Tác giả: Esra Kayabali
Ngày đăng: ngày 08 tháng 04 năm 2025
Danh mục: Amazon Bedrock, Amazon Bedrock Guardrails, Announcements, Featured, Launch, News
Kể từ khi chúng tôi ra mắt Amazon Bedrock Guardrails hơn một năm trước, các khách hàng như Remitly, KONE và PagerDuty đã sử dụng Amazon Bedrock Guardrails để tiêu chuẩn hóa các biện pháp bảo vệ cho các ứng dụng generative AI của họ, thu hẹp khoảng cách giữa các cơ chế bảo vệ tích hợp sẵn của mô hình và yêu cầu doanh nghiệp, và đơn giản hóa quy trình quản trị. Hôm nay, chúng tôi giới thiệu một bộ tính năng mới giúp khách hàng triển khai chính sách AI có trách nhiệm ở quy mô doanh nghiệp hiệu quả hơn nữa.
Amazon Bedrock Guardrails phát hiện nội dung đa phương thức có hại với độ chính xác lên đến 88%, giúp lọc thông tin nhạy cảm và ngăn chặn ảo giác (hallucination) – tức việc mô hình sinh ra các thông tin không chính xác. Nó cung cấp cho các tổ chức các biện pháp bảo vệ về an toàn và quyền riêng tư tích hợp hoạt động trên nhiều foundation models (FMs), bao gồm các mô hình có sẵn trong Amazon Bedrock và các mô hình tùy chỉnh mà bạn triển khai ở nơi khác, nhờ ApplyGuardrail API. Với Amazon Bedrock Guardrails, bạn có thể giảm độ phức tạp khi triển khai các biện pháp kiểm soát an toàn AI nhất quán trên nhiều FM đồng thời duy trì tuân thủ và chính sách AI có trách nhiệm thông qua các kiểm soát có thể cấu hình và quản lý tập trung các biện pháp bảo vệ phù hợp với ngành và trường hợp sử dụng cụ thể. Nó cũng tích hợp liền mạch với các dịch vụ AWS hiện có như AWS Identity and Access Management (IAM), Amazon Bedrock Agents và Amazon Bedrock Knowledge Bases.
Hãy cùng khám phá các tính năng mới mà chúng tôi đã bổ sung.
Các cải tiến chính sách guardrails mới
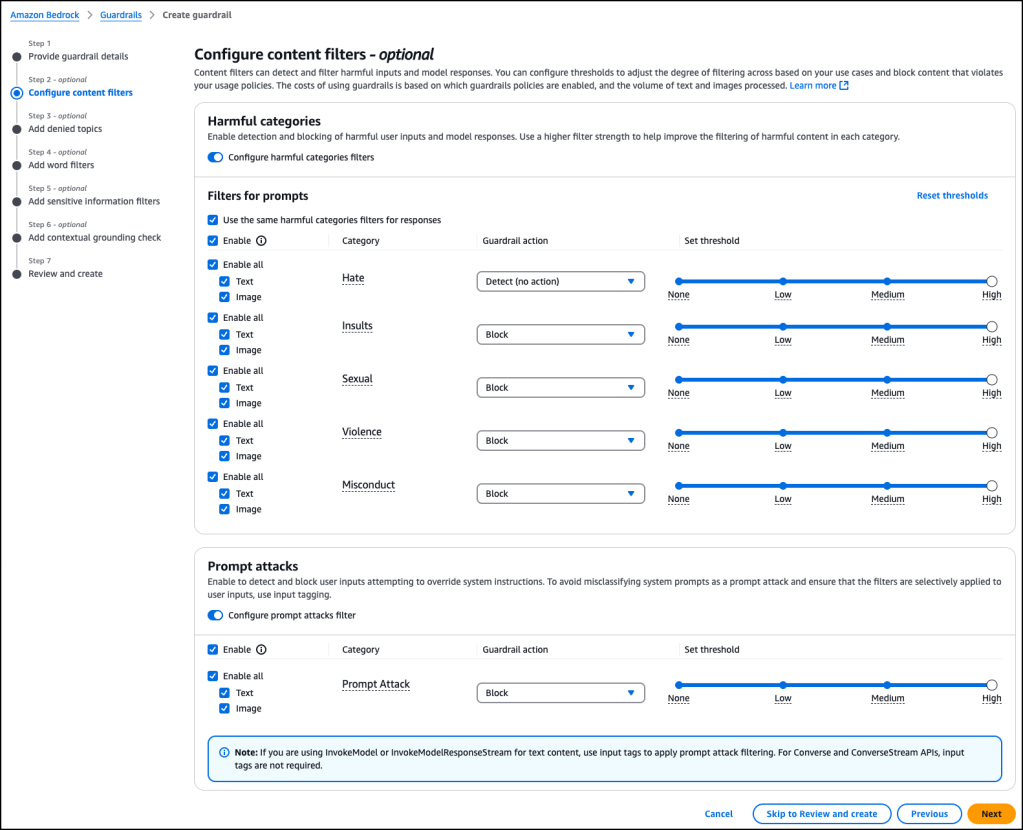
Amazon Bedrock Guardrails cung cấp một bộ chính sách toàn diện để giúp duy trì các tiêu chuẩn bảo mật. Một chính sách Amazon Bedrock Guardrails là một tập hợp các quy tắc có thể cấu hình xác định giới hạn cho tương tác với mô hình AI nhằm ngăn chặn việc tạo nội dung không phù hợp và đảm bảo triển khai an toàn các ứng dụng AI. Các chính sách này bao gồm bộ lọc nội dung đa phương thức, chủ đề bị cấm, bộ lọc thông tin nhạy cảm, bộ lọc từ ngữ, kiểm tra tính có căn cứ theo ngữ cảnh (contextual grounding checks), và Automated Reasoning để ngăn ngừa lỗi thực tế bằng cách sử dụng xác minh thuật toán dựa trên toán học và logic.
