Tác giả: Sheng Chen và Eric Chapman
Ngày phát hành: 18 MAR 2026
Chuyên mục: Advanced (300), Amazon Elastic Kubernetes Service, Amazon Managed Grafana, Amazon Managed Service for Prometheus, Containers, Financial Services, Generative AI, Healthcare, Hybrid Cloud Management, Manufacturing, Technical How-to, Telecommunications
Các ứng dụng AI tạo sinh hiện đại yêu cầu triển khai gần nơi dữ liệu được tạo ra và các quyết định kinh doanh được đưa ra, nhưng điều này tạo ra những thách thức mới về hạ tầng. Các tổ chức trong lĩnh vực sản xuất, chăm sóc sức khỏe, tài chính và viễn thông cần cung cấp các khối lượng công việc AI có độ trễ thấp, hiệu quả năng lượng tại biên, đồng thời duy trì tính cục bộ của dữ liệu và tuân thủ quy định. Tuy nhiên, việc quản lý Kubernetes tại chỗ làm tăng độ phức tạp trong vận hành, có thể làm chậm quá trình đổi mới.
Bạn có thể sử dụng Amazon Elastic Kubernetes Service (Amazon EKS) Hybrid Nodes để giải quyết vấn đề này bằng cách kết nối hạ tầng tại chỗ với mặt phẳng điều khiển (control plane) của Amazon EKS dưới dạng các node từ xa. Điều này cho phép bạn tăng tốc triển khai khối lượng công việc AI với các quy trình vận hành nhất quán, đồng thời đáp ứng các yêu cầu về độ trễ, tuân thủ và lưu trú dữ liệu. EKS Hybrid Nodes loại bỏ sự phức tạp và gánh nặng của việc tự quản lý Kubernetes tại chỗ, giúp nhóm của bạn có thể tập trung vào việc triển khai các ứng dụng AI và thúc đẩy đổi mới. Nó cung cấp các quy trình làm việc và công cụ thống nhất cùng với giám sát tập trung và khả năng quan sát nâng cao trên toàn bộ hạ tầng phân tán của bạn.
EKS Hybrid Nodes cho phép bạn cung cấp các khả năng AI ở bất cứ nơi nào doanh nghiệp của bạn yêu cầu, chẳng hạn như các trường hợp sử dụng sau:
- Chạy các dịch vụ có độ trễ thấp tại các địa điểm tại chỗ, bao gồm suy luận thời gian thực tại biên.
- Huấn luyện mô hình với dữ liệu phải được giữ lại tại chỗ để đáp ứng các yêu cầu tuân thủ quy định.
- Triển khai khối lượng công việc suy luận gần dữ liệu nguồn, chẳng hạn như các ứng dụng Retrieval-Augmented Generation (RAG) sử dụng cơ sở tri thức cục bộ.
- Tái sử dụng đầu tư phần cứng hiện có.
Bài đăng này trình bày một ví dụ thực tế về việc tích hợp EKS Hybrid Nodes với NVIDIA DGX Spark, một nền tảng GPU nhỏ gọn và tiết kiệm năng lượng được tối ưu hóa cho việc triển khai AI tại biên. Trong bài đăng này, chúng tôi sẽ hướng dẫn bạn triển khai một mô hình ngôn ngữ lớn (LLM) để suy luận AI tạo sinh có độ trễ thấp tại chỗ, thiết lập giám sát node và khả năng quan sát GPU với quản lý tập trung thông qua Amazon EKS. Mặc dù bài đăng này sử dụng DGX Spark, kiến trúc và các mẫu được thảo luận vẫn áp dụng cho các hệ thống NVIDIA DGX hoặc nền tảng GPU khác.
Tổng quan giải pháp
Để thực hiện hướng dẫn demo này, bạn sẽ tạo một cụm EKS với EKS Hybrid Nodes được bật và kết nối một DGX Spark tại chỗ làm hybrid node. Bạn sẽ cài đặt NVIDIA GPU Operator cho Kubernetes để cung cấp tài nguyên GPU cho suy luận AI tạo sinh cục bộ. Sau đó, bạn sẽ triển khai một LLM trên các hybrid node bằng cách sử dụng NVIDIA NIM, đây là một bộ microservice được NVIDIA tối ưu hóa để triển khai mô hình tăng tốc. Bạn cũng sẽ thiết lập EKS Node Monitoring Agent (NMA) của Amazon EKS để giám sát tình trạng node và phát hiện các vấn đề cụ thể của GPU. Cuối cùng, bạn sẽ tích hợp NVIDIA Data Center GPU Manager (DCGM) Exporter với Amazon Managed Service for Prometheus và Amazon Managed Grafana để cung cấp khả năng quan sát các chỉ số GPU trên các hybrid node.
