Để xây dựng một doanh nghiệp dựa trên dữ liệu, việc phổ biến tài sản dữ liệu doanh nghiệp trong một danh mục dữ liệu là rất quan trọng. Với một danh mục dữ liệu thống nhất, bạn có thể nhanh chóng tìm kiếm các bộ dữ liệu và tìm kiếm schema dữ liệu, định dạng dữ liệu và vị trí. AWS Glue Data Catalog cung cấp một kho dữ liệu đồng nhất nơi các hệ thống khác nhau có thể lưu trữ và tìm thấy siêu dữ liệu để theo dõi dữ liệu trong các kho dữ liệu.
Apache Flink là một công cụ xử lý dữ liệu phổ biến để thực hiện ETL phân tán, phân tích và ứng dụng dựa trên sự kiện được mở rộng. Nó cung cấp quản lý thời gian và trạng thái chính xác với tính chịu lỗi. Flink có thể xử lý dòng có giới hạn (batch) và dòng không giới hạn (stream) với một API hoặc ứng dụng thống nhất. Sau khi dữ liệu được xử lý bằng Apache Flink, các ứng dụng downstream có thể truy cập vào dữ liệu được tổ chức với một danh mục dữ liệu đồng nhất. Với siêu dữ liệu thống nhất, cả các ứng dụng xử lý dữ liệu và tiêu thụ dữ liệu có thể truy cập vào các bảng bằng cách sử dụng siêu dữ liệu giống nhau.
Bài viết này cho thấy cho bạn cách tích hợp Apache Flink trên Amazon EMR với AWS Glue Data Catalog để bạn có thể nhập dữ liệu streaming và truy cập vào dữ liệu gần thời gian thực để phân tích kinh doanh.
Kiến trúc của Apache Flink connector và catalog
Apache Flink sử dụng connector và catalog để tương tác với dữ liệu và siêu dữ liệu. Hình sau cho thấy kiến trúc của Apache Flink connector để đọc/ghi dữ liệu và catalog để đọc/ghi siêu dữ liệu.
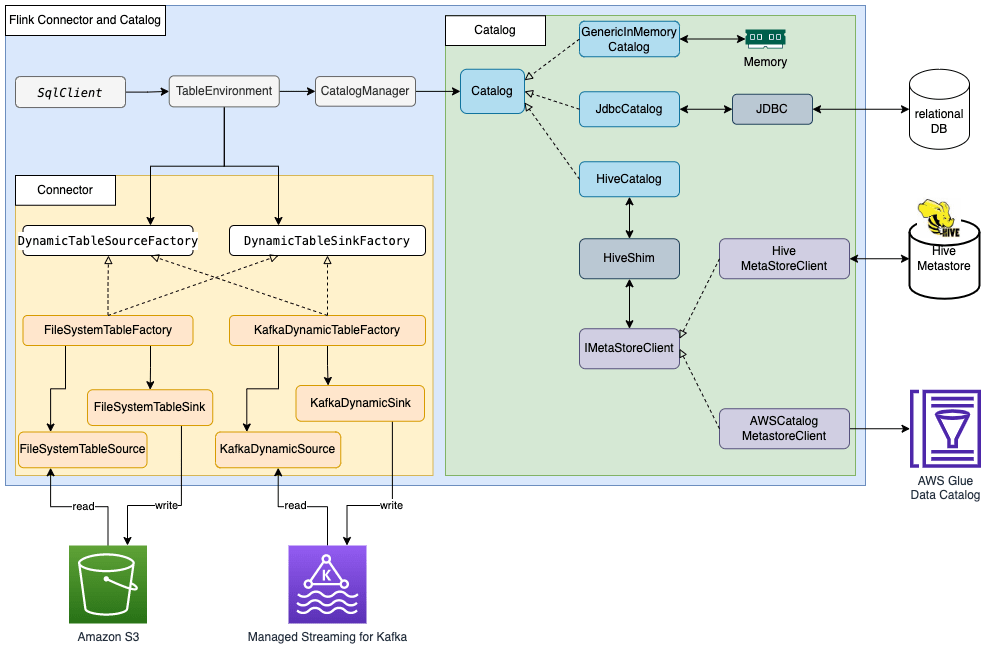
Đối với đọc/ghi dữ liệu, Flink sử dụng giao diện DynamicTableSourceFactory để đọc và DynamicTableSinkFactory để ghi. Mỗi connector của Flink sẽ thực hiện hai giao diện này để truy cập dữ liệu trong các kho lưu trữ khác nhau. Ví dụ, connector FileSystem của Flink có FileSystemTableFactory để đọc/ghi dữ liệu trên Hadoop Distributed File System (HDFS) hoặc Amazon Simple Storage Service (Amazon S3), connector HBase của Flink có HBase2DynamicTableFactory để đọc/ghi dữ liệu trên HBase, và connector Kafka của Flink có KafkaDynamicTableFactory để đọc/ghi dữ liệu trên Kafka. Bạn có thể tham khảo Table & SQL Connectors để biết thêm thông tin.
Đối với đọc/ghi siêu dữ liệu, Flink có giao diện catalog. Flink có ba triển khai sẵn cho catalog. GenericInMemoryCatalog lưu trữ dữ liệu catalog trong bộ nhớ. JdbcCatalog lưu trữ dữ liệu catalog trong cơ sở dữ liệu quan hệ hỗ trợ JDBC. Hiện tại, cơ sở dữ liệu MySQL và PostgreSQL được hỗ trợ trong JDBC catalog. HiveCatalog lưu trữ dữ liệu catalog trong Hive Metastore. HiveCatalog sử dụng HiveShim để cung cấp tính tương thích với các phiên bản Hive khác nhau. Chúng ta có thể cấu hình các client metastore khác nhau để sử dụng Hive Metastore hoặc AWS Glue Data Catalog. Trong bài viết này, chúng ta cấu hình thuộc tính hive.metastore.client.factory.class của Amazon EMR thành com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory (xem sử dụng AWS Glue Data Catalog như metastore cho Hive) để sử dụng AWS Glue Data Catalog để lưu trữ dữ liệu catalog của Flink. Tham khảo Catalogs để biết thêm thông tin.
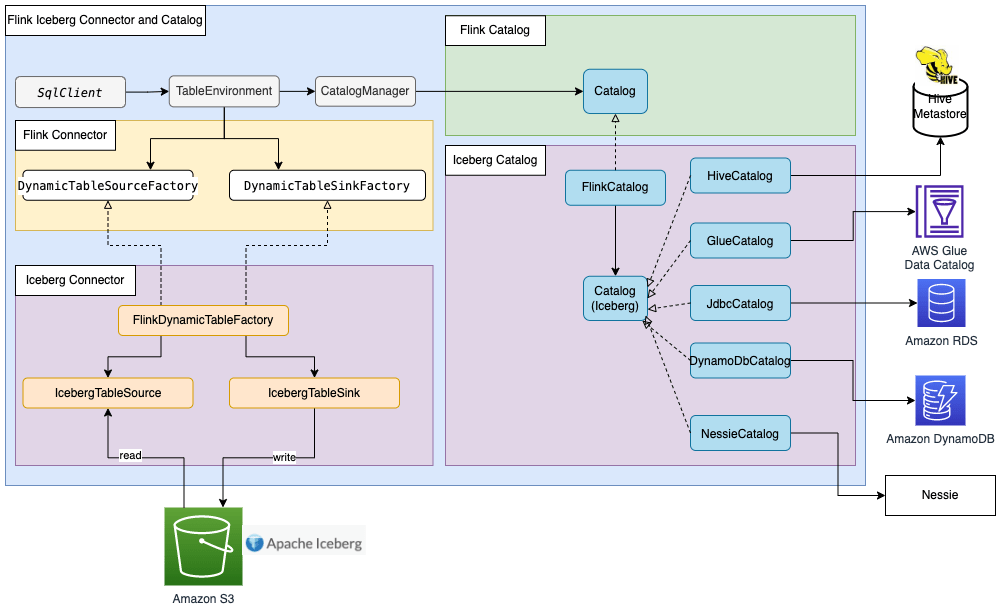
Hầu hết các kết nối tích hợp sẵn trong Flink, chẳng hạn như Kafka, Amazon Kinesis, Amazon DynamoDB, Elasticsearch, hoặc FileSystem, có thể sử dụng Flink HiveCatalog để lưu trữ siêu dữ liệu trong AWS Glue Data Catalog. Tuy nhiên, một số kết nối cài đặt như Apache Iceberg có cơ chế quản lý catalog riêng của chúng. FlinkCatalog trong Iceberg cài đặt giao diện catalog trong Flink. FlinkCatalog trong Iceberg có một wrapper đến cài đặt catalog riêng của nó. Sơ đồ sau cho thấy mối quan hệ giữa Apache Flink, kết nối Iceberg và catalog. Để biết thêm thông tin, tham khảo Tạo catalog và sử dụng catalog và Catalogs.
