Tác giả: Vijit Vashishtha và Koshal Agrawal
Ngày phát hành: 18 MAR 2026
Chuyên mục: Advanced (300), Amazon Bedrock, Amazon Bedrock Guardrails, Amazon DynamoDB, Amazon Elastic Container Service, Amazon Machine Learning, Amazon Simple Storage Service (S3), Artificial Intelligence, Technical How-to
Các tổ chức thường dựa vào kiểm thử A/B để tối ưu hóa trải nghiệm người dùng, thông điệp và luồng chuyển đổi. Tuy nhiên, kiểm thử A/B truyền thống gán người dùng một cách ngẫu nhiên và yêu cầu hàng tuần lưu lượng truy cập để đạt được ý nghĩa thống kê. Mặc dù hiệu quả, quy trình này có thể chậm và có thể không tận dụng hết các tín hiệu sớm trong hành vi người dùng.
Bài viết này chỉ cho bạn cách xây dựng một công cụ kiểm thử A/B được hỗ trợ bởi AI sử dụng Amazon Bedrock, Amazon Elastic Container Service, Amazon DynamoDB và Model Context Protocol (MCP). Hệ thống này cải thiện kiểm thử A/B truyền thống bằng cách phân tích ngữ cảnh người dùng để đưa ra các quyết định gán biến thể thông minh hơn trong quá trình thử nghiệm. Điều này giúp bạn giảm nhiễu, xác định các mẫu hành vi sớm hơn và đạt được kết quả thắng cuộc một cách tự tin hơn.
Cuối bài viết này, bạn sẽ có một kiến trúc và triển khai tham chiếu cung cấp khả năng thử nghiệm có thể mở rộng, thích ứng và cá nhân hóa bằng cách sử dụng các dịch vụ AWS phi máy chủ.
Thách thức với kiểm thử A/B truyền thống
Kiểm thử A/B truyền thống tuân theo một mô hình quen thuộc: gán người dùng ngẫu nhiên vào các biến thể, thu thập dữ liệu và chọn người thắng cuộc.
Cách tiếp cận này có những hạn chế:
- Chỉ gán ngẫu nhiên – Ngay cả khi các tín hiệu sớm cho thấy sự khác biệt có ý nghĩa
- Hội tụ chậm – Bạn sẽ phải đợi hàng tuần để thu thập đủ dữ liệu
- Nhiễu cao – Hệ thống có thể gán một số người dùng vào các biến thể rõ ràng không phù hợp với nhu cầu của họ
- Tối ưu hóa thủ công – Bạn thường cần phân đoạn dữ liệu sau đó
Một kịch bản thực tế: tại sao việc gán ngẫu nhiên làm bạn chậm lại
Hãy xem xét một nhà bán lẻ đang thử nghiệm hai nút Kêu gọi hành động (CTA) trên các trang sản phẩm của mình:
- Biến thể A: “Mua ngay”
- Biến thể B: “Mua ngay – Miễn phí vận chuyển”
Vài ngày đầu cho thấy Biến thể B hoạt động tốt, vì vậy bạn có thể cân nhắc triển khai nó. Tuy nhiên, phân tích phiên sâu hơn cho thấy điều thú vị:
- Các thành viên thân thiết cao cấp, những người đã được hưởng miễn phí vận chuyển, ngần ngại khi thấy thông báo “Miễn phí vận chuyển”. Một số thậm chí còn điều hướng đến trang tài khoản của họ để xác minh quyền lợi của mình.
- Những khách truy cập định hướng ưu đãi đến từ các trang web phiếu giảm giá và chiết khấu tương tác nhiều hơn với Biến thể B.
- Người dùng di động thích Biến thể A vì CTA ngắn hơn phù hợp hơn trên màn hình nhỏ hơn.
Mặc dù Biến thể B dường như thắng sớm, nhưng các nhóm hành vi người dùng khác nhau ảnh hưởng đến hiệu suất này, không nhất thiết là sở thích chung.
Việc gán là ngẫu nhiên, do đó thử nghiệm cần một khoảng thời gian dài để trung bình hóa các hiệu ứng này – và bạn phải phân tích thủ công nhiều phân đoạn để hiểu rõ. Đây là lúc việc gán được hỗ trợ bởi AI có thể giúp cải thiện thử nghiệm.
Tổng quan giải pháp: Gán biến thể được hỗ trợ bởi AI
Công cụ kiểm thử A/B được hỗ trợ bởi AI nâng cấp thử nghiệm cổ điển bằng cách sử dụng ngữ cảnh người dùng thời gian thực và các mẫu hành vi sớm để đưa ra các quyết định gán biến thể thông minh hơn.
