Tác giả: Hazim Qudah
Ngày phát hành: 26 MAR 2026
Chuyên mục: Advanced (300), Amazon SageMaker, Amazon SageMaker Unified Studio, Amazon Simple Storage Service (S3), Artificial Intelligence, Technical How-to
Năm ngoái, AWS đã công bố một tích hợp giữa Amazon SageMaker Unified Studio và các bucket đa năng của Amazon S3. Tích hợp này giúp các nhóm dễ dàng sử dụng dữ liệu phi cấu trúc được lưu trữ trong Amazon Simple Storage Service (Amazon S3) cho các trường hợp sử dụng học máy (ML) và phân tích dữ liệu.
Trong bài đăng này, chúng tôi sẽ trình bày cách tích hợp các bucket đa năng của S3 với Amazon SageMaker Catalog để tinh chỉnh Llama 3.2 11B Vision Instruct cho tác vụ trả lời câu hỏi bằng hình ảnh (VQA) bằng cách sử dụng Amazon SageMaker Unified Studio. Đối với tác vụ này, chúng tôi cung cấp cho mô hình ngôn ngữ lớn (LLM) của mình một hình ảnh đầu vào và câu hỏi, sau đó nhận được câu trả lời. Ví dụ, yêu cầu xác định ngày giao dịch từ một hóa đơn chi tiết:
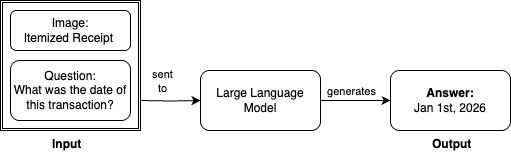
Để minh họa này, chúng tôi sử dụng Amazon SageMaker JumpStart để truy cập mô hình Llama 3.2 11B Vision Instruct. Ngay từ đầu, mô hình cơ sở này đạt được điểm Average Normalized Levenshtein Similarity (ANLS) là 85.3% trên bộ dữ liệu DocVQA. ANLS là một chỉ số được sử dụng để đánh giá hiệu suất của các mô hình trong các tác vụ trả lời câu hỏi bằng hình ảnh, đo lường sự tương đồng giữa câu trả lời dự đoán của mô hình và câu trả lời đúng. Mặc dù 85.3% cho thấy hiệu suất cơ bản mạnh mẽ, mức độ này có thể không hiệu quả nhất cho các tác vụ yêu cầu độ chính xác và tỉ mỉ cao hơn.
Để cải thiện hiệu suất mô hình thông qua tinh chỉnh, chúng tôi sẽ sử dụng bộ dữ liệu DocVQA từ Hugging Face. Bộ dữ liệu này chứa 39.500 hàng dữ liệu huấn luyện, mỗi hàng có một hình ảnh đầu vào, một câu hỏi và một câu trả lời dự kiến tương ứng. Chúng tôi sẽ tạo ba phiên bản mô hình được tinh chỉnh bằng cách sử dụng các kích thước bộ dữ liệu khác nhau (1.000, 5.000 và 10.000 hình ảnh). Sau đó, chúng tôi sẽ đánh giá chúng bằng cách sử dụng Amazon SageMaker MLflow serverless được quản lý hoàn toàn để theo dõi thử nghiệm và đo lường các cải thiện về độ chính xác.
Toàn bộ quá trình nhập dữ liệu, phát triển mô hình và đánh giá chỉ số từ đầu đến cuối sẽ được điều phối bằng Amazon SageMaker Unified Studio. Dưới đây là sơ đồ luồng quy trình cấp cao mà chúng tôi sẽ thực hiện cho kịch bản này. Chúng tôi sẽ mở rộng về điều này trong suốt bài đăng trên blog.
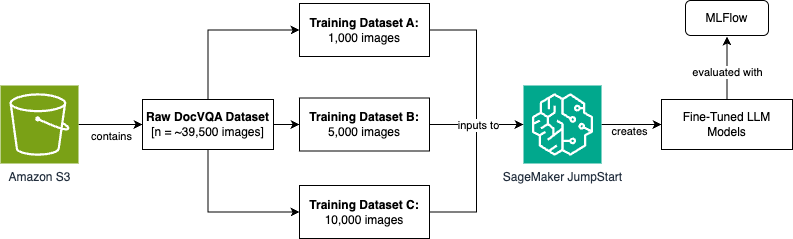
Để đạt được luồng quy trình này, chúng tôi xây dựng một kiến trúc thực hiện việc nhập dữ liệu, tiền xử lý dữ liệu, huấn luyện mô hình và đánh giá bằng Amazon SageMaker Unified Studio. Chúng tôi sẽ chia nhỏ từng bước trong các phần sau.
Jupyter notebook được sử dụng và tham chiếu trong suốt bài tập này có thể được tìm thấy trong kho lưu trữ GitHub này.
Điều kiện tiên quyết
Để chuẩn bị cho tổ chức của bạn sử dụng tích hợp mới giữa Amazon SageMaker Unified Studio và các bucket đa năng của Amazon S3, bạn phải hoàn thành các điều kiện tiên quyết sau. Lưu ý rằng các bước này diễn ra trên một miền dựa trên Identity Center.
- Tạo một tài khoản AWS.
- Tạo một miền Amazon SageMaker Unified Studio bằng cách sử dụng thiết lập nhanh.
- Tạo hai dự án trong miền SageMaker Unified Studio để mô hình hóa kịch bản trong bài đăng này: một cho vai trò nhà sản xuất dữ liệu và một cho vai trò người tiêu dùng dữ liệu. Dự án đầu tiên được sử dụng để khám phá và lập danh mục bộ dữ liệu trong một bucket Amazon S3. Dự án thứ hai tiêu thụ bộ dữ liệu để tinh chỉnh ba lần lặp của mô hình ngôn ngữ lớn của chúng tôi. Xem Tạo một dự án để biết thêm thông tin.
