Tác giả: Mihir Borkar, Arghya Banerjee, and Amit Maindola
Ngày phát hành: 20 JAN 2026
Chuyên mục: Advanced (300), Amazon EMR, Analytics, AWS Glue, Technical How-to
Các tổ chức quản lý khối lượng công việc phân tích quy mô lớn ngày càng đối mặt với những thách thức với các data lake truyền thống dựa trên Apache Parquet với phân vùng kiểu Hive, bao gồm truy vấn chậm, quản lý tệp phức tạp và đảm bảo tính nhất quán hạn chế. Apache Iceberg giải quyết những vấn đề này bằng cách cung cấp các giao dịch ACID, tiến hóa schema liền mạch và khả năng phục hồi dữ liệu tại một thời điểm cụ thể, giúp thay đổi cách các doanh nghiệp xử lý hạ tầng dữ liệu của họ.
Trong bài viết này, chúng tôi trình bày cách bạn có thể thực hiện di chuyển quy mô lớn từ các bảng Parquet hiện có sang các bảng Apache Iceberg. Sử dụng Amazon DynamoDB làm cơ chế điều phối trung tâm, chúng tôi chỉ ra cách bạn có thể triển khai các hoạt động di chuyển tại chỗ có khả năng cấu hình cao, có thể lặp lại và chịu lỗi – khai thác toàn bộ tiềm năng của kiến trúc data lake hiện đại mà không cần di chuyển hoặc sao chép dữ liệu rộng rãi.
Tổng quan giải pháp
Khi thực hiện di chuyển tại chỗ, Apache Iceberg sử dụng khả năng tham chiếu trực tiếp các tệp dữ liệu hiện có. Khả năng này chỉ được hỗ trợ cho các định dạng như Parquet, ORC và Avro, vì các định dạng này tự mô tả và bao gồm thông tin schema và metadata nhất quán. Không giống như các định dạng thô như CSV hoặc JSON, chúng thực thi cấu trúc và hỗ trợ truy cập theo cột hoặc theo hàng hiệu quả, cho phép Iceberg tích hợp chúng mà không cần ghi lại dữ liệu.
Trong bài viết này, chúng tôi trình bày cách bạn có thể di chuyển một data lake dựa trên Parquet hiện có không được catalog trong AWS Glue bằng cách sử dụng hai phương pháp:
- Phương pháp Iceberg migrate và
register_table. Lý tưởng để chuyển đổi các bảng Parquet đã đăng ký Hive hiện có thành các bảng được quản lý bởi Iceberg. - Phương pháp Iceberg
add_files. Phù hợp nhất để nhanh chóng đưa dữ liệu Parquet thô vào Iceberg mà không cần ghi lại tệp.
Giải pháp cũng tích hợp một bảng DynamoDB hoạt động như một control plane có thể mở rộng, để bạn có thể thực hiện di chuyển tại chỗ data lake của mình từ định dạng Parquet sang định dạng Iceberg.
Sơ đồ sau đây cho thấy các phương pháp khác nhau mà bạn có thể sử dụng để đạt được việc di chuyển tại chỗ data lake được phân vùng kiểu Hive của bạn:
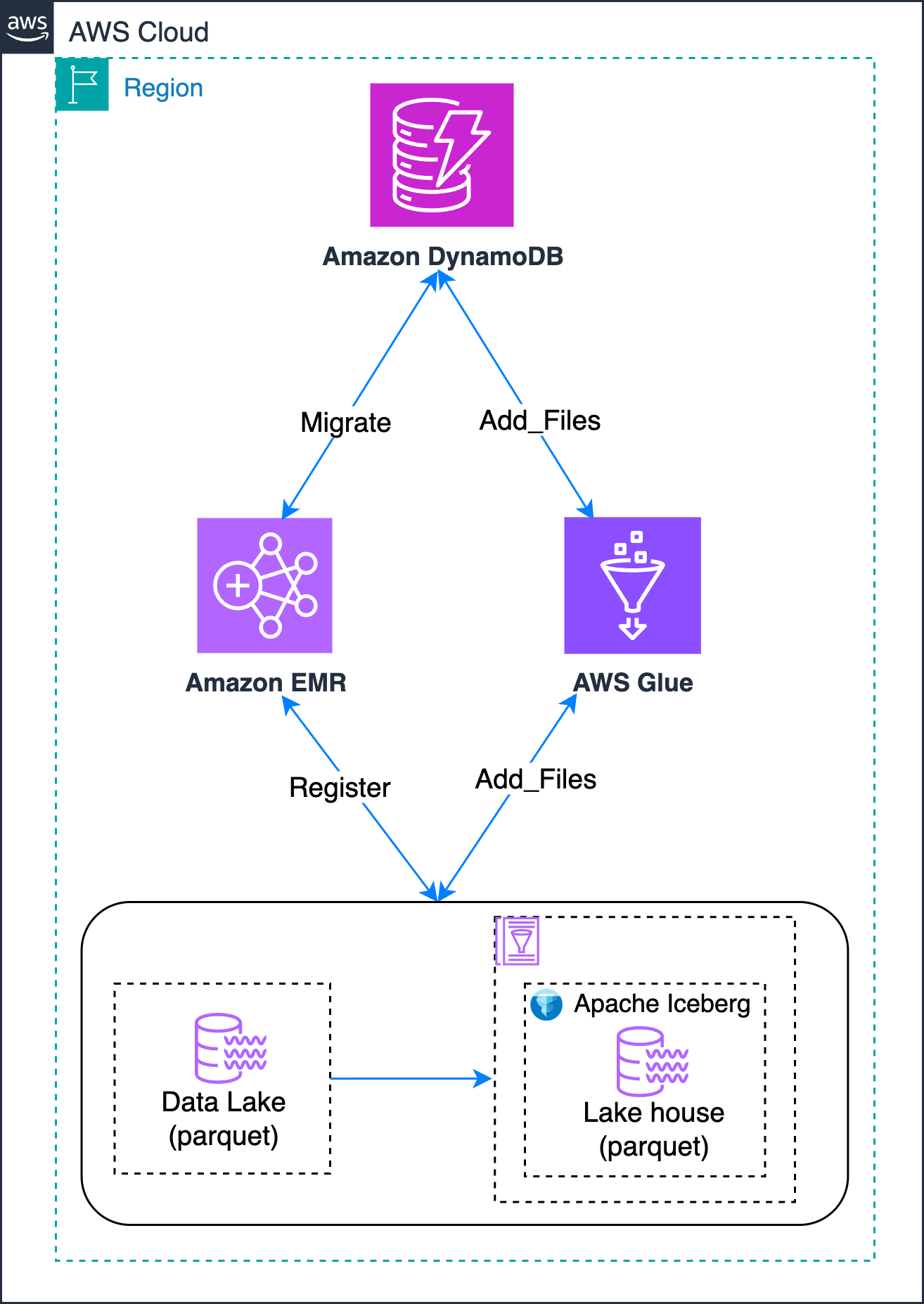
Bạn sử dụng DynamoDB để theo dõi trạng thái di chuyển, xử lý các lần thử lại và ghi lại lỗi cũng như kết quả. Điều này mang lại những lợi ích sau:
- Kiểm soát tập trung các đường dẫn Amazon Simple Storage Service (Amazon S3) nào cần di chuyển.
- Theo dõi vòng đời của từng tập dữ liệu qua các giai đoạn di chuyển.