Sơ đồ sau đây trình bày tổng quan cấp cao về kiến trúc giải pháp của chúng tôi.
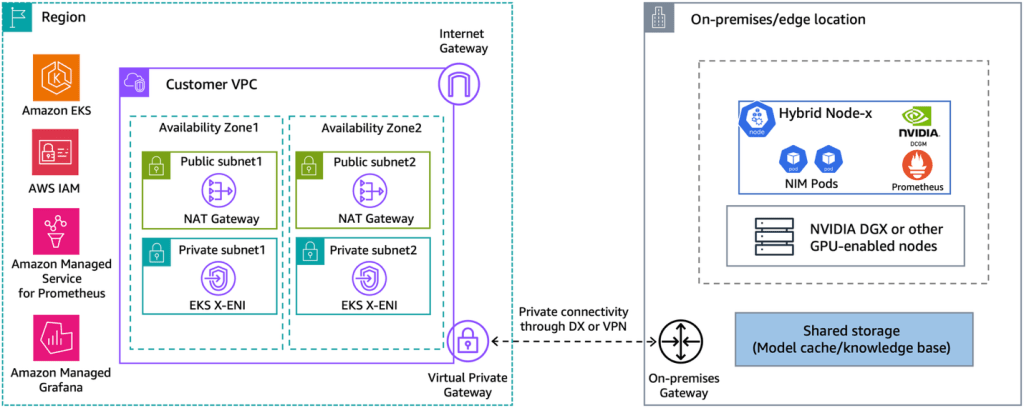
Hình 1: Kiến trúc lai để triển khai khối lượng công việc GenAI tại chỗ hoặc tại biên sử dụng Amazon EKS Hybrid Nodes với NVIDIA DGX
EKS Hybrid Nodes yêu cầu kết nối mạng riêng giữa môi trường tại chỗ hoặc biên của bạn và AWS Region. Kết nối này có thể được thiết lập bằng cách sử dụng AWS Direct Connect hoặc AWS Site-to-Site VPN vào Amazon Virtual Private Cloud (Amazon VPC) của bạn. Các khối CIDR (Classless Inter-Domain Routing) của node và pod cho các hybrid node và khối lượng công việc container của bạn phải là duy nhất và có thể định tuyến trên môi trường mạng của bạn. Bạn cung cấp các CIDR này làm giá trị RemoteNodeNetwork và RemotePodNetwork khi tạo cụm EKS với hybrid node.
Hướng dẫn này không đề cập đến các điều kiện tiên quyết về mạng lai cho EKS Hybrid Nodes. Truy cập hướng dẫn sử dụng Amazon EKS để biết chi tiết.
Điều kiện tiên quyết
Các điều kiện tiên quyết sau đây là cần thiết để hoàn thành giải pháp này:
- Amazon VPC với hai subnet riêng tư và hai subnet công cộng, trên hai Availability Zones (AZs).
- Một cụm EKS với hybrid node được bật. Làm theo hướng dẫn sử dụng Amazon EKS để triển khai.
- Các node tính toán tại chỗ chạy hệ điều hành tương thích.
- Kết nối riêng tư giữa mạng tại chỗ và Amazon VPC (thông qua VPN hoặc Direct Connect).
- Hai khối CIDR RFC-1918 hoặc CGNAT có thể định tuyến cho
RemoteNodeNetworkvàRemotePodNetwork. - Cấu hình tường lửa tại chỗ và các nhóm bảo mật của cụm EKS để cho phép giao tiếp hai chiều giữa mặt phẳng điều khiển Amazon EKS và các CIDR của node và pod từ xa, theo các điều kiện tiên quyết về mạng.
- Hệ thống NVIDIA DGX (hoặc các hệ thống hỗ trợ GPU khác) làm hybrid node.
- Tài khoản NVIDIA NGC và khóa API để truy cập NIMs, xem tài liệu của NVIDIA.
- Các công cụ sau:
Hướng dẫn chi tiết
Các bước sau đây sẽ hướng dẫn bạn thực hiện giải pháp này.
Chuẩn bị EKS Hybrid Nodes
Ba phần sau đây sẽ hướng dẫn bạn chuẩn bị cho EKS Hybrid Nodes.