- Dự án người tiêu dùng dữ liệu của bạn phải có quyền truy cập vào một ứng dụng MLflow serverless được quản lý bởi SageMaker đang chạy, ứng dụng này sẽ được sử dụng cho mục đích thử nghiệm và đánh giá. Để biết thêm thông tin, hãy xem hướng dẫn tạo một ứng dụng MLflow serverless.
- Một bucket Amazon S3 nên được điền sẵn với bộ dữ liệu thô sẽ được sử dụng cho trường hợp sử dụng phát triển ML của bạn. Trong bài đăng trên blog này, chúng tôi sử dụng bộ dữ liệu DocVQA từ Hugging Face để tinh chỉnh một trường hợp sử dụng trả lời câu hỏi bằng hình ảnh (VQA).
- Yêu cầu tăng hạn mức dịch vụ để sử dụng tính toán p4de.24xlarge cho các công việc huấn luyện. Xem Yêu cầu tăng hạn mức để biết thêm thông tin.
Kiến trúc
Sau đây là kiến trúc tham chiếu mà chúng tôi xây dựng trong suốt bài đăng này:
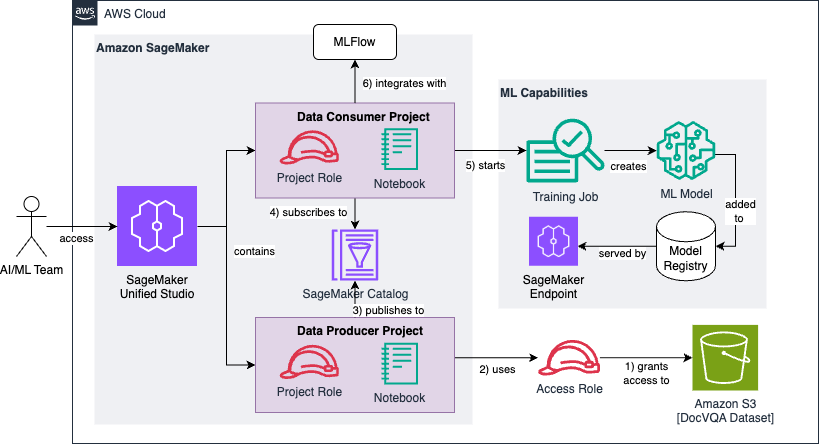
Chúng ta có thể chia sơ đồ kiến trúc thành một chuỗi sáu bước cấp cao, mà chúng ta sẽ quan sát trong các phần sau:
- Đầu tiên, bạn tạo và cấu hình một vai trò truy cập IAM cấp quyền đọc cho một bucket Amazon S3 đã tồn tại chứa bộ dữ liệu DocVQA thô và chưa được xử lý.
- Dự án nhà sản xuất dữ liệu sử dụng vai trò truy cập để khám phá và thêm bộ dữ liệu vào danh mục dự án.
- Dự án nhà sản xuất dữ liệu làm giàu bộ dữ liệu với siêu dữ liệu tùy chọn và xuất bản nó lên SageMaker Catalog.
- Dự án người tiêu dùng dữ liệu đăng ký bộ dữ liệu đã xuất bản, làm cho nó có sẵn cho nhóm dự án chịu trách nhiệm phát triển (hoặc tinh chỉnh) các mô hình học máy.
- Dự án người tiêu dùng dữ liệu tiền xử lý dữ liệu và chuyển đổi nó thành ba bộ dữ liệu huấn luyện với các kích thước khác nhau (1k, 5k và 10k hình ảnh). Mỗi bộ dữ liệu được sử dụng để tinh chỉnh mô hình ngôn ngữ lớn cơ sở của chúng tôi.
- Chúng tôi sử dụng MLflow để theo dõi kết quả thử nghiệm và đánh giá của ba mô hình so với chỉ số thành công Average Normalized Levenshtein Similarity (ANLS) của chúng tôi.
Hướng dẫn giải pháp
Như đã đề cập trước đó, chúng tôi sẽ chọn sử dụng bộ dữ liệu DocVQA từ Hugging Face cho tác vụ trả lời câu hỏi bằng hình ảnh. Trong kịch bản của tổ chức bạn, bộ dữ liệu thô này có thể là bất kỳ dữ liệu phi cấu trúc nào liên quan đến trường hợp sử dụng ML của bạn. Ví dụ bao gồm nhật ký trò chuyện hỗ trợ khách hàng, tài liệu nội bộ, đánh giá sản phẩm, hợp đồng pháp lý, bài báo nghiên cứu, bài đăng trên mạng xã hội, kho lưu trữ email, dữ liệu cảm biến và hồ sơ giao dịch tài chính.
Trong phần điều kiện tiên quyết của Jupyter notebook của chúng tôi, chúng tôi điền sẵn bucket Amazon S3 của mình bằng cách sử dụng Datasets API từ Hugging Face:
import osfrom datasets import load_dataset# Create data directoryos.makedirs("data", exist_ok=True)# Load and save train split (first 10,000 rows)train_data = load_dataset("HuggingFaceM4/DocumentVQA", split="train[:10000]", cache_dir="./data")train_data.save_to_disk("data/train")# Load and save validation split (first 100 rows)val_data = load_dataset("HuggingFaceM4/DocumentVQA", split="validation[:100]", cache_dir="./data")val_data.save_to_disk("data/validation")
Sau khi truy xuất bộ dữ liệu, chúng tôi hoàn thành điều kiện tiên quyết bằng cách đồng bộ hóa nó với một bucket Amazon S3. Điều này đại diện cho bucket được mô tả trong phần dưới cùng bên phải của sơ đồ kiến trúc của chúng tôi đã hiển thị trước đó.