- Ghi lại và kiểm tra lỗi trên cơ sở từng đường dẫn.
- Cho phép chạy lại bằng cách cập nhật các cờ trạng thái hoặc xóa thông báo lỗi.
Điều kiện tiên quyết
Trước khi bắt đầu, bạn cần:
- Một tài khoản AWS
- AWS Command Line Interface (AWS CLI) đã được cài đặt
- Quyền AWS Identity and Access Management (IAM) để truy cập Amazon DynamoDB, Amazon EMR và AWS Glue
- Một Amazon Virtual Private Cloud (Amazon VPC) hiện có hoặc mới cho các cluster Amazon EMR
- Truy cập Amazon Athena với một workgroup đã được cấu hình và vị trí kết quả truy vấn (Amazon S3) đã được đặt
- Một cluster Amazon EMR sử dụng Hive làm metastore, với quyền truy cập SSH. (Xem Phụ lục A để biết hướng dẫn thiết lập.)
- Một cluster Amazon EMR hoặc môi trường Amazon EMR Serverless sử dụng AWS Glue Data Catalog làm Spark metastore, với quyền truy cập SSH. (Xem Phụ lục B để biết hướng dẫn thiết lập.)
- Đối với AWS Glue exchange, transform, and load (ETL), hãy sử dụng Glue 4.0 trở lên.
Tạo tập dữ liệu Parquet mẫu làm nguồn
Bạn có thể tạo tập dữ liệu Parquet mẫu để kiểm tra các phương pháp khác nhau bằng cách sử dụng trình chỉnh sửa truy vấn của Athena. Thay thế <amzn-s3-demo-bucket> bằng một bucket có sẵn trong tài khoản của bạn.
- Tạo một database AWS Glue (
test_db), nếu chưa có.sql CREATE DATABASE IF NOT EXISTS test_db - Tạo một bảng Parquet mẫu (
table1) và thêm dữ liệu để sử dụng cho việc kiểm tra phương phápadd_files.sql CREATE TABLE table1 WITH ( external_location = 's3://<amzn-s3-demo-bucket>/table1/', format = 'PARQUET', partitioned_by = ARRAY['date', 'hour'] ) AS SELECT 1 as id, 'John Doe' as name, 25 as age, 'Engineer' as job_title, current_date as created_date, current_date as date, hour(current_timestamp) as hour UNION ALL SELECT 2, 'Jane Smith', 30, 'Manager', current_date, current_date, hour(current_timestamp) UNION ALL SELECT 3, 'Bob Johnson', 35, 'Analyst', current_date, current_date, hour(current_timestamp); - Tạo một bảng Parquet mẫu (
table2) và thêm dữ liệu để sử dụng cho việc kiểm tra phương pháp migrate vàregister_table. Thay thế<amzn-s3-demo-bucket>bằng tên bucket của bạn.sql CREATE TABLE table2 WITH ( external_location = 's3://<amzn-s3-demo-bucket>/table2/', format = 'PARQUET', partitioned_by = ARRAY['date', 'hour'] ) AS SELECT 1 as id, 'John Doe' as name, 25 as age, 'Engineer' as job_title, current_date as created_date, current_date as date, hour(current_timestamp) as hour UNION ALL SELECT 2, 'Jane Smith', 30, 'Manager', current_date, current_date, hour(current_timestamp) UNION ALL SELECT 3, 'Bob Johnson', 35, 'Analyst', current_date, current_date, hour(current_timestamp); - Xóa các bảng khỏi Data Catalog vì bạn chỉ cần dữ liệu Parquet với cấu trúc phân vùng kiểu Hive.
