Tác giả: Renuka Kumar, Toby Fotherby, Shweta Keshavanarayana, Thomas Matthew, Daniel Vaquero, Atul Varshneya và Jessica Wu
Ngày xuất bản: 24 tháng 4 năm 2025
Danh mục: Amazon Bedrock, Artificial Intelligence, Generative AI, Technical How-to
Bài đăng trên blog này được viết chung bởi Renuka Kumar và Thomas Matthew từ Cisco.
Dữ liệu doanh nghiệp về bản chất bao gồm nhiều miền dữ liệu khác nhau, chẳng hạn như bảo mật, tài chính, sản phẩm và nhân sự. Dữ liệu trên các miền này thường được duy trì trên các môi trường dữ liệu khác nhau (chẳng hạn như Amazon Aurora, Oracle và Teradata), với mỗi miền quản lý hàng trăm hoặc có thể là hàng nghìn bảng để biểu diễn và lưu trữ dữ liệu kinh doanh. Các bảng này chứa các lược đồ phức tạp dành riêng cho từng miền, với các trường hợp bảng lồng nhau và dữ liệu đa chiều yêu cầu các truy vấn cơ sở dữ liệu phức tạp và kiến thức dành riêng cho từng miền để truy xuất dữ liệu.
Những tiến bộ gần đây trong AI tạo sinh đã dẫn đến sự phát triển nhanh chóng của công nghệ chuyển đổi ngôn ngữ tự nhiên sang SQL (NL2SQL), sử dụng các mô hình ngôn ngữ lớn được đào tạo trước (LLM) và ngôn ngữ tự nhiên để tạo các truy vấn cơ sở dữ liệu một cách tức thì. Mặc dù công nghệ này hứa hẹn sự đơn giản và dễ sử dụng để truy cập dữ liệu, nhưng việc chuyển đổi các truy vấn ngôn ngữ tự nhiên thành các truy vấn cơ sở dữ liệu phức tạp với độ chính xác và ở quy mô doanh nghiệp vẫn là một thách thức đáng kể. Đối với dữ liệu doanh nghiệp, một khó khăn lớn bắt nguồn từ trường hợp phổ biến là các bảng cơ sở dữ liệu có cấu trúc nhúng yêu cầu kiến thức chuyên sâu hoặc quy trình xử lý tinh vi (ví dụ: chuỗi định dạng XML nhúng). Do đó, các giải pháp NL2SQL cho dữ liệu doanh nghiệp thường không đầy đủ hoặc không chính xác.
Bài đăng này mô tả một mô hình mà các nhóm AWS và Cisco đã phát triển và triển khai, có thể thực hiện được ở quy mô lớn và giải quyết được nhiều trường hợp sử dụng doanh nghiệp đầy thách thức. Phương pháp này cho phép sử dụng generative models đơn giản hơn, do đó tiết kiệm chi phí hơn và độ trễ thấp hơn bằng cách giảm quá trình xử lý cần thiết để tạo SQL.
Những thách thức cụ thể đối với NL2SQL quy mô doanh nghiệp
Độ chính xác trong việc tạo truy vấn là tối quan trọng đối với các trường hợp sử dụng NL2SQL; các truy vấn SQL không chính xác có thể dẫn đến rò rỉ dữ liệu doanh nghiệp nhạy cảm hoặc dẫn đến kết quả không chính xác ảnh hưởng đến các quyết định kinh doanh quan trọng. Dữ liệu quy mô doanh nghiệp đặt ra những thách thức cụ thể cho NL2SQL, bao gồm:
- Các lược đồ phức tạp thường được tối ưu hóa cho việc lưu trữ, chứ không phải cho việc truy xuất – Cơ sở dữ liệu doanh nghiệp về bản chất là hệ thống phân tán và được tối ưu hóa cho việc lưu trữ chứ không phải cho truy xuất. Do đó, các lược đồ bảng rất phức tạp, bao gồm các bảng lồng nhau và các cấu trúc dữ liệu đa chiều (ví dụ: một ô chứa một mảng dữ liệu). Do đó, việc tạo các truy vấn để truy xuất từ các kho dữ liệu này đòi hỏi chuyên môn cụ thể và liên quan đến các phép lọc và nối phức tạp.
- Các truy vấn ngôn ngữ tự nhiên đa dạng và phức tạp – Đầu vào ngôn ngữ tự nhiên của người dùng cũng có thể phức tạp vì chúng có thể tham chiếu đến danh sách các thực thể quan tâm hoặc phạm vi ngày. Việc chuyển đổi ý nghĩa logic của các truy vấn người dùng này thành truy vấn cơ sở dữ liệu có thể dẫn đến các truy vấn SQL quá dài và phức tạp do thiết kế ban đầu của lược đồ dữ liệu.
- Khoảng cách kiến thức LLM – Các mô hình ngôn ngữ NL2SQL thường được đào tạo trên các lược đồ dữ liệu có sẵn công khai cho mục đích giáo dục và có thể không được trang bị kiến thức đủ phức tạp về các cơ sở dữ liệu phân tán lớn trong môi trường sản xuất. Do đó, khi đối mặt với các lược đồ bảng của doanh nghiệp phức tạp hoặc các truy vấn người dùng phức tạp, LLM gặp khó khăn trong việc tạo các câu lệnh truy vấn chính xác vì chúng không thể hiểu rõ mối quan hệ giữa các giá trị và thực thể của lược đồ.