Tại thời điểm này, chúng tôi đã sẵn sàng bắt đầu làm việc với dữ liệu của mình trong Amazon SageMaker Unified Studio, bắt đầu với dự án nhà sản xuất dữ liệu của chúng tôi. Một dự án trong Amazon SageMaker Unified Studio là một ranh giới trong một miền nơi bạn có thể cộng tác với những người khác về một trường hợp sử dụng kinh doanh. Để đưa dữ liệu Amazon S3 vào dự án của bạn, trước tiên bạn phải thêm quyền truy cập vào dữ liệu và sau đó thêm dữ liệu vào dự án của bạn. Trong bài đăng này, chúng tôi tuân theo phương pháp sử dụng vai trò truy cập để tạo điều kiện cho quá trình này. Xem Thêm dữ liệu Amazon S3 để biết thêm thông tin.
Sau khi vai trò truy cập của chúng tôi được tạo theo hướng dẫn trong tài liệu đã tham chiếu trước đó, chúng tôi có thể tiếp tục khám phá và lập danh mục bộ dữ liệu của mình. Trong dự án nhà sản xuất dữ liệu của chúng tôi, chúng tôi điều hướng đến Data → Add data → Add S3 location:
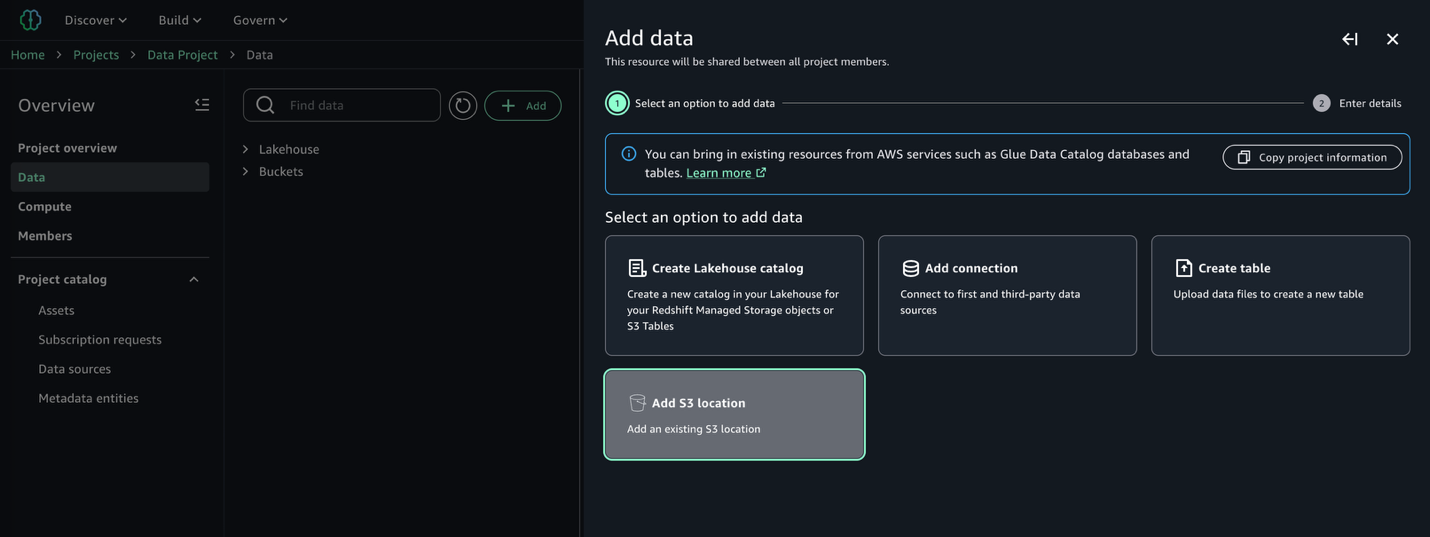
