Tác giả: Nilo Bustani, Rodrigue Koffi, and Alexis Perez-Mendoza
Ngày phát hành: 08 APR 2026
Chuyên mục: Amazon Managed Grafana, Amazon Managed Service for Prometheus, Management & Governance, Management Tools, Monitoring and observability
Nếu bạn đang chạy các dịch vụ như các phiên bản Amazon EC2, các container Amazon Elastic Container Service (Amazon ECS) và các cụm Amazon Managed Streaming for Apache Kafka (Amazon MSK) trong AWS, việc duy trì các Prometheus server riêng biệt cho mỗi môi trường sẽ tạo ra gánh nặng vận hành đáng kể. Việc quản lý cấu hình scraper, tính sẵn sàng cao, khả năng mở rộng và bảo mật sẽ làm bạn mất tập trung vào việc xây dựng các ứng dụng tuyệt vời.
AWS managed collector hoặc scraper của Amazon Managed Service for Prometheus giúp loại bỏ gánh nặng này. Thay vì triển khai và duy trì các Prometheus server trong mỗi môi trường, giờ đây bạn có thể sử dụng các scraper được quản lý hoàn toàn để thu thập số liệu Prometheus từ các tài nguyên được kết nối với Amazon VPC của bạn và lưu trữ chúng trong workspace của Amazon Managed Service for Prometheus. Điều này có nghĩa là bạn không còn cần phải quản lý tính sẵn sàng của collector, khả năng mở rộng hoặc sự sai lệch cấu hình.
Bài viết này sẽ hướng dẫn bạn cách triển khai AWS managed collector trên ba môi trường tính toán phổ biến: các phiên bản Amazon EC2, khối lượng công việc Amazon ECS và các cụm Amazon MSK. Bài viết này sẽ trình bày cách một dịch vụ được quản lý duy nhất có thể thay thế nhiều triển khai Prometheus tự quản lý.
Điều kiện tiên quyết và thiết lập
Trước khi bắt đầu, hãy xác minh rằng bạn đã có những điều sau:
Tài nguyên AWS:
- Một workspace của Amazon Managed Service for Prometheus
- Một Amazon VPC với các subnet riêng tư trên nhiều Availability Zone
- Quyền IAM để tạo scraper và quản lý nhóm bảo mật
- Workspace Amazon Managed Grafana (tùy chọn, để trực quan hóa)
Công cụ:
Lưu ý: Các ví dụ sử dụng Vùng US West (Oregon) us-west-2. Bạn có thể điều chỉnh các lệnh và ARN cho Vùng ưa thích của mình. Các lệnh AWS CLI sử dụng các biến shell (ví dụ: $SUBNET_ID_1, $SECURITY_GROUP_ID) làm chỗ giữ chỗ. Trước khi chạy bất kỳ lệnh nào, hãy xác minh rằng tất cả các biến đã được điền với các giá trị hợp lệ cho môi trường của bạn. Nên thử nghiệm các lệnh trong tài khoản không phải sản xuất trước.
Thu thập số liệu từ các phiên bản Amazon EC2
Các phiên bản EC2 vẫn là lựa chọn phổ biến cho các khối lượng công việc yêu cầu các loại hoặc cấu hình phiên bản cụ thể. Bạn có thể bắt đầu bằng cách cấu hình managed scraper để thu thập cả số liệu ứng dụng và số liệu cấp hệ thống từ các phiên bản EC2. Dưới đây là cách thiết lập có thể trông như thế này:
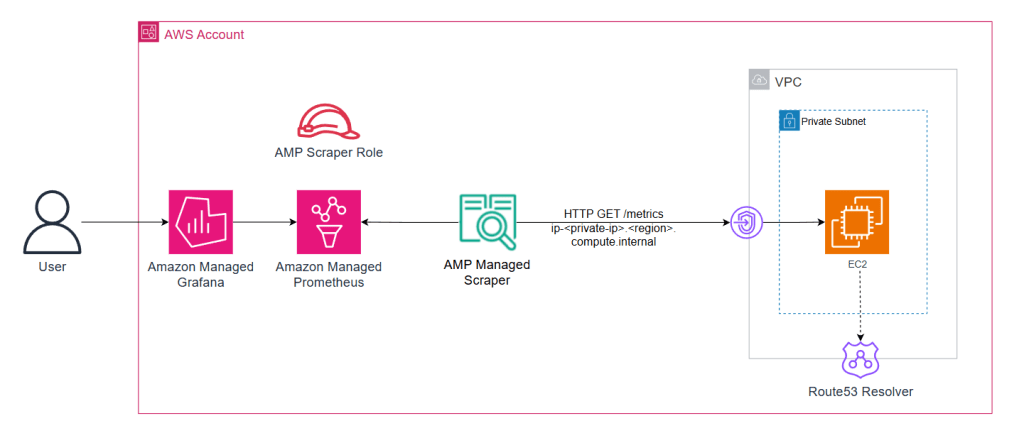
Hình 1: AWS managed-collector với khối lượng công việc chạy trên các phiên bản Amazon EC2
1. Thiết lập node exporter
Ví dụ này sử dụng Prometheus Node Exporter trên một phiên bản Amazon EC2 để hiển thị số liệu hệ thống ở định dạng Prometheus. Hãy làm theo hướng dẫn cài đặt trong tài liệu Prometheus Node Exporter.
