Tác giả: Satveer Khurpa, Andrew Kane, Antonio Rodriguez, và Shyam Srinivasan
Ngày đăng: Ngày 28 tháng 3 năm 2025
Danh mục: Amazon Bedrock, Amazon Bedrock Guardrails, Announcements, Artificial Intelligence
Amazon Bedrock Guardrails chính thức ra mắt bộ lọc nội dung hình ảnh, cho phép bạn kiểm duyệt cả nội dung hình ảnh lẫn văn bản trong các ứng dụng generative AI. Trước đây, tính năng chỉ giới hạn ở việc lọc văn bản với cải tiến này, bạn đã có giải pháp kiểm duyệt toàn diện cho cả hai loại nội dung. Năng lực mới này giúp bạn không còn phải tự xây dựng cơ chế bảo vệ hình ảnh hay tốn công cho việc kiểm duyệt thủ công vốn dễ sai sót và mất thời gian.
Ông Tero Hottinen, Phó Chủ tịch kiêm Trưởng bộ phận Quan hệ Đối tác Chiến lược tại KONE, đưa ra hình dung về trường hợp sử dụng (use case) sau đây:
“Qua quá trình đánh giá hiện tại, KONE nhận thấy tiềm năng của Amazon Bedrock Guardrails như một thành phần chủ chốt trong việc bảo vệ các ứng dụng AI tạo sinh, đặc biệt là đối với việc kiểm tra mức độ phù hợp (relevance) và khả năng bám sát vào ngữ cảnh (contextual grounding), cũng như các cơ chế bảo vệ đa phương thức (multimodal). Công ty hình dung việc tích hợp các sơ đồ thiết kế sản phẩm và tài liệu hướng dẫn vào ứng dụng của mình, trong đó Amazon Bedrock Guardrails sẽ đóng vai trò then chốt giúp chẩn đoán (diagnosis) và phân tích nội dung đa phương thức một cách chính xác hơn.”
Amazon Bedrock Guardrails cung cấp các cơ chế bảo vệ (safeguards) có thể tùy chỉnh để giúp khách hàng chặn các đầu vào và đầu ra có hại hoặc không mong muốn cho các ứng dụng GenAI của họ. Khách hàng có thể tạo các Guardrails tùy chỉnh được tinh chỉnh riêng cho các trường hợp sử dụng (use cases) cụ thể của họ, bằng cách triển khai các chính sách (policies) khác nhau để phát hiện và lọc nội dung có hại hoặc không mong muốn từ cả các yêu cầu đầu vào (input prompts) và các phản hồi của mô hình (model responses). Hơn nữa, khách hàng có thể sử dụng Guardrails để phát hiện hiện tượng ảo giác (hallucinations) của mô hình, và giúp đảm bảo các phản hồi là chính xác và bám sát vào ngữ cảnh (grounded). Thông qua API ApplyGuardrail độc lập của mình, Guardrails cho phép khách hàng áp dụng các chính sách nhất quán trên bất kỳ foundation model nào, bao gồm cả các mô hình được lưu trữ trên Amazon Bedrock, các mô hình tự lưu trữ (self-hosted), và các mô hình của bên thứ ba. Bedrock Guardrails hỗ trợ tích hợp liền mạch (seamless integration) với Bedrock Agents và Bedrock Knowledge Bases, cho phép các nhà phát triển thực thi các cơ chế bảo vệ trên nhiều luồng công việc (workflows) khác nhau, chẳng hạn như các hệ thống Tạo sinh Tăng cường truy xuất (Retrieval Augmented Generation – RAG) và các ứng dụng mang tính tác tử (agentic).
Amazon Bedrock Guardrails cung cấp sáu chính sách (policies) riêng biệt, bao gồm:
- Bộ lọc nội dung: Để phát hiện và lọc các nội dung độc hại thuộc nhiều danh mục, bao gồm thù ghét, xúc phạm, nội dung khiêu dâm, bạo lực, hành vi sai trái, và để ngăn chặn các cuộc tấn công bằng yêu cầu đầu vào (prompt attacks).
