự điều phối cẩn thận, và việc giám sát hiệu suất của chúng đặt ra những thách thức về khả năng quan sát độc đáo. Quan trọng nhất, LLM có thể tạo ra thông tin hợp lý nhưng không chính xác khi chúng thiếu quyền truy cập vào kiến thức chuyên môn.
Để hiểu những hạn chế này đối với một ví dụ thực tế, hãy xem xét một kịch bản dịch vụ khách hàng tưởng chừng đơn giản: người dùng cần kiểm tra trạng thái đơn hàng hoặc yêu cầu hủy đơn hàng. Tương tác này đòi hỏi phải hiểu ý định của người dùng, trích xuất thông tin liên quan như số đơn hàng và chi tiết tài khoản, xác minh thông tin với các hệ thống backend, xác nhận hành động trước khi thực hiện và duy trì ngữ cảnh trong suốt cuộc trò chuyện. Nếu không có một cách tiếp cận có cấu trúc, cả hệ thống dựa trên quy tắc và LLM thô đều không thể xử lý các quy trình nhiều bước này đòi hỏi bộ nhớ, lập kế hoạch và tích hợp với các hệ thống bên ngoài.
Những hạn chế cơ bản này giải thích tại sao các phương pháp hiện có liên tục không đạt được hiệu quả trong các ứng dụng thực tế. Các hệ thống dựa trên quy tắc không thể kết nối hiệu quả cuộc trò chuyện tự nhiên với các quy trình kinh doanh có cấu trúc, trong khi LLM không thể duy trì trạng thái qua nhiều tương tác. Cả hai phương pháp đều không thể tích hợp liền mạch với các hệ thống backend để truy xuất và cập nhật dữ liệu, và cả hai đều cung cấp khả năng hiển thị hạn chế về hiệu suất và trải nghiệm người dùng. Quan trọng nhất, các giải pháp hiện tại không thể cân bằng sự linh hoạt cần thiết cho cuộc trò chuyện tự nhiên với việc thực thi quy tắc kinh doanh cần thiết cho dịch vụ khách hàng đáng tin cậy.
