Bài đăng này được viết cùng với với Jonathan Hwang, người đứng đầu Foundation Data Analytics tại Zendesk.
Với vai trò là Senior Solutions Architect, tôi đã nói chuyện với các Chief technology officers (CTOs) và ban lãnh đạo điều hành của các doanh nghiệp lớn như các ngân hàng lớn, các doanh nghiệp software as a service (SaaS), các doanh nghiệp SMB và các công ty khởi nghiệp.
Qua 6 phần trong bài viết này, tôi sẽ chia sẻ những hiểu biết và kiến thức được tổng hợp từ nhiều Giám đốc Công nghệ và các nhà Lãnh đạo Kỹ thuật trong hành trình áp dụng công nghệ Điện toán đám mây. Dưới đây là những đúc kết về các cách áp dụng hay nhất về kiến trúc Điện toán đám mây được xây dựng trên kết quả thực hành của tôi để giúp bạn xây dựng và điều hành thành công các ứng dụng trên Cloud. Các cách áp dụng đa dạng khía cạnh bao gồm Xây dựng và vận hành ứng dụng, Bảo mật, Quản lý tài chính , Trí tuệ nhân tạo, các mô hình vận hành và chiến lược để dịch chuyển lên Cloud.
Trong Phần 3, cùng với người đứng đầu Foundation Analytics tại Zendesk, Jonathan Hwang, chúng tôi chỉ ra cách Zendesk từng bước mở rộng dữ liệu và khả năng phân tích của họ để sử dụng hiệu quả nguồn dữ liệu và thông tin mà họ thu thập được từ những tương tác của khách hàng. Bạn có thể tìm hiểu cách Zendesk xây dựng một kiến trúc dữ liệu hiện đại bằng cách sử dụng dịch vụ Amazon Simple Storage Service (Amazon S3) để lưu trữ, Apache Hudi để xử lý dữ liệu phân cấp và AWS Lake Formation để kiểm soát truy cập chi tiết.
Tại sao Zendesk cần xây dựng và mở rộng quy mô nền tảng dữ liệu của họ
Zendesk là một nền tảng dịch vụ khách hàng, nơi kết nối hơn 100.000 thương hiệu với hàng trăm triệu khách hàng qua điện thoại, trò chuyện, email, nhắn tin, các kênh xã hội, cộng đồng, trang web đánh giá và trung tâm trợ giúp. Họ thu thập và sử dụng dữ liệu từ các kênh này để đưa ra các quyết định cho chiến lược kinh doanh tốt nhất và tạo ra các sản phẩm mới và cải tiến các sản phẩm khác.
Vào năm 2014, đội ngũ chuyên về dữ liệu của Zendesk đã xây dựng phiên bản đầu tiên của nền tảng dữ liệu lớn (Big Data) trong trung tâm dữ liệu của riêng họ bằng cách sử dụng Apache Hadoop để áp dụng Máy học (Machine Learning). Cùng với đó, họ đã tung ra Answer Bot và Zendesk Benchmark report. Những sản phẩm này rất thành công đến nỗi chúng sớm sử dụng hết tài nguyên tính toán có sẵn trong trung tâm dữ liệu.
Vào cuối năm 2017, Zendesk nhận định rõ ràng nhu cầu cấp thiết của họ về việc hiện đại hóa dữ liệu và nhân rộng khả năng xử lý dữ liệu bằng cách dịch chuyển lên Đám mây (Cloud)
Ngày càng hiện đại hóa khả năng xử lý dữ liệu
Zendesk đã xây dựng và mở rộng khối lượng công việc của họ để sử dụng các hồ chứa dữ liệu (data lakes) trên AWS, nhưng họ sớm gặp phải những thách thức về kiến trúc mới:
- Quy tắc “right to be forgotten” trong General Data Protection Regulation (GDPR) đã gây khó khăn và tốn kém cho việc duy trì các hồ chứa dữ liệu (data lakes), bởi vì việc xóa một phần dữ liệu nhỏ cần phải xử lý lại các bộ dữ liệu lớn.