- Gánh nặng chú ý và độ trễ của LLM – Các truy vấn chứa dữ liệu đa chiều thường liên quan đến việc lọc nhiều cấp trên mỗi ô của dữ liệu. Để tạo truy vấn cho các trường hợp như thế này, mô hình sinh dữ liệu cần xử lý nhiều thông tin hơn để có thể xem xét đến số lượng ngày càng tăng của các bảng, cột và giá trị liên quan; phân tích các mẫu; và tạo thêm nhiều mã thông báo. Điều này làm tăng độ trễ tạo truy vấn của LLM và khả năng xảy ra lỗi tạo truy vấn, do LLM hiểu sai mối quan hệ dữ liệu và tạo các câu lệnh lọc không chính xác.
- Thách thức tinh chỉnh – Một cách tiếp cận phổ biến để đạt được độ chính xác cao hơn với việc tạo truy vấn là tinh chỉnh mô hình với nhiều mẫu truy vấn SQL hơn. Tuy nhiên, không dễ để tạo dữ liệu đào tạo để tạo SQL cho các cấu trúc nhúng trong các cột (ví dụ: JSON hoặc XML), để xử lý các tập hợp định danh, v.v., để có được hiệu suất cơ bản (là vấn đề chúng ta đang cố gắng giải quyết ngay từ đầu). Điều này cũng dẫn đến sự chậm lại trong chu kỳ phát triển.
Thiết kế giải pháp và phương pháp luận
Giải pháp được mô tả trong bài đăng này cung cấp một bộ tối ưu hóa giải quyết các thách thức đã đề cập ở trên đồng thời giảm lượng công việc mà LLM phải thực hiện để tạo ra đầu ra chính xác. Bài viết này được phát triển dựa trên nội dung của bài viết “Tạo giá trị từ dữ liệu doanh nghiệp: Các giải pháp hay nhất cho Text2SQL và AI tạo sinh”. Bài đăng đó có nhiều khuyến nghị hữu ích để tạo SQL chất lượng cao và các hướng dẫn được nêu có thể đủ cho nhu cầu của bạn, tùy thuộc vào độ phức tạp vốn có của lược đồ cơ sở dữ liệu.
Để đạt được độ chính xác cao trong các tình huống phức tạp, giải pháp sẽ chia nhỏ quá trình tạo câu lệnh NL2SQL thành một chuỗi các bước tập trung và các vấn đề phụ, thu hẹp phạm vi sinh dữ liệu, tập trung vào miền dữ liệu phù hợp. Bằng cách trừu tượng hóa dữ liệu cho các phép nối phức tạp và cấu trúc dữ liệu, phương pháp này cho phép sử dụng các LLM nhỏ hơn và giá cả phải chăng hơn cho tác vụ. Phương pháp này giúp giảm kích thước và độ phức tạp của lời nhắc để suy luận, giảm độ trễ phản hồi và cải thiện độ chính xác, đồng thời cho phép sử dụng các mô hình được đào tạo sẵn.
Thu hẹp phạm vi vào các miền dữ liệu cụ thể
Quy trình giải pháp thu hẹp không gian lược đồ tổng thể thành miền dữ liệu mà truy vấn của người dùng nhắm đến. Mỗi miền dữ liệu tương ứng với tập hợp các cấu trúc dữ liệu cơ sở dữ liệu (bảng, chế độ xem, v.v.) thường được sử dụng cùng nhau để trả lời một tập hợp các truy vấn người dùng có liên quan, cho một ứng dụng hoặc miền doanh nghiệp. Giải pháp sử dụng miền dữ liệu để xây dựng các câu lệnh đầu vào (prompt) cho LLM.
Mẫu này bao gồm các thành phần sau:
- Ánh xạ truy vấn đầu vào thành miền – Điều này liên quan đến việc ánh xạ từng truy vấn của người dùng thành miền dữ liệu phù hợp để tạo phản hồi cho NL2SQL khi chạy. Ánh xạ này có bản chất tương tự như phân loại ý định và cho phép xây dựng lời nhắc LLM có phạm vi cho từng truy vấn đầu vào (được mô tả tiếp theo).
- Phạm vi miền dữ liệu để xây dựng lời nhắc tập trung – Đây là một phương pháp tiếp cận theo kiểu “chia để trị” (chia nhỏ vấn đề lớn thành các phần nhỏ hơn để giải quyết). Bằng cách tập trung vào miền dữ liệu của truy vấn đầu vào, thông tin dư thừa, chẳng hạn như lược đồ cho các miền dữ liệu khác trong kho dữ liệu doanh nghiệp, có thể được loại trừ. Điều này có thể được coi là một hình thức cắt tỉa lời nhắc; tuy nhiên, nó cung cấp nhiều hơn là chỉ giảm lời nhắc. Giảm ngữ cảnh lời nhắc xuống miền dữ liệu tập trung cho phép phạm vi lớn hơn cho các ví dụ học tập ít lần, khai báo các quy tắc kinh doanh cụ thể, v.v.
