Tác giả: Sam Bydlon
Ngày phát hành: 03 APR 2026
Chuyên mục: Amazon Bedrock, Amazon Bedrock AgentCore, Amazon SageMaker, Artificial Intelligence, AWS IoT Greengrass, AWS IoT SiteWise, AWS Lambda, AWS Parallel Computing Service, AWS ParallelCluster, Kinesis Video Streams, Strands Agents, Technical How-to, Thought Leadership
Giới thiệu
Trả lời các câu hỏi kỹ thuật trải rộng nhiều chuyên ngành hiếm khi chỉ là việc tìm ra câu trả lời đúng. Một trong những phần khó nhất thường là điều phối đúng người để cung cấp câu trả lời đó. Điều gì sẽ xảy ra nếu AI có thể tăng cường sự điều phối này – không phải bằng cách thay thế các nhóm chuyên gia, mà bằng cách tăng tốc nghiên cứu ban đầu và tổng hợp của họ?
Khi các câu hỏi kỹ thuật phức tạp trải rộng nhiều lĩnh vực, con đường dẫn đến câu trả lời thường liên quan đến nhiều ma sát. Một câu hỏi về việc xây dựng hệ thống robot tự hành có thể yêu cầu ý kiến từ các chuyên gia IoT, các nhà thực hành GenAI, các chuyên gia điện toán không gian và các kỹ sư HPC. Mỗi chuyên gia duy trì chuyên môn sâu, nhưng việc điều phối kiến thức tập thể của họ mất thời gian.
Các tổ chức có các chuyên gia tài năng trên nhiều lĩnh vực chuyên môn khác nhau, nhưng việc điều phối có thể là một trở ngại: xác định những chuyên gia nào cần tham gia, giúp họ thống nhất về câu hỏi và tổng hợp các quan điểm của họ thành một phản hồi mạch lạc.
Ví dụ, tại AWS có một tổ chức Advanced Computing bao gồm bảy nhóm chuyên biệt: HPC, Quantum Computing, Visual Computing, Spatial Computing, IoT, Technology Partnerships và Emerging Technologies (tập trung nhiều vào GenAI ứng dụng). Các câu hỏi của khách hàng thường trải rộng hai hoặc ba trong số các lĩnh vực này. Cấu trúc nhóm hoạt động tốt, với các chuyên gia duy trì chuyên môn sâu trong lĩnh vực của họ trong khi cộng tác xuyên biên giới, nhưng giống như bất kỳ tổ chức nào có chuyên môn phân tán, việc điều phối mất thời gian.
Quan sát này đã dẫn đến một thử nghiệm: điều gì sẽ xảy ra nếu chúng ta xây dựng một hệ thống AI đa tác nhân phản ánh chính xác cấu trúc nhóm này? Bảy tác nhân AI, mỗi tác nhân đại diện cho một lĩnh vực, với một điều phối viên định tuyến các câu hỏi và tập hợp đúng nhóm cho mỗi truy vấn.
Hệ thống kết quả chạy trên Amazon Bedrock AgentCore, dịch vụ được quản lý của AWS để xây dựng và triển khai các ứng dụng AI tác nhân. Bản thân các tác nhân được xây dựng bằng AWS Strands Agents, một SDK mã nguồn mở để điều phối đa tác nhân.
Hệ thống xử lý nghiên cứu ban đầu và điều phối đa lĩnh vực, tạo ra một kiến trúc hoặc phương pháp giải pháp dự thảo. Các chuyên gia con người sau đó có thể xác thực, tinh chỉnh và đưa ra quyết định cuối cùng. Điều này giải quyết nút thắt cổ chai về điều phối: thay vì mất nhiều ngày để xác định đúng chuyên gia, lên lịch họp và tổng hợp các quan điểm, bạn sẽ có một điểm khởi đầu trong vài phút.
Như chúng ta sẽ thấy trong các ví dụ dưới đây, điều này có thể nén những gì có thể là nhiều ngày hoặc nhiều tuần nghiên cứu thành một lần tư vấn duy nhất. Đề xuất giá trị: không phải câu trả lời hoàn hảo, mà là thời gian tạo bản nháp được tăng tốc cho phép các chuyên gia con người tập trung vào việc tinh chỉnh thay vì nghiên cứu ban đầu.
Trong bài đăng này, chúng ta sẽ đi sâu vào cách hệ thống này hoạt động, trình diễn nó xử lý các truy vấn thực tế và trích xuất các mẫu mà bạn có thể áp dụng. Cho dù bạn đang xây dựng các hệ thống tương tự cho tổ chức của mình, tìm hiểu cách Amazon Bedrock AgentCore hoạt động thông qua một ví dụ thực tế hay khám phá các loại vấn đề mà AI tác nhân có thể giải quyết, bài đăng này cung cấp các chi tiết triển khai cụ thể.
Triển khai hoàn chỉnh có sẵn trên GitHub, bao gồm mã cơ sở hạ tầng, định nghĩa tác nhân và tập lệnh triển khai.