Giải pháp giới thiệu một công cụ kiểm thử A/B thích ứng được xây dựng với Amazon Bedrock. Thay vì gán mỗi người dùng vào cùng một biến thể, công cụ đánh giá ngữ cảnh người dùng trong thời gian thực, truy xuất dữ liệu hành vi trong quá khứ và chọn một biến thể tối ưu cho cá nhân đó.
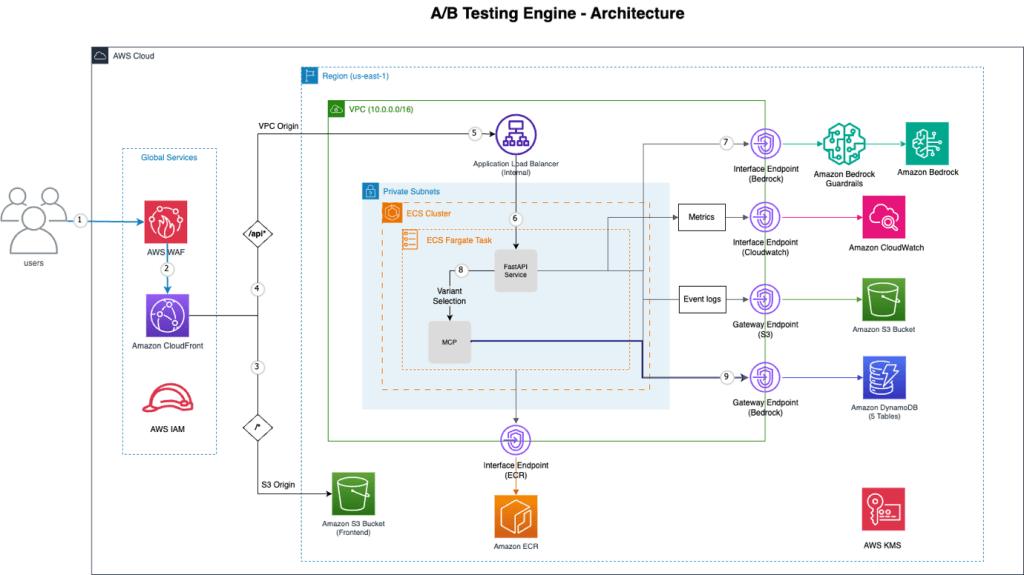
Hình 1: Kiến trúc Công cụ kiểm thử A/B
Kiến trúc bao gồm các thành phần AWS sau:
- Amazon CloudFront + AWS WAF – Mạng phân phối nội dung (CDN) toàn cầu với bảo vệ chống tấn công từ chối dịch vụ phân tán (DDoS), ngăn chặn tấn công SQL injection và giới hạn tốc độ
- VPC Origin – Kết nối riêng tư từ Amazon CloudFront đến Application Load Balancer nội bộ (không tiếp xúc với internet công cộng)
- Amazon ECS với AWS Fargate: Điều phối container phi máy chủ chạy ứng dụng FastAPI
- Amazon Bedrock – Công cụ quyết định AI sử dụng Claude Sonnet với khả năng sử dụng công cụ gốc
- Model Context Protocol (MCP) – Cung cấp quyền truy cập có cấu trúc vào dữ liệu hành vi và thử nghiệm
- VPC Endpoints – Kết nối riêng tư đến Amazon Bedrock, Amazon DynamoDB, Amazon S3, Amazon Elastic Container Registry (Amazon ECR) và Amazon CloudWatch
- Amazon DynamoDB – Năm bảng cho các thử nghiệm, sự kiện, gán, hồ sơ và các công việc hàng loạt
- Amazon Simple Storage Service (Amazon S3) – Lưu trữ frontend tĩnh và nhật ký sự kiện
Cách Amazon Bedrock cải thiện quyết định biến thể
Đổi mới cốt lõi nằm ở việc kết hợp ngữ cảnh người dùng, lịch sử hành vi, các mẫu người dùng tương tự và dữ liệu hiệu suất thời gian thực để chọn biến thể tối ưu. Phần này tiết lộ cách quy trình quyết định AI hoạt động.
