Tác giả: Lana Zhang và Sharon Li
Ngày phát hành: 25 MAR 2026
Chuyên mục: Advanced (300), Amazon Bedrock, Amazon Nova, Best Practices, Education, Games, Manufacturing, Marketing & Advertising, Media & Entertainment, Sports
Nội dung video hiện diện ở khắp mọi nơi, từ giám sát an ninh và sản xuất truyền thông đến các nền tảng xã hội và truyền thông doanh nghiệp. Tuy nhiên, việc trích xuất thông tin chi tiết có ý nghĩa từ khối lượng lớn video vẫn là một thách thức lớn. Các tổ chức cần những giải pháp không chỉ hiểu được những gì xuất hiện trong video mà còn cả ngữ cảnh, câu chuyện và ý nghĩa tiềm ẩn của nội dung.
Trong bài viết này, chúng tôi khám phá cách các mô hình nền tảng đa phương thức (FM) của Amazon Bedrock cho phép hiểu video ở quy mô lớn thông qua ba phương pháp kiến trúc riêng biệt. Mỗi phương pháp được thiết kế cho các trường hợp sử dụng khác nhau và sự đánh đổi giữa chi phí-hiệu suất. Giải pháp hoàn chỉnh có sẵn dưới dạng mẫu AWS mã nguồn mở trên GitHub.
Sự phát triển của phân tích video
Các phương pháp phân tích video truyền thống dựa vào việc xem xét thủ công hoặc các kỹ thuật thị giác máy tính cơ bản để phát hiện các mẫu được xác định trước. Mặc dù có chức năng, các phương pháp này phải đối mặt với những hạn chế đáng kể:
- Hạn chế về quy mô: Xem xét thủ công tốn thời gian và chi phí
- Tính linh hoạt hạn chế: Các hệ thống dựa trên quy tắc không thể thích ứng với các kịch bản mới
- Thiếu ngữ cảnh: Thị giác máy tính truyền thống thiếu khả năng hiểu ngữ nghĩa
- Độ phức tạp tích hợp: Khó kết hợp vào các ứng dụng hiện đại
Sự xuất hiện của các mô hình nền tảng đa phương thức trên Amazon Bedrock đã thay đổi mô hình này. Các mô hình này có thể xử lý cả thông tin hình ảnh và văn bản cùng nhau. Điều này cho phép chúng hiểu các cảnh, tạo mô tả ngôn ngữ tự nhiên, trả lời các câu hỏi về nội dung video và phát hiện các sự kiện tinh tế mà khó có thể định nghĩa bằng lập trình.

Ba phương pháp để hiểu video
Hiểu nội dung video vốn dĩ rất phức tạp, kết hợp thông tin hình ảnh, âm thanh và thời gian phải được phân tích cùng nhau để có được những thông tin chi tiết có ý nghĩa. Các trường hợp sử dụng khác nhau, chẳng hạn như phân tích cảnh truyền thông, phát hiện quảng cáo, theo dõi camera IP hoặc kiểm duyệt mạng xã hội, đòi hỏi các quy trình làm việc riêng biệt với sự đánh đổi khác nhau về chi phí, độ chính xác và độ trễ. Giải pháp này cung cấp ba quy trình làm việc riêng biệt, mỗi quy trình sử dụng các phương pháp trích xuất video khác nhau được tối ưu hóa cho các kịch bản cụ thể.
Quy trình làm việc dựa trên khung hình: độ chính xác ở quy mô lớn
Phương pháp dựa trên khung hình lấy mẫu các khung hình ảnh theo các khoảng thời gian cố định, loại bỏ các khung hình tương tự hoặc dư thừa, và áp dụng các mô hình nền tảng hiểu hình ảnh để trích xuất thông tin hình ảnh ở cấp độ khung hình. Phiên âm âm thanh được thực hiện riêng bằng cách sử dụng Amazon Transcribe.

