Các cảnh báo thời gian thực là rất quan trọng để proactive biết khi hệ thống không hoạt động như mong đợi hoặc tự động thực hiện các biện pháp sửa chữa. Các cảnh báo cho phép bạn có thời gian để điều tra và khắc phục vấn đề trước khi nó dẫn đến một tình trạng gián đoạn. Tuy nhiên, hệ thống và các chỉ số mà bạn muốn áp dụng các cảnh báo không phải lúc nào cũng đơn giản. Một cảnh báo dễ dàng để cấu hình khi được áp dụng cho một chỉ số đơn của một nguồn tài nguyên duy nhất như CPU Utilization cho một Amazon EC2 instance. Cũng có thể có các kịch bản khi bạn cần phải có các cảnh báo vượt ra ngoài sự đơn giản này để giám sát nhiều nguồn tài nguyên cùng một lúc mà không cần phải lo lắng về vòng đời của bất kỳ nguồn tài nguyên nào.
Amazon CloudWatch Metrics Insights là một công cụ truy vấn SQL hiệu suất cao mạnh mẽ để truy vấn các chỉ số. Trong bài đăng blog này, chúng tôi sẽ thể hiện cách tạo cảnh báo dựa trên các truy vấn sử dụng tính năng tích hợp cảnh báo mới của Amazon CloudWatch với CloudWatch Metrics Insights, cho phép giám sát nhiều nguồn tài nguyên sử dụng một cảnh báo duy nhất. Nó cung cấp khả năng cảnh báo cho các kịch bản mà trước đây không dễ dàng để cấu hình.
Giới thiệu về CloudWatch Metrics Insights
Với CloudWatch Metrics Insights, bạn có thể dễ dàng truy vấn và phân tích các chỉ số để có được cái nhìn tốt hơn về sức khỏe và hiệu suất của cơ sở hạ tầng và ứng dụng quy mô lớn.
Trong khi Metrics Insights đi kèm với ngôn ngữ SQL tiêu chuẩn, bạn cũng có thể bắt đầu sử dụng Metrics Insights bằng cách sử dụng trình tạo truy vấn trực quan. Trình tạo truy vấn giúp bạn xây dựng truy vấn một cách trực quan mà không cần biết SQL. Bạn có thể chọn các chỉ số, không gian tên và chiều dữ liệu một cách trực quan, và bảng điều khiển sẽ tự động xây dựng các truy vấn SQL dựa trên các lựa chọn.
Để bắt đầu sử dụng Metrics Insights, bạn có thể làm theo tài liệu Truy vấn chỉ số của bạn với Metrics Insights.
Giới thiệu về các cảnh báo CloudWatch
Các cảnh báo Amazon CloudWatch được sử dụng như một cách để cảnh báo hoặc tự động hóa các hành động khắc phục khi các thông số đo lường ứng dụng và cơ sở hạ tầng vượt quá ngưỡng cố định hoặc động. Các cảnh báo CloudWatch giúp bạn cải thiện hiệu quả giám sát cơ sở hạ tầng bằng cách giảm thời gian phát hiện, phân loại và chẩn đoán các vấn đề ảnh hưởng đến hiệu suất khối lượng công việc.
Để bắt đầu sử dụng Cảnh báo CloudWatch, bạn có thể làm theo tài liệu Hướng dẫn sử dụng Cảnh báo Amazon CloudWatch.
Trường hợp sử dụng phổ biến
Các cảnh báo được tạo bằng các truy vấn Metrics Insights cho phép bạn giám sát nhiều tài nguyên cùng một lúc. Truy vấn Metrics Insight tự động bao gồm tài nguyên mới phù hợp với định nghĩa của nó. Ví dụ, bạn có thể giám sát nhiều nhóm tự động điều chỉnh với một cảnh báo duy nhất, mà không cần lo lắng về các trường hợp thêm hoặc xóa các instance trong quá trình điều chỉnh tự động cho bất kỳ nhóm tự động điều chỉnh nào. Điều này loại bỏ việc tạo và quản lý các cảnh báo cho từng chỉ số và từng tài nguyên, giúp tăng hiệu suất giám sát cơ sở hạ tầng bằng cách giảm thời gian phát hiện, chẩn đoán và xử lý sự cố ảnh hưởng đến hiệu suất của các khối lượng công việc.
