Tác giả: Praveen Gadi, Damian Pukaluk, Scott Mishra, and Paul Wu
Ngày phát hành: 26 MAR 2026
Chuyên mục: Advanced (300), Amazon Polly, Announcements, Artificial Intelligence, Customer Solutions, Launch, Technical How-to
Xây dựng trải nghiệm đàm thoại tự nhiên đòi hỏi khả năng tổng hợp giọng nói phải theo kịp các tương tác thời gian thực. Hôm nay, chúng tôi vui mừng thông báo về API Bidirectional Streaming mới cho Amazon Polly, cho phép tổng hợp văn bản thành giọng nói (TTS) theo thời gian thực một cách hợp lý, nơi bạn có thể bắt đầu gửi văn bản và nhận âm thanh đồng thời.
API mới này được xây dựng cho các ứng dụng AI đàm thoại tạo văn bản hoặc âm thanh một cách tăng dần, như các phản hồi từ các mô hình ngôn ngữ lớn (LLM), nơi người dùng phải bắt đầu tổng hợp âm thanh trước khi toàn bộ văn bản có sẵn. Amazon Polly đã hỗ trợ streaming âm thanh đã tổng hợp trở lại người dùng. API mới này tiến xa hơn bằng cách tập trung vào giao tiếp hai chiều qua HTTP/2, cho phép tăng tốc độ, giảm độ trễ và sử dụng hợp lý hơn.
Thách thức với tổng hợp giọng nói truyền thống
Các API chuyển văn bản thành giọng nói truyền thống tuân theo mô hình yêu cầu-phản hồi. Điều này yêu cầu bạn phải thu thập toàn bộ văn bản trước khi thực hiện yêu cầu tổng hợp. Amazon Polly streaming âm thanh trở lại một cách tăng dần sau khi yêu cầu được thực hiện, nhưng nút thắt cổ chai nằm ở phía đầu vào—bạn không thể bắt đầu gửi văn bản cho đến khi nó hoàn toàn có sẵn. Trong các ứng dụng đàm thoại được hỗ trợ bởi LLM, nơi văn bản được tạo ra từng token một, điều này có nghĩa là phải chờ toàn bộ phản hồi trước khi quá trình tổng hợp bắt đầu.
Hãy xem xét một trợ lý ảo được hỗ trợ bởi một LLM. Mô hình tạo ra các token tăng dần trong vài giây. Với TTS truyền thống, người dùng phải chờ đợi:
- LLM hoàn thành việc tạo ra toàn bộ phản hồi
- Dịch vụ TTS tổng hợp toàn bộ văn bản
- Âm thanh được tải xuống trước khi phát lại bắt đầu
API streaming hai chiều mới của Amazon Polly được thiết kế để giải quyết những nút thắt cổ chai này.
Điều gì mới: Bidirectional Streaming
API StartSpeechSynthesisStream giới thiệu một cách tiếp cận khác biệt cơ bản:
- Gửi văn bản tăng dần: Streaming văn bản đến Amazon Polly khi nó có sẵn—không cần chờ đợi các câu hoặc đoạn văn hoàn chỉnh.
- Nhận âm thanh ngay lập tức: Nhận các byte âm thanh đã tổng hợp trở lại theo thời gian thực khi chúng được tạo ra.
- Kiểm soát thời gian tổng hợp: Sử dụng cấu hình flush để kích hoạt tổng hợp ngay lập tức văn bản đã được đệm.
- Giao tiếp song công thực sự: Gửi và nhận đồng thời qua một kết nối duy nhất.