Quy trình làm việc này lý tưởng cho:
- An ninh và giám sát: Phát hiện các điều kiện hoặc sự kiện cụ thể theo thời gian
- Đảm bảo chất lượng: Giám sát các quy trình sản xuất hoặc vận hành
- Giám sát tuân thủ: Xác minh việc tuân thủ các giao thức an toàn
Kiến trúc sử dụng AWS Step Functions để điều phối toàn bộ pipeline:
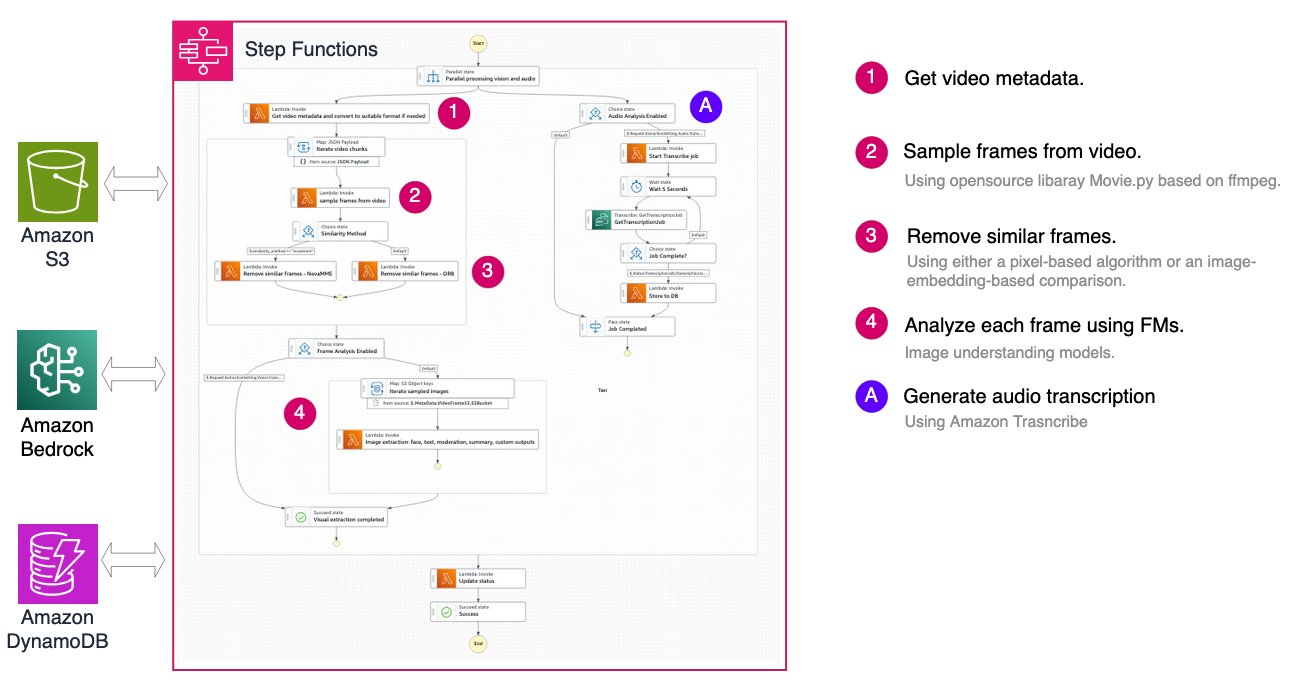
Lấy mẫu thông minh: tối ưu hóa chi phí và chất lượng
Một tính năng chính của quy trình làm việc dựa trên khung hình là loại bỏ trùng lặp khung hình thông minh, giúp giảm đáng kể chi phí xử lý bằng cách loại bỏ các khung hình dư thừa trong khi vẫn giữ lại thông tin hình ảnh. Giải pháp cung cấp hai phương pháp so sánh độ tương đồng riêng biệt.
So sánh Nova Multimodal Embeddings (MME) sử dụng mô hình nhúng đa phương thức của Amazon Nova để tạo ra các biểu diễn vector 256 chiều của mỗi khung hình. Mỗi khung hình được mã hóa thành một nhúng vector bằng cách sử dụng mô hình Nova MME, và khoảng cách cosine giữa các khung hình liên tiếp được tính toán. Các khung hình có khoảng cách dưới ngưỡng (mặc định 0.2, trong đó giá trị thấp hơn cho thấy độ tương đồng cao hơn) sẽ bị loại bỏ. Phương pháp này vượt trội trong việc hiểu ngữ nghĩa nội dung hình ảnh, vẫn mạnh mẽ đối với các biến thể nhỏ về ánh sáng và góc nhìn trong khi nắm bắt các khái niệm hình ảnh cấp cao. Tuy nhiên, nó phát sinh thêm chi phí API Amazon Bedrock cho việc tạo nhúng và thêm độ trễ cao hơn một chút cho mỗi khung hình. Phương pháp này được khuyến nghị cho nội dung mà sự tương đồng ngữ nghĩa quan trọng hơn sự khác biệt ở cấp độ pixel, chẳng hạn như phát hiện thay đổi cảnh hoặc xác định các khoảnh khắc độc đáo.