Bạn có thể tìm thấy một số truy vấn mẫu Metrics Insights và các ví dụ sử dụng cho các cảnh báo Metrics Insights tại đây.
Giải pháp của chúng tôi
Chúng ta sẽ tạo các tài nguyên sau đây:
- 2 Auto Scaling groups
- CloudWatch alarm sử dụng truy vấn Metrics Insights
Khởi chạy các instance EC2
Các thông số đo được từ các metrics sẽ được sử dụng để tạo alarms. Trong bài đăng này, chúng ta sẽ minh họa việc tạo CloudWatch alarm bằng cách sử dụng truy vấn Metrics Insights có thể bao gồm nhiều EC2 instances. Chúng ta sẽ triển khai 2 nhóm Autoscaling ví dụ nhưng trong thực tế nó có thể là hàng trăm nhóm tự động co giãn hoặc các instance riêng lẻ.
Tạo hai nhóm Auto-Scaling bằng cách sử dụng Create an Auto Scaling group using a launch template
Tạo cảnh báo CloudWatch bằng cách sử dụng truy vấn Metrics Insights
Chúng tôi sẽ thực hiện 2 cảnh báo sử dụng truy vấn Metrics Insights. Cảnh báo đầu tiên sẽ kích hoạt khi tỉ lệ sử dụng CPU trung bình trên tất cả các EC2 instance vượt quá 70%, và cảnh báo thứ hai sẽ kích hoạt khi Tỉ lệ sử dụng CPU của bất kỳ instance nào vượt quá 80%
1. Mở CloudWatch trong AWS Console. Chọn All Metrics trong Metrics trong thanh điều hướng bên trái của CloudWatch.
Hình1. Bảng điều khiển CloudWatch
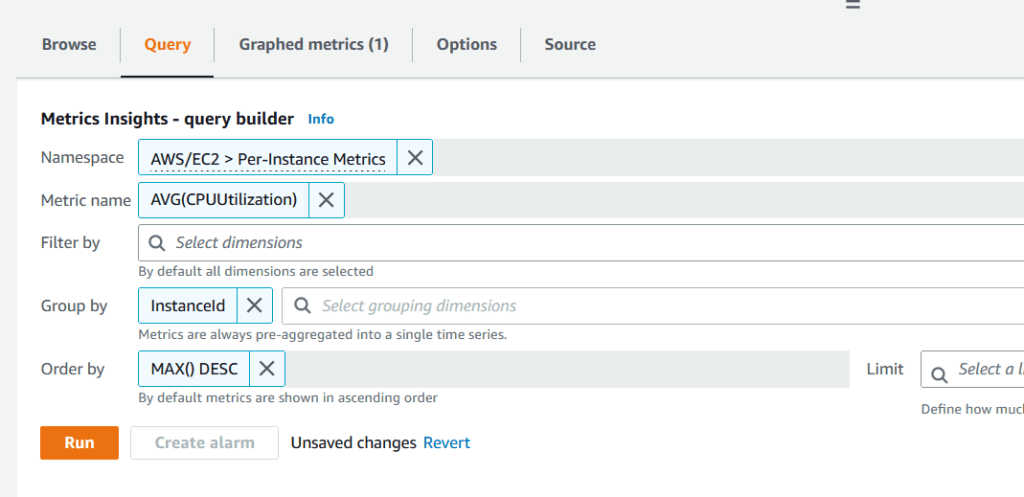
2. Sau khi đã chọn All Metrics, chọn Tab Query để hiển thị trình tạo truy vấn Metrics Insights.

Hình 2. Trình tạo truy vấn Metrics Insights
Hình 2 cho thấy khi bạn chọn namespaces và dimensions một cách trực quan, bảng điều khiển tự động xây dựng truy vấn SQL của bạn dựa trên lựa chọn của bạn. Bạn có thể sử dụng trình soạn thảo truy vấn để nhập các truy vấn SQL của bạn bất cứ lúc nào để đào sâu và chỉ ra các vấn đề với chi tiết càng tinh vi.