Giải pháp này giải quyết những thách thức này thông qua các tác nhân AI—các hệ thống kết hợp khả năng ngôn ngữ tự nhiên của LLM với quy trình làm việc có cấu trúc, tích hợp công cụ và khả năng quan sát toàn diện.
Kiến trúc giải pháp
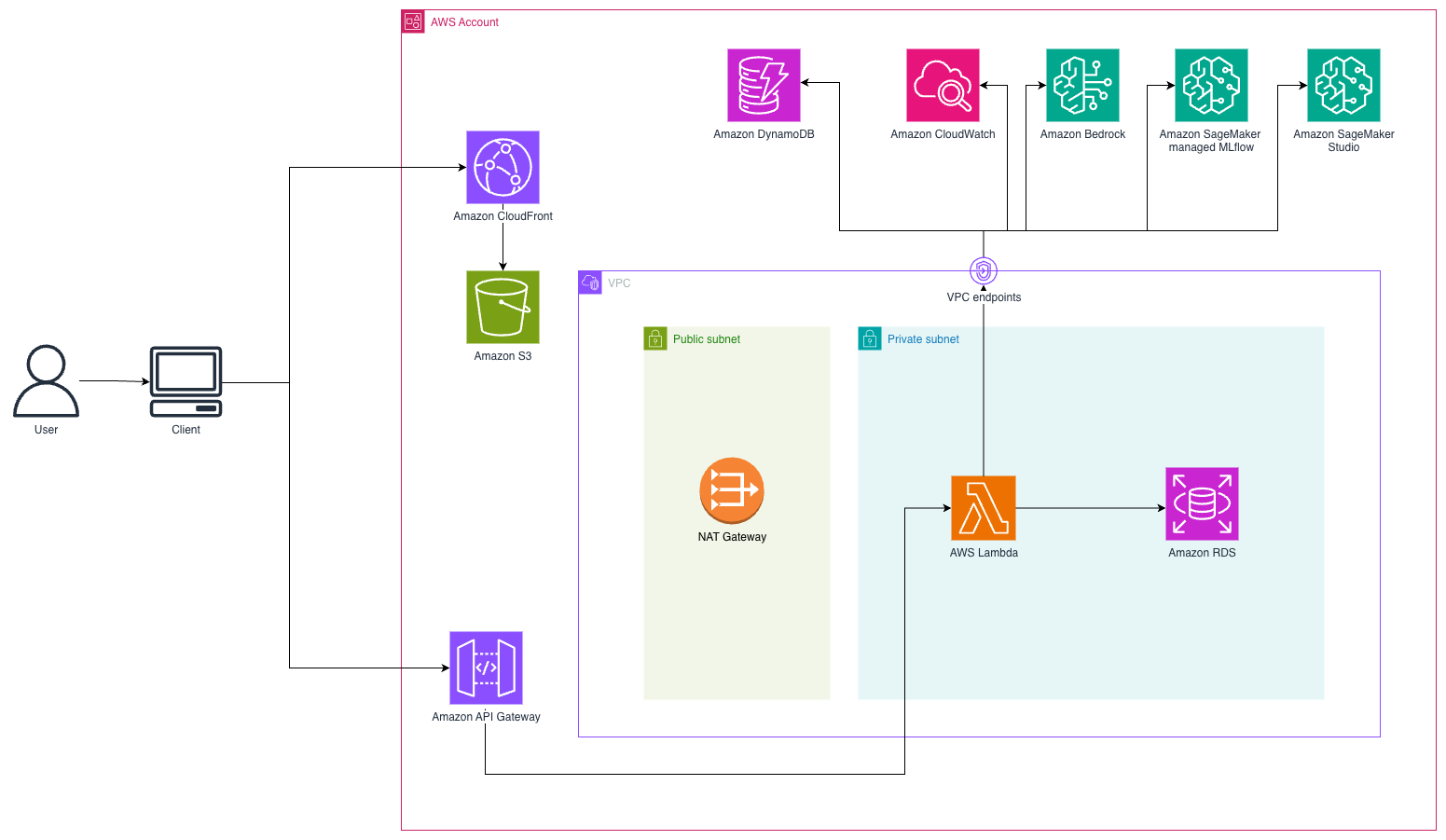
Giải pháp này triển khai một hệ thống AI đàm thoại phi máy chủ sử dụng kiến trúc dựa trên WebSocket cho các tương tác khách hàng theo thời gian thực. Khách hàng truy cập một frontend React được lưu trữ trên Amazon Simple Storage Service (Amazon S3) và được phân phối thông qua Amazon CloudFront. Khi khách hàng gửi tin nhắn, hệ thống thiết lập kết nối WebSocket liên tục thông qua Amazon API Gateway đến các hàm AWS Lambda điều phối luồng hội thoại. Sơ đồ sau minh họa kiến trúc giải pháp.
Kiến trúc tác nhân
Giải pháp này sử dụng các tác nhân AI, các hệ thống nơi LLM tự động điều khiển các quy trình và việc sử dụng công cụ của riêng chúng trong khi vẫn duy trì quyền kiểm soát cách chúng hoàn thành nhiệm vụ. Không giống như các ứng dụng LLM đơn giản, các tác nhân này duy trì trạng thái và ngữ cảnh qua nhiều tương tác, có thể sử dụng các công cụ bên ngoài để thu thập thông tin hoặc thực hiện hành động, suy luận về các bước tiếp theo của chúng dựa trên kết quả trước đó và hoạt động với một mức độ tự chủ nhất định. Quy trình làm việc của tác nhân tuân theo một mẫu có cấu trúc gồm khởi tạo, hiểu ý định người dùng, lập kế hoạch các hành động cần thiết, thực hiện các lệnh gọi công cụ khi cần, tạo phản hồi và cập nhật trạng thái hội thoại cho các tương tác trong tương lai.