- Gặp khó khăn trong việc quản lý về Bảo Mật và Quản trị hơn khi hồ chứa dữ liệu (data lakes) được mở rộng cho một lượng người dùng lớn hơn.
Các phần sau đây cho bạn biết cách Zendesk đang giải quyết các quy tắc GDPR bằng cách phát triển từ các tệp Apache Parquet thuần trên Amazon S3 thành các Hudi dataset trên Amazon S3 để cho phép chèn / cập nhật / xóa ở mức độ dòng. Để giải quyết vấn đề bảo mật và quản trị, Zendesk đang chuyển sang AWS Lake Formation Bảo mật tập trung để kiểm soát truy cập chi tiết trên quy mô lớn.
Nền tảng dữ liệu của Zendesk
Hình 1 mô phỏng nền tảng dữ liệu hiện tại của Zendesk. Nền tảng hiện tại bao gồm ba đường dẫn dữ liệu (data pipelines): “Data Hub,” “Data Lake,” and “Self Service.”
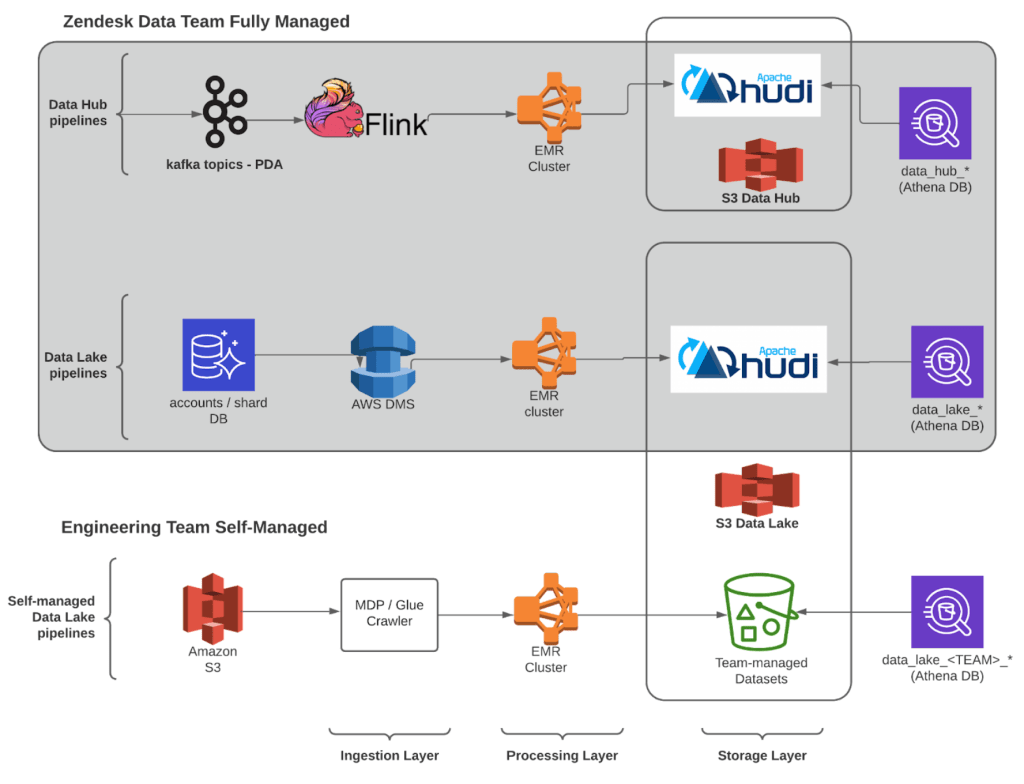
Data Lake pipelines
Data Lake và Data Hub pipelines bao gồm toàn bộ vòng đời của dữ liệu từ khi được thu thập đến khi được sử dụng.
Data Lake pipelines hợp nhất dữ liệu từ cơ sở dữ liệu có độ phân tán cao của Zendesk thành một hồ chứa dữ liệu (data lake) để phân tích.