Tổng quan giải pháp
Về cốt lõi, triển khai này sử dụng cái mà chúng ta sẽ gọi là mẫu bầy đàn động được điều phối bởi điều phối viên, được xây dựng bằng AWS Strands Agents. Một tác nhân điều phối phân tích các truy vấn đến và quyết định cách phản hồi: kiểm tra các tương tác trong quá khứ được lưu trữ trong AgentCore Memory, trả lời trực tiếp cho các câu hỏi tiếp theo đơn giản hoặc tự động tạo ra một bầy đàn tạm thời gồm các chuyên gia từ một nhóm bảy tác nhân chuyên gia miền. Mỗi tác nhân chuyên gia được thiết kế để phản hồi như một kiến trúc sư giải pháp AWS chuyên về lĩnh vực tương ứng của họ.
Điều phối viên chọn các tác nhân chuyên gia nào sẽ tham gia dựa trên truy vấn. Các câu hỏi đơn giản có thể chỉ cần một chuyên gia, trong khi các câu hỏi đa miền phức tạp có thể yêu cầu hai hoặc ba chuyên gia làm việc cùng nhau như một bầy đàn. Sau khi được chọn, các tác nhân này cộng tác thông qua các lần chuyển giao, chuyển các câu hỏi cho nhau khi họ làm việc để tìm ra câu trả lời.
Mỗi tác nhân chuyên gia có quyền truy cập vào các Knowledge Bases chuyên biệt theo miền chứa thông tin hiện tại – tài liệu dịch vụ, câu chuyện thành công của khách hàng, thông số kỹ thuật API, hướng dẫn giải pháp và nhiều hơn nữa. Khi một tác nhân cần thông tin, họ truy vấn Knowledge Bases của mình theo thời gian thực, đọc kết quả và có thể truy vấn lại để đào sâu hoặc làm rõ.
Kết quả là một hệ thống đa tác nhân động, nơi mỗi tác nhân có thể thực hiện RAG (Retrieval Augmented Generation) tác nhân trên một Knowledge Bases chuyên biệt và nơi các tác nhân thay phiên nhau và xây dựng dựa trên các phản hồi của nhau. Hãy nghĩ về cách bạn có thể truy vấn một LLM, đọc kết quả, sau đó đặt các câu hỏi tiếp theo để hướng tới một giải pháp. Các tác nhân này cũng làm điều tương tự, nhưng mỗi tác nhân mang đến chuyên môn miền khác nhau. Phản hồi của một tác nhân trở thành ngữ cảnh cho truy vấn của tác nhân khác. Các quan điểm của họ kết hợp theo những cách mà sẽ không xảy ra với một tác nhân duy nhất hoặc một tra cứu Knowledge Bases đơn giản.
Đằng sau hậu trường, hệ thống chạy trên Amazon Bedrock AgentCore Runtime để lưu trữ tác nhân, AgentCore Gateway để truy cập công cụ và AgentCore Memory để duy trì tính liên tục của cuộc hội thoại. AWS Lambda xử lý các lệnh gọi công cụ thông qua AgentCore Gateway và Amazon Bedrock Knowledge Bases cung cấp tài liệu chuyên biệt theo miền liên quan đến các truy vấn của tác nhân. Hãy xem cách các thành phần này kết hợp với nhau.
Kiến trúc AWS
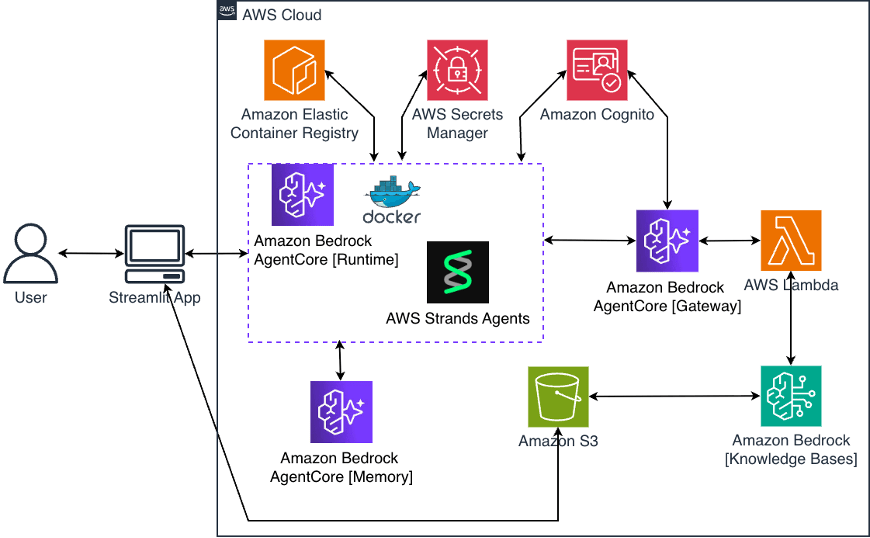
Hình 1: Cơ sở hạ tầng AWS hiển thị Amazon AgentCore Runtime, Gateway với MCP, Lambda định tuyến đến Knowledge Bases và Memory để duy trì tính liên tục của cuộc hội thoại.
Hình 1 hiển thị cơ sở hạ tầng AWS cung cấp năng lượng cho hệ thống đa tác nhân này. Ở trung tâm là Amazon Bedrock AgentCore. Triển khai này sử dụng ba khả năng của AgentCore: Runtime để lưu trữ mã tác nhân, Gateway để truy cập công cụ an toàn thông qua Model Context Protocol (MCP) và Memory để duy trì tính liên tục của cuộc hội thoại. AgentCore cũng cung cấp Identity để xác thực và Observability để giám sát, mặc dù triển khai này không sử dụng các nguyên thủy đó.