OpenCV ORB (Oriented FAST and Rotated BRIEF) áp dụng phương pháp thị giác máy tính, sử dụng tính năng phát hiện để xác định và khớp các điểm chính giữa các khung hình liên tiếp mà không yêu cầu các lệnh gọi API bên ngoài. ORB phát hiện các điểm chính và tính toán các mô tả nhị phân cho mỗi khung hình, tính toán điểm tương đồng dưới dạng tỷ lệ các tính năng khớp với tổng số điểm chính. Với ngưỡng mặc định là 0.325 (trong đó giá trị cao hơn cho thấy độ tương đồng cao hơn), phương pháp này cung cấp khả năng xử lý nhanh với độ trễ tối thiểu và không có chi phí API bổ sung. Việc khớp tính năng bất biến với xoay làm cho nó tuyệt vời để phát hiện chuyển động camera và chuyển đổi khung hình. Tuy nhiên, nó có thể nhạy cảm với những thay đổi ánh sáng đáng kể và có thể không nắm bắt được sự tương đồng ngữ nghĩa hiệu quả như các phương pháp dựa trên nhúng. Phương pháp này được khuyến nghị cho các kịch bản camera tĩnh như cảnh quay giám sát, hoặc các ứng dụng nhạy cảm về chi phí mà sự tương đồng ở cấp độ pixel là đủ.
Quy trình làm việc dựa trên cảnh quay: hiểu dòng chảy câu chuyện
Thay vì lấy mẫu từng khung hình riêng lẻ, quy trình làm việc dựa trên cảnh quay phân đoạn video thành các clip ngắn (cảnh quay) hoặc các phân đoạn có thời lượng cố định và áp dụng các mô hình nền tảng hiểu video cho mỗi phân đoạn. Phương pháp này nắm bắt ngữ cảnh thời gian trong mỗi cảnh quay trong khi vẫn duy trì tính linh hoạt để xử lý các video dài hơn.
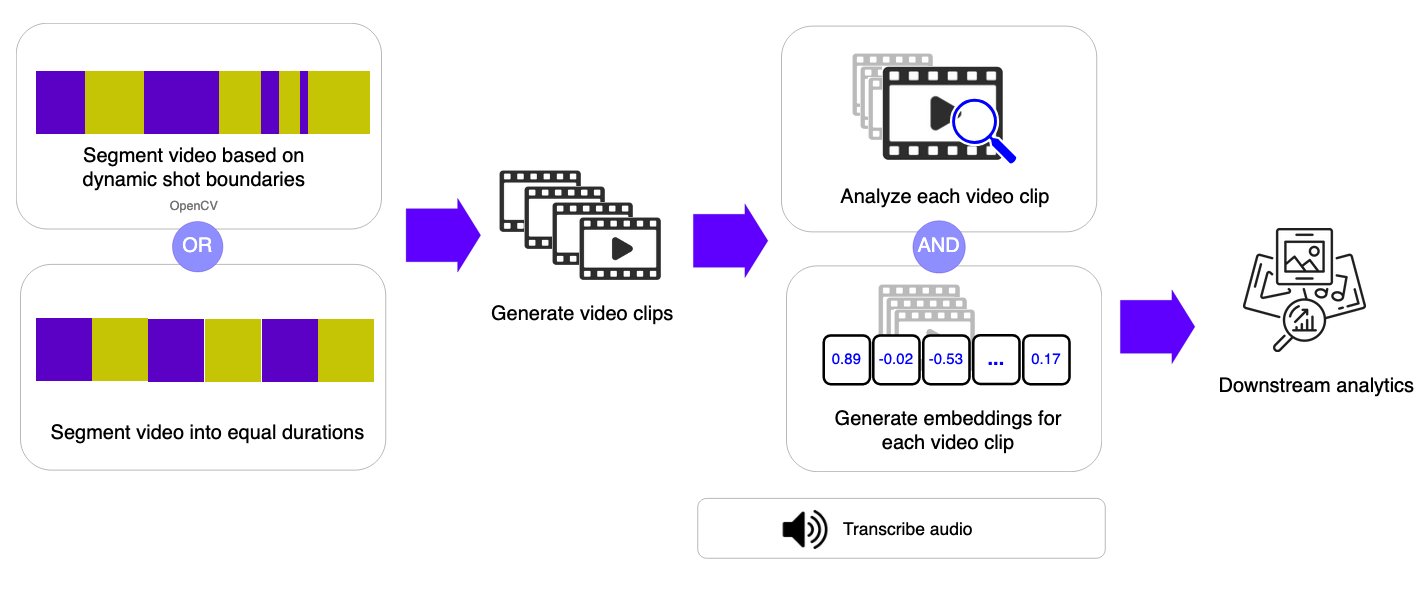
Bằng cách tạo cả nhãn ngữ nghĩa và nhúng cho mỗi cảnh quay, phương pháp này cho phép tìm kiếm và truy xuất video hiệu quả trong khi cân bằng độ chính xác và tính linh hoạt. Kiến trúc nhóm các cảnh quay thành các lô 10 để xử lý song song trong các bước tiếp theo, cải thiện thông lượng trong khi quản lý giới hạn đồng thời của AWS Lambda.