sql DROP TABLE IF EXISTS test_db.table1
Tạo bảng điều khiển DynamoDB
Trước khi bắt đầu quá trình di chuyển, bạn phải tạo một bảng DynamoDB đóng vai trò là control plane. Bảng này ánh xạ các đường dẫn Amazon S3 nguồn đến các đích database và bảng Iceberg tương ứng của chúng, cho phép theo dõi có hệ thống quá trình di chuyển.
Để triển khai cơ chế kiểm soát này, hãy tạo một bảng với cấu trúc sau:
- Một khóa chính
s3_pathlưu trữ vị trí dữ liệu Parquet nguồn - Hai thuộc tính xác định vị trí Iceberg đích:
target_db_nametarget_table_name
Để tạo bảng điều khiển DynamoDB
- Tạo bảng Amazon DynamoDB bằng lệnh AWS CLI sau:
shell aws dynamodb create-table \ --table-name migration-control-table \ --attribute-definitions \ AttributeName=s3_path,AttributeType=S \ --key-schema \ AttributeName=s3_path,KeyType=HASH \ --billing-mode PAY_PER_REQUEST \ --region <REGION> - Xác minh bảng được tạo thành công. Thay thế
<REGION>bằng AWS Region nơi dữ liệu của bạn được lưu trữ:shell aws dynamodb describe-table --table-name migration-control-table --region <REGION> - Tạo một tệp
migration_data.jsonvới nội dung sau.
Trong ví dụ này:- Thay thế
<amzn-s3-demo-bucket>và<TablePrefix>bằng tên S3 bucket và tiền tố của bạn chứa dữ liệu ParquetThay thế<DatabaseName>bằng tên database Iceberg đích của bạnThay thế<TableName>bằng tên bảng Iceberg đích của bạn
{ "your-migration-table": [ { "PutRequest": { "Item": { "s3_path": {"S": "s3://<amzn-s3-demo-bucket>/table1/"}, "target_db_name": {"S": "test_db"}, "target_table_name": {"S": "table1"} } } }, { "PutRequest": { "Item": { "s3_path": {"S": "s3://<amzn-s3-demo-bucket>/table2/"}, "target_db_name": {"S": "test_db"}, "target_table_name": {"S": "table2"} } } }, { "PutRequest": { "Item": { "s3_path": {"S": "s3://<amzn-s3-demo-bucket>/<TablePrefix>/"}, "target_db_name": {"S": "<DatabaseName>"}, "target_table_name": {"S": "<TableName>"} } } } ] }Tệp này định nghĩa ánh xạ giữa các đường dẫn Amazon S3 và các đích bảng Iceberg tương ứng của chúng. - Thay thế
- Chạy lệnh CLI sau để tải bảng điều khiển DynamoDB.
shell aws dynamodb batch-write-item \ --request-items file://migration_data.json \ --region <REGION;>
Các phương pháp di chuyển
Trong phần này, bạn sẽ khám phá hai phương pháp để di chuyển các bảng Parquet hiện có của bạn sang định dạng Apache Iceberg:
- Phương pháp Apache Iceberg migrate và register_table – Phương pháp này đầu tiên chuyển đổi bảng Parquet của bạn sang định dạng Iceberg bằng cách sử dụng quy trình migrate gốc, sau đó đăng ký nó trong AWS Glue bằng quy trình
register_table. - Phương pháp Apache Iceberg add_files – Phương pháp này tạo một bảng Iceberg trống và sử dụng quy trình
add_filesđể nhập các tệp dữ liệu Parquet hiện có mà không di chuyển vật lý chúng.
Quy trình Apache Iceberg migrate và register_table
Sử dụng quy trình Migrate của Apache Iceberg được sử dụng để chuyển đổi tại chỗ một bảng Hive hoặc Parquet hiện có thành một bảng được quản lý bởi Iceberg. Sau đó, bạn có thể sử dụng quy trình RegisterTable của Apache Iceberg để đăng ký bảng tương ứng trong AWS Glue.