Cung cấp tên của bucket Amazon S3 và tiền tố tương ứng chứa dữ liệu thô của chúng tôi, và lưu ý sự hiện diện của menu thả xuống vai trò truy cập chứa vai trò truy cập điều kiện tiên quyết đã tạo trước đó:
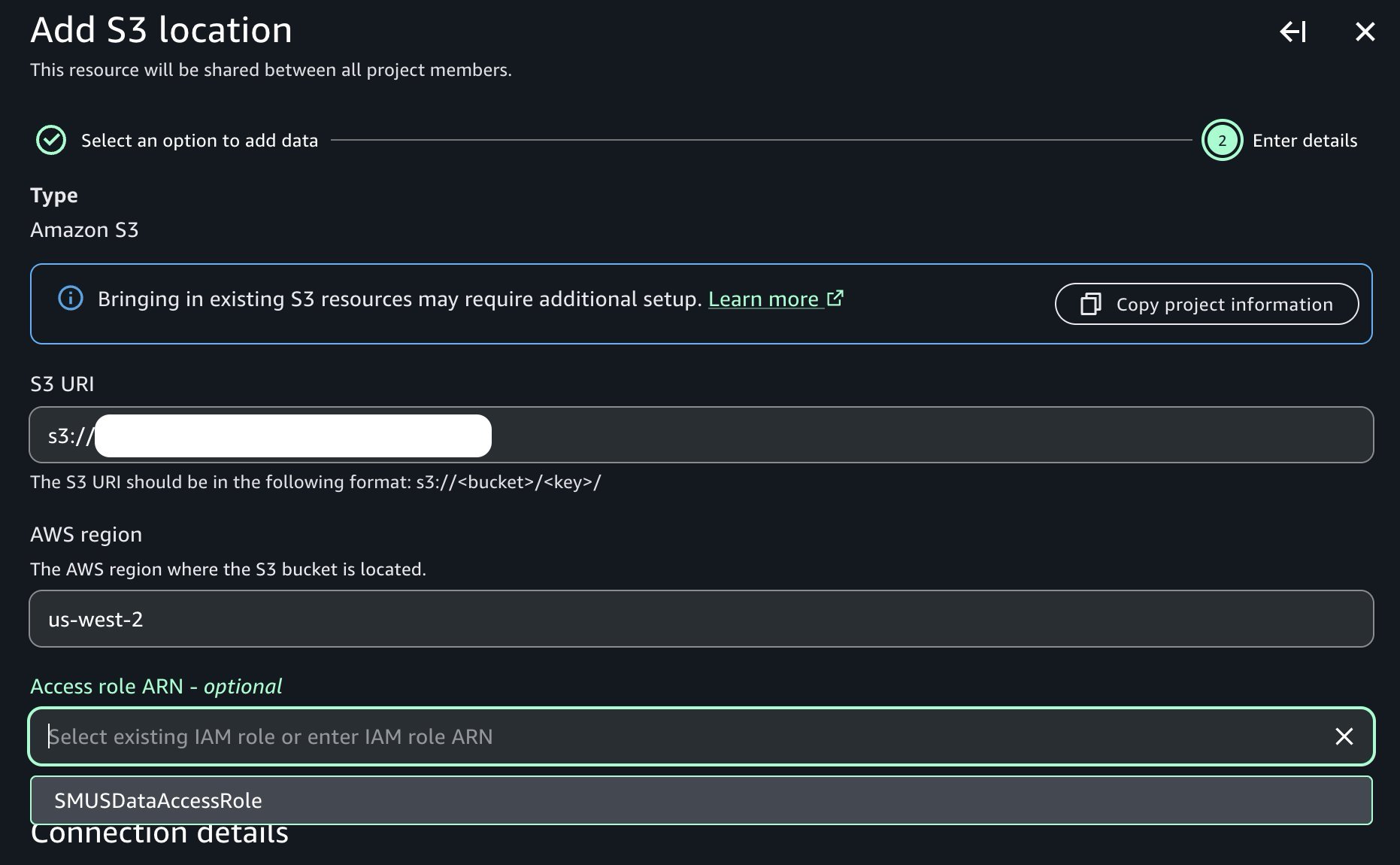
Sau khi được thêm, lưu ý rằng chúng tôi hiện có thể thấy bucket Amazon S3 mới của mình trong danh mục dự án như trong hình ảnh sau:
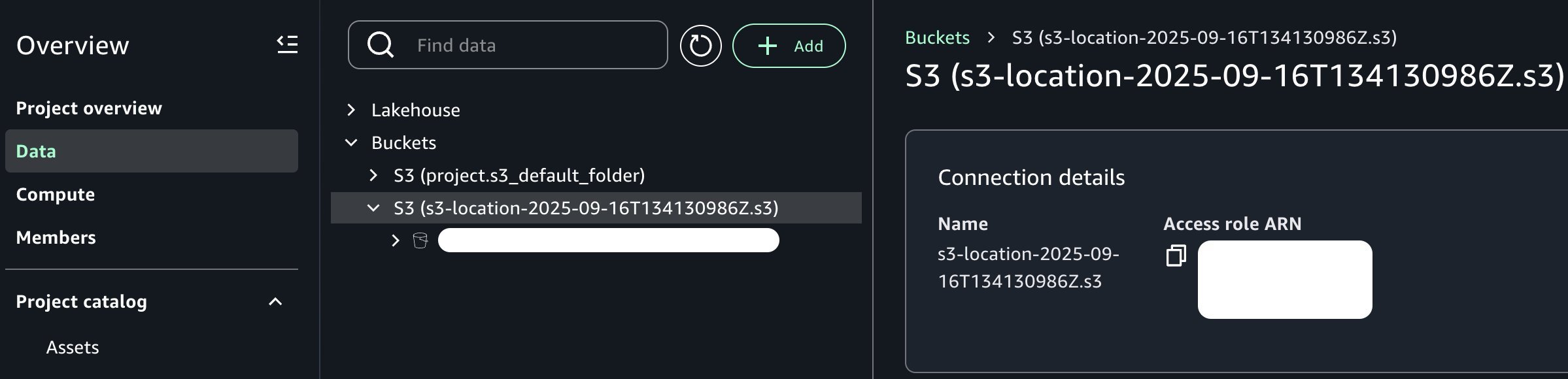
Từ góc độ của vai trò nhà sản xuất dữ liệu của chúng tôi, bộ dữ liệu hiện có sẵn trong ngữ cảnh dự án của chúng tôi. Tùy thuộc vào tổ chức và yêu cầu của bạn, bạn có thể muốn làm giàu thêm tài sản dữ liệu này. Ví dụ, bạn có thể kết hợp nó với các nguồn dữ liệu bổ sung, áp dụng các phép biến đổi dành riêng cho doanh nghiệp, triển khai kiểm tra chất lượng dữ liệu hoặc tạo các tính năng phái sinh thông qua các pipeline kỹ thuật tính năng. Tuy nhiên, với mục đích của bài đăng này, chúng tôi sẽ làm việc với bộ dữ liệu ở dạng hiện tại để giữ trọng tâm vào điểm cốt lõi của việc tích hợp các bucket đa năng của Amazon S3 với Amazon SageMaker Unified Studio.