Để xây dựng các tác nhân đàm thoại hiệu quả, chúng ta cần bốn khả năng cốt lõi:
- Trí thông minh để hiểu và phản hồi người dùng
- Bộ nhớ để duy trì ngữ cảnh trong các cuộc hội thoại
- Khả năng thực hiện hành động trong các hệ thống bên ngoài
- Điều phối để quản lý các quy trình làm việc nhiều bước phức tạp
Việc triển khai của chúng tôi giải quyết các yêu cầu này thông qua các dịch vụ và framework Amazon Web Services (AWS) cụ thể.
Amazon Bedrock đóng vai trò là lớp thông minh, cung cấp quyền truy cập vào các mô hình nền tảng (FM) tiên tiến thông qua một API nhất quán. Amazon Bedrock được sử dụng để xử lý nhận dạng ý định nhằm hiểu những gì người dùng đang cố gắng thực hiện, trích xuất thực thể để xác định thông tin chính như số đơn hàng và chi tiết khách hàng, tạo ngôn ngữ tự nhiên để tạo ra các phản hồi phù hợp với ngữ cảnh, ra quyết định để xác định hành động tốt nhất tiếp theo trong luồng hội thoại và điều phối việc sử dụng công cụ để tương tác với các hệ thống bên ngoài. Lớp thông minh này cho phép tác nhân của chúng tôi hiểu ngôn ngữ tự nhiên trong khi vẫn duy trì việc ra quyết định có cấu trúc cần thiết cho dịch vụ khách hàng đáng tin cậy.
Quản lý trạng thái (bộ nhớ tác nhân) được xử lý thông qua Amazon DynamoDB, cung cấp bộ nhớ liên tục cho ngữ cảnh hội thoại ngay cả khi có gián đoạn hoặc khởi động lại hệ thống. Trạng thái bao gồm ID phiên làm việc làm định danh hội thoại duy nhất, lịch sử hội thoại đầy đủ để duy trì ngữ cảnh, bản ghi được định dạng tối ưu hóa cho cửa sổ ngữ cảnh của mô hình, thông tin được trích xuất như số đơn hàng và chi tiết khách hàng, và các cờ quy trình cho biết trạng thái xác nhận và thành công truy xuất thông tin. Trạng thái liên tục này cho phép tác nhân của chúng tôi duy trì ngữ cảnh qua nhiều tương tác, giải quyết một trong những hạn chế chính của việc triển khai LLM thô.
Đoạn mã quản lý trạng thái (để triển khai đầy đủ, bạn có thể tham khảo mã trong backend/app.py):
# Save conversation state to DynamoDBttl_value = int(time.time()) + (3600 * 4) # 4 hrsitem = { 'conversationId': session_id, 'state': json.dumps(state_dict), 'chat_status': state_dict['session_end'], 'update_ts_pst': str(datetime.now(pst)), 'ttl': ttl_value, 'timestamp': int(time.time())}ddb_table.put_item(Item=item)
Trạng thái bao gồm giá trị Time-To-Live (TTL) tự động hết hạn các cuộc hội thoại sau một khoảng thời gian không hoạt động, giúp quản lý chi phí lưu trữ.
Gọi hàm, còn được gọi là sử dụng công cụ, cho phép tác nhân của chúng tôi tương tác với các hệ thống bên ngoài một cách có cấu trúc. Thay vì tạo văn bản tự do cố gắng mô tả một hành động, mô hình tạo ra các lệnh gọi có cấu trúc đến các hàm được xác định trước với các tham số cụ thể. Bạn có thể coi đây là việc cung cấp cho LLM một bộ công cụ hoàn chỉnh với hướng dẫn sử dụng, trong đó LLM quyết định khi nào sử dụng các công cụ này và thông tin nào cần cung cấp. Việc triển khai của chúng tôi định nghĩa các công cụ cụ thể kết nối với cơ sở dữ liệu Amazon Relational Database (Amazon RDS) for PostgreSQL: get_user để tra cứu khách hàng, get_order_by_id để lấy chi tiết đơn hàng, get_customer_orders để liệt kê các đơn hàng của khách hàng, cancel_order để hủy đơn hàng và update_order để sửa đổi đơn hàng.
