Tác giả: Ezat Karimi và Jon Handler
Ngày phát hành: 08 APR 2026
Chuyên mục: Advanced (300), Amazon Aurora, Amazon DocumentDB, Amazon DynamoDB, Amazon OpenSearch Service, Amazon RDS, Amazon Redshift, Database, PostgreSQL compatible, RDS for PostgreSQL, Technical How-to
Các ứng dụng hiện đại dựa vào JSON để trao đổi dữ liệu và linh hoạt lưu trữ. Bản chất không có schema của JSON cho phép các nhà phát triển lặp lại nhanh chóng mà không cần di chuyển tốn kém, nhưng sự linh hoạt này lại tạo ra sự phức tạp về kiến trúc. Không có một cơ sở dữ liệu nào có thể xử lý hiệu quả đồng thời các yêu cầu mâu thuẫn về giao dịch ACID cho các hoạt động tài chính, độ trễ thấp toàn cầu cho tương tác người dùng, phân tích quy mô petabyte cho kinh doanh thông minh và tìm kiếm phức tạp để khám phá nội dung. Các khối lượng công việc này có đặc điểm hiệu suất và yêu cầu vận hành khác nhau về cơ bản. Việc ép chúng vào một công cụ duy nhất thường dẫn đến tắc nghẽn hiệu suất, chi phí tăng cao và hạn chế vận hành. May mắn thay, bạn có thể giải quyết những thách thức này bằng cách kết hợp các dịch vụ AWS được xây dựng có mục đích, mỗi dịch vụ được tối ưu hóa cho các mẫu khối lượng công việc cụ thể, đồng thời giữ cho dữ liệu của bạn được đồng bộ hóa trên các hệ thống này.
Sử dụng kiến trúc tham chiếu phát trực tuyến phim, bài đăng này trình bày cách triển khai và đồng bộ hóa các khối lượng công việc JSON vận hành, phân tích và tìm kiếm trên các dịch vụ AWS. Mẫu này cung cấp một bản thiết kế có thể mở rộng cho bất kỳ trường hợp sử dụng nào yêu cầu khả năng dữ liệu JSON đa phương thức.
Tại sao khối lượng công việc JSON yêu cầu các dịch vụ chuyên biệt
Các đặc điểm xác định của JSON, cấu trúc không có schema, lồng ghép phân cấp và các tập thuộc tính biến đổi, làm cho nó linh hoạt độc đáo cho phát triển ứng dụng, nhưng chính sự linh hoạt đó lại tạo ra sự phức tạp về kiến trúc mà không một cơ sở dữ liệu nào có thể giải quyết hiệu quả.
Không giống như các định dạng schema cố định, các tài liệu JSON có thể phát triển tự do: một mục nhập danh mục phim có thể mang một vài thuộc tính hôm nay và hàng chục thuộc tính vào ngày mai, với các trường hoàn toàn khác nhau trên các loại nội dung. Sự biến đổi schema này có nghĩa là dữ liệu JSON chống lại các định nghĩa cột cứng nhắc của cơ sở dữ liệu quan hệ, cấu trúc phẳng của kho khóa-giá trị và cấu trúc bản ghi cố định của kho dữ liệu cột, tất cả cùng một lúc. Đồng thời, JSON là định dạng trao đổi gốc cho các API web, luồng sự kiện và nội dung do người dùng tạo, điều đó có nghĩa là cùng một dữ liệu JSON phải phục vụ các người tiêu dùng khác nhau về cơ bản: các ứng dụng cần các bản ghi riêng lẻ ngay lập tức, các nhà phân tích cần tổng hợp hàng triệu bản ghi và người dùng cần tìm kiếm và khám phá nội dung thông qua các truy vấn ngôn ngữ tự nhiên.
Các mẫu này yêu cầu các tối ưu hóa chuyên biệt mà một công cụ duy nhất không thể cung cấp:
- Truy cập vận hành yêu cầu đọc và ghi độ trễ thấp với đảm bảo ACID cho các tài liệu JSON riêng lẻ (ví dụ: truy xuất vị trí phát lại của người dùng hoặc cập nhật bản ghi đăng ký)
- Xử lý phân tích yêu cầu quét và tổng hợp hàng tỷ sự kiện JSON với lưu trữ cột và xử lý song song (ví dụ: xác định nội dung thịnh hành trên hàng tỷ sự kiện xem)
- Các hoạt động khám phá yêu cầu mã hóa, chỉ mục đảo ngược và tính điểm mức độ liên quan trên các trường JSON (ví dụ: trả về kết quả được xếp hạng cho một truy vấn tìm kiếm mờ như “
space movies with Chris”)
Không có một công cụ nào xử lý cả ba mẫu một cách hiệu quả. Giải pháp là một dịch vụ được xây dựng có mục đích cho mỗi mẫu, được đồng bộ hóa để đảm bảo tính nhất quán của dữ liệu trên tất cả các lớp.
Chọn dịch vụ AWS cho khối lượng công việc JSON
AWS cung cấp các dịch vụ được xây dựng có mục đích cho các mẫu truy cập và cấu trúc dữ liệu riêng biệt. Bằng cách đồng bộ hóa chúng, mỗi lớp đều vượt trội: kho lưu trữ vận hành xử lý các giao dịch, kho dữ liệu phân tích thực hiện phân tích lịch sử sâu sắc và lớp khám phá cung cấp các tìm kiếm dưới một giây, tất cả trong khi duy trì một chế độ xem JSON thống nhất.
Cây quyết định sau đây (chọn để phóng to) minh họa một cách tiếp cận để chọn các dịch vụ AWS dựa trên các mẫu truy cập dữ liệu và yêu cầu khối lượng công việc của bạn. Đối với các ứng dụng vận hành, hãy chọn giữa các cơ sở dữ liệu quan hệ Amazon (Amazon Aurora hoặc Amazon RDS), kho tài liệu (Amazon DocumentDB with MongoDB compatibility) hoặc kho khóa-giá trị (Amazon DynamoDB) tùy thuộc vào cấu trúc dữ liệu, yêu cầu mở rộng, độ phức tạp của truy vấn và nhu cầu độ trễ. Bạn đưa tất cả các kho dữ liệu chính vào lớp ngữ nghĩa và khám phá, Amazon OpenSearch Service để tìm kiếm toàn văn bản và ngữ nghĩa, và Amazon Simple Storage Service (Amazon S3) Vectors để lưu trữ nhúng vector hiệu quả về chi phí. Trong khi đó Amazon S3 đóng vai trò là lớp data lake nền tảng cung cấp dữ liệu cho các công cụ phân tích như Amazon Redshift và Amazon Athena.