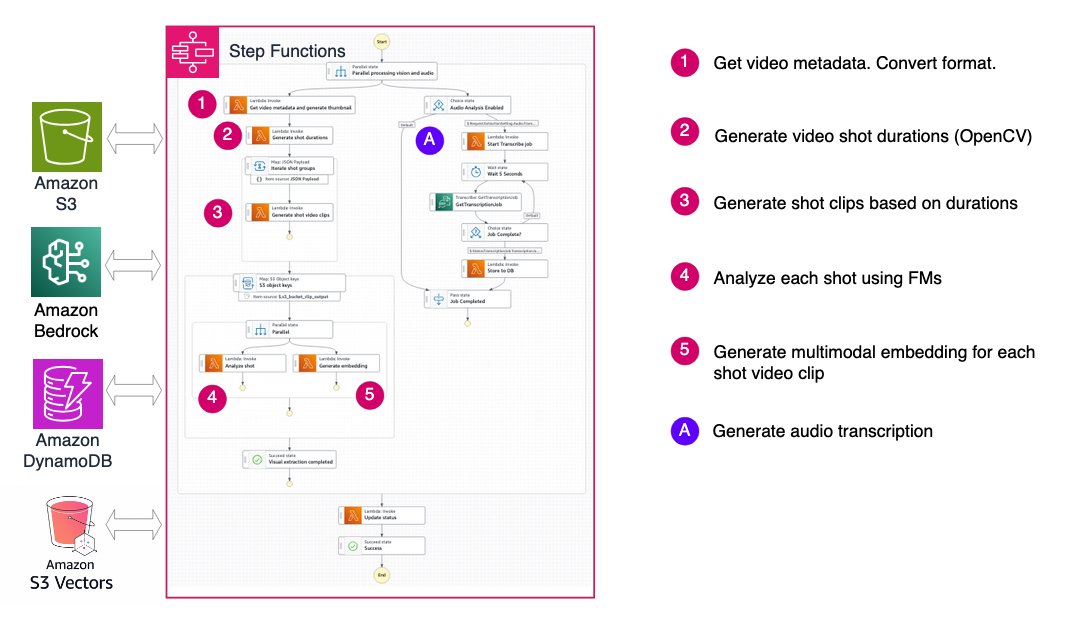
Quy trình làm việc này vượt trội trong:
- Sản xuất truyền thông: Phân tích cảnh quay để đánh dấu chương và mô tả cảnh
- Phân loại nội dung: Tự động gắn thẻ và sắp xếp thư viện video
- Tạo điểm nổi bật: Xác định các khoảnh khắc quan trọng trong nội dung dài
Phân đoạn video: hai phương pháp
Quy trình làm việc dựa trên cảnh quay cung cấp các tùy chọn phân đoạn linh hoạt để phù hợp với các đặc điểm video và trường hợp sử dụng khác nhau. Hệ thống tải xuống tệp video từ Amazon Simple Storage Service (Amazon S3) vào bộ nhớ tạm thời trong AWS Lambda, sau đó áp dụng thuật toán phân đoạn đã chọn dựa trên các tham số cấu hình.
Phát hiện cảnh OpenCV tự động chia video thành các phân đoạn dựa trên những thay đổi hình ảnh trong nội dung. Phương pháp này sử dụng thư viện PySceneDetect để phát hiện các chuyển đổi như cắt cảnh, thay đổi camera hoặc những thay đổi đáng kể trong nội dung hình ảnh.
Bằng cách xác định ranh giới cảnh tự nhiên, hệ thống giữ các khoảnh khắc liên quan được nhóm lại với nhau. Điều này làm cho phương pháp này đặc biệt hiệu quả đối với các video đã chỉnh sửa hoặc có cốt truyện như phim, chương trình TV, bài thuyết trình và vlog, nơi các cảnh đại diện cho các đơn vị nội dung có ý nghĩa. Vì việc phân đoạn tuân theo cấu trúc của chính video, độ dài phân đoạn có thể thay đổi tùy thuộc vào tốc độ và phong cách chỉnh sửa.
Phân đoạn thời lượng cố định chia video thành các khoảng thời gian có độ dài bằng nhau, bất kể điều gì đang xảy ra trong video.