3. Đối với alarm thứ nhất, chỉ định Namespace là AWS/EC2 và chọn Per-Instance Metrics. Dưới Metric Name, chọn hàm AVG và chọn CPUUtilization, sau đó nhấn Run.
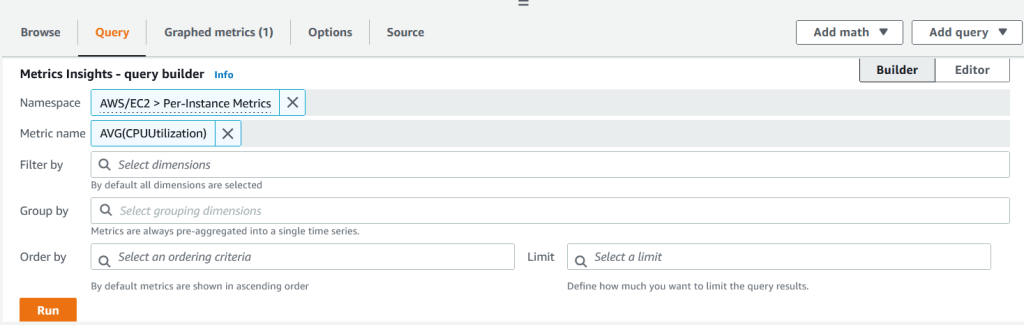
Ngoài AVG, có các hàm khác như SUM, COUNT, MIN và MAX để tóm tắt các metric.
4. Sau khi nhấn Run, bạn nên thấy biểu đồ được vẽ cho trung bình CPU Utilization trên tất cả các EC2 instances. Nhấn vào Graphed metrics.
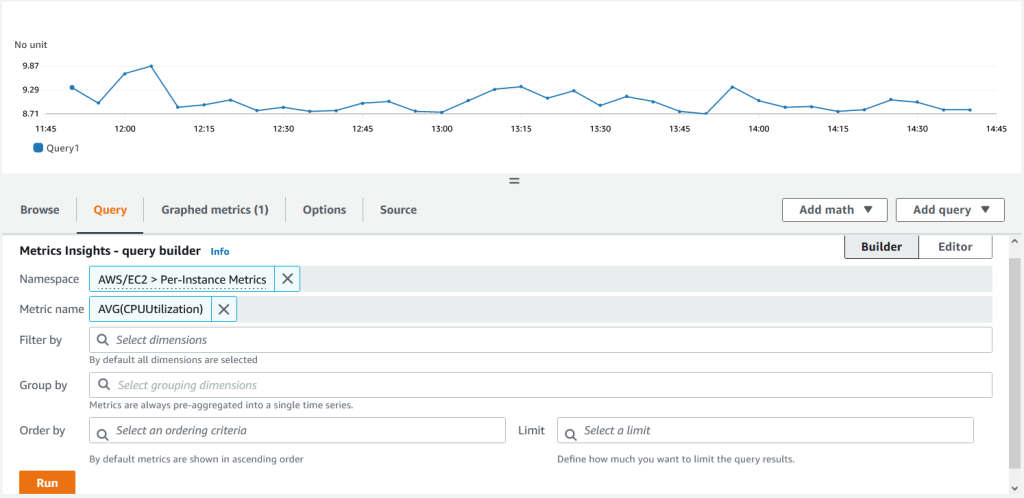
5. Trong Graphed metrics, bạn có thể xem toàn bộ truy vấn SQL bằng cách nhấp vào phần được đánh dấu màu vàng dưới phần chi tiết. Nhấn vào biểu tượng báo động (được đánh dấu màu cam) dưới Actions để tạo alarm.