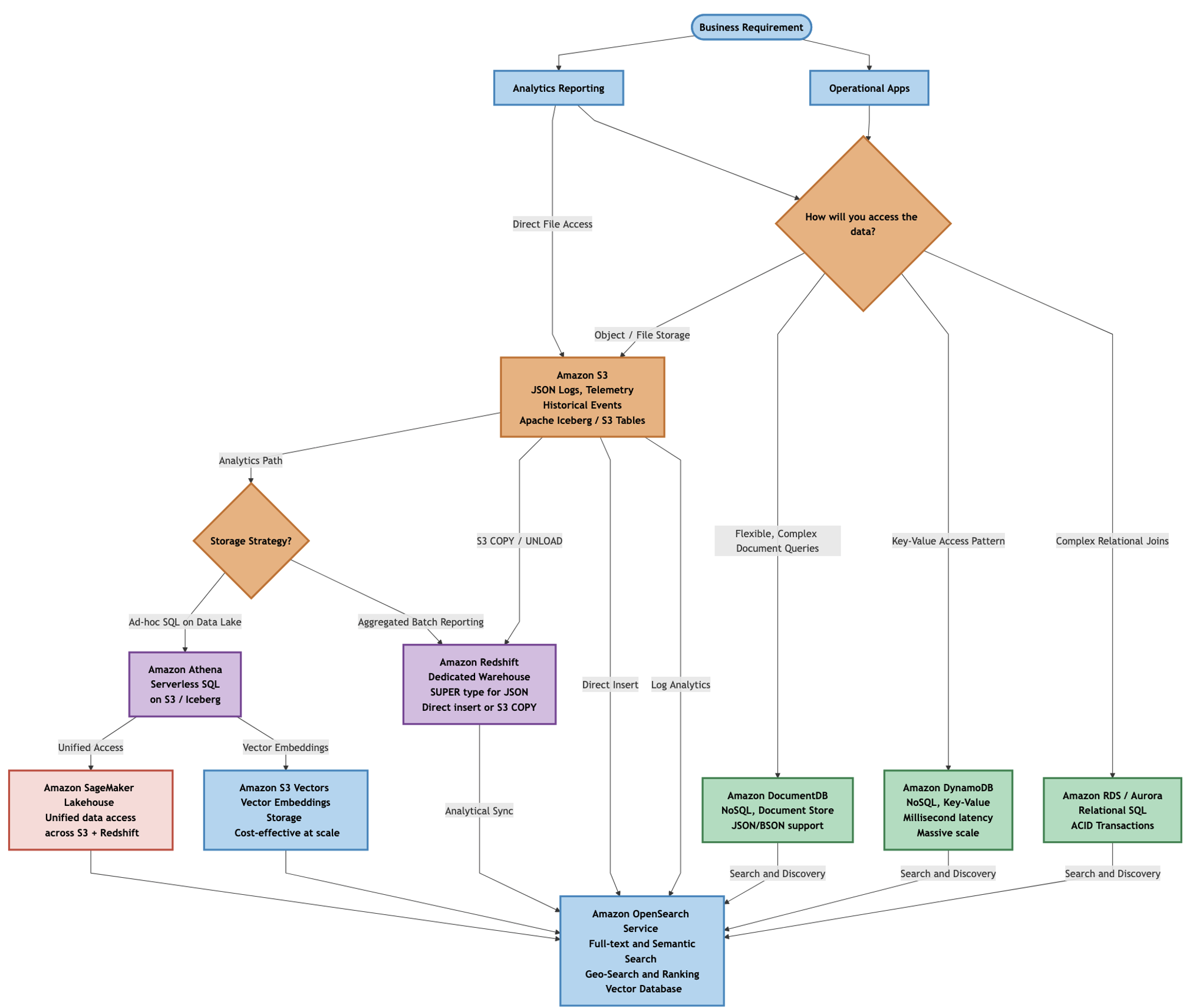
Lưu ý rằng trong khi các cơ sở dữ liệu đồ thị như Amazon Neptune có thể cung cấp một kiến trúc thay thế cho một số trường hợp sử dụng cá nhân hóa và đề xuất (mô hình hóa mối quan hệ giữa người xem, nội dung và đánh giá), bài đăng này tập trung vào các mẫu hướng tài liệu phù hợp với cấu trúc phân cấp của JSON và được triển khai phổ biến hơn trong các nền tảng phát trực tuyến.
Đối với một nền tảng phát trực tuyến phim, các lựa chọn thiết kế này thể hiện trên nhiều yêu cầu kiến trúc. Trong khi JSON đóng vai trò là định dạng dữ liệu xuyên suốt, mỗi dịch vụ giải quyết một nhu cầu vận hành riêng biệt:
- Amazon DynamoDB – Ghi sự kiện khối lượng lớn để theo dõi hoạt động người dùng và theo dõi trạng thái thời gian thực, duy trì vị trí phát lại hiện tại, mã thông báo phiên và tùy chọn người dùng trên các thiết bị.
- Amazon DocumentDB – Quản lý danh mục phim với các thuộc tính lồng ghép, biến đổi.
- Amazon Aurora PostgreSQL và Amazon RDS for PostgreSQL – Đảm bảo tính toàn vẹn giao dịch cho thanh toán và đăng ký, sử dụng các cột
JSONBnơi lưu trữ JSON phù hợp trong khi vẫn duy trì đảm bảo ACID. - Amazon S3 – Lưu trữ bền vững, chi phí thấp cho các nhật ký JSON quy mô petabyte và dữ liệu đo từ xa.
- Amazon Redshift – Phân tích lịch sử xem bằng cách sử dụng kiểu dữ liệu
SUPERcho BI. - Amazon OpenSearch Service – Cung cấp khả năng khám phá nội dung với khớp mờ và xếp hạng.
Chúng ta bắt đầu với Amazon OpenSearch Service vì tìm kiếm và khám phá đại diện cho mục tiêu tích hợp chính của kiến trúc này. Hiểu những gì OpenSearch yêu cầu về cấu trúc tài liệu, lập chỉ mục trường và tần suất đồng bộ hóa sẽ thiết lập nền tảng cho cách mỗi kho dữ liệu thượng nguồn phải được cấu hình để cung cấp dữ liệu hiệu quả. Mỗi phần tiếp theo sau đó sẽ đi sâu vào chi tiết triển khai cho DynamoDB, DocumentDB, Aurora PostgreSQL, S3 và Redshift, bao gồm các chiến lược lưu trữ, bật CDC và các quy trình đồng bộ hóa giúp OpenSearch phù hợp với từng hệ thống nguồn.
Amazon OpenSearch Service
Đối với trường hợp sử dụng phát trực tuyến phim, bạn cần một lớp khám phá có thể phục vụ tìm kiếm hướng người dùng trên tất cả các kho lưu trữ chính của bạn. Amazon OpenSearch Service hoạt động như lớp khám phá hiệu suất cao này, được xây dựng trên, chứ không phải thay thế, các kho dữ liệu vận hành và phân tích của bạn. Trong khi các cơ sở dữ liệu xử lý các ghi giao dịch và kho dữ liệu quản lý các tổng hợp nặng, OpenSearch Service vượt trội trong các khối lượng công việc khám phá nơi người dùng khám phá nội dung thông qua các kết quả khớp một phần, bộ lọc đa chiều và kết quả được xếp hạng trên các tài liệu JSON.
