Tác giả: Shreyas Subramanian, Nick McCarthy, Shalendra Chhabra, và Shreeya Sharma
Ngày phát hành: 25 MAR 2026
Chuyên mục: Amazon Bedrock, Announcements, Artificial Intelligence
Vào tháng 12 năm 2025, chúng tôi đã thông báo về việc Reinforcement fine-tuning (RFT) có sẵn trên Amazon Bedrock bắt đầu với sự hỗ trợ cho các mô hình Nova. Tiếp theo là hỗ trợ mở rộng cho các mô hình mã nguồn mở như OpenAI GPT OSS 20B và Qwen 3 32B vào tháng 2 năm 2026. RFT trong Amazon Bedrock tự động hóa quy trình tùy chỉnh từ đầu đến cuối. Điều này cho phép các mô hình học hỏi từ phản hồi trên nhiều phản hồi khả thi bằng cách sử dụng một tập hợp nhỏ các prompt, thay vì các tập dữ liệu huấn luyện lớn truyền thống.
Trong bài đăng này, chúng tôi sẽ hướng dẫn chi tiết quy trình làm việc từ đầu đến cuối khi sử dụng RFT trên Amazon Bedrock với các API tương thích OpenAI: từ thiết lập xác thực, triển khai hàm thưởng dựa trên Lambda, khởi động tác vụ huấn luyện và chạy suy luận theo yêu cầu trên mô hình đã được fine-tune của bạn. Ở đây, chúng tôi sử dụng tập dữ liệu toán học GSM8K làm ví dụ và nhắm mục tiêu mô hình gpt-oss-20B của OpenAI được lưu trữ trên Bedrock.
Cách hoạt động của Reinforcement fine-tuning
Reinforcement Fine-Tuning (RFT) đại diện cho một sự thay đổi trong cách chúng ta tùy chỉnh các mô hình ngôn ngữ lớn (LLM). Không giống như fine-tuning có giám sát (SFT) truyền thống, yêu cầu các mô hình học hỏi từ các cặp I/O tĩnh, RFT cho phép các mô hình học hỏi thông qua một vòng lặp phản hồi lặp đi lặp lại, nơi chúng tạo ra các phản hồi, nhận đánh giá và liên tục cải thiện khả năng ra quyết định của mình.
Khái niệm cốt lõi: học hỏi từ phản hồi
Về bản chất, học tăng cường là việc dạy một tác nhân (trong trường hợp này là một LLM) đưa ra các quyết định tốt hơn bằng cách cung cấp phản hồi về các hành động của nó. Hãy nghĩ về nó như việc huấn luyện một người chơi cờ vua. Thay vì chỉ cho họ mọi nước đi có thể trong mọi tình huống (điều không thể), bạn để họ chơi và cho họ biết những nước đi nào dẫn đến vị trí thắng. Theo thời gian, người chơi học cách nhận ra các mẫu và đưa ra các quyết định chiến lược dẫn đến thành công. Đối với LLM, mô hình tạo ra nhiều phản hồi khả thi cho một prompt nhất định, nhận điểm (thưởng) cho mỗi phản hồi dựa trên mức độ đáp ứng tiêu chí của bạn, và học cách ưu tiên các mẫu và chiến lược tạo ra các đầu ra có điểm cao hơn.