Mã tác nhân tự chạy trong một container serverless trên AgentCore Runtime. Khi hệ thống được triển khai, AWS Cloud Development Kit (CDK) tự động xây dựng một Docker container từ mã tác nhân, đẩy nó lên Amazon Elastic Container Registry (Amazon ECR) và cấu hình runtime để sử dụng nó. Runtime tự động mở rộng quy mô dựa trên nhu cầu và chỉ tính phí cho việc sử dụng thực tế.
Khi một tác nhân chuyên gia cần truy vấn một Knowledge Bases, nó đi qua AgentCore Gateway. Gateway được xây dựng trên Model Context Protocol (MCP), một tiêu chuẩn mở đang nhanh chóng trở thành phương pháp tiếp cận của ngành để kết nối các tác nhân AI với các công cụ và nguồn dữ liệu. MCP cung cấp một cách tiêu chuẩn hóa để các tác nhân khám phá và gọi các công cụ mà không cần tích hợp tùy chỉnh cho từng Backend. Điều này quan trọng vì khi hệ sinh thái tác nhân của bạn phát triển, bạn có thể thêm các công cụ mới thông qua Gateway mà không cần sửa đổi mã tác nhân vì các tác nhân tự động khám phá các công cụ có sẵn thông qua MCP.
AgentCore Gateway hỗ trợ nhiều loại đích để kết nối với các Backend khác nhau: các hàm AWS Lambda, thông số kỹ thuật OpenAPI hoặc các máy chủ MCP tùy chỉnh. Triển khai này sử dụng một đích Lambda duy nhất định tuyến đến Knowledge Bases thích hợp dựa trên tác nhân chuyên gia nào đang thực hiện yêu cầu. Để xác thực, triển khai này sử dụng OAuth với Amazon Cognito để đảm bảo chỉ các tác nhân được ủy quyền mới có thể truy cập các Knowledge Bases.
Hàm Lambda nhận tên miền và văn bản truy vấn từ tác nhân. Bảy Knowledge Bases được xây dựng bằng Amazon Bedrock Knowledge Bases, mỗi Knowledge Bases được kết nối với một bucket Amazon S3 chứa các tài liệu chuyên biệt theo miền. Khi bạn tải tài liệu lên, dịch vụ sẽ tự động chia nhỏ chúng, tạo các Embedding và lập chỉ mục chúng để tìm kiếm Vector.
AgentCore Memory cung cấp tính liên tục của cuộc hội thoại thông qua hai cơ chế bổ sung. Đối với bộ nhớ ngắn hạn trong một phiên, hệ thống tải lịch sử cuộc hội thoại gần đây giữa người dùng và hệ thống AI (một vài lần trao đổi gần đây nhất) và thêm nó trực tiếp vào ngữ cảnh của tác nhân. Điều này cho phép các câu hỏi tiếp theo tự nhiên trong cùng một cuộc hội thoại. Đối với bộ nhớ dài hạn giữa các phiên, AgentCore Memory sử dụng chiến lược bộ nhớ ngữ nghĩa xử lý các cuộc hội thoại để hiểu ý nghĩa và mối quan hệ. Điều này giúp điều phối viên có thể tìm kiếm kiến thức trong quá khứ khi trả lời các câu hỏi, ngay cả nhiều tuần sau đó. Sự kết hợp này có nghĩa là các cuộc hội thoại cảm thấy tự nhiên tại thời điểm đó trong khi xây dựng kiến thức tổ chức theo thời gian.
Kiến trúc hệ thống đa tác nhân
Bây giờ chúng ta đã giải thích kiến trúc AWS, hãy xem cách các tác nhân tự cộng tác để trả lời các câu hỏi.
Hình 2 hiển thị mẫu cộng tác đa tác nhân. Điều phối viên phân tích từng truy vấn và quyết định các tác nhân chuyên gia nào sẽ tham gia. Đối với một câu hỏi đơn giản như “AWS PCS là gì?”, nó chỉ chọn tác nhân HPC. Đối với một câu hỏi phức tạp về việc xây dựng một Digital Twin với bảo trì dự đoán được hỗ trợ bởi AI, nó có thể chọn ba tác nhân: Spatial Computing (cho kiến trúc Digital Twin), IoT (để thu thập dữ liệu cảm biến) và Generative AI (cũng bao gồm ML truyền thống như bảo trì dự đoán).