- Bộ lọc chủ đề: Để hạn chế các chủ đề cụ thể.
- Bộ lọc thông tin nhạy cảm: Để chặn thông tin nhận dạng cá nhân (Personally Identifiable Information – PII).
- Bộ lọc từ ngữ: Để chặn các thuật ngữ cụ thể.
- Kiểm tra khả năng bám sát vào ngữ cảnh (contextual grounding checks): Để phát hiện hiện tượng ảo giác (hallucinations) và phân tích mức độ phù hợp (relevance) của phản hồi.
- Kiểm tra Suy luận Tự động (Automated Reasoning checks): (hiện đang trong giai đoạn preview giới hạn (gated preview)) để xác định, sửa chữa và giải thích các khẳng định mang tính thực tế (factual claims).
Với năng lực kiểm duyệt nội dung hình ảnh mới, các cơ chế bảo vệ này giờ đây được mở rộng cho cả văn bản và hình ảnh, giúp khách hàng chặn tới 88% nội dung đa phương thức (multimodal) độc hại. Bạn có thể cấu hình việc kiểm duyệt một cách độc lập cho nội dung hình ảnh hoặc văn bản (hoặc cả hai), với các ngưỡng (thresholds) có thể điều chỉnh từ thấp đến cao, giúp bạn xây dựng các ứng dụng AI tạo sinh tuân thủ các chính sách AI có trách nhiệm (responsible AI policies) của tổ chức mình.
Tính năng mới này hiện đã khả dụng rộng rãi tại các Khu vực AWS Regions sau: US East (N. Virginia), US West (Oregon), Europe (Frankfurt), và Asia Pacific (Tokyo).
Trong bài viết này, chúng tôi sẽ thảo luận về cách bắt đầu sử dụng các bộ lọc nội dung hình ảnh trong Amazon Bedrock Guardrails
Tổng quan về giải pháp
Để bắt đầu, hãy tạo một guardrail trên AWS Management Console và cấu hình các bộ lọc nội dung cho dữ liệu dạng văn bản, hình ảnh, hoặc cả hai. Bạn cũng có thể sử dụng AWS SDKs để tích hợp năng lực này vào các ứng dụng của bạn.
Tạo một guardrail
Để tạo một guardrail, hãy thực hiện các bước sau:
- Trên Amazon Bedrock console, trên thanh điều hướng, bên dưới mục Safeguards, hãy chọn Guardrails.
- Hãy chọn Create guardrail.
- Trong phần Configure content filters, bên dưới các mục Harmful categories và Prompt attacks, bạn có thể sử dụng các bộ lọc nội dung hiện có để phát hiện và chặn dữ liệu hình ảnh ngoài dữ liệu văn bản.
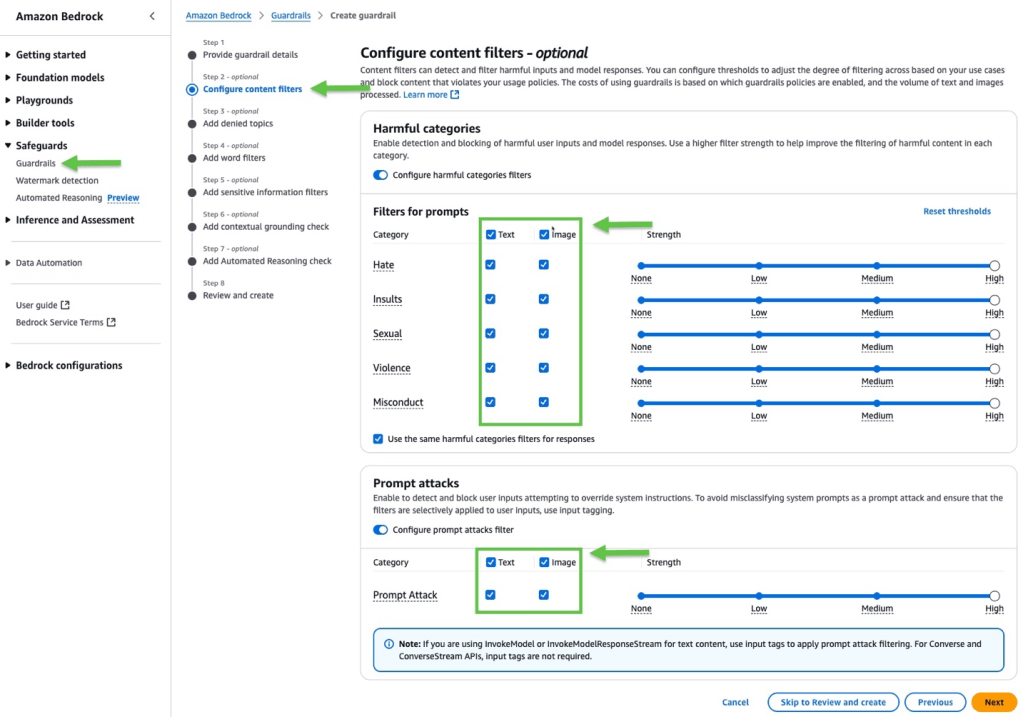
4. Sau khi đã chọn và cấu hình xong các bộ lọc nội dung muốn sử dụng, bạn có thể lưu guardrail lại và bắt đầu sử dụng nó để giúp chặn các đầu vào và đầu ra có hại hoặc không mong muốn cho các ứng dụng GenAI của mình.
Để kiểm thử guardrail mới trên Amazon Bedrock console, hãy chọn guardrail đó và nhấn Test. Bạn có hai tùy chọn: kiểm thử guardrail bằng cách chọn và gọi (invoke) một mô hình, hoặc kiểm thử guardrail mà không cần gọi mô hình bằng cách sử dụng API ApplyGuardail độc lập của Amazon Bedrock Guardrails.
Với API ApplyGuardrail, bạn có thể xác thực (validate) nội dung tại bất kỳ điểm nào trong luồng ứng dụng của mình, trước khi xử lý hoặc trả kết quả về cho người dùng. Bạn cũng có thể sử dụng API này để đánh giá các đầu vào và đầu ra cho các FMs (foundation models) tự quản lý (tùy chỉnh) hoặc của bên thứ ba, bất kể cơ sở hạ tầng (infrastructure) nền tảng là gì. Ví dụ, bạn có thể dùng API để đánh giá một mô hình Meta Llama 3.2 được lưu trữ trên Amazon SageMaker hoặc một mô hình Mistral NeMo đang chạy trên máy tính xách tay của bạn.
Kiểm thử guardrail bằng cách chọn và gọi một mô hình
Hãy chọn một mô hình hỗ trợ đầu vào hoặc đầu ra dạng hình ảnh, ví dụ như Claude 3.5 Sonnet của Anthropic. Xác minh rằng các bộ lọc yêu cầu đầu vào (prompt) và phản hồi (response) đã được bật cho nội dung hình ảnh. Sau đó, hãy cung cấp một yêu cầu đầu vào (prompt), tải lên một tệp hình ảnh, và nhấn Run.
