Tác giả: Nika Mishurina, Bharat Venkat, Dan Iancu, and James Rehfeld
Ngày phát hành: 01 APR 2026
Chuyên mục: Advanced (300), Amazon Rekognition, Amazon SageMaker AI, Amazon SageMaker Ground Truth, Architecture, Technical How-to
An toàn tại nơi làm việc đã được cải thiện đáng kể trong vài thập kỷ qua. Theo Cục Thống kê Lao động, tỷ lệ tai nạn lao động tại Hoa Kỳ đã giảm hơn 60% kể từ đầu những năm 1970. Điều này được thúc đẩy bởi các quy định chặt chẽ hơn, chương trình đào tạo tốt hơn và văn hóa hoạt động ưu tiên an toàn ngày càng phát triển. Mặc dù có những tiến bộ này, Tổ chức Lao động Quốc tế báo cáo rằng 395 triệu công nhân trên toàn thế giới vẫn bị thương tích không gây tử vong mỗi năm, và Hội đồng An toàn Quốc gia ước tính rằng tai nạn lao động đã gây thiệt hại cho nền kinh tế Hoa Kỳ 176,5 tỷ USD vào năm 2023.
Thách thức không còn là thiếu cam kết về an toàn, mà là những hạn chế của các phương pháp giám sát truyền thống. Kiểm tra an toàn thủ công, mặc dù có giá trị, chỉ bao phủ một phần nhỏ các khu vực hoạt động và tạo ra các ảnh chụp nhanh tại một thời điểm thay vì giám sát liên tục. Khi các tổ chức mở rộng quy mô trên hàng trăm cơ sở, dù là nhà máy sản xuất, trung tâm phân phối, sân bay, công trường xây dựng hay môi trường phòng thí nghiệm, việc duy trì khả năng hiển thị nhất quán, theo thời gian thực về việc tuân thủ Thiết bị Bảo hộ Cá nhân (PPE) và giám sát mối nguy hiểm dựa trên khu vực ngày càng trở nên khó khăn.
Theo OSHA, các trường hợp tử vong và thương tích do va chạm với phương tiện có thể phòng ngừa 100%, nhưng chúng vẫn là nguyên nhân hàng đầu gây tử vong tại nơi làm việc. Tuy nhiên, 90% các chấn thương mắt tại nơi làm việc có thể tránh được bằng cách đeo kính bảo hộ, theo Học viện Nhãn khoa Hoa Kỳ.
Thị giác máy tính và AI tạo sinh đại diện cho sự phát triển tiếp theo trong an toàn nơi làm việc, không thay thế các chương trình an toàn hiện có, mà bổ sung chúng bằng giám sát tự động, liên tục, có thể mở rộng trên các cơ sở 24/7. Bài đăng này mô tả một giải pháp sử dụng mạng lưới camera cố định để giám sát môi trường hoạt động gần như theo thời gian thực, phát hiện các mối nguy hiểm tiềm ẩn trong khi thu thập các hình chiếu đối tượng trên sàn và mối quan hệ của chúng với các vạch kẻ sàn. Mặc dù chúng tôi minh họa cách tiếp cận thông qua các ví dụ triển khai trung tâm phân phối, kiến trúc cơ bản áp dụng rộng rãi trên các ngành công nghiệp. Chúng tôi khám phá các quyết định kiến trúc, chiến lược mở rộng quy mô lên hàng trăm địa điểm, giảm thời gian triển khai địa điểm, tạo dữ liệu tổng hợp bằng các công cụ AI tạo sinh như GLIGEN và các trở ngại kỹ thuật quan trọng khác mà chúng tôi đã vượt qua.
Tổng quan giải pháp
Giải pháp thị giác máy tính của chúng tôi sử dụng kiến trúc phi máy chủ, hướng sự kiện được thiết kế để mở rộng hiệu quả trên hàng nghìn camera và xử lý khối lượng lớn dữ liệu hình ảnh để phát hiện rủi ro. Hệ thống bao gồm những điều sau:
- Một mô hình học máy (ML) xác định các mối nguy hiểm an toàn tại nơi làm việc
- Xử lý dữ liệu hình ảnh theo thời gian thực cho các rủi ro mới nổi
- Phương pháp chú thích phát hiện kép thu thập cả đường viền đối tượng và hình chiếu trên sàn của chúng so với các vạch kẻ an toàn.
Hệ thống làm mờ khuôn mặt người và các đặc điểm nhận dạng để giúp bảo vệ PII trong khi vẫn duy trì độ chính xác phát hiện mối nguy hiểm. Để duy trì bảo mật và phân tách hoạt động phù hợp, giải pháp được phân phối trên nhiều tài khoản AWS. Chúng tôi đã tách biệt quy trình huấn luyện, cơ sở hạ tầng thu thập hình ảnh, ứng dụng web của người dùng cuối và tạo một tài khoản phân tích chuyên dụng cho nhóm BI để phát triển các giải pháp báo cáo và phân tích thành các môi trường riêng biệt với các kiểm soát truy cập và cách ly dữ liệu phù hợp. Hệ thống liên tục học hỏi để cải thiện độ chính xác phát hiện. Các nhà quản lý an toàn sử dụng bảng điều khiển giám sát để theo dõi và phản ứng với các mối nguy hiểm. Sơ đồ kiến trúc sau đây minh họa cách các thành phần này hoạt động cùng nhau để tạo ra một giải pháp giám sát an toàn end-to-end.