Các điểm mạnh cốt lõi của nó bao gồm tìm kiếm toàn văn bản, ngữ nghĩa và địa lý trên dữ liệu JSON, phân tích nhật ký và tìm kiếm vector, cho phép hàng tỷ tìm kiếm vector chiều cao với độ trễ thấp để hỗ trợ AI tạo sinh và hệ thống đề xuất. Đối với một nền tảng phát trực tuyến phim, các khả năng này cung cấp năng lượng cho thanh tìm kiếm, băng chuyền đề xuất và các trang chủ được cá nhân hóa.
OpenSearch Service rất cần thiết cho các khối lượng công việc JSON khi ứng dụng của bạn yêu cầu các khả năng tìm kiếm hướng người dùng mà các cơ sở dữ liệu vận hành không thể cung cấp hiệu quả. Trong khi DynamoDB vượt trội trong việc truy xuất dấu trang của một người dùng cụ thể theo ID người dùng, và DocumentDB trả về hiệu quả một tài liệu phim hoàn chỉnh theo ID tiêu đề, cả hai đều không thể trả lời hiệu quả các truy vấn như “tìm tất cả các phim có space trong tiêu đề hoặc mô tả, với các diễn viên có tên chứa Chris, được lọc theo thể loại khoa học viễn tưởng, được xếp hạng theo đánh giá người dùng và mức độ phổ biến gần đây”.
Các truy vấn đa trường, khớp mờ, xếp hạng mức độ liên quan này yêu cầu các chỉ mục đảo ngược và thuật toán tính điểm được xây dựng có mục đích cho các khối lượng công việc khám phá, chính xác là những gì OpenSearch Service cung cấp cho các tài liệu JSON ở quy mô lớn.
Các mẫu tích hợp với OpenSearch Ingestion
Vì dữ liệu JSON của bạn hiện được phân phối trên năm kho lưu trữ chuyên biệt, OpenSearch Service cần duy trì bản sao đồng bộ hóa của riêng mình về các trường liên quan đến tìm kiếm từ mỗi nguồn. OpenSearch Ingestion (OSI) giữ cho OpenSearch Service được đồng bộ hóa với các trường liên quan đến tìm kiếm từ các kho dữ liệu chính của bạn.
Lưu ý rằng trong khi OSI giải quyết việc đồng bộ hóa vào OpenSearch Service cho các trường hợp sử dụng tìm kiếm và khám phá, nó không giải quyết các yêu cầu đồng bộ hóa cho các khối lượng công việc phân tích và báo cáo, vốn yêu cầu các chiến lược riêng biệt.
OSI triển khai đồng bộ hóa thông qua một cách tiếp cận hai giai đoạn:
Giai đoạn 1: Ảnh chụp ban đầu (baseline) – Việc tích hợp bắt đầu bằng cách xuất các ảnh chụp đầy đủ từ cơ sở dữ liệu nguồn sang Amazon S3. OSI nhập các ảnh chụp này để thiết lập một baseline dữ liệu toàn diện trong OpenSearch Service.
Giai đoạn 2: Đồng bộ hóa liên tục (delta) – Sau khi baseline được thiết lập, hệ thống chuyển sang cập nhật gần thời gian thực bằng cách sử dụng Change Data Capture (CDC). OSI giám sát các thay đổi gia tăng từ nhật ký nguồn, chẳng hạn như Amazon DynamoDB Streams, DocumentDB Change Streams hoặc PostgreSQL Write-Ahead Logs (WAL), để giữ cho các chỉ mục hiện tại.
Để tối ưu hóa lưu trữ và hiệu suất, hãy cấu hình OSI để làm phẳng các cấu trúc JSON lồng ghép. Điều này cho phép lập chỉ mục chọn lọc các trường cụ thể thay vì sao chép toàn bộ tài liệu nguồn, giảm chi phí trong lớp khám phá.
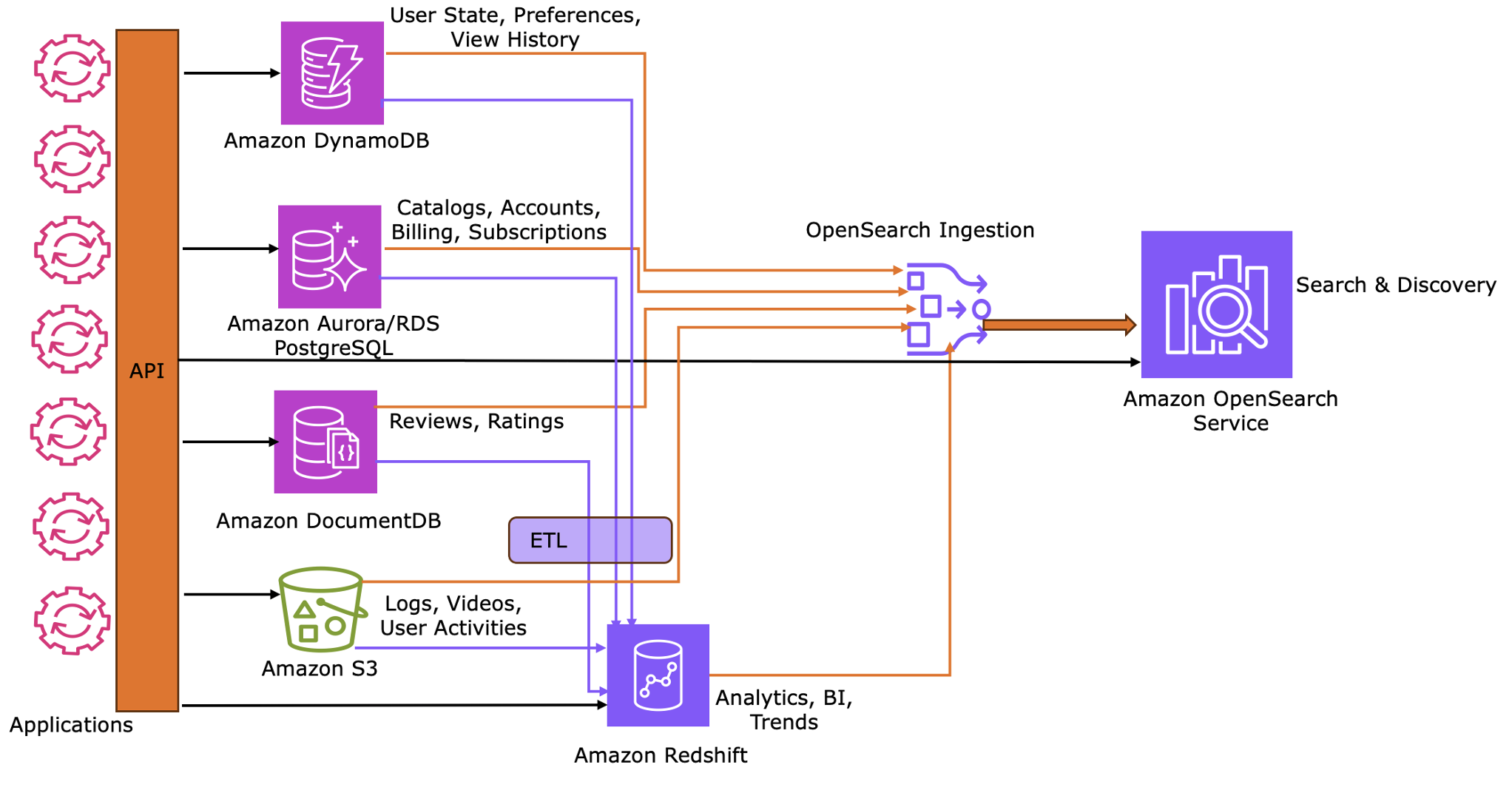
Các phần sau đây trình bày chi tiết các mẫu tích hợp cho từng dịch vụ, giải thích logic lưu trữ, bật CDC, cơ chế ảnh chụp và các quy trình đồng bộ hóa cụ thể giúp OpenSearch phù hợp với các hệ thống nguồn.