Mỗi phân đoạn bao gồm một khoảng thời gian nhất quán (ví dụ: 10 giây), tạo ra các clip có thể dự đoán và đồng nhất. Phương pháp này hợp lý hóa quá trình xử lý và cải thiện thời gian xử lý cũng như ước tính chi phí. Mặc dù nó có thể chia cảnh giữa hành động, phân đoạn thời lượng cố định hoạt động tốt cho các bản ghi liên tục như cảnh quay giám sát, sự kiện thể thao hoặc luồng trực tiếp, nơi việc lấy mẫu thời gian đều đặn quan trọng hơn việc bảo toàn ranh giới câu chuyện.
Nhúng đa phương thức: tìm kiếm video ngữ nghĩa
Nhúng đa phương thức đại diện cho một phương pháp mới nổi để hiểu video, đặc biệt mạnh mẽ cho các ứng dụng tìm kiếm video ngữ nghĩa. Giải pháp cung cấp các quy trình làm việc sử dụng các mô hình Amazon Nova Multimodal Embedding và TwelveLabs Marengo có sẵn trên Amazon Bedrock.
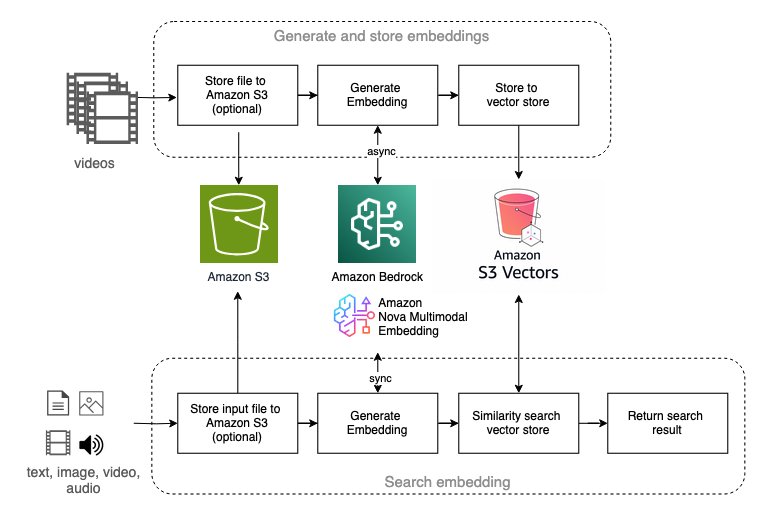
Các quy trình làm việc này cho phép:
- Tìm kiếm ngôn ngữ tự nhiên: Tìm các phân đoạn video bằng cách sử dụng truy vấn văn bản
- Tìm kiếm tương đồng hình ảnh: Định vị nội dung bằng cách sử dụng hình ảnh tham chiếu
- Truy xuất đa phương thức: Thu hẹp khoảng cách giữa nội dung văn bản và hình ảnh
Kiến trúc hỗ trợ cả hai mô hình nhúng với một giao diện thống nhất:
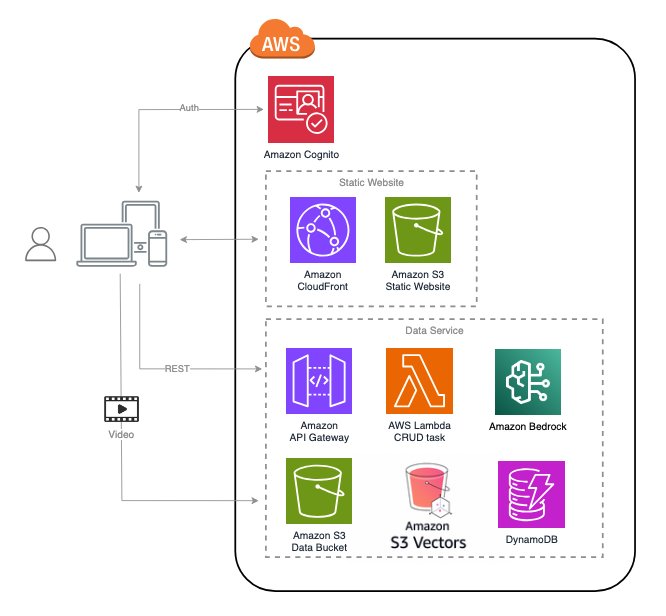
Hiểu về sự đánh đổi giữa chi phí và hiệu suất
Một trong những thách thức chính trong phân tích video sản xuất là quản lý chi phí trong khi vẫn duy trì chất lượng. Giải pháp cung cấp tính năng theo dõi mức sử dụng token và ước tính chi phí tích hợp để giúp bạn đưa ra quyết định sáng suốt về lựa chọn mô hình và cấu hình quy trình làm việc.