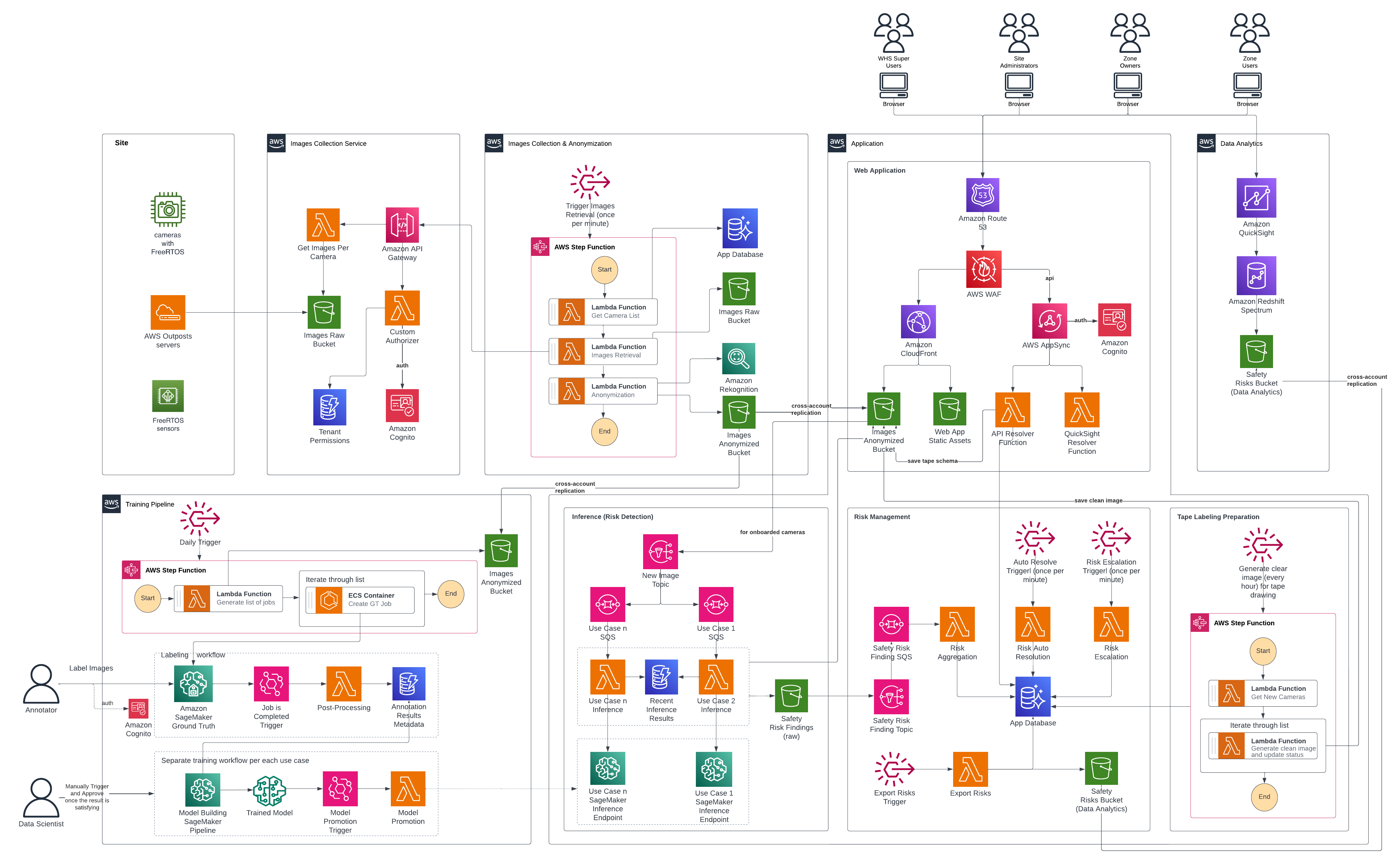
Hệ thống triển khai cấu trúc kiểm soát truy cập dựa trên vai trò phân cấp với bốn loại người dùng.
- Super Users là quản trị viên hệ thống có khả năng hiển thị toàn tổ chức, chịu trách nhiệm khởi tạo triển khai địa điểm và giám sát tình trạng hệ thống.
- Site Administrators hoạt động ở cấp cơ sở, cấu hình các vùng và quản lý quyền trong địa điểm của họ.
- Zone Owners đóng vai trò vận hành quan trọng—họ nhận và khắc phục các thông báo rủi ro an toàn, hoàn thành các công việc dán nhãn băng keo để xác minh độ chính xác phát hiện và thực hiện cấu hình triển khai camera. Hệ thống chỉ bắt đầu phát hiện rủi ro tự động sau khi Zone Owners hoàn thành toàn bộ quá trình cấu hình, để các tham số được thiết lập đúng cách.
- Zone Users có quyền truy cập chỉ đọc vào các rủi ro và cảnh báo mà không có khả năng cấu hình.
Thu thập và ẩn danh hình ảnh
Quy trình làm việc bắt đầu bằng việc thu thập hình ảnh tự động từ các camera địa điểm đã được cấu hình và ủy quyền thông qua một dịch vụ hình ảnh chuyên dụng cung cấp khả năng chụp ảnh định kỳ. Hình ảnh thô ban đầu được lưu trữ trong một bucket Amazon Simple Storage Service (Amazon S3) trong một tài khoản riêng biệt, bị hạn chế truy cập, nơi chúng ngay lập tức trải qua quá trình ẩn danh. Sau khi quá trình ẩn danh hoàn tất, hình ảnh thô sẽ tự động bị xóa khỏi bucket trong vòng vài ngày, theo chính sách lưu giữ của tổ chức. Amazon Rekognition phát hiện khuôn mặt của các cá nhân có mặt trong hình ảnh, và mã Python tùy chỉnh sau đó áp dụng một lớp phủ để làm mờ các khuôn mặt được phát hiện, giúp bảo vệ quyền riêng tư. Các hình ảnh đã được ẩn danh được sao chép trên nhiều tài khoản AWS phục vụ các mục đích khác nhau: huấn luyện các mô hình thị giác máy tính, chạy suy luận để phát hiện các mối nguy hiểm an toàn và cung cấp năng lượng cho ứng dụng web của người dùng cuối nơi Zone Users giám sát và phản ứng với các rủi ro được phát hiện. Ứng dụng web hiển thị các hình ảnh đã được ẩn danh, được chú thích bằng các chỉ báo trực quan cho PPE bị thiếu như một ví dụ hoặc các mối nguy hiểm an toàn tiềm ẩn khác. Phản hồi trực quan rõ ràng này loại bỏ việc đoán mò để Zone Users có thể nhanh chóng hiểu mối nguy hiểm nào đã được xác định và vị trí của nó trên sàn cơ sở, tạo điều kiện cho phản ứng và khắc phục nhanh chóng. Ngoài ra, họ có thể điều chỉnh tổ chức sơ đồ sàn xác định các khu vực chính xác nơi công nhân được yêu cầu đeo PPE hoặc các đối tượng và thiết bị khác được đặt theo quy tắc và dán băng keo 5S.
Quy trình huấn luyện và quảng bá mô hình
Các hệ thống học máy cần các bộ dữ liệu ground truth chất lượng cao. Các ví dụ được gắn nhãn này dạy các mô hình xác định và phân loại các mối nguy hiểm an toàn. Gắn nhãn dữ liệu là quá trình các nhà chú thích con người xem xét hình ảnh và chú thích tỉ mỉ các đối tượng, hành vi và điều kiện quan tâm. Ví dụ, vẽ các hộp giới hạn xung quanh các vật cản trong lối đi, xác định công nhân không có PPE phù hợp hoặc đánh dấu các ranh giới băng keo sàn. Dữ liệu huấn luyện chất lượng kém tạo ra các mô hình không đáng tin cậy, bỏ sót các mối nguy hiểm an toàn hoặc tạo ra các cảnh báo sai, làm xói mòn lòng tin của người dùng. Ngược lại, đầu tư vào dữ liệu huấn luyện chất lượng cao, được gắn nhãn chính xác—với các chú thích rõ ràng, nhất quán được xem xét bởi các chuyên gia trong lĩnh vực—cho phép mô hình phát hiện các rủi ro thực sự với độ chính xác và độ tin cậy. Điều này cuối cùng quyết định sự thành công hay thất bại của toàn bộ hệ thống giám sát an toàn. Như được mô tả sau trong bài đăng này, việc tạo dữ liệu tổng hợp có thể bổ sung hoặc có khả năng thay thế chú thích thủ công cho các trường hợp sử dụng cụ thể nơi các ví dụ trong thế giới thực khan hiếm hoặc tốn nhiều công sức để thu thập.