Bây giờ chúng tôi đã sẵn sàng xuất bản bucket này lên SageMaker Catalog của chúng tôi. Chúng tôi có thể thêm siêu dữ liệu kinh doanh tùy chọn như tệp README, thuật ngữ chú giải và các loại dữ liệu khác. Chúng tôi thêm một README đơn giản, bỏ qua các trường siêu dữ liệu khác để ngắn gọn, và tiếp tục xuất bản bằng cách chọn Publish to Catalog trong menu Actions.
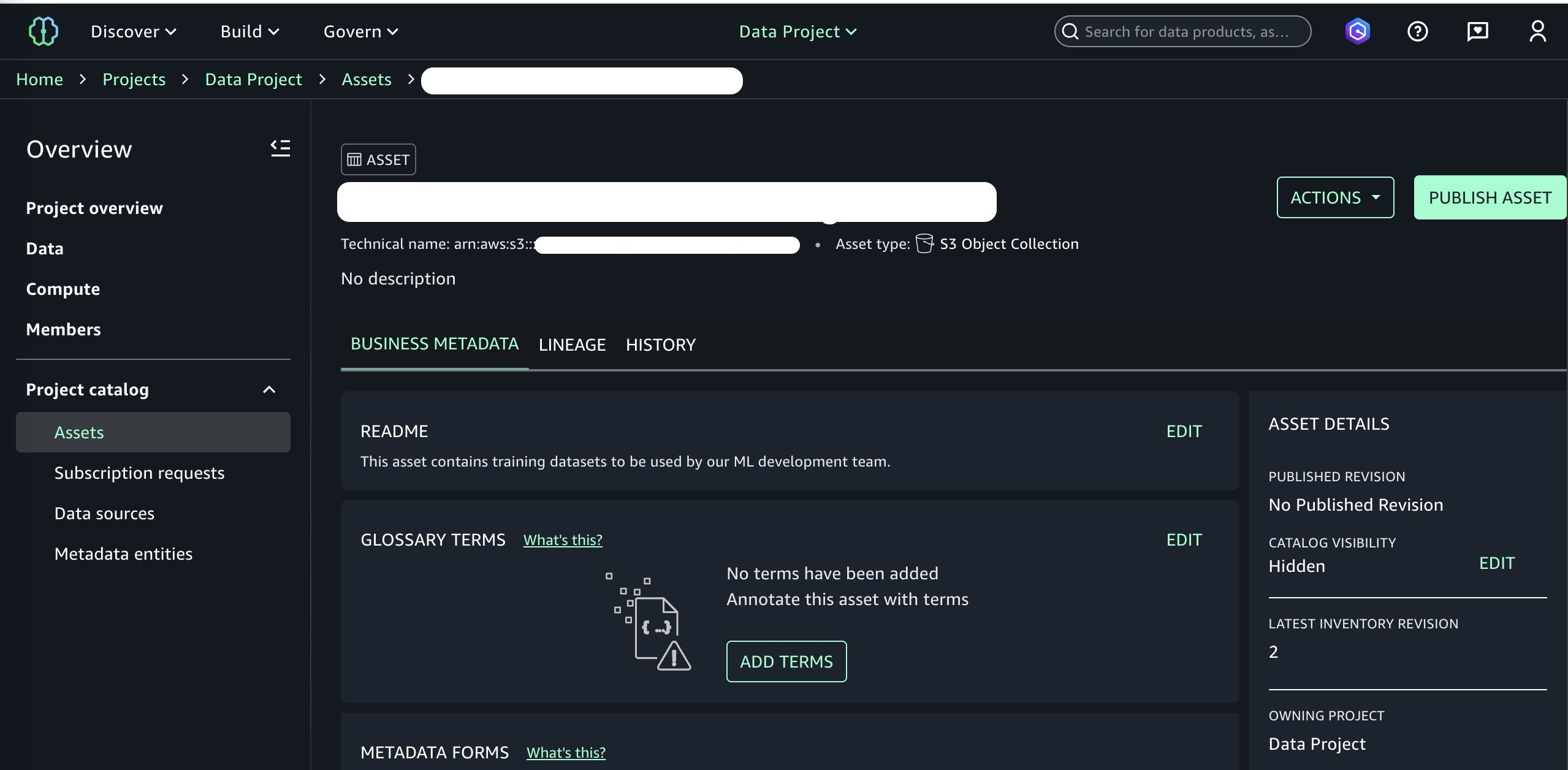
Tại thời điểm này, chúng tôi đã thêm tài sản dữ liệu vào SageMaker Catalog của mình và nó đã sẵn sàng để được tiêu thụ bởi các dự án khác trong miền của chúng tôi. Chuyển sang góc độ của vai trò người tiêu dùng dữ liệu của chúng tôi và chọn dự án người tiêu dùng, chúng tôi hiện có thể đăng ký tài sản dữ liệu mới được xuất bản của mình. Xem Đăng ký sản phẩm dữ liệu trong Amazon SageMaker Unified Studio để biết thêm thông tin.