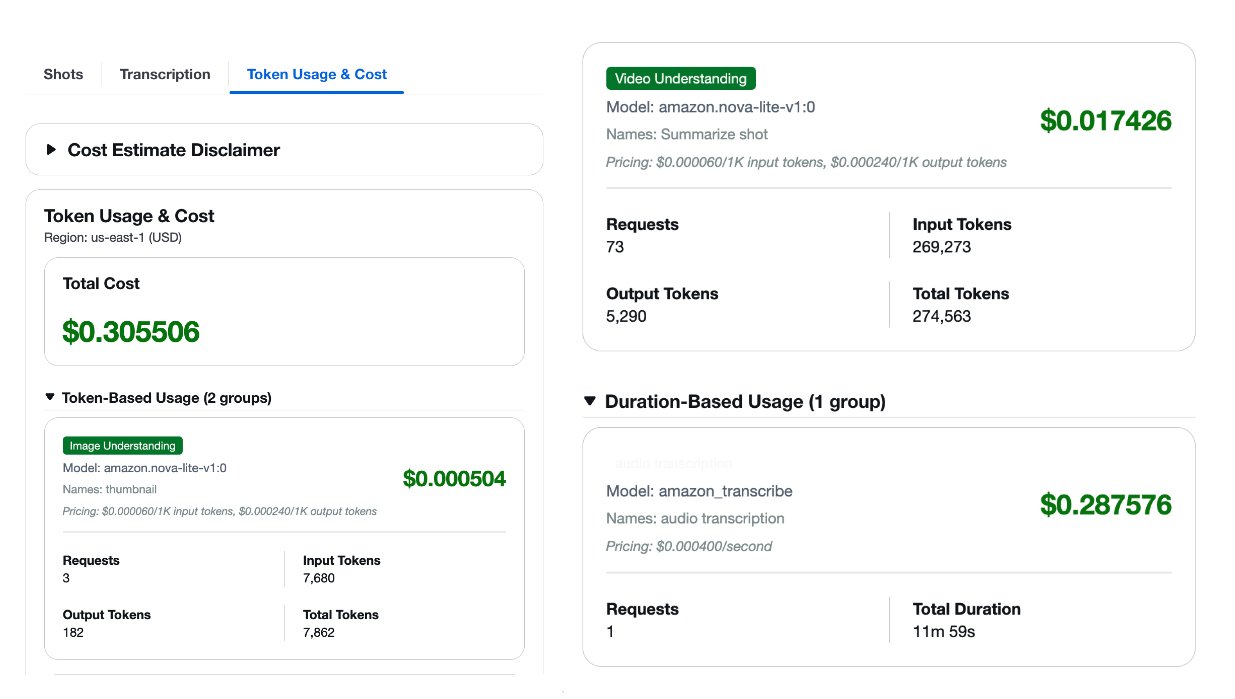
Ảnh chụp màn hình trước đó hiển thị một ước tính chi phí mẫu được tạo bởi giải pháp để minh họa định dạng. Nó không nên được sử dụng làm nguồn định giá. Đối với mỗi video được xử lý, bạn nhận được phân tích chi phí chi tiết theo loại mô hình, bao gồm các mô hình nền tảng Amazon Bedrock và Amazon Transcribe cho phiên âm âm thanh. Với khả năng hiển thị này, bạn có thể cải thiện cấu hình của mình dựa trên các yêu cầu và ràng buộc ngân sách cụ thể của mình.