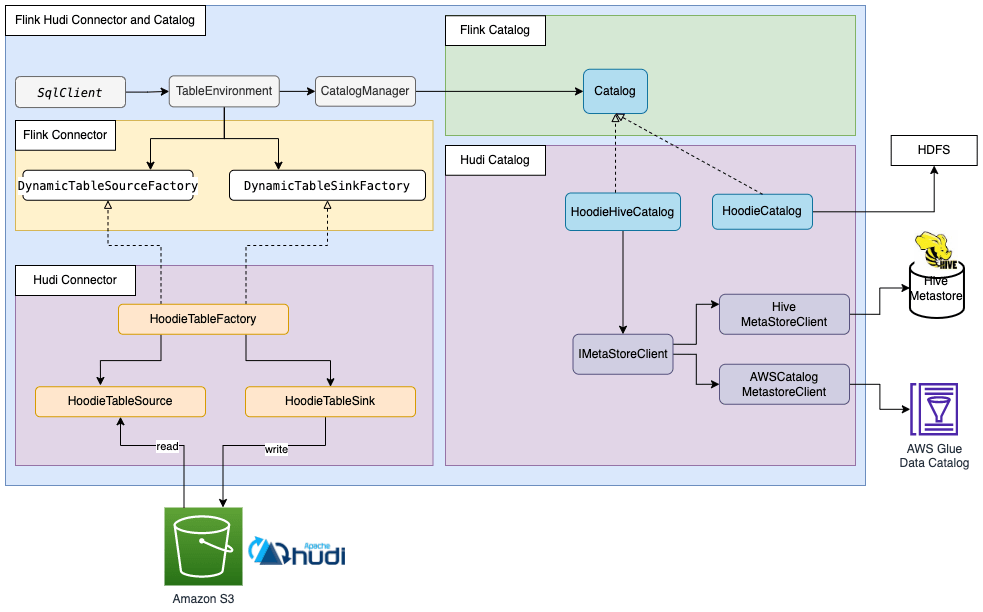
Apache Hudi cũng có cơ chế quản lý metadata riêng của mình. Cả HoodieCatalog và HoodieHiveCatalog đều triển khai một giao diện catalog trong Flink. HoodieCatalog lưu trữ metadata trên hệ thống tệp như HDFS. HoodieHiveCatalog lưu trữ metadata trong Hive Metastore hoặc AWS Glue Data Catalog, tùy thuộc vào việc bạn cấu hình hive.metastore.client.factory.class để sử dụng com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory. Sơ đồ sau thể hiện mối quan hệ giữa Apache Flink, connector Hudi và catalog. Để biết thêm thông tin, vui lòng tham khảo Create Catalog.
Bởi vì Iceberg và Hudi có các cơ chế quản lý catalog khác nhau, chúng tôi trình bày ba kịch bản tích hợp Flink với AWS Glue Data Catalog trong bài đăng này:
- Đọc/Ghi vào các bảng Iceberg trong Flink với metadata trong Glue Data Catalog
- Đọc/Ghi vào các bảng Hudi trong Flink với metadata trong Glue Data Catalog
- Đọc/Ghi vào các định dạng lưu trữ khác trong Flink với metadata trong Glue Data Catalog
Tổng quan về giải pháp
Sơ đồ kiến trúc chung của giải pháp được mô tả trong bài đăng này như sau:
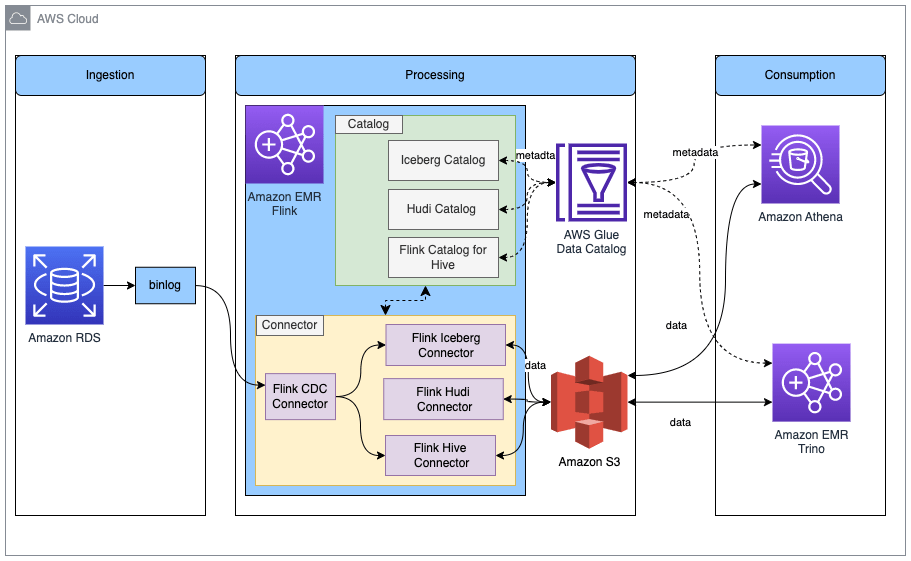
Trong giải pháp này, chúng ta cho phép Amazon RDS cho MySQL binlog để trích xuất các thay đổi giao dịch theo thời gian thực. Bộ kết nối EMR Flink CDC của Amazon đọc dữ liệu binlog và xử lý dữ liệu. Dữ liệu đã được biến đổi có thể được lưu trữ trong Amazon S3. Chúng tôi sử dụng AWS Glue Data Catalog để lưu trữ siêu dữ liệu như lược đồ bảng và vị trí bảng. Các ứng dụng tiêu thụ dữ liệu phía dưới như Amazon Athena hoặc Amazon EMR Trino truy cập dữ liệu cho phân tích kinh doanh.
Các bước cấu hình giải pháp như sau:
- Bật chế độ binlog cho Amazon RDS cho MySQL và khởi tạo cơ sở dữ liệu.
- Tạo một cụm EMR với AWS Glue Data Catalog.
- Nhận dữ liệu CDC (thay đổi dữ liệu) với Apache Flink CDC trong Amazon EMR.
- Lưu trữ dữ liệu đã xử lý trong Amazon S3 với siêu dữ liệu trong AWS Glue Data Catalog.
- Xác minh tất cả siêu dữ liệu bảng được lưu trữ trong AWS Glue Data Catalog.
- Tiêu thụ dữ liệu với Athena hoặc Amazon EMR Trino cho phân tích kinh doanh.
- Cập nhật và xóa các bản ghi nguồn trong Amazon RDS cho MySQL và xác minh sự phản ánh của các bảng hồi quy dữ liệu.
Điều kiện tiên quyết
Bài viết này sử dụng một vai trò IAM AWS với quyền cho các dịch vụ sau:
- Amazon RDS cho MySQL (5.7.40)
- Amazon EMR (6.9.0)
- Amazon Athena
- AWS Glue Data Catalog
- Amazon S3
Kích hoạt binlog cho Amazon RDS cho MySQL và khởi tạo cơ sở dữ liệu
Để bật CDC trong Amazon RDS cho MySQL, chúng ta cần cấu hình ghi nhật ký nhị phân cho Amazon RDS cho MySQL. Tham khảo Configuring MySQL binary logging để biết thêm thông tin. Chúng ta cũng tạo cơ sở dữ liệu salesdb trong MySQL và tạo các bảng customer, order và các bảng khác để thiết lập nguồn dữ liệu.
- Trên bảng điều khiển Amazon RDS, chọn Parameter groups trong bảng điều hướng.
- Tạo một nhóm tham số mới cho MySQL.
- Chỉnh sửa nhóm tham số bạn vừa tạo để đặt giá trị binlog_row_image=full.
- Tạo một RDS cho trường hợp sử dụng MySQL với nhóm tham số.
- Ghi lại các giá trị cho tên máy chủ (hostname), tên người dùng (username) và mật khẩu (password), mà chúng ta sẽ sử dụng sau này.
- Tải xuống kịch bản khởi tạo cơ sở dữ liệu MySQL từ Amazon S3 bằng cách chạy lệnh sau:
aws s3 cp s3://emr-workshops-us-west-2/glue_immersion_day/scripts/salesdb.sql ./salesdb.sql
- Kết nối vào cơ sở dữ liệu RDS cho MySQL và chạy lệnh salesdb.sql để khởi tạo cơ sở dữ liệu, cung cấp tên máy chủ và tên người dùng theo cấu hình cơ sở dữ liệu RDS cho MySQL của bạn:
mysql -h <hostname> -u <username> -p
mysql> source salesdb.sql
Tạo một cụm EMR với AWS Glue Data Catalog
Từ phiên bản Amazon EMR 6.9.0, API/SQL bảng Flink có thể tích hợp với AWS Glue Data Catalog. Để sử dụng tích hợp Flink và AWS Glue, bạn phải tạo một phiên bản Amazon EMR 6.9.0 hoặc sau đó.