Migrate
- Trong cluster EMR của bạn với Hive làm metastore, tạo một phiên PySpark với các gói Iceberg sau:
shell pyspark \ --name "Iceberg Migration" \ --conf "spark.jars=/usr/share/aws/iceberg/lib/iceberg-spark3-runtime.jar" \ --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \ --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog \ --conf spark.sql.catalog.spark_catalog.type=hive
Bài viết này sử dụng Iceberg v1.9.1 (bản dựng Amazon EMR), là bản gốc của Amazon EMR 7.11. Luôn xác minh phiên bản được hỗ trợ mới nhất và cập nhật các tọa độ gói cho phù hợp. - Tiếp theo, tạo bảng tương ứng của bạn trong Hive catalog (bạn có thể bỏ qua bước này nếu bạn đã có bảng được tạo trong Hive catalog của mình). Thay thế
<amzn-s3-demo-bucket>bằng tên S3 bucket của bạn.
Trong đoạn mã sau, thay đổi hoặc xóa lệnhPARTITIONED BYdựa trên chiến lược phân vùng của bảng của bạn, lệnhMSCK Repair tablechỉ nên được chạy nếu bảng tương ứng của bạn được phân vùng.python #You can automate this for production Scaling with DynamoDB as control table s3_path = "s3://<amzn-s3-demo-bucket>/table1/" target_db_name = "test_db" target_table_name = "table1" # Read data in a dataframe to infer schema df = spark.read.parquet(s3_path) df.createOrReplaceTempView("temp_view") # Get schema as string schema = spark.table("temp_view").schema schema_string = ", ".join([f"{field.name} {field.dataType.simpleString()}" for field in schema]) # Create Database If not exists spark.sql(f"CREATE DATABASE IF NOT EXISTS {target_db_name}").show() # full_table_name= test_db.table1 full_table_name = f"{target_db_name}.{target_table_name}" # Create table spark.sql(f""" CREATE TABLE IF NOT EXISTS {full_table_name} ( {schema_string} ) STORED AS PARQUET PARTITIONED BY (date, hour) LOCATION '{s3_path}' """) # Refresh, repair, and validate spark.sql(f"REFRESH TABLE {full_table_name}") spark.sql(f"MSCK REPAIR TABLE {full_table_name}") - Chuyển đổi bảng Parquet thành bảng Iceberg trong Hive
python # Run migration procedure spark.sql(f"CALL spark_catalog.system.migrate('{full_table_name}')") # Validate that the table is successfully migrated spark.sql(f"DESCRIBE FORMATTED {full_table_name}").show(truncate=False)
Chạy lệnhmigrateđể chuyển đổi bảng dựa trên Parquet thành bảng Iceberg, tạo thư mục metadata và tệpmetadata.jsontrong đó.
Bạn có thể dừng ở điểm này nếu bạn không có ý định di chuyển bảng Iceberg hiện có của mình từ Hive sang Data Catalog.
Register
- Đăng nhập vào cluster EMR đã bật AWS Glue làm Spark Catalog.
- Đăng ký bảng Iceberg vào Data Catalog của bạn.
Tạo phiên với các gói Iceberg tương ứng. Thay thế<amzn-s3-demo-bucket>bằng tên bucket của bạn và<warehouse>bằng thư mục warehouse.shell pyspark \ --conf "spark.jars=/usr/share/aws/iceberg/lib/iceberg-spark3-runtime.jar" \ --conf "spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions" \ --conf "spark.sql.catalog.glue_catalog=org.apache.iceberg.spark.SparkCatalog" \ --conf "spark.sql.catalog.glue_catalog.warehouse= s3://<amzn-s3-demo-bucket>/<warehouse>/" \ --conf "spark.sql.catalog.glue_catalog.catalog-impl=org.apache.iceberg.aws.glue.GlueCatalog" \ --conf "spark.sql.catalog.glue_catalog.io-impl=org.apache.iceberg.aws.s3.S3FileIO" - Chạy lệnh
register_tableđể làm cho bảng Iceberg hiển thị trong AWS Glue.register_tableđăng ký tệp metadata của bảng Iceberg hiện có (metadata.json) với một catalog (glue_catalog) để Spark (và các engine khác) có thể truy vấn nó.- Quy trình này tạo một mục Data Catalog cho bảng, trỏ nó đến vị trí metadata đã cho.
<amzn-s3-demo-bucket>và<metadata-prefix>bằng tên S3 bucket và tên tiền tố metadata của bạn. Đảm bảo rằng EMR Spark Cluster của bạn đã được cấu hình với các quyền AWS Glue thích hợp.# You can automate this for production Scaling with DynamoDB as control table metadata_location = "s3://<amzn-s3-demo-bucket>/table1/metadata/<metadata-prefix>.metadata.json" target_db_name = "test_db" target_table_name = "table1" full_table_name = f"{target_db_name}.{target_table_name}" # Register existing Iceberg table metadata in Glue Catalog spark.sql(f"CALL glue_catalog.system.register_table('{full_table_name}', '{metadata_location}')") # Set table properties (example: Iceberg format version 2) spark.sql(f"ALTER TABLE glue_catalog.{full_table_name} SET TBLPROPERTIES('format-version'='2')") - Xác minh rằng bảng Iceberg hiện đã hiển thị trong Data Catalog.