Zendesk sử dụng Amazon Database Migration Service (AWS DMS) để thực hiện change data capture (CDC) từ hơn 1.800 Amazon Aurora MySQL databases trong 8 AWS Regions. Nó phát hiện các transaction bị thay đổi và cập nhật chúng vào hồ chứa dữ liệu (data lake) bằng cách sử dụng Amazon EMR và Hudi.
Zendesk ticket data bao gồm hơn 10 tỷ sự kiện và có quy mô lên đến petabyte dữ liệu. Các file trong hồ chứa dữ liệu (data lake) trong Amazon S3 được chuyển đổi và lưu trữ ở định dạng Apache Hudi và được đăng ký trên AWS Glue catalog và nó luôn sẵn sàng với tư cách là bảng dữ liệu để phục vụ cho truy vấn phân tích qua Amazon Athena.
Data Hub pipelines
Các Data Hub pipelines tập trung vào các sự kiện ở thời gian thực và các trường hợp sử dụng phân tích dữ liệu streaming (streaming analytics ) với Apache Kafka. Bất kỳ ứng dụng nào tại Zendesk đều có thể đưa các sự kiện lên global Kafka message bus. Apache Flink nhập các sự kiện này vào Amazon S3.
Data Hub cung cấp dữ liệu doanh nghiệp chất lượng cao, có tính khả dụng và khả năng nhân rộng cao.
Self-managed pipeline
Các đường dẫn dữ liệu tự quản lý cho phép các đội kỹ sư sản phẩm sử dụng hồ chứa dữ liệu (data lake) cho những trường hợp sử dụng không phù hợp với các mẫu tích hợp tiêu chuẩn. Tất cả các đội kỹ sư sản phẩm trong nội bộ của Zendesk có thể sử dụng các công cụ cơ bản như Amazon EMR, Amazon S3, Athena, và AWS Glue để xuất bản bộ dữ liệu phân tích của riêng họ và chia sẻ với các đội khác.
Một ví dụ đáng chú ý về vấn đề này là từ nhóm kỹ sư phát hiện sự gian lận ( fraud detection ) của Zendesk. Họ xuất bản dữ liệu và phát hiện gian lận thông qua nền tảng hồ chứa dữ liệu tự quản lý của chúng tôi và sử dụng Amazon QuickSight để trực quan hóa.
Bạn cần mô hình bảo mật và tuân thủ chi tiết
Các hồ chứa dữ liệu có thể thúc đẩy tăng trưởng thông qua việc ra quyết định và đổi mới sản phẩm nhanh hơn. Tuy nhiên, chúng cũng có thể mang đến những thách thức mới về bảo mật và tuân thủ:
- Khả năng Hiển thị và Khả năng Kiểm tra. Ai có quyền truy cập vào dữ liệu nào? Mọi người có cấp độ truy cập nào và làm thế nào / khi nào và ai đang truy cập nó?
- Kiểm soát quyền truy cập cụ thể. Làm cách nào để bạn xác định và thực thi quyền truy cập đặc quyền ít nhất vào các tập con dữ liệu trên quy mô lớn mà không tạo ra tắc nghẽn hoặc sự phụ thuộc vào yếu tố con người /đội ngũ chủ chốt.
Lake Formation giúp giải quyết những khúc mắc này bằng cách kiểm tra quyền truy cập dữ liệu và cung cấp bảo mật cấp dòng và cột cũng như mô hình kiểm soát truy cập được ủy quyền để tạo ra các trình quản lý dữ liệu cho hệ thống Bảo Mật và Quản Trị của bạn
Zendesk đã sử dụng Lake Formation để xây dựng một mô hình kiểm soát truy cập chi tiết sử dụng Bảo mật cấp dòng. Nó phát hiện các loại dữ liệu và thông tin cá nhân (Personally Identifiable Information – PII) ngay cả khi mở rộng qui mô hồ chứa dữ liệu (data lake).