2. Tạo cấu hình AWS managed collector
Managed scraper sẽ thu thập số liệu từ cả Node Exporter (hiển thị số liệu trên cổng mặc định 9100) và số liệu ứng dụng mẫu (hiển thị trên cổng 8080) bằng cách sử dụng cấu hình sau:
cat > /tmp/ec2-scraper.yml << EOFglobal: scrape_interval: 30s scrape_timeout: 10sscrape_configs: - job_name: 'ec2-metrics' static_configs: - targets: - ip-$IP_ADDRESS.us-west-2.compute.internal:8080 metrics_path: '/metrics' relabel_configs: - source_labels: [__address__] target_label: instance replacement: 'ec2-metrics-instance-new' - target_label: service replacement: 'ec2-metrics' - target_label: environment replacement: 'dev' metric_relabel_configs: - source_labels: [__name__] regex: '.*' action: keep - job_name: ec2-node-exporter static_configs: - targets: - ip-$IP_ADDRESS.us-west-2.compute.internal:9100EOFCONFIG_BLOB=$(base64 -w 0 /tmp/ec2-scraper.yml)
Phần relabel_configs có thể được sửa đổi để thêm các nhãn nhất quán vào số liệu của bạn, giúp dễ dàng truy vấn và lọc trên các dịch vụ khác nhau.
3. Triển khai managed scraper
aws amp create-scraper \ --alias "ec2-payment-service-scraper" \ --source '{ "vpcConfiguration": { "subnetIds": ["$SUBNET_ID_1", "$SUBNET_ID_2"], "securityGroupIds": ["$SECURITY_GROUP_ID"] } }' \ --destination '{ "ampConfiguration": { "workspaceArn": "arn:aws:aps:us-west-2:ACCOUNT_ID:workspace/ws-WORKSPACE_ID" } }' \ --scrape-configuration "{\"configurationBlob\":\"$CONFIG_BLOB\"}"
Khi bạn tạo một managed scraper, Amazon Managed Service for Prometheus tự động tạo một service-linked role (AWSServiceRoleForAmazonPrometheusScraperInternal) cấp cho scraper quyền truy cập vào tài nguyên VPC của bạn và ghi vào workspace của bạn.
4. Xác thực số liệu EC2
Trong vòng vài phút, bạn sẽ thấy số liệu chảy vào workspace Amazon Managed Service for Prometheus đích. Bạn có thể xác minh điều này trong bảng điều khiển số liệu CloudWatch hoặc bằng cách truy vấn workspace từ Amazon Managed Grafana.