python # Lookout for format as iceberg/parquet spark.sql("SHOW TBLPROPERTIES glue_catalog.test_db.table1").show()
Quy trình add_files của Apache Iceberg
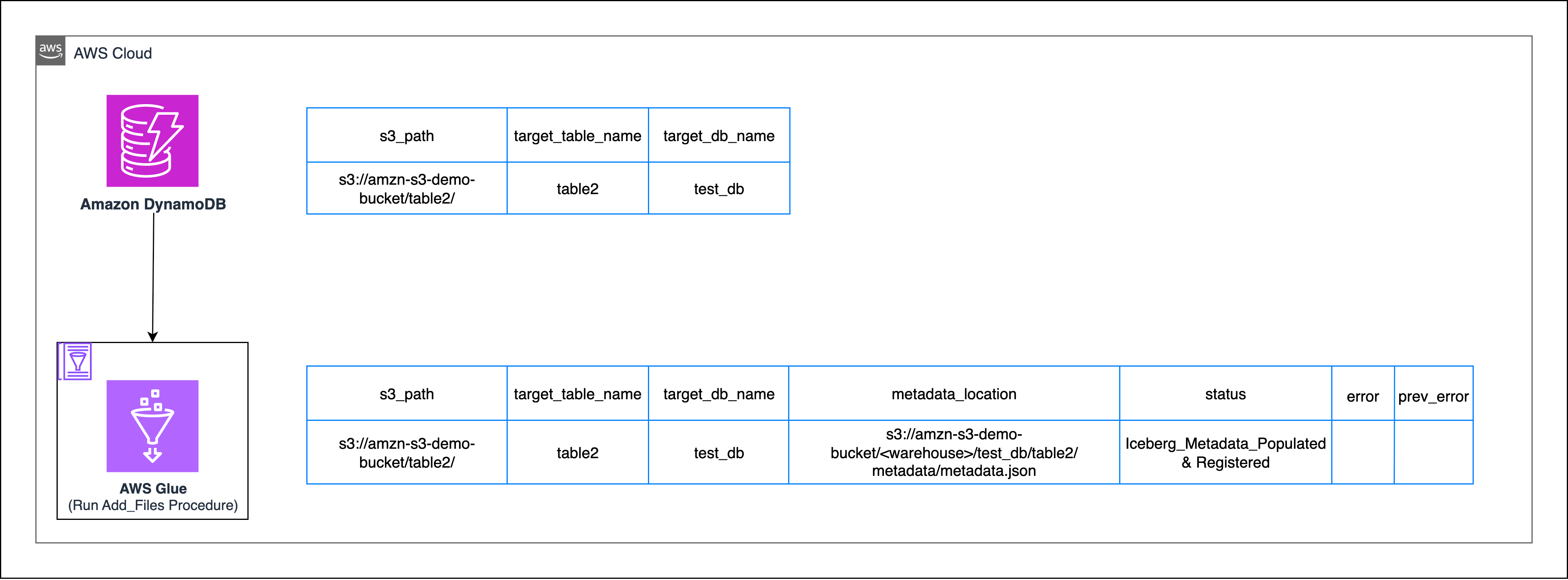
Ở đây, bạn sẽ sử dụng quy trình add_files của Iceberg để nhập các tệp dữ liệu thô (Parquet, ORC, Avro) vào một bảng Iceberg hiện có bằng cách cập nhật metadata của nó. Quy trình này hoạt động cho cả Hive và Data Catalog, nó không di chuyển hoặc ghi lại các tệp vật lý – nó chỉ đăng ký chúng để Iceberg có thể quản lý chúng.
Phương pháp này bao gồm các bước sau:
- Tạo một bảng Iceberg trống trong AWS Glue.
Vì quy trình add_files mong đợi bảng Iceberg đã có sẵn, bạn cần tạo một bảng Iceberg trống bằng cách suy luận schema bảng. - Đăng ký các vị trí dữ liệu hiện có vào bảng Iceberg.
Sử dụng quy trình add_files trong một Iceberg catalog được hỗ trợ bởi Glue sẽ đăng ký đường dẫn S3 đích cùng với tất cả các thư mục con của nó vào bảng Iceberg trống được tạo ở bước trước.
Bạn có thể hợp nhất cả hai bước vào một Spark job duy nhất. Đối với AWS Glue job sau, bạn đã chỉ định iceberg làm giá trị cho tham số job --datalake-formats. Xem tài liệu cấu hình AWS Glue job để biết thêm chi tiết.