Các thành phần chính của RFT
Các thành phần RFT chính bao gồm mô hình tác nhân/diễn viên (policy), trạng thái đầu vào cho mô hình, hành động đầu ra từ mô hình và hàm thưởng như được hiển thị trong sơ đồ sau:
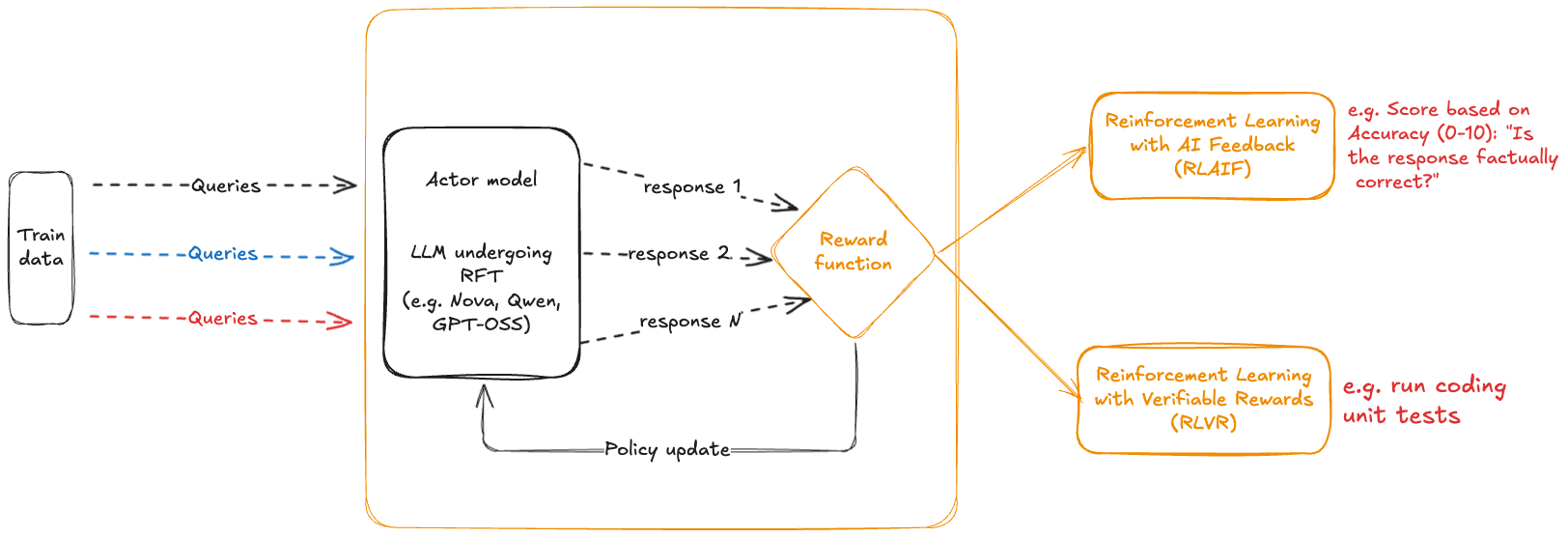
Mô hình tác nhân là mô hình nền tảng (FM) mà bạn đang tùy chỉnh. Trong Amazon Bedrock RFT, đây có thể là Amazon Nova, Llama, Qwen hoặc các mô hình được hỗ trợ khác. Trạng thái là ngữ cảnh hiện tại, bao gồm prompt, lịch sử hội thoại (đối với các tương tác đa lượt) và siêu dữ liệu liên quan. Hành động là phản hồi của mô hình đối với một prompt. Hàm thưởng gán một điểm số số học cho một cặp (trạng thái, hành động), đánh giá mức độ tốt của một phản hồi mô hình cho một trạng thái nhất định. Khi làm như vậy, hàm thưởng có thể sử dụng thông tin bổ sung như phản hồi ground truth hoặc kiểm thử đơn vị cho việc tạo mã. Đây là tín hiệu phản hồi quan trọng thúc đẩy quá trình học. Phần thưởng cao hơn cho thấy phản hồi tốt hơn.
Một trong những lợi thế chính của RFT là mô hình học hỏi từ các phản hồi mà nó tạo ra trong quá trình huấn luyện, không chỉ từ các ví dụ đã được thu thập trước. Cách tiếp cận này mở ra một số lợi ích tổng hợp. Bởi vì mô hình tích cực khám phá các cách tiếp cận mới và học hỏi từ kết quả, nó có thể thích ứng trong thời gian thực: khi nó cải thiện, nó tự nhiên gặp phải các kịch bản mới đẩy nó đi xa hơn. Điều này cũng làm cho quá trình hiệu quả hơn nhiều, giảm bớt nhu cầu tạo trước và gắn nhãn hàng nghìn ví dụ. Kết quả là một hệ thống có khả năng cải tiến liên tục, trở nên mạnh mẽ hơn khi nó gặp phải một loạt các tình huống đa dạng hơn. Khả năng học trực tuyến này là điều cho phép RFT đạt được hiệu suất vượt trội trong các tác vụ phức tạp như tạo mã, suy luận toán học và hội thoại đa lượt. Đối với các tác vụ có thể kiểm chứng như toán học, điều này đặc biệt hiệu quả vì việc kiểm tra tính đúng đắn hoàn toàn tự động – tránh nhu cầu gắn nhãn thủ công.