Truy vấn số liệu cho job ec2-metrics:
{job="ec2-metrics"}
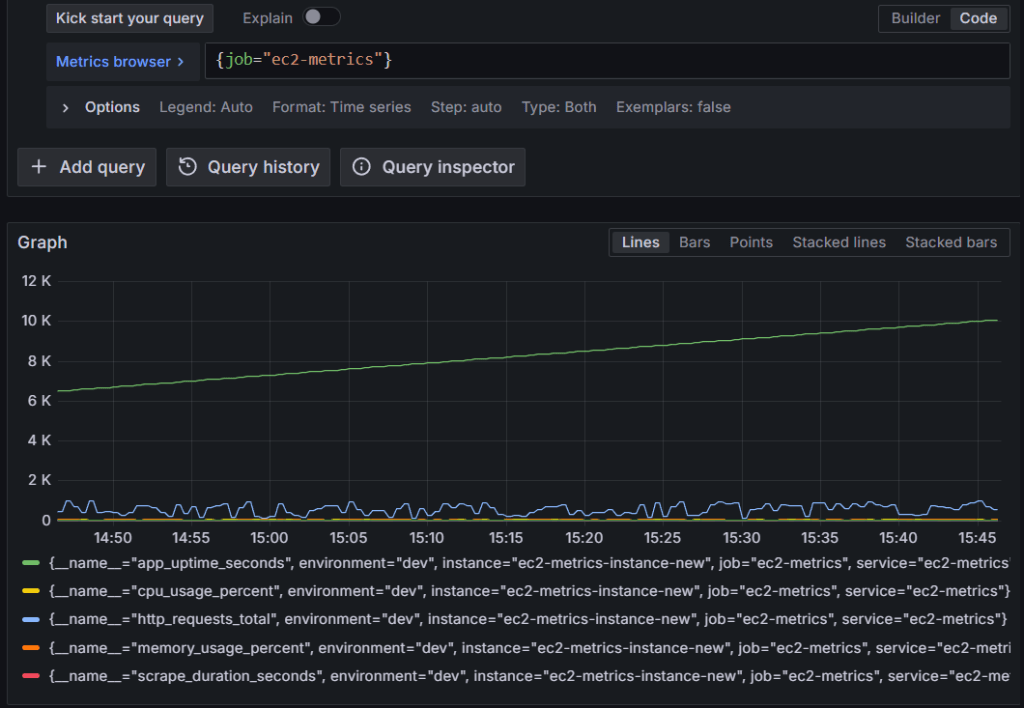
Hình 2: Truy vấn Amazon Managed Service for Prometheus để lấy số liệu EC2 từ AWS-managed collector
Giám sát khối lượng công việc ECS với khám phá dịch vụ động
Các tác vụ Amazon ECS là tạm thời, địa chỉ IP thay đổi khi các container được thay thế và các dịch vụ mở rộng động. Khám phá dịch vụ AWS Cloud Map giải quyết những thách thức này bằng cách duy trì các bản ghi DNS cho các tác vụ đang chạy, mà managed scraper tự động truy vấn.
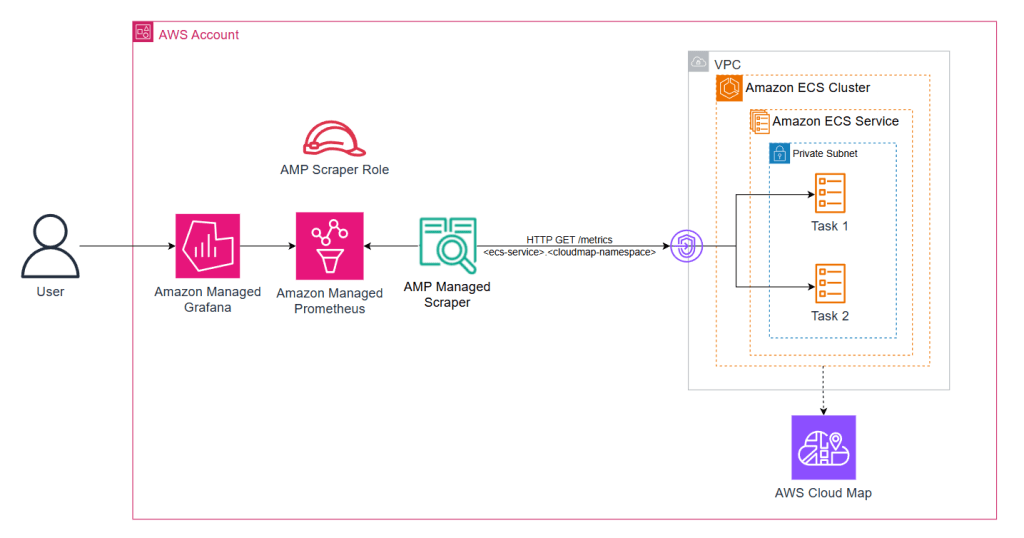
Hình 3: AWS managed-collector với khối lượng công việc chạy trên Amazon ECS
Đối với ví dụ này, dịch vụ payforadoption từ AWS One Observability Workshop được sử dụng, minh họa một microservice thực tế hiển thị số liệu Prometheus.