- Bổ sung định nghĩa SQL DDL với siêu dữ liệu để tăng cường suy luận LLM – Điều này liên quan đến việc tăng cường ngữ cảnh nhắc nhở LLM bằng cách bổ sung SQL DDL cho miền dữ liệu với các mô tả về bảng, cột và quy tắc để LLM sử dụng làm hướng dẫn về việc tạo ra nó. Điều này được mô tả chi tiết hơn ở phần sau của bài đăng này.
- Xác định biến thể truy vấn và thông tin kết nối – Đối với mỗi miền dữ liệu, siêu dữ liệu máy chủ cơ sở dữ liệu (chẳng hạn như biến thể SQL và URI kết nối) được ghi lại trong quá trình tích hợp trường hợp sử dụng và được cung cấp khi chạy để tự động đưa vào lời nhắc tạo SQL và thực hiện truy vấn tiếp theo. Điều này cho phép khả năng mở rộng thông qua việc tách truy vấn ngôn ngữ tự nhiên khỏi nguồn dữ liệu được truy vấn cụ thể. Cùng nhau, biến thể SQL và cơ chế trừu tượng hóa thông tin kết nối cho phép giải pháp không phụ thuộc vào nguồn dữ liệu; các nguồn dữ liệu có thể được phân phối trong hoặc trên các đám mây khác nhau hoặc được cung cấp bởi các nhà cung cấp khác nhau. Tính mô-đun này cho phép bổ sung các nguồn dữ liệu và miền dữ liệu mới có thể mở rộng, vì mỗi nguồn dữ liệu và miền dữ liệu đều độc lập.
Quản lý các định danh để tạo SQL (IDs tài nguyên)
Việc phân giải định danh liên quan đến việc trích xuất các tài nguyên được đặt tên, dưới dạng các thực thể được đặt tên, từ truy vấn của người dùng và ánh xạ các giá trị thành các ID duy nhất phù hợp với nguồn dữ liệu mục tiêu trước khi tạo NL2SQL. Điều này có thể được triển khai bằng cách sử dụng xử lý ngôn ngữ tự nhiên (NLP) hoặc LLM để áp dụng các khả năng nhận dạng thực thể được đặt tên (NER) để thúc đẩy quá trình giải quyết. Bước tùy chọn này có giá trị nhất khi có nhiều tài nguyên được đặt tên và quá trình tra cứu phức tạp. Ví dụ: trong truy vấn của người dùng như “Isabelle Werth, Nedo Nadi và Allyson Felix đã thi đấu trong trò chơi nào?” có các tài nguyên được đặt tên: ‘allyson felix’, ‘isabelle werth’ và ‘nedo nadi’. Bước này cho phép phản hồi nhanh chóng và chính xác cho người dùng khi không thể giải quyết một tài nguyên thành một định danh (ví dụ: do mơ hồ).
Quy trình tùy chọn này để xử lý nhiều hoặc nhiều định danh được ghép nối được đưa vào để giảm gánh nặng cho LLM đối với các truy vấn của người dùng với các tập hợp định danh đầy thách thức cần được kết hợp, chẳng hạn như các định danh có thể đi theo cặp (như kiểu ID, giá trị ID) hoặc khi có nhiều định danh. Thay vì để LLM chèn trực tiếp từng ID duy nhất vào câu lệnh SQL, các định danh được cung cấp bằng cách xác định một cấu trúc dữ liệu tạm thời (như bảng tạm thời) và một tập hợp các câu lệnh chèn tương ứng. LLM được nhắc nhở bằng các ví dụ học tập ít lần để tạo SQL cho truy vấn của người dùng bằng cách kết hợp với cấu trúc dữ liệu tạm thời, thay vì cố gắng chèn các định danh. Điều này tạo ra một mẫu truy vấn đơn giản hơn và nhất quán hơn cho các trường hợp có một, nhiều hoặc nhiều cặp định danh.
Xử lý các cấu trúc dữ liệu phức tạp: Trừu tượng hóa các cấu trúc dữ liệu miền
Bước này nhằm mục đích đơn giản hóa các cấu trúc dữ liệu phức tạp thành một dạng mà mô hình ngôn ngữ có thể hiểu được mà không cần phải phân tích các mối quan hệ phức tạp giữa các dữ liệu. Ví dụ, các cấu trúc dữ liệu phức tạp có thể xuất hiện dưới dạng các bảng hoặc danh sách lồng nhau trong một cột bảng.
Chúng ta có thể định nghĩa các cấu trúc dữ liệu tạm thời (như dạng xem và bảng) trừu tượng hóa các phép nối nhiều bảng phức tạp, các cấu trúc lồng nhau, v.v. Các phép trừu tượng cấp cao hơn này cung cấp các cấu trúc dữ liệu được đơn giản hóa để tạo và thực thi truy vấn. Các định nghĩa cấp cao nhất của các phép trừu tượng này được bao gồm như một phần của ngữ cảnh nhắc nhở để tạo truy vấn và các định nghĩa đầy đủ được cung cấp cho công cụ thực thi SQL, cùng với truy vấn được tạo. Các truy vấn kết quả từ quy trình này có thể sử dụng các phép toán tập hợp đơn giản (như IN, trái ngược với các phép nối phức tạp) mà LLM được đào tạo tốt, do đó làm giảm nhu cầu về các phép nối lồng nhau và bộ lọc trên các cấu trúc dữ liệu phức tạp.