Amazon DynamoDB
Amazon DynamoDB là một cơ sở dữ liệu NoSQL cung cấp hiệu suất nhất quán và khả năng mở rộng dự đoán được cho các tra cứu khóa-giá trị. Nó hỗ trợ nguyên bản các tài liệu JSON (tôn trọng giới hạn kích thước mục là 400 KB), cho phép các hoạt động trực tiếp trên các thuộc tính lồng ghép mà không cần schema cố định. Thông lượng ghi lớn và độ trễ thấp của nó rất cần thiết cho các luồng sự kiện JSON khối lượng lớn.
Thiết kế không có schema lý tưởng cho việc theo dõi hoạt động người dùng: nó xử lý các cấu trúc sự kiện khác nhau, chẳng hạn như các sự kiện “play” với điểm tiếp tục hoặc các sự kiện “search” với xếp hạng truy vấn, mà không yêu cầu di chuyển.
Đối với một nền tảng phát trực tuyến phim, hãy sử dụng DynamoDB để quản lý trạng thái người dùng thời gian thực, quản lý phiên và các khối lượng công việc vận hành thông lượng cao nơi hiệu suất ở quy mô là ưu tiên hàng đầu. Trong kiến trúc này, DynamoDB lưu trữ trạng thái “hiện tại” của tương tác người dùng dưới dạng tài liệu JSON: điểm tiếp tục phát lại (dấu thời gian), mã thông báo phiên hoạt động và dấu trang cá nhân (“My List”). Lớp vận hành tinh gọn này cho phép trải nghiệm “tiếp tục xem” liền mạch, đa thiết bị, với các sự kiện lịch sử được lưu trữ vào Amazon S3.
Tích hợp Amazon DynamoDB với Amazon OpenSearch Service khi các thay đổi trong trạng thái người dùng, chẳng hạn như dấu trang mới được thêm hoặc một bộ phim đã hoàn thành, ảnh hưởng trực tiếp đến việc khám phá nội dung để đảm bảo rằng kết quả tìm kiếm phản ánh các tùy chọn gần đây thay vì nội dung chung chung.
Triển khai cho một nền tảng phát trực tuyến phim
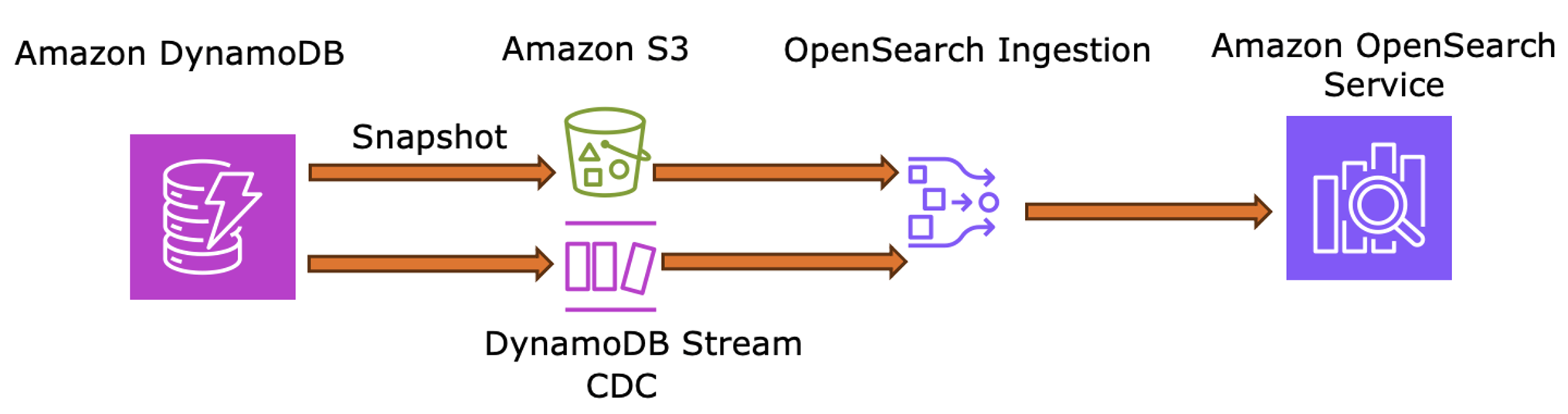
- Lưu trữ – Sử dụng DynamoDB với
useridlàm khóa phân vùng vàtitleidlàm khóa sắp xếp để theo dõi phát lại và dấu trang. - Tải ban đầu – Xuất ảnh chụp bảng sang S3 thông qua Point-in-Time Recovery (
PITR) cho baseline của OSI. - Đồng bộ hóa thời gian thực – Bật DynamoDB Streams cho OSI để nắm bắt các thay đổi trạng thái (
resume points, watch history) và cập nhật ngay lập tức các xếp hạng được cá nhân hóa trong OpenSearch.
Sơ đồ sau đây minh họa cách DynamoDB Streams và OSI giữ cho OpenSearch Service được đồng bộ hóa với hoạt động người dùng mới nhất.
Amazon DocumentDB
Amazon DocumentDB được xây dựng có mục đích để quản lý JSON ở quy mô lớn, hỗ trợ các cấu trúc lồng ghép, phức tạp mà không cần schema được xác định trước. Nó cho phép tương tác trực tiếp thông qua ký hiệu dấu chấm, toán tử mảng và các pipeline tổng hợp toàn diện để chuyển đổi dữ liệu sâu.