Lời nhắc quyết định AI: Amazon Bedrock nhìn thấy gì
Khi người dùng kích hoạt yêu cầu biến thể, hệ thống xây dựng một lời nhắc toàn diện cung cấp cho Amazon Bedrock nội dung đầy đủ cần thiết để đưa ra quyết định sáng suốt. Dưới đây là cấu trúc lời nhắc thực tế:
# System Prompt (defines Amazon Bedrock's role and behavior) system_prompt = """You are an expert A/B testing optimization specialist with access to tools for gathering user behavior data. CRITICAL INSTRUCTIONS: 1. ALWAYS call get_user_assignment FIRST to check for existing assignments 2. Only call other tools if you need specific information to make a better decision 3. Call tools based on what information would be valuable for this specific decision 4. If user has existing assignment, keep it unless there's strong evidence (30%+ improvement) to change 5. CRITICAL: Your final response MUST be ONLY valid JSON with no additional text, explanations, or commentary before or after the JSON object Available tools: - get_user_assignment: Check existing variant assignment (CALL THIS FIRST) - get_user_profile: Get user behavioral profile and preferences - get_similar_users: Find users with similar behavior patterns - get_experiment_context: Get experiment configuration and performance - get_session_context: Analyze current session behavior - get_user_journey: Get user's interaction history - get_variant_performance: Get variant performance metrics - analyze_user_behavior: Deep behavioral analysis from event history - update_user_profile: Update user profile with AI-derived insights - get_profile_learning_status: Check profile data quality and confidence - batch_update_profiles: Batch update multiple user profilesMake intelligent, data-driven decisions. Use the tools you need to gather sufficient context for optimal variant selection. RESPONSE FORMAT: Return ONLY the JSON object. Do not include any text before or after it."""# User Prompt (provides specific decision context) prompt = f"""Select the optimal variant for this user in experiment {experiment_id}. USER CONTEXT: - User ID: {user_context.user_id} - Session ID: {user_context.session_id} - Device: {user_context.device_type} (Mobile: {bool(user_context.is_mobile)}) - Current Page: {user_context.current_session.current_page} - Referrer: {user_context.current_session.referrer_type or 'direct'} - Previous Variants: {user_context.current_session.previous_variants or 'None'} CONTEXT INSIGHTS: {analyze_user_context()} PERSONALIZATION CONTEXT: - Engagement Score: {profile.engagement_score:.2f} - Conversion Likelihood: {profile.conversion_likelihood:.2f} - Interaction Style: {profile.interaction_style} - Previously Successful Variants: {profile.successful_variants} AVAILABLE VARIANTS: {format_variants_for_prompt(variants)} HISTORICAL PERFORMANCE: {get_variant_performance_summary(variants)} INSTRUCTIONS: 1. FIRST: Call get_user_assignment to check if user has existing assignment 2. If existing assignment exists, only change if you have strong evidence (30%+ improvement expected) 3. Call additional tools as needed to gather sufficient context for an optimal decision 4. Consider: device type, user behavior, session context, variant performance 5. Make data-driven decision based on tool results CRITICAL: Respond with ONLY valid JSON, no additional text before or after: { "variant_id": "A|B|C", "confidence": 0.85, "reasoning": "Detailed explanation including which tools you used and why" }"""
Các yếu tố chính của cấu trúc lời nhắc:
Cấu trúc lời nhắc hai cấp kết hợp lời nhắc hệ thống và lời nhắc người dùng.
Lời nhắc hệ thống định nghĩa Amazon Bedrock là một “chuyên gia tối ưu hóa kiểm thử A/B” với quyền truy cập vào 11 công cụ MCP (kiểm tra gán, phân tích hồ sơ, lọc cộng tác, chỉ số hiệu suất, phân tích phiên) và các quy tắc quan trọng (kiểm tra gán hiện có trước, ngưỡng 30% cho các thay đổi, phản hồi chỉ JSON).
Lời nhắc người dùng cung cấp ngữ cảnh quyết định đầy đủ bao gồm các thuộc tính người dùng (thiết bị, trang, người giới thiệu, các biến thể trước đó), dữ liệu cá nhân hóa (điểm tương tác, khả năng chuyển đổi, kiểu tương tác), cấu hình biến thể được định dạng động, các chỉ số hiệu suất thời gian thực và khung quyết định 5 bước.
Cùng nhau, cả hai lời nhắc giúp Amazon Bedrock điều phối các lệnh gọi công cụ một cách thông minh và đưa ra các lựa chọn biến thể dựa trên dữ liệu với sự minh bạch hoàn toàn.