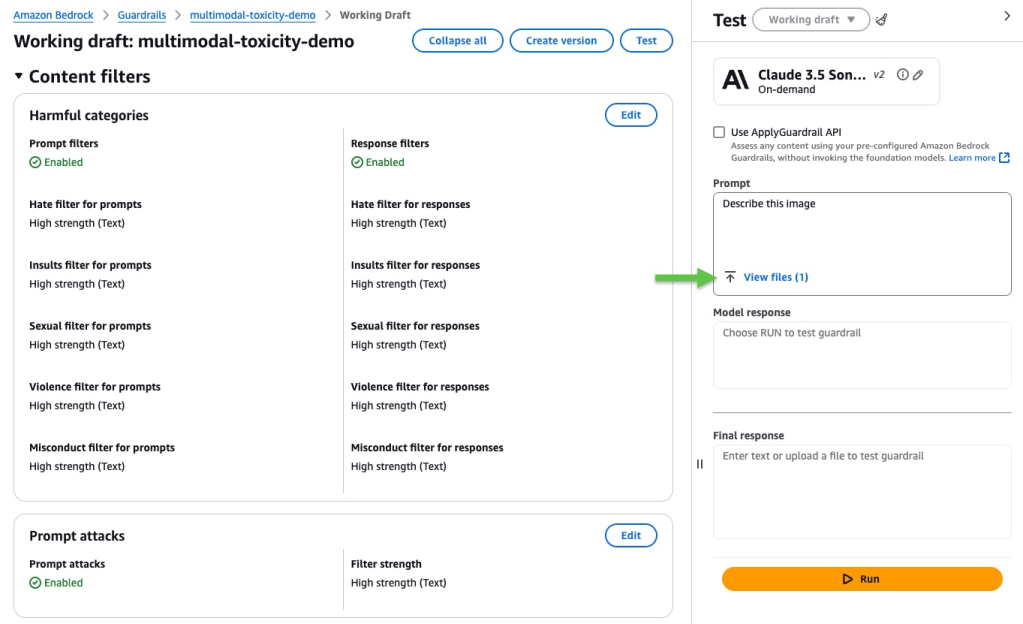
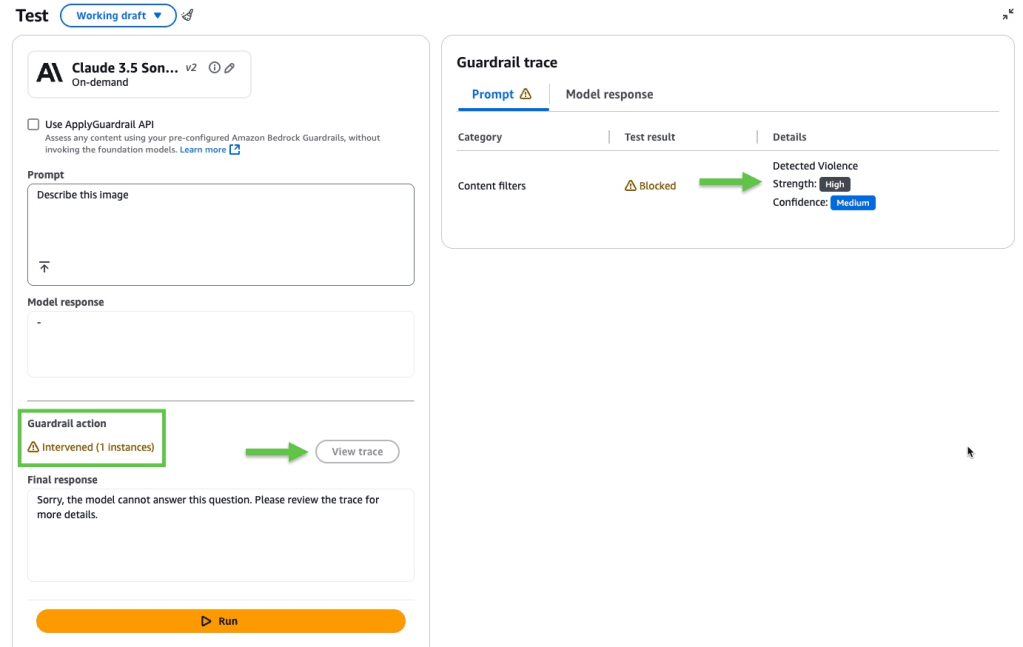
Trong ví dụ này, Amazon Bedrock Guardrails đã can thiệp. Nhấn vào View trace để xem thêm chi tiết.
Bản ghi theo dõi (trace) của guardrail cung cấp thông tin về cách các biện pháp an toàn đã được áp dụng trong một phiên tương tác. Nó cho thấy liệu Amazon Bedrock Guardrails có can thiệp hay không, và những đánh giá nào đã được thực hiện trên cả yêu cầu đầu vào (prompt) và phản hồi của mô hình (model response). Trong ví dụ này, các bộ lọc nội dung đã chặn yêu cầu đầu vào bởi vì chúng phát hiện thấy yếu tố bạo lực trong hình ảnh với độ tin cậy (confidence) ở mức trung bình.