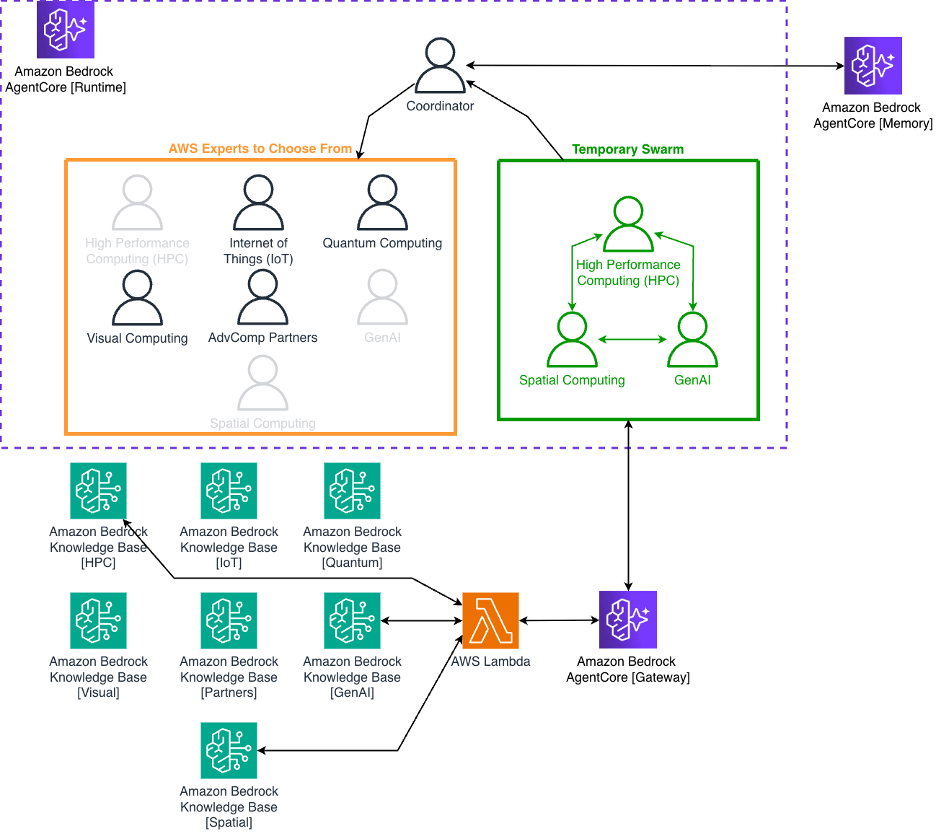
Hình 2: Hệ thống đa tác nhân hiển thị điều phối viên chọn 3 chuyên gia (HPC, Spatial, GenAI) từ một nhóm 7 chuyên gia miền, với sự cộng tác dựa trên chuyển giao và các công cụ MCP để truy cập Knowledge Bases.
Khi điều phối viên chọn các tác nhân chuyên gia, nó gọi một công cụ có tên advcomp_swarm, công cụ này tạo ra một nhóm tạm thời gồm các chuyên gia đó bằng cách sử dụng cấu trúc swarm của AWS Strands Agents. Trong các kiến trúc đa tác nhân, nhóm này đôi khi được gọi là mẫu chuyển giao — một tập hợp các tác nhân mà mỗi tác nhân có thể giao tiếp trực tiếp với bất kỳ tác nhân nào khác trong nhóm. Mỗi tác nhân chuyên gia có một lời nhắc hệ thống chuyên biệt theo miền định hình cách nó suy nghĩ về các vấn đề. Tác nhân HPC suy nghĩ như một kiến trúc sư giải pháp AWS chuyên về điện toán hiệu năng cao. Tác nhân Quantum suy nghĩ về các thuật toán lượng tử và Amazon Braket. Tác nhân Generative AI tập trung vào Amazon Bedrock, AgentCore và các dịch vụ Machine Learning.
Các tác nhân cộng tác thông qua các lần chuyển giao. Sau khi một tác nhân cung cấp phân tích của mình, họ rõ ràng chuyển giao cho thành viên tiếp theo trong nhóm. Điều này tạo ra một luồng hội thoại nơi mỗi tác nhân xây dựng dựa trên những gì các tác nhân trước đó đã nói. Hệ thống áp đặt các giới hạn: tối đa 20 lần chuyển giao và 20 lần lặp cho mỗi swarm, với tổng thời gian thực hiện là 30 phút. Các ràng buộc này giữ cho sự cộng tác tập trung và ngăn chặn việc thực hiện vượt quá giới hạn.
Truy cập Knowledge Bases diễn ra thông qua AgentCore Gateway. Khi một tác nhân cần thông tin, họ gọi công cụ query_knowledge_base với tên miền và truy vấn tìm kiếm của họ. Tác nhân bao gồm một JSON web token (JWT), được lấy từ Amazon Cognito thông qua OAuth, trong yêu cầu. Gateway xác thực token và định tuyến đến hàm AWS Lambda.
Hàm Lambda ánh xạ miền đến Amazon Bedrock Knowledge Base thích hợp và gọi API RetrieveAndGenerate. API này thực hiện tìm kiếm Vector để tìm các đoạn tài liệu liên quan, sau đó sử dụng một Foundation Model để tổng hợp các đoạn đó thành một câu trả lời mạch lạc. Tác nhân nhận phản hồi tổng hợp này và có thể truy vấn lại để đào sâu hoặc làm rõ.