- Tạo cấu hình tệp iceberg.properties cho tích hợp Amazon EMR Trino với Data Catalog. Khi định dạng bảng là Iceberg, tệp của bạn nên có nội dung sau đây:
iceberg.catalog.type=glue
connector.name=iceberg
- Tải lên iceberg.properties lên một bucket S3, ví dụ như DOC-EXAMPLE-BUCKET.
Để biết thêm thông tin về cách tích hợp Amazon EMR Trino với Iceberg, tham khảo Use an Iceberg cluster with Trino.
- Tạo tệp trino-glue-catalog-setup.sh để cấu hình tích hợp Trino với Data Catalog. Sử dụng trino-glue-catalog-setup.sh như là bootstrap script. Tệp của bạn nên có nội dung sau đây (thay thế DOC-EXAMPLE-BUCKET bằng tên bucket S3 của bạn):
set -ex
sudo aws s3 cp s3://DOC-EXAMPLE-BUCKET/iceberg.properties /etc/trino/conf/catalog/iceberg.properties
- Tải lên trino-glue-catalog-setup.sh lên bucket S3 của bạn (DOC-EXAMPLE-BUCKET).
Tham khảo Create bootstrap actions to install additional software để biết thêm thông tin.
- Tạo tệp flink-glue-catalog-setup.sh để cấu hình tích hợp Flink với Data Catalog.
- Sử dụng một script runner và chạy script flink-glue-catalog-setup.sh như một bước chức năng.
Tệp của bạn nên có nội dung sau đây (tên tệp JAR ở đây sử dụng Amazon EMR 6.9.0; tên tệp JAR phiên bản sau có thể thay đổi, vì vậy hãy đảm bảo cập nhật theo phiên bản Amazon EMR của bạn).
Lưu ý rằng ở đây chúng ta sử dụng một bước Amazon EMR, không phải là bootstrap, để chạy script này. Một script bước Amazon EMR được chạy sau khi Amazon EMR Flink được cấp phát.
set -ex
sudo cp /usr/lib/hive/auxlib/aws-glue-datacatalog-hive3-client.jar /usr/lib/flink/lib
sudo cp /usr/lib/hive/lib/antlr-runtime-3.5.2.jar /usr/lib/flink/lib
sudo cp /usr/lib/hive/lib/hive-exec.jar /lib/flink/lib
sudo cp /usr/lib/hive/lib/libfb303-0.9.3.jar /lib/flink/lib
sudo cp /usr/lib/flink/opt/flink-connector-hive_2.12-1.15.2.jar /lib/flink/lib
sudo chmod 755 /usr/lib/flink/lib/aws-glue-datacatalog-hive3-client.jar
sudo chmod 755 /usr/lib/flink/lib/antlr-runtime-3.5.2.jar
sudo chmod 755 /usr/lib/flink/lib/hive-exec.jar
sudo chmod 755 /usr/lib/flink/lib/libfb303-0.9.3.jar
sudo chmod 755 /usr/lib/flink/lib/flink-connector-hive_2.12-1.15.2.jar
sudo wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.2.1/flink-sql-connector-mysql-cdc-2.2.1.jar -O /lib/flink/lib/flink-sql-connector-mysql-cdc-2.2.1.jar
sudo chmod 755 /lib/flink/lib/flink-sql-connector-mysql-cdc-2.2.1.jar
sudo ln -s /usr/share/aws/iceberg/lib/iceberg-flink-runtime.jar /usr/lib/flink/lib/
sudo ln -s /usr/lib/hudi/hudi-flink-bundle.jar /usr/lib/flink/lib/
sudo mv /usr/lib/flink/opt/flink-table-planner_2.12-1.15.2.jar /usr/lib/flink/lib/
sudo mv /usr/lib/flink/lib/flink-table-planner-loader-1.15.2.jar /usr/lib/flink/opt/
- Tải tệp flink-glue-catalog-setup.sh lên bucket S3 của bạn (DOC-EXAMPLE-BUCKET).
Tham khảo Configuring Flink to Hive Metastore in Amazon EMR để biết thêm thông tin về cách cấu hình Flink và Hive Metastore. Tham khảo Run commands and scripts on an Amazon EMR cluster để biết thêm chi tiết về cách chạy lệnh và script trên Amazon EMR.
- Tạo một cluster EMR 6.9.0 với các ứng dụng Hive, Flink và Trino.
Bạn có thể tạo một cluster EMR bằng AWS Command Line Interface (AWS CLI) hoặc AWS Management Console. Tham khảo phần con của mỗi phương pháp để biết thêm hướng dẫn.
Tạo một cụm EMR bằng AWS CLI
Để sử dụng AWS CLI, hoàn thành các bước sau:
- Tạo tệp emr-flink-trino-glue.json để cấu hình Amazon EMR sử dụng Data Catalog. Tệp của bạn nên có nội dung sau:
[
{
“Classification”: “hive-site”,
“Properties”: {
“hive.metastore.client.factory.class”: “com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory”
}
},
{
“Classification”: “trino-connector-hive”,
“Properties”: {
“hive.metastore”: “glue”
}
}
]
- Chạy lệnh sau để tạo cụm EMR. Cung cấp đường dẫn thư mục chứa tệp emr-flink-trino-glue.json trên máy cục bộ của bạn, bucket S3, khu vực của cụm EMR, tên khóa EC2 và bucket S3 cho logs của EMR.
aws emr create-cluster –release-label emr-6.9.0 \
–applications Name=Hive Name=Flink Name=Spark Name=Trino \
–region us-west-2 \
–name flink-trino-glue-emr69 \
–configurations “file:///<your configuration path>/emr-flink-trino-glue.json” \
–bootstrap-actions ‘[{“Path”:”s3://DOC-EXAMPLE-BUCKET/trino-glue-catalog-setup.sh”,”Name”:”Add iceberg.properties for Trino”}]’ \
–steps ‘[{“Args”:[“s3://DOC-EXAMPLE-BUCKET/flink-glue-catalog-setup.sh”],”Type”:”CUSTOM_JAR”,”ActionOnFailure”:”CONTINUE”,”Jar”:”s3://<region>.elasticmapreduce/libs/script-runner/script-runner.jar”,”Properties”:””,”Name”:”Flink-glue-integration”}]’ \
–instance-groups \
InstanceGroupType=MASTER,InstanceType=m6g.2xlarge,InstanceCount=1 \
InstanceGroupType=CORE,InstanceType=m6g.2xlarge,InstanceCount=2 \
–use-default-roles \
–ebs-root-volume-size 30 \
–ec2-attributes KeyName=<keyname> \
–log-uri s3://<s3-bucket-for-emr>/elasticmapreduce/
Tạo cụm EMR trên bảng điều khiển
Để sử dụng giao diện console, hãy thực hiện các bước sau:
- Trên giao diện Amazon EMR, tạo một EMR cluster và chọn Use for Hive table metadata cho các thiết lập AWS Glue Data Catalog.
- Thêm các thiết lập cấu hình với đoạn mã sau:
[
{
“Classification”: “trino-connector-hive”,
“Properties”: {
“hive.metastore”: “glue”
}
}
]
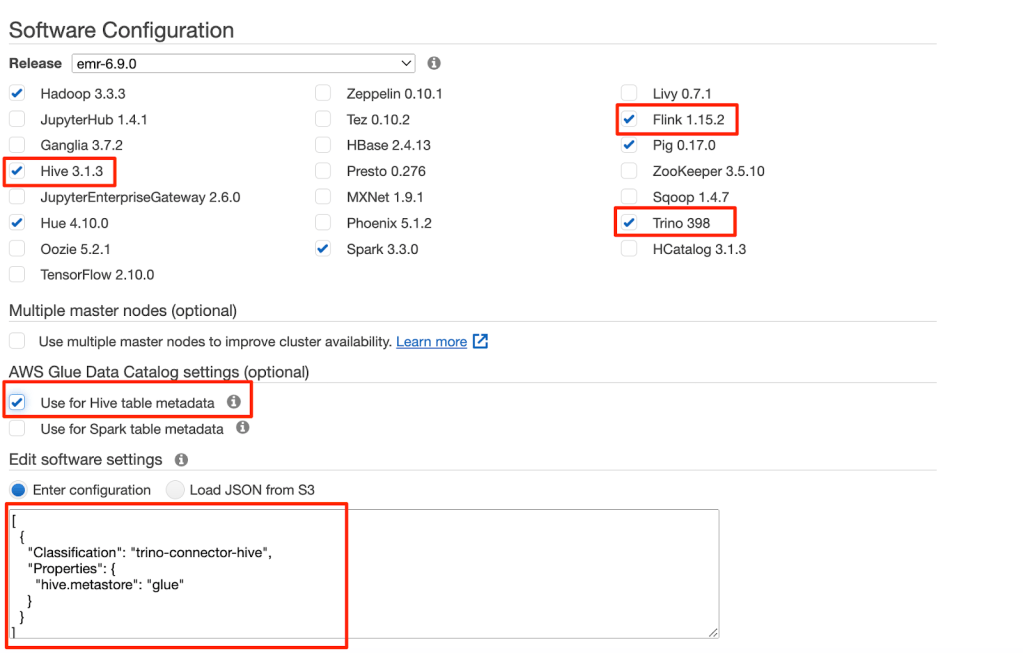
- Trong phần Steps, thêm một bước gọi là Custom JAR.