Một số khách hàng của Zendesk từ chối đưa dữ liệu và thông tin của họ vào hệ thống Máy học (Machine Learning) hoặc trong các dự án khảo sát thị trường. Zendesk sử dụng Lake Formation để áp dụng bảo mật cấp hàng nhằm lọc ra các hồ sơ liên quan đến danh sách tài khoản khách hàng đã chọn không tham gia. Chúng cũng giúp người dùng dữ liệu có thể hiểu được bảng dữ liệu nào chứa PII bằng cách tự động phát hiện và gắn thẻ các cột trong danh mục dữ liệu bằng AWS Glue’s PII detection algorithm.
Giá trị của việc xử lý các dữ liệu thời gian thực
Khi bạn xử lý dữ liệu càng nhanh và sớm sau khi dữ liệu được tạo, quyết định sẽ được đưa ra nhanh hơn và chính xác hơn
Các thiết kế mẫu trong phân tích dữ liệu streaming, được thực hiện bằng cách sử dụng các dịch vụ như Amazon Managed Streaming for Apache Kafka (Amazon MSK) hoặc Amazon Kinesis, tạo ra một enterprise eventbus để trao đổi dữ liệu giữa các ứng dụng không đồng nhất trong thời gian thực.
Ví dụ: người ta thường sử dụng tính năng streaming để tăng cường quá trình thu thập dữ liệu (data ingestion) từ CSDL truyền thống bằng phương pháp CDC vào data lake cùng với quá trình streaming ingestion bổ sung cho các application events.
CDC là một mẫu thiết kế kiến trúc thu thập dữ liệu phổ biến, nhưng thông tin có thể ở mức quá chi tiết. Điều này yêu cầu bối cảnh ứng dụng phải được tái tạo lại trong data lake và business logic phải được sử giống giống nhau ở hai nơi, bên trong ứng dụng và trong lớp xử lý data lake. Điều này tạo ra nguy cơ trình bày sai ngữ nghĩa của ngữ cảnh ứng dụng.
Zendesk đã phải đối mặt với thách thức này khi thực hiện CDC data lake ingestion của họ từ các Aurora clusters. Họ đã tạo một event bus được xây dựng với Apache Kafka để tăng cường CDC của họ với các application domain events cấp cao hơn để trao đổi trực tiếp giữa các ứng dụng không đồng nhất.
Kiến trúc streaming của Zendesk
CDC database ticket table schema đôi khi có thể chứa các thuộc tính phức tạp và không cần thiết dành riêng cho ứng dụng và không thể hiện được domain model của ticket. Điều này khiến cho downstream consumers không hiểu để sử dụng dữ liệu. Một ticket domain object có thể bao gồm một số database tables khi được modeled ở dạng third normal form, điều này làm cho việc truy vấn đối với các nhà phân tích trở nên khó khăn. Đây cũng là một phương pháp tích hợp dễ gây ra vấn đề vì các ứng dụng và dịch vụ sử dụng dữ liệu có thể dễ dàng bị ảnh hưởng khi logic của ứng dụng thay đổi, điều này khiến cho việc thiết lập một chế độ xem dữ liệu chung trở nên khó khăn.
Để hướng tới giao tiếp dựa trên sự kiện giữa các microservices, Zendesk đã tạo dự án Platform Data Architecture (PDA), sử dụng standard object model để thể hiện chế độ xem ngữ nghĩa, cấp cao hơn của dữ liệu ứng dụng của họ. Standard objects là các domain objects được thiết kế để giao tiếp giữa nhiều domain và không chịu ảnh hưởng bởi cơ chế CDC. Cuối cùng, Zendesk đặt mục tiêu chuyển đổi data architecture của họ từ một tập hợp các isolated products và data silos thành một nền tảng dữ liệu thống nhất gắn kết.