Cách Amazon Bedrock RFT hoạt động
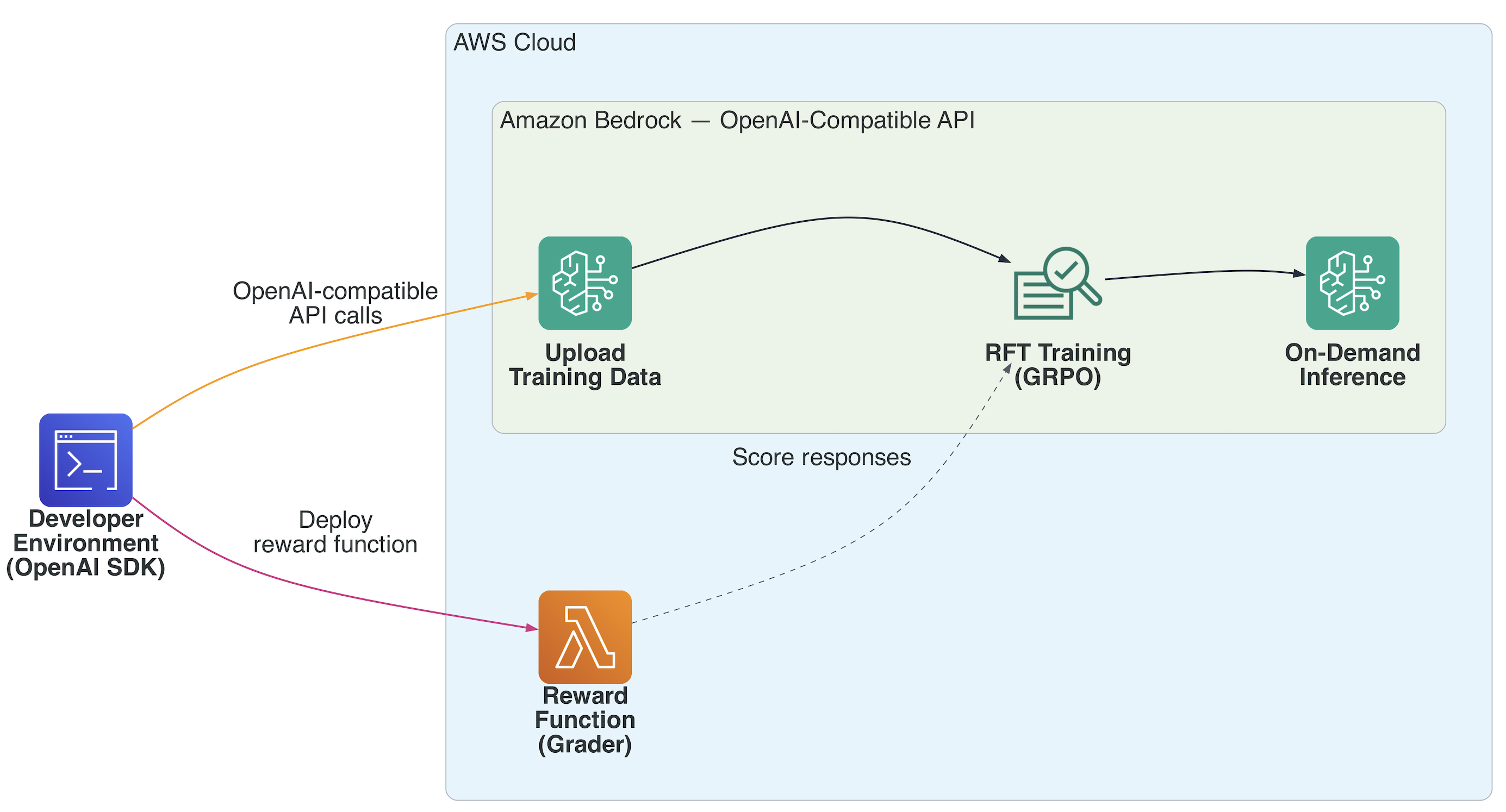
Amazon Bedrock RFT được xây dựng để làm cho Reinforcement fine-tuning trở nên thực tế ở cấp độ doanh nghiệp. Nó xử lý các công việc nặng nhọc, vì vậy các nhóm có thể tập trung vào vấn đề mà họ đang giải quyết thay vì cơ sở hạ tầng bên dưới. Toàn bộ pipeline RFT chạy tự động. Đối với mỗi prompt trong tập dữ liệu huấn luyện của bạn, Amazon Bedrock tạo ra nhiều phản hồi ứng viên từ mô hình tác nhân của bạn, quản lý việc phân lô, song song hóa và phân bổ tài nguyên một cách tự động. Tính toán phần thưởng cũng mở rộng liền mạch. Cho dù bạn đang sử dụng phần thưởng có thể kiểm chứng hay thiết lập LLM-as-Judge, Amazon Bedrock điều phối đánh giá trên hàng nghìn cặp prompt-phản hồi trong khi xử lý đồng thời và phục hồi lỗi mà không cần can thiệp thủ công. Tối ưu hóa chính sách chạy trên GRPO, một thuật toán học tăng cường tiên tiến, với tính năng phát hiện hội tụ tích hợp để quá trình huấn luyện dừng lại khi cần. Trong suốt quá trình, các chỉ số Amazon CloudWatch và bảng điều khiển Amazon Bedrock cung cấp cho bạn khả năng hiển thị theo thời gian thực về xu hướng phần thưởng, cập nhật chính sách và hiệu suất mô hình tổng thể, để bạn có thể biết quá trình huấn luyện đang ở đâu. Quy trình làm việc bắt đầu từ môi trường phát triển của bạn (VS Code, Terminal, Jupyter hoặc SageMaker AI notebook) bằng cách sử dụng OpenAI SDK tiêu chuẩn được trỏ đến endpoint Mantle của Bedrock. Từ đó:
- Tải dữ liệu huấn luyện lên qua Files API (định dạng jsonl với messages và reference answers)
- Triển khai hàm thưởng dưới dạng một AWS Lambda để chấm điểm các phản hồi do mô hình tạo ra
- Tạo tác vụ fine-tuning — engine GRPO của Bedrock tạo ra các phản hồi, gửi chúng đến bộ chấm điểm Lambda của bạn và cập nhật trọng số dựa trên điểm thưởng
- Giám sát quá trình huấn luyện qua các sự kiện và checkpoint
- Gọi mô hình đã được fine-tune của bạn theo yêu cầu — không cần cung cấp endpoint, không cần hosting.