Mỗi tác nhân chỉ có thể truy cập Knowledge Bases của miền riêng của mình. Tác nhân HPC truy vấn Knowledge Bases HPC, tác nhân Quantum truy vấn Knowledge Bases Quantum, v.v. Sự phân tách này phản ánh cấu trúc tổ chức con người mà chúng ta đang sao chép: mỗi chuyên gia có chuyên môn sâu trong lĩnh vực của họ. Lý do thiết kế là các lời nhắc tác nhân chuyên biệt theo miền kết hợp với quyền truy cập Knowledge Bases tập trung giúp các tác nhân duy trì các quan điểm chuyên biệt — tương tự như việc cấp cho một tác nhân quyền truy cập vào 100 công cụ thường kém hiệu quả hơn so với việc phân phối các công cụ đó cho các tác nhân chuyên biệt. Khi nhiều chuyên gia cộng tác, quyền truy cập Knowledge Bases kết hợp của họ cung cấp phạm vi bao phủ toàn diện trên các miền.
Hệ thống bộ nhớ chạy trong suốt quá trình này. Trước khi điều phối viên gọi swarm tác nhân chuyên gia, nó kiểm tra AgentCore Memory để tìm các cuộc hội thoại liên quan trong quá khứ. Nếu tìm thấy đủ thông tin, nó sẽ trả lời ngay lập tức mà không cần tập hợp các chuyên gia. Cách tiếp cận ưu tiên bộ nhớ này cải thiện hiệu quả cho các câu hỏi tiếp theo. Sau khi swarm hoàn thành, điều phối viên lưu cuộc hội thoại vào bộ nhớ, bao gồm cả các tác nhân đã tham gia. Điều này tạo ra một vòng lặp học tập nơi hệ thống trở nên tốt hơn trong việc trả lời các câu hỏi tương tự theo thời gian.
Toàn bộ luồng yêu cầu trông như sau: Người dùng gửi truy vấn → Điều phối viên kiểm tra bộ nhớ → Nếu cần, điều phối viên chọn các tác nhân chuyên gia và gọi công cụ swarm → Swarm chuyên gia được tạo với các công cụ MCP → Các tác nhân cộng tác thông qua các lần chuyển giao, truy vấn Knowledge Bases → Gateway xác thực, AWS Lambda truy vấn Bedrock Knowledge Bases → Swarm tổng hợp phản hồi cuối cùng → Điều phối viên lưu cuộc hội thoại và các bài học vào bộ nhớ. Kiến trúc này cân bằng hiệu quả (ưu tiên bộ nhớ), chuyên môn (các chuyên gia miền) và thông tin hiện tại (truy cập Knowledge Bases).
Xem hệ thống hoạt động
Hãy cùng xem xét ba truy vấn minh họa các khía cạnh khác nhau của hệ thống: truy xuất kiến thức của một tác nhân duy nhất, cộng tác đa tác nhân và tương tác qua lại lặp đi lặp lại giữa các tác nhân.
Truy vấn 1: “AWS PCS là gì?”
Hình 3: Video demo hiển thị truy xuất Knowledge Bases của một chuyên gia duy nhất cho AWS PCS.
Câu hỏi đơn giản này đóng vai trò là cơ sở của chúng tôi. Điều phối viên chọn tác nhân HPC, người truy vấn Knowledge Bases HPC. Phản hồi giải thích rằng AWS Parallel Computing Service (PCS) là một dịch vụ được quản lý để chạy các khối lượng công việc HPC, khác biệt với AWS ParallelCluster. Đối với truy vấn này, cả hệ thống đa tác nhân và lệnh gọi LLM trực tiếp đều cung cấp các câu trả lời tương đương – các mô hình đủ mới để biết về AWS PCS. Điều này thiết lập một cơ sở: khi các Foundation Model có thông tin hiện tại trong dữ liệu huấn luyện của chúng, cả hai cách tiếp cận đều hoạt động tốt.
Truy vấn 2: “Sàn nhà máy của chúng tôi có 2.800 camera và cảm biến theo dõi robot trên một cơ sở rộng 500.000 feet vuông. Chúng tôi đang bị ngập trong dữ liệu nhưng không thể hình dung được các điểm nghẽn xảy ra ở đâu hoặc sử dụng Machine Learning để dự đoán lỗi thiết bị. Làm thế nào để chúng tôi xây dựng một Digital Twin tích hợp Generative AI để giúp robot của chúng tôi điều hướng hiệu quả hơn?”
Hình 4: Video demo hiển thị sự cộng tác của nhiều chuyên gia cho kiến trúc Digital Twin nhà máy.
Điều này minh họa sự cộng tác đa tác nhân. Điều phối viên phân tích truy vấn và xác định ba lĩnh vực kỹ thuật riêng biệt: điện toán không gian (kiến trúc Digital Twin và trực quan hóa 3D), IoT (thu thập dữ liệu camera và cảm biến) và AI/ML (bảo trì dự đoán và điều hướng). Nó tập hợp một nhóm gồm ba tác nhân chuyên gia đó.
Các tác nhân cộng tác thông qua các lần chuyển giao, mỗi tác nhân xây dựng dựa trên công việc của tác nhân trước đó. Tác nhân IoT bắt đầu bằng cách thiết kế lớp nhập dữ liệu với AWS IoT Core, Amazon Kinesis Video Streams cho 2.800 camera, AWS IoT Greengrass để xử lý biên và AWS IoT SiteWise để mô hình hóa tài sản. Họ chuyển giao cho tác nhân Spatial Computing, người lấy nền tảng IoT đó và thêm bản đồ không gian 3D với Visual Asset Management System (VAMS), lập chỉ mục không gian trong Amazon DynamoDB và AWS IoT TwinMaker để trực quan hóa. Cuối cùng, tác nhân GenAI thêm lớp thông minh: một hệ thống điều hướng đa tác nhân sử dụng AWS Strands Agents và Amazon Bedrock AgentCore Runtime, Amazon SageMaker để bảo trì dự đoán (thường sử dụng các mô hình ML truyền thống để dự báo chuỗi thời gian) và Amazon Bedrock Knowledge Bases cho các truy vấn ngôn ngữ tự nhiên.