6. Trên trang Create alarm, bạn có thể cấu hình Period để đánh giá metric và giá trị ngưỡng cho alarm. Khi bạn đặt ngưỡng cho metric, một đường đỏ xuất hiện trên trang đại diện cho giá trị ngưỡng.
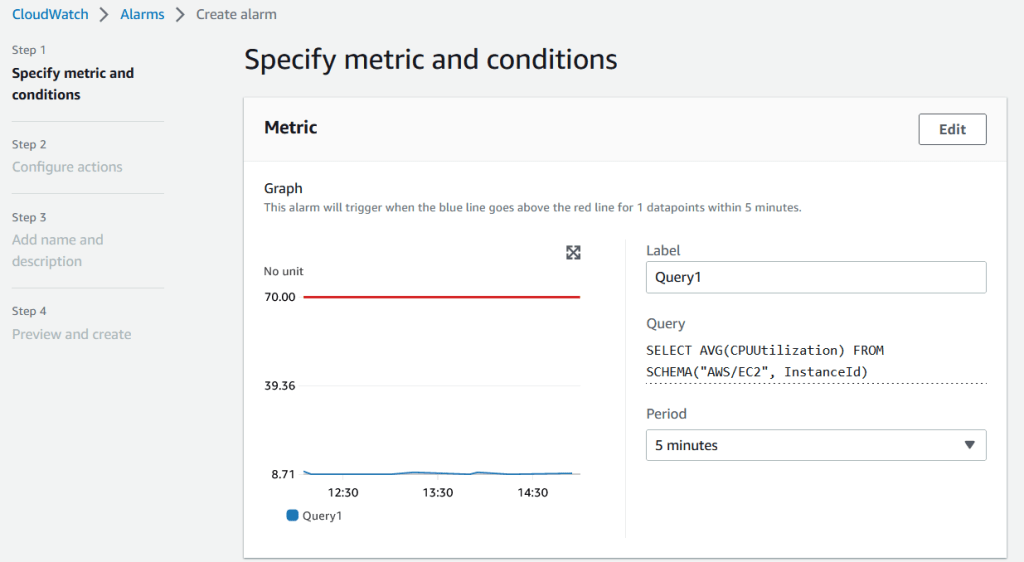
Hình 7. Tạo alarm.
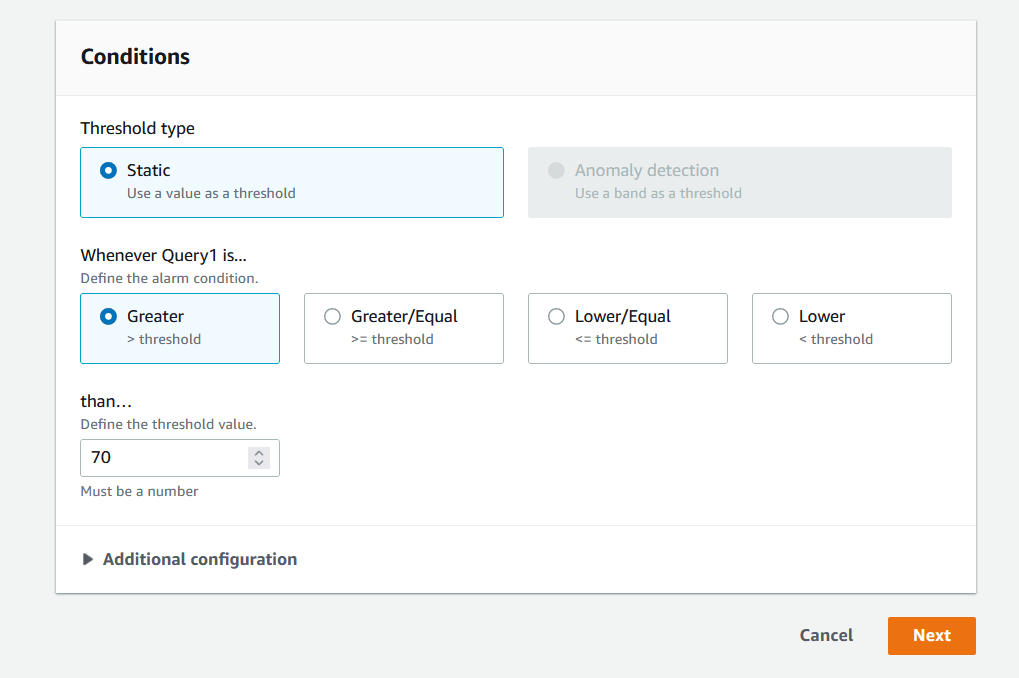
Hình 8.Chỉ định các điều kiện để đưa ra cảnh báo.