Dữ liệu của bạn không rời khỏi môi trường bảo mật của AWS trong suốt quá trình và không được sử dụng để huấn luyện các mô hình do Amazon Bedrock cung cấp. Ở đây, chúng tôi sẽ hướng dẫn bạn một trường hợp sử dụng cụ thể về việc huấn luyện mô hình OpenAI GPT-OSS với tập dữ liệu GSM8K. Để biết thêm chi tiết, hãy xem Hướng dẫn sử dụng Bedrock RFT.
Điều kiện tiên quyết
Trước khi bạn có thể bắt đầu, bạn cần:
- Một tài khoản AWS có quyền truy cập Amazon Bedrock trong một AWS Region được hỗ trợ
- Một khóa API Bedrock (ngắn hạn hoặc dài hạn). Bạn cũng có thể xác thực bằng thông tin đăng nhập AWS Sigv4 nhưng trong hướng dẫn này, chúng tôi sử dụng Khóa API Amazon Bedrock. Để biết thêm thông tin, hãy xem Truy cập và bảo mật cho các mô hình mã nguồn mở trong Hướng dẫn sử dụng Amazon Bedrock.
- Các IAM role cho việc thực thi Lambda và fine-tuning Amazon Bedrock
- Python với
openai,boto3, vàaws-bedrock-token-generatorđã được cài đặt. Nếu bạn đang làm việc trên shell bên trong venv, hoặc với Jupyter notebook, bạn có thể làm:
pip install openai boto3 aws-bedrock-token-generator
Bước 1: Cấu hình client OpenAI
Trỏ OpenAI SDK tiêu chuẩn đến endpoint Amazon Bedrock Mantle của bạn. Xác thực sử dụng khóa API AmazonBedrock được tạo thông qua thư viện aws-bedrock-token-generator:
from openai import OpenAIfrom aws_bedrock_token_generator import provide_tokenAWS_REGION = "us-west-2"MANTLE_ENDPOINT = f"https://bedrock-mantle.{AWS_REGION}.api.aws"client = OpenAI( base_url=f"{MANTLE_ENDPOINT}/v1", api_key=provide_token(region=AWS_REGION),)
Vậy là xong. Mọi lệnh gọi tiếp theo đều sử dụng giao diện OpenAI SDK tiêu chuẩn! Lưu ý: Chúng tôi khuyên bạn nên sử dụng và làm mới các khóa Amazon Bedrock ngắn hạn khi cần thay vì thiết lập và sử dụng các khóa dài hạn không hết hạn.
Bước 2: Chuẩn bị và tải dữ liệu huấn luyện lên
Mỗi bản ghi trong tập dữ liệu yêu cầu một trường messages và có thể tùy chọn bao gồm một trường reference_answer. Trường messages chứa prompt được trình bày cho mô hình, được định dạng bằng tiêu chuẩn tin nhắn OpenAI, trong đó mỗi tin nhắn chỉ định một vai trò (chẳng hạn như “user”) và nội dung tương ứng. Trường reference_answer tùy chọn cung cấp ngữ cảnh bổ sung cho việc tính toán phần thưởng, chẳng hạn như câu trả lời ground-truth, quy tắc đánh giá hoặc các chiều chấm điểm được sử dụng bởi hàm thưởng.
Đối với các ví dụ GSM8K, mỗi mẫu huấn luyện chứa một bài toán đố toán học trong tin nhắn người dùng và một câu trả lời tham chiếu chứa giải pháp số chính xác. Prompt hướng dẫn mô hình cung cấp lý luận của nó trong các thẻ có cấu trúc và trình bày câu trả lời cuối cùng ở định dạng \boxed{} mà hàm thưởng có thể trích xuất một cách đáng tin cậy, như trong ví dụ sau:
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "A chat between a curious User and an artificial intelligence Bot.
The Bot gives helpful, detailed, and polite answers to the User's questions.
The Bot first thinks about the reasoning process and then provides the User with the answer.
The reasoning process and answer are enclosed within <|begin_internal_thought|> <|end_internal_thought|>
and <|begin_of_solution|> <|end_of_solution|> respectively. The final answer must be enclosed
in \\boxed{} within the solution block.\n\nNatalia sold clips to 48 of her friends in April, and then
she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?"
}
]
}
],
"reference_answer": {
"answer": "72"
},
"data_source": "gsm8k_nova"
}Chúng tôi cung cấp một hàm trợ giúp để chuyển đổi các bản ghi GSM8K thô sang định dạng JSONL tương thích với Amazon Bedrock RFT trong kho lưu trữ GitHub này.
Lưu ý rằng trường data_source đảm bảo rằng hàm thưởng thích hợp được áp dụng trong quá trình huấn luyện trong khi các định dạng prompt có cấu trúc căn chỉnh đầu ra với logic trích xuất của hàm thưởng.