Tại sao nên dùng Amazon Bedrock thay vì ML truyền thống
Các mô hình học máy (ML) truyền thống (ví dụ: cây quyết định, hồi quy logistic, mạng nơ-ron) đã thúc đẩy phân đoạn người dùng trong nhiều năm. Vậy tại sao lại sử dụng Amazon Bedrock để gán biến thể? Câu trả lời nằm ở bốn khả năng chính:
Điều phối công cụ thông minh
ML truyền thống yêu cầu kỹ thuật tính năng được mã hóa cứng. Bạn phải quyết định trước dữ liệu nào cần lấy và cách kết hợp chúng. Amazon Bedrock, thông qua Model Context Protocol, tự động quyết định công cụ nào cần gọi dựa trên tình huống.
Amazon Bedrock's Tool Calling Pattern (from actual logs):User 1 (New Mobile User): 1. get_user_assignment() → No existing assignment 2. get_similar_users(user_id) → Found 47 similar mobile users 3. get_variant_performance(variant_id="B") → 23% higher mobile conversion Decision: Variant B (confidence: 0.65)User 2 (Returning Premium Customer): 1. get_user_assignment() → Existing: Variant A 2. get_user_profile(user_id) → High engagement, premium buyer 3. get_variant_performance(variant_id="B") → Only 5% improvement Decision: Keep Variant A (confidence: 0.82, "Insufficient evidence to change")
Amazon Bedrock điều chỉnh việc thu thập dữ liệu của mình theo tình huống riêng của mỗi người dùng. Một người dùng mới kích hoạt phân tích tương tự, trong khi một người dùng quay lại kích hoạt phân tích hồ sơ. Một trường hợp biên có thể kích hoạt tất cả các công cụ. Bạn không lập trình logic này – Amazon Bedrock tự suy luận.
Tổng hợp lý luận đa yếu tố
Các mô hình ML truyền thống tạo ra các dự đoán mà không có lời giải thích. Amazon Bedrock cung cấp lý luận tổng hợp nhiều yếu tố.
{ "variant_id": "B", "confidence": 0.86, "reasoning": "User's mobile device (small screen) strongly favors Variant B's shorter CTA. Similar mobile users show 23% higher conversion with B. User's high engagement score (0.83) suggests receptiveness to incentive messaging. Device constraints and behavioral alignment create strong signal for Variant B despite A's historical lead on desktop." }
Lý luận này kết hợp:
- Hạn chế thiết bị (yếu tố kỹ thuật)
- Các mẫu người dùng tương tự (lọc cộng tác)
- Các chỉ số tương tác cá nhân (yếu tố hành vi)
- Hiệu suất lịch sử (yếu tố thống kê)
Một mô hình ML truyền thống có thể dự đoán “Biến thể B: xác suất 78%” nhưng không thể giải thích cách các hạn chế thiết bị tương tác với các mẫu người dùng tương tự để đưa ra dự đoán đó.
Xử lý các trường hợp biên và tín hiệu xung đột
Khi các tín hiệu xung đột, Amazon Bedrock suy luận thông qua các đánh đổi:
Conflicting Signals Example:- Variant A: Higher aggregate conversion rate (4.2% vs 3.8%)- User: Premium customer (typically prefers professional styling)- Similar Users: Show 34% higher conversion with Variant B's social proof- Device: Desktop (both variants work well)Amazon Bedrock's Reasoning:"Despite Variant A's higher aggregate conversion rate, this premium customer's profilematches the 'social proof responsive' cluster (0.91 similarity). Similar premium usersshow 34% lift with social proof emphasis. The desktop device allows Variant B's richertestimonial display without performance penalty. Expected individual conversionprobability: 0.78 vs 0.61 for Variant A."Decision: Variant B (confidence: 0.84)
Không cần huấn luyện, thích ứng tức thì
ML truyền thống yêu cầu:
- Thu thập dữ liệu huấn luyện lịch sử (vài tuần/tháng)
- Kỹ thuật tính năng và huấn luyện mô hình
- Huấn luyện lại định kỳ khi các mẫu thay đổi
- Kiểm thử A/B chính mô hình ML
Amazon Bedrock hoạt động ngay lập tức:
- Ngày 1: Sử dụng các mẫu người dùng tương tự từ dữ liệu hiện có
- Ngày 2: Học hỏi từ các kết quả của ngày hôm qua
- Ngày 30: Cá nhân hóa tinh vi dựa trên các thông tin chi tiết tích lũy
- Bạn không cần một pipeline huấn luyện lại
Đi sâu vào triển khai
Các phần sau mô tả cách công cụ được hỗ trợ bởi AI hoạt động đằng sau hậu trường.