Các thành phần chính
| Thành phần | Hướng sự kiện | Hướng | Mục đích |
|---|---|---|---|
TextEvent | Inbound | Client → Amazon Polly | Gửi văn bản để tổng hợp |
CloseStreamEvent | Inbound | Client → Amazon Polly | Báo hiệu kết thúc đầu vào văn bản |
AudioEvent | Outbound | Amazon Polly → Client | Nhận các đoạn âm thanh đã tổng hợp |
StreamClosedEvent | Outbound | Amazon Polly → Client | Xác nhận hoàn thành luồng |
So sánh với các phương pháp truyền thống
Triển khai tách tệp truyền thống
Trước đây, để đạt được TTS độ trễ thấp yêu cầu các triển khai ở cấp ứng dụng:
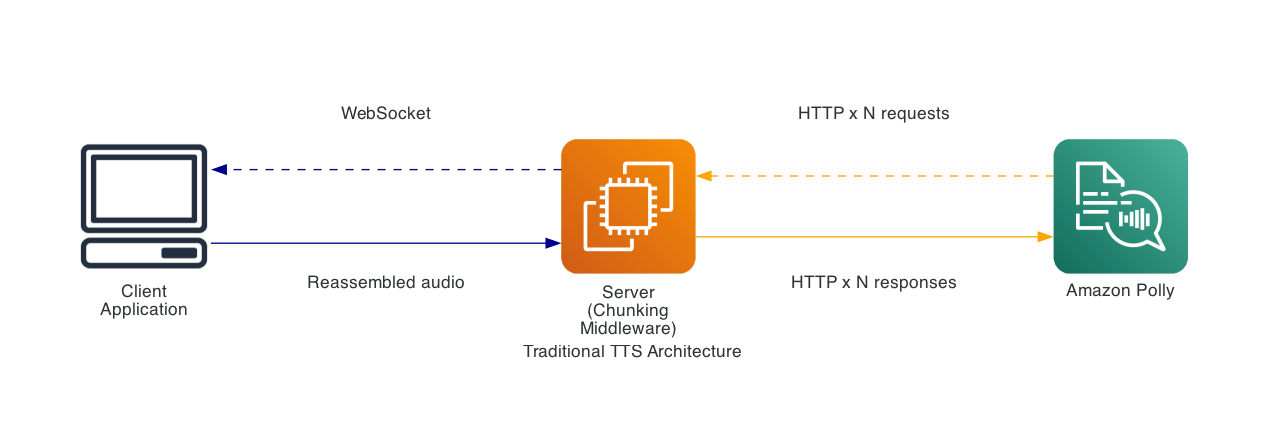
Cách tiếp cận này yêu cầu:
- Logic tách văn bản phía máy chủ
- Nhiều lượt gọi API Amazon Polly song song
- Tái tạo âm thanh phức tạp
Sau: Native Bidirectional Streaming

Lợi ích:
- Không yêu cầu logic tách biệt
- Một kết nối liên tục duy nhất
- Streaming gốc theo cả hai hướng
- Giảm độ phức tạp của cơ sở hạ tầng
- Độ trễ thấp hơn
Điểm chuẩn hiệu suất
Để đo lường tác động thực tế, chúng tôi đã chấm điểm cả API SynthesizeSpeech truyền thống và API StartSpeechSynthesisStream hai chiều mới với cùng một đầu vào: 7.045 ký tự văn xuôi (970 từ), sử dụng giọng Matthew với Generative engine, đầu ra MP3 ở 24kHz trong us-west-2.
Cách chúng tôi đo lường: Cả hai thử nghiệm đều mô phỏng một LLM tạo ra các token với tốc độ ~30 ms mỗi từ. Thử nghiệm API truyền thống đệm các từ cho đến khi đạt đến ranh giới câu, sau đó gửi câu hoàn chỉnh dưới dạng yêu cầu SynthesizeSpeech và chờ phản hồi âm thanh đầy đủ trước khi tiếp tục. Các thử nghiệm này phản ánh cách các tích hợp TTS truyền thống hoạt động, bởi vì bạn phải có câu hoàn chỉnh trước khi yêu cầu tổng hợp. Thử nghiệm API streaming hai chiều gửi từng từ đến luồng khi nó đến, cho phép Amazon Polly bắt đầu tổng hợp trước khi toàn bộ văn bản có sẵn. Cả hai thử nghiệm đều sử dụng cùng một văn bản, giọng nói và cấu hình đầu ra.