- Đặt vị trí JAR thành s3://<region>.elasticmapreduce/libs/script-runner/script-runner.jar, trong đó <region> là khu vực mà cụm EMR của bạn đang đặt.
- Đặt Arguments thành đường dẫn S3 mà bạn đã tải lên trước đó.
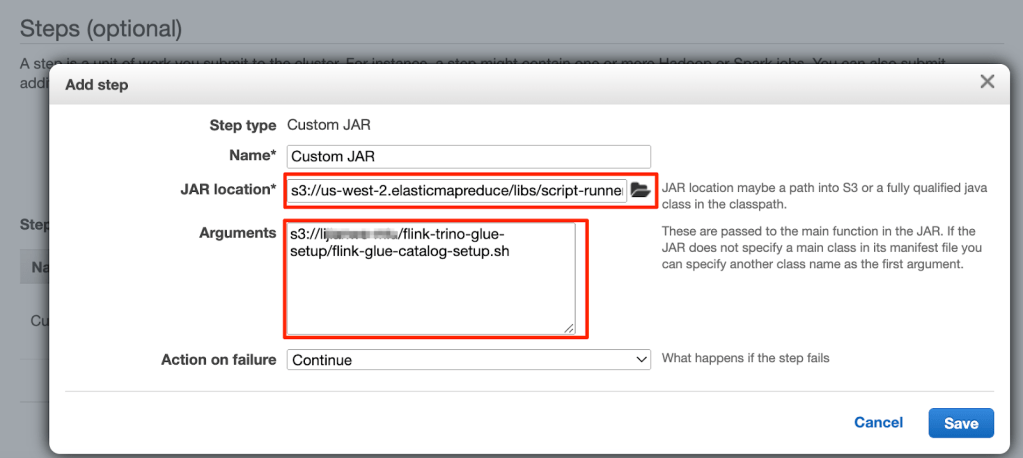
- Trong phần Bootstrap Actions, chọn Custom Action.
- Thiết lập Script location thành đường dẫn S3 mà bạn đã tải lên trước đó.
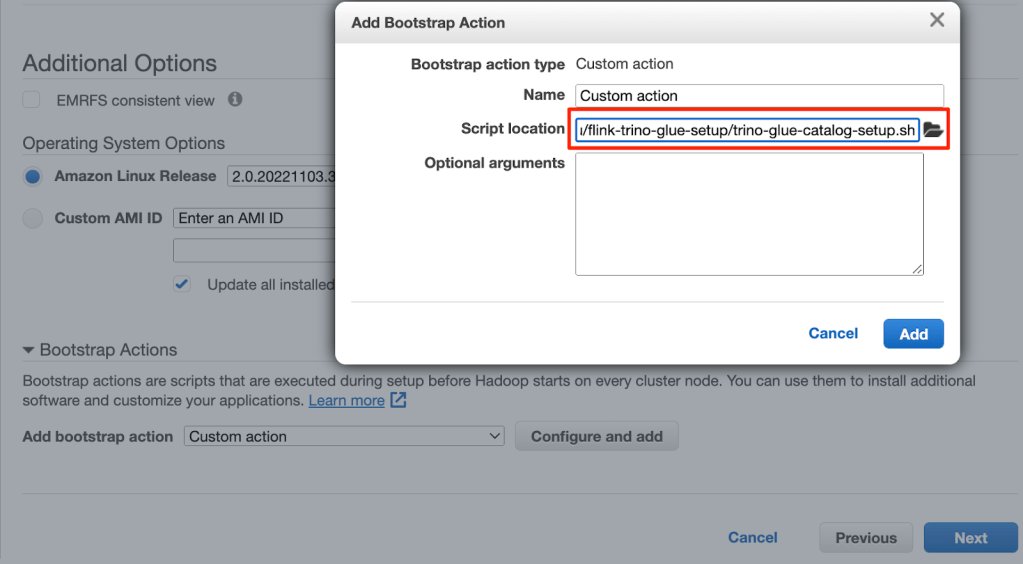
- Tiếp tục các bước tiếp theo để hoàn thành việc tạo cụm EMR của bạn.
Đưa dữ liệu CDC vào với Apache Flink CDC trên Amazon EMR
Bộ kết nối Flink CDC hỗ trợ đọc bản chụp cơ sở dữ liệu và bắt các cập nhật trong các bảng được cấu hình. Chúng tôi đã triển khai bộ kết nối Flink CDC cho MySQL bằng cách tải xuống flink-sql-connector-mysql-cdc-2.2.1.jar và đưa nó vào thư viện Flink khi tạo cluster EMR của chúng tôi. Bộ kết nối Flink CDC có thể sử dụng Flink Hive catalog để lưu trữ lược đồ bảng Flink CDC vào Hive Metastore hoặc AWS Glue Data Catalog. Trong bài viết này, chúng tôi sử dụng Data Catalog để lưu trữ bảng Flink CDC của chúng tôi.
Hoàn thành các bước sau để đưa cơ sở dữ liệu và bảng RDS cho MySQL vào Flink CDC và lưu trữ siêu dữ liệu trong Data Catalog:
- Kết nối SSH đến EMR primary node.
- Bắt đầu Flink trên phiên YARN bằng cách chạy lệnh sau, cung cấp tên bucket S3 của bạn:
flink-yarn-session -d -jm 2048 -tm 4096 -s 2 \
-D state.backend=rocksdb \
-D state.backend.incremental=true \
-D state.checkpoint-storage=filesystem \
-D state.checkpoints.dir=s3://<flink-glue-integration-bucket>/flink-checkponts/ \
-D state.checkpoints.num-retained=10 \
-D execution.checkpointing.interval=10s \
-D execution.checkpointing.mode=EXACTLY_ONCE \
-D execution.checkpointing.externalized-checkpoint-retention=RETAIN_ON_CANCELLATION \
-D execution.checkpointing.max-concurrent-checkpoints=1
- Bắt đầu Flink SQL client CLI bằng cách chạy lệnh sau:
/usr/lib/flink/bin/sql-client.sh embedded
- Tạo catalog Flink Hive bằng cách chỉ định loại catalog là hive và cung cấp tên bucket S3 của bạn:
CREATE CATALOG glue_catalog WITH (
‘type’ = ‘hive’,
‘default-database’ = ‘default’,
‘hive-conf-dir’ = ‘/etc/hive/conf.dist’
);
USE CATALOG glue_catalog;
CREATE DATABASE IF NOT EXISTS flink_cdc_db WITH (‘hive.database.location-uri’= ‘s3://<flink-glue-integration-bucket>/flink-glue-for-hive/warehouse/’)
use flink_cdc_db;
Bởi vì chúng ta đang cấu hình EMR Hive catalog để sử dụng AWS Glue Data Catalog, tất cả các cơ sở dữ liệu và bảng được tạo trong Flink Hive catalog sẽ được lưu trữ trong Data Catalog.
- Tạo bảng Flink CDC bằng cách cung cấp tên máy chủ, tên người dùng và mật khẩu cho trường hợp RDS cho MySQL đã tạo trước đó.
Lưu ý rằng vì tên người dùng và mật khẩu RDS cho MySQL sẽ được lưu trữ trong Data Catalog như các thuộc tính bảng, bạn nên bật ủy quyền cơ sở dữ liệu / bảng AWS Glue với AWS Lake Formation để bảo vệ dữ liệu nhạy cảm của mình.