Sau khi hình ảnh đã được ẩn danh được thu thập và lưu trữ vào Amazon S3, quy trình làm việc AWS Step Functions tạo GT Job sẽ tạo các công việc gắn nhãn Amazon SageMaker Ground Truth cho các trường hợp sử dụng cần thiết và các địa điểm và camera được giám sát. Step Function này được kích hoạt theo một nhịp độ cấu hình được định kỳ bởi một quy tắc Amazon EventBridge. Nó tích hợp với phản hồi của Zone User và các dự đoán mô hình ML đã lưu, để các nhà khoa học dữ liệu có thể ưu tiên các lớp và camera hoạt động kém khác nhau. Một nhóm các nhà chú thích chuyên dụng sau đó hoàn thành các công việc. Các công việc đã hoàn thành trải qua quá trình xử lý hậu kỳ bằng AWS Lambda để chuyển đổi chúng thành định dạng phù hợp cho việc huấn luyện. Quy trình xử lý hậu kỳ lưu trữ siêu dữ liệu công việc như các camera và lớp được bao gồm, vào Amazon DynamoDB, trong khi các chú thích được lưu trữ trong một S3 Bucket. Sau khi dữ liệu huấn luyện sẵn sàng, các nhà khoa học dữ liệu kích hoạt các quy trình xây dựng mô hình Amazon SageMaker AI Pipelines bằng cách sử dụng các script cho phép lựa chọn siêu tham số và dữ liệu GT linh hoạt. SageMaker AI Pipeline bao gồm bảy bước:
- Bước tải checkpoint
- Bước chuẩn bị và chia tách dữ liệu
- Bước huấn luyện mô hình
- Bước tạo đường cơ sở độ lệch
- Bước đánh giá mô hình
- Bước đóng gói mô hình
- Bước đăng ký mô hình
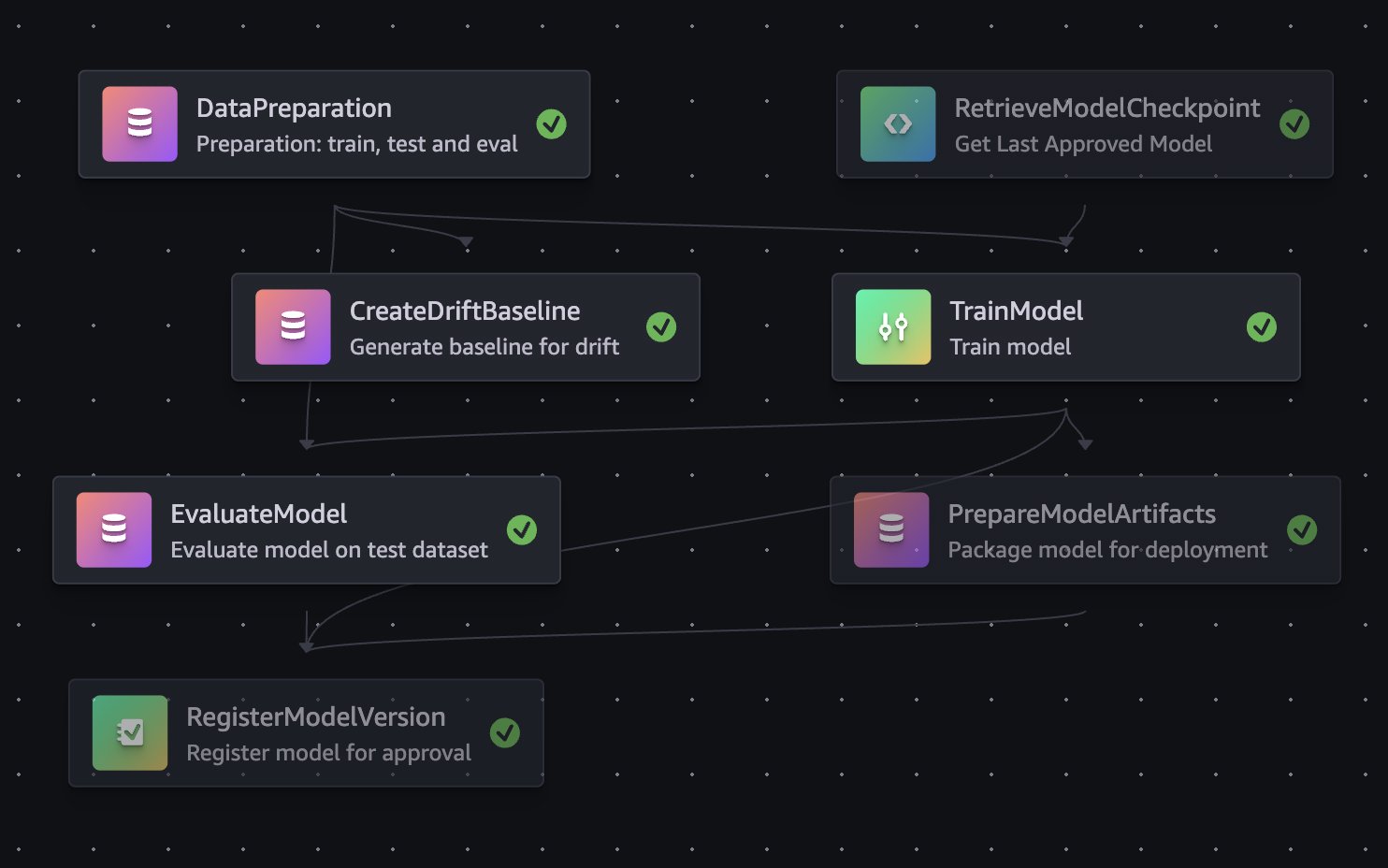
Các nhà khoa học dữ liệu xem xét các số liệu đánh giá mô hình đã được huấn luyện và phê duyệt các mô hình mà họ muốn sử dụng trong quy trình suy luận. Việc phê duyệt mô hình kích hoạt một sự kiện EventBridge, sự kiện này kích hoạt Lambda quảng bá mô hình. Lambda quảng bá mô hình tạo một đánh giá mã đối với kho lưu trữ mã cơ sở hạ tầng ứng dụng để cập nhật Amazon S3 URI của mô hình được sử dụng cho SageMaker AI endpoint. Quy trình làm việc này tách biệt các bản cập nhật khoa học và ứng dụng. Các nhà khoa học phê duyệt các mô hình khi các số liệu đánh giá đáp ứng tiêu chí chấp nhận. Các kỹ sư phần mềm sau đó có thể hợp nhất và quản lý các bản cập nhật endpoint giống như các thay đổi phần mềm và cơ sở hạ tầng khác thông qua các quy trình tích hợp và phân phối liên tục (CI/CD). Sau khi đánh giá mã được thông qua, hệ thống sẽ cập nhật SageMaker AI Endpoint tương ứng và quy trình suy luận sẽ sử dụng endpoint đã cập nhật. Các checkpoint mô hình đã được phê duyệt cũng được sử dụng làm cơ sở cho các lần huấn luyện lại trong tương lai, cho phép cải tiến gia tăng nhanh chóng mà không cần các công việc huấn luyện chạy dài thường xuyên.