| Chỉ số | SynthesizeSpeech truyền thống | Bidirectional Streaming | Cải thiện |
|---|---|---|---|
| Tổng thời gian xử lý | 115.226 ms (~115s) | 70.071 ms (~70s) | Nhanh hơn 39% |
| Lượt gọi API | 27 | 1 | Ít hơn 27 lần |
| Số câu được gửi | 27 (tuần tự) | 27 (streaming khi từ đến) | — |
| Tổng số byte âm thanh | 2.354.292 | 2.324.636 | — |
Ưu điểm chính là về kiến trúc: API hai chiều cho phép gửi văn bản đầu vào và nhận âm thanh đã tổng hợp đồng thời qua một kết nối duy nhất. Thay vì chờ đợi từng câu tích lũy trước khi yêu cầu tổng hợp, văn bản được streaming đến Amazon Polly từng từ một khi LLM tạo ra nó. Đối với AI đàm thoại, điều này có nghĩa là Amazon Polly nhận và xử lý văn bản một cách tăng dần trong suốt quá trình tạo, thay vì nhận tất cả cùng một lúc sau khi LLM hoàn thành. Kết quả là giảm thời gian chờ tổng hợp sau khi quá trình tạo hoàn tất—độ trễ tổng thể từ lời nhắc đến âm thanh được phân phối hoàn chỉnh giảm đáng kể.
Triển khai kỹ thuật
Bắt đầu
Bạn có thể sử dụng API streaming hai chiều với AWS SDK cho Java-2x, JavaScript v3, .NET v4, C++, Go v2, Kotlin, PHP v3, Ruby v3, Rust và Swift. Hiện tại không hỗ trợ cho CLIs (AWS Command Line Interface (AWS CLI) v1 và v2, PowerShell v4 và v5), Python, .NET v3. Dưới đây là một ví dụ:
// Create the async Polly clientPollyAsyncClient pollyClient = PollyAsyncClient.builder().region(Region.US_WEST_2).credentialsProvider(DefaultCredentialsProvider.create()).build();// Create the stream requestStartSpeechSynthesisStreamRequest request = StartSpeechSynthesisStreamRequest.builder().voiceId(VoiceId.JOANNA).engine(Engine.GENERATIVE).outputFormat(OutputFormat.MP3).sampleRate("24000").build();
Gửi sự kiện văn bản
Văn bản được gửi đến Amazon Polly bằng cách sử dụng một Publisher reactive streams. Mỗi TextEvent chứa văn bản:
TextEvent textEvent = TextEvent.builder() .text("Hello, this is streaming text-to-speech!") .build();
Xử lý sự kiện âm thanh
Âm thanh đến thông qua một response handler với một visitor pattern:
StartSpeechSynthesisStreamResponseHandler responseHandler =StartSpeechSynthesisStreamResponseHandler.builder().onResponse(response -> System.out.println("Stream connected")).onError(error -> handleError(error)).subscriber(StartSpeechSynthesisStreamResponseHandler.Visitor.builder().onAudioEvent(audioEvent -> {// Process audio chunk immediatelybyte[] audioData = audioEvent.audioChunk().asByteArray();playOrBufferAudio(audioData);}).onStreamClosedEvent(event -> {System.out.println("Synthesis complete. Characters processed: "+ event.requestCharacters());}).build()).build();
Ví dụ hoàn chỉnh: streaming văn bản từ một LLM
Dưới đây là một ví dụ thực tế cho thấy cách tích hợp streaming hai chiều với việc tạo văn bản tăng dần:
public class LLMIntegrationExample {private final PollyAsyncClient pollyClient;private Subscriber<? super StartSpeechSynthesisStreamActionStream> textSubscriber;/** * Start a bidirectional stream and return a handle for sending text. */public CompletableFuture<Void> startStream(VoiceId voice, AudioConsumer audioConsumer) {StartSpeechSynthesisStreamRequest request = StartSpeechSynthesisStreamRequest.builder().voiceId(voice).engine(Engine.GENERATIVE).outputFormat(OutputFormat.PCM).sampleRate("16000").build();// Publisher that allows external