Thay thế <amzn-s3-demo-bucket> bằng tên S3 bucket của bạn và <warehouse> bằng thư mục warehouse.
from pyspark.sql import SparkSessionimport logginglogging.basicConfig(level=logging.INFO)logger = logging.getLogger(__name__)target_db_name = "test_db"target_table_name = "table2"s3_path = "s3://<amzn-s3-demo-bucket>/table2"# Set to None or [] for unpartitionedpartitioned_cols = ["date", "hour"] spark = SparkSession.builder \ .appName("Iceberg Add Files") \ .config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \ .config("spark.sql.catalog.glue_catalog", "org.apache.iceberg.spark.SparkCatalog") \ .config("spark.sql.catalog.glue_catalog.catalog-impl", "org.apache.iceberg.aws.glue.GlueCatalog") \ .config("spark.sql.catalog.glue_catalog.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \ .config("spark.sql.catalog.glue_catalog.warehouse", "s3://<amzn-s3-demo-bucket>/<warehouse>/") \ .getOrCreate()full_table_name = f"glue_catalog.{target_db_name}.{target_table_name}"# Read schema from one file (schema inference)df = spark.read.parquet(s3_path)schema = df.schema# Create empty Iceberg tableempty_df = spark.createDataFrame([], schema)if partitioned_cols: empty_df.writeTo(full_table_name).using("iceberg").partitionedBy(*partitioned_cols). .tableProperty("format-version", "2").create()else: empty_df.writeTo(full_table_name).using("iceberg").tableProperty("format-version", "2").create()logger.info(f"Created empty Iceberg table: {full_table_name}")spark.sql(f"""CALL glue_catalog.system.add_files( '{target_db_name}.{target_table_name}', 'parquet.`{s3_path}`')""")
Khi làm việc với các tập dữ liệu không được phân vùng kiểu Hive, việc di chuyển trực tiếp sang Apache Iceberg bằng cách sử dụng add_files có thể không hoạt động như mong đợi. Xem Phụ lục C để biết thêm thông tin.
Các cân nhắc
Hãy cùng khám phá hai cân nhắc chính mà bạn nên giải quyết khi triển khai chiến lược di chuyển của mình.
Quản lý trạng thái bằng bảng điều khiển DynamoDB
Sử dụng đoạn mã mẫu sau để cập nhật trạng thái của bảng DynamoDB:
def update_dynamodb_record(self, s3_path, metadata_loc=None, error_msg=None): # Get current error message try: response = self.dynamodb.get_item( TableName='migration-control-table', Key={'s3_path': {'S': s3_path}} ) current_error = response.get('Item', {}).get('error_message', {}).get('S', '') except: current_error = "" if error_msg: # Error case error_msg = (error_msg or "Unknown error")[:1000] update_expr = "SET error_message = :err" attr_values = {':err': {'S': error_msg}} if current_error: update_expr += ", prev_error_message = :prev" attr_values[':prev'] = {'S': current_error} update_kwargs = {'TableName': 'Iceberg_migration','Key': {'s3_path': {'S': s3_path}},'UpdateExpression': update_expr,'ExpressionAttributeValues': attr_values} self.logger.error(f"Set error for {s3_path}: {error_msg}") else: # Success case update_kwargs = { 'TableName': 'Iceberg_migration', 'Key': {'s3_path': {'S': s3_path}}, 'UpdateExpression': 'SET #s = :status, #m = :meta, #p = :prev, #e = :err', 'ExpressionAttributeNames': {'#s': 'status','#p': 'prev_error_message','#e': 'error_message','#m': 'metadata_location' }, 'ExpressionAttributeValues': { ':status': {'S': 'Iceberg_Metadata_Populated and Registered'}, ':prev': {'S': current_error}, ':err': {'S': ''}, ':meta': {'S': metadata_loc} } } self.logger.info(f"Updated DynamoDB status for {s3_path}: {metadata_loc}")
Điều này đảm bảo rằng mọi lỗi đều được ghi lại và lưu vào DynamoDB dưới dạng error_message. Trong các lần thử lại liên tiếp, các lỗi trước đó sẽ chuyển sang prev_error_message và các lỗi mới sẽ ghi đè lên error_message. Các hoạt động thành công sẽ xóa error_message và lưu trữ lỗi cuối cùng.
Bảo vệ dữ liệu của bạn khỏi việc xóa không mong muốn
Để bảo vệ dữ liệu của bạn khỏi việc xóa không mong muốn, không bao giờ xóa các tệp dữ liệu hoặc metadata trực tiếp từ Amazon S3. Các bảng Iceberg được đăng ký trong AWS Glue hoặc Athena là các managed tables và nên được xóa bằng lệnh DROP TABLE từ Spark hoặc Athena. Lệnh DROP TABLE xóa cả metadata bảng và các tệp dữ liệu cơ bản trong S3. Xem Phụ lục D để biết thêm thông tin.
Dọn dẹp
Hoàn thành các bước sau để dọn dẹp tài nguyên của bạn:
- Xóa bảng điều khiển DynamoDB
- Xóa database và các bảng
- Xóa các cluster EMR và job AWS Glue được sử dụng để kiểm tra
Kết luận
Trong bài viết này, chúng tôi đã chỉ cho bạn cách hiện đại hóa data lake dựa trên Parquet của bạn thành một lakehouse được hỗ trợ bởi Apache Iceberg mà không cần ghi lại hoặc sao chép dữ liệu. Bạn đã học được hai phương pháp bổ sung cho việc di chuyển tại chỗ này:
- Migrate và register – Lý tưởng để chuyển đổi các bảng Parquet đã đăng ký Hive hiện có thành các bảng được quản lý bởi Iceberg.