Đoạn mã sau cho phép xử lý đúng trình tự tin nhắn giữa trợ lý và người dùng cùng với tên công cụ và đầu vào hoặc tham số cần thiết. (Để biết chi tiết triển khai, hãy tham khảo backend/utils/utils.py):
def use_tool(messages): tool_use = messages[-1]["content"][-1].get("toolUse") if tool_use: tool_name = tool_use["name"] tool_input = tool_use["input"] # Process the tool call tool_result = _process_tool_call(tool_name, tool_input) # Format response for the model message = { "role": "user", "content": [ { "toolResult": { "toolUseId": tool_use["toolUseId"], "content": [ {"text": json.dumps(tool_result)} ], "status": "success", } } ], } return message
Các công cụ được định nghĩa với các schema JSON cung cấp các hợp đồng rõ ràng để mô hình tuân theo:
tool_config = { "toolChoice": {"auto": {}}, "tools": [ { "toolSpec": { "name": "get_order_by_id", "description": "Retrieves the details of a specific order based on the order ID.", "inputSchema": { "json": { "type": "object", "properties": { "order_id": { "type": "string", "description": "The unique identifier for the order.", } }, "required": ["order_id"], }, }, }, } ]}
Đoạn mã trước chỉ hiển thị một ví dụ về định nghĩa công cụ, tuy nhiên trong quá trình triển khai có ba công cụ khác nhau được cấu hình. Để biết chi tiết đầy đủ, hãy tham khảo backend/tools_config/entry_intent_tool.py hoặc backend/tools_config/agent_tool.py
Khả năng này giúp mô hình dựa trên dữ liệu và hệ thống thực tế, giảm ảo giác bằng cách cung cấp thông tin thực tế, mở rộng khả năng của mô hình vượt ra ngoài những gì nó có thể tự làm và thực thi các mẫu nhất quán cho các tương tác hệ thống. Bản chất có cấu trúc của việc gọi hàm có nghĩa là mô hình chỉ có thể yêu cầu dữ liệu cụ thể thông qua các giao diện được xác định rõ ràng thay vì đưa ra các giả định.
LangGraph cung cấp framework điều phối để xây dựng các ứng dụng có trạng thái, nhiều bước bằng cách sử dụng phương pháp đồ thị có hướng. Nó cung cấp khả năng theo dõi rõ ràng trạng thái hội thoại, phân tách các mối quan tâm trong đó mỗi nút xử lý một giai đoạn hội thoại cụ thể, định tuyến có điều kiện để ra quyết định động dựa trên ngữ cảnh, phát hiện chu trình để xử lý các vòng lặp và các mẫu lặp lại, và kiến trúc linh hoạt dễ dàng mở rộng với các nút mới hoặc sửa đổi các luồng hiện có. Bạn có thể coi LangGraph như việc tạo một sơ đồ cho cuộc hội thoại của mình, trong đó mỗi hộp đại diện cho một phần cụ thể của cuộc hội thoại và các mũi tên hiển thị cách di chuyển giữa chúng.
Luồng hội thoại được triển khai dưới dạng đồ thị có hướng bằng LangGraph. Để tham khảo, hãy kiểm tra đồ họa luồng tác nhân trong phần Kiến trúc giải pháp.
Đoạn mã sau hiển thị đồ thị trạng thái là ngữ cảnh đồ thị cấu trúc được sử dụng để thu thập thông tin qua các tương tác người dùng khác nhau, cung cấp cho tác nhân ngữ cảnh phù hợp:
class State(TypedDict): # Messages tracked in the conversation history messages: list # Transcription attributes tracks updates posted by the agent transcript: list # Session Id is the unique identifier attribute of the conversation session_id: str # Order number order_number: str # tracks in the conversation is still active session_end: bool # tracks the current node in the conversation current_turn: int # tracks the next node in the conversation next_node: str # track status of the confirmation order_confirmed: bool # track status of the orders eligible order_info_found: bool
Đối tượng trạng thái này duy trì thông tin liên quan về cuộc hội thoại, cho phép hệ thống đưa ra các quyết định sáng suốt về định tuyến và phản hồi.