Mỗi tác nhân truy vấn Knowledge Bases chuyên biệt theo miền của họ nhiều lần trong quá trình cộng tác này. Tác nhân IoT truy vấn “AWS IoT SiteWise asset modeling” và “fleet provisioning for 2,800 devices.” Tác nhân Spatial truy vấn “spatial data management” và “bottleneck detection.” Tác nhân GenAI truy vấn “AgentCore multi-agent orchestration” và “AWS Strands Agents collaboration.” Các truy vấn thời gian thực này đảm bảo các khuyến nghị phản ánh khả năng hiện tại của AWS.
Kết quả này là một điểm khởi đầu, không phải là câu trả lời cuối cùng. Một chuyên gia con người sẽ cần xác thực các lựa chọn dịch vụ, điền vào các thành phần còn thiếu và điều chỉnh theo các ràng buộc cụ thể. Đó là quy trình làm việc dự kiến. Hệ thống xử lý nghiên cứu và tổng hợp ban đầu; con người xác thực và tinh chỉnh.
So sánh điều này với những gì một lệnh gọi LLM trực tiếp tạo ra: hướng dẫn chung như “xem xét các nền tảng Digital Twin của bên thứ ba,” “sử dụng ML truyền thống trước,” và “Gen AI là phần bổ sung.” Phản hồi của LLM thận trọng và không phụ thuộc vào nhà cung cấp, điều này hợp lý để khám phá các tùy chọn, nhưng ít cụ thể hơn khi bạn cần chi tiết triển khai AWS.
Hệ thống đa tác nhân cung cấp một kiến trúc chi tiết, cụ thể của AWS với các dịch vụ cụ thể, các mẫu tích hợp và các bước triển khai. Điều thú vị là bản tóm tắt cấp cao của điều phối viên không khác biệt đáng kể so với phản hồi LLM trực tiếp. Cả hai đều đề cập đến Digital Twin, IoT và AI. Giá trị thực nằm ở các dấu vết tác nhân. Tác nhân IoT thiết kế lớp dữ liệu, tác nhân Spatial Computing thêm trực quan hóa trên nền tảng đó và tác nhân GenAI tích hợp thông minh với ngữ cảnh không gian. Đó không phải là ba câu trả lời riêng biệt được ghép lại với nhau mà là một kiến trúc mạch lạc, tích hợp, nơi mỗi lớp phụ thuộc vào lớp trước đó. Một người đánh giá có thể đi sâu vào các cuộc hội thoại này để hiểu lý do, đặt câu hỏi về các lựa chọn cụ thể và tinh chỉnh cách tiếp cận.
Truy vấn 3: “Chúng tôi chạy các mô phỏng thời tiết HPC tạo ra hàng Terabyte dữ liệu. Trước đây chúng tôi đã sử dụng AWS ParallelCluster cho các mô phỏng này nhưng sẵn sàng sử dụng công nghệ HPC mới từ AWS. Ngoài ra, chúng tôi muốn AI tìm các mẫu bão và đang nghĩ rằng GenAI/AI tác nhân có thể giúp ích nhưng không chắc chắn về cách thức và những gì AWS cung cấp. Hãy để các chuyên gia của bạn cùng nhau tinh chỉnh một đề xuất, chỉ ra những điểm yếu trong lập luận của nhau và đưa ra một số ý tưởng cho chúng tôi.”
Hình 5: Video demo về các chuyên gia HPC và GenAI lặp lại qua lại để tinh chỉnh một kiến trúc tích hợp.
Truy vấn này minh họa mẫu cộng tác mạng vượt ra ngoài các kiến trúc giám sát. Người dùng rõ ràng yêu cầu các chuyên gia “cùng nhau tinh chỉnh một đề xuất” và “chỉ ra những điểm yếu trong lập luận của nhau”, kích hoạt chế độ lặp của hệ thống, nơi các tác nhân chuyển giao qua lại nhiều lần thay vì thực hiện một chuỗi chuyển giao tuyến tính.
Digital Twin nhà máy của Truy vấn 2 có thể được giải quyết bằng mẫu giám sát (điều phối viên giao nhiệm vụ cho các tác nhân công nhân IoT, Spatial và GenAI, mỗi tác nhân phản hồi lại điều phối viên) hoặc mẫu mạng (các tác nhân công nhân có thể giao tiếp trực tiếp với nhau, với tất cả các đường dẫn giao tiếp có sẵn giữa các tác nhân). Nhưng truy vấn mô phỏng thời tiết này đặc biệt hưởng lợi từ cách tiếp cận mạng. Mặc dù một giám sát viên có thể định tuyến tin nhắn qua lại giữa các tác nhân công nhân HPC và GenAI về mặt kỹ thuật, nhưng các kiến trúc giám sát không được thiết kế để tinh chỉnh lặp đi lặp lại — chúng xuất sắc trong việc ủy quyền nhiệm vụ, không phải tạo điều kiện cho các cuộc tranh luận nhiều vòng nơi các tác nhân công nhân thách thức các giả định của nhau và xác thực các tuyên bố dựa trên tài liệu. Mẫu mạng cho phép các tác nhân công nhân trực tiếp chuyển giao cho nhau, tạo ra một luồng hội thoại nơi các đề xuất được tinh chỉnh thông qua đánh giá ngang hàng (của tác nhân) thay vì các trao đổi do điều phối viên làm trung gian.
