Tác giả: Yuan Wei, Sharon Li, và Xin Hao
Ngày phát hành: 02 MAR 2026
Chuyên mục: Amazon Bedrock, Amazon Machine Learning, Amazon Nova, Artificial Intelligence, Best Practices
Các mô hình ngôn ngữ lớn (LLM) hoạt động tốt trên các tác vụ tổng quát nhưng gặp khó khăn với công việc chuyên biệt đòi hỏi hiểu dữ liệu độc quyền, quy trình nội bộ và thuật ngữ chuyên ngành. Supervised fine-tuning (SFT) điều chỉnh LLM cho các ngữ cảnh tổ chức này. SFT có thể được triển khai thông qua hai phương pháp riêng biệt: Parameter-Efficient Fine-Tuning (PEFT), chỉ cập nhật một tập hợp con các tham số mô hình, mang lại quá trình huấn luyện nhanh hơn và chi phí tính toán thấp hơn trong khi vẫn duy trì cải thiện hiệu suất hợp lý; Full-rank SFT, cập nhật tất cả các tham số mô hình thay vì một tập hợp con và tích hợp nhiều kiến thức miền hơn PEFT.
Full-rank SFT thường đối mặt với một thách thức: quên thảm khốc. Khi các mô hình học các mẫu cụ thể theo miền, chúng mất đi các khả năng tổng quát bao gồm tuân thủ hướng dẫn, suy luận và kiến thức rộng. Các tổ chức phải lựa chọn giữa chuyên môn miền và trí thông minh tổng quát, điều này hạn chế tiện ích của mô hình trong các trường hợp sử dụng của doanh nghiệp.
Amazon Nova Forge giải quyết vấn đề này. Nova Forge là một dịch vụ mới mà bạn có thể sử dụng để xây dựng các mô hình tiên phong của riêng mình bằng cách sử dụng Nova. Khách hàng của Nova Forge có thể bắt đầu phát triển từ các điểm kiểm tra mô hình ban đầu, kết hợp dữ liệu độc quyền với dữ liệu huấn luyện được Amazon Nova tuyển chọn và lưu trữ các mô hình tùy chỉnh của họ một cách an toàn trên AWS.
Trong bài viết này, chúng tôi chia sẻ kết quả từ đánh giá toàn diện của nhóm Khoa học Ứng dụng AWS Trung Quốc về Nova Forge bằng cách sử dụng một tác vụ phân loại Voice of Customer (VOC) đầy thách thức, được so sánh với các mô hình mã nguồn mở. Với hơn 16.000 mẫu bình luận của khách hàng trên một hệ thống phân cấp nhãn bốn cấp phức tạp chứa 1.420 danh mục lá, chúng tôi chứng minh cách tiếp cận trộn dữ liệu của Nova Forge mang lại hai lợi thế:
- Cải thiện hiệu suất tác vụ trong miền: đạt được cải thiện điểm F1 17%
- Duy trì khả năng tổng quát: duy trì điểm MMLU (Massive Multitask Language Understanding) gần như ban đầu và khả năng tuân thủ hướng dẫn sau khi tinh chỉnh
Thách thức: phân loại phản hồi khách hàng trong thế giới thực
Hãy xem xét một kịch bản điển hình tại một công ty thương mại điện tử lớn. Nhóm trải nghiệm khách hàng nhận được hàng nghìn bình luận của khách hàng hàng ngày với phản hồi chi tiết về chất lượng sản phẩm, trải nghiệm giao hàng, vấn đề thanh toán, khả năng sử dụng trang web và tương tác dịch vụ khách hàng. Để hoạt động hiệu quả, họ cần một LLM có thể tự động phân loại mỗi bình luận vào các danh mục có thể hành động với độ chính xác cao. Mỗi phân loại phải đủ cụ thể để chuyển vấn đề đến đúng nhóm: hậu cần, tài chính, phát triển hoặc dịch vụ khách hàng, và kích hoạt quy trình làm việc phù hợp. Điều này đòi hỏi chuyên môn hóa miền.
Tuy nhiên, cùng một LLM này không hoạt động độc lập. Trong toàn bộ tổ chức của bạn, các nhóm cần mô hình để:
- Tạo phản hồi hướng tới khách hàng yêu cầu kỹ năng giao tiếp tổng quát
- Thực hiện phân tích dữ liệu yêu cầu suy luận toán học và logic
- Soạn thảo tài liệu tuân thủ các hướng dẫn định dạng cụ thể
Điều này đòi hỏi khả năng tổng quát rộng—tuân thủ hướng dẫn, suy luận, kiến thức trên các miền và khả năng giao tiếp trôi chảy.