CREATE TABLE `glue_catalog`.`flink_cdc_db`.`customer_cdc` (
`CUST_ID` double NOT NULL,
`NAME` STRING NOT NULL,
`MKTSEGMENT` STRING NOT NULL,
PRIMARY KEY (`CUST_ID`) NOT ENFORCED
) WITH (
‘connector’ = ‘mysql-cdc’,
‘hostname’ = ‘<hostname>’,
‘port’ = ‘3306’,
‘username’ = ‘<username>’,
‘password’ = ‘<password>’,
‘database-name’ = ‘salesdb’,
‘table-name’ = ‘CUSTOMER’
);
CREATE TABLE `glue_catalog`.`flink_cdc_db`.`customer_site_cdc` (
`SITE_ID` double NOT NULL,
`CUST_ID` double NOT NULL,
`ADDRESS` STRING NOT NULL,
`CITY` STRING NOT NULL,
`STATE` STRING NOT NULL,
`COUNTRY` STRING NOT NULL,
`PHONE` STRING NOT NULL,
PRIMARY KEY (`SITE_ID`) NOT ENFORCED
) WITH (
‘connector’ = ‘mysql-cdc’,
‘hostname’ = ‘<hostname>’,
‘port’ = ‘3306’,
‘username’ = ‘<username>’,
‘password’ = ‘<password>’,
‘database-name’ = ‘salesdb’,
‘table-name’ = ‘CUSTOMER_SITE’
);
CREATE TABLE `glue_catalog`.`flink_cdc_db`.`sales_order_all_cdc` (
`ORDER_ID` int NOT NULL,
`SITE_ID` double NOT NULL,
`ORDER_DATE` TIMESTAMP NOT NULL,
`SHIP_MODE` STRING NOT NULL
) WITH (
‘connector’ = ‘mysql-cdc’,
‘hostname’ = ‘<hostname>’,
‘port’ = ‘3306’,
‘username’ = ‘<username>’,
‘password’ = ‘<password>’,
‘database-name’ = ‘salesdb’,
‘table-name’ = ‘SALES_ORDER_ALL’,
‘scan.incremental.snapshot.enabled’ = ‘FALSE’
);
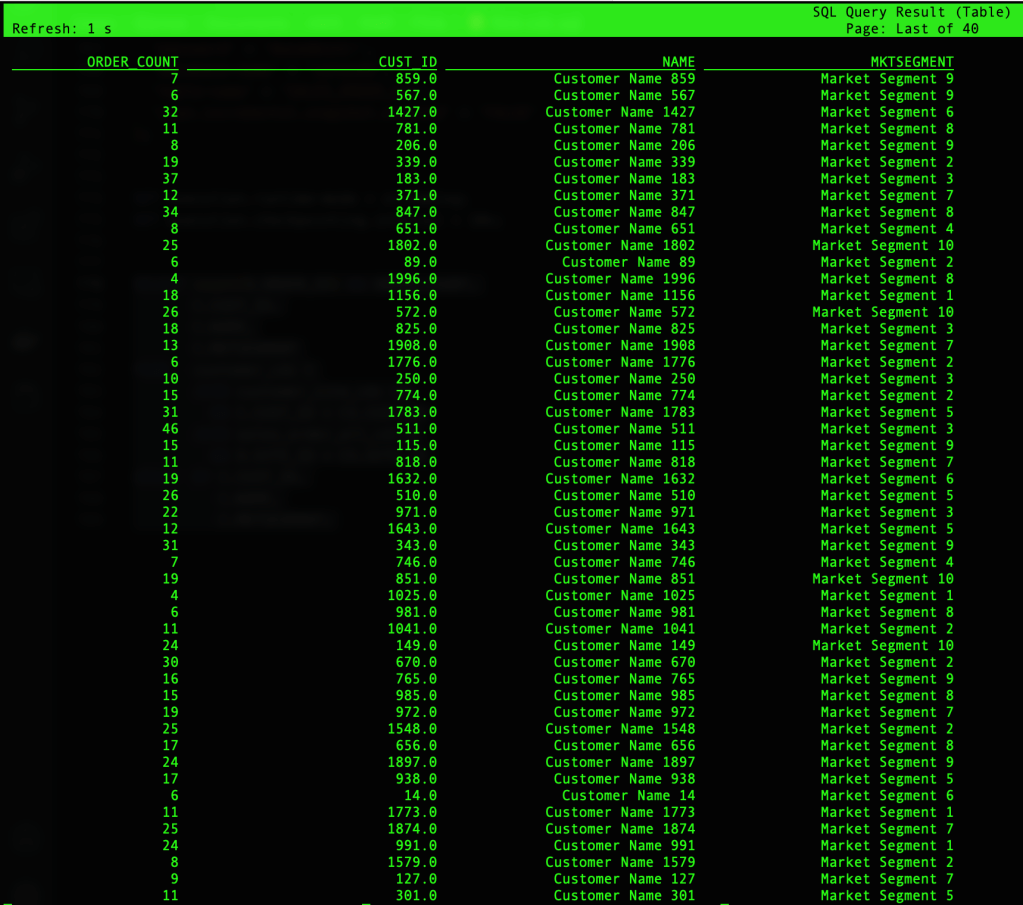
- Đưa ra câu truy vấn cho bảng bạn vừa tạo:
SELECT count(O.ORDER_ID) AS ORDER_COUNT,
C.CUST_ID,
C.NAME,
C.MKTSEGMENT
FROM customer_cdc C
JOIN customer_site_cdc CS
ON C.CUST_ID = CS.CUST_ID
JOIN sales_order_all_cdc O
ON O.SITE_ID = CS.SITE_ID
GROUP BY C.CUST_ID,
C.NAME,
C.MKTSEGMENT;
Bạn sẽ nhận được kết quả truy vấn như ảnh sau.
Lưu trữ dữ liệu đã xử lý trên Amazon S3 với siêu dữ liệu trong Data Catalog
Bởi vì chúng ta đang tiếp nhận dữ liệu cơ sở dữ liệu quan hệ trong Amazon RDS cho MySQL, dữ liệu gốc có thể được cập nhật hoặc xóa bỏ. Để hỗ trợ cập nhật và xóa dữ liệu, chúng ta có thể chọn các công nghệ hồ sơ dữ liệu như Apache Iceberg hoặc Apache Hudi để lưu trữ dữ liệu đã xử lý. Như chúng tôi đã đề cập trước đó, Iceberg và Hudi có quản lý hồ sơ dữ liệu khác nhau. Chúng tôi sẽ hiển thị cả hai kịch bản để sử dụng Flink để đọc / ghi bảng Iceberg và Hudi với siêu dữ liệu trong AWS Glue Data Catalog.
Đối với những trường hợp không sử dụng Iceberg hoặc Hudi, chúng ta sử dụng một tệp FileSystem Parquet để chỉ ra cách connector tích hợp sẵn của Flink sử dụng Data Catalog.
Đọc/Viết vào bảng Iceberg trong Flink với metadata trong Glue Data Catalog
Sơ đồ sau đây cho thấy kiến trúc cho cấu hình này.
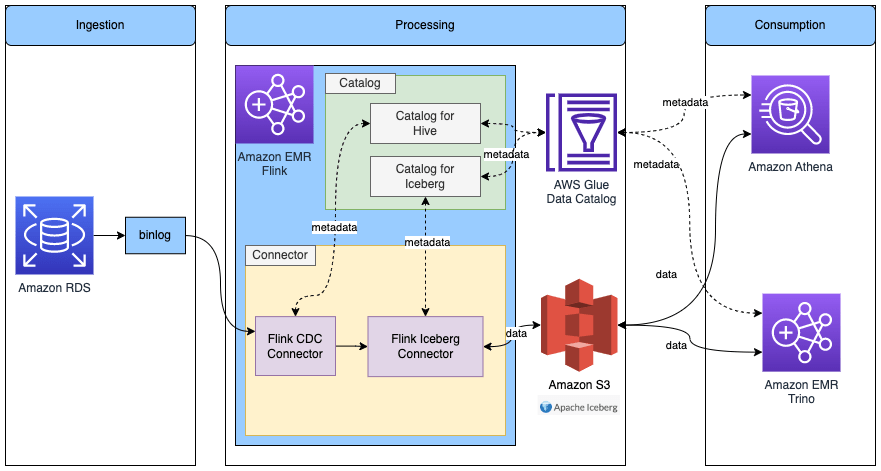
- Tạo một Flink Iceberg catalog sử dụng Data Catalog bằng cách chỉ định catalog-impl là org.apache.iceberg.aws.glue.GlueCatalog.
Để biết thêm thông tin về tích hợp Flink và Data Catalog cho Iceberg, hãy tham khảo Glue Catalog.