- add_files – Phù hợp nhất để nhanh chóng đưa dữ liệu Parquet thô vào Iceberg mà không cần ghi lại tệp.
Cả hai phương pháp đều được hưởng lợi từ việc theo dõi trạng thái tập trung của DynamoDB, cho phép thử lại, kiểm tra lỗi và quản lý vòng đời trên nhiều tập dữ liệu.
Bằng cách kết hợp Apache Iceberg với Amazon EMR, AWS Glue và Amazon DynamoDB, bạn có thể tạo một pipeline di chuyển sẵn sàng cho sản xuất, có thể quan sát được, tự động và dễ dàng mở rộng cho các nâng cấp định dạng dữ liệu trong tương lai. Mô hình này tạo thành một nền tảng vững chắc để xây dựng một lakehouse dựa trên Iceberg trên AWS, giúp bạn đạt được phân tích nhanh hơn, quản trị dữ liệu tốt hơn và tính linh hoạt lâu dài cho các khối lượng công việc đang phát triển.
Để bắt đầu, hãy thử triển khai giải pháp này bằng cách sử dụng các bảng mẫu (table1 và table2) mà bạn đã tạo bằng các truy vấn Athena. Chúng tôi khuyến khích bạn chia sẻ kinh nghiệm di chuyển và câu hỏi của mình trong phần bình luận.
Phụ lục A — Tạo cluster EMR cho Hive metastore bằng console và AWS CLI
Các bước trên Console:
- Mở AWS Management Console cho Amazon EMR và chọn Create cluster.
- Chọn Spark hoặc Hive trong phần ứng dụng.
- Trong phần AWS Glue Data Catalog settings, đảm bảo các tùy chọn sau không được chọn:
- Use for Hive table metadata
- Use for Spark table metadata
- Cấu hình truy cập SSH (KeyName).
- Cấu hình mạng (VPC, subnets, SGs) để cho phép truy cập vào S3.
Các bước trên AWS CLI:
aws emr create-cluster \ --region us-east-1 \ --name "IcebergHiveCluster711" \ --release-label emr-7.11.0 \ --applications Name=Hive Name=Spark Name=Hadoop \ --ec2-attributes '{"KeyName":"<key-pair>","SubnetId":"<subnet-id>"}' \ --instance-groups '[ { "Name":"Master", "InstanceGroupType":"MASTER", "InstanceType":"m5.xlarge", "InstanceCount":1 }, { "Name":"Workers", "InstanceGroupType":"CORE", "InstanceType":"m5.xlarge", "InstanceCount":2 } ]' \ --use-default-roles
Phụ lục B — Cluster EMR với AWS Glue làm Spark Metastore
Các bước trên Console:
- Mở Amazon EMR console, chọn Create cluster và sau đó chọn EMR Serverless hoặc provisioned EMR.
- Trong phần Software Configuration, xác minh rằng Spark đã được cài đặt.
- Trong phần AWS Glue Data Catalog settings, chọn Use Glue Data Catalog for Spark metadata.
- Cấu hình truy cập SSH (KeyName).
- Cấu hình cài đặt mạng (VPC, subnets và security groups) để cho phép truy cập vào Amazon S3 và AWS Glue.
AWS CLI (provisioned Amazon EMR):
aws emr create-cluster \ --region us-east-1 \ --name "IcebergGlueCluster711" \ --release-label emr-7.11.0 \ --applications Name=Spark Name=Hadoop \ --ec2-attributes '{"KeyName":"<key-pair>","SubnetId":"<subnet-id>"}' \ --instance-groups '[ { "Name":"Master", "InstanceGroupType":"MASTER", "InstanceType":"m5.xlarge", "InstanceCount":1 }, { "Name":"Workers", "InstanceGroupType":"CORE", "InstanceType":"m5.xlarge", "InstanceCount":2 } ]' \ --configurations '[{"Classification":"spark-hive-site","Properties":{"hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"}}]' \ --use-default-roles
Phụ lục C — Tập dữ liệu không được phân vùng kiểu Hive và Iceberg add_files
Phụ lục này giải thích tại sao việc di chuyển tại chỗ trực tiếp bằng quy trình kiểu add_files có thể không hoạt động như mong đợi đối với các tập dữ liệu không được phân vùng kiểu Hive và đưa ra các bản sửa lỗi và ví dụ được khuyến nghị.
AWS Glue và Athena tuân theo phân vùng kiểu Hive, trong đó các giá trị cột phân vùng được mã hóa trong đường dẫn S3 thay vì bên trong các tệp dữ liệu. Ví dụ, theo tập dữ liệu Parquet được tạo trong phần Tạo tập dữ liệu Parquet mẫu làm nguồn của bài viết này:
s3://amzn-s3-demo-bucket/events/event_date=2024-09-01/hour=5/part-0000.parquets3://amzn-s3-demo-bucket/events/event_date=2024-09-02/hour=5/part-0001.parquet
- Các cột phân vùng (
event_date,hour) được biểu diễn trong cấu trúc thư mục. - Các cột không phân vùng (ví dụ:
id,name,age) vẫn nằm trong các tệp Parquet. - Iceberg
add_filescó thể ánh xạ chính xác các phân vùng dựa trên đường dẫn thư mục, ngay cả khi các cột phân vùng bị thiếu trong chính tệp Parquet.
| Partition column | Stored in path | Stored in file | Athena or AWS Glue and Iceberg behavior |
|---|---|---|---|
| event_date | Yes | Yes | Partitions inferred correctly |
| hour | Yes | No | Partitions still inferred from path |
Bố cục phân vùng không phải kiểu Hive (trường hợp có vấn đề)
s3://amzn-s3-demo-bucket/events/date/part-0000.parquets3://amzn-s3-demo-bucket/events/date/part-0001.parquet
- Không có cột phân vùng trong đường dẫn.