Phương pháp đánh giá
Tổng quan thử nghiệm
Để kiểm tra xem Nova Forge có thể mang lại cả chuyên môn hóa miền và khả năng tổng quát hay không, chúng tôi đã thiết kế một khung đánh giá kép đo lường hiệu suất trên hai chiều.
Đối với hiệu suất cụ thể theo miền, chúng tôi sử dụng một bộ dữ liệu Voice of Customer (VOC) thực tế được lấy từ các đánh giá thực tế của khách hàng. Bộ dữ liệu chứa 14.511 mẫu huấn luyện và 861 mẫu thử nghiệm, phản ánh dữ liệu doanh nghiệp quy mô sản xuất. Bộ dữ liệu sử dụng một phân loại bốn cấp, trong đó Cấp 4 đại diện cho các danh mục lá (mục tiêu phân loại cuối cùng). Mỗi danh mục bao gồm một giải thích mô tả về phạm vi của nó. Ví dụ về các danh mục:
| Cấp 1 | Cấp 2 | Cấp 3 | Cấp 4 (danh mục lá) |
|---|---|---|---|
| Installation – app configuration | Initial setup guidance | Setup process | Trải nghiệm cài đặt dễ dàng: Đặc điểm và mức độ phức tạp của quy trình cài đặt |
| Usage – hardware experience | Night vision performance | Low-light Image quality | Độ rõ nét của tầm nhìn ban đêm: Chế độ tầm nhìn ban đêm tạo ra hình ảnh trong điều kiện ánh sáng yếu hoặc tối |
| Usage – hardware experience | Pan-tilt-zoom functionality | Rotation capability | Xoay 360 độ: Camera có thể xoay đủ 360 độ, cung cấp phạm vi bao phủ toàn cảnh |
| After-sales policy and cost | Return and exchange policy | Return process execution | Hoàn trả sản phẩm đã hoàn tất: Khách hàng đã khởi tạo và hoàn tất việc trả lại sản phẩm do các vấn đề về chức năng |
Bộ dữ liệu cho thấy sự mất cân bằng lớp cực đoan điển hình của môi trường phản hồi khách hàng trong thế giới thực. Hình ảnh sau đây hiển thị phân phối lớp:
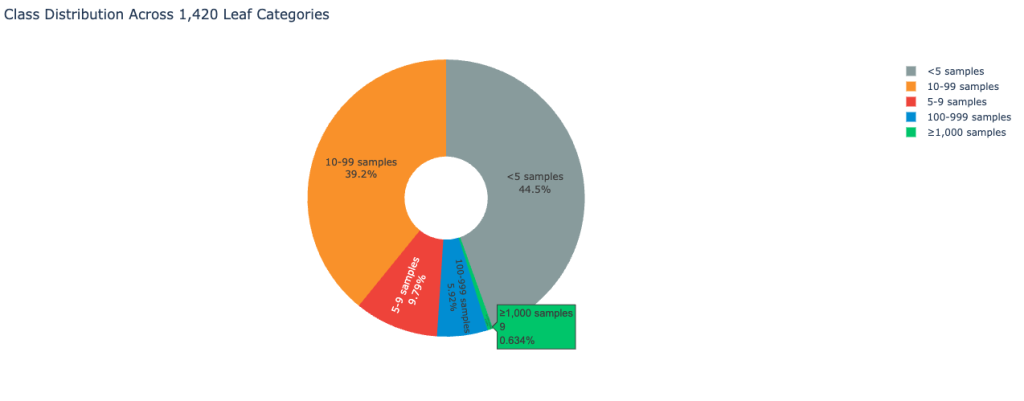
Do đó, bộ dữ liệu đặt ra một thách thức đáng kể đối với độ chính xác phân loại.
Để đánh giá các khả năng tổng quát, chúng tôi sử dụng tập hợp thử nghiệm công khai của chuẩn MMLU (Massive Multitask Language Understanding) (tất cả các tập con). Bài kiểm tra bao gồm các môn học trong khoa học nhân văn, khoa học xã hội, khoa học tự nhiên và các lĩnh vực khác quan trọng đối với một số người. Trong bài viết này, MMLU đóng vai trò là thước đo cho khả năng duy trì tổng quát. Chúng tôi sử dụng nó để đo lường liệu việc tinh chỉnh có giám sát có cải thiện hiệu suất miền với chi phí làm suy giảm các hành vi mô hình nền tảng hay không, và để đánh giá hiệu quả của việc trộn dữ liệu Nova trong việc giảm thiểu hiện tượng quên thảm khốc.