Như đã đề cập trước đó, dữ liệu huấn luyện là một tệp JSONL trong đó mỗi dòng chứa một cuộc hội thoại với các tin nhắn và một câu trả lời tham chiếu. Đối với GSM8K, nó trông như thế này:
{ "messages": [ {"role": "user", "content": "Janet's ducks lay 16 eggs per day. She eats three for breakfast and bakes muffins with four. She sells the rest at $2 each. How much does she make daily? Let's think step by step and output the final answer after '####'."} ], "reference_answer": "#### 18"}
Bạn có thể sử dụng các trường bổ sung ở đây có thể hữu ích cho hàm Lambda grader của bạn trong bước chúng ta sẽ thấy sau, nhưng lưu ý rằng cấu trúc messages và reference_answer là bắt buộc.
Sau đó, chúng ta có thể tải tập dữ liệu đã chuẩn bị của mình lên qua Files API:
with open("rft_train_data.jsonl", "rb") as f: file_response = client.files.create(file=f, purpose="fine-tune")training_file_id = file_response.idprint(f"Training file uploaded: {training_file_id}")
Bước 3: Triển khai hàm thưởng Lambda
Hàm thưởng là cốt lõi của RFT. Nó nhận các phản hồi do mô hình tạo ra và trả về một điểm số. Đối với các bài toán toán học, điều này khá đơn giản: trích xuất câu trả lời và so sánh nó với ground truth.
Đây là hàm thưởng được sử dụng trong hướng dẫn này (từ kho lưu trữ mẫu):
def lambda_handler(event, context): trajectories = event if isinstance(event, list) else event.get("trajectories", []) scores = [] for trajectory in trajectories: trajectory_id = trajectory.get("id", "no-id") # Get the model's response from the last assistant message response = "" for msg in reversed(trajectory.get("messages", [])): if msg.get("role") == "assistant": response = msg.get("content", "") break # Extract ground truth from reference answer reference_answer = trajectory.get("reference_answer", {}) reference_text = reference_answer.get("text", "") gt_match = re.findall(r"#### (\-?[0-9\.\,]+)", reference_text) ground_truth = gt_match[-1].replace(",", "") if gt_match else "" # Score: 1.0 if correct, 0.0 otherwise result = compute_score( trajectory_id=trajectory_id, solution_str=response, ground_truth=ground_truth, ) scores.append(asdict(result)) return scores
Hàm này trả về một danh sách các đối tượng RewardOutput, mỗi đối tượng chứa một aggregate_reward_score nằm trong khoảng từ 0 đến 1. Triển khai hàm này dưới dạng một hàm AWS Lambda với thời gian chờ 5 phút và bộ nhớ 512 MB. Lưu ý rằng bạn có thể hoàn toàn tùy chỉnh những gì xảy ra bên trong hàm Lambda thưởng này để phù hợp với trường hợp sử dụng của bạn. Amazon Bedrock cũng hỗ trợ các bộ chấm điểm model-as-a-judge cho các tác vụ chủ quan mà việc xác minh tự động không thể thực hiện được. Để biết thêm thông tin về cách thiết lập hàm thưởng, hãy xem Thiết lập hàm thưởng cho các mô hình mã nguồn mở.
Bước 4: Tạo tác vụ fine-tuning
Bây giờ chúng ta sử dụng lệnh gọi API duy nhất sau đây để bắt đầu tác vụ:
job_response = client.fine_tuning.jobs.create( model="openai.gpt-oss-20b", training_file=training_file_id, extra_body={ "method": { "type": "reinforcement", "reinforcement": { "grader": { "type": "lambda", "lambda": { "function": lambda_arn # Replace with reward function Arn } }, "hyperparameters": { "n_epochs": 1, "batch_size": 4, "learning_rate_multiplier": 1.0 } } } })job_id = job_response.id