Quy trình suy luận
Mỗi trường hợp sử dụng hoạt động thông qua quy trình suy luận riêng, cùng nhau cung cấp khả năng giám sát an toàn toàn diện. Hệ thống hoạt động như một giám sát viên an toàn kỹ thuật số, liên tục giám sát các hoạt động của cơ sở và phân biệt giữa quy trình làm việc bình thường và các mối nguy hiểm tiềm ẩn. Khi một hình ảnh được đưa vào S3 bucket đã được ẩn danh, nó sẽ kích hoạt một thông báo Amazon Simple Notification Service (Amazon SNS) được định tuyến đến một hàng đợi Amazon Simple Queue Service (Amazon SQS) chuyên dụng. Mỗi trường hợp sử dụng được xử lý độc lập thông qua hàng đợi riêng, hàng đợi này gọi một SageMaker AI Endpoint lưu trữ một mô hình thị giác máy tính được tùy chỉnh cho kịch bản đó. Ví dụ, phát hiện thiết bị vận hành, xác định công nhân có thiết bị an toàn hoặc giám sát các điều kiện quan trọng khác về an toàn. Phần “Phát hiện cảnh báo thông minh” trình bày chi tiết cách hệ thống xác thực và leo thang các phát hiện. Các vi phạm được xác nhận tạo ra các cảnh báo chứa loại đối tượng, vị trí chính xác và thời gian vi phạm. Bằng chứng trực quan bao gồm cả hình ảnh gốc được chụp từ camera và phiên bản được chú thích với các lớp phủ được mã hóa màu: đường viền màu xanh lam đánh dấu các khu vực bị hạn chế, đường viền màu đỏ làm nổi bật các đối tượng vi phạm và điểm tin cậy gắn nhãn cho mỗi phát hiện. Sau đó, hệ thống phân phối các cảnh báo thông qua các kênh song song. DynamoDB lưu trữ các bản ghi vi phạm có cấu trúc cho phép truy vấn nhanh. Các sự kiện Amazon S3 kích hoạt xử lý và thông báo downstream. Các lỗi được theo dõi trong các Dead Letter Queues (DLQs) cụ thể cho từng trường hợp sử dụng, nơi chúng có thể được phân tích hoặc xử lý lại sau này.
Quản lý rủi ro
Khi quy trình suy luận phát hiện các mối nguy hiểm tiềm ẩn và lưu chúng vào S3 bucket chuyên dụng, nó sẽ kích hoạt một hàm Lambda bằng cách sử dụng Amazon SNS và SQS. Hàm này tổng hợp thông minh các rủi ro cho mỗi camera theo từng trường hợp sử dụng để tránh tình trạng quá tải cảnh báo. Thay vì làm phiền các nhóm an toàn bằng các thông báo trùng lặp, hệ thống sẽ thêm các sự cố mới vào các rủi ro đang mở hiện có. Mỗi phút, một lịch trình Amazon EventBridge sẽ kích hoạt một hàm Lambda kiểm tra xem các rủi ro có còn xuất hiện trong các hình ảnh camera mới nhất hay không. Nếu một vi phạm đã được giải quyết, hệ thống sẽ tự động đóng nó. Đồng thời, một hàm được lên lịch khác sẽ giám sát xem SLA để giải quyết rủi ro đã bị vượt quá hay chưa và gửi thông báo qua các kênh ưu tiên đã cấu hình của vùng, Slack, email hoặc hệ thống quản lý vé nội bộ. Hệ thống thông báo bao gồm các cấp độ leo thang, để những người phù hợp được cảnh báo dựa trên mức độ nghiêm trọng và thời gian một vấn đề đã mở. Mỗi giờ (mặc dù lịch trình này linh hoạt), hệ thống xuất dữ liệu rủi ro từ endpoint đọc cơ sở dữ liệu và chia sẻ nó với nhóm BI để phân tích sâu hơn và phát hiện xu hướng.
Ứng dụng web
Người dùng xem xét các rủi ro đang hoạt động và đã được giải quyết thông qua một ứng dụng web React được phân phối qua Amazon CloudFront và được hỗ trợ bởi API AWS AppSync. Ứng dụng tuân thủ các phương pháp bảo mật tốt nhất của AWS với Amazon Route 53 để phân giải DNS và AWS WAF để bảo vệ chống lại các lỗ hổng web phổ biến. AWS AppSync sử dụng các bộ giải AWS Lambda để nhúng phân tích Amazon Quick Sight và xử lý các hoạt động CRUD.
Quản trị viên trang web có thể sử dụng tính năng Quản lý trang web để cấu hình các trường hợp sử dụng và các tham số thông báo. Các vùng camera tổ chức các rủi ro liên quan thành các cảnh báo để xem xét nhanh chóng. Chúng có thể được xác nhận hoặc đánh dấu là dương tính giả, và hệ thống tự động giải quyết các cảnh báo khi không còn phát hiện rủi ro. Người dùng cũng có thể tìm kiếm các rủi ro lịch sử, với cả hai chế độ xem hiển thị xu hướng hàng ngày, thời gian giải quyết trung bình và tỷ lệ dương tính giả.
Chuẩn bị dán nhãn băng keo
Trường hợp sử dụng Housekeeping về cơ bản dựa vào việc hiểu mối quan hệ không gian giữa các đối tượng được phát hiện và các băng keo sàn 5S xác định vị trí đặt thiết bị và vật liệu. Housekeeping, trong ngữ cảnh này, đề cập đến việc duy trì một không gian làm việc sạch sẽ, có tổ chức và an toàn bằng cách giữ thiết bị, vật liệu và công cụ được lưu trữ ở các vị trí được chỉ định. Một lợi thế chính của hệ thống này là nó không yêu cầu bản đồ kỹ thuật số hoặc sơ đồ sàn có sẵn. Thay vào đó, Zone Owners có thể xác định các vùng an toàn và khu vực tổ chức bằng cách tham chiếu các băng keo vật lý hiển thị trong hình ảnh camera. Các băng keo màu khác nhau đại diện cho những nơi thuộc về các đối tượng nhất định và nơi tồn tại các hạn chế. Tuy nhiên, một thách thức thực tế phát sinh trong quá trình hoạt động bình thường của cơ sở: băng keo sàn thường xuyên bị che khuất bởi thiết bị, vật liệu và sự di chuyển của nhân viên trong suốt cả ngày. Sự che khuất này gây khó khăn cho các nhà chú thích con người trong việc xác định và gắn nhãn chính xác các ranh giới băng keo khi triển khai camera mới. Để giải quyết thách thức này, một quy trình chuẩn bị dán nhãn băng keo thông minh đã được phát triển để tạo ra các hình ảnh tổng hợp rõ ràng, không bị che khuất của băng keo sàn. Hệ thống phân tích nhiều khung hình camera được chụp vào các thời điểm khác nhau trong ngày, cùng với các dự đoán phát hiện đối tượng tương ứng của chúng. Sử dụng cơ chế bỏ phiếu, nó xác định các vùng pixel không có đối tượng được phát hiện và ghép các phần rõ ràng này lại với nhau thành một hình ảnh tổng hợp nơi các băng keo hiển thị đầy đủ. Quy trình làm việc tự động này chạy hàng giờ bằng cách sử dụng AWS Step Functions. Hàm Lambda đầu tiên xác định các camera mới được triển khai yêu cầu dán nhãn băng keo, trong khi hàm thứ hai tạo hình ảnh tổng hợp, lưu chúng vào Amazon S3 và cập nhật trạng thái camera để cho biết sẵn sàng cho việc chú thích. Quá trình Camera Onboarding tạo các tệp JSON chứa tọa độ của mỗi chú thích băng keo sàn 5S cho mỗi camera. Các chú thích này có thể truy cập được trong ứng dụng, cho phép người dùng kiểm tra và sửa đổi chúng khi cần thiết khi tổ chức sàn thay đổi. Trong quá trình suy luận, hệ thống phủ các vị trí đối tượng được phát hiện lên các ranh giới băng keo sàn và đánh giá sự tuân thủ theo các quy tắc kinh doanh và tổ chức đã cấu hình. Khi phát hiện vi phạm, các cảnh báo Housekeeping cung cấp ngữ cảnh toàn diện, bao gồm đối tượng được phác thảo vi phạm, khu vực băng keo 5S cụ thể liên quan và quy tắc đã bị vi phạm. Phản hồi chi tiết này cho phép người vận hành nhanh chóng định vị các vấn đề và đánh dấu các cảnh báo dương tính giả. Hình ảnh sau đây được tạo bởi Amazon Nova để minh họa giao diện người dùng dán nhãn băng keo:

Thành phần phân tích dữ liệu
Cuối cùng, dữ liệu phát hiện rủi ro này được biến thành thông tin chi tiết kinh doanh thực sự thông qua Amazon Redshift Spectrum và Quick Sight. Redshift Spectrum cho phép nhóm BI truy vấn dữ liệu rủi ro nằm trong S3 mà không gặp rắc rối khi di chuyển hoặc tải nó đi nơi khác, giúp phân tích lịch sử nhanh chóng và đơn giản.