- Trong Flink SQL client CLI, chạy lệnh sau và cung cấp tên bucket S3 của bạn:
CREATE CATALOG glue_catalog_for_iceberg WITH (
‘type’=’iceberg’,
‘warehouse’=’s3://<flink-glue-integration-bucket>/flink-glue-for-iceberg/warehouse/’,
‘catalog-impl’=’org.apache.iceberg.aws.glue.GlueCatalog’,
‘io-impl’=’org.apache.iceberg.aws.s3.S3FileIO’,
‘lock-impl’=’org.apache.iceberg.aws.glue.DynamoLockManager’,
‘lock.table’=’FlinkGlue4IcebergLockTable’ );
- Tạo bảng Iceberg để lưu trữ dữ liệu đã xử lý:
USE CATALOG glue_catalog_for_iceberg;
CREATE DATABASE IF NOT EXISTS flink_glue_iceberg_db;
USE flink_glue_iceberg_db;
CREATE TABLE `glue_catalog_for_iceberg`.`flink_glue_iceberg_db`.`customer_summary` (
`CUSTOMER_ID` bigint,
`NAME` STRING,
`MKTSEGMENT` STRING,
`COUNTRY` STRING,
`ORDER_COUNT` BIGINT,
PRIMARY KEY (`CUSTOMER_ID`) NOT Enforced
)
WITH (
‘format-version’=’2’,
‘write.upsert.enabled’=’true’);
- Chèn dữ liệu đã xử lý vào Iceberg:
INSERT INTO `glue_catalog_for_iceberg`.`flink_glue_iceberg_db`.`customer_summary`
SELECT CAST(C.CUST_ID AS BIGINT) CUST_ID,
C.NAME,
C.MKTSEGMENT,
CS.COUNTRY,
count(O.ORDER_ID) AS ORDER_COUNT
FROM `glue_catalog`.`flink_cdc_db`.`customer_cdc` C
JOIN `glue_catalog`.`flink_cdc_db`.`customer_site_cdc` CS
ON C.CUST_ID = CS.CUST_ID
JOIN `glue_catalog`.`flink_cdc_db`.`sales_order_all_cdc` O
ON O.SITE_ID = CS.SITE_ID
GROUP BY C.CUST_ID,
C.NAME,
C.MKTSEGMENT,
CS.COUNTRY;
Đọc / Ghi vào bảng Hudi trong Flink với metadata trong Glue Data Catalog
Sơ đồ sau cho thấy kiến trúc cho cấu hình này.
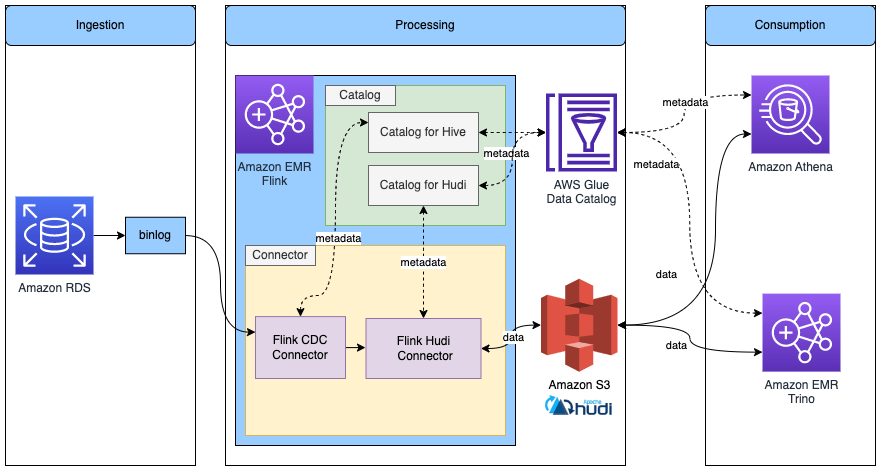
Hoàn thành các bước sau:
- Tạo một catalog cho Hudi sử dụng catalog Hive bằng cách chỉ định mode là hms.
Bởi vì chúng ta đã cấu hình Amazon EMR để sử dụng Data Catalog khi tạo cụm EMR, nên Hudi Hive catalog này sử dụng Data Catalog bên dưới. Để biết thêm thông tin về tích hợp Flink và Data Catalog cho Hudi, hãy tham khảo Create Catalog.
- Trong Flink SQL client CLI, chạy lệnh sau đây và cung cấp tên bucket S3 của bạn:
CREATE CATALOG glue_catalog_for_hudi WITH (
‘type’ = ‘hudi’,
‘mode’ = ‘hms’,
‘table.external’ = ‘true’,
‘default-database’ = ‘default’,
‘hive.conf.dir’ = ‘/etc/hive/conf.dist’,
‘catalog.path’ = ‘s3://<flink-glue-integration-bucket>/flink-glue-for-hudi/warehouse/’
);
- Tạo một bảng Hudi sử dụng Data Catalog và cung cấp tên bucket S3 của bạn:
USE CATALOG glue_catalog_for_hudi;
CREATE DATABASE IF NOT EXISTS flink_glue_hudi_db;
use flink_glue_hudi_db;
CREATE TABLE `glue_catalog_for_hudi`.`flink_glue_hudi_db`.`customer_summary` (
`CUSTOMER_ID` bigint,
`NAME` STRING,
`MKTSEGMENT` STRING,
`COUNTRY` STRING,
`ORDER_COUNT` BIGINT,
PRIMARY KEY (`CUSTOMER_ID`) NOT Enforced
)
WITH (
‘connector’ = ‘hudi’,
‘write.tasks’ = ‘4’,
‘path’ = ‘s3://<flink-glue-integration-bucket>/flink-glue-for-hudi/warehouse/customer_summary’,
‘table.type’ = ‘COPY_ON_WRITE’,
‘read.streaming.enabled’ = ‘true’,
‘read.streaming.check-interval’ = ‘1’
);
- Chèn dữ liệu được xử lý vào Hudi:
INSERT INTO `glue_catalog_for_hudi`.`flink_glue_hudi_db`.`customer_summary`
SELECT CAST(C.CUST_ID AS BIGINT) CUST_ID,
C.NAME,
C.MKTSEGMENT,
CS.COUNTRY,
count(O.ORDER_ID) AS ORDER_COUNT
FROM `glue_catalog`.`flink_cdc_db`.`customer_cdc` C
JOIN `glue_catalog`.`flink_cdc_db`.`customer_site_cdc` CS
ON C.CUST_ID = CS.CUST_ID
JOIN `glue_catalog`.`flink_cdc_db`.`sales_order_all_cdc` O
ON O.SITE_ID = CS.SITE_ID
GROUP BY C.CUST_ID,
C.NAME,
C.MKTSEGMENT,
CS.COUNTRY;
Đọc/Ghi vào các bảng lưu trữ định dạng khác trong Flink với metadata trong Glue Data Catalog
Sơ đồ sau cho thấy kiến trúc cho cấu hình này.
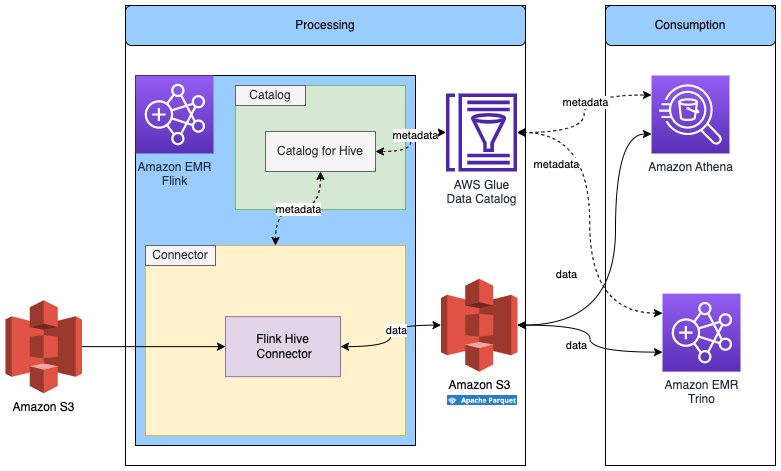
Chúng ta đã tạo Flink Hive catalog trong bước trước đó, vì vậy chúng ta sẽ tái sử dụng catalog đó.
- Trong CLI Flink SQL client, chạy lệnh sau:
USE CATALOG glue_catalog;
CREATE DATABASE IF NOT EXISTS flink_hive_parquet_db;
use flink_hive_parquet_db;
Chúng ta thay đổi ngôn ngữ SQL sang Hive để tạo bảng với cú pháp Hive.
- Tạo một bảng với SQL sau và cung cấp tên bucket S3 của bạn:
SET table.sql-dialect=hive;
CREATE TABLE `customer_summary` (
`CUSTOMER_ID` bigint,
`NAME` STRING,
`MKTSEGMENT` STRING,
`COUNTRY` STRING,
`ORDER_COUNT` BIGINT
)
STORED AS parquet
LOCATION ‘s3://<flink-glue-integration-bucket>/flink-glue-for-hive-parquet/warehouse/customer_summary’;
Bởi vì tệp Parquet không hỗ trợ các hàng cập nhật, chúng ta không thể tiêu thụ dữ liệu từ dữ liệu CDC. Tuy nhiên, chúng ta có thể tiêu thụ dữ liệu từ Iceberg hoặc Hudi.