Kiểm thử guardrail mà không cần gọi mô hình
Trên Amazon Bedrock console, hãy chọn Use ApplyGuardrail API—đây là API độc lập dùng để kiểm thử guardrail mà không cần gọi mô hình. Hãy chọn xem bạn muốn xác thực (validate) một yêu cầu đầu vào (prompt) hay một ví dụ về kết quả do mô hình tạo ra (model generated output). Sau đó, hãy lặp lại các bước từ phần trước. Xác minh rằng các bộ lọc yêu cầu đầu vào (prompt) và phản hồi (response) đã được bật cho nội dung hình ảnh, cung cấp nội dung cần xác thực, và nhấn Run.

Đối với ví dụ này, chúng tôi đã tái sử dụng cùng một hình ảnh và yêu cầu đầu vào, và Amazon Bedrock Guardrails lại tiếp tục can thiệp. Hãy nhấn vào View trace một lần nữa để xem thêm chi tiết.

Kiểm thử guardrail với tính năng tạo hình ảnh
Bây giờ, chúng ta hãy cùng kiểm thử tính năng phát hiện nội dung độc hại đa phương thức (multimodal toxicity detection) của Amazon Bedrock Guardrails với các trường hợp sử dụng (use cases) liên quan đến tạo hình ảnh. Sau đây là một ví dụ về việc sử dụng các bộ lọc nội dung hình ảnh của Amazon Bedrock Guardrails với một trường hợp sử dụng tạo hình ảnh. Chúng tôi tạo một hình ảnh bằng cách sử dụng mô hình Stability trên Amazon Bedrock thông qua API InvokeModel và guardrail:
guardrailIdentifier = <<guardrail_id>>
guardrailVersion ="1"
model_id = 'stability.sd3-5-large-v1:0'
output_images_folder = 'images/output'
body = json.dumps(
{
"prompt": "A Gun", # for image generation ("A gun" should get blocked by violence)
"output_format": "jpeg"
}
)
bedrock_runtime = boto3.client("bedrock-runtime", region_name=region)
try:
print("Making a call to InvokeModel API for model: {}".format(model_id))
response = bedrock_runtime.invoke_model(
body=body,
modelId=model_id,
trace='ENABLED',
guardrailIdentifier=guardrailIdentifier,
guardrailVersion=guardrailVersion
)
response_body = json.loads(response.get('body').read())
print("Received response from InvokeModel API (Request Id: {})".format(response['ResponseMetadata']['RequestId']))
if 'images' in response_body and len(response_body['images']) > 0:
os.makedirs(output_images_folder, exist_ok=True)
images = response_body["images"]
for image in images:
image_id = ''.join(random.choices(string.ascii_lowercase + string.digits, k=6))
image_file = os.path.join(output_images_folder, "generated-image-{}.jpg".format(image_id))
print("Saving generated image {} at {}".format(image_id, image_file))
with open(image_file, 'wb') as image_file_descriptor:
image_file_descriptor.write(base64.b64decode(image.encode('utf-8')))
else:
print("No images generated from model")
guardrail_trace = response_body['amazon-bedrock-trace']['guardrail']
guardrail_trace['modelOutput'] = ['<REDACTED>']
print(guardrail_trace['outputs'])
print("\nGuardrail Trace: {}".format(json.dumps(guardrail_trace, indent=2)))
except botocore.exceptions.ClientError as err:
print("Failed while calling InvokeModel API with RequestId = {}".format(err.response['ResponseMetadata']['RequestId']))
raise errBạn có thể truy cập ví dụ hoàn chỉnh từ kho mã nguồn (repo) trên GitHub.