Luồng hội thoại của chúng tôi sử dụng ba nút chính: nút ý định ban đầu xử lý các yêu cầu ban đầu của người dùng và trích xuất thông tin chính, nút xác nhận đơn hàng xác minh chi tiết và xác nhận ý định của người dùng, và nút giải quyết thực hiện các hành động được yêu cầu và cung cấp kết thúc. Cách tiếp cận này cung cấp quản lý trạng thái rõ ràng, định tuyến có điều kiện, phân tách các mối quan tâm, khả năng tái sử dụng trên các luồng hội thoại khác nhau và trực quan hóa rõ ràng các đường dẫn hội thoại:
# Define nodes and edgesgraph_builder = StateGraph(State)# Add nodesgraph_builder.add_node("entry_intent", entry_intent.node)graph_builder.add_node("order_confirmation", order_confirmation.node)graph_builder.add_node("resolution", resolution.node)# Add conditional edges with routing logicgraph_builder.add_conditional_edges( START, initial_router, { 'entry_intent': 'entry_intent', 'order_confirmation': 'order_confirmation', 'resolution': 'resolution' })
Các cạnh giữa các nút sử dụng logic có điều kiện để xác định luồng trên một thực thi thời gian chạy như được hiển thị trong đoạn mã sau dựa trên nội dung của StateGraph:
graph_builder.add_conditional_edges( 'entry_intent', lambda x: x["next_node"], { 'order_confirmation': 'order_confirmation', '__end__': END })
Mỗi nút trong đồ thị hội thoại được triển khai dưới dạng một hàm Python xử lý trạng thái hiện tại và trả về một trạng thái được cập nhật. Nút ý định ban đầu xử lý các yêu cầu ban đầu của người dùng, trích xuất thông tin chính như số đơn hàng và xác định các bước tiếp theo bằng cách diễn giải các truy vấn của khách hàng. Nó sử dụng các công cụ để tìm kiếm thông tin đơn hàng liên quan, trích xuất các chi tiết chính như số đơn hàng hoặc định danh khách hàng, và xác định xem có đủ thông tin để tiếp tục hay không. Nút xác nhận đơn hàng xác minh chi tiết và xác nhận ý định của người dùng bằng cách trình bày chi tiết đơn hàng đã tìm thấy cho khách hàng, xác minh đây là đơn hàng chính xác đang được thảo luận và xác nhận ý định của khách hàng liên quan đến đơn hàng. Nút giải quyết thực hiện các hành động được yêu cầu và cung cấp kết thúc bằng cách thực hiện các hành động cần thiết như cung cấp trạng thái hoặc hủy đơn hàng, xác nhận hoàn thành thành công các hành động được yêu cầu, trả lời các câu hỏi tiếp theo về đơn hàng và cung cấp một kết luận tự nhiên cho cuộc hội thoại:
@mlflow.trace(span_type=SpanType.AGENT)def node(state: Dict[str, Any]) -> Dict[str, Any]: """ Entry intent node for processing chat messages and managing order information. This node handles: 1. Initial message processing with the chat model 2. Tool execution for order information retrieval 3. State management and updates 4. Dynamic routing based on order information """
Để biết chi tiết triển khai đầy đủ, hãy tham khảo: backend/nodes.
Các nút sử dụng một mẫu nhất quán để trích xuất thông tin liên quan từ trạng thái, xử lý tin nhắn người dùng bằng LLM, thực hiện các công cụ cần thiết, cập nhật trạng thái với thông tin mới và xác định nút tiếp theo trong luồng.
Khả năng quan sát trở nên thiết yếu vì các ứng dụng LLM đặt ra những thách thức độc đáo bao gồm đầu ra không xác định trong đó cùng một đầu vào có thể tạo ra các kết quả khác nhau, các chuỗi phức tạp trong đó nhiều mô hình và công cụ tương tác theo trình tự, giám sát hiệu suất trong đó độ trễ ảnh hưởng đến trải nghiệm người dùng và đánh giá chất lượng đòi hỏi các số liệu chuyên biệt. MLflow được quản lý trên Amazon SageMaker AI giải quyết những thách thức này thông qua các khả năng theo dõi chuyên biệt để giám sát các tương tác mô hình, độ trễ, mức sử dụng token và đường dẫn hội thoại.