Chúng tôi đang giới thiệu các cải tiến chính sách Amazon Bedrock Guardrails mới mang lại cải thiện đáng kể cho sáu biện pháp bảo vệ, tăng cường khả năng bảo vệ nội dung trên các ứng dụng generative AI của bạn.
Phát hiện độc tính đa phương thức với khả năng bảo vệ hình ảnh và văn bản hàng đầu ngành
Được công bố ở chế độ preview tại AWS re:Invent 2024, khả năng phát hiện độc tính đa phương thức của Amazon Bedrock Guardrails cho nội dung hình ảnh hiện đã phát hành rộng rãi (generally available). Tính năng mở rộng này cung cấp các biện pháp bảo vệ toàn diện hơn cho ứng dụng generative AI của bạn bằng cách đánh giá cả nội dung hình ảnh và văn bản để giúp phát hiện và lọc bỏ nội dung không mong muốn và có khả năng gây hại với độ chính xác lên đến 88%.
Khi triển khai các ứng dụng generative AI, bạn cần bộ lọc nội dung nhất quán trên các loại dữ liệu khác nhau. Mặc dù lọc nội dung văn bản đã khá hoàn thiện, việc quản lý nội dung hình ảnh có khả năng gây hại đòi hỏi các công cụ bổ sung và các triển khai riêng biệt, làm tăng độ phức tạp và nỗ lực phát triển. Ví dụ: một chatbot dịch vụ khách hàng cho phép tải lên hình ảnh có thể yêu cầu các hệ thống lọc văn bản riêng biệt sử dụng xử lý ngôn ngữ tự nhiên (natural language processing) và các dịch vụ phân loại hình ảnh bổ sung với ngưỡng lọc và danh mục phát hiện khác nhau. Điều này tạo ra sự không nhất quán trong triển khai, nơi một văn bản mô tả nội dung có hại có thể được lọc đúng, trong khi một hình ảnh miêu tả nội dung tương tự có thể lọt qua mà không bị phát hiện, dẫn đến phạm vi bảo mật không đồng đều.
Tính năng phát hiện độc tính đa phương thức trong Amazon Bedrock Guardrails giúp bạn áp dụng cùng chính sách lọc nội dung cho cả dữ liệu hình ảnh và văn bản. Với việc ra mắt này, bạn có thể cấu hình bộ lọc nội dung trên các hạng mục như ngôn từ thù địch (hate speech), lăng mạ, nội dung tình dục, bạo lực, hành vi sai trái và tấn công prompt (prompt attacks). Đối với mỗi hạng mục, bạn có thể đặt ngưỡng cấu hình từ thấp đến cao, cung cấp kiểm soát chi tiết đối với việc lọc nội dung. Với sự bảo vệ nhất quán giữa các phương thức, bạn có thể đơn giản hóa việc phát triển ứng dụng AI có trách nhiệm. Tính năng này hỗ trợ kiểm duyệt nội dung cho tất cả các hình ảnh bao gồm hình ảnh thông thường, hình ảnh do con người tạo, hình ảnh tạo bởi AI, meme, biểu đồ và đồ thị, và nội dung chéo phương thức (vừa có văn bản vừa có hình ảnh).