Kết luận
Trong bài viết này, chúng ta đã cùng tìm hiểu cách các bộ lọc nội dung hình ảnh mới của Amazon Bedrock Guardrails cung cấp các năng lực kiểm duyệt nội dung đa phương thức (multimodal content moderation) một cách toàn diện. Bằng cách mở rộng ra ngoài phạm vi chỉ lọc văn bản, giải pháp này giờ đây giúp khách hàng chặn tới 88% nội dung đa phương thức có hại hoặc không mong muốn, áp dụng trên các danh mục có thể tùy chỉnh bao gồm thù ghét, xúc phạm, nội dung khiêu dâm, bạo lực, hành vi sai trái, và phát hiện tấn công bằng yêu cầu đầu vào (prompt attack). Guardrails có thể giúp các tổ chức trong nhiều lĩnh vực như y tế, sản xuất, dịch vụ tài chính, truyền thông và giáo dục nâng cao an toàn thương hiệu (brand safety) mà không cần phải tốn công sức xây dựng các cơ chế bảo vệ tùy chỉnh hay thực hiện các quy trình đánh giá thủ công vốn dễ xảy ra sai sót.
Để tìm hiểu thêm, vui lòng xem tài liệu Stop harmful content in models using Amazon Bedrock Guardrails.
Về tác giả

Satveer Khurpa là Kiến trúc sư giải pháp chuyên gia Cấp cao Toàn cầu (Sr. WW Specialist Solutions Architect), chuyên về Amazon Bedrock tại Amazon Web Services (AWS), với chuyên môn sâu về bảo mật cho Amazon Bedrock. Ở vai trò này, ông vận dụng chuyên môn của mình về các kiến trúc dựa trên đám mây (cloud-based architectures) để phát triển các giải pháp AI tạo sinh sáng tạo cho các khách hàng thuộc nhiều ngành công nghiệp đa dạng. Sự am hiểu sâu sắc của ông Satveer về các công nghệ AI tạo sinh và các nguyên tắc bảo mật (security principles) cho phép ông thiết kế các ứng dụng có trách nhiệm, an toàn và có khả năng mở rộng (scalable), giúp mở ra các cơ hội kinh doanh mới và mang lại giá trị hữu hình, đồng thời vẫn duy trì được một trạng thái bảo mật (security posture) vững chắc.

Shyam Srinivasan hiện là thành viên trong nhóm sản phẩm Amazon Bedrock Guardrails. Anh luôn mong muốn góp phần làm cho thế giới trở nên tốt đẹp hơn thông qua công nghệ và rất tự hào khi được đồng hành trong hành trình này. Trong thời gian rảnh, Shyam thích chạy đường dài, đi du lịch vòng quanh thế giới và trải nghiệm những nền văn hóa mới cùng gia đình và bạn bè.

Antonio Rodriguez là Kiến trúc sư Giải pháp Chuyên gia Generative AI Cấp cao tại AWS. Anh hỗ trợ các công ty thuộc mọi quy mô giải quyết thách thức, thúc đẩy đổi mới và tạo ra cơ hội kinh doanh mới với Amazon Bedrock. Ngoài công việc, anh thích dành thời gian cho gia đình và chơi thể thao cùng bạn bè.

Tiến sĩ Andrew Kane là Lãnh đạo Kỹ thuật Toàn cầu về Bảo mật và Tuân thủ cho các Dịch vụ Generative AI của AWS, phụ trách cung cấp các giải pháp kỹ thuật chuyên sâu cho khách hàng về bảo mật, cũng như làm việc với các CISO trong việc áp dụng dịch vụ generative AI trong tổ chức của họ. Trước khi gia nhập AWS vào đầu năm 2015, Andrew đã có hai thập kỷ làm việc trong các lĩnh vực như xử lý tín hiệu, hệ thống thanh toán tài chính, theo dõi vũ khí, và các hệ thống biên tập cũng như xuất bản. Anh đam mê karate (chỉ còn một đai nữa là đạt Hắc đai) và cũng là một người yêu thích nấu bia thủ công tại nhà, sử dụng thiết bị nấu bia tự động cùng các cảm biến IoT. Anh từng là người có giấy phép kinh doanh hợp pháp tại một quán rượu nông thôn cổ kính ở Anh (có từ năm 1468) cho đến đầu năm 2020.