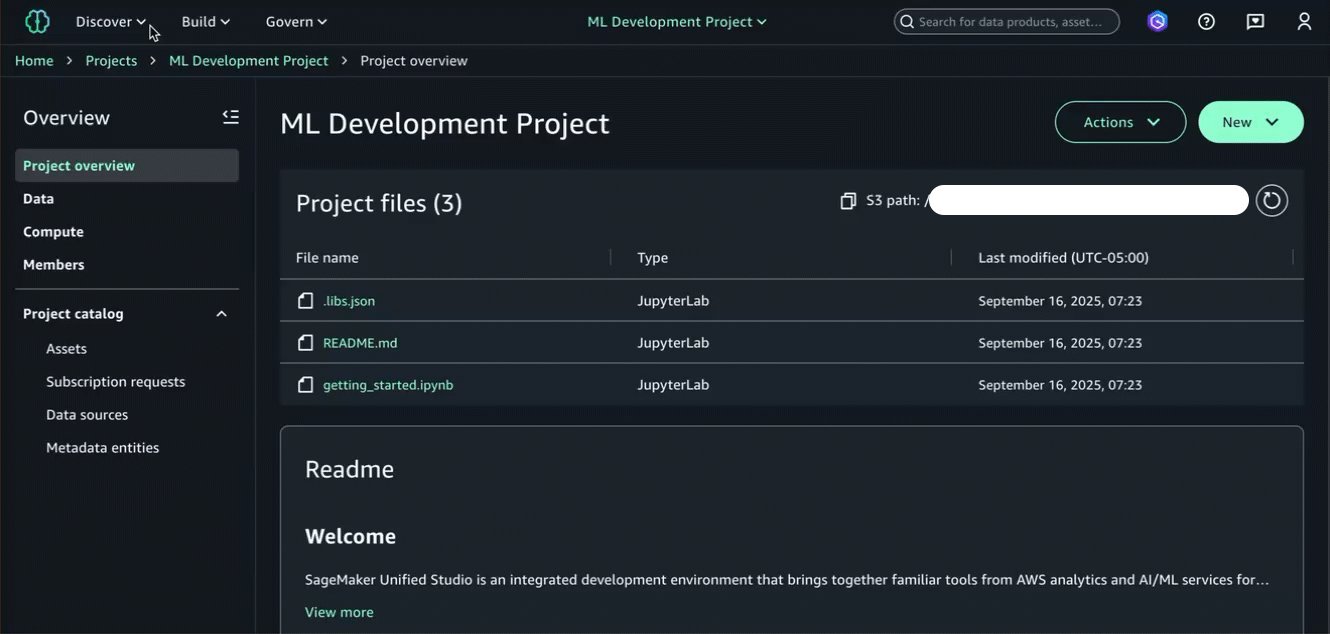
Bây giờ chúng tôi đã đăng ký tài sản dữ liệu trong dự án phát triển ML của mình, nơi chúng tôi sẽ xây dựng mô hình ML, chúng tôi có thể bắt đầu quy trình làm việc phát triển mô hình. Điều này bao gồm ba bước chính: tìm nạp bộ dữ liệu từ bucket của chúng tôi bằng cách sử dụng Amazon S3 Access Grants, chuẩn bị nó để tinh chỉnh và huấn luyện các mô hình của chúng tôi.
Người được cấp quyền có thể truy cập dữ liệu Amazon S3 bằng cách sử dụng AWS Command Line Interface (AWS CLI), AWS SDKs và Amazon S3 REST API. Ngoài ra, bạn có thể sử dụng các plugin Python và Java của AWS để gọi Amazon S3 Access Grants. Để ngắn gọn, chúng tôi chọn phương pháp AWS CLI trong notebook và mã sau. Chúng tôi cũng bao gồm một ví dụ cho thấy việc sử dụng boto3-s3-access-grants-plugin của Python trong phần phụ lục của notebook để tham khảo.
Quá trình này bao gồm hai bước: đầu tiên là lấy thông tin xác thực truy cập tạm thời vào mặt phẳng điều khiển Amazon S3 thông qua mô-đun CLI s3control, sau đó sử dụng các thông tin xác thực đó để đồng bộ hóa dữ liệu cục bộ. Cập nhật biến AWS_ACCOUNT_ID với ID tài khoản thích hợp chứa bộ dữ liệu của bạn.
import jsonAWS_ACCOUNT_ID = "123456789" # REPLACE THIS WITH YOUR ACCOUNT IDS3_BUCKET_NAME = "s3://MY_BUCKET_NAME/" # REPLACE THIS WITH YOUR BUCKET# Get credentialsresult = !aws s3control get-data-access --account-id {AWS_ACCOUNT_ID} --target {S3_BUCKET_NAME} --permission READjson_response = json.loads(result.s)creds = json_response['Credentials']# Configure profile with cell magic!aws configure set aws_access_key_id {creds['AccessKeyId']} --profile access-grants-consumer-access-profile!aws configure set aws_secret_access_key {creds['SecretAccessKey']} --profile access-grants-consumer-access-profile!aws configure set aws_session_token {creds['SessionToken']} --profile access-grants-consumer-access-profileprint("Profile configured successfully!")!aws s3 sync {S3_BUCKET_NAME} ./ --profile access-grants-consumer-access-profile
Sau khi chạy mã trước đó và nhận được kết quả thành công, chúng ta hiện có thể truy cập bucket S3 cục bộ. Với bộ dữ liệu thô của chúng ta hiện có thể truy cập cục bộ, chúng ta cần chuyển đổi nó sang định dạng cần thiết để tinh chỉnh LLM của chúng ta. Chúng ta sẽ tạo ba bộ dữ liệu với các kích thước khác nhau (1k, 5k và 10k hình ảnh) để đánh giá cách kích thước bộ dữ liệu ảnh hưởng đến hiệu suất mô hình.