Chuẩn bị thông tin xác thực IAM
- Amazon EKS Hybrid Nodes sử dụng thông tin xác thực AWS Identity and Access Management (IAM) tạm thời được cung cấp bởi kích hoạt lai của AWS Systems Manager hoặc IAM Roles Anywhere để xác thực với cụm EKS. Làm theo hướng dẫn sử dụng Amazon EKS để tạo vai trò IAM Hybrid Nodes cần thiết (
AmazonEKSHybridNodesRole) bằng một trong hai tùy chọn. - Tạo một mục nhập truy cập Amazon EKS với vai trò IAM Hybrid Nodes để cho phép các node tại chỗ của bạn tham gia cụm. Truy cập Chuẩn bị quyền truy cập cụm cho hybrid node trong hướng dẫn sử dụng Amazon EKS để biết thêm chi tiết.
aws eks create-access-entry \--cluster-name <CLUSTER_NAME> \--principal-arn <HYBRID_NODES_ROLE_ARN> \--type HYBRID_LINUX
Cài đặt nodeadm và kết nối DGX Spark làm hybrid node
- Sử dụng EKS Hybrid Nodes CLI (nodeadm) để khởi động và cài đặt tất cả các thành phần cần thiết để các hybrid node của bạn tham gia cụm EKS. Demo này sử dụng phiên bản ARM64 của nodeadm cho DGX Spark.
curl -OL 'https://hybrid-assets.eks.amazonaws.com/releases/latest/bin/linux/arm64/nodeadm'chmod +x nodeadmnodeadm install 1.34 --credential-provider ssm
- Chuẩn bị một tệp cấu hình
nodeConfig.yamlbằng cách sử dụng thông tin xác thực IAM tạm thời được tạo trong phần trước. Sau đây là một ví dụ về việc sử dụng kích hoạt lai của Systems Manager cho thông tin xác thực hybrid node.
apiVersion: node.eks.aws/v1alpha1kind: NodeConfigspec: cluster: name: <CLUSTER_NAME> region: <CLUSTER_REGION> hybrid: ssm: activationCode: <SSM_ACTIVATION_CODE> activationId: <SSM_ACTIVATION_ID>
- Chạy lệnh
nodeadm initvớinodeConfig.yamlcủa bạn để kết nối các hybrid node của bạn vào cụm EKS.
nodeadm init --config-source file://nodeConfig.yaml
- Đối với các hybrid node hỗn hợp GPU và non-GPU, chúng tôi khuyên bạn nên thêm một taint
--register-with-taints=nvidia.com/gpu=Exists:NoSchedulevào các node GPU để tối đa hóa việc sử dụng tài nguyên GPU. Tham khảo tài liệu về cách sửa đổi cấu hình kubelet bằng cách sử dụngnodeadm.
Cài đặt Cilium Container Network Interface (CNI)
- Trước khi chạy khối lượng công việc trên hybrid node, bạn phải cài đặt một CNI tương thích. Đối với ví dụ này, chúng tôi sử dụng Cilium vì nó là CNI được AWS hỗ trợ cho EKS Hybrid Nodes.
Tạo một tệp cấu hình Cilium: cilium-values.yaml.
# BGP Control Plane for LoadBalancer servicesbgpControlPlane: enabled: true# NodePort servicesnodePort: enabled: true# Node affinity - Run Cilium only on hybrid nodesaffinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: eks.amazonaws.com/compute-type operator: In values: - hybrid # IPAM configuration for pod networkingipam: mode: cluster-pool operator: clusterPoolIPv4PodCIDRList: - 192.168.64.0/24 # RemotePodNetwork CIDR clusterPoolIPv4MaskSize: 25# Cilium Operator configurationoperator: rollOutPods: true unmanagedPodWatcher: restart: false affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: eks.amazonaws.com/compute-type operator: In values: - hybrid
- Cài đặt Cilium trên EKS Hybrid Nodes bằng Helm với cấu hình trên.
helm repo add cilium https://helm.cilium.io/CILIUM_VERSION=1.18.6helm install cilium cilium/cilium \--version ${CILIUM_VERSION} \--values cilium-values.yaml \--namespace kube-system
- Nếu bạn đang chạy webhook trên hybrid node, thì bạn phải đảm bảo rằng các Pod CIDR tại chỗ có thể định tuyến trên môi trường mạng lai, sử dụng các kỹ thuật như định tuyến BGP, định tuyến tĩnh hoặc ARP proxying. Demo này sử dụng mặt phẳng điều khiển Cilium BGP để bật BGP peering giữa các hybrid node và router tại chỗ, và để quảng bá Pod CIDR đến mạng tại chỗ.