Đầu tiên, hãy xem xét những gì một lệnh gọi LLM trực tiếp tạo ra cho truy vấn này. Phản hồi mô phỏng một cuộc thảo luận đa tác nhân thách thức tiền đề liệu GenAI có phải là cách tiếp cận đúng đắn để nhận dạng mẫu trong dữ liệu thời tiết hay không và khuyến nghị bắt đầu với thị giác máy tính truyền thống và Deep Learning trước khi thêm khả năng GenAI. Nó cung cấp một chiến lược triển khai theo giai đoạn (Tháng 1-3, 3-6, 6+) và kết thúc bằng các câu hỏi làm rõ về tần suất mô phỏng, các mẫu quan tâm cụ thể và chính sách lưu giữ dữ liệu. Đây là tư duy chiến lược có giá trị: LLM đẩy lùi các giả định và giúp tinh chỉnh các yêu cầu trước khi đi sâu vào triển khai. Nếu bạn vẫn đang khám phá liệu GenAI có phù hợp hay không hoặc đang xem xét nhiều nhà cung cấp Cloud, phản hồi tức thì này cung cấp hướng dẫn chiến lược chất lượng.
Hệ thống đa tác nhân áp dụng một cách tiếp cận khác. Tác nhân GenAI đề xuất một kiến trúc AI ban đầu: Amazon Bedrock Agents với suy luận streaming, Amazon SageMaker Processing cho dữ liệu Network Common Data Form (NetCDF) và ước tính chi phí. Nhưng tác nhân HPC thách thức năm giả định cụ thể: Bedrock có thể hỗ trợ streaming thời gian thực không? SageMaker có phải là công cụ phù hợp để tiền xử lý NetCDF không? Chúng ta có nên sử dụng các VPC riêng biệt để cách ly không? Chi phí thực tế cho việc xử lý 10TB/ngày là bao nhiêu? Làm thế nào để chúng ta cung cấp khả năng giải thích cho các nhà khí tượng học?
Tác nhân GenAI truy vấn Knowledge Bases để xác thực các tuyên bố, sau đó sửa đổi kiến trúc: chuyển từ SageMaker sang AWS Batch (thừa nhận “bạn nói đúng!”), xác nhận streaming của Bedrock với độ trễ 3-5 giây, cung cấp phân tích chi phí chi tiết (tổng cộng 15-19 nghìn đô la/tháng) và giải thích khả năng theo dõi của Bedrock để giải thích. Tác nhân HPC xác thực các sửa đổi này dựa trên Knowledge Bases của riêng họ bằng cách xác nhận đường dẫn xuất FSx, kiến trúc VPC và các mẫu cách ly mạng, sau đó phê duyệt thiết kế cuối cùng với các tinh chỉnh cụ thể như phân tách tiền tố S3.
Sự tương tác qua lại này tạo ra bốn tương tác với ba lần chuyển giao giữa hai tác nhân. So sánh điều này với một mẫu giám sát nơi một điều phối viên sẽ giao nhiệm vụ cho các tác nhân công nhân, mỗi tác nhân phản hồi một lần. Cách tiếp cận mạng cho phép các tác nhân công nhân thách thức các đề xuất của nhau, xác thực dựa trên tài liệu và tinh chỉnh lặp đi lặp lại cho đến khi cả hai đồng ý về một giải pháp. Phản hồi cuối cùng của tác nhân HPC bao gồm các chi tiết cụ thể về bố cục subnet VPC, thông số kỹ thuật nhóm bảo mật và chính sách vòng đời S3 đã xuất hiện thông qua quá trình tinh chỉnh lặp đi lặp lại.
Hệ thống đa tác nhân hoạt động tốt nhất khi người dùng đã quyết định hướng chung và tập trung vào việc tạo ra một kế hoạch triển khai chi tiết, cụ thể của AWS. Nếu bạn biết mình muốn một giải pháp AWS và cần các thông số kỹ thuật sẵn sàng sản xuất với các điểm tích hợp đã được xác thực, hệ thống đa tác nhân cung cấp các chi tiết kiến trúc có thể kiểm chứng được xuất hiện thông qua sự cộng tác. Đánh đổi là thời gian thực hiện (hơn sáu phút so với vài giây) nhưng bạn nhận được lý do có thể theo dõi (“KB của tôi xác nhận khả năng xuất FSx”), ước tính chi phí đã được xác thực được sửa đổi thông qua các thách thức của chuyên gia và các thông số kỹ thuật cụ thể sẵn sàng để triển khai.