Đối với một nền tảng phát trực tuyến phim, hãy sử dụng DocumentDB làm kho lưu trữ Danh mục phim. Trong khi các mục chia sẻ một lõi chung, các danh mục hiện đại bao gồm nội dung đa dạng, phim truyền hình, phim tài liệu, thể thao và các tựa phim quốc tế, mỗi loại có siêu dữ liệu riêng biệt, thưa thớt. Lưu trữ hướng tài liệu lý tưởng cho sự biến đổi này:
- Phim điện ảnh bao gồm các thuộc tính như đạo diễn, diễn viên, thời lượng, ngày phát hành tại rạp và hãng sản xuất
- Phim truyền hình yêu cầu số mùa, số tập, ngày công chiếu loạt phim và siêu dữ liệu cho mỗi tập
- Phim tài liệu thường bao gồm các thẻ chủ đề, đối tượng phỏng vấn và tín dụng cảnh quay lưu trữ
- Nội dung quốc tế mang các tiêu đề được bản địa hóa, hệ thống xếp hạng khu vực, các bản âm thanh được lồng tiếng và phụ đề có sẵn bằng nhiều ngôn ngữ
- Nội dung dành cho trẻ em bao gồm xếp hạng độ tuổi phù hợp, cờ nội dung giáo dục và siêu dữ liệu kiểm soát của phụ huynh
Lưu trữ điều này dưới dạng JSON loại bỏ các schema quan hệ phức tạp, các cột có thể null và các lần di chuyển thường xuyên. Các pipeline tổng hợp của DocumentDB tiếp tục hợp lý hóa việc xử lý trong cơ sở dữ liệu, chẳng hạn như lọc theo thể loại hoặc tính toán xếp hạng trung bình trên các tập hợp con danh mục.
Tích hợp Amazon DocumentDB với Amazon OpenSearch Service khi siêu dữ liệu danh mục phải thúc đẩy việc khám phá nội dung thông qua tìm kiếm toàn văn bản, lọc theo khía cạnh và xếp hạng mức độ liên quan. DocumentDB xử lý nguyên bản các cấu trúc JSON lồng ghép phổ biến trong các danh mục sản phẩm, bao gồm mô tả được bản địa hóa, mảng thể loại và danh sách diễn viên.
Triển khai cho một nền tảng phát trực tuyến phim
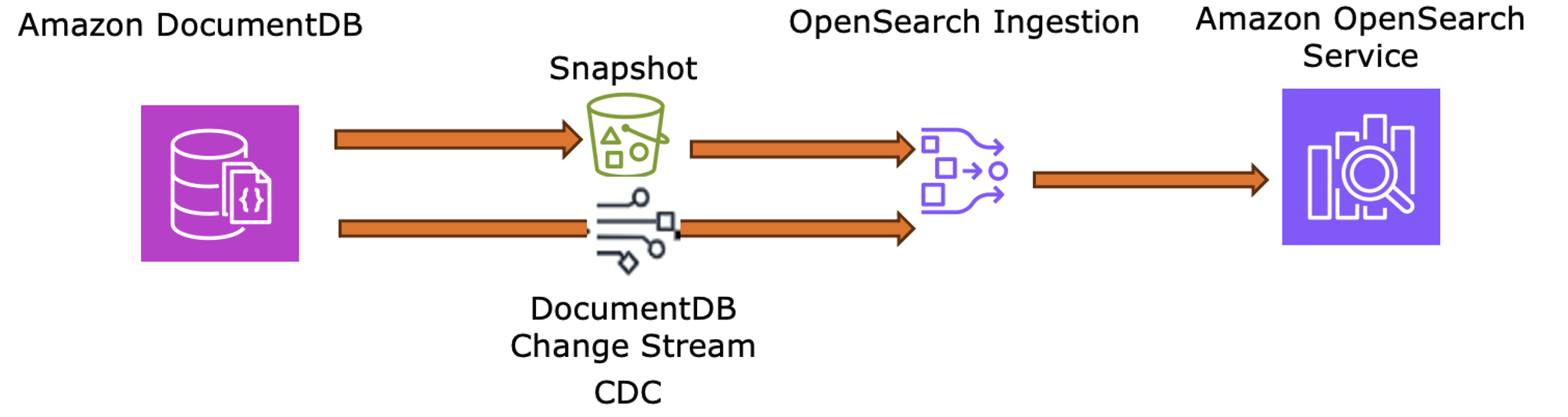
- Lưu trữ – Lưu trữ các tài liệu danh mục phim dưới dạng JSON trong các bộ sưu tập DocumentDB, được cấu trúc để chứa các thuộc tính biến đổi mà không cần di chuyển schema.
- Tải ban đầu – Xuất bộ sưu tập hiện tại sang S3 để OSI thực hiện đồng bộ hóa baseline đầy đủ.
- Đồng bộ hóa thời gian thực – Bật Change Streams trên DocumentDB để OSI nắm bắt và đẩy các cập nhật gia tăng (phát hành mới, thay đổi siêu dữ liệu) trực tiếp đến OpenSearch.
Sơ đồ sau đây minh họa cách DocumentDB Change Streams và OSI giữ cho OpenSearch Service được đồng bộ hóa với nội dung mới nhất.
Amazon Aurora PostgreSQL
Dịch vụ này kết hợp các đảm bảo ACID nghiêm ngặt với hỗ trợ JSON mạnh mẽ thông qua kiểu dữ liệu JSONB. Khả năng kép này cho phép bạn thực hiện các phép nối quan hệ phức tạp trong khi sử dụng lập chỉ mục GIN và các hàm chuyên biệt để truy vấn dữ liệu bán cấu trúc một cách hiệu quả. Amazon Aurora PostgreSQL là lựa chọn được khuyến nghị cho các khối lượng công việc quan hệ yêu cầu hỗ trợ JSON do hiệu suất, khả năng mở rộng và cơ sở hạ tầng được quản lý vượt trội so với các lựa chọn thay thế tự quản lý.
Đối với một nền tảng phát trực tuyến phim, hãy chọn Aurora PostgreSQL làm nguồn chính cho Thanh toán, Tài khoản và Đăng ký. Trong khi các nền tảng phát trực tuyến quy mô lớn thường nới lỏng các ràng buộc toàn vẹn tham chiếu vì lý do hiệu suất, các quy trình làm việc thanh toán và đăng ký được hưởng lợi từ tính nhất quán giao dịch mà PostgreSQL cung cấp cho các hoạt động tài chính quan trọng. JSONB được sử dụng để biểu diễn dữ liệu bán cấu trúc như siêu dữ liệu.
Các bản ghi kiểm toán được truyền xuống thông qua CDC đến các hệ thống kiểm toán và tuân thủ chuyên dụng thay vì được giữ lại trong kho lưu trữ vận hành chính, giữ cho Aurora tập trung vào các hoạt động giao dịch.