Mỗi nút hội thoại được trang trí bằng tính năng theo dõi MLflow:
@mlflow.trace(span_type=SpanType.AGENT)def node(state: Dict[str, Any]) -> Dict[str, Any]: # Node implementation
Trình trang trí đơn giản này tự động thu thập thông tin phong phú về việc thực thi của mỗi nút. Nó ghi lại các lệnh gọi mô hình, hiển thị các mô hình nào đã được gọi và với các tham số nào. Nó theo dõi các số liệu phản hồi như độ trễ, mức sử dụng token và lý do hoàn thành. Nó ánh xạ các đường dẫn hội thoại, hiển thị cách người dùng điều hướng qua đồ thị hội thoại. Nó cũng ghi lại việc sử dụng công cụ, cho biết công cụ nào đã được gọi và kết quả của chúng, cũng như các mẫu lỗi xác định khi nào và tại sao lỗi xảy ra.
Dữ liệu được thu thập được trực quan hóa trong giao diện người dùng MLflow, cung cấp thông tin chi tiết để giám sát hiệu suất sản xuất, cơ hội tối ưu hóa, gỡ lỗi và đo lường tác động kinh doanh.
Các dấu vết MLflow ghi lại toàn bộ quá trình thực thi quy trình làm việc của tác nhân bao gồm các nút liên quan đến tương tác, đầu vào và đầu ra cho mỗi nút, và siêu dữ liệu bổ sung như độ trễ, các lệnh gọi công cụ và trình tự hội thoại.
Ảnh chụp màn hình sau hiển thị một ví dụ về các dấu vết máy chủ theo dõi MLFlow ghi lại quá trình thực thi quy trình làm việc của tác nhân, bao gồm các nút liên quan, đầu vào và đầu ra cho mỗi nút, và siêu dữ liệu như độ trễ, các lệnh gọi công cụ và trình tự hội thoại.