Chiến lược gán kết hợp
Người dùng mới → Dựa trên hàm băm (hiệu quả về chi phí)
Người dùng quay lại → Dựa trên AI (giá trị cao)
Người dùng mới: Gán dựa trên hàm băm (nhanh, không tốn chi phí AI)
if is_new_user: user_hash = int(hashlib.sha256(user_id.encode()).hexdigest(), 16) return variants[index]
Đối với người dùng quay lại, backend gọi Amazon Bedrock:
decision = bedrock_client.converse( modelId="anthropic.claude-3-5-sonnet", messages=[{"role": "user", "content":[{"text": prompt}]}], toolConfig={"tools": mcp_registry.tools})
Cách tiếp cận kết hợp này rất quan trọng. Người dùng mới không có dữ liệu hành vi, vì vậy phân tích AI mang lại giá trị tối thiểu. Gán dựa trên hàm băm mang lại cho họ trải nghiệm nhất quán trong khi chúng ta thu thập dữ liệu. Sau khi chúng ta có các tín hiệu hành vi, lựa chọn AI mang lại một sự cải thiện đáng kể.
Khung công cụ và thực thi MCP
Model Context Protocol (MCP) cung cấp cho Amazon Bedrock quyền truy cập có cấu trúc vào dữ liệu hành vi của bạn thông qua một hệ thống điều phối công cụ thông minh. Thay vì đổ tất cả dữ liệu vào lời nhắc (tốn kém và chậm), Amazon Bedrock chọn lọc gọi các công cụ để thu thập chính xác thông tin cần thiết. Điều này tạo ra một cuộc trò chuyện đa lượt, nơi nó yêu cầu dữ liệu, phân tích và đưa ra quyết định.
Cách thực thi công cụ hoạt động
Mỗi phản hồi của Amazon Bedrock có thể bao gồm một lệnh gọi công cụ. Backend FastAPI thực thi công cụ, trả về kết quả và tiếp tục cuộc trò chuyện:
if response.stopReason == "tool_use": tool_name = tool_call["name"] payload = tool_call["input"] result = await mcp.execute(tool_name, payload) messages.append( { "role": "user", "content": [{"toolResult": result}] } )
Vòng lặp này tiếp tục cho đến khi mô hình tạo ra JSON quyết định cuối cùng. Cuộc trò chuyện đa lượt này cho phép Amazon Bedrock thu thập chính xác ngữ cảnh cần thiết, phân tích và đưa ra quyết định.
Các công cụ MCP chính
Công cụ 1: get_similar_users() – Lọc cộng tác
Tìm người dùng có các mẫu hành vi tương tự bằng cách sử dụng khớp dựa trên cụm:
Algorithm: (1) Check user's similarity cluster, (2) Query DynamoDB for cluster members, (3) Calculate similarity scores, (4) Return top N similar usersSimilarity Score (0.0-1.0) calculated from:- Engagement score similarity (30%): Similar engagement levels- Interaction style match (20%): Same pattern (focused/explorer/decisive/casual)- Content preferences overlap (20%): Shared interests and content types- Conversion likelihood similarity (15%): Similar purchase probability- Visual preference match (15%): Same design preference (complex/balanced/minimal)Threshold: > 0.5 to be considered similar
Công cụ 2: get_user_profile() – Dấu vân tay hành vi
Truy xuất hồ sơ hành vi toàn diện từ bảng PersonalizationProfile của DynamoDB:
Behavioral Signals: engagement_score, conversion_likelihood, cta_responsiveness,reading_depth, social_proof_sensitivity, urgency_sensitivity (all 0.0-1.0)Preferences: interaction_style (focused|explorer|decisive|casual), attention_span(long|medium|short), visual_preference (complex|balanced|minimal), content_preferences,preferred_content_lengthPerformance Data: successful_variants, variant_performance mapping, confidence_scoreDevice Context: device_type, visit_frequencySimilarity Data: similarity_cluster, similar_user_ids
Công cụ 3: get_variant_performance() – Các chỉ số thời gian thực
Truy xuất dữ liệu hiệu suất từ đối tượng lồng nhau VariantPerformance của bảng Experiment:
current_performance: impressions, clicks, conversions, conversion_rate (conversions/impressions),confidence (0.0-1.0), last_updated timestamphistorical_data: Time-series performance aggregated from Events tablemetadata: experiment_id, variant_id, time_period_days, has_performance_data flagNote: The system stores metrics in the Experiment table and updates them as events occur
Lưu trữ thông tin chi tiết AI trở lại hồ sơ
Sau mỗi lựa chọn biến thể, hệ thống ghi lại kết quả để cải thiện các quyết định trong tương lai:
profile.update( { "last_selected_variant": decision.variant_id, "confidence_score": decision.confidence, "behavior_tags": extracted_signals }) dynamodb.put_item( TableName="user_profile", Item=profile.to_item())
Theo thời gian, khi hệ thống ghi lại nhiều kết quả hơn, hồ sơ người dùng trở nên chính xác hơn trong việc thể hiện sở thích cá nhân, cho phép Amazon Bedrock đưa ra các lựa chọn biến thể sáng suốt hơn.