Áp dụng cấu hình Cilium BGP sau cho cụm của bạn.
---apiVersion: cilium.io/v2kind: CiliumBGPClusterConfigmetadata: name: cilium-bgpspec: nodeSelector: matchExpressions: - key: eks.amazonaws.com/compute-type operator: In values: - hybrid bgpInstances: - name: "cilium-bgp" localASN: <NODES_ASN> peers: - name: "onprem-router" peerASN: <ONPREM_ROUTER_ASN> peerAddress: <ONPREM_ROUTER_IP> peerConfigRef: name: "cilium-peer"---apiVersion: cilium.io/v2kind: CiliumBGPPeerConfigmetadata: name: cilium-peerspec: timers: holdTimeSeconds: 30 keepAliveTimeSeconds: 10 gracefulRestart: enabled: true restartTimeSeconds: 120 families: - afi: ipv4 safi: unicast advertisements: matchLabels: advertise: "bgp"---apiVersion: cilium.io/v2kind: CiliumBGPAdvertisementmetadata: name: bgp-adv-pod labels: advertise: bgpspec: advertisements: - advertisementType: "PodCIDR"
- Xác thực rằng các node của bạn đã kết nối với cụm EKS và ở trạng thái
Ready.
$ kubectl get nodes -o wide -l eks.amazonaws.com/compute-type=hybridNAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIMEmi-0e06d30895cfcc155 Ready <none> 17d v1.34.2-eks-ecaa3a6 192.168.100.101 <none> Ubuntu 24.04.3 LTS 6.14.0-1015-nvidia containerd://2.2.1
Cài đặt NVIDIA GPU Operator cho Kubernetes
NVIDIA GPU Operator sử dụng khung operator của Kubernetes để tự động hóa quản lý vòng đời của các thành phần phần mềm NVIDIA cần thiết để cung cấp tài nguyên GPU. Các thành phần này bao gồm trình điều khiển NVIDIA (để bật CUDA), plugin thiết bị Kubernetes cho GPU, NVIDIA Container Toolkit, và giám sát dựa trên DCGM cùng các thành phần khác.
- Triển khai NVIDIA GPU Operator trên hybrid node bằng biểu đồ Helm chính thức.
helm repo add nvidia https://helm.ngc.nvidia.com/nvidiahelm repo updatehelm install gpu-operator nvidia/gpu-operator \--namespace gpu-operator \--create-namespace \--set driver.enabled=true \--set toolkit.enabled=true \--set devicePlugin.enabled=true \--set gfd.enabled=true \--set migManager.enabled=true \--set nodeStatusExporter.enabled=true \--set dcgmExporter.enabled=true \--set operator.defaultRuntime=containerd \--set operator.runtimeClass=nvidia \--wait
- Đợi cho đến khi tất cả các pod trong namespace
gpu-operatorđang chạy hoặc đã hoàn thành.
$ kubectl get pods -n gpu-operatorNAMESPACE NAME READY STATUS RESTARTS AGEgpu-operator gpu-feature-discovery-7jvph 1/1 Running 1 (2m39s ago) 15dgpu-operator gpu-operator-7569f8b499-7k59n 1/1 Running 1 (2m39s ago) 27mgpu-operator gpu-operator-node-feature-discovery-gc-55ffc49ccc-glq9l 1/1 Running 1 (2m39s ago) 27mgpu-operator gpu-operator-node-feature-discovery-master-6b5787f695-n92x4 1/1 Running 1 (2m39s ago) 27mgpu-operator gpu-operator-node-feature-discovery-worker-9wqq5 1/1 Running 1 (2m39s ago) 15dgpu-operator nvidia-container-toolkit-daemonset-f9brm 1/1 Running 1 (2m39s ago) 15dgpu-operator nvidia-cuda-validator-nzwmh 0/1 Completed 0 92sgpu-operator nvidia-dcgm-exporter-hn4vz 1/1 Running 1 (2m39s ago) 15dgpu-operator nvidia-device-plugin-daemonset-4kb5c 1/1 Running 1 (2m39s ago) 15dgpu-operator nvidia-node-status-exporter-xpz9j 1/1 Running 1 (2m39s ago) 15dgpu-operator nvidia-operator-validator-t662d 1/1 Running 1 (2m39s ago) 15d
- NVIDIA GPU Operator xác thực stack bằng cách sử dụng các pod
nvidia-operator-validatorvànvidia-cuda-validator. Xác minh nhật ký trên các pod này và xác nhận rằng các xác thực thành công.