Tăng cường dữ liệu bằng các định nghĩa dữ liệu để xây dựng nhanh chóng
Một số tối ưu hóa được ghi chú trước đó yêu cầu làm rõ một số thông số cụ thể của miền dữ liệu. May mắn thay, điều này chỉ phải được thực hiện khi các lược đồ và trường hợp sử dụng được đưa vào sử dụng hoặc cập nhật. Lợi ích là độ chính xác tạo ra cao hơn, độ trễ và chi phí tạo ra giảm và khả năng hỗ trợ các yêu cầu truy vấn phức tạp tùy ý.
Để nắm bắt ngữ nghĩa của một miền dữ liệu, các yếu tố sau được xác định:
- Các bảng và dạng xem chuẩn trong lược đồ dữ liệu, cùng với các chú thích để mô tả các bảng và cột.
- Gợi ý JOIN cho các bảng và chế độ xem, chẳng hạn như khi nào nên sử dụng phép nối ngoài.
- Các quy tắc cụ thể cho miền dữ liệu, chẳng hạn như cột nào có thể không xuất hiện trong câu lệnh select cuối cùng.
- Một bộ các ví dụ few-shot learning về truy vấn của người dùng và các câu lệnh SQL tương ứng. Một bộ ví dụ tốt sẽ bao gồm nhiều loại truy vấn của người dùng cho miền đó.
- Định nghĩa lược đồ dữ liệu cho mọi bảng và chế độ xem tạm thời được sử dụng trong giải pháp.
- Lời nhắc hệ thống dành riêng cho từng lĩnh vực nêu rõ vai trò và chuyên môn của LLM, biến thể SQL và phạm vi hoạt động của nó.
- Lời nhắc người dùng theo từng miền cụ thể.
- Ngoài ra, nếu sử dụng bảng tạm thời hoặc chế độ xem cho miền dữ liệu, cần có một tập lệnh SQL, khi thực thi, sẽ tạo ra các cấu trúc dữ liệu tạm thời mong muốn cần được xác định. Tùy thuộc vào trường hợp sử dụng, đây có thể là tập lệnh tĩnh hoặc được tạo động.
Theo đó, lời nhắc để tạo SQL là động và được xây dựng dựa trên miền dữ liệu của câu hỏi đầu vào, với một tập hợp các định nghĩa cụ thể về cấu trúc dữ liệu và các quy tắc phù hợp với truy vấn đầu vào. Chúng tôi gọi tập hợp các phần tử này là ngữ cảnh miền dữ liệu . Mục đích của ngữ cảnh miền dữ liệu là cung cấp siêu dữ liệu lời nhắc cần thiết cho LLM tạo. Các ví dụ về điều này và các phương pháp được mô tả trong các phần trước đều có trong kho lưu trữ GitHub. Có một ngữ cảnh cho mỗi miền dữ liệu, như minh họa trong hình sau.

Tổng hợp tất cả lại: Luồng thực hiện
Phần này mô tả luồng thực thi của giải pháp. Một ví dụ về triển khai mẫu này có sẵn trong kho lưu trữ GitHub. Truy cập kho lưu trữ để theo dõi mã.
Để minh họa luồng thực thi, chúng tôi sử dụng một cơ sở dữ liệu mẫu với dữ liệu về số liệu thống kê Olympic và một cơ sở dữ liệu khác với lịch nghỉ phép của nhân viên công ty. Chúng tôi theo dõi luồng thực thi cho miền liên quan đến số liệu thống kê Olympic bằng cách sử dụng truy vấn người dùng “Isabelle Werth, Nedo Nadi và Allyson Felix đã thi đấu trong những trò chơi nào?” để hiển thị đầu vào và đầu ra của các bước trong luồng thực thi, như minh họa trong hình sau.