Bạn cũng có thể nhấp vào Query để xem truy vấn hoàn chỉnh. Điều này hữu ích khi truy vấn dài và bao phủ nhiều dòng.
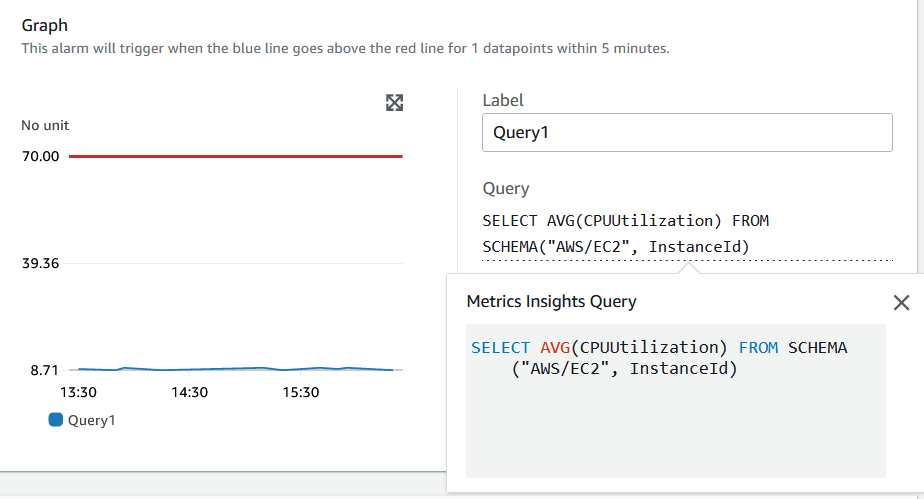
Hình 9. Hoàn thành truy vấn trên trang tạo cảnh báo.