text injectionPublisher<StartSpeechSynthesisStreamActionStream> textPublisher = subscriber -> {this.textSubscriber = subscriber;subscriber.onSubscribe(new Subscription() {@Overridepublic void request(long n) { /* Demand-driven by subscriber */ }@Overridepublic void cancel() { textSubscriber = null; }});};StartSpeechSynthesisStreamResponseHandler handler =StartSpeechSynthesisStreamResponseHandler.builder().subscriber(StartSpeechSynthesisStreamResponseHandler.Visitor.builder().onAudioEvent(event -> {if (event.audioChunk() != null) {audioConsumer.accept(event.audioChunk().asByteArray());}}).onStreamClosedEvent(event -> audioConsumer.complete()).build()).build();return pollyClient.startSpeechSynthesisStream(request, textPublisher, handler);}/** * Send text file to the stream. Call this as LLM tokens arrive. */public void sendText(String text, boolean flush) {if (textSubscriber != null) {TextEvent event = TextEvent.builder().text(text).flushStreamConfiguration(FlushStreamConfiguration.builder().force(flush).build()).build();textSubscriber.onNext(event);}}/** * Close the stream when text generation is complete.*/public void closeStream() {if (textSubscriber != null) {textSubscriber.onNext(CloseStreamEvent.builder().build());textSubscriber.onComplete();}}}
Mô hình tích hợp với LLM streaming
Sau đây cho thấy cách tích hợp các mô hình với LLM streaming:
// Start the Polly streampollyStreamer.startStream(VoiceId.JOANNA, audioPlayer::playChunk);// As LLM generates tokens...llmClient.streamCompletion(prompt, token -> {// Send each token to Polly//Optionally Flush at sentence boundaries to force synthesis//note the tradeoff here: you may get the audio sooner, but audio quality may be impactedboolean isSentenceEnd = token.endsWith(".") || token.endsWith("!") || token.endsWith("?");pollyStreamer.sendText(token, isSentenceEnd);});// When LLM completespollyStreamer.closeStream();
Lợi ích kinh doanh
Cải thiện trải nghiệm người dùng
Độ trễ ảnh hưởng trực tiếp đến sự hài lòng của người dùng. Người dùng nghe phản hồi càng nhanh, tương tác càng tự nhiên và hấp dẫn. API streaming hai chiều cho phép:
- Giảm thời gian chờ đợi nhận thấy – Phát lại âm thanh bắt đầu trong khi LLM vẫn đang tạo, che giấu thời gian xử lý backend.
- Tăng cường tương tác – Tương tác nhanh hơn, phản hồi tốt hơn dẫn đến tăng khả năng giữ chân người dùng và sự hài lòng.
- Triển khai hợp lý – Việc thiết lập và quản lý giải pháp streaming giờ đây là một lượt gọi API duy nhất với các hook và callback rõ ràng để loại bỏ sự phức tạp.
Giảm chi phí vận hành
Hợp lý hóa kiến trúc của bạn trực tiếp dẫn đến tiết kiệm chi phí:
| Yếu tố chi phí | Phân đoạn truyền thống | Bidirectional Streaming |
|---|---|---|
| Cơ sở hạ tầng | Máy chủ WebSocket, bộ cân bằng tải, middleware phân đoạn | Kết nối trực tiếp từ client đến Amazon Polly |
| Phát triển | Logic phân đoạn tùy chỉnh, tái tạo âm thanh, xử lý lỗi | SDK xử lý độ phức tạp |
| Bảo trì | Nhiều thành phần cần giám sát và cập nhật | Điểm tích hợp duy nhất |
| Lượt gọi API | Nhiều lượt gọi cho mỗi yêu cầu (một cho mỗi đoạn) | Một phiên streaming duy nhất |
Các tổ chức có thể mong đợi giảm chi phí cơ sở hạ tầng bằng cách loại bỏ các máy chủ trung gian và giảm thời gian phát triển bằng cách sử dụng khả năng streaming gốc.