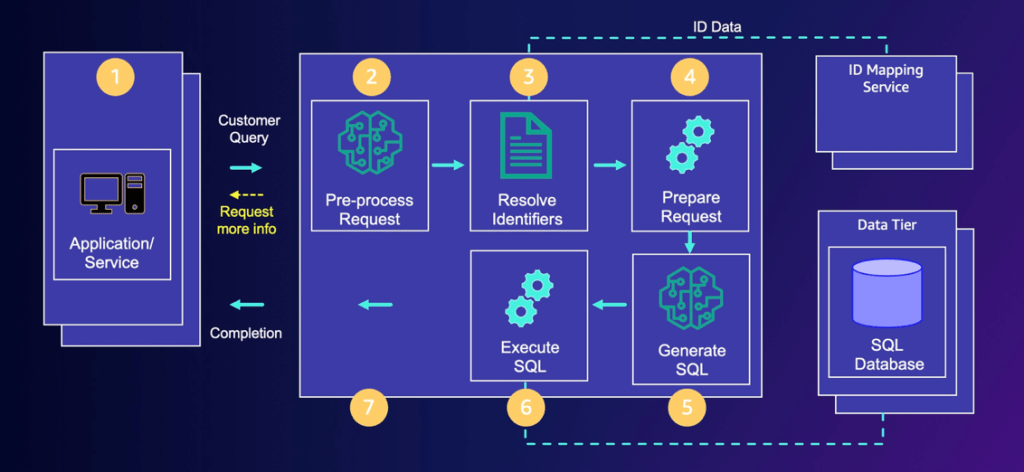
Xử lý trước yêu cầu
Bước đầu tiên của luồng NL2SQL là xử lý trước yêu cầu. Mục tiêu chính của bước này là phân loại truy vấn của người dùng thành một miền. Như đã giải thích trước đó, bước này thu hẹp phạm vi của vấn đề thành miền dữ liệu phù hợp để tạo SQL. Ngoài ra, bước này xác định và trích xuất các tài nguyên được đặt tên được tham chiếu trong truy vấn của người dùng. Sau đó, chúng được sử dụng để gọi dịch vụ nhận dạng trong bước tiếp theo để lấy các mã định danh cơ sở dữ liệu cho các tài nguyên được đặt tên này .
Sử dụng ví dụ đã đề cập trước đó, đầu vào và đầu ra của bước này như sau:
user_query = "In what games did Isabelle Werth, Nedo Nadi and Allyson Felix compete?"
pre_processed_request = request_pre_processor.run(user_query)
domain = pre_processed_request[app_consts.DOMAIN]
# Output pre_processed_request:
{'user_query': 'In what games did Isabelle Werth, Nedo Nadi and Allyson Felix compete?', 'domain': 'olympics',
'named_resources': {'allyson felix', 'isabelle werth', 'nedo nadi'} }Giải quyết các định danh (thành ID cơ sở dữ liệu)
Bước này xử lý các chuỗi tài nguyên được đặt tên được trích xuất ở bước trước và giải quyết chúng thành các mã định danh có thể được sử dụng trong các truy vấn cơ sở dữ liệu. Như đã đề cập trước đó, các tài nguyên được đặt tên (ví dụ: “group22”, “user123” và “I”) được tra cứu bằng các phương tiện cụ thể của giải pháp, chẳng hạn như thông qua tra cứu cơ sở dữ liệu hoặc dịch vụ ID.
Đoạn code sau đây cho thấy quá trình thực hiện bước này trong ví dụ đang chạy của chúng tôi:
named_resources = pre_processed_request[app_consts.NAMED_RESOURCES]
if len(named_resources) > 0:
identifiers = id_service_facade.resolve(named_resources)
# add identifiers to the pre_processed_request object
pre_processed_request[app_consts.IDENTIFIERS] = identifiers
else:
pre_processed_request[app_consts.IDENTIFIERS] = []
# Output pre_processed_request:
{'user_query': 'In what games did Isabelle Werth, Nedo Nadi and Allyson Felix compete?', 'domain': 'olympics',
'named_resources': {'allyson felix', 'isabelle werth', 'nedo nadi'},
'identifiers': [ {'id': 34551, 'role': 32, 'name': 'allyson felix'},
{'id': 129726, 'role': 32, 'name': 'isabelle werth'},
{'id': 84026, 'role': 32, 'name': 'nedo nadi'} ] }Chuẩn bị yêu cầu
Bước này là bước then chốt trong mô hình này. Sau khi có được tên miền và các tài nguyên được đặt tên cùng với ID đã tra cứu của chúng, chúng tôi sử dụng ngữ cảnh tương ứng cho tên miền đó để tạo ra nội dung sau:
- Một lời nhắc cho LLM để tạo truy vấn SQL tương ứng với truy vấn của người dùng
- Một tập lệnh SQL để tạo lược đồ cụ thể cho miền
Để tạo lời nhắc cho LLM, bước này sẽ lắp ráp lời nhắc hệ thống, lời nhắc người dùng và truy vấn người dùng đã nhận từ đầu vào, cùng với định nghĩa lược đồ cụ thể cho miền, bao gồm các bảng tạm thời mới được tạo cũng như bất kỳ gợi ý về phép nối (join hints) nào và cuối cùng là các ví dụ few-shot examples cho miền dữ liệu đó. Ngoài truy vấn người dùng được nhận như trong đầu vào, các thành phần khác dựa trên các giá trị được cung cấp trong ngữ cảnh cho miền đó.
Một tập lệnh SQL để tạo các cấu trúc tạm thời theo miền bắt buộc (như chế độ xem và bảng) được xây dựng từ thông tin trong ngữ cảnh. Sơ đồ theo miền trong dấu nhắc LLM, gợi ý JOIN và một vài ví dụ được căn chỉnh với sơ đồ được tạo ra bằng cách chạy tập lệnh này. Trong ví dụ của chúng tôi, bước này được hiển thị trong đoạn code sau. Đầu ra là một từ điển có hai khóa, llm_prompt và sql_preamble. Các chuỗi giá trị cho những khóa này đã được cắt bớt ở đây; đầu ra đầy đủ có thể được xem trong Jupyter Notebook .