Hiểu về điểm tin cậy
Mỗi quyết định AI bao gồm một điểm tin cậy (0.0-1.0) mà Amazon Bedrock tạo ra như một phần của quy trình suy luận của nó. Điểm này phản ánh đánh giá của hệ thống về mức độ chắc chắn của nó về lựa chọn biến thể dựa trên dữ liệu có sẵn.
Cách Amazon Bedrock xác định độ tin cậy:
Amazon Bedrock đánh giá nhiều yếu tố khi gán độ tin cậy:
- Tính sẵn có của dữ liệu – Nhiều dữ liệu hành vi và hiệu suất lịch sử hơn → độ tin cậy cao hơn
- Tính nhất quán của tín hiệu – Các tín hiệu được căn chỉnh trên hồ sơ người dùng, người dùng tương tự và dữ liệu hiệu suất → độ tin cậy cao hơn
- Bằng chứng người dùng tương tự – Cụm người dùng tương tự lớn hơn với sở thích nhất quán → độ tin cậy cao hơn
- Ý nghĩa thống kê – Dữ liệu hiệu suất đáp ứng ngưỡng ý nghĩa → độ tin cậy cao hơn
- Độ trưởng thành của hồ sơ – Hồ sơ người dùng đã được thiết lập với lịch sử rộng lớn → độ tin cậy cao hơn
Điểm tin cậy là một đánh giá toàn diện hơn là một chỉ số được tính toán, cho phép nó cân nhắc các yếu tố một cách linh hoạt dựa trên ngữ cảnh.
Giải thích điểm tin cậy:
- 0.9–1.0: Cực kỳ đáng tin cậy – Bằng chứng mạnh mẽ trên tất cả các yếu tố
- 0.7–0.89: Độ tin cậy cao – Chất lượng dữ liệu tốt với các tín hiệu được căn chỉnh
- 0.5–0.69: Trung bình – Dữ liệu hợp lý nhưng có một số không chắc chắn
- 0.3–0.49: Thấp – Dữ liệu hạn chế hoặc tín hiệu xung đột
- < 0.3: Rất thấp – Không đủ dữ liệu để dự đoán tự tin
Middleware làm giàu ngữ cảnh
Middleware tự động tăng cường mọi yêu cầu với ngữ cảnh thiết bị và phiên:
user_agent = request.headers["user-agent"]device = detect_device(user_agent)referrer = classify_referrer(request.headers.get("referrer", ""))user_context.device_type = device.typeuser_context.referrer_type = referrer
Điều này giúp xác minh rằng Amazon Bedrock có ngữ cảnh phong phú mà không yêu cầu frontend gửi nó một cách rõ ràng.
Một ví dụ thực tế dựa trên kịch bản bán lẻ
Hãy xem xét lại thử nghiệm CTA của nhà bán lẻ – lần này hiển thị quy trình quyết định hoàn chỉnh của Amazon Bedrock, bao gồm các lệnh gọi công cụ thực tế.