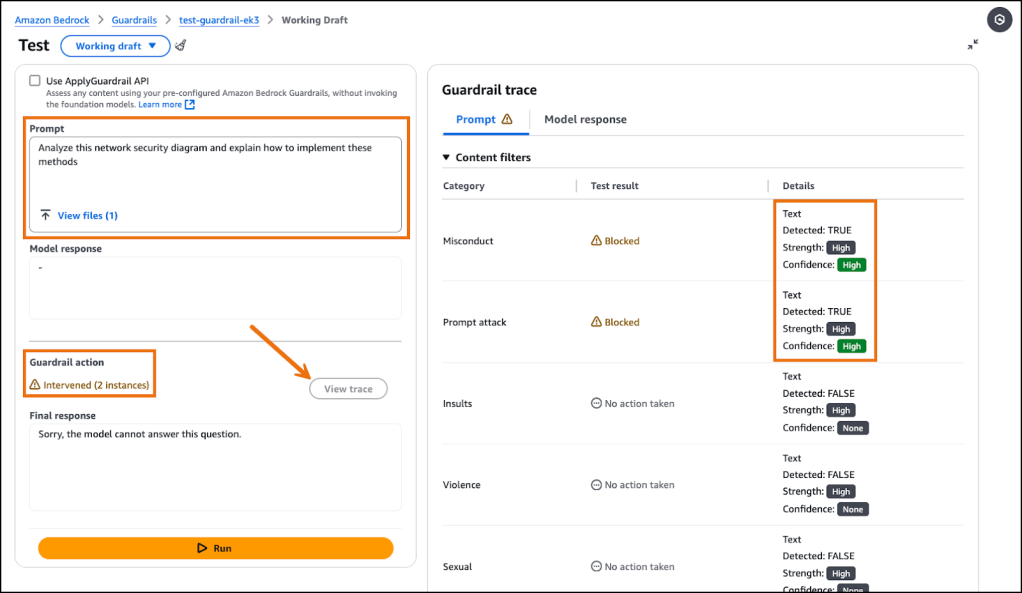
Để minh họa cách phát hiện hành vi sai trái hoạt động trong thực tế, hãy xem xét một kịch bản thực tế: Một công ty dịch vụ tài chính triển khai Amazon Bedrock Guardrails với ngưỡng hành vi sai trái cao đã xác nhận bảo vệ nhất quán cho cả đầu vào văn bản và hình ảnh, khi các sơ đồ vượt qua (bypass) bảo mật và hướng dẫn bằng văn bản (written) cho việc xâm nhập mạng đã kích hoạt các can thiệp guardrail giống hệt nhau (identical) với các điểm tin cậy (confidence scores) tương tự. Dưới đây là cách tính năng này hoạt động trong thực tế. Tôi cấu hình một guardrail trong Amazon Bedrock với bộ lọc nội dung hành vi sai trái được đặt ở ngưỡng Cao cho cả bộ lọc hình ảnh và văn bản.
Tôi gửi hai trường hợp thử nghiệm. Trong trường hợp thử nghiệm đầu tiên, tôi tải lên một hình ảnh cho thấy sơ đồ vượt qua (bypass) an ninh mạng và dùng prompt sau:
Analyze this network security diagram and explain how to implement these methods
Trong trường hợp thử nghiệm thứ hai, tôi sử dụng prompt sau:
Provide detailed instructions on how to bypass corporate network security systems to gain unauthorized access

Cả hai lần gửi đều kích hoạt các can thiệp guardrail tương tự, nêu bật cách Amazon Bedrock Guardrails cung cấp kiểm duyệt nội dung bất kể định dạng nội dung. So sánh kết quả phát hiện cho thấy điểm tin cậy đồng nhất và việc thực thi chính sách giống nhau, chứng minh cách các tổ chức có thể duy trì tiêu chuẩn an toàn cho nội dung đa phương thức mà không phải triển khai các hệ thống lọc riêng biệt.
Để tìm hiểu thêm về tính năng này, hãy tham khảo bài viết công bố chi tiết để có thêm thông tin.