$ kubectl logs -n gpu-operator nvidia-operator-validator-t662dDefaulted container "nvidia-operator-validator" out of: nvidia-operator-validator, driver-validation (init), toolkit-validation (init), cuda-validation (init), plugin-validation (init)all validations are successful$ kubectl logs -n gpu-operator nvidia-cuda-validator-nzwmhDefaulted container "nvidia-cuda-validator" out of: nvidia-cuda-validator, cuda-validation (init)cuda workload validation is successful
- GPU trong node DGX Spark hiện đã được hiển thị cho kubelet và có thể nhìn thấy trong nodes allocatable:
$ kubectl get nodes "-o=custom-columns=NAME:.metadata.name,GPU:.status.allocatable.nvidia\.com/gpu" -l eks.amazonaws.com/compute-type=hybridNAME GPUmi-0e06d30895cfcc155 1
Triển khai NVIDIA NIM để suy luận trên EKS Hybrid Nodes
- Để triển khai NVIDIA NIM, bạn phải thiết lập một khóa API NVIDIA NGC và tạo các secret của registry container bằng khóa đó.
kubectl create secret docker-registry ngc-secret --docker-server=nvcr.io --docker-username='$oauthtoken' --docker-password=$NGC_API_KEYkubectl create secret generic ngc-api --from-literal=NGC_API_KEY=$NGC_API_KEY
- Tải xuống biểu đồ Helm NIM bằng lệnh sau:
helm fetch https://helm.ngc.nvidia.com/nim/charts/nim-llm-<version_number>.tgz --username='$oauthtoken' --password=$NGC_API_KEYcd nim-deploy/helm
- Chọn một mô hình được hỗ trợ cho NVIDIA NIM dựa trên thông số kỹ thuật GPU của các hybrid node của bạn. Tạo các ghi đè biểu đồ helm bằng đường dẫn hình ảnh container NIM, và đặt
ngcAPISecretvàimagePullSecretsbằng các secret đã tạo ở Bước 1.
cat > qwen3-32b-spark-nim.values.yaml <<EOFimage: repository: "nvcr.io/nim/qwen/qwen3-32b-dgx-spark" tag: 1.0.0-variantmodel: ngcAPISecret: ngc-apinodeSelector: eks.amazonaws.com/compute-type: hybridresources: limits: nvidia.com/gpu: 1persistence: enabled: falseimagePullSecrets: - name: ngc-secrettolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule"EOF
- Triển khai một LLM dựa trên NIM bằng lệnh sau. Trong ví dụ này, tôi đang chạy một hình ảnh Qwen3-32B được tối ưu hóa đặc biệt cho node DGX Spark.
helm install my-nim nim-llm-1.15.4.tgz -f ./qwen3-32b-spark-nim.values.yaml
Việc triển khai này không liên tục và không sử dụng bộ nhớ đệm mô hình. Để triển khai bộ nhớ đệm mô hình, bạn cần cài đặt trình điều khiển CSI và cấu hình Persistent Volumes bằng cách sử dụng hạ tầng lưu trữ tại chỗ.
- Pod NIM được triển khai trên hybrid node có thể định tuyến thông qua BGP, do đó bạn có thể truy cập trực tiếp API của nó để kiểm tra mô hình.
$ kubectl get pods -o wide | grep nimmy-nim-nim-llm-0 1/1 Running 0 86m 192.168.64.102 mi-0e06d30895cfcc155 <none> <none>$ curl -X 'POST' \ "http://192.168.64.102:8000/v1/chat/completions" \ -H 'accept: application/json' \ -H 'Content-Type: application/json' \ -d '{ "model": "Qwen/Qwen3-32B", "prompt": "What is Kubernetes?", "max_tokens": 100 }'
Sau đây là một ví dụ về phản hồi dự kiến:
{ "id": "cmpl-d5161978bda9401b9b7a4ef0a529b6ce", "object": "text_completion", "created": 1770465499, "model": "Qwen/Qwen3-32B", "choices": [ { "index": 0, "text": " Why do you need it?\n\nKubernetes is a container orchestration system that automates the deployment, scaling, and management of containerized applications. It is an open-source system that was originally developed by Google and is now maintained by the Cloud Native Computing Foundation (CNCF). Kubernetes allows developers to easily deploy and manage applications in a distributed environment, making it a popular choice for organizations that use containerized applications.\n\nOne of the main reasons why Kubernetes is needed is because it provides a way to manage container", "logprobs": null, "finish_reason": "length", "stop_reason": null, "prompt_logprobs": null } ], "service_tier": null, "system_fingerprint": null, "usage": { "prompt_tokens": 4, "total_tokens": 104, "completion_tokens": 100, "prompt_tokens_details": null }, "kv_transfer_params": null}
Bạn đã triển khai thành công một LLM bằng NVIDIA NIM trên EKS Hybrid Nodes của mình.