7. Trên trang Configure actions, bạn có thể thêm chủ đề SNS để thông báo và nhấn Next.
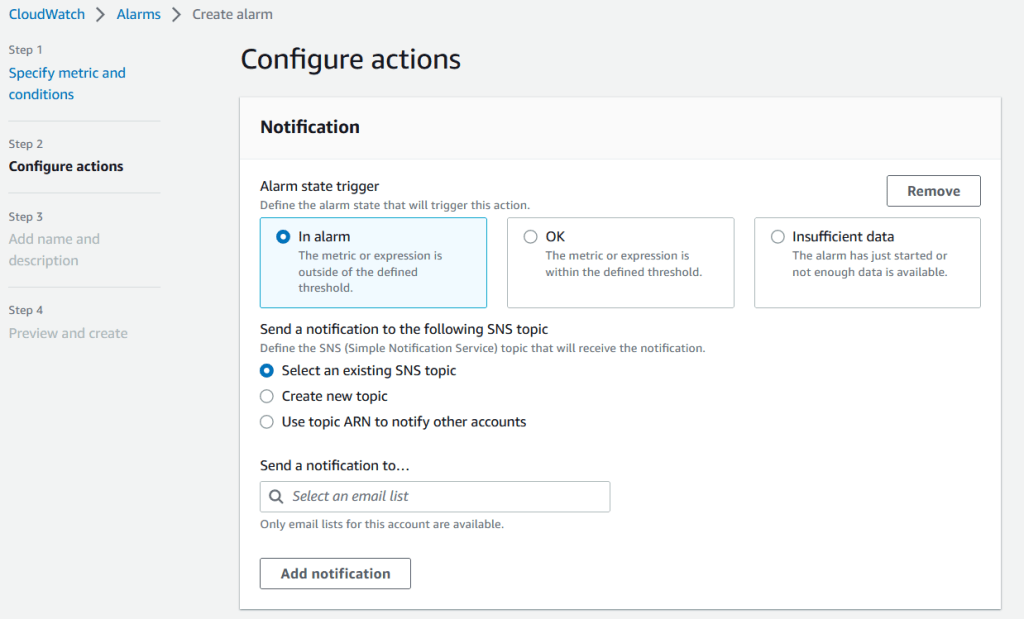
Hình 10. Cấu hình hành động cho cảnh báo.
8. Trên trang tiếp theo, bạn có thể thêm tên có ý nghĩa và mô tả cho alarm.
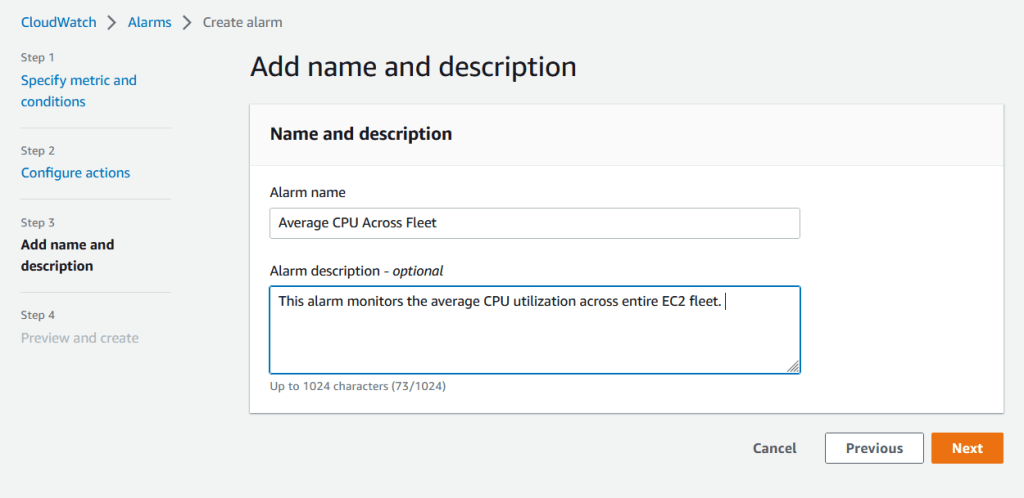
9. Cuối cùng, chọn Next để xem lại các thiết lập cho alarm và nhấn Create alarm để hoàn tất việc tạo alarm.
10. Để tạo ra báo động thứ hai cho “Sử dụng CPU vượt quá 80% cho bất kỳ” , bạn có thể thay đổi truy vấn được sử dụng trong bước 4 bằng cách thêm Group by InstanceId và ORDER by MAX() hàm DESC (Descending). Truy vấn này sẽ trả về dữ liệu chuỗi thời gian cho mỗi instance, được sắp xếp theo thứ tự giảm dần theo sử dụng CPU.
11. Sau khi bạn nhấp vào Run, bạn sẽ nhận thấy rằng nhiều chuỗi thời gian được trả về và một đồ thị riêng được vẽ cho từng instance.

Hình 13. Nhiều chuỗi thời gian.