Giống như hầu hết các đầu ra do AI tạo ra ngày nay, đề xuất này yêu cầu xem xét của con người. Một kiến trúc sư giải pháp con người có thể phát hiện lỗi, xác định các thành phần còn thiếu, đặt câu hỏi về các giả định chi phí hoặc điều chỉnh theo các ràng buộc cụ thể mà hệ thống không biết. Nhưng thay vì bắt đầu từ một trang trống và mất nhiều ngày nghiên cứu cấu hình xuất FSx, khả năng streaming của Bedrock, các mẫu cách ly VPC và các mô hình chi phí trên nhiều dịch vụ, sau đó điều phối với các chuyên gia miền để xác thực các điểm tích hợp, con người có một điểm khởi đầu chi tiết với các khuyến nghị đa miền, dựa trên tài liệu.
Hệ thống đã nén những gì có thể là nhiều ngày hoặc nhiều tuần nghiên cứu và điều phối thành một cuộc tư vấn sáu phút với lý do có thể theo dõi. Đó là đề xuất giá trị: không phải câu trả lời hoàn hảo mà là thời gian tạo bản nháp được tăng tốc cho phép các chuyên gia con người tập trung vào việc tinh chỉnh thay vì nghiên cứu ban đầu.
Sự tiến triển từ truy xuất kiến thức của một chuyên gia duy nhất đến cộng tác đa chuyên gia đến tương tác qua lại lặp đi lặp lại minh họa phạm vi của hệ thống đa tác nhân. Các câu hỏi đơn giản nhận được câu trả lời nhanh chóng, chính xác. Các vấn đề phức tạp nhận được chuyên môn phối hợp mà chúng cần. Và các câu hỏi trải rộng các miền liên kết sâu sắc được hưởng lợi từ việc các tác nhân lặp lại cùng nhau thay vì chỉ chuyển giao một lần.
Kết luận
Điều phối chuyên môn trên nhiều lĩnh vực là một vấn đề thực sự. Chuyên môn tồn tại trong các tổ chức. Nút thắt cổ chai là tập hợp đúng người lại với nhau một cách nhanh chóng. Hệ thống này tăng cường sự điều phối đó bằng cách tăng tốc nghiên cứu ban đầu và tạo giải pháp dự thảo.
Chúng tôi đã mô hình hóa hệ thống được mô tả trong bài đăng này dựa trên cấu trúc nhóm Advanced Computing thực tế của AWS: bảy tác nhân chuyên gia miền, một điều phối viên định tuyến các câu hỏi và quyền truy cập vào tài liệu hiện tại thông qua Knowledge Bases. Hệ thống xử lý nghiên cứu và tổng hợp ban đầu. Các chuyên gia con người sau đó có thể xác thực và tinh chỉnh. Đó là sự tăng cường, không phải thay thế.
Ví dụ về Digital Twin nhà máy minh họa điều này rất rõ: ba tác nhân chuyên gia đã cộng tác để thiết kế một kiến trúc tích hợp nơi thu thập dữ liệu IoT, trực quan hóa không gian và điều hướng được hỗ trợ bởi AI hoạt động cùng nhau. Hệ thống đã nén những gì có thể là nhiều ngày nghiên cứu và điều phối đa miền thành một cuộc tư vấn sáu phút với lý do có thể theo dõi và các điểm tích hợp đã được xác thực.
Điều này chứng minh những gì có thể thực hiện được khi bạn kết hợp điều phối đa tác nhân, truy cập kiến thức thời gian thực và bộ nhớ hội thoại. Những khả năng này có thể tăng cường cách các nhóm kỹ thuật làm việc — giảm năng lượng kích hoạt để bắt đầu các vấn đề phức tạp, duy trì ngữ cảnh giữa các cuộc hội thoại và điều phối chuyên môn phân tán.
Sẵn sàng khám phá các hệ thống đa tác nhân cho tổ chức của bạn?
- Thử mã: Triển khai hoàn chỉnh có sẵn trên Github với hướng dẫn triển khai và mã cơ sở hạ tầng.
- Liên hệ AWS: Liên hệ với nhóm tài khoản AWS hoặc kiến trúc sư giải pháp của bạn để được hướng dẫn về việc triển khai các hệ thống tương tự.
- Hỗ trợ chuyên biệt: Đối với chuyên môn về AI tác nhân và điện toán nâng cao, hãy yêu cầu nhóm tài khoản của bạn kết nối bạn với nhóm AWS Advanced Computing – Emerging Technologies.
- Chia sẻ phản hồi: Chúng tôi rất muốn nghe cách bạn đang suy nghĩ về kiến trúc đa tác nhân — hãy để lại bình luận bên dưới.
Về tác giả

Sam Bydlon
Tiến sĩ Sam Bydlon là Kiến trúc sư Giải pháp Chuyên gia thuộc nhóm Advanced Computing – Emerging Technologies tại AWS. Sam nhận bằng Tiến sĩ Địa vật lý từ Đại học Stanford vào năm 2018 và có hơn 16 năm kinh nghiệm phát triển và sử dụng các mô phỏng trong nghiên cứu khoa học và dịch vụ tài chính. Trong thời gian rảnh rỗi, Sam thích ăn xúc xích, xem các trận đấu bóng chày và ăn xúc xích tại các trận đấu bóng chày.