- Sử dụng mã sau để truy vấn bảng Iceberg và chèn dữ liệu vào bảng Parquet:
SET table.sql-dialect=default;
SET execution.runtime-mode = batch;
INSERT INTO `glue_catalog`.`flink_hive_parquet_db`.`customer_summary`
SELECT * from `glue_catalog_for_iceberg`.`flink_glue_iceberg_db`.`customer_summary`;
Xác nhận tất cả các siêu dữ liệu bảng được lưu trữ trong Data Catalog
Bạn có thể truy cập vào bảng điều khiển AWS Glue để xác nhận tất cả các bảng được lưu trữ trong Data Catalog.
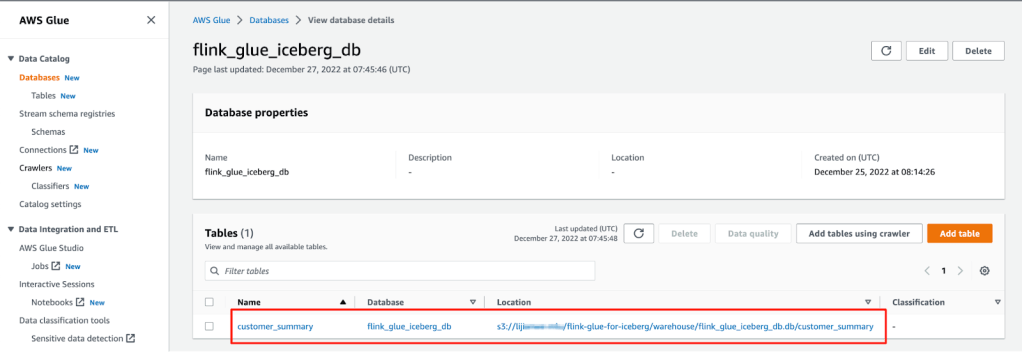
- Trên bảng điều khiển AWS Glue, chọn Databases trong bảng điều hướng để liệt kê tất cả các cơ sở dữ liệu mà chúng ta đã tạo.
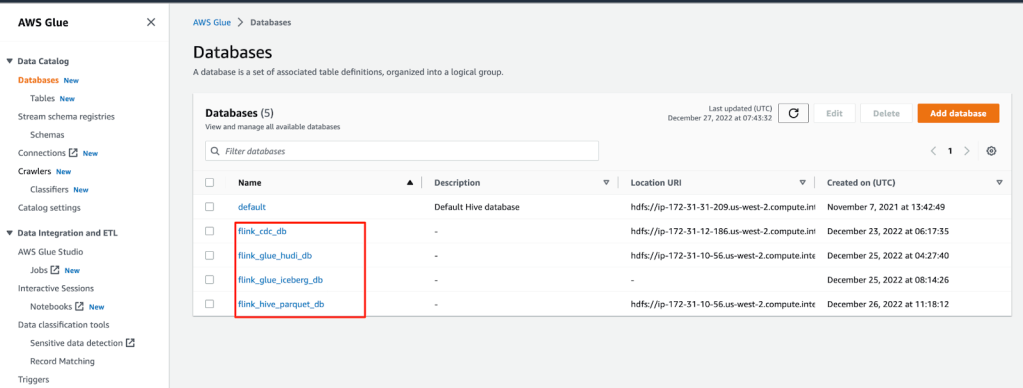
- Mở một cơ sở dữ liệu và xác nhận rằng tất cả các bảng đều nằm trong cơ sở dữ liệu đó.
Tiêu thụ dữ liệu bằng Athena hoặc Amazon EMR Trino cho phân tích kinh doanh
Bạn có thể sử dụng Athena hoặc Amazon EMR Trino để truy cập dữ liệu kết quả.
Truy vấn dữ liệu với Athena
Để truy cập dữ liệu với Athena, thực hiện các bước sau:
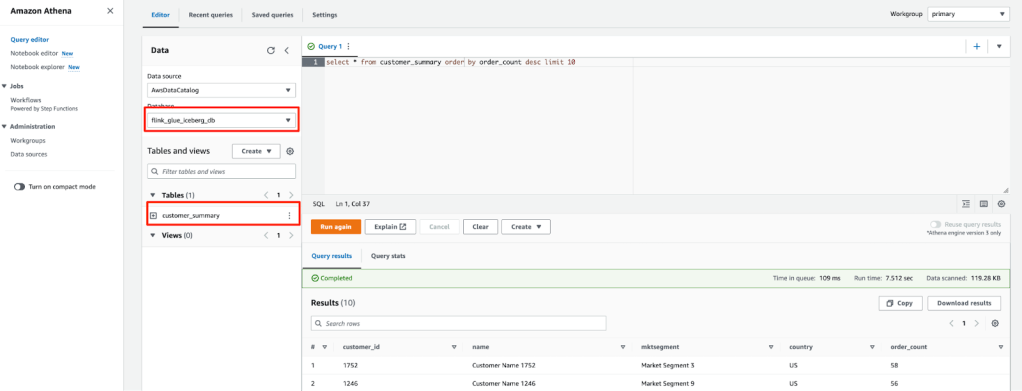
- Mở trình soạn thảo truy vấn Athena.
- Chọn flink_glue_iceberg_db cho Database.
Bạn sẽ thấy bảng customer_summary được liệt kê.
- Chạy script SQL sau để truy vấn bảng kết quả Iceberg:
select * from customer_summary order by order_count desc limit 10
Kết quả truy vấn sẽ giống như ảnh chụp màn hình bên dưới.
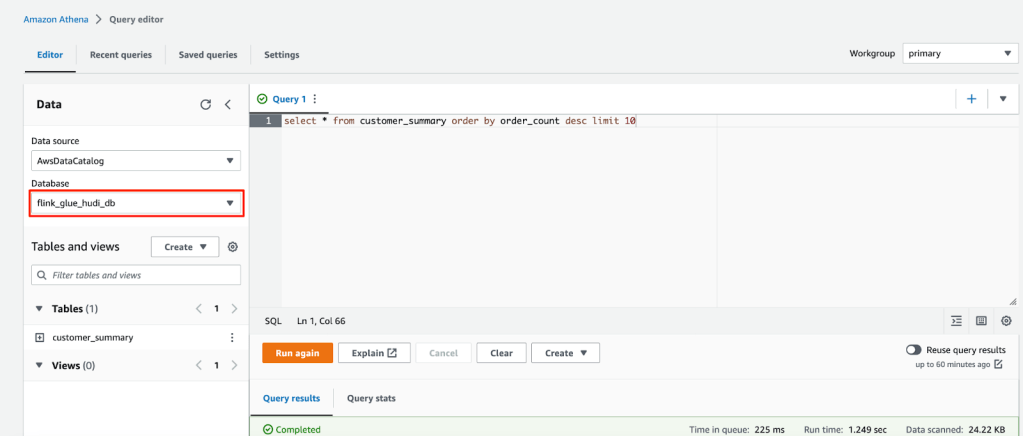
- Đối với bảng Hudi, thay đổi Database thành flink_glue_hudi_db và chạy cùng truy vấn SQL.
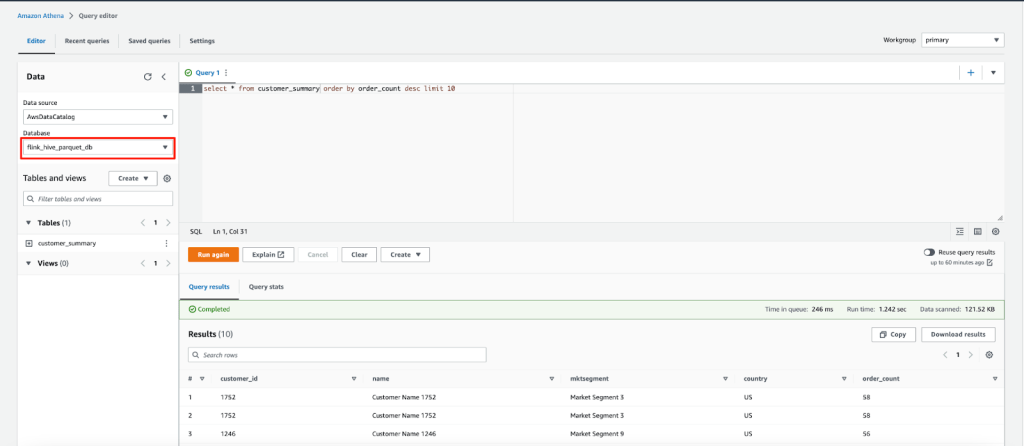
- Đối với bảng Parquet, thay đổi Database thành flink_hive_parquet_db và chạy cùng truy vấn SQL.
Truy vấn dữ liệu bằng Amazon EMR Trino
Để truy cập vào Iceberg bằng Amazon EMR Trino, SSH vào EMR primary node.