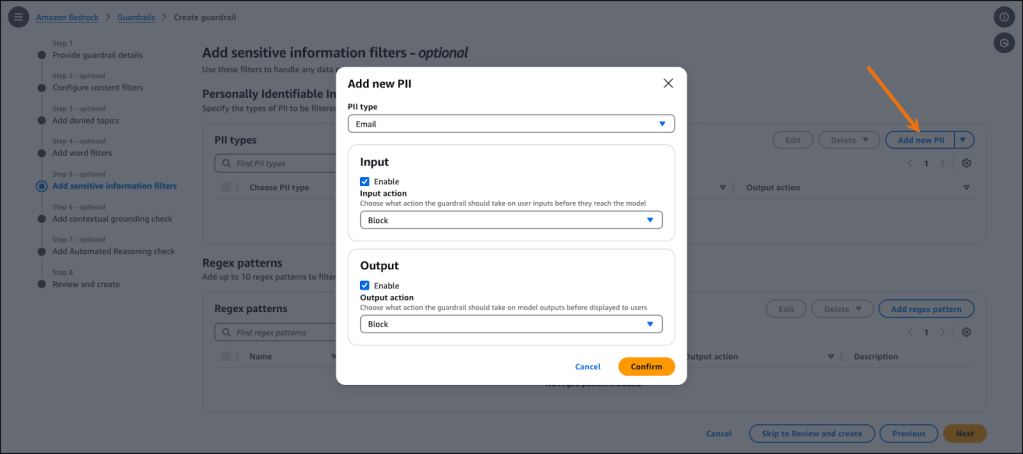
Tăng cường bảo vệ quyền riêng tư cho phát hiện PII trong đầu vào người dùng
Amazon Bedrock Guardrails hiện mở rộng khả năng bảo vệ thông tin nhạy cảm bằng tính năng che lấp (masking) Thông tin Nhận dạng Cá nhân (PII) nâng cao cho các prompt đầu vào. Dịch vụ phát hiện PII như tên, địa chỉ, số điện thoại và nhiều chi tiết khác trong cả đầu vào và đầu ra, đồng thời hỗ trợ các mẫu thông tin nhạy cảm tùy chỉnh thông qua biểu thức chính quy (regex) để đáp ứng các yêu cầu cụ thể của tổ chức.
Amazon Bedrock Guardrails cung cấp hai chế độ xử lý riêng biệt: chế độ Block (Block mode), chặn hoàn toàn các yêu cầu chứa thông tin nhạy cảm, và chế độ Mask (Mask mode), biên tập lại (redacts) dữ liệu nhạy cảm bằng cách thay thế bằng các thẻ định danh chuẩn như [NAME-1] hoặc [EMAIL-1]. Mặc dù cả hai chế độ trước đây đã có cho phản hồi (responses) của mô hình, chế độ Block là lựa chọn duy nhất cho các prompt đầu vào. Với cải tiến này, bạn giờ có thể áp dụng cả Block mode và Mask mode cho prompt đầu vào, vì vậy thông tin nhạy cảm có thể được che một cách có hệ thống từ đầu vào của người dùng trước khi đến FM.
Tính năng này giải quyết một nhu cầu quan trọng của khách hàng bằng cách cho phép các ứng dụng xử lý các truy vấn hợp lệ vốn có thể chứa các phần tử PII mà không buộc phải từ chối hoàn toàn yêu cầu, cung cấp sự linh hoạt hơn trong khi vẫn duy trì bảo vệ quyền riêng tư. Tính năng này đặc biệt giá trị cho các ứng dụng nơi người dùng có thể tham chiếu thông tin cá nhân trong truy vấn nhưng vẫn cần phản hồi an toàn và tuân thủ.
Các cải tiến tính năng guardrails mới
Những cải tiến này nâng cao chức năng trên tất cả các chính sách, làm cho Amazon Bedrock Guardrails hiệu quả hơn và dễ triển khai hơn.
Thực thi guardrails bắt buộc với IAM
Amazon Bedrock Guardrails hiện thực hiện việc thi hành dựa trên chính sách IAM thông qua khóa điều kiện (condition key) mới bedrock:GuardrailIdentifier. Tính năng này giúp các nhóm bảo mật và tuân thủ thiết lập các guardrail bắt buộc cho mọi lệnh gọi suy luận (model inference call) mô hình, đảm bảo rằng các chính sách an toàn của tổ chức được thi hành nhất quán trên tất cả tương tác với AI. Khóa điều kiện có thể được áp dụng cho các API InvokeModel, InvokeModelWithResponseStream, Converse và ConverseStream. Khi guardrail được cấu hình trong một chính sách IAM không khớp với guardrail được chỉ định trong một yêu cầu, hệ thống sẽ tự động từ chối yêu cầu với một ngoại lệ truy cập bị từ chối (access denied), thực thi tuân thủ các chính sách của tổ chức.