1. Cấu hình nhóm bảo mật
Xác nhận rằng nhóm bảo mật tác vụ ECS cho phép lưu lượng truy cập đến từ scraper:
aws ec2 authorize-security-group-ingress \ --group-id $SECURITY_GROUP_ID \ --ip-permissions IpProtocol=tcp,FromPort=80,ToPort=80,UserIdGroupPairs='[{GroupId=$SECURITY_GROUP_ID}]'
Điều này tạo ra một quy tắc tự tham chiếu, cho phép các tài nguyên trong cùng một nhóm bảo mật giao tiếp.
2. Tạo cấu hình AWS managed collector
Tạo cấu hình scraper dựa trên DNS:
cat > /tmp/ecs-scraper.yml << EOFglobal: scrape_interval: 30s scrape_timeout: 10sscrape_configs: - job_name: 'ecs-payforadoption' dns_sd_configs: - names: ['payforadoption-go.Workshop-space'] type: A port: 80 metrics_path: '/metrics' relabel_configs: - target_label: service_name replacement: 'payforadoption-go' - target_label: cloudmap_namespace replacement: 'Workshop-space' - target_label: environment replacement: 'production' - target_label: compute_platform replacement: 'ecs-fargate'EOFCONFIG_BLOB=$(base64 -w 0 /tmp/ecs-scraper.yml)
Phần dns_sd_configs cho scraper biết để truy vấn tên DNS payforadoption-go.Workshop-space và scrape tất cả các địa chỉ IP được trả về.
3. Tạo AWS managed collector
Mẫu triển khai vẫn giống như trước:
aws amp create-scraper \ --alias "ecs-payforadoption-scraper" \ --source '{ "vpcConfiguration": { "subnetIds": ["$SUBNET_ID_1", "$SUBNET_ID_2"], "securityGroupIds": ["$SECURITY_GROUP_ID"] } }' \ --destination '{ "ampConfiguration": { "workspaceArn": "arn:aws:aps:us-west-2:ACCOUNT_ID:workspace/ws-WORKSPACE_ID" } }' \ --scrape-configuration "{\"configurationBlob\":\"$CONFIG_BLOB\"}"
Khi Amazon ECS thay thế một tác vụ, scraper sẽ nhận các thay đổi trong truy vấn DNS tiếp theo của nó (thường là mỗi 30 giây), hỗ trợ thu thập số liệu liên tục mà không cần can thiệp thủ công.
4. Xác thực số liệu Amazon ECS
Chạy một truy vấn. Ví dụ, hiển thị tốc độ yêu cầu trung bình mỗi giây đến tác vụ ECS trong 5 phút qua:
rate(payforadoption_requests_total[5m])
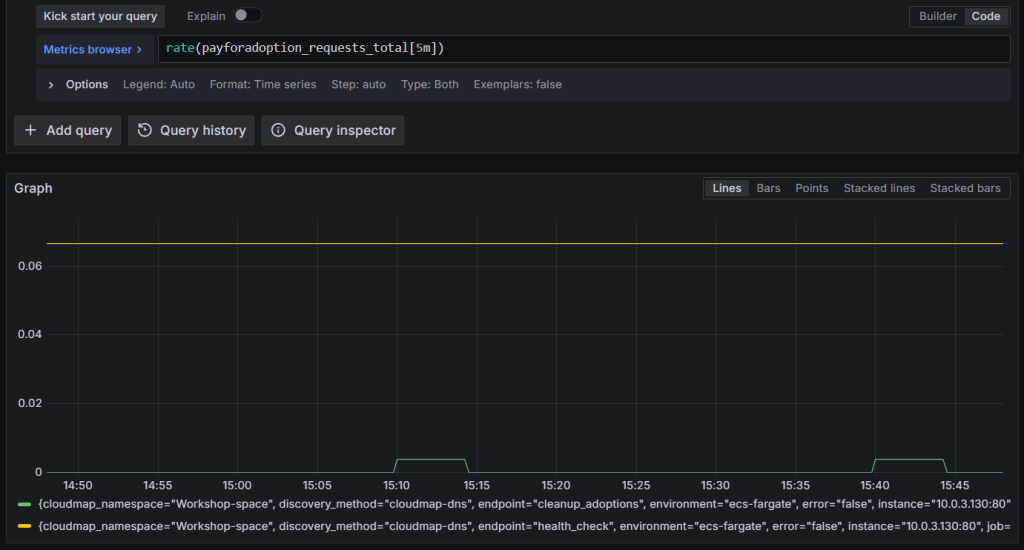
Hình 4: Truy vấn Amazon Managed Service for Prometheus để lấy số liệu ECS
Thu thập số liệu Prometheus từ các cụm Amazon MSK
Giám sát tình trạng cụm Amazon MSK là rất quan trọng đối với các kiến trúc hướng sự kiện. Các cụm Amazon MSK hiển thị hai loại số liệu thông qua Prometheus exporter khi bạn bật OpenMonitoring: JMX Exporter cho các số liệu cụ thể của Kafka (chủ đề, phân vùng, độ trễ của consumer) và Node Exporter cho các số liệu hệ thống của broker (CPU, bộ nhớ, đĩa).