Kiến trúc hệ thống
Giải pháp hoàn chỉnh được xây dựng trên các dịch vụ serverless của AWS, cung cấp khả năng mở rộng và hiệu quả chi phí:
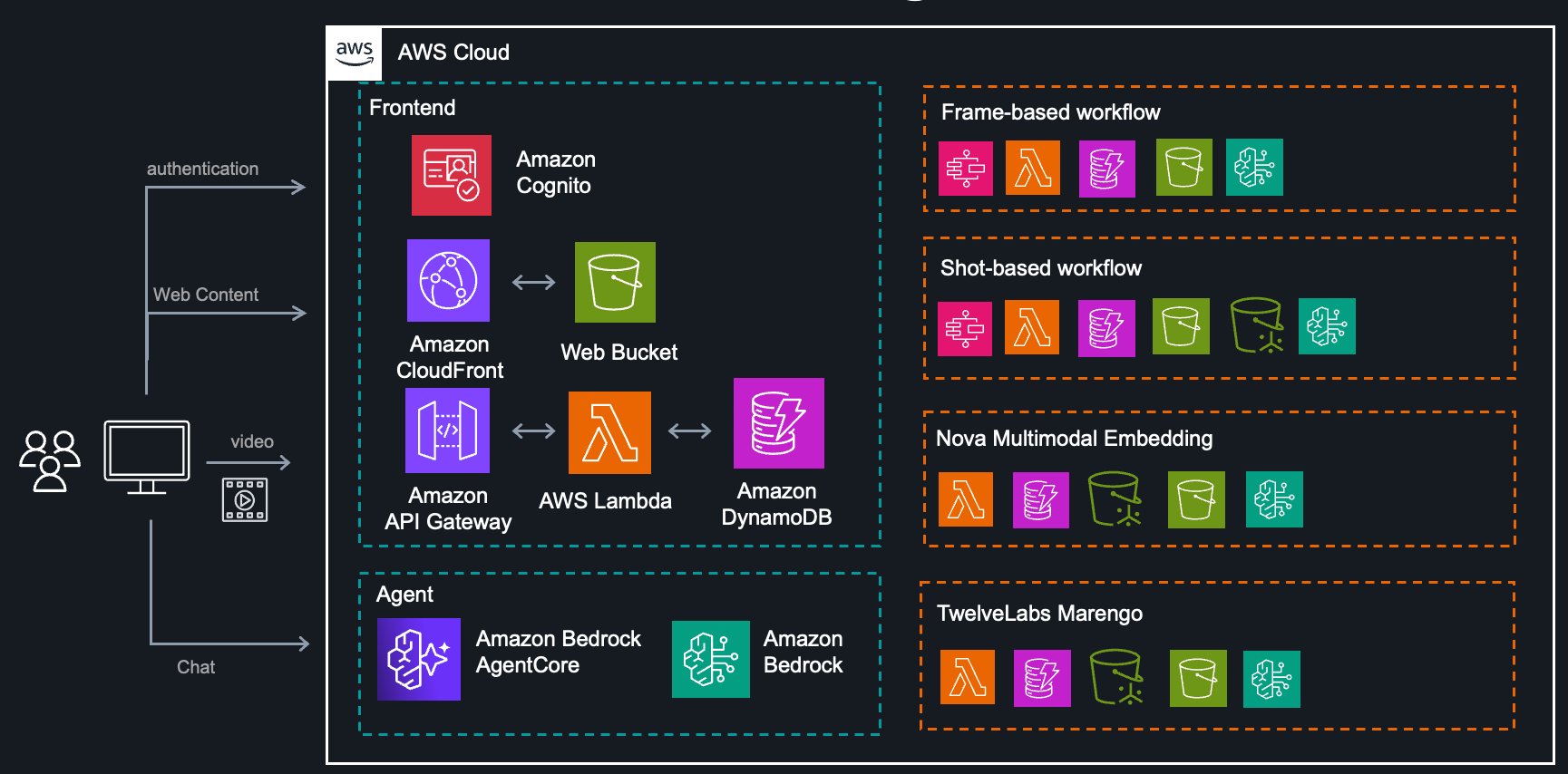
Kiến trúc bao gồm:
- Extraction Service: Điều phối các quy trình làm việc dựa trên khung hình và cảnh quay bằng cách sử dụng Step Functions
- Nova Service: Backend cho Nova Multimodal Embedding với tìm kiếm vector
- TwelveLabs Service: Backend cho các mô hình nhúng Marengo với tìm kiếm vector
- Agent Service: Trợ lý AI được hỗ trợ bởi Amazon Bedrock Agents để đề xuất quy trình làm việc
- Frontend: Ứng dụng React được phục vụ bằng Amazon CloudFront để tương tác với người dùng
- Analytics Service: Các sổ ghi chép mẫu minh họa các mẫu phân tích hạ nguồn
Truy cập siêu dữ liệu video của bạn
Giải pháp lưu trữ siêu dữ liệu được trích xuất ở nhiều định dạng để truy cập linh hoạt:
- Amazon S3: Đầu ra mô hình nền tảng thô, siêu dữ liệu tác vụ hoàn chỉnh và tài sản đã xử lý được tổ chức theo ID tác vụ và loại dữ liệu.
- Amazon DynamoDB: Dữ liệu có cấu trúc, có thể truy vấn được tối ưu hóa để truy xuất theo video, dấu thời gian hoặc loại phân tích trên nhiều bảng cho các dịch vụ khác nhau.
- Programmatic API: Gọi trực tiếp để tự động hóa, xử lý hàng loạt và tích hợp vào các pipeline hiện có.