- Chạy lệnh sau để bắt đầu Trino CLI:
trino-cli –catalog iceberg
Amazon EMR Trino hiện có thể truy vấn các bảng trong AWS Glue Data Catalog.
- Chạy lệnh sau để truy vấn bảng kết quả:
show schemas;
use flink_glue_iceberg_db;
show tables;
select * from customer_summary order by order_count desc limit 10;
Kết quả truy vấn sẽ trông giống như hình ảnh sau đây.
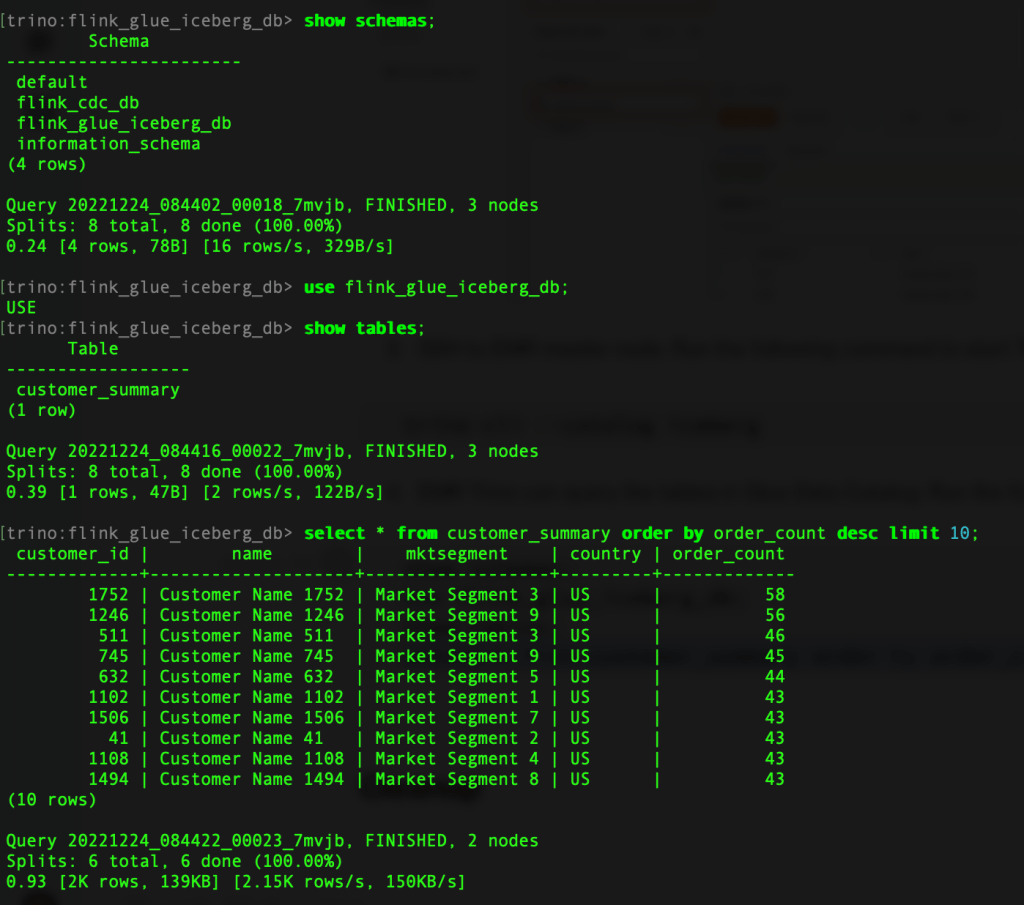
- Thoát khỏi Trino CLI.
- Bắt đầu Trino CLI với hệ thống hive để truy vấn bảng Hudi:
trino-cli –catalog hive
- Chạy lệnh sau để truy vấn bảng Hudi:
show schemas;
use flink_glue_hudi_db;
show tables;
select * from customer_summary order by order_count desc limit 10;
Cập nhật và xóa bản ghi nguồn trong Amazon RDS cho MySQL và xác minh sự phản ánh của các bảng hồ sơ dữ liệu
Chúng ta có thể cập nhật và xóa một số bản ghi trong cơ sở dữ liệu RDS cho MySQL sau đó xác minh rằng các thay đổi được phản ánh trong các bảng Iceberg và Hudi.
- Kết nối với cơ sở dữ liệu RDS cho MySQL và chạy các câu lệnh SQL sau:
update CUSTOMER set NAME = ‘updated_name’ where CUST_ID=7;
delete from CUSTOMER where CUST_ID=11;
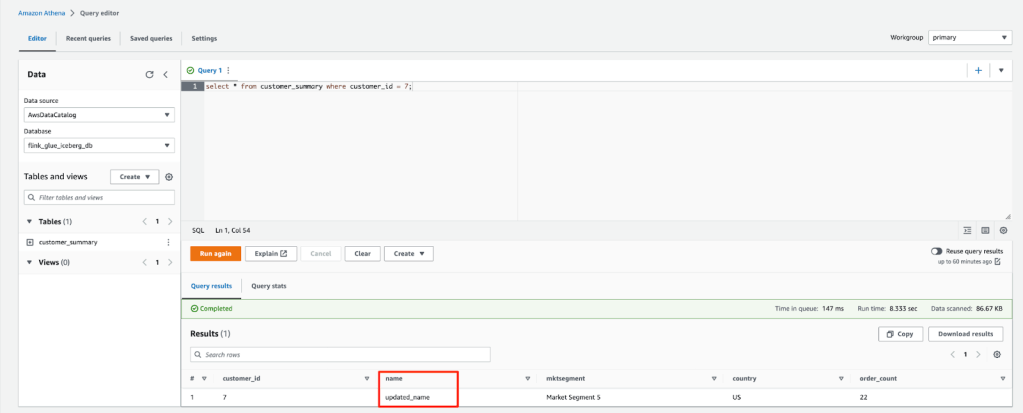
- Truy vấn bảng customer_summary với Athena hoặc Amazon EMR Trino.
Các bản ghi đã được cập nhật và xóa được phản ánh trong các bảng Iceberg và Hudi.
Dọn dẹp
Khi bạn hoàn tất bài tập này, hãy thực hiện các bước sau để xóa tài nguyên của bạn và ngừng chị phí:
- Xóa cơ sở dữ liệu RDS cho MySQL.
- Xóa cụm EMR.
- Xóa cơ sở dữ liệu và bảng được tạo trong Data Catalog.
- Xóa các tệp trong Amazon S3.
Kết luận
Bài viết này đã chỉ cho bạn cách tích hợp Apache Flink trong Amazon EMR với AWS Glue Data Catalog. Bạn có thể sử dụng bộ kết nối Flink SQL để đọc / ghi dữ liệu trong một kho lưu trữ khác, chẳng hạn như Kafka, CDC, HBase, Amazon S3, Iceberg hoặc Hudi. Bạn cũng có thể lưu trữ siêu dữ liệu trong Data Catalog. Flink table API có cơ chế thực hiện bộ kết nối và bộ sưu tập tương tự. Trong một phiên, chúng ta có thể sử dụng nhiều trường hợp bộ sưu tập trỏ đến các loại khác nhau, chẳng hạn như IcebergCatalog và HiveCatalog, và sử dụng chúng lẫn nhau trong truy vấn của bạn. Bạn cũng có thể viết mã với Flink table API để phát triển cùng một giải pháp tích hợp Flink và Data Catalog.
Trong giải pháp của chúng tôi, chúng tôi tiêu thụ nhật ký nhị phân RDS cho MySQL trực tiếp với Flink CDC. Bạn cũng có thể sử dụng Amazon MSK Connect để tiêu thụ nhật ký nhị phân với MySQL Debezim và lưu trữ dữ liệu trong Amazon Managed Streaming for Apache Kafka (Amazon MSK). Tham khảo Create a low-latency source-to-data lake pipeline using Amazon MSK Connect, Apache Flink, and Apache Hudi để biết thêm thông tin.
Với chức năng xử lý dữ liệu thống nhất phân lô và trực tiếp của Amazon EMR Flink, bạn có thể nhận và xử lý dữ liệu với một công cụ tính toán. Với Apache Iceberg và Hudi tích hợp trong Amazon EMR, bạn có thể xây dựng một hồ dữ liệu có khả năng tiến hóa và có khả năng mở rộng. Với AWS Glue Data Catalog, bạn có thể quản lý tất cả các danh mục dữ liệu doanh nghiệp một cách thống nhất và tiêu thụ dữ liệu dễ dàng.
Hãy làm theo các bước trong bài viết này để xây dựng giải pháp kết hợp xử lý dữ liệu streaming và batch với Amazon EMR Flink và AWS Glue Data Catalog. Nếu bạn có bất kỳ câu hỏi nào, hãy để lại một bình luận.
Bài được dịch từ bài viết trên AWS Blogs, bạn có thể xem bài viết gốc tại đây.