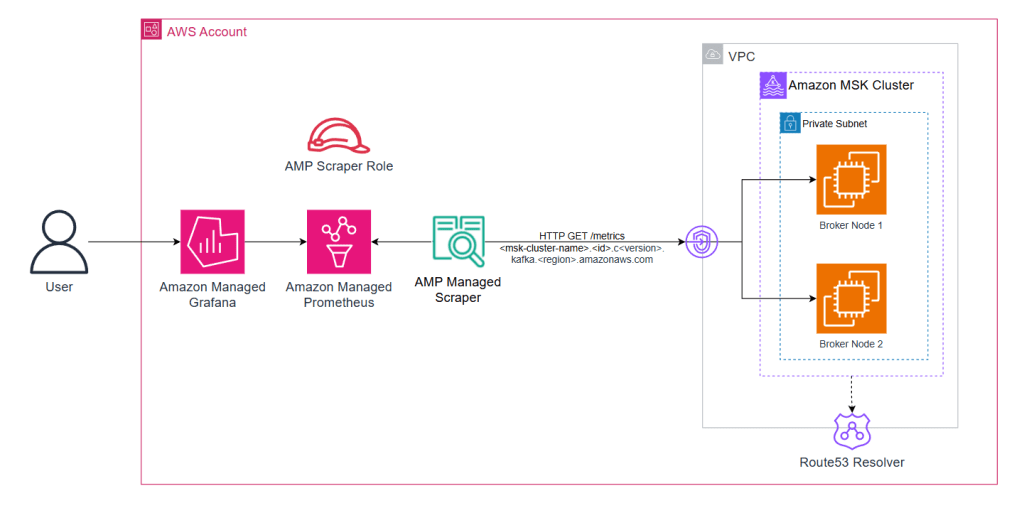
Hình 5: AWS managed-collector với khối lượng công việc chạy trên Amazon MSK
1. Bật OpenMonitoring trên các cụm Amazon MSK
Lệnh sau bật cả hai exporter trên tất cả các node broker. JMX Exporter lắng nghe trên cổng 11001 và Node Exporter trên cổng 11002:
aws kafka update-monitoring \ --cluster-arn "arn:aws:kafka:REGION:ACCOUNT_ID:cluster/metrics-msk-cluster/CLUSTER_ID" \ --current-version "CURRENT_VERSION" \ --open-monitoring '{ "Prometheus": { "JmxExporter": {"EnabledInBroker": true}, "NodeExporter": {"EnabledInBroker": true} } }' \ --enhanced-monitoring PER_TOPIC_PER_PARTITION
2. Triển khai scraper cho Amazon MSK
Amazon MSK cung cấp một tên DNS cấp cụm phân giải thành tất cả các IP của broker. Sử dụng điều này để khám phá dịch vụ giúp việc giám sát của bạn có khả năng phục hồi trước việc thay thế broker và mở rộng cụm.