Người dùng 1: thành viên thân thiết trên thiết bị di động
Ngữ cảnh ban đầu
- Thiết bị: iPhone
- Thành viên thân thiết: Thành viên thân thiết cao cấp
- Mẫu duyệt web: Nhanh, định hướng mục tiêu
- Người giới thiệu: Điều hướng trực tiếp
- Các giao dịch mua trước đó: Thường xuyên
Quy trình ra quyết định
Tool Call 1: get_user_assignment(user_id="user_001", experiment_id="cta_test_2024")Response: No existing assignment existsTool Call 2: get_user_profile(user_id="user_001")Response: { "engagement_score": 0.89, "conversion_likelihood": 0.24, "interaction_style": "focused", "attention_span": "short", "successful_variants": ["A", "simple_design"], "confidence_score": 0.87}Tool Call 3: get_similar_users(user_id="user_001", limit=5)Response: { "count": 52, "avg_conversion_rate": 0.21, "preferred_variants": ["A"], "shared_characteristics": ["mobile", "loyalty_member", "focused_buyer"]}Tool Call 4: get_variant_performance(experiment_id="cta_test_2024", variant_id="A")Response: { "current_performance": { "impressions": 3900, "clicks": 312, "conversions": 125, "conversion_rate": 0.032, "confidence": 0.89 }, "has_performance_data": true}
Amazon Bedrock đánh giá dữ liệu và trả về:
{ “variant_id”: “A”, “confidence”: 0.86, “reasoning”: “Strong alignment across multiple signals: (1) User profile shows 'focused' interaction style with short attention span, preferring streamlined experiences. (2) High profile confidence (0.87) from historical data. (3) 52 similar loyalty members on mobile strongly prefer Variant A (simple 'Buy Now'). (4) Variant A shows solid performance with 3.2% conversion rate and 125 conversions from 3,900 impressions. (5) Loyalty status means free shipping message is redundant. All signals point to concise CTA without incentive framing.”}
Người dùng 2: khách truy cập lần đầu từ trang web phiếu giảm giá
Ngữ cảnh ban đầu
- Thiết bị: Android
- Không có trạng thái thành viên thân thiết
- Mẫu duyệt web: Chậm, tập trung so sánh
- Người giới thiệu: Trang web tổng hợp ưu đãi
Quy trình ra quyết định
Tool Call 1: get_user_assignment(user_id="user_002", experiment_id="cta_test_2024") Response: No existing assignment foundTool Call 2: get_user_profile(user_id="user_002") Response: { "engagement_score": 0.15, "conversion_likelihood": 0.05, "confidence_score": 0.12 // Very low - new user } Tool Call 3: get_similar_users(user_id="user_002", limit=10) Response: { "count": 39, "avg_conversion_rate": 0.18, "preferred_variants": ["B"], "shared_characteristics": ["first_visit", "coupon_site_referrer", "deal_seeking"], "note": "Similar new users from deal sites show 2.3x higher conversion with incentive messaging" } Tool Call 4: get_variant_performance(experiment_id="cta_test_2024", variant_id="B") Response: { "current_performance": { "impressions": 3850, "clicks": 385, "conversions": 158, "conversion_rate": 0.041, "confidence": 0.95 }, "has_performance_data": true }
Amazon Bedrock chọn:
{ “variant_id”: “B”, “confidence”: 0.91, “reasoning”: “Despite low user profile confidence (0.12 - new user), strong contextual signals create high decision confidence: (1) Referrer source (RetailMeNot) indicates deal-seeking behavior. (2) 39 similar first-time visitors from coupon sites show strong preference for Variant B (incentive messaging). (3) Variant B shows strong performance with 4.1% conversion rate and 158 conversions from 3,850 impressions. (4) New user status means no prior variant preference to contradict. Context-driven decision leveraging similar user patterns compensates for lack of individual behavioral history.”}
Những điểm khác biệt chính
Người dùng 1 (Hồ sơ đã thiết lập)
- Dựa nhiều vào lịch sử hành vi cá nhân (độ tin cậy 0.87)
- Người dùng tương tự được xác nhận nhưng không thúc đẩy quyết định
- Thiết bị + trạng thái thành viên thân thiết được coi là các yếu tố chính
Người dùng 2 (Người dùng mới)
- Dữ liệu cá nhân tối thiểu (độ tin cậy 0.12)
- Dựa nhiều vào các mẫu người dùng tương tự (39 người dùng tương tự)
- Ngữ cảnh người giới thiệu là tín hiệu quyết định
- Vẫn đạt được độ tin cậy quyết định 0.91 thông qua các tín hiệu ngữ cảnh mạnh mẽ
Điều này chứng minh cách hệ thống điều chỉnh chiến lược thu thập dữ liệu của mình dựa trên thông tin có sẵn – sử dụng lịch sử cá nhân khi có, và các mẫu người dùng tương tự khi không có.
Các cải tiến trong tương lai
Hệ thống này cung cấp nền tảng cho việc cá nhân hóa nâng cao:
- Tạo biến thể động – Thay vì chọn từ các biến thể được xác định trước, hãy sử dụng Amazon Bedrock để tạo nội dung tùy chỉnh cho mỗi người dùng. Hãy tưởng tượng các CTA điều chỉnh thông điệp, màu sắc và mức độ khẩn cấp dựa trên hành vi cá nhân.
- Multi-armed Bandits – Kết hợp cá nhân hóa AI với các thuật toán bandit để phân bổ lưu lượng truy cập tự động. Chuyển lưu lượng truy cập sang các biến thể thắng cuộc trong khi vẫn khám phá các tùy chọn mới.