Các bảng điều khiển Quick Sight cung cấp cho các nhà quản lý an toàn và lãnh đạo vận hành bức tranh toàn cảnh: các khu vực nào của cơ sở là điểm nóng về vi phạm, rủi ro thay đổi như thế nào giữa ca ngày và ca đêm, loại đối tượng nào gây ra nhiều vấn đề nhất và liệu các biện pháp can thiệp an toàn của bạn có thực sự tạo ra sự khác biệt hay không. Bạn thậm chí có thể so sánh hiệu suất giữa các cơ sở để phát hiện các phương pháp hay nhất đáng để nhân rộng.
Phát hiện cảnh báo thông minh
Quy trình bốn giai đoạn
Khi một hình ảnh đến S3 bucket đã được ẩn danh, hệ thống sẽ xử lý nó qua bốn giai đoạn:
Giai đoạn 1: Phát hiện đối tượng
SageMaker Endpoint chạy một mô hình thị giác máy tính phát hiện thiết bị vận hành, vật liệu và thiết bị an toàn của công nhân. Trong trường hợp sử dụng Housekeeping, mô hình xác định các loại thiết bị khác nhau như thiết bị vận chuyển, thùng chứa và thiết bị an toàn, cùng với các vật liệu thường thấy trong môi trường công nghiệp. Một khả năng quan trọng là khả năng của mô hình phân biệt giữa đường viền nhìn thấy của đối tượng và dấu chân thực tế của nó trên sàn.
Giai đoạn 2: Phân tích dựa trên vùng với “Băng keo kỹ thuật số”
Chỉ phát hiện thôi là chưa đủ. Hệ thống phải hiểu liệu các đối tượng được phát hiện có gây ra rủi ro thực sự hay không. Các vùng được xác định trước, được gọi là “băng keo”, đánh dấu các khu vực bị hạn chế, lối đi và ranh giới an toàn thông qua các công việc gắn nhãn. Hệ thống tính toán phần trăm chồng chéo giữa dấu chân của mỗi đối tượng được phát hiện và các vùng bị hạn chế này. Các ngưỡng có thể cấu hình, thường là 50% chồng chéo, xác định liệu một đối tượng có vi phạm các giao thức an toàn hay không, lọc ra các trường hợp ngoại lệ khi các đối tượng chỉ chạm nhẹ vào các đường ranh giới. Đối với mô-đun phát hiện PPE, hệ thống sử dụng mô hình thị giác máy tính dựa trên YOLO thực hiện phát hiện đồng thời trên nhiều chiều. Nó định vị công nhân trong khung hình, phân loại sự hiện diện hoặc vắng mặt của thiết bị an toàn cần thiết và áp dụng phân tích ngữ cảnh để xác định các mục PPE nào là bắt buộc trong các khu vực cụ thể. Nhận thức ngữ cảnh này cho phép hệ thống điều chỉnh các yêu cầu của nó cho các vùng khác nhau trong môi trường hoạt động.
Giai đoạn 3: Thuật toán “Thời gian nán lại”
Để tránh các cảnh báo sai từ các đối tượng tạm thời, hệ thống theo dõi các vi phạm theo thời gian. Nó phân tích các đối tượng qua các khoảng thời gian liên tiếp, thường là từng phút, sử dụng các thuật toán tương tự mặt nạ để xác nhận cùng một đối tượng vẫn tồn tại thay vì bị thay thế bởi các vật phẩm tương tự. Điều này xây dựng một “số lượng sao chép” cho thấy số phút liên tiếp một đối tượng đã vi phạm. Các loại đối tượng và vùng rủi ro khác nhau có thời gian nán lại chấp nhận được khác nhau—các khu vực rủi ro cao áp dụng ngưỡng ngắn hơn, trong khi các khu vực làm việc chung cho phép thời gian dài hơn để phù hợp với các hoạt động bình thường.
Giai đoạn 4: Xác thực đa lớp và tạo cảnh báo
Trước khi tạo cảnh báo, hệ thống áp dụng các lớp xác thực cuối cùng. Ngưỡng tin cậy lọc ra các phát hiện có độ chắc chắn thấp dựa trên độ phức tạp của loại đối tượng. So sánh mặt nạ Run-Length Encoding (RLE) xác minh rằng đối tượng được theo dõi nhất quán qua các khoảng thời gian thay vì các đối tượng khác nhau xuất hiện ở các vị trí tương tự. Ngữ cảnh vùng xác định mức độ nghiêm trọng và định tuyến của mỗi cảnh báo. Sau khi được xác thực, một cảnh báo được tạo với siêu dữ liệu phong phú:
{ "violations_details": { "object_type": "equipment_footprint", "zone_identifier": "PEDESTRIAN_ZONE:AREA_A:001", "detection_count": 5, "object_dwell_time": 3, "confidence_score": 0.85, "annotated_image_uri": "s3://bucket/annotations/violation_image.jpg" }}
Thách thức về khả năng mở rộng hạ tầng
Chúng tôi đã thiết kế hệ thống để hỗ trợ hàng nghìn camera. Quy mô này đòi hỏi các quyết định kiến trúc cẩn thận.
Nền tảng kiến trúc cho khả năng mở rộng
Cốt lõi của hệ thống chúng tôi là một mô hình driver-worker phi máy chủ đã chứng tỏ là thiết yếu để đạt được quy mô cần thiết. Mô hình này tách rời các tác vụ xử lý hình ảnh, cho phép mở rộng độc lập các thành phần khác nhau trong khi cung cấp khả năng cách ly lỗi. Nếu một worker thất bại, nó không ảnh hưởng đến toàn bộ pipeline. Driver điều phối phân phối công việc trong khi các worker xử lý hình ảnh đồng thời, cho phép chúng tôi mở rộng theo chiều ngang để xử lý đồng thời từ hàng trăm địa điểm. Worker ban đầu này kéo hình ảnh thô và kích hoạt một chuỗi các trình xử lý downstream chuyên biệt, mỗi trình xử lý đóng góp vào quy trình giám sát an toàn tổng thể.