Lưu ý rằng lệnh gọi tạo cho tác vụ fine-tuning trước đó sử dụng các siêu tham số sau:
| Tham số | Mô tả |
|---|---|
n_epochs | Số lần chạy đầy đủ qua dữ liệu huấn luyện. Bắt đầu với 1. |
batch_size | Số prompt mỗi bước huấn luyện. Lớn hơn = cập nhật ổn định hơn. |
learning_rate_multiplier | Chúng tôi khuyên bạn nên sử dụng giá trị <1.0 để đảm bảo sự ổn định. |
Bước 5: Giám sát quá trình huấn luyện
Để theo dõi tiến độ của tác vụ, chúng ta sử dụng API liệt kê sự kiện như sau:
events = client.fine_tuning.jobs.list_events( fine_tuning_job_id=job_id, limit=100)
Đối với một tác vụ ví dụ GPT-OSS sử dụng tập con dữ liệu GSM8K, quá trình huấn luyện chạy tổng cộng 67 bước với nhiều sự kiện khác nhau được phát ra khi tác vụ huấn luyện tiến triển. Dưới đây là dòng thời gian của các bước này:
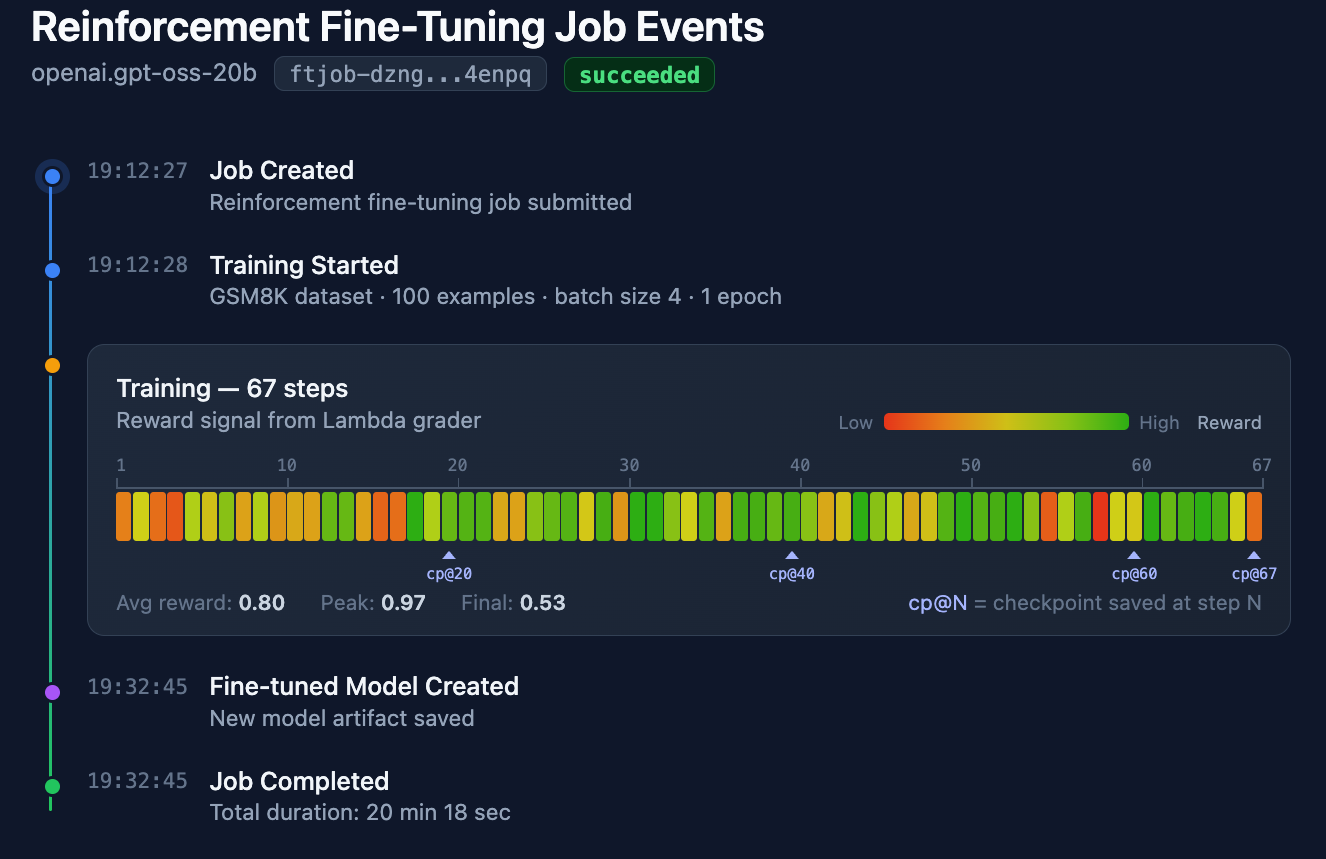
Bây giờ hãy phân tích một trong những sự kiện này trong quá trình huấn luyện:
{ "id": "ftevent-c3c14785-4a3b-4dab-99a5-a15aeb6c0742", "created_at": 1771442218, "level": "info", "message": "Step 4/67: training metrics", "object": "fine_tuning.job.event", "data": { "total_steps": 67, "actor_grad_norm": 0.0008667297661304474, "response_length_mean": 519.09375, "step": 4, "actor_pg_loss": 0.10153239965438844, "critic_rewards_mean": 0.4375, "actor_entropy": 0.6235736012458801, "critic_advantages_mean": 0.013622610829770563 }, "type": "metrics"}
Hãy cùng thảo luận ý nghĩa của chúng:
| Chỉ số | Ý nghĩa |
|---|---|
| step / total_steps | Bước huấn luyện hiện tại / tổng số bước |
| critic_rewards_mean | Điểm thưởng trung bình trên batch (0.4375 có nghĩa là khoảng 44% phản hồi nhận được câu trả lời đúng từ bộ chấm điểm của bạn). Đây là chỉ số chính cần theo dõi — bạn muốn nó có xu hướng tăng lên. |
| actor_pg_loss | Policy gradient loss. Đây là mục tiêu đang được tối ưu hóa — mức độ chính sách của mô hình đang được đẩy về phía các phản hồi có phần thưởng cao hơn. Biến động tự nhiên; không có giá trị “tốt” duy nhất. |
| actor_entropy | Mức độ phân bố xác suất token của mô hình. Cao hơn = đầu ra khám phá/đa dạng hơn. Nếu nó sụp đổ về 0, mô hình đang trở nên quá xác định (mode collapse). Bạn muốn nó giảm dần, không sụp đổ đột ngột. |
| actor_grad_norm | Độ lớn của cập nhật gradient cho actor (mô hình). Các đỉnh lớn có thể cho thấy sự không ổn định trong huấn luyện. Giá trị của bạn rất nhỏ (0.0009), cho thấy các cập nhật ổn định, thận trọng. |
| critic_advantages_mean | Ước tính lợi thế trung bình — mức độ tốt hơn/tệ hơn của một phản hồi so với dự đoán cơ sở của critic. Gần bằng 0 (0.014) có nghĩa là critic được hiệu chỉnh tốt. Giá trị dương lớn có nghĩa là mô hình đang hoạt động tốt hơn nhiều so với mong đợi; giá trị âm lớn có nghĩa là tệ hơn. |
| response_length_mean | Độ dài token trung bình của các phản hồi được tạo (519). Đáng theo dõi — nếu nó tăng không giới hạn, mô hình có thể đang gian lận độ dài để lấy phần thưởng. |
Những điều cần theo dõi trong quá trình huấn luyện:
critic_rewards_meancó xu hướng tăng = mô hình đang họcactor_entropysụp đổ về 0 = mode collapse (xấu)actor_grad_normtăng đột biến = không ổn địnhresponse_length_meanbùng nổ = gian lận phần thưởng?