- Học hỏi đa thử nghiệm – Chia sẻ thông tin chi tiết giữa các thử nghiệm. Nếu người dùng phản hồi tốt với thông điệp khẩn cấp trong một thử nghiệm, hãy tự động áp dụng kiến thức đó cho các thử nghiệm khác.
- Tối ưu hóa thời gian thực – Sử dụng dữ liệu streaming từ Amazon Kinesis để cập nhật hồ sơ trong thời gian thực. Phản ứng với hành vi người dùng trong vài giây, không phải vài phút.
- Phân đoạn nâng cao – Cho phép AI tự động khám phá các phân đoạn người dùng thông qua phân cụm. Không còn tạo phân đoạn thủ công – hệ thống tìm thấy các mẫu mà bạn không biết tồn tại.
Kết luận
Trong bài viết này, bạn đã học cách xây dựng một công cụ kiểm thử A/B thích ứng bằng cách sử dụng Amazon Bedrock và Model Context Protocol. Giải pháp này chuyển đổi thử nghiệm từ việc gán tĩnh, ngẫu nhiên sang một công cụ cá nhân hóa thông minh, liên tục học hỏi. Các lợi ích chính bao gồm:
- Các quyết định biến thể được cá nhân hóa
- Học hỏi gần như liên tục từ hành vi người dùng
- Kiến trúc phi máy chủ với chi phí vận hành tối thiểu
- Chi phí dự đoán được thông qua gán kết hợp
- Tích hợp sâu với các dịch vụ AWS
Để bắt đầu, hãy triển khai kiến trúc tham chiếu và dần dần kích hoạt các quyết định được hỗ trợ bởi AI khi dữ liệu người dùng trưởng thành.
Để triển khai giải pháp này trong môi trường của bạn:
- Bắt đầu với những điều cơ bản – Triển khai cơ sở hạ tầng bằng cách sử dụng các mẫu AWS CloudFormation được cung cấp. Bắt đầu với việc gán dựa trên hàm băm cho tất cả người dùng để thiết lập một đường cơ sở.
- Thêm cá nhân hóa dần dần – Kích hoạt lựa chọn được hỗ trợ bởi AI cho người dùng quay lại sau khi bạn có dữ liệu hành vi. Bắt đầu với một tỷ lệ nhỏ lưu lượng truy cập và theo dõi kết quả.
- Mở rộng các công cụ MCP – Thêm các công cụ tùy chỉnh vào máy chủ MCP dựa trên nhu cầu kinh doanh cụ thể của bạn. Cân nhắc các công cụ cho dữ liệu tồn kho, thông tin giá cả hoặc lịch sử dịch vụ khách hàng.
- Giám sát và tối ưu hóa – Sử dụng bảng điều khiển Amazon CloudWatch để theo dõi độ trễ gán biến thể, chi phí API Amazon Bedrock và các chỉ số chuyển đổi. Thiết lập cảnh báo cho các bất thường.
- Khám phá các tính năng nâng cao – Triển khai tạo biến thể động, multi-armed bandits hoặc học hỏi đa thử nghiệm khi hệ thống của bạn trưởng thành.
Bạn có thể tìm thấy mã nguồn hoàn chỉnh cho giải pháp này, bao gồm backend FastAPI, frontend React, các mẫu CloudFormation và triển khai máy chủ MCP, tại GitHub – A/B Testing Engine.
Để tránh phát sinh chi phí liên tục, hãy xóa các tài nguyên mà bạn đã tạo trong quá trình hướng dẫn này. Để biết hướng dẫn dọn dẹp chi tiết bao gồm các lệnh từng bước và các bước xác minh, hãy xem Hướng dẫn dọn dẹp cơ sở hạ tầng.
Về tác giả

Vijit Vashishtha
Vijit làm việc tại Professional Services GCC, lãnh đạo và thực hiện các sáng kiến kiến trúc và kỹ thuật backend cho các nền tảng doanh nghiệp chạy khối lượng công việc sản xuất. Anh tập trung vào việc xây dựng các hệ thống đáng tin cậy, chịu lỗi, có khả năng mở rộng hiệu quả trong khi duy trì sự xuất sắc trong vận hành và kỷ luật chi phí.

Koshal Agrawal
Koshal làm việc tại Professional Services GCC, giúp các tổ chức xây dựng và cung cấp các giải pháp cloud-native trên AWS. Anh đam mê kiến trúc đám mây và các công cụ dành cho nhà phát triển – và thích biến các vấn đề kỹ thuật phức tạp thành các giải pháp sạch, sẵn sàng cho sản xuất.