Quy trình suy luận ML hoạt động như một người gác cổng thông minh trong kiến trúc này. Thay vì làm ngập các thành phần downstream với mọi hình ảnh được chụp, lớp suy luận chỉ hiển thị các hình ảnh nơi các vấn đề an toàn đã được phát hiện. Việc lọc này là cần thiết vì nó ngăn các thành phần tương tác với Amazon Aurora PostgreSQL bị quá tải bởi khối lượng dữ liệu hình ảnh thô từ hàng trăm địa điểm. Để quản lý trạng thái xử lý, các thành phần suy luận ML sử dụng DynamoDB, cung cấp khả năng quản lý trạng thái phi máy chủ, có thể mở rộng cần thiết để theo dõi các hoạt động suy luận trên mạng lưới camera phân tán của chúng tôi.
Phát triển hạ tầng suy luận của chúng tôi
Một trong những thách thức mở rộng quy mô đáng kể nhất của chúng tôi xuất hiện khi chúng tôi chuyển đổi từ proof-of-concept sang quy mô sản xuất. Ban đầu, chúng tôi triển khai các SageMaker Serverless inference endpoint với khoảng 50 camera. Tuy nhiên, khi chúng tôi mở rộng quy mô để xử lý hình ảnh từ hàng trăm địa điểm, chúng tôi đã gặp phải những hạn chế nghiêm trọng: SageMaker Serverless inference thiếu hỗ trợ GPU và áp đặt cấu hình bộ nhớ tối đa 6GB, dẫn đến lỗi hết bộ nhớ. Giải pháp yêu cầu chuyển sang các SageMaker Serverful inference endpoint được cấu hình với các instance thuộc dòng ml.g6 và triển khai các chính sách tự động mở rộng quy mô. Đạt được quy mô cũng có nghĩa là làm việc với các nhóm dịch vụ AWS để tăng giới hạn cho hàng nghìn lần thực thi Lambda đồng thời, tối ưu hóa phân bổ bộ nhớ và đa luồng, và điều chỉnh kích thước lô SQS để tối đa hóa thông lượng trong giới hạn bộ nhớ.
Tối ưu hóa Lambda và SQS cho khả năng đồng thời lớn
Đạt được quy mô yêu cầu cũng có nghĩa là làm việc chặt chẽ với các nhóm dịch vụ AWS để tăng giới hạn hỗ trợ hàng nghìn lần thực thi Lambda đồng thời trên các tài khoản của chúng tôi. Ngoài việc tăng giới hạn, chúng tôi đã đầu tư đáng kể vào việc tối ưu hóa cấu hình Lambda của mình từ phân bổ bộ nhớ đến logic xử lý sử dụng khả năng đa luồng. Việc tích hợp giữa Lambda và SQS đòi hỏi sự chú ý đặc biệt. Chúng tôi đã tối ưu hóa các hàm Lambda để đạt được khả năng tiêu thụ đồng thời tối đa, tái cấu trúc xử lý lỗi để giảm thiểu các container bị lỗi và điều chỉnh số lượng tin nhắn tối đa trên mỗi lô để xử lý khối lượng tin nhắn lớn hiệu quả trong giới hạn bộ nhớ.
Quản lý dữ liệu ground truth dựa trên dữ liệu ở quy mô lớn
Mặc dù việc tạo dữ liệu tổng hợp giảm đáng kể gánh nặng chú thích, chú thích thủ công vẫn quan trọng để giải quyết các điều kiện địa điểm độc đáo và triển khai các trường hợp sử dụng mới. Khi giải pháp mở rộng sang các cơ sở mới, mỗi địa điểm giới thiệu các góc camera, điều kiện ánh sáng và bố cục thiết bị riêng biệt, những điều này được hưởng lợi từ các chú thích thực tế được nhắm mục tiêu để tinh chỉnh hiệu suất mô hình. Cách tiếp cận của chúng tôi để quản lý dữ liệu ground truth cho việc huấn luyện mô hình đã phát triển đáng kể khi chúng tôi mở rộng quy mô. Ban đầu, chúng tôi triển khai một chiến lược đơn giản nhưng tốn nhiều công sức: tạo các công việc chú thích cho mọi địa điểm hàng ngày. Cách tiếp cận này hoạt động tốt trong giai đoạn đầu với số lượng địa điểm hạn chế, nhưng khi chúng tôi mở rộng sang hàng trăm địa điểm phân tán về mặt địa lý, khối lượng chú thích thủ công trở nên không thể duy trì. Số lượng công việc gắn nhãn hàng ngày khổng lồ – một công việc cho mỗi địa điểm mỗi ngày – nhanh chóng làm quá tải khả năng chú thích của chúng tôi và tạo ra một nút thắt cổ chai hoạt động đáng kể đe dọa khả năng liên tục cải thiện hiệu suất mô hình của chúng tôi.
Chúng tôi đã hình dung lại cơ bản quy trình làm việc của mình bằng cách sử dụng Amazon Athena để truy vấn và phân tích khối lượng lớn kết quả suy luận kết hợp với dữ liệu phản hồi của khách hàng ở quy mô lớn. Chúng tôi đã xác định các phân đoạn hoạt động kém bằng cách tổng hợp tỷ lệ dương tính giả trên các loại camera và điều kiện triển khai, ưu tiên huấn luyện lại trên các nguồn hình ảnh có tỷ lệ lỗi cao. Chúng tôi cũng đưa ra các suy luận trong đó điểm tin cậy của mô hình giảm xuống dưới ngưỡng đã thiết lập, gắn cờ các dự đoán không chắc chắn này để chú thích và xem xét có mục tiêu. Chúng tôi tiếp tục tăng cường phân tích này với các LLM đa phương thức Claude trên Amazon Bedrock để phân tích các mẫu bị phân loại sai và phát hiện các lớp đối tượng chưa được đại diện trong phân phối huấn luyện hiện có của chúng tôi. Điều này trực tiếp thông báo chiến lược thu thập dữ liệu của chúng tôi để giải quyết sự mất cân bằng lớp và các trường hợp ngoại lệ trong các công việc huấn luyện trong tương lai. Sự thay đổi này từ lấy mẫu tổng thể sang quản lý thông minh, dựa trên hiệu suất đã làm cho quy trình chú thích của chúng tôi bền vững ở quy mô lớn. Nó cũng cải thiện hiệu quả huấn luyện bằng cách chỉ đạo các nỗ lực gắn nhãn đến những nơi chúng sẽ có tác động lớn nhất đến việc cải thiện mô hình.