# Output prepared_request:
{'llm_prompt': 'You are a SQL expert. Given the following SQL tables definitions, ...
CREATE TABLE games (id INTEGER PRIMARY KEY, games_year INTEGER, ...);
...
<example>
question: How many gold medals has Yukio Endo won? answer: ```{"sql":
"SELECT a.id, count(m.medal_name) as "count"
FROM athletes_in_focus a INNER JOIN games_competitor gc ...
WHERE m.medal_name = 'Gold' GROUP BY a.id;" }```
</example>
...
'sql_preamble': [ 'CREATE temp TABLE athletes_in_focus (row_id INTEGER
PRIMARY KEY, id INTEGER, full_name TEXT DEFAULT NULL);',
'INSERT INTO athletes_in_focus VALUES
(1,84026,'nedo nadi'), (2,34551,'allyson felix'), (3,129726,'isabelle werth');"]}Tạo SQL
Bây giờ lời nhắc đã được chuẩn bị cùng với mọi thông tin cần thiết để cung cấp ngữ cảnh phù hợp cho LLM, chúng tôi cung cấp thông tin đó cho LLM tạo SQL trong bước này. Mục tiêu là để LLM xuất ra SQL với cấu trúc liên kết, bộ lọc và cột chính xác. Xem code sau:
llm_response = llm_service_facade.invoke(prepared_request[ 'llm_prompt' ])
generated_sql = llm_response[ 'llm_output' ]
# Output generated_sql:
{'sql': 'SELECT g.games_name, g.games_year FROM athletes_in_focus a
JOIN games_competitor gc ON gc.person_id = a.id
JOIN games g ON gc.games_id = g.id;'}Thực hiện SQL
Sau khi truy vấn SQL được LLM tạo ra, chúng ta có thể gửi nó đến bước tiếp theo. Tại bước này, phần mở đầu SQL và SQL được tạo ra được hợp nhất để tạo thành một tập lệnh SQL hoàn chỉnh để thực thi. Sau đó, tập lệnh SQL hoàn chỉnh được thực thi trên kho dữ liệu, phản hồi được truy xuất và sau đó phản hồi được gửi về cho máy khách hoặc người dùng. Xem đoạn code sau:
sql_script = prepared_request[ 'sql_preamble' ] + [ generated_sql[ 'sql' ] ]
database = app_consts.get_database_for_domain(domain)
results = rdbms_service_facade.execute_sql(database, sql_script)
# Output results:
{'rdbms_output': [
('games_name', 'games_year'),
('2004 Summer', 2004),
...
('2016 Summer', 2016)],
'processing_status': 'success'}Lợi ích của giải pháp
Nhìn chung, các thử nghiệm của chúng tôi đã chỉ ra một số lợi ích, chẳng hạn như:
- Độ chính xác cao – Điều này được đo bằng cách khớp chuỗi truy vấn được tạo với truy vấn SQL mục tiêu cho từng trường hợp thử nghiệm. Trong các thử nghiệm của mình, chúng tôi đã quan sát thấy độ chính xác trên 95% cho 100 truy vấn, trải dài trên ba miền dữ liệu.
- Tính nhất quán cao – Tính nhất quán được đo bằng việc mô hình luôn tạo ra cùng một câu lệnh SQL trong nhiều lần chạy khác nhau. Chúng tôi đã quan sát thấy tính nhất quán trên 95% cho 100 truy vấn, trải dài trên ba miền dữ liệu. Với cấu hình thử nghiệm, các truy vấn đều chính xác trong hầu hết thời gian; một số ít thỉnh thoảng tạo ra kết quả không nhất quán.
- Chi phí thấp và độ trễ thấp – Phương pháp này hỗ trợ việc sử dụng các LLM nhỏ. Chúng tôi đã quan sát việc tạo SQL trong khoảng thời gian từ 1–3 giây bằng cách sử dụng các mô hình Meta’s Code Llama 13B và Anthropic’s Claude Haiku 3.
- Khả năng mở rộng – Các phương pháp trừu tượng hóa dữ liệu mà chúng tôi sử dụng đã tạo điều kiện cho việc mở rộng độc lập với số lượng thực thể hoặc mã định danh trong dữ liệu cho một trường hợp sử dụng nhất định. Ví dụ, trong các thử nghiệm của chúng tôi bao gồm danh sách 200 tài nguyên được đặt tên khác nhau trên mỗi hàng của một bảng và hơn 10.000 hàng như vậy, chúng tôi đã đo được phạm vi độ trễ là 2–5 giây để tạo SQL và 3,5–4,0 giây để thực thi SQL.
- Giải quyết sự phức tạp – Sử dụng các phép trừu tượng hóa dữ liệu để đơn giản hóa sự phức tạp cho phép tạo ra chính xác các truy vấn doanh nghiệp phức tạp tùy ý, điều mà chắc chắn sẽ không thể thực hiện được nếu không có chúng.