- Tệp có thể không chứa các cột phân vùng.
Nếu bạn cố gắng tạo một bảng Iceberg trống và tải trực tiếp nó bằng add_files trên một bố cục không phải kiểu Hive, điều sau đây sẽ xảy ra:
- Iceberg không thể tự động ánh xạ các phân vùng, các hoạt động
add_filesthất bại hoặc đăng ký các tệp với metadata phân vùng không chính xác hoặc bị thiếu. - Các truy vấn trong Athena hoặc AWS Glue sẽ trả về các giá trị NULL không mong muốn hoặc kết quả không đầy đủ.
- Các lần ghi tăng dần liên tiếp bằng
add_filessẽ thất bại.
Các phương pháp được khuyến nghị:
Tạo một bảng AWS Glue và sử dụng quy trình Iceberg snapshot:
- Tạo một bảng trong AWS Glue trỏ đến tập dữ liệu Parquet hiện có của bạn.
Bạn có thể cần cung cấp schema theo cách thủ công vì glue crawler có thể không tự động suy luận nó cho bạn.
- Sử dụng quy trình snapshot của Iceberg để chuyển đổi và di chuyển bảng AWS Glue của bạn vào bảng Iceberg đích.
Điều này hoạt động vì Iceberg dựa vào AWS Glue để suy luận schema, vì vậy phương pháp này đảm bảo ánh xạ chính xác các cột và phân vùng mà không cần ghi lại dữ liệu. Để biết thêm thông tin, hãy xem Quy trình Snapshot.
Phụ lục D — Hiểu các loại bảng: Managed so với external
Theo mặc định, tất cả các bảng không phải Iceberg được tạo trong AWS Glue hoặc Athena đều là external tables, Athena không quản lý dữ liệu cơ bản. Nếu bạn sử dụng CREATE TABLE mà không có từ khóa EXTERNAL cho các bảng không phải Iceberg, Athena sẽ đưa ra lỗi.
Tuy nhiên, khi làm việc với các bảng Iceberg, AWS Glue và Athena cũng quản lý dữ liệu cơ bản cho các bảng tương ứng, vì vậy các bảng này được coi là internal tables.
Chạy DROP TABLE trên các bảng Iceberg sẽ xóa bảng và dữ liệu cơ bản.
Bảng sau mô tả cách tác động của các hành động DELETE và DROP TABLE trên các bảng Iceberg trong AWS Glue và Athena:
| Operation | What it does | Effect on S3 data |
|---|---|---|
| DELETE FROM mydb.products_iceberg WHERE date = 2025-10-06; | Creates new snapshot, hides deleted rows | Data files stay until cleanup |
| DROP TABLE test_db.table1; | Deletes table and all data | Files are permanently removed |
Về tác giả

Mihir Borkar
Mihir là một Kiến trúc sư dữ liệu AWS dày dặn kinh nghiệm với gần một thập kỷ kinh nghiệm thiết kế và triển khai các giải pháp dữ liệu quy mô doanh nghiệp trên AWS. Anh chuyên hiện đại hóa kiến trúc dữ liệu bằng cách sử dụng các dịch vụ phân tích dữ liệu AWS, thiết kế các data lake và nền tảng phân tích có khả năng mở rộng với trọng tâm vào các giải pháp hiệu quả, tiết kiệm chi phí. Trong thời gian rảnh rỗi, Mihir thích đọc về các công nghệ đám mây mới nổi và khám phá những phát triển mới nhất trong AI/ML.

Amit Maindola
Amit là một Kiến trúc sư dữ liệu cấp cao trong nhóm AWS ProServe, tập trung vào kỹ thuật dữ liệu, phân tích và AI/ML tại Amazon Web Services. Anh giúp khách hàng trong hành trình chuyển đổi kỹ thuật số của họ và cho phép họ xây dựng các giải pháp phân tích dựa trên đám mây có khả năng mở rộng cao, mạnh mẽ và an toàn trên AWS để thu thập thông tin chi tiết kịp thời và đưa ra các quyết định kinh doanh quan trọng.

Arghya Banerjee
Arghya là Kiến trúc sư giải pháp cấp cao tại AWS ở Khu vực Vịnh San Francisco, tập trung vào việc giúp khách hàng áp dụng và sử dụng AWS Cloud. Anh tập trung vào dữ liệu lớn, data lake, các dịch vụ phân tích streaming và batch, và các công nghệ AI tạo sinh.