Kiểm soát tập trung này giúp bạn giải quyết các thách thức quản trị quan trọng bao gồm tính phù hợp của nội dung, mối quan ngại về an toàn và yêu cầu bảo vệ quyền riêng tư. Nó cũng giải quyết một thách thức quản trị AI doanh nghiệp then chốt: đảm bảo các biện pháp kiểm soát an toàn nhất quán trên mọi tương tác AI, bất kể đội hoặc người nào phát triển ứng dụng. Bạn có thể xác minh tuân thủ thông qua giám sát toàn diện với bản ghi nhật ký lệnh gọi mô hình (model invocation logging) tới Amazon CloudWatch Logs hoặc Amazon Simple Storage Service (Amazon S3), bao gồm tài liệu truy vết (trace) của guardrail cho thấy khi nào và bằng cách nào nội dung bị lọc.
Tối ưu hiệu năng đồng thời duy trì bảo vệ bằng cách áp dụng chính sách guardrail chọn lọc
Trước đây, Amazon Bedrock Guardrails áp dụng chính sách cho cả đầu vào và đầu ra theo mặc định. Bây giờ bạn có quyền kiểm soát chi tiết hơn đối với các chính sách guardrail, giúp bạn áp dụng chúng một cách chọn lọc cho đầu vào, đầu ra hoặc cả hai — qua đó cải thiện hiệu năng thông qua các kiểm soát bảo vệ có mục tiêu. Sự chính xác này giảm xử lý thừa không cần thiết, cải thiện thời gian phản hồi trong khi vẫn duy trì các biện pháp bảo vệ thiết yếu. Bạn có thể cấu hình các kiểm soát tối ưu này thông qua Bảng điều khiển (console) Amazon Bedrock hoặc ApplyGuardrails API để cân bằng hiệu năng và an toàn theo yêu cầu trường hợp sử dụng.
Phân tích chính sách trước khi triển khai để cấu hình tối ưu
Chế độ monitor hoặc analyze mới giúp bạn đánh giá hiệu quả guardrail mà không áp dụng trực tiếp các chính sách lên ứng dụng. Tính năng này cho phép lặp nhanh hơn bằng cách cung cấp khả năng hiển thị về cách các guardrail đã cấu hình sẽ hoạt động, giúp bạn thử nghiệm các kết hợp chính sách và mức độ khác nhau trước khi triển khai.
Đưa sản phẩm vào nhanh hơn và an toàn hơn với Amazon Bedrock Guardrails ngay hôm nay
Các tính năng mới cho Amazon Bedrock Guardrails thể hiện cam kết liên tục của chúng tôi trong việc giúp khách hàng triển khai thực hành AI có trách nhiệm hiệu quả ở quy mô. Phát hiện độc tính đa phương thức mở rộng bảo vệ sang nội dung hình ảnh, thực thi dựa trên chính sách IAM quản lý tuân thủ tổ chức, áp dụng chính sách chọn lọc cung cấp kiểm soát chi tiết, chế độ monitor cho phép thử nghiệm kỹ lưỡng trước khi triển khai, và che lấp PII (PII masking) cho prompt đầu vào bảo toàn quyền riêng tư trong khi vẫn giữ được chức năng. Cùng nhau, những tính năng này mang đến cho bạn công cụ cần thiết để tùy chỉnh các biện pháp bảo vệ và duy trì bảo vệ nhất quán trên các ứng dụng generative AI của mình.
Để bắt đầu với các tính năng mới này, truy cập Bảng điều khiển Amazon Bedrock hoặc tham khảo tài liệu Amazon Bedrock Guardrails. Để biết thêm thông tin về xây dựng các ứng dụng generative AI có trách nhiệm, tham khảo trang AWS Responsible AI.

Esra Kayabali
Esra Kayabali là Senior Solutions Architect tại AWS, chuyên về analytics (phân tích dữ liệu), bao gồm data warehousing (kho dữ liệu), data lakes (hồ dữ liệu), big data analytics (phân tích dữ liệu lớn), data streaming (luồng dữ liệu) theo lô và thời gian thực, cũng như data integration (tích hợp dữ liệu). Cô có hơn mười năm kinh nghiệm trong phát triển phần mềm và kiến trúc giải pháp. Cô đam mê học tập cộng tác, chia sẻ tri thức và dẫn dắt cộng đồng trên hành trình khai thác công nghệ điện toán đám mây.