Mã mẫu cũng cung cấp một ví dụ về cách vẽ biểu đồ các chỉ số này.
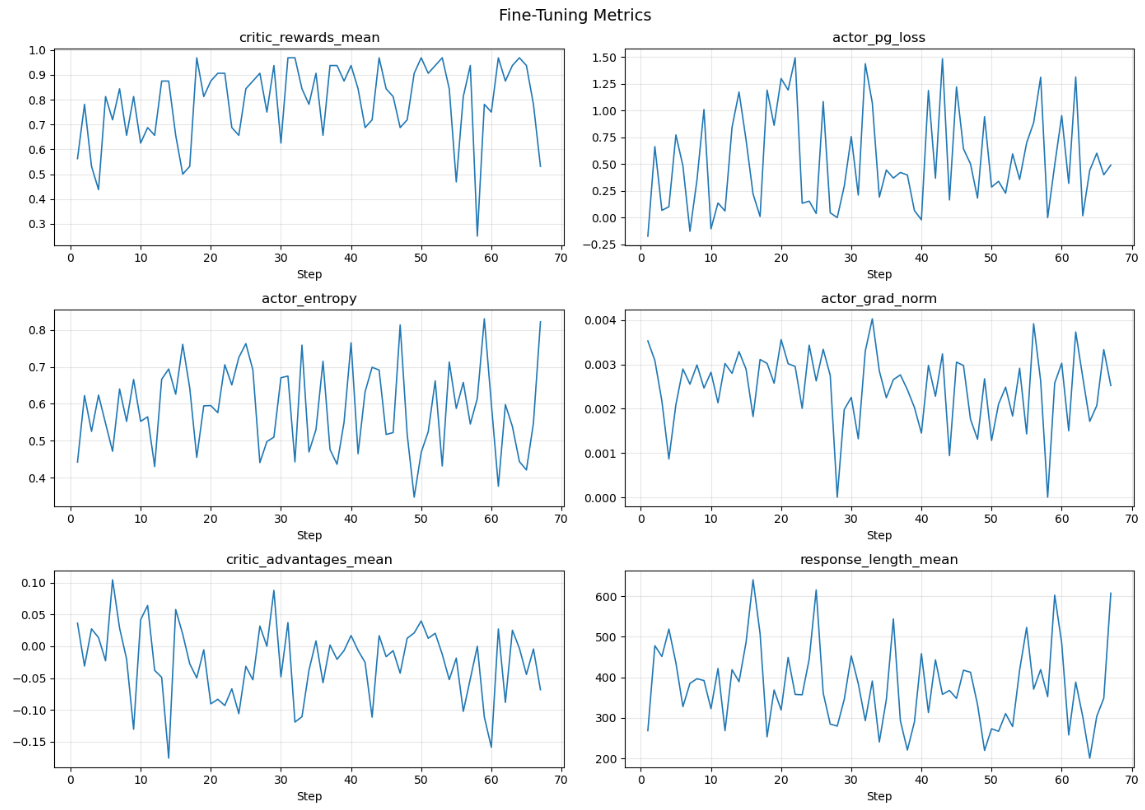
Đường cong phần thưởng cho thấy mô hình cải thiện từ ~0.56 lên mức ổn định 0.85–0.97 vào giữa quá trình huấn luyện. Độ dài phản hồi cũng có xu hướng ngắn hơn theo thời gian, cho thấy mô hình đã học cách súc tích hơn trong khi giải quyết các bài toán GSM8K một cách chính xác. Dưới đây là danh sách các checkpoint khi chúng được lưu:
checkpoints = client.fine_tuning.jobs.checkpoints.list( fine_tuning_job_id=job_id)
Bước 6: Chạy suy luận theo yêu cầu
Sau khi tác vụ thành công, hãy gọi trực tiếp mô hình đã được fine-tune của bạn. Không cần cung cấp endpoint, không cần hosting:
job_details = client.fine_tuning.jobs.retrieve(job_id)fine_tuned_model = job_details.fine_tuned_modelresponse = client.chat.completions.create( model=fine_tuned_model, messages=[ {"role": "user", "content": "If a train travels 120 miles in 2 hours, what is its speed in miles per hour?"} ],)print(response.choices[0].message.content)
Bạn cũng có thể sử dụng API responses để truyền phát phản hồi từ mô hình đã được fine-tune:
stream = client.responses.create( model=fine_tuned_model, input=[{"role": "user", "content": "Your prompt here"}], stream=True, reasoning={"effort": "low"})for event in stream: if event.type == "response.output_text.delta": print(event.delta, end="", flush=True)
Kết luận
Reinforcement fine-tuning trên Amazon Bedrock kết hợp ba yếu tố giúp quy trình làm việc từ đầu đến cuối trở nên thực tế:
- Khả năng tương thích với OpenAI SDK — không cần học SDK mới. Trỏ
OPENAI_BASE_URLvàOPENAI_API_KEYđến Bedrock và sử dụng các lệnh gọiclient.fine_tuning.jobs.create()tương tự. - Hàm thưởng dựa trên Lambda — viết logic chấm điểm của bạn bằng Python, triển khai dưới dạng Lambda và Amazon Bedrock sẽ xử lý vòng lặp huấn luyện (GRPO) cho bạn.