| Mục | Mô tả |
|---|---|
| Total samples | 15,372 đánh giá của khách hàng |
| Label hierarchy | Phân loại 4 cấp, tổng cộng 1.420 danh mục |
| Training set | 14.511 mẫu |
| Test set | 861 mẫu |
| MMLU Benchmark all (test split) | 14.000 mẫu |
Đánh giá tác vụ trong miền: phân loại phản hồi khách hàng
Để hiểu cách Nova Forge hoạt động trong các kịch bản doanh nghiệp thực tế, trước tiên chúng tôi đánh giá độ chính xác của mô hình trên tác vụ phân loại VOC trước và sau khi tinh chỉnh có giám sát. Với cách tiếp cận này, chúng tôi có thể định lượng các lợi ích thích ứng miền trong khi thiết lập một đường cơ sở để phân tích độ bền sau đó.
Đánh giá mô hình cơ sở
Chúng tôi bắt đầu với đánh giá mô hình cơ sở để đánh giá hiệu suất sẵn có trên tác vụ phân loại VOC mà không cần tinh chỉnh cụ thể cho tác vụ. Thiết lập này thiết lập khả năng vốn có của mỗi mô hình để xử lý phân loại chi tiết cao dưới các ràng buộc định dạng đầu ra nghiêm ngặt. Lời nhắc sau đây được sử dụng cho tác vụ phân loại VOC:
# Role DefinitionYou are a rigorous customer experience classification system. Your sole responsibility is to map user feedback to the existing label taxonomy at Level 1 through Level 4 (L1–L4). You must strictly follow the predefined taxonomy structure and must not create, modify, or infer any new labels.## Operating Principles### 1. Strict taxonomy alignmentAll classifications must be fully grounded in the provided label taxonomy and strictly adhere to its hierarchical structure.### 2. Feedback decomposition using MECE principlesA single piece of user feedback may contain one or multiple issues. You must carefully analyze all issues described and decompose the feedback into multiple non-overlapping segments, following the MECE (Mutually Exclusive, Collectively Exhaustive) principle:- **Semantic singularity**: Each segment describes only one issue, function, service, or touchpoint (for example, pricing, performance, or UI).- **Independence**: Segments must not overlap in meaning.- **Complete coverage**: All information in the original feedback must be preserved without omission.### 3. No taxonomy expansionYou must not invent, infer, or modify any labels or taxonomy levels.## Label TaxonomyThe following section provides the label taxonomy: {tag category}. Use this taxonomy to perform L1–L4 classification for the original VOC feedback. No taxonomy expansion is allowed.## Task InstructionsYou will be given a piece of user feedback: {user comment}. Users may come from different regions and use different languages. You must accurately understand the user's language and intent before assigning labels.Refer to the provided examples for the expected labeling format.## Output FormatReturn the classification results in JSON format only. For each feedback segment, output the original text along with the corresponding L1–L4 labels and sentiment. Do not generate or rewrite content.
json[{"content": "","L1": "","L2": "","L3": "","L4": "","emotion": ""}]
```Để đánh giá mô hình cơ sở, chúng tôi đã chọn:* [**Amazon Nova 2 Lite**](https://aws.amazon.com/blogs/aws/introducing-amazon-nova-2-lite-a-fast-cost-effective-reasoning-model/): Được đánh giá trên [Amazon Bedrock](https://aws.amazon.com/bedrock/?nc2=type_a)* [**Qwen3-30B-A3B**](https://huggingface.co/Qwen/Qwen3-30B-A3B): Mô hình mã nguồn mở được triển khai trên [Amazon Elastic Compute Cloud (Amazon EC2)](https://aws.amazon.com/ec2/?nc2=type_a) với [vLLM](https://github.com/vllm-project/vllm)| Mô hình | Precision | Recall | F1-Score || :--- | :--- | :--- | :--- || Nova 2 Lite | 0.4596 | 0.3627 | 0.387 || Qwen3-30B-A3B | 0.4567 | 0.3864 | 0.394 |Điểm F1 cho thấy **Nova 2 Lite và Qwen3-30B-A3B thể hiện hiệu suất tương đương** trên tác vụ cụ thể theo miền này, với cả hai mô hình đều đạt điểm F1 gần 0.39. Những kết quả này cũng làm nổi bật khó khăn cố hữu của tác vụ: ngay cả các mô hình nền tảng mạnh mẽ cũng gặp khó khăn với phân loại nhãn chi tiết khi không có dữ liệu cụ thể theo miền được cung cấp.