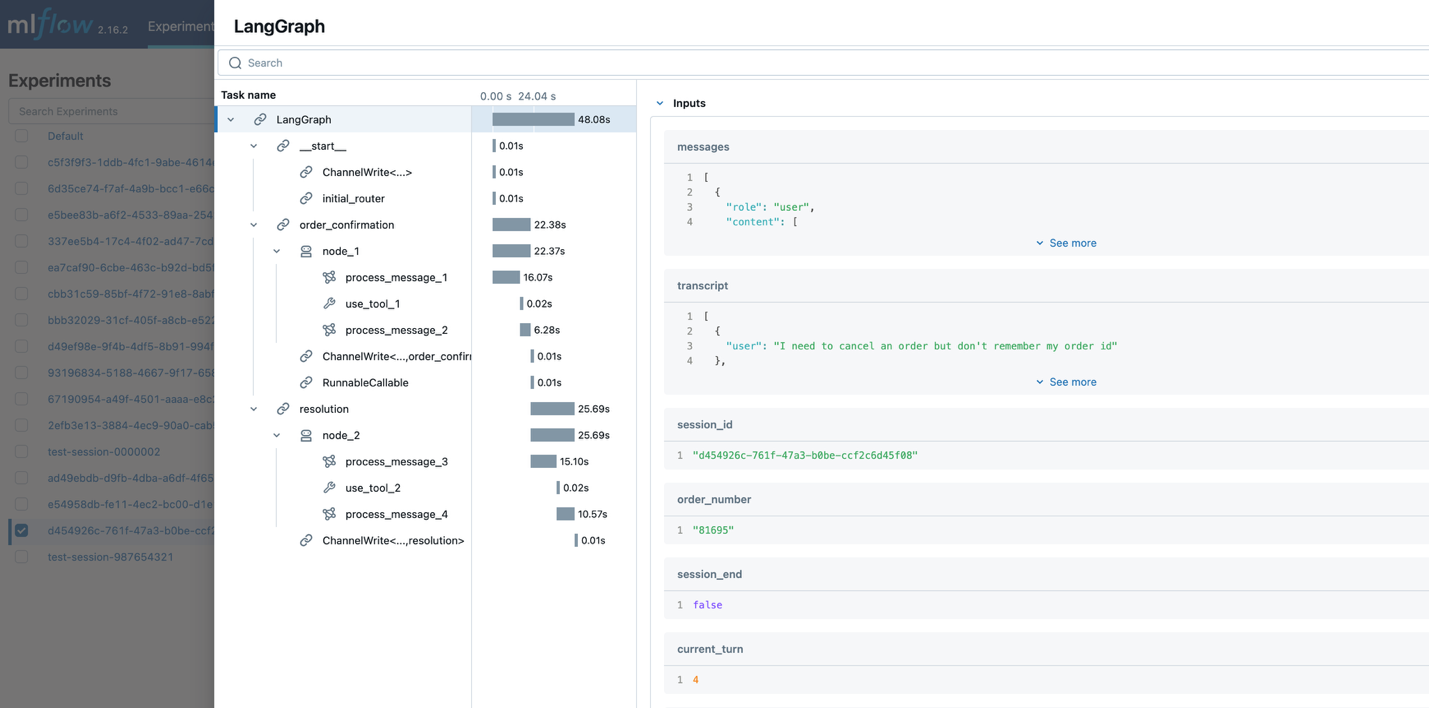
Khả năng truy xuất nguồn gốc này rất quan trọng để cải thiện liên tục tác nhân. Các nhà phát triển có thể xác định các mẫu trong các cuộc hội thoại thành công và các cơ hội để tối ưu hóa.
Điều kiện tiên quyết
Để xây dựng một tác nhân AI đàm thoại phi máy chủ sử dụng Claude với LangGraph và MLflow được quản lý trên Amazon SageMaker AI, bạn cần các điều kiện tiên quyết sau:
Yêu cầu tài khoản AWS:
- Một tài khoản AWS có quyền tạo các hàm Lambda, bảng DynamoDB, API Gateway, S3 bucket, CloudFront distribution, các phiên bản Amazon RDS for PostgreSQL và tài nguyên Amazon Virtual Private Cloud (Amazon VPC)
- Quyền truy cập Amazon Bedrock với Claude 3.5 Sonnet của Anthropic được bật
Môi trường phát triển:
- AWS Command Line Interface (AWS CLI) được cài đặt trên máy cục bộ của bạn
- Các tiện ích Git và Docker được cài đặt trên máy cục bộ của bạn
- Quyền tạo tài nguyên AWS
- Python 3.12 trở lên
- Node.js 20+ và npm được cài đặt
- AWS Cloud Development Kit (AWS CDK) CLI được cài đặt (
npm install -g aws-cdk) - Vai trò Amazon CloudWatch Logs Amazon Resource Name (ARN) được cấu hình trong cài đặt tài khoản API Gateway (bắt buộc để ghi nhật ký API Gateway):
- Tạo một vai trò AWS Identity and Access Management (IAM) với các quyền cần thiết. Để được hướng dẫn, hãy tham khảo Quyền ghi nhật ký CloudWatch.
- Cấu hình vai trò trong bảng điều khiển API Gateway. Chỉ làm theo các bước 1–3.