- Suy luận theo yêu cầu — không cần quản lý endpoint. Gọi
client.chat.completions.create()với ID mô hình đã được fine-tune của bạn và trả tiền theo token.
Notebook đầy đủ với mã từ đầu đến cuối cho cả GPT-OSS 20B và Qwen3 32B có sẵn trên GitHub:
Để biết thêm chi tiết, hãy xem tài liệu Amazon Bedrock Reinforcement Fine-Tuning.
Về tác giả

Shreyas Subramanian là một Principal Data Scientist và giúp khách hàng giải quyết các thách thức kinh doanh bằng cách sử dụng Generative AI và deep learning với các dịch vụ AWS như Amazon Bedrock và AgentCore. Tiến sĩ Subramanian đóng góp vào nghiên cứu tiên tiến về deep learning, Agentic AI, các mô hình nền tảng và kỹ thuật tối ưu hóa với nhiều sách, bài báo và bằng sáng chế mang tên ông. Trong vai trò hiện tại tại Amazon, Tiến sĩ Subramanian làm việc với nhiều nhà lãnh đạo khoa học và nhóm nghiên cứu trong và ngoài Amazon, giúp hướng dẫn khách hàng tận dụng tốt nhất các thuật toán và kỹ thuật tiên tiến để giải quyết các vấn đề kinh doanh quan trọng. Ngoài AWS, Tiến sĩ Subramanian là một chuyên gia đánh giá các bài báo và tài trợ về AI thông qua các tổ chức như Neurips, ICML, ICLR, NASA và NSF.

Nick McCarthy là Kiến trúc sư Giải pháp Chuyên gia AI tạo sinh cấp cao trong nhóm Amazon Bedrock, làm việc tại văn phòng AWS New York. Anh ấy giúp khách hàng tùy chỉnh các mô hình GenAI của họ trên AWS. Anh ấy đã làm việc với các khách hàng trong nhiều ngành khác nhau – bao gồm chăm sóc sức khỏe, tài chính, thể thao, viễn thông và năng lượng – giúp họ đẩy nhanh kết quả kinh doanh thông qua việc sử dụng AI và machine learning. Anh ấy có bằng Cử nhân Vật lý và bằng Thạc sĩ Machine Learning từ UCL, London.

Shreeya Sharma là Giám đốc Sản phẩm Kỹ thuật cấp cao tại AWS, nơi cô đã và đang làm việc để tận dụng sức mạnh của AI tạo sinh nhằm cung cấp các sản phẩm sáng tạo và lấy khách hàng làm trung tâm. Shreeya có bằng thạc sĩ từ Đại học Duke. Ngoài công việc, cô ấy thích đi du lịch, nhảy múa và ca hát.

Shalendra Chhabra hiện là Trưởng nhóm Sản phẩm tại Bedrock. Trước đây, ông là Trưởng phòng Quản lý Sản phẩm cho các Dịch vụ Human-in-the-Loop (HIL) của Amazon SageMaker. Trước đó, Shalendra đã ươm tạo và lãnh đạo Language and Conversational Intelligence cho Microsoft Teams Meetings, là EIR tại Amazon Alexa Techstars Startup Accelerator, Phó Chủ tịch Sản phẩm và Tiếp thị tại Discuss.io, Trưởng phòng Sản phẩm và Tiếp thị tại Clipboard (được Salesforce mua lại), và Trưởng phòng Quản lý Sản phẩm tại Swype (được Nuance mua lại). Tổng cộng, Shalendra đã giúp xây dựng, vận chuyển và tiếp thị các sản phẩm đã tiếp cận hơn một tỷ người.