**Tinh chỉnh có giám sát**Sau đó, chúng tôi áp dụng **tinh chỉnh có giám sát toàn tham số (SFT)** sử dụng dữ liệu VOC của khách hàng. Tất cả các mô hình được tinh chỉnh bằng cùng một bộ dữ liệu và cấu hình huấn luyện tương đương để so sánh công bằng.**Cơ sở hạ tầng huấn luyện:*** **Nova 2 Lite:** Được tinh chỉnh trên cụm [Amazon SageMaker](https://aws.amazon.com/sagemaker/?nc2=type_a) HyperPod sử dụng bốn phiên bản p5.48xlarge (như được chỉ định trong [chủ đề Nova customization SageMaker hyperpod trong Hướng dẫn dành cho nhà phát triển AI của Amazon SageMaker](https://docs.aws.amazon.com/sagemaker/latest/dg/nova-hp.html))* **Qwen3-30B-A3B:** Được tinh chỉnh trên Amazon EC2 sử dụng các phiên bản p6-b200.48xlarge**So sánh hiệu suất tác vụ trong miền**| Mô hình | Dữ liệu huấn luyện | Precision | Recall | F1-Score || :--- | :--- | :--- | :--- | :--- || Nova 2 Lite | None (baseline) | 0.4596 | 0.3627 | 0.387 || Nova 2 Lite | Customer data only | 0.6048 | 0.5266 | 0.5537 || Qwen3-30B | Customer data only | 0.5933 | 0.5333 | 0.5552 |Sau khi tinh chỉnh chỉ với dữ liệu khách hàng, **Nova 2 Lite đạt được cải thiện hiệu suất đáng kể**, với F1 tăng từ 0.387 lên 0.5537—mức tăng tuyệt đối 17 điểm. Kết quả này đưa mô hình Nova vào hàng đầu cho tác vụ này và làm cho hiệu suất của nó có thể so sánh với mô hình mã nguồn mở Qwen3-30B đã được tinh chỉnh. Những kết quả này xác nhận hiệu quả của **Nova full-parameter SFT** cho các khối lượng công việc phân loại doanh nghiệp phức tạp.**Đánh giá khả năng tổng quát: Chuẩn MMLU**Các mô hình được tinh chỉnh cho phân loại VOC thường được triển khai vượt ra ngoài một tác vụ duy nhất và được tích hợp vào các quy trình làm việc doanh nghiệp rộng lớn hơn. Việc duy trì các khả năng tổng quát là quan trọng. Các chuẩn công nghiệp như MMLU cung cấp một cơ chế hiệu quả để đánh giá các khả năng tổng quát và phát hiện hiện tượng quên thảm khốc trong các mô hình đã được tinh chỉnh.Đối với mô hình Nova đã được tinh chỉnh, Amazon SageMaker HyperPod cung cấp [các công thức đánh giá sẵn có](https://docs.aws.amazon.com/sagemaker/latest/dg/customize-fine-tune-evaluate-available-tasks.html) giúp hợp lý hóa việc đánh giá MMLU với cấu hình tối thiểu.| Mô hình | Dữ liệu huấn luyện | VOC F1-Score | Độ chính xác MMLU || :--- | :--- | :--- | :--- || Nova 2 Lite | None (baseline) | 0.38 | <span style="color: #339966">0.75</span> || Nova 2 Lite | Customer data only | 0.55 | <span style="color: #ff0000">0.47</span> || Nova 2 Lite | 75% customer + 25% Nova data | 0.5 | <span style="color: #339966">0.74</span> || Qwen3-30B | Customer data only | 0.55 | <span style="color: #ff0000">0.0038</span> |Khi Nova 2 Lite được tinh chỉnh chỉ sử dụng dữ liệu khách hàng, chúng tôi quan sát thấy **sự sụt giảm đáng kể về độ chính xác MMLU từ 0.75 xuống 0.47**, cho thấy sự mất mát các khả năng tổng quát. Sự suy giảm này thậm chí còn rõ rệt hơn đối với mô hình Qwen, vốn phần lớn mất khả năng tuân thủ hướng dẫn sau khi tinh chỉnh. Một ví dụ về đầu ra bị suy giảm của mô hình Qwen:
Hành vi này cũng liên quan đến thiết kế lời nhắc VOC, nơi kiến thức danh mục được nội hóa thông qua tinh chỉnh có giám sát—một cách tiếp cận phổ biến trong các hệ thống phân loại quy mô lớn.