Kỹ năng và kiến thức:
- Quen thuộc với kiến trúc phi máy chủ
- Kiến thức cơ bản về Python và React
- Hiểu biết về các dịch vụ AWS (AWS Lambda, Amazon DynamoDB, Amazon VPC)
Hướng dẫn triển khai
Để xây dựng một tác nhân AI đàm thoại phi máy chủ sử dụng Claude với LangGraph và MLflow được quản lý trên Amazon SageMaker AI, hãy làm theo các bước sau:
- Clone kho lưu trữ và thiết lập thư mục gốc của dự án:
git clone https://github.com/aws-samples/sample-aws-genai-serverless-orchestration-chatbot-mlflow.gitcd sample-aws-genai-serverless-orchestration-chatbot-mlflowexport PROJECT_ROOT=$(pwd)
- Bootstrap môi trường AWS của bạn (bắt buộc nếu bootstrap chưa được thực hiện trước đó):
cd $PROJECT_ROOT/infracdk bootstrap
- Cài đặt các dependency:
# Install dependenciescd $PROJECT_ROOTmake install
- Xây dựng và triển khai ứng dụng:
cd $PROJECT_ROOTmake deploy
Script này sẽ:
- Triển khai cơ sở hạ tầng backend, bao gồm VPC, hàm Lambda, cơ sở dữ liệu và MLflow
- Lấy ARN của Lambda từ stack backend
- Triển khai frontend với WebSocket API Gateway tích hợp
- Lấy URL WebSocket API thực tế từ stack đã triển khai
- Tạo và tải lên
config.jsonvới cấu hình thời gian chạy lên Amazon S3
Dọn dẹp tài nguyên
Để tránh các khoản phí liên tục từ các tài nguyên được tạo trong bài đăng này, hãy dọn dẹp các tài nguyên khi chúng không còn cần thiết. Sử dụng lệnh sau:
cd $PROJECT_ROOTmake clean
Kết luận
Trong bài đăng này, chúng tôi đã chỉ ra cách kết hợp khả năng suy luận của LLM từ Amazon Bedrock, khả năng điều phối của LangGraph và khả năng quan sát của MLflow được quản lý trên Amazon SageMaker AI có thể được sử dụng để xây dựng các tác nhân dịch vụ khách hàng. Kiến trúc này cho phép các cuộc hội thoại tự nhiên, nhiều lượt trong khi vẫn duy trì ngữ cảnh qua các tương tác, tích hợp liền mạch với các hệ thống backend để thực hiện các hành động trong thế giới thực như tra cứu và hủy đơn hàng.
Khả năng quan sát toàn diện được cung cấp bởi MLflow để các nhà phát triển có thể giám sát luồng hội thoại, theo dõi hiệu suất mô hình và tối ưu hóa hệ thống dựa trên các mẫu sử dụng thực tế. Bằng cách sử dụng các dịch vụ phi máy chủ của AWS, giải pháp này tự động mở rộng quy mô để xử lý các khối lượng công việc khác nhau trong khi vẫn duy trì hiệu quả chi phí thông qua mô hình định giá trả theo mức sử dụng. Bạn có thể sử dụng bản thiết kế này để xây dựng các giải pháp AI đàm thoại tinh vi thu hẹp khoảng cách giữa tương tác ngôn ngữ tự nhiên và các quy trình kinh doanh có cấu trúc, mang lại giá trị kinh doanh thông qua trải nghiệm khách hàng được cải thiện và hiệu quả hoạt động.
Bạn đã sẵn sàng đưa tác nhân AI đàm thoại của mình đi xa hơn chưa? Hãy bắt đầu với Amazon Bedrock AgentCore để tăng tốc các tác nhân của bạn lên sản xuất với bộ nhớ thông minh và một cổng để cho phép truy cập an toàn, có kiểm soát vào các công cụ và dữ liệu. Khám phá cách MLflow tích hợp với Bedrock AgentCore Runtime để có khả năng quan sát toàn diện trên toàn bộ hệ sinh thái tác nhân của bạn.
Về tác giả

Sri Potluri là Kiến trúc sư Cơ sở hạ tầng Đám mây tại AWS. Anh ấy đam mê giải quyết các vấn đề phức tạp và cung cấp các giải pháp có cấu trúc tốt cho nhiều khách hàng khác nhau. Chuyên môn của anh ấy trải rộng trên một loạt các công nghệ đám mây, cung cấp cơ sở hạ tầng có khả năng mở rộng và đáng tin cậy phù hợp với những thách thức độc đáo của từng dự án.

Luis Felipe Yepez Barrios là Kỹ sư Học máy thuộc AWS Professional Services, tập trung vào các hệ thống phân tán có khả năng mở rộng và công cụ tự động hóa để đẩy nhanh đổi mới khoa học trong lĩnh vực học máy (ML). Hơn nữa, anh ấy hỗ trợ các khách hàng doanh nghiệp tối ưu hóa các giải pháp học máy của họ thông qua các dịch vụ AWS.