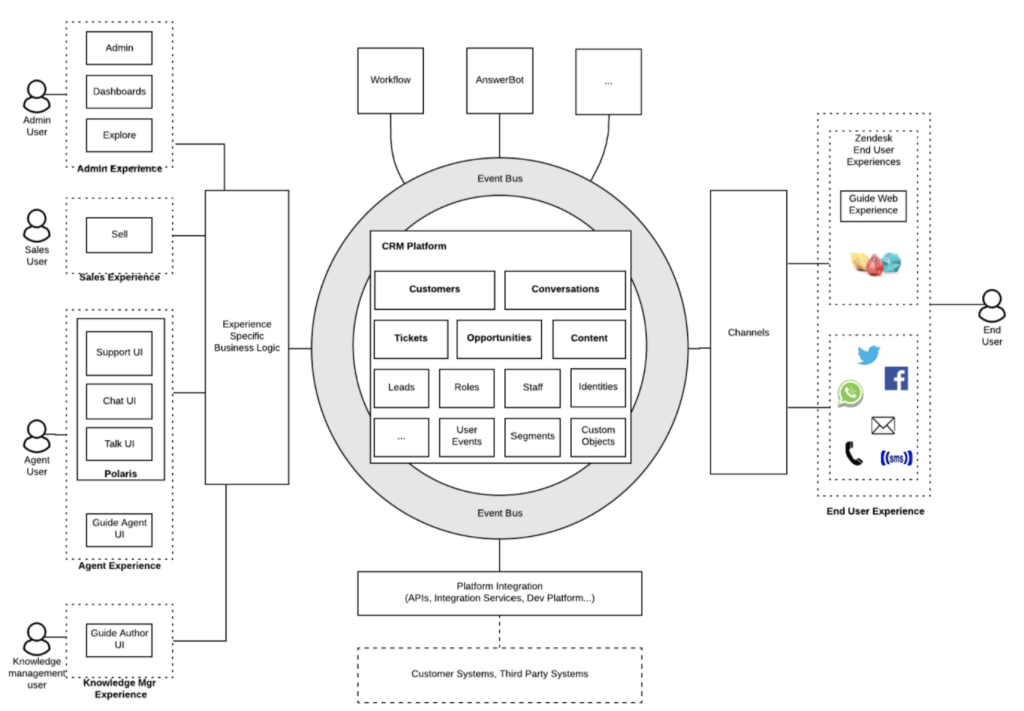
Hình 2 cho thấy cách tất cả các sản phẩm và người dùng của Zendesk tích hợp thông qua các standard objects chung và các standard events trong Data Hub. Các ứng dụng publish và sử dụng ( consume ) standard objects và events đều đến từ event bus.
Ví dụ, một complete ticket standard object sẽ được xuất bản lên eventbus bất cứ khi nào nó được tạo, cập nhật hoặc thay đổi. Về mặt sử dụng ( consume ), các sự kiện này được nhóm sản phẩm sử dụng để kích hoạt các khả năng của nền tảng như tìm kiếm, xuất dữ liệu, phân tích và trang tổng quan báo cáo.
Tóm lược
Khi hoạt động kinh doanh của Zendesk phát triển, data lake của họ đã phát triển từ các tệp Parquet đơn giản trên Amazon S3 thành data lake và có thể cập nhật tăng dần dựa trên kiến trúc Hudi hiện đại. Giờ đây, các chính sách bảo mật IAM của họ được sử dụng nhằm kiểm soát truy cập chi tiết thông qua Lake Formation.
Chúng tôi đã nhiều lần chứng kiến những cải tiến về mặt kiến trúc một cách từ từ đạt được thành công vì nó làm giảm rủi ro kinh doanh liên quan đến sự thay đổi và cung cấp đủ thời gian cho nhóm của bạn để tìm hiểu và đánh giá các hoạt động và các dịch vụ được quản lý trên Cloud.
Nếu bạn muốn tìm kiếm thêm nội dung về kiến trúc? AWS Architecture Center cung cấp các sơ đồ kiến trúc tham chiếu, các giải pháp kiến trúc đã được hiệu chỉnh, các phương pháp hay nhất Well-Architected, các mẫu, biểu tượng và hơn thế nữa!
Các bài viết khác trong loạt bài này