Ghi nhãn hình ảnh ở quy mô lớn
Chú thích thủ công dữ liệu huấn luyện là một thách thức, đặc biệt đối với các vi phạm an toàn hiếm gặp. Khối lượng hình ảnh khổng lồ kết hợp với tính chất tốn nhiều công sức của việc gắn nhãn thủ công, làm cho các phương pháp chú thích truyền thống không thực tế đối với một số trường hợp sử dụng nhất định. Một số vi phạm an toàn cực kỳ hiếm trong thực tế nhưng lại là nguyên nhân thường xuyên gây ra thương tích tại nơi làm việc. Một ví dụ điển hình là phát hiện tràn sàn: mặc dù đã kiểm tra và chú thích hơn nửa triệu hình ảnh, chỉ có vài trăm ví dụ về tràn chất lỏng hoặc mảnh vụn trên lối đi được xác định. Mặc dù tỷ lệ xảy ra thấp này đáng khen ngợi từ góc độ an toàn, nhưng nó đặt ra một thách thức cơ bản cho việc huấn luyện mô hình. Không có đủ ví dụ trong thế giới thực để huấn luyện một mô hình phát hiện mạnh mẽ. Tương tự, phát hiện PPE đặt ra một thách thức về sự đa dạng dữ liệu. Trong phần lớn các hình ảnh được chụp, các mục PPE xuất hiện trong một màu chủ đạo duy nhất. Tuy nhiên, các chính sách tại nơi làm việc thường cho phép các biến thể, và công nhân đôi khi đeo PPE chấp nhận được với các màu khác nhau. Nếu không có đủ ví dụ huấn luyện trên các biến thể màu sắc, mô hình có nguy cơ không phát hiện được các mục có màu không chuẩn, tạo ra các điểm mù an toàn tiềm ẩn.
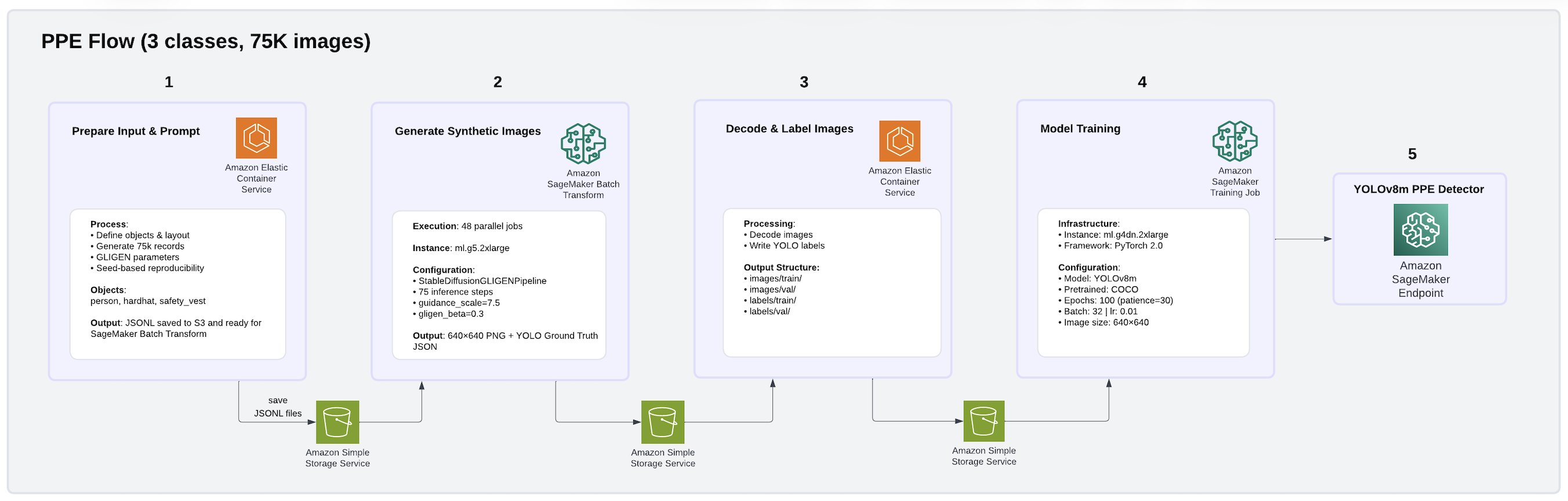
Để giải quyết những thách thức này, chúng tôi đã xây dựng một quy trình tạo dữ liệu tổng hợp và huấn luyện mô hình hoàn toàn trên AWS bằng cách sử dụng GLIGEN (Grounded Language-to-Image Generation), một mô hình tạo sinh dựa trên khuếch tán được triển khai dưới dạng các công việc Amazon SageMaker Batch Transform. Sử dụng cách tiếp cận này, chúng tôi đã tạo ra một bộ dữ liệu PPE gồm 75.000 hình ảnh bao gồm ba lớp: người, mũ bảo hiểm và áo bảo hộ. Kiến trúc quy trình được minh họa trong hình ảnh sau.
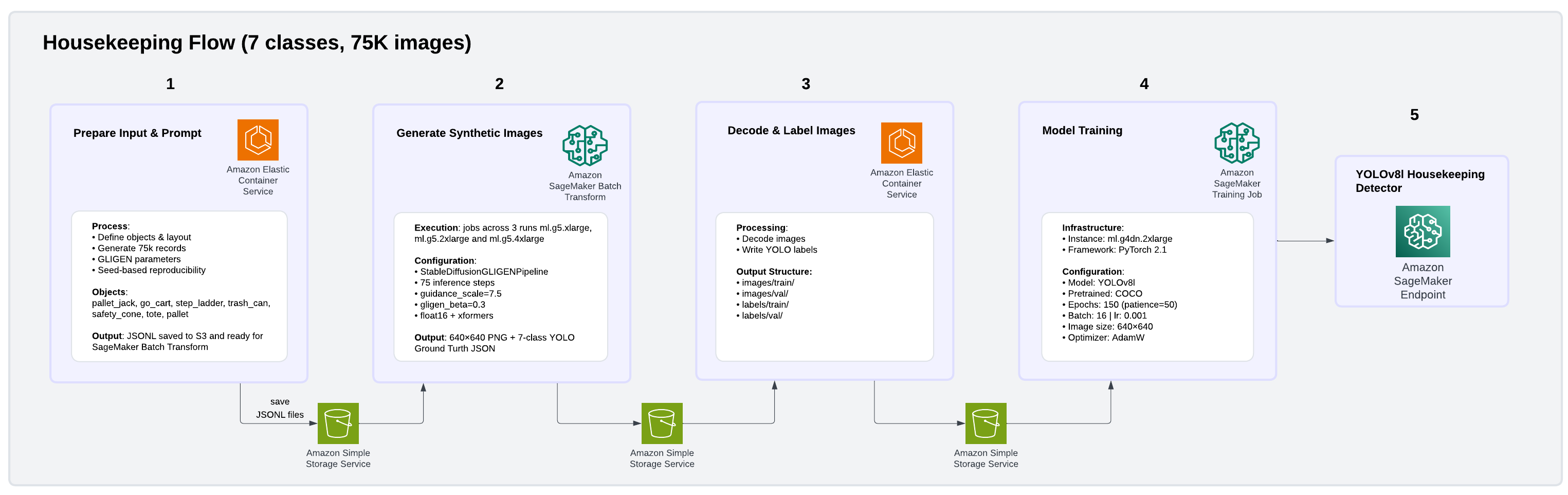
Chúng tôi cũng đã tạo ra một bộ dữ liệu Housekeeping gồm 75.000 hình ảnh bao gồm bảy lớp đối tượng cơ sở phổ biến: xe nâng pallet, xe đẩy hàng, thang gấp, thùng rác, nón an toàn, thùng chứa và pallet. Kiến trúc quy trình được minh họa trong hình ảnh sau.