Tích hợp Aurora PostgreSQL với Amazon OpenSearch Service khi kiến trúc của bạn yêu cầu nguồn bản ghi chính cho siêu dữ liệu và các bản ghi chi tiết cho dữ liệu được quy định. Với cách tiếp cận này, lớp khám phá phản ánh phiên bản dữ liệu vận hành mới nhất trong khi cung cấp khả năng tìm kiếm toàn văn bản nâng cao.
Triển khai cho một nền tảng phát trực tuyến phim
- Lưu trữ – Lưu trữ các bản ghi thanh toán và tài khoản cốt lõi trong các bảng quan hệ, chỉ sử dụng
JSONBcho dữ liệu bán cấu trúc như cờ đăng ký và thẻ. - Tải ban đầu – Xuất ảnh chụp Aurora sang S3 ở định dạng Parquet để thiết lập baseline dữ liệu tài khoản người đăng ký.
- Đồng bộ hóa thời gian thực – Bật sao chép logic trên cụm Aurora để OSI tiêu thụ các sự kiện
WALcủa PostgreSQL, đảm bảo các thay đổi đăng ký và trạng thái phản ánh trong OpenSearch gần thời gian thực.
Sơ đồ sau đây minh họa cách các sự kiện WAL của PostgreSQL và OSI đồng bộ hóa siêu dữ liệu tài khoản vào OpenSearch Service để khám phá.

Amazon S3
Amazon S3 là data lake nền tảng cho tất cả dữ liệu phân tích JSON, cung cấp lưu trữ có thể mở rộng, hiệu quả về chi phí cho nhật ký, dữ liệu đo từ xa và các sự kiện lịch sử. Đối với các khối lượng công việc cần phát triển schema hoặc tính nhất quán giao dịch, các định dạng bảng mở như Apache Iceberg (thông qua Amazon S3 Tables) thêm cấu trúc vào JSON thô. Ngoài việc hỗ trợ xuất OSI, S3 cung cấp năng lượng cho các tập dữ liệu quy mô petabyte cho các công cụ như Amazon Redshift, Amazon Athena và OpenSearch Service.
Đối với hoạt động người dùng, hãy sử dụng S3 để nắm bắt lịch sử bất biến khổng lồ của mọi sự kiện phát lại (plays, pauses và skips) dưới dạng tệp nhật ký JSON. Điều này giảm tải các bản ghi lịch sử khối lượng lớn từ Amazon DynamoDB, cho phép lớp vận hành tập trung vào trạng thái người dùng hiện tại (resume points, bookmarks, active sessions) trong khi vẫn giữ một bản ghi lịch sử hoàn chỉnh để phân tích sâu trong Amazon Redshift.
Tích hợp Amazon S3 với Amazon OpenSearch Service khi bạn cần bật khả năng khám phá trên khối lượng lớn dữ liệu JSON được lưu trữ trong data lake của bạn. Lưu ý rằng Amazon Athena đóng vai trò là điểm vào chính cho phân tích trên các tập dữ liệu S3 lớn, trong khi OpenSearch Service có thể hoạt động như một lớp ngữ nghĩa để cho phép khám phá và thăm dò dữ liệu tương tác.
Triển khai cho một nền tảng phát trực tuyến phim
- Logic nhập liệu – Truyền trực tiếp nhật ký Hoạt động người dùng thô và Chất lượng dịch vụ (QoS) đến S3 dưới dạng JSON, nắm bắt các sự kiện đệm và chuyển đổi tốc độ bit.
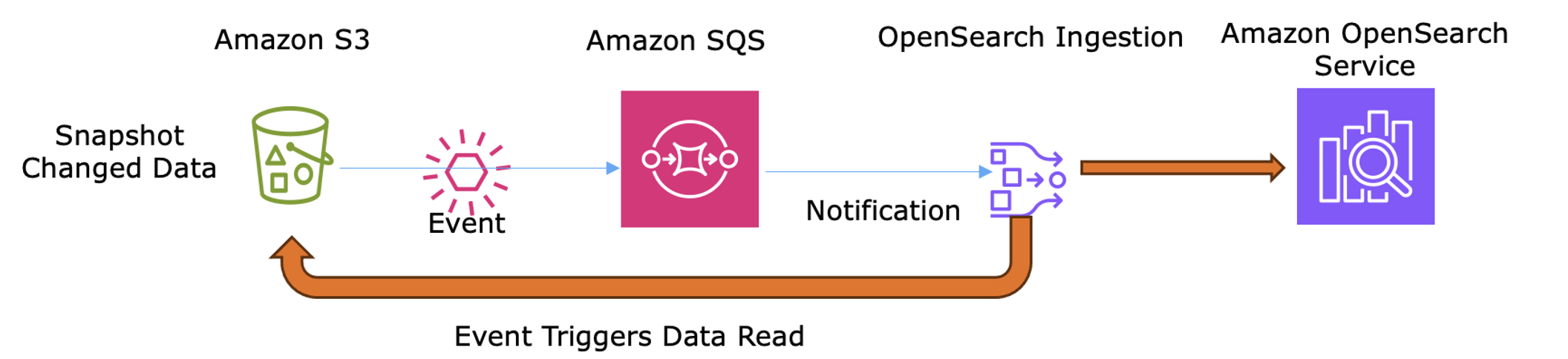
- Cấu hình OSI – Sử dụng plugin nguồn S3 và thông báo Amazon SQS để kích hoạt nhập liệu tự động khi các lô nhật ký mới đến.
- Quy trình đồng bộ hóa – OSI chuyển đổi JSON bằng cách ẩn danh các định danh và trích xuất các tín hiệu hành vi (ví dụ: “
most-watched genre”) trước khi lập chỉ mục chúng trong OpenSearch Service để khám phá.
Sơ đồ sau đây cho thấy cách Thông báo sự kiện S3 kích hoạt OSI thông qua SQS để nhập và chuyển đổi các tệp nhật ký cho khám phá OpenSearch Service.
Amazon Redshift
Amazon Redshift cung cấp khả năng xử lý phân tích trực tuyến hiệu suất cao (OLAP) cho các tập dữ liệu JSON lớn. Thông qua kiểu dữ liệu SUPER, nó cung cấp hỗ trợ nguyên bản cho JSON phức tạp, phân cấp, cho phép truy vấn tương thích SQL thông qua PartiQL mà không cần làm phẳng hoặc chuyển đổi dữ liệu trước khi tải.
Lưu trữ cột của Amazon Redshift và xử lý song song lớn (MPP) lý tưởng cho kinh doanh thông minh quy mô petabyte và báo cáo lịch sử. Kiến trúc này đặc biệt hiệu quả cho JSON vì nó cho phép các nhà phân tích chỉ đọc các trường lồng ghép cần thiết thay vì quét toàn bộ đối tượng.