Mỗi bộ dữ liệu huấn luyện chứa một thư mục huấn luyện và xác thực, mỗi thư mục phải chứa một thư mục con images và tệp metadata.jsonl đi kèm với các ví dụ huấn luyện. Định dạng tệp siêu dữ liệu bao gồm ba trường khóa/giá trị trên mỗi dòng:
{"file_name": "images/img_0.jpg", "prompt": "what is the date mentioned in this letter?", "completion": "1/8/93"}{"file_name": "images/img_1.jpg", "prompt": "what is the contact person name mentioned in letter?", "completion": "P. Carter"}
Với các tạo phẩm này được tải lên Amazon S3, chúng ta hiện có thể tinh chỉnh LLM của mình bằng cách sử dụng SageMaker JumpStart để truy cập mô hình Llama 3.2 11B Vision Instruct đã được huấn luyện trước. Chúng ta sẽ tạo ba biến thể tinh chỉnh riêng biệt để đánh giá. Chúng tôi đã tạo một hàm train() để tạo điều kiện này bằng cách sử dụng phương pháp tham số hóa, làm cho nó có thể tái sử dụng cho các kích thước bộ dữ liệu khác nhau:
def train(name, instance_type, training_data_path, experiment_name, run): ... estimator = JumpStartEstimator( model_id=model_id, model_version=model_version, environment={"accept_eula": "true"}, # Must accept as true disable_output_compression=True, instance_type=instance_type, hyperparameters=my_hyperparameters, ) ...
Hàm huấn luyện của chúng tôi xử lý một số khía cạnh quan trọng:
- Lựa chọn mô hình: Sử dụng phiên bản mới nhất của Llama 3.2 11B Vision Instruct từ SageMaker JumpStart.
- Siêu tham số: Notebook mẫu sử dụng API
retrieve_default()trong SageMaker SDK để tự động tìm nạp các siêu tham số mặc định cho mô hình của chúng tôi. - Kích thước lô: Siêu tham số mặc định duy nhất mà chúng tôi thay đổi, đặt thành 1 trên mỗi thiết bị do kích thước mô hình lớn và các ràng buộc về bộ nhớ.
- Loại phiên bản: Chúng tôi sử dụng loại phiên bản ml.p4de.24xlarge cho công việc huấn luyện này và khuyên bạn nên sử dụng cùng loại hoặc lớn hơn.
- Tích hợp MLflow: Tự động ghi nhật ký siêu tham số, tên công việc và siêu dữ liệu huấn luyện để theo dõi thử nghiệm.
- Triển khai điểm cuối: Tự động triển khai từng mô hình đã huấn luyện đến một điểm cuối SageMaker để suy luận.
Nhắc lại rằng quá trình huấn luyện sẽ mất vài giờ để hoàn thành bằng cách sử dụng loại phiên bản ml.p4de.24xlarge.
Bây giờ chúng ta sẽ đánh giá các mô hình đã tinh chỉnh của mình bằng cách sử dụng chỉ số Average Normalized Levenshtein Similarity (ANLS). Chỉ số này đánh giá các đầu ra dựa trên văn bản bằng cách đo lường sự tương đồng giữa các câu trả lời dự đoán và câu trả lời đúng, ngay cả khi có lỗi nhỏ hoặc biến thể. Nó đặc biệt hữu ích cho các tác vụ như trả lời câu hỏi bằng hình ảnh vì nó có thể xử lý các biến thể nhỏ trong câu trả lời. Xem thẻ mô hình Llama 3.2 3B để biết thêm thông tin.
MLflow sẽ theo dõi các thử nghiệm và kết quả của chúng tôi để so sánh dễ dàng. Pipeline đánh giá của chúng tôi bao gồm một số hàm chính để mã hóa hình ảnh cho suy luận mô hình, định dạng tải trọng, tính toán ANLS và theo dõi kết quả. Hàm training_pipeline() điều phối toàn bộ quy trình làm việc với các lần chạy MLflow lồng nhau để tổ chức thử nghiệm tốt hơn.
# MLFlow configurationarn = "" # replace with ARN of project's MLflow instancemlflow.set_tracking_uri(arn)def training_pipeline(training_size): # Set experiment experiment_name = f"docvqa-{training_size}" mlflow.set_experiment(experiment_name) # Start main run with mlflow.start_run(run_name="pipeline-run"): # DataPreprocess nested run with mlflow.start_run(run_name="DataPreprocess", nested=True): training_data_path = process_data("train", f"docvqa_{training_size}/train", training_size) # TrainDeploy nested run with mlflow.start_run(run_name="TrainDeploy", nested=True) as run: model_name = train(f"docvqa-{training_size}", "ml.p4d.24xlarge", training_data_path, experiment_name, run) #model_name = 'base-model' # Evaluate nested run with mlflow.start_run(run_name="Evaluate", nested=True): # Load validation data with open("./docvqa_1k/validation/metadata.jsonl") as f: data = [json.loads(line) for line in f] print(f"\nStarting validation for {model_name}") # Log parameters mlflow.log_param("model_name", model_name) mlflow.log_param("total_images", len(data[:50])) mlflow.log_param("threshold", 0.5) predictor = retrieve_default(model_id="meta-vlm-llama-3-2-11b-vision-instruct", model_version="*", endpoint_name=model_name) results = [] anls_scores = [] # Process each image for i, each in enumerate(data[:50]): filename = each['file_name'] question = each["prompt"] ground_truth = each["completion"] image_path = f"./docvqa_1k/validation/{filename}" print(f"Processing {filename} ({i+1}/50)") # Get model prediction using traced function inferred_response = invoke_model(predictor, question, image_path) # Calculate ANLS score anls_score = anls_metric_single(inferred_response, ground_truth) anls_scores.append(anls_score) # Store result result = { 'filename': filename, 'ground_truth': ground_truth, 'inferred_response': inferred_response, 'anls_score': anls_score } results.append(result) print(f" Ground Truth: {ground_truth}") print(f" Prediction: {inferred_response}") print(f" ANLS Score: {anls_score:.4f}") # Calculate average ANLS score avg_anls = sum(anls_scores) / len(anls_scores) if anls_scores else 0.0 # Log metrics mlflow.log_metric("average_anls_score", avg_anls) # Save results to CSV timestamp = datetime.now().strftime("%Y%m%d_%H%M%S") csv_filename = f"anls_validation_{model_name}_{timestamp}.csv" save_results_to_csv(results, csv_filename) # Log CSV as artifact mlflow.log_artifact(csv_filename) print(f"Results for {model_name}:") print(f" Average ANLS Score: {avg_anls:.4f}") mlflow.log_param("metric_type", "anls") mlflow.log_param("threshold", "0.5")
Sau khi điều phối ba lần thực thi từ đầu đến cuối cho ba kích thước bộ dữ liệu của chúng tôi, chúng tôi xem xét kết quả chỉ số ANLS trong MLflow. Sử dụng chức năng so sánh, chúng tôi ghi nhận điểm ANLS cao nhất là 0.902 trong mô hình docvqa-10000, tăng 4.9 điểm phần trăm so với mô hình cơ sở (0.902 − 0.853 = 0.049).