12. Hiện tại, báo động không được hỗ trợ với nhiều chuỗi thời gian, vì vậy bạn cần sử dụng các hàm toán học định lượng để có được một chuỗi thời gian duy nhất. Nhấp vào tab Graphed metrics. Trong Graphed metrics, nhấp vào Add math (được làm nổi bật bằng màu cam), All functions và chọn hàm FIRST (được làm nổi bật bằng màu vàng). Hàm này sẽ trả về chuỗi thời gian đầu tiên trong tất cả các dữ liệu chuỗi thời gian.
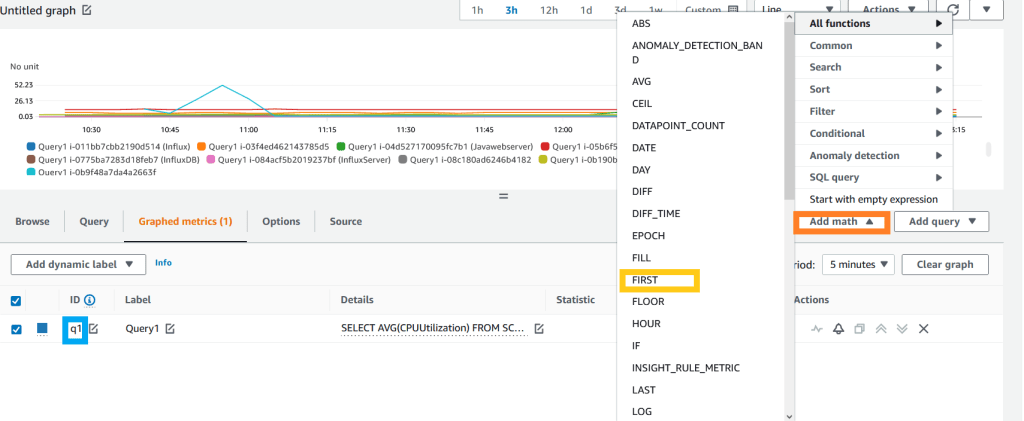
Hình 14. Thêm hàm định lượng số liệu.
Lưu ý nhãn truy vấn số liệu Insight của chúng ta q1 (được làm nổi bật bằng màu xanh lam). Chúng ta sẽ sử dụng hàm FIRST của định lượng số liệu.
13. Cập nhật định nghĩa hàm toán học số liệu và nhấp vào Apply.
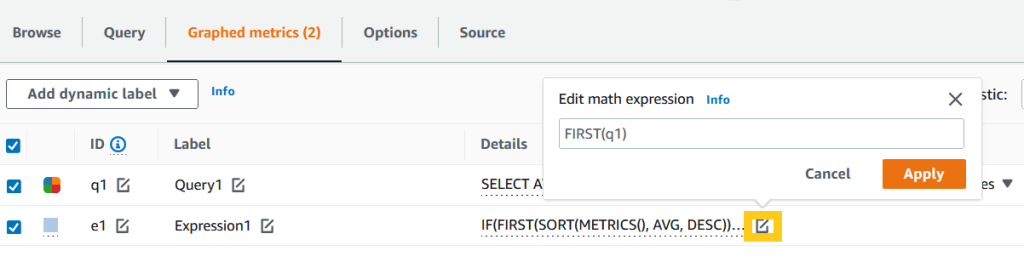
Hình 15. Hàm toán học số liệu để tạo ra chuỗi thời gian duy nhất.
14. Bỏ chọn hộp kiểm cho truy vấn Metrics Insight và nhấp vào biểu tượng báo động bên cạnh hàm Metric math. Điều này sẽ đưa bạn đến trang Tạo cảnh báo, nơi bạn có thể làm theo cùng quy trình như trước để cấu hình ngưỡng báo động, chọn chủ đề SNS và sau đó tạo báo động.

Hình 16. Tạo báo động sử dụng toán học số liệu.