Bạn có thể sử dụng mô hình truy cập linh hoạt này để tích hợp công cụ vào các quy trình làm việc của mình—cho dù thực hiện phân tích khám phá trong sổ ghi chép, xây dựng các pipeline tự động hay phát triển các ứng dụng sản xuất.
Các trường hợp sử dụng thực tế
Giải pháp bao gồm các sổ ghi chép mẫu minh họa ba kịch bản phổ biến:
- Phát hiện sự kiện camera IP: Tự động giám sát cảnh quay giám sát để tìm các sự kiện hoặc điều kiện cụ thể mà không cần sự giám sát liên tục của con người.
- Phân tích chương truyền thông: Phân đoạn nội dung video dài thành các chương logic với mô tả và siêu dữ liệu tự động.
- Kiểm duyệt nội dung mạng xã hội: Xem xét nội dung video do người dùng tạo ở quy mô lớn để đảm bảo tuân thủ các nguyên tắc của nền tảng.
Những ví dụ này cung cấp các điểm khởi đầu mà bạn có thể mở rộng và tùy chỉnh cho các trường hợp sử dụng cụ thể của mình.
Bắt đầu
Triển khai giải pháp
Giải pháp có sẵn dưới dạng gói CDK trên GitHub và có thể được triển khai vào tài khoản AWS của bạn chỉ với một vài lệnh. Việc triển khai tạo ra tất cả các tài nguyên cần thiết bao gồm:
- Máy trạng thái Step Functions để điều phối
- Các hàm Lambda cho logic xử lý
- Các bảng DynamoDB để lưu trữ siêu dữ liệu
- Các bucket S3 để lưu trữ tài sản
- Phân phối CloudFront cho giao diện web
- Nhóm người dùng Amazon Cognito để xác thực
Sau khi triển khai, bạn có thể ngay lập tức bắt đầu tải lên video, thử nghiệm với các pipeline phân tích và mô hình nền tảng khác nhau, và so sánh hiệu suất giữa các cấu hình.
Kết luận
Hiểu video không còn giới hạn ở các tổ chức có đội ngũ và cơ sở hạ tầng thị giác máy tính chuyên biệt. Các mô hình nền tảng đa phương thức của Amazon Bedrock, kết hợp với các dịch vụ serverless của AWS, giúp phân tích video tinh vi trở nên dễ tiếp cận và hiệu quả về chi phí. Cho dù bạn đang xây dựng hệ thống giám sát an ninh, công cụ sản xuất truyền thông hay nền tảng kiểm duyệt nội dung, ba phương pháp kiến trúc được trình bày trong giải pháp này cung cấp các điểm khởi đầu linh hoạt được thiết kế cho các yêu cầu khác nhau. Điều quan trọng là chọn phương pháp phù hợp cho trường hợp sử dụng của bạn: dựa trên khung hình để giám sát chính xác, dựa trên cảnh quay cho nội dung tường thuật và dựa trên nhúng cho tìm kiếm ngữ nghĩa. Khi các mô hình đa phương thức tiếp tục phát triển, chúng ta sẽ thấy nhiều khả năng hiểu video tinh vi hơn nữa xuất hiện. Tương lai là về AI không chỉ nhìn thấy các khung hình video mà còn thực sự hiểu câu chuyện mà chúng kể.
Sẵn sàng bắt đầu?
- Thử workshop thực hành để học có hướng dẫn
- Khám phá kho lưu trữ GitHub để biết hướng dẫn triển khai và mã nguồn
Tìm hiểu thêm:
Về tác giả

Lana Zhang
Lana Zhang là Kiến trúc sư Giải pháp Chuyên gia Cấp cao về AI tạo sinh tại AWS trong Tổ chức Chuyên gia Toàn cầu. Cô chuyên về AI/ML, tập trung vào các trường hợp sử dụng như trợ lý giọng nói AI và hiểu đa phương thức. Cô làm việc chặt chẽ với khách hàng trong nhiều ngành khác nhau, bao gồm truyền thông và giải trí, trò chơi, thể thao, quảng cáo, dịch vụ tài chính và chăm sóc sức khỏe, để giúp họ chuyển đổi các giải pháp kinh doanh thông qua AI.

Sharon Li
Sharon Li là Kiến trúc sư Giải pháp Chuyên gia AI/ML tại Amazon Web Services (AWS) có trụ sở tại Boston, Massachusetts. Với niềm đam mê tận dụng công nghệ tiên tiến, Sharon đi đầu trong việc phát triển và triển khai các giải pháp AI tạo sinh đổi mới trên nền tảng đám mây AWS.