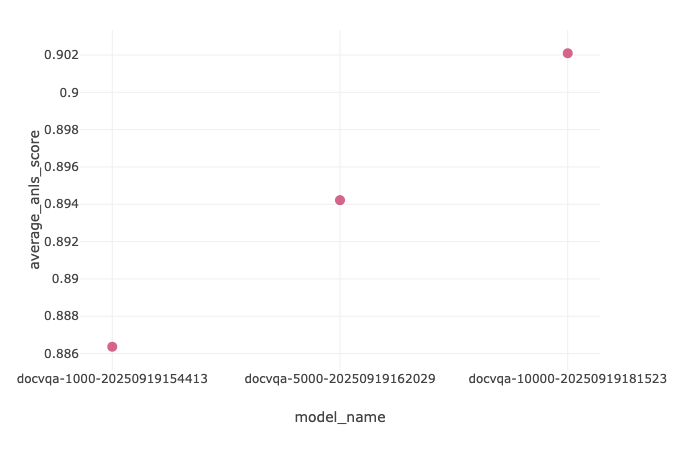
| Mô hình | ANLS |
|---|---|
| docvqa-1000 | 0.886 |
| docvqa-5000 | 0.894 |
| docvqa-10000 | 0.902 |
| Mô hình cơ sở | 0.853 |
Dọn dẹp
Để tránh các khoản phí phát sinh, hãy xóa các tài nguyên đã tạo trong quá trình hướng dẫn này. Điều này bao gồm các điểm cuối SageMaker và tài nguyên dự án như ứng dụng MLflow, JupyterLab IDE và miền.
Kết luận
Dựa trên dữ liệu trên, chúng tôi quan sát thấy mối quan hệ tích cực giữa kích thước của bộ dữ liệu huấn luyện và ANLS, theo đó mô hình docvqa-10000 có hiệu suất được cải thiện.
Chúng tôi đã sử dụng MLflow để thử nghiệm và trực quan hóa xung quanh chỉ số thành công của chúng tôi. Những cải tiến hơn nữa trong các lĩnh vực như điều chỉnh siêu tham số và làm giàu dữ liệu có thể mang lại kết quả tốt hơn nữa.
Hướng dẫn này minh họa cách tích hợp Amazon SageMaker Unified Studio với các bucket đa năng của S3 giúp hợp lý hóa con đường từ dữ liệu phi cấu trúc đến các mô hình ML sẵn sàng sản xuất. Các lợi ích chính bao gồm:
- Khám phá và lập danh mục dữ liệu đơn giản hóa thông qua giao diện hợp nhất
- Truy cập dữ liệu an toàn hơn thông qua S3 Access Grants mà không cần quản lý quyền phức tạp
- Cộng tác suôn sẻ giữa các nhà sản xuất và người tiêu dùng dữ liệu trên các dự án
- Theo dõi thử nghiệm từ đầu đến cuối với tích hợp MLflow được quản lý
Các tổ chức hiện có thể sử dụng hiệu quả hơn các tài sản dữ liệu S3 hiện có của họ cho các khối lượng công việc ML trong khi vẫn duy trì các kiểm soát quản trị và bảo mật. Cải thiện hiệu suất 4.9% từ mô hình cơ sở đến biến thể tinh chỉnh được cải thiện của chúng tôi (0.853–0.902 ANLS) xác nhận phương pháp tiếp cận cho các tác vụ trả lời câu hỏi bằng hình ảnh.
Đối với các bước tiếp theo, hãy xem xét khám phá các kỹ thuật tiền xử lý bộ dữ liệu bổ sung, thử nghiệm với các kiến trúc mô hình khác nhau có sẵn thông qua SageMaker JumpStart hoặc mở rộng quy mô sang các bộ dữ liệu lớn hơn theo yêu cầu của trường hợp sử dụng của bạn.
- Bắt đầu với Amazon SageMaker JumpStart
- Các khối lượng công việc chuyển đổi dữ liệu với SageMaker Processing
Mã giải pháp được sử dụng cho bài đăng trên blog này có thể được tìm thấy trong kho lưu trữ GitHub này.
Về tác giả

Hazim Qudah
Hazim Qudah là Kiến trúc sư Giải pháp Chuyên gia AI/ML tại Amazon Web Services. Anh ấy thích giúp khách hàng xây dựng và áp dụng các giải pháp AI/ML bằng cách sử dụng các công nghệ và phương pháp hay nhất của AWS. Trước khi đảm nhận vai trò tại AWS, anh ấy đã dành nhiều năm tư vấn công nghệ với khách hàng trên nhiều ngành và khu vực địa lý. Trong thời gian rảnh rỗi, anh ấy thích chạy bộ và chơi với những chú chó Nala và Chai của mình!