Đối với một nền tảng phát trực tuyến phim, hãy sử dụng Amazon Redshift làm công cụ chính để phân tích nhật ký Hoạt động người dùng dài hạn được lưu trữ dưới dạng JSON trong Amazon S3. Bằng cách xử lý hàng tỷ sự kiện play, pause và skip được nắm bắt dưới dạng tài liệu JSON, Amazon Redshift xác định các mẫu cấp cao, chẳng hạn như sự gia tăng lượng người xem theo khu vực hoặc mức độ phổ biến thể loại theo mùa. Kiểu dữ liệu SUPER cho phép các truy vấn trích xuất các trường lồng ghép từ các tải trọng sự kiện JSON mà không yêu cầu định nghĩa schema cứng nhắc, phù hợp với các cấu trúc sự kiện đang phát triển khi nền tảng thêm các khả năng theo dõi mới.
Tích hợp Amazon Redshift với Amazon OpenSearch Service khi các thông tin chi tiết từ phân tích lịch sử phức tạp của dữ liệu JSON phải ảnh hưởng đến trải nghiệm khách hàng thời gian thực. Chiến lược này xử lý khối lượng tính toán khổng lồ của phân tích mẫu trên hàng triệu người đăng ký, chỉ xuất các “trending scores” cấp cao sang OpenSearch Service để hiển thị nội dung “Trending Now” và xếp hạng được cá nhân hóa, mà không lưu trữ hoặc xử lý nhật ký lịch sử quy mô petabyte.
Triển khai cho một nền tảng phát trực tuyến phim
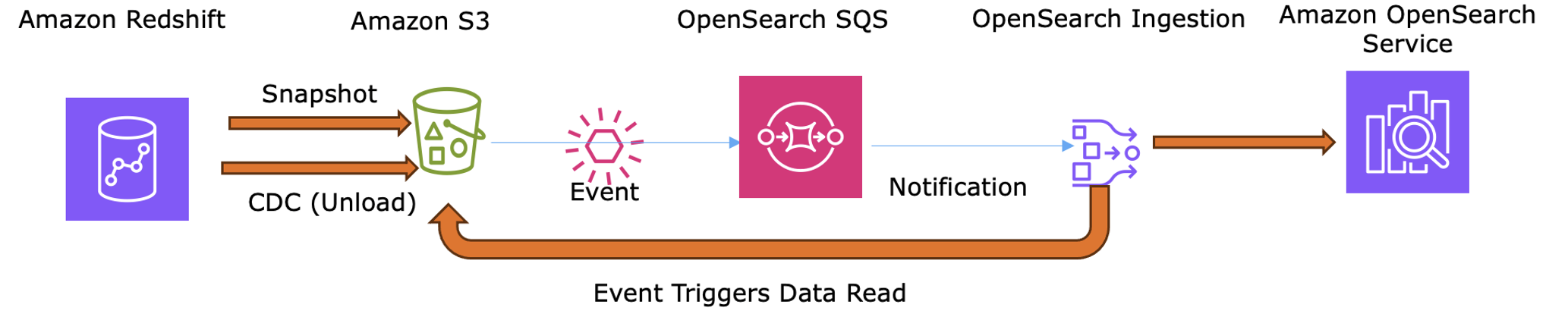
- Phân tích – Amazon Redshift xử lý hàng tỷ sự kiện
User Activitytừ data lake S3 để tính toán điểm xu hướng, xác định các bộ phim đang có đà phát triển theo khu vực hoặc các thể loại đang trải qua sự gia tăng theo mùa. - Ảnh chụp – Sử dụng lệnh
UNLOADđể xuất các điểm xu hướng được tính toán trước (movie_id,trend_rank) sang S3, chỉ gửi các kết quả tổng hợp thay vì dữ liệu xem thô. - Đồng bộ hóa theo lịch trình – Vì Redshift thiếu CDC nguyên bản, OSI sử dụng plugin nguồn S3 để nhập các tệp được xuất này theo lịch trình (
hourly or daily). - Lập chỉ mục – OSI trích xuất các định danh và điểm số để OpenSearch Service tăng cường xếp hạng tìm kiếm và điền vào các băng chuyền xu hướng.
Sơ đồ sau đây cho thấy cách các điểm xu hướng được xuất thông qua UNLOAD và được OSI nhập để giữ cho xếp hạng và băng chuyền xu hướng của OpenSearch Service hiện tại.
Các chiến lược tối ưu hóa tích hợp
Trong khi OSI tự động hóa quy trình đồng bộ hóa, bạn có thể tối ưu hóa việc triển khai của mình bằng cách cân bằng tính đầy đủ của dữ liệu với hiệu quả vận hành. Các tập dữ liệu JSON đặc biệt phù hợp để tối ưu hóa vì chúng có thể dễ dàng được phân đoạn, đồng bộ hóa một phần, theo lô hoặc loại bỏ trùng lặp bằng cách sử dụng các định danh tài liệu. Giảm thiểu việc di chuyển dữ liệu trong khi vẫn duy trì chức năng với các chiến lược sau:
Đồng bộ hóa trường chọn lọc – Chỉ lập chỉ mục các trường cần thiết để tìm kiếm, lọc hoặc tổng hợp, duy trì cơ sở dữ liệu nguồn làm hệ thống bản ghi. Ví dụ, trong siêu dữ liệu phim, OpenSearch Service nên lưu trữ tiêu đề, mô tả, tên diễn viên và thể loại, nhưng bỏ qua ngân sách sản xuất, định danh nội bộ và bản ghi tập phim đầy đủ.
Các hoạt động theo lô – Sử dụng bộ đệm OSI để nhóm các tài liệu thành các yêu cầu hàng loạt đến OpenSearch Service trước khi lập chỉ mục. Sử dụng bộ đệm lớn hơn (ví dụ: 10MB with a 60-second timeout) để cải thiện thông lượng cho dữ liệu khối lượng lớn, không khẩn cấp như nhật ký lịch sử. Sử dụng bộ đệm nhỏ hơn (ví dụ: 1MB with a 5-second timeout) để giảm độ trễ cho dữ liệu nhạy cảm về thời gian như hoạt động người dùng.
Loại bỏ trùng lặp nguồn – Sử dụng ID tài liệu xác định hoặc khóa tổng hợp (như movie_id, user_id + timestamp) được tạo tại nguồn để các sự kiện JSON trùng lặp cập nhật cùng một bản ghi OpenSearch Service thay vì tạo nhiều mục nhập.
Cập nhật gia tăng – Dựa vào luồng CDC để cập nhật tài liệu một phần nhằm giảm tải mạng và chi phí lập chỉ mục. OSI tự động thực hiện cập nhật một phần khi luồng CDC cung cấp các thay đổi gia tăng. Ví dụ, nếu xếp hạng của một bộ phim thay đổi, OSI chỉ cập nhật trường xếp hạng trong OpenSearch Service thay vì lập chỉ mục lại toàn bộ tài liệu JSON.