GLIGEN cho phép tạo ra các bộ dữ liệu huấn luyện rất thực tế, nhưng được kiểm soát, giải quyết cả sự khan hiếm sự kiện hiếm và khoảng trống đa dạng dữ liệu mà không yêu cầu thu thập hoặc chú thích hình ảnh thủ công. Đối với các sự cố tràn sàn, GLIGEN nhận các đầu vào hộp giới hạn có cấu trúc chỉ định vị trí các đối tượng nên xuất hiện, tạo ra các cảnh cơ sở quang học thực tế với các sự cố tràn hoặc mảnh vụn được đặt trong các ngữ cảnh sàn cơ sở thực tế. Đối với sự đa dạng màu sắc PPE, GLIGEN tạo ra hình ảnh công nhân đeo thiết bị an toàn với nhiều màu sắc khác nhau, tạo ra sự đa dạng cần thiết để phát hiện mạnh mẽ trên các biến thể chấp nhận được. Đối với mỗi hình ảnh, GLIGEN nhận tọa độ hộp giới hạn chỉ định vị trí đối tượng và tạo ra các cảnh cơ sở quang học thực tế 512×512 với các chú thích ground truth được tự động nhúng vào đầu ra, hoàn toàn tránh việc gắn nhãn thủ công. Các đầu ra thô được truyền từ Amazon S3, giải mã và chuyển đổi sang định dạng chú thích YOLO bằng cách sử dụng các worker Python song song, sau đó được tải lên lại S3 dưới dạng các bộ dữ liệu sẵn sàng để huấn luyện. Chúng tôi đã huấn luyện các mô hình YOLOv8 trên Amazon SageMaker AI bằng PyTorch 2.1, với cấu hình cuối cùng sử dụng lập lịch tốc độ học cosine và tối ưu hóa AdamW. Đây là sự kết hợp đã chứng tỏ rất quan trọng để ổn định biến thể mô hình YOLOv8l lớn hơn và ngăn chặn sự phân kỳ gradient trong quá trình huấn luyện. Ngoài việc tạo dữ liệu huấn luyện, hình ảnh tổng hợp của GLIGEN cũng tăng cường suy luận bằng cách giảm rủi ro phát hiện dương tính giả và cung cấp sự hiểu biết chính xác hơn, theo ngữ cảnh về môi trường hoạt động.
Kết luận
Giải pháp của chúng tôi thể hiện độ chính xác cao. Đối với các trường hợp sử dụng được huấn luyện hoàn toàn trên dữ liệu tổng hợp được tạo bởi GLIGEN, mô hình PPE đạt độ chính xác trung bình (mAP@50) 99,5% với độ chính xác và độ thu hồi 100% trên cả ba lớp. Mô hình Housekeeping đạt 94,3% mAP@50 với độ chính xác 91,4% và độ thu hồi 86,9% trên bảy lớp đối tượng cơ sở khó hơn, tất cả đều không cần một hình ảnh thực tế nào được chú thích thủ công. Độ chính xác có thể được cải thiện hơn nữa bằng cách tăng khối lượng hình ảnh huấn luyện được sử dụng để xây dựng và huấn luyện mô hình tùy chỉnh. Ngoài độ chính xác, thông qua thử nghiệm trên 10.000 hình ảnh tổng hợp, chúng tôi đã thấy giải pháp của mình hoạt động mạnh mẽ trên hai khía cạnh quan trọng:
- tốc độ lên đến 37 giây, được đo bằng thời gian trôi qua giữa một hình ảnh được chụp và thông báo được gửi đến Zone Operators.
- khả năng mở rộng trên 10.000+ camera, được xác thực thông qua xử lý đồng thời 10.000 hình ảnh, nếu một camera tạo ra một khung hình tại một thời điểm.
Mặc dù bài đăng này tập trung vào việc triển khai kho hàng của chúng tôi, kiến trúc mà chúng tôi đã mô tả được thiết kế có chủ đích không phụ thuộc vào ngành. Các khả năng cốt lõi, phát hiện đối tượng, lý luận không gian dựa trên vùng, theo dõi vi phạm theo thời gian và xử lý hình ảnh bảo vệ quyền riêng tư, không dành riêng cho một môi trường duy nhất. Cùng một quy trình phát hiện xác định các vi phạm PPE và các mối nguy hiểm Housekeeping trên sàn trung tâm phân phối có thể được điều chỉnh để giám sát ranh giới thiết bị trên sàn sản xuất, thực thi các giao thức phòng sạch trong phòng thí nghiệm hoặc theo dõi việc tuân thủ an toàn tại các công trường xây dựng. Mỗi ngành yêu cầu một mô hình huấn luyện cụ thể theo lĩnh vực, các quy tắc kinh doanh được tùy chỉnh và cấu hình vùng độc đáo, nhưng kiến trúc hướng sự kiện cơ bản, các mẫu mở rộng quy mô và khung phát hiện cảnh báo thông minh vẫn không đổi. Chúng tôi mong muốn khám phá những phần mở rộng này trong công việc tương lai.
Để biết thêm thông tin về các giải pháp an toàn lao động của AWS, hãy xem Cung cấp một cách tiếp cận tích hợp về an toàn: Cách các giải pháp an toàn lao động của AWS giúp công việc an toàn hơn.
Về tác giả

Nika Mishurina
Nika là Kiến trúc sư Giải pháp Cấp cao tại Amazon Web Services. Cô đam mê làm hài lòng khách hàng thông qua việc xây dựng các giải pháp sẵn sàng sản xuất end-to-end. Ngoài công việc, cô thích đi du lịch, chơi tennis, trượt tuyết, tập thể dục và khám phá những điều mới mẻ.

Bharat Venkat
Bharat là Nhà khoa học Dữ liệu tại Amazon Web Services, tập trung vào việc xây dựng các giải pháp AI tạo sinh và MLOps cho khách hàng. Ngoài công việc, anh thích chơi cờ vua và pickleball, cũng như thử các nhà hàng mới ở khu vực DC.

Dan Iancu
Dan là Nhà khoa học Dữ liệu Cấp cao tại Amazon Web Services. Anh tập trung vào việc huấn luyện và triển khai các giải pháp Thị giác Máy tính và AI tạo sinh ở quy mô lớn cho khách hàng AWS. Ngoài công việc, anh thích đọc sách, đi bộ đường dài, chèo thuyền và khiêu vũ.

James Rehfeld
James là Tư vấn viên Chuyển giao Cấp cao tại Amazon Web Services. Anh tập trung vào việc thiết kế và xây dựng các giải pháp có khả năng mở rộng, được kiến trúc tốt và mang lại trải nghiệm người dùng tối ưu. Ngoài công việc, anh thích chạy bộ, đi du lịch và thỉnh thoảng chơi trò chơi điện tử.