Các trường hợp sử dụng
API streaming hai chiều được khuyến nghị cho:
- Conversational AI Assistants – Streaming phản hồi của LLM trực tiếp thành giọng nói
- Real-time Translation – Tổng hợp văn bản đã dịch khi nó được tạo ra
- Interactive Voice Response (IVR) – Hệ thống điện thoại động, phản hồi nhanh
- Accessibility Tools – Trình đọc màn hình và chuyển văn bản thành giọng nói thời gian thực
- Gaming – Dynamic NPC dialogue và tường thuật
- Live Captioning – Đầu ra âm thanh cho các hệ thống chuyển giọng nói thành văn bản trực tiếp
Kết luận
API Bidirectional Streaming mới cho Amazon Polly đại diện cho một bước tiến đáng kể trong tổng hợp giọng nói thời gian thực. Bằng cách cho phép streaming thực sự theo cả hai hướng, nó loại bỏ các nút thắt cổ chai về độ trễ vốn đã gây khó khăn cho các ứng dụng AI đàm thoại.
Những điểm chính:
- Giảm độ trễ – Âm thanh bắt đầu phát trong khi văn bản vẫn đang được tạo
- Kiến trúc đơn giản hóa – Không cần các giải pháp thay thế tách tệp hoặc cơ sở hạ tầng phức tạp
- Tích hợp LLM gốc – Được xây dựng có mục đích để streaming văn bản từ các mô hình ngôn ngữ
- Kiểm soát linh hoạt – Kiểm soát chi tiết thời gian tổng hợp với cấu hình flush
Cho dù bạn đang xây dựng một trợ lý ảo, công cụ hỗ trợ tiếp cận hay bất kỳ ứng dụng nào yêu cầu chuyển văn bản thành giọng nói phản hồi nhanh, API streaming hai chiều cung cấp nền tảng cho những trải nghiệm đàm thoại thực sự.
Các bước tiếp theo
API streaming hai chiều hiện đã có sẵn rộng rãi (Generally Available). Để bắt đầu:
- Cập nhật lên AWS SDK for Java 2.x mới nhất với hỗ trợ streaming hai chiều
- Xem lại tài liệu API để tham khảo chi tiết
- Thử mã ví dụ trong bài viết này để trải nghiệm streaming độ trễ thấp
Chúng tôi rất vui được xem bạn sẽ xây dựng những gì với khả năng mới này. Hãy chia sẻ phản hồi và các trường hợp sử dụng của bạn với chúng tôi!
Về tác giả

Scott Mishra
Scott là Kiến trúc sư Giải pháp cấp cao cho Amazon Web Services. Scott là một cố vấn kỹ thuật đáng tin cậy, giúp khách hàng doanh nghiệp thiết kế và triển khai các giải pháp đám mây ở quy mô lớn. Anh ấy thúc đẩy sự thành công của khách hàng thông qua khả năng lãnh đạo kỹ thuật, hướng dẫn kiến trúc và giải quyết vấn đề sáng tạo khi làm việc với các công nghệ đám mây tiên tiến. Scott chuyên về các giải pháp AI tạo sinh.

Praveen Gadi
Praveen là Kiến trúc sư Giải pháp cấp cao cho Amazon Web Services. Praveen là một cố vấn kỹ thuật đáng tin cậy cho các khách hàng doanh nghiệp. Anh ấy giúp khách hàng đạt được mục tiêu kinh doanh và tối đa hóa khoản đầu tư vào đám mây của họ. Praveen chuyên về các giải pháp tích hợp và năng suất của nhà phát triển.

Paul Wu
Paul là Kiến trúc sư Giải pháp cho Amazon Web Services. Paul là một cố vấn kỹ thuật đáng tin cậy cho các khách hàng doanh nghiệp. Anh ấy giúp khách hàng đạt được mục tiêu kinh doanh và tối đa hóa khoản đầu tư vào đám mây của họ.

Damian Pukaluk
Damian là Kỹ sư Phát triển Phần mềm tại AWS Polly.