Chúng tôi cho rằng thành công của giải pháp với các mô hình tuyệt vời nhưng nhẹ này (so với biến thể Meta Llama 70B hoặc Claude Sonnet của Anthropic) là do các điểm đã nêu trước đó, với độ phức tạp của tác vụ LLM được giảm là động lực thúc đẩy. Mã triển khai chứng minh cách thực hiện điều này. Nhìn chung, bằng cách sử dụng các tối ưu hóa được nêu trong bài đăng này, việc tạo SQL ngôn ngữ tự nhiên cho dữ liệu doanh nghiệp khả thi hơn nhiều so với cách khác.
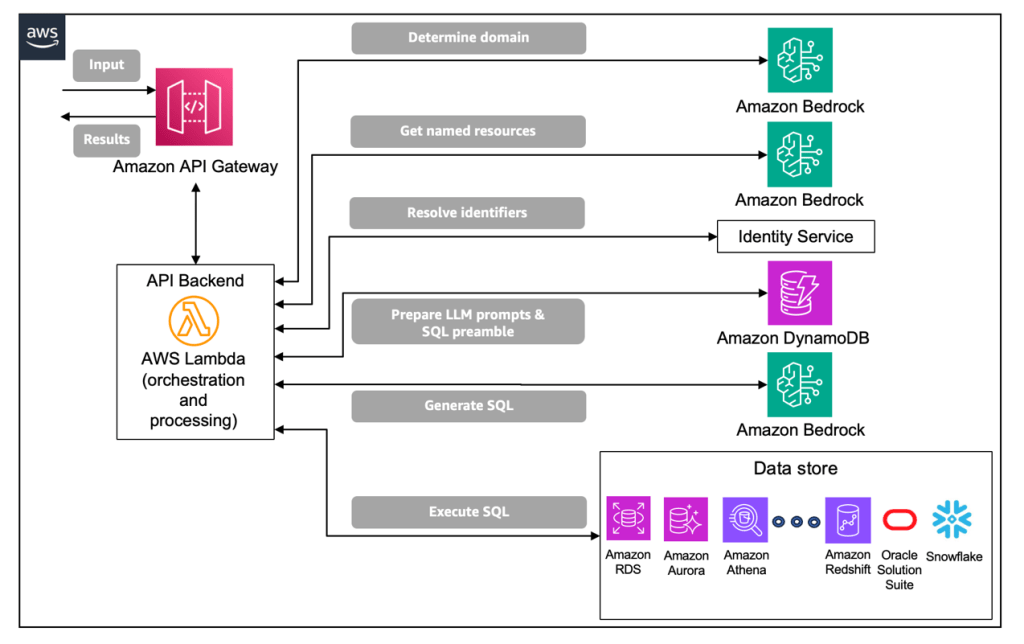
Kiến trúc giải pháp AWS
Trong phần này, chúng tôi minh họa cách bạn có thể triển khai kiến trúc trên AWS. Người dùng cuối gửi các truy vấn ngôn ngữ tự nhiên của họ đến giải pháp NL2SQL bằng cách sử dụng REST API. Amazon API Gateway được sử dụng để cung cấp REST API, có thể được bảo mật bởi Amazon Cognito. API được liên kết với hàm AWS Lambda, hàm này triển khai và sắp xếp các bước xử lý được mô tả trước đó bằng ngôn ngữ lập trình do người dùng lựa chọn (chẳng hạn như Python) theo cách không cần máy chủ. Trong ví dụ triển khai này, vốn sử dụng Amazon Bedrock, giải pháp đã dùng mô hình Claude Haiku 3 của Anthropic.
Tóm lại, các bước xử lý như sau:
- Xác định miền bằng cách sử dụng LLM trên Amazon Bedrock để phân loại.
- Gọi Amazon Bedrock để trích xuất các tài nguyên có tên liên quan từ yêu cầu.
- Sau khi các tài nguyên được đặt tên được xác định, bước này gọi một dịch vụ (Dịch vụ nhận dạng) trả về các thông số nhận dạng cụ thể có liên quan đến các tài nguyên được đặt tên cho tác vụ đang thực hiện. Dịch vụ nhận dạng về mặt logic là một dịch vụ tra cứu khóa/giá trị, có thể hỗ trợ nhiều miền.
- Bước này chạy trên Lambda để tạo dấu nhắc LLM nhằm tạo SQL và xác định cấu trúc SQL tạm thời sẽ được công cụ SQL thực thi cùng với SQL do LLM tạo ra (ở bước tiếp theo).
- Với lời nhắc đã chuẩn bị, bước này sẽ gọi LLM đang chạy trên Amazon Bedrock để tạo các câu lệnh SQL tương ứng với truy vấn ngôn ngữ tự nhiên đầu vào.
- Bước này thực hiện truy vấn SQL được tạo ra đối với cơ sở dữ liệu mục tiêu. Trong ví dụ triển khai của chúng tôi, chúng tôi đã sử dụng cơ sở dữ liệu SQLite cho mục đích minh họa, nhưng bạn có thể sử dụng máy chủ cơ sở dữ liệu khác.