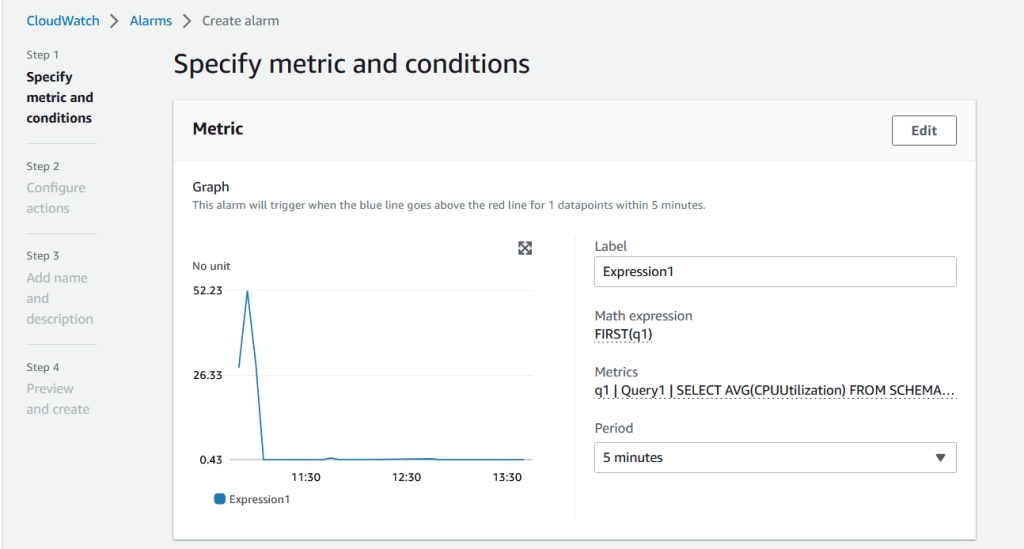
Hình 17. Chỉ định điều kiện cho báo động.
Bây giờ bạn đã tạo được cảnh báo bằng cách sử dụng truy vấn Metrics Insights, nó sẽ tự động bao gồm các chỉ số cho bất kỳ các instances EC2 mới triển khai một cách độc lập hoặc thậm chí là như một phần của một nhóm tự động điều chỉnh.
Bây giờ khi bạn tạo ra tải cho các instances của mình, bạn có thể xem cảnh báo này hoạt động.
Sau khi cảnh báo được kích hoạt
Trong trường hợp sử dụng CPU trung bình trên toàn bộ hệ thống vượt ngưỡng, bạn có thể xem xét xem có bất kỳ instance cụ thể nào gây ra tình trạng này. Bạn có thể sử dụng Metrics Insights để lấy thông tin này.
Trong trường hợp sử dụng CPU của một instance duy nhất vượt quá ngưỡng, bạn có thể sử dụng Metrics Insights để xác định instance Id và tiếp tục khắc phục sự cố. Bước xác định instance Id cũng có thể được tự động hóa bằng cách sử dụng AWS Lambda.
Chi phí
Chi phí tiêu chuẩn của Amazon CloudWatch sẽ được áp dụng cho các cảnh báo được tạo bằng Metrics Insights.
Dọn dẹp
Để tránh các khoản phí trong tài khoản của bạn, hãy xóa các tài nguyên mà bạn đã tạo.
- Xóa cảnh báo CloudWatch: xem tài liệu về Chỉnh sửa hoặc xóa cảnh báo CloudWatch
- Xóa các nhóm Auto-scaling: xem tài liệu để Xóa cơ sở hạ tầng Auto Scaling của bạn
Kết luận
Bài viết này đã thể hiện cách sử dụng truy vấn Metrics Insights để tạo một cảnh báo linh hoạt có thể giám sát nhiều tài nguyên cùng một lúc, mà không cần cấu hình cho từng tài nguyên riêng lẻ.
Bài được dịch từ bài viết trên AWS Blogs, bạn có thể xem bài viết gốc tại đây.