Cấu hình giám sát tập trung và khả năng quan sát cho các chỉ số GPU
Hai phần sau đây sẽ hướng dẫn bạn cấu hình giám sát tập trung và khả năng quan sát cho các chỉ số GPU.
Cài đặt EKS Node Monitoring Agent
EKS Node Monitoring Agent (NMA) được đóng gói trong một hình ảnh container có thể được triển khai dưới dạng DaemonSet trên các EKS Hybrid Nodes của bạn. Nó thu thập thông tin tình trạng node và phát hiện các vấn đề cụ thể của GPU bằng cách sử dụng NVIDIA DCGM và NVIDIA Management Library (NVML). Nó báo cáo các vấn đề về tình trạng bằng cách cập nhật các điều kiện trạng thái node và phát ra các sự kiện Kubernetes. Truy cập bài đăng AWS Container này để tìm hiểu thêm chi tiết về NMA.
- Để cài đặt NMA trên hybrid node, hãy sử dụng lệnh AWS CLI sau để tạo tiện ích bổ sung Amazon EKS.
aws eks create-addon --cluster-name <CLUSTER_NAME> --addon-name eks-node-monitoring-agent
- Khi được cài đặt, NMA bắt đầu thu thập các điều kiện node tùy chỉnh cho EKS Hybrid Nodes. Từ ví dụ sau, bạn có thể thấy NMA đã phát hiện giao diện clustering 200 GbE (enp1s0f0np0) của hybrid node bị ngắt kết nối vì tôi chỉ sử dụng một DGX Spark duy nhất.
kubectl describe node mi-0e06d30895cfcc155 | sed -n '/^Conditions:/,/^Addresses:/p' | head -n -1Conditions: Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- NetworkingReady False Sat, 07 Feb 2026 23:52:59 +1100 Sat, 07 Feb 2026 05:22:59 +1100 InterfaceNotRunning Interface Name: "enp1s0f0np0", MAC: "4c:bb:47:2c:11:1d" is not up KernelReady True Sat, 07 Feb 2026 05:12:28 +1100 Sat, 07 Feb 2026 05:12:28 +1100 KernelIsReady Monitoring for the Kernel system is active AcceleratedHardwareReady True Sat, 07 Feb 2026 05:12:28 +1100 Sat, 07 Feb 2026 05:12:28 +1100 NvidiaAcceleratedHardwareIsReady Monitoring for the Nvidia AcceleratedHardware system is active ContainerRuntimeReady True Sat, 07 Feb 2026 05:12:28 +1100 Sat, 07 Feb 2026 05:12:28 +1100 ContainerRuntimeIsReady Monitoring for the ContainerRuntime system is active StorageReady True Sat, 07 Feb 2026 05:12:28 +1100 Sat, 07 Feb 2026 05:12:28 +1100 DiskIsReady Monitoring for the Disk system is active [...]
- NMA cũng cung cấp một phương pháp thu thập nhật ký tự động thông qua một Kubernetes CRD có tên
NodeDiagnostic. Để bật thu thập nhật ký từ các hybrid node của bạn, hãy tạo một tài nguyên tùy chỉnhNodeDiagnostictrên cụm của bạn và tham khảo hướng dẫn sử dụng Amazon EKS để biết thêm chi tiết.
apiVersion: eks.amazonaws.com/v1alpha1kind: NodeDiagnosticmetadata: name: <HYBRID_NODE_NAME>spec: logCapture: destination: <S3_PRESIGNED_HTTP_PUT_URL>
Tích hợp NVIDIA DCGM Exporter với Amazon Managed Service for Prometheus và Amazon Managed Grafana
Ngoài việc giám sát tình trạng node, bạn có thể sử dụng NVIDIA DCGM Exporter (trong stack GPU Operator) để thu thập các chỉ số hiệu suất GPU và dữ liệu đo từ xa có thể được Prometheus thu thập. Phần này trình bày cách tích hợp DCGM Exporter với Amazon Managed Service for Prometheus và Amazon Managed Grafana để bật khả năng quan sát GPU nâng cao trên các EKS Hybrid Nodes của bạn.