Kết quả cuối cùng thu được bằng cách chạy pipeline trước đó trên Lambda. Khi quy trình làm việc hoàn tất, kết quả được cung cấp dưới dạng phản hồi cho yêu cầu REST API.
Sơ đồ sau đây minh họa kiến trúc giải pháp.
Phần kết luận
Trong bài đăng này, các nhóm AWS và Cisco đã tiết lộ một phương pháp tiếp cận có thể giải quyết các thách thức của việc tạo SQL cấp doanh nghiệp. Các nhóm đã có thể giảm độ phức tạp của quy trình NL2SQL trong khi vẫn mang lại độ chính xác cao hơn và hiệu suất tổng thể tốt hơn.
Mặc dù chúng tôi đã hướng dẫn bạn qua một ví dụ về trường hợp sử dụng tập trung vào việc trả lời các câu hỏi về vận động viên Olympic, nhưng mô hình linh hoạt này có thể được điều chỉnh liền mạch cho nhiều ứng dụng kinh doanh và trường hợp sử dụng khác nhau. Mã demo có sẵn trong kho lưu trữ GitHub. Chúng tôi mời bạn để lại bất kỳ câu hỏi và phản hồi nào trong phần bình luận.
Về tác giả

Renuka Kumar
Renuka Kumar là Kỹ sư trưởng kỹ thuật tại Cisco. Trong 2 năm qua, bà đã thiết kế kiến trúc và dẫn dắt phát triển các năng lực AI/ML cho mảng bảo mật đám mây của Cisco, bao gồm cả việc ra mắt những đổi mới đầu tiên trên thị trường trong lĩnh vực này. Bà có hơn 20 năm kinh nghiệm trong nhiều lĩnh vực công nghệ tiên tiến, với hơn 10 năm tập trung vào bảo mật và quyền riêng tư. Renuka có bằng Tiến sĩ Khoa học Máy tính & Kỹ thuật tại Đại học Michigan.

Toby Fotherby
Toby Fotherby là Kiến trúc sư giải pháp cấp cao chuyên về AI và ML tại AWS. Anh hỗ trợ khách hàng ứng dụng những tiến bộ mới nhất về AI/ML và AI tạo sinh để mở rộng đổi mới. Toby có hơn 10 năm kinh nghiệm đa ngành trong việc dẫn dắt các sáng kiến chiến lược, đồng thời sở hữu bằng thạc sĩ về Trí tuệ nhân tạo và Khoa học dữ liệu. Ngoài ra, anh còn lãnh đạo một chương trình đào tạo thế hệ Kiến trúc sư Giải pháp AI tiếp theo.

Shweta Keshavanarayana
Shweta là Quản lý giải pháp khách hàng cấp cao tại AWS. Bà làm việc với các khách hàng chiến lược của AWS, hỗ trợ họ trong hành trình di trú và hiện đại hóa lên đám mây. Shweta đam mê việc giải quyết các thách thức phức tạp của khách hàng bằng những giải pháp sáng tạo. Bà có bằng Cử nhân Khoa học Máy tính & Kỹ thuật. Ngoài công việc, Shweta tham gia quản lý đội cricket U9 của con trai, đồng thời cố vấn cho phụ nữ trong ngành công nghệ và phục vụ cộng đồng địa phương.

Thomas Matthew
Thomas Matthew là Kỹ sư AI/ML tại Cisco. Trong suốt 10 năm qua, ông đã ứng dụng lý thuyết đồ thị và phân tích chuỗi thời gian để giải quyết các vấn đề phát hiện và ngăn chặn rò rỉ dữ liệu trong lĩnh vực an ninh mạng. Ông từng trình bày nghiên cứu tại BlackHat và DefCon. Hiện tại, Thomas hỗ trợ tích hợp công nghệ AI tạo sinh vào các sản phẩm bảo mật đám mây của Cisco.

Daniel Vaquero
Daniel Vaquero là Kiến trúc sư giải pháp cấp cao về AI/ML tại AWS. Ông giúp khách hàng giải quyết các thách thức kinh doanh bằng trí tuệ nhân tạo và học máy, từ cách tiếp cận truyền thống đến AI tạo sinh. Daniel có hơn 12 năm kinh nghiệm trong thị giác máy tính, nhiếp ảnh tính toán, học máy và khoa học dữ liệu. Ông có bằng Tiến sĩ Khoa học Máy tính từ Đại học California, Santa Barbara (UCSB).

Atul Varshneya
Atul Varshneya từng là Kiến trúc sư giải pháp cấp cao chuyên về AI/ML tại AWS. Hiện ông tập trung phát triển các giải pháp trong lĩnh vực AI/ML, đặc biệt là AI tạo sinh. Với sự nghiệp kéo dài hơn 40 năm, Atul từng giữ vai trò lãnh đạo R&D công nghệ tại nhiều tập đoàn lớn và các công ty khởi nghiệp.

Jessica Wu
Jessica Wu là Kiến trúc sư giải pháp tại AWS. Cô hỗ trợ khách hàng xây dựng kiến trúc có hiệu năng cao, khả năng phục hồi, chịu lỗi, tối ưu chi phí và bền vững.