Đáng chú ý, khi trộn dữ liệu Nova được áp dụng trong quá trình tinh chỉnh, Nova 2 Lite duy trì hiệu suất tổng quát gần như ban đầu. Độ chính xác MMLU vẫn ở mức 0.74, chỉ thấp hơn 0.01 so với đường cơ sở ban đầu, trong khi VOC F1 vẫn cải thiện 12 điểm (0.38 → 0.50). Điều này xác nhận rằng trộn dữ liệu Nova là một cơ chế thực tế và hiệu quả để giảm thiểu hiện tượng quên thảm khốc trong khi vẫn duy trì hiệu suất miền.
Các phát hiện chính và khuyến nghị thực tế
Đánh giá này cho thấy rằng khi mô hình cơ sở cung cấp một nền tảng vững chắc, tinh chỉnh có giám sát toàn tham số trên Amazon Nova Forge có thể mang lại những lợi ích đáng kể cho các tác vụ phân loại doanh nghiệp phức tạp. Đồng thời, các kết quả xác nhận rằng hiện tượng quên thảm khốc là một mối lo ngại thực sự trong các quy trình tinh chỉnh sản xuất. Việc tinh chỉnh chỉ với dữ liệu khách hàng có thể làm suy giảm các khả năng tổng quát như tuân thủ hướng dẫn và suy luận, hạn chế khả năng sử dụng của mô hình trong các kịch bản kinh doanh rộng lớn hơn.
Khả năng trộn dữ liệu của Nova Forge cung cấp một chiến lược giảm thiểu hiệu quả. Bằng cách kết hợp dữ liệu khách hàng với các bộ dữ liệu được Nova tuyển chọn trong quá trình tinh chỉnh, các nhóm có thể duy trì các khả năng tổng quát gần như ban đầu trong khi vẫn tiếp tục đạt được hiệu suất mạnh mẽ theo miền cụ thể.
Dựa trên những phát hiện này, chúng tôi khuyến nghị các thực hành sau khi sử dụng Nova Forge:
- Sử dụng tinh chỉnh có giám sát để tối đa hóa hiệu suất trong miền cho các tác vụ phức tạp hoặc được tùy chỉnh cao.
- Áp dụng trộn dữ liệu Nova khi các mô hình được kỳ vọng hỗ trợ nhiều quy trình làm việc tổng quát trong sản xuất, để giảm thiểu rủi ro quên thảm khốc.
Cùng nhau, các thực hành này giúp cân bằng việc tùy chỉnh mô hình với độ bền sản xuất, cho phép triển khai các mô hình đã được tinh chỉnh một cách đáng tin cậy hơn trong môi trường doanh nghiệp.

Kết luận
Trong bài viết này, chúng tôi đã chứng minh cách các tổ chức có thể xây dựng các mô hình AI chuyên biệt mà không làm giảm trí thông minh tổng quát với khả năng trộn dữ liệu của Nova Forge. Tùy thuộc vào trường hợp sử dụng và mục tiêu kinh doanh của bạn, Nova Forge có thể mang lại các lợi ích khác, bao gồm truy cập các điểm kiểm tra trong tất cả các giai đoạn phát triển mô hình và thực hiện học tăng cường với các hàm thưởng trong môi trường của bạn. Để bắt đầu với các thử nghiệm của mình, hãy xem Hướng dẫn dành cho nhà phát triển Nova Forge để biết tài liệu chi tiết.
Về tác giả

Yuan Wei là một Nhà khoa học Ứng dụng tại Amazon Web Services, làm việc với các khách hàng doanh nghiệp về các bằng chứng khái niệm và tư vấn kỹ thuật. Cô chuyên về các mô hình ngôn ngữ lớn và mô hình ngôn ngữ thị giác, tập trung vào việc đánh giá các kỹ thuật mới nổi dưới các ràng buộc về dữ liệu, chi phí và hệ thống trong thế giới thực.

Xin Hao là Chuyên gia Go-to-Market AI/ML cấp cao tại AWS, giúp khách hàng đạt được thành công với các mô hình Amazon Nova và các giải pháp AI tạo sinh liên quan. Anh có kinh nghiệm thực tế sâu rộng trong điện toán đám mây, AI/ML và AI tạo sinh. Trước khi gia nhập AWS, Xin đã dành hơn 10 năm trong lĩnh vực sản xuất công nghiệp, bao gồm tự động hóa công nghiệp và gia công CNC.

Sharon Li là Kiến trúc sư Giải pháp Chuyên gia AI/ML tại Amazon Web Services (AWS) có trụ sở tại Boston, Massachusetts. Với niềm đam mê tận dụng công nghệ tiên tiến, Sharon đi đầu trong việc phát triển và triển khai các giải pháp AI tạo sinh đổi mới trên nền tảng đám mây AWS.