- Bắt đầu bằng cách tạo một không gian làm việc Amazon Managed Service for Prometheus.
aws amp create-workspace --alias dgx-spark-metrics --region ap-southeast-2 --query 'workspaceId' --output text
- Tiếp theo, làm theo hướng dẫn sử dụng này để tạo một vai trò IAM cho phép Prometheus nhập các chỉ số GPU đã thu thập từ EKS Hybrid Nodes vào không gian làm việc được quản lý. Xác minh rằng vai trò có các quyền sau được đính kèm.
{ "Version":"2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "aps:RemoteWrite", "aps:GetSeries", "aps:GetLabels", "aps:GetMetricMetadata" ], "Resource": "*" } ]}
- Chuẩn bị một tệp giá trị Helm cài đặt Prometheus như ví dụ sau. Cung cấp Amazon Resource Name (ARN) của vai trò nhập Prometheus từ bước cuối cùng, cập nhật đường dẫn điểm cuối
remoteWritevới URL không gian làm việc Prometheus được quản lý và thêm các cấu hình thu thập DCGM Exporter.
# RBAC permissions for service discoveryrbac: create: trueserviceAccounts: server: name: amp-iamproxy-ingest-service-account annotations: eks.amazonaws.com/role-arn: <AMP-INGEST-ROLE-ARN>server: persistentVolume: enabled: false remoteWrite: - url: https://<AWS-Managed-Prometheus-Workspace-URL>/api/v1/remote_write sigv4: region: <CLUSTER_REGION> queue_config: max_samples_per_send: 1000 max_shards: 200 capacity: 2500 global: scrape_interval: 30s external_labels: cluster: <CLUSTER_NAME># Additional scrape configs for DCGM ExporterserverFiles: prometheus.yml: scrape_configs: # DCGM Exporter - GPU metrics - job_name: 'dcgm-exporter' kubernetes_sd_configs: - role: endpoints # Auto-discover Kubernetes endpoints namespaces: names: - gpu-operator # Look in gpu-operator namespace relabel_configs: - source_labels: [__meta_kubernetes_service_name] regex: nvidia-dcgm-exporter # Match the DCGM exporter service action: keep - source_labels: [__meta_kubernetes_pod_node_name] target_label: node # Add node label to metrics
- Sử dụng Helm để triển khai Prometheus đến các hybrid node bằng các giá trị trên. Prometheus sử dụng DCGM Exporter để thu thập các chỉ số hiệu suất GPU và ghi từ xa vào không gian làm việc Amazon Managed Service for Prometheus.
helm repo add prometheus-community https://prometheus-community.github.io/helm-chartshelm repo add kube-state-metrics https://kubernetes.github.io/kube-state-metricshelm repo updatekubectl create namespace prometheushelm install prometheus prometheus-community/prometheus \ -n prometheus \ -f ./prometheus-amp-helm-values.yaml
- Làm theo hướng dẫn này để tạo một không gian làm việc Amazon Managed Grafana, bao gồm các quyền và quyền truy cập xác thực cần thiết thông qua IAM Identity Center. Sau đó, cấu hình không gian làm việc Grafana để thêm Amazon Managed Service for Prometheus làm nguồn dữ liệu.
- Cuối cùng, tạo một bảng điều khiển Grafana mới (hoặc nhập một bảng điều khiển như thế này) để trực quan hóa các chỉ số GPU đã thu thập như mức sử dụng GPU, bộ nhớ GPU đã sử dụng, nhiệt độ GPU và mức tiêu thụ năng lượng.