Thiết kế cho tính nhất quán cuối cùng
Trong một nền tảng JSON phân tán, tính nhất quán cuối cùng không phải là một sự thỏa hiệp mà là một lựa chọn thiết kế có chủ ý cho phép mỗi dịch vụ chuyên biệt hoạt động ở các đặc điểm hiệu suất tối ưu của nó. Bởi vì các tài liệu JSON tự chứa và linh hoạt về schema, chúng có thể được đồng bộ hóa một phần và lập chỉ mục chọn lọc trên các dịch vụ, giảm nguy cơ làm gián đoạn người tiêu dùng hạ nguồn và làm cho chúng rất phù hợp với mô hình này. Bằng cách thiết kế cho tính nhất quán cuối cùng, bạn thừa nhận rằng lớp khám phá cố ý chậm hơn sự thật vận hành trong các cửa sổ có giới hạn, có thể dự đoán được, điều này có thể chấp nhận được vì các đặc điểm khối lượng công việc JSON cho phép linh hoạt trong thời gian đồng bộ hóa. Trong suốt quá trình này, các cơ chế CDC duy trì thứ tự thay đổi, đảm bảo tính toàn vẹn của dữ liệu ngay cả với sự chậm trễ nhỏ.
Đối với một nền tảng phát trực tuyến phim, các cửa sổ đồng bộ hóa chấp nhận được được xác định bởi các yêu cầu khối lượng công việc và kỳ vọng của người dùng chứ không phải giới hạn cơ sở dữ liệu. Các mục tiêu cấp dịch vụ ví dụ này phản ánh những gì người dùng cảm nhận là độ trễ chấp nhận được dựa trên bản chất của mỗi hoạt động:
Cập nhật danh mục (Amazon DocumentDB) – Mục tiêu đồng bộ hóa trong vòng vài chục giây sau khi một bộ phim được thêm vào danh mục vận hành trước khi xuất hiện trong kết quả tìm kiếm. Khi một dịch vụ phát trực tuyến thêm nội dung mới, người dùng không biết chính xác khi nào nó xuất hiện đến từng giây. Ngay cả đối với các bản phát hành được mong đợi cao nơi người dùng đang chờ đợi các bản phát hành nửa đêm, họ thường điều hướng trực tiếp đến trang chi tiết của chương trình thay vì khám phá nó thông qua tìm kiếm, làm cho độ trễ chỉ mục tìm kiếm không thể nhận thấy.
Hoạt động người dùng (Amazon DynamoDB) – Mục tiêu đồng bộ hóa trong vòng vài giây để hỗ trợ “Just Watched” hoặc các đề xuất được cá nhân hóa. Sự chậm trễ nhỏ trong cá nhân hóa có tác động tối thiểu đến người dùng vì các thuật toán đề xuất đã hoạt động trên các mẫu lịch sử chứ không phải trạng thái tức thì. Người dùng mong đợi các đề xuất phát triển theo thời gian, không phải ngay lập tức sau mỗi tương tác.
Thay đổi thanh toán/cấp độ (Amazon Aurora) – Mục tiêu đồng bộ hóa dưới 30 giây cho các hệ thống kiểm toán và phân tích hạ nguồn. Đường dẫn quan trọng cho các thay đổi đăng ký, xác thực thanh toán và cấp quyền truy cập nội dung, được phục vụ trực tiếp bởi kho dữ liệu vận hành, không phải chỉ mục tìm kiếm. Đồng bộ hóa CDC hạ nguồn chỉ ảnh hưởng đến nhật ký kiểm toán và phân tích, vốn hoạt động trên các tổng hợp hàng giờ hoặc hàng ngày nơi độ trễ đồng bộ hóa không thể nhìn thấy về mặt vận hành.
Xuất phân tích (Amazon Redshift) – Mục tiêu đồng bộ hóa theo lịch trình hàng giờ hoặc hàng ngày để phản ánh điểm xu hướng. Các khối lượng công việc kinh doanh thông minh vốn hoạt động trên các chu kỳ báo cáo theo lịch trình nơi dữ liệu “current” thường có nghĩa là “as of the last ETL run” chứ không phải thời gian thực.
OSI giúp thực thi các mục tiêu cấp dịch vụ này bằng cách cung cấp giám sát, xử lý áp lực ngược và hàng đợi thư chết. Điều này duy trì lớp đồng bộ hóa như một cầu nối được quản lý, có thể quan sát được giữa bộ lưu trữ chính của bạn và các khả năng tìm kiếm nâng cao của bạn.
Kết luận
Trong bài đăng này, chúng tôi đã chỉ cho bạn cách xây dựng kiến trúc cơ sở dữ liệu JSON thống nhất bằng cách phân phối khối lượng công việc trên các dịch vụ AWS chuyên biệt. Bạn đã học được rằng bạn có thể sử dụng Amazon DynamoDB cho dữ liệu vận hành, Amazon DocumentDB cho các danh mục linh hoạt, Amazon Aurora PostgreSQL cho tính toàn vẹn giao dịch, Amazon S3 để lưu trữ data lake, Amazon Redshift để phân tích và Amazon OpenSearch Service để khám phá, tất cả đều được đồng bộ hóa thông qua OSI.
Đánh giá các khối lượng công việc JSON hiện tại của bạn và xác định các mẫu truy cập nào, vận hành, phân tích hoặc khám phá, mỗi khối lượng công việc phục vụ. Làm theo các khuyến nghị trong bài đăng này để triển khai một hệ thống phân tán nơi các dịch vụ AWS chuyên biệt xử lý các khối lượng công việc JSON theo thế mạnh của chúng. Sau khi bạn triển khai kiến trúc JSON mục tiêu của mình trong AWS, hãy chia sẻ kinh nghiệm, thách thức và chiến lược tối ưu hóa của bạn trong phần bình luận bên dưới.
Về tác giả

Ezat Karimi
Ezat là Kiến trúc sư Giải pháp Cấp cao tại AWS, có trụ sở tại Austin, TX. Ezat chuyên thiết kế và cung cấp các giải pháp và chiến lược hiện đại hóa cho các ứng dụng cơ sở dữ liệu. Làm việc chặt chẽ với nhiều nhóm AWS, Ezat giúp khách hàng di chuyển khối lượng công việc cơ sở dữ liệu của họ lên đám mây AWS.

Jon Handler
Jon là Kiến trúc sư Giải pháp Chính cấp cao tại AWS có trụ sở tại Palo Alto, CA. Jon làm việc chặt chẽ với OpenSearch và Amazon OpenSearch Service, cung cấp trợ giúp và hướng dẫn cho nhiều khách hàng có khối lượng công việc phân tích vector, tìm kiếm và nhật ký mà họ muốn chuyển sang AWS Cloud.