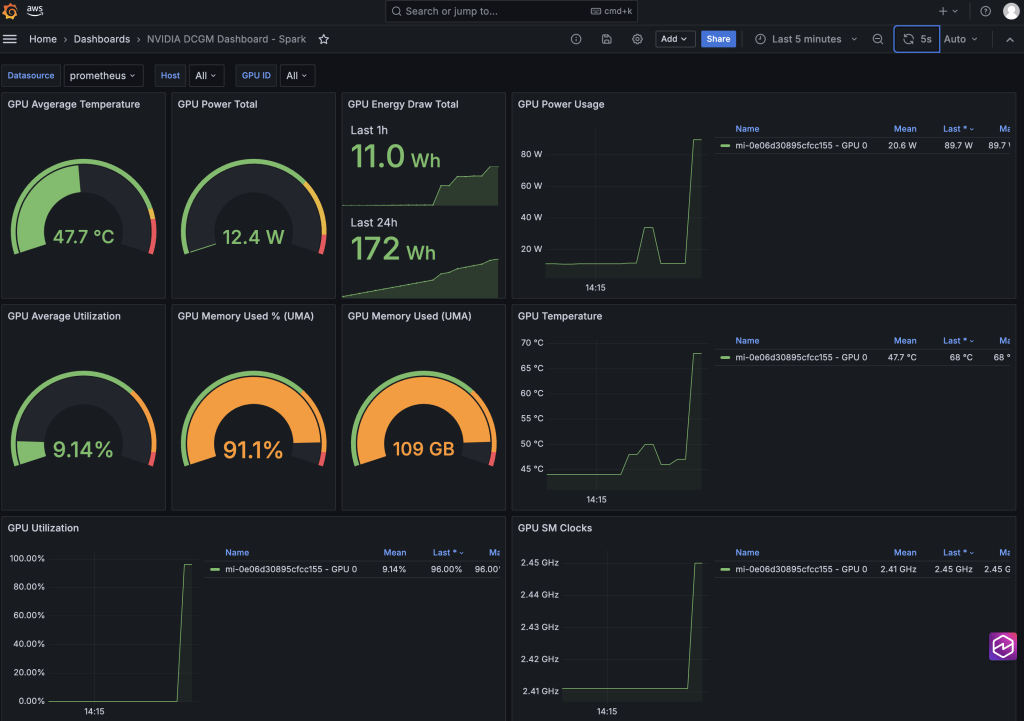
Hình 2: Sử dụng Amazon Managed Grafana để giám sát và trực quan hóa các chỉ số GPU và dữ liệu đo từ xa trên các hybrid node
Bạn có thể tích hợp EKS Hybrid Nodes với các dịch vụ đám mây của AWS để hợp lý hóa việc triển khai AI tạo sinh tại chỗ bằng cách loại bỏ chi phí quản lý Kubernetes, đồng thời duy trì các quy trình vận hành nhất quán với khả năng quan sát tập trung trên các vị trí đám mây, tại chỗ và biên.
Dọn dẹp tài nguyên
Để tránh phát sinh chi phí dài hạn, hãy xóa các tài nguyên AWS đã tạo trong quá trình hướng dẫn demo.
helm delete my-nimhelm delete prometheus -n prometheusaws amp delete-workspace --workspace-id <AMP-WORKSPACE-ID> --region <AWS_REGION>aws grafana delete-workspace --workspace-id <AMG-WORKSPACE-ID> --region <AWS_REGION>eksctl delete cluster --name <CLUSTER_NAME> --region <CLUSTER_REGION>
Dọn dẹp các tài nguyên điều kiện tiên quyết khác mà bạn đã tạo nếu chúng không còn cần thiết.
Kết luận
Bài đăng này cung cấp một ví dụ thực tế về cách Amazon EKS Hybrid Nodes hỗ trợ triển khai AI tạo sinh bằng cách sử dụng các node GPU của riêng bạn tại các vị trí tại chỗ và biên. Các tổ chức có thể sử dụng EKS Hybrid Nodes để tăng tốc triển khai AI với tính cục bộ của dữ liệu và độ trễ tối thiểu, đồng thời duy trì quản lý nhất quán và khả năng quan sát tập trung trên các môi trường phân tán.
Để tìm hiểu thêm về EKS Hybrid Nodes hoặc chạy khối lượng công việc AI/ML trên Amazon EKS, hãy khám phá các tài nguyên sau:
- Hướng dẫn sử dụng EKS Hybrid Nodes
- Blog AWS: Tìm hiểu sâu về Amazon EKS Hybrid Nodes
- Phiên AWS re:Invent 2024 (KUB205) – Mang sức mạnh của Amazon EKS đến các ứng dụng tại chỗ của bạn
- Dự án AWS AI trên EKS
Về tác giả

Sheng Chen là Kiến trúc sư Giải pháp Chuyên gia cấp cao tại AWS Australia, mang đến hơn 20 năm kinh nghiệm trong lĩnh vực hạ tầng CNTT, kiến trúc đám mây và mạng đa đám mây. Trong vai trò hiện tại, Sheng giúp khách hàng tăng tốc di chuyển lên đám mây và hiện đại hóa hạ tầng bằng cách tận dụng các công nghệ đám mây gốc. Anh chuyên về Amazon EKS, các dịch vụ đám mây lai của AWS, kỹ thuật nền tảng và hạ tầng AI.

Eric Chapman là Giám đốc Sản phẩm Kỹ thuật tại AWS. Anh tập trung vào việc mang sức mạnh của Amazon EKS đến bất cứ nơi nào khách hàng cần chạy khối lượng công việc Kubernetes của họ.