Lấy tên DNS của cụm của bạn (xóa tiền tố cụ thể của broker như b-1. hoặc b-2.):
CLUSTER_DNS="metricsmskcluster.xxxx.xxx.kafka.REGION.amazonaws.com"cat > /tmp/msk-scraper.yml << EOFglobal: scrape_interval: 30s external_labels: cluster_name: metrics-msk-clusterscrape_configs: - job_name: msk-jmx scheme: http metrics_path: /metrics scrape_timeout: 10s dns_sd_configs: - names: - $CLUSTER_DNS type: A port: 11001 relabel_configs: - source_labels: [__meta_dns_name] target_label: broker_dns - source_labels: [__address__] target_label: instance - target_label: compute_platform replacement: 'msk' - job_name: msk-node scheme: http metrics_path: /metrics scrape_timeout: 10s dns_sd_configs: - names: - CLUSTER_DNS type: A port: 11002 relabel_configs: - source_labels: [__meta_dns_name] target_label: broker_dns - source_labels: [__address__] target_label: instance - target_label: compute_platform replacement: 'msk'EOFCONFIG_BLOB=$(base64 -w 0 /tmp/msk-scraper.yml)
3. Tạo AWS managed collector
Các broker Amazon MSK cần cho phép lưu lượng truy cập đến từ scraper trên cả hai cổng exporter. Sau đó, bạn sẽ triển khai cấu hình scraper:
SCRAPER_SG=$(aws cloudformation describe-stacks \ --stack-name msk-metrics-stack \ --query 'Stacks[0].Outputs[?OutputKey==`PrometheusScraperSecurityGroupId`].OutputValue' \ --output text)aws amp create-scraper \ --alias "msk-metrics-scraper" \ --source "{\"vpcConfiguration\":{\"subnetIds\":[\"subnet-xxx\",\"subnet-yyy\"],\"securityGroupIds\":[\"$SCRAPER_SG\"]}}" \ --destination "{\"ampConfiguration\":{\"workspaceArn\":\"arn:aws:aps:us-west-2:ACCOUNT_ID:workspace/ws-WORKSPACE_ID\"}}" \ --scrape-configuration "{\"configurationBlob\":\"$CONFIG_BLOB\"}"
4. Xác minh số liệu Amazon MSK
Trong vòng vài phút, bạn bắt đầu thấy độ trễ của consumer, số lượng phân vùng, mức sử dụng tài nguyên broker và các số liệu MSK khác mà không cần quản lý bất kỳ hạ tầng Prometheus nào.
Chạy một truy vấn. Ví dụ, hiển thị thông lượng broker tổng thể trên tất cả các chủ đề bằng cách sử dụng:
kafka_server_BrokerTopicMetrics_MeanRate
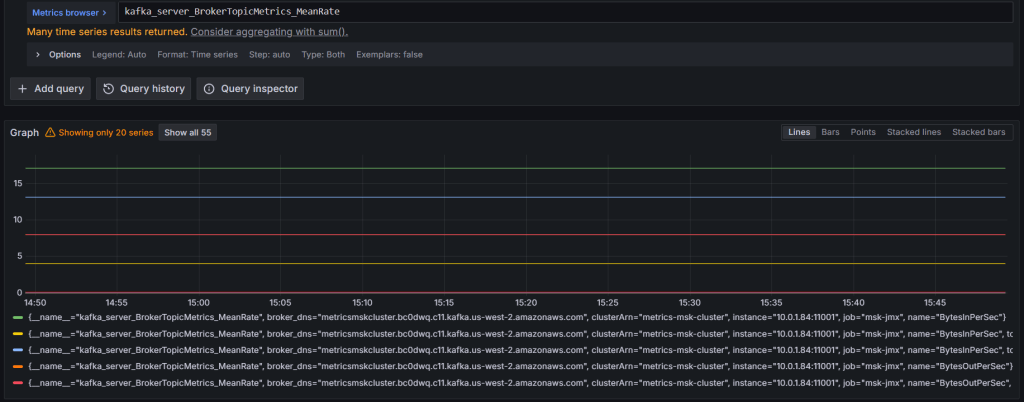
Hình 6: Truy vấn Amazon Managed Service for Prometheus để lấy số liệu Amazon MSK
Tổng hợp tất cả
Giờ đây bạn đã có số liệu từ EC2, ECS và MSK, bạn có thể hợp nhất việc truy vấn và cảnh báo trên toàn bộ hạ tầng của mình. Bạn có thể kết nối một workspace Amazon Managed Grafana với workspace Amazon Managed Service for Prometheus làm nguồn dữ liệu và viết các truy vấn PromQL bao gồm cả ba nền tảng tính toán:
Truy vấn tổng tốc độ yêu cầu trên tất cả các dịch vụ:
sum(rate({__name__=~"http_requests_total|payforadoption_requests_total"}[5m])) by (environment, service)
Điều này tổng hợp tốc độ yêu cầu HTTP từ phiên bản EC2 và dịch vụ ECS, được nhóm theo dịch vụ và nền tảng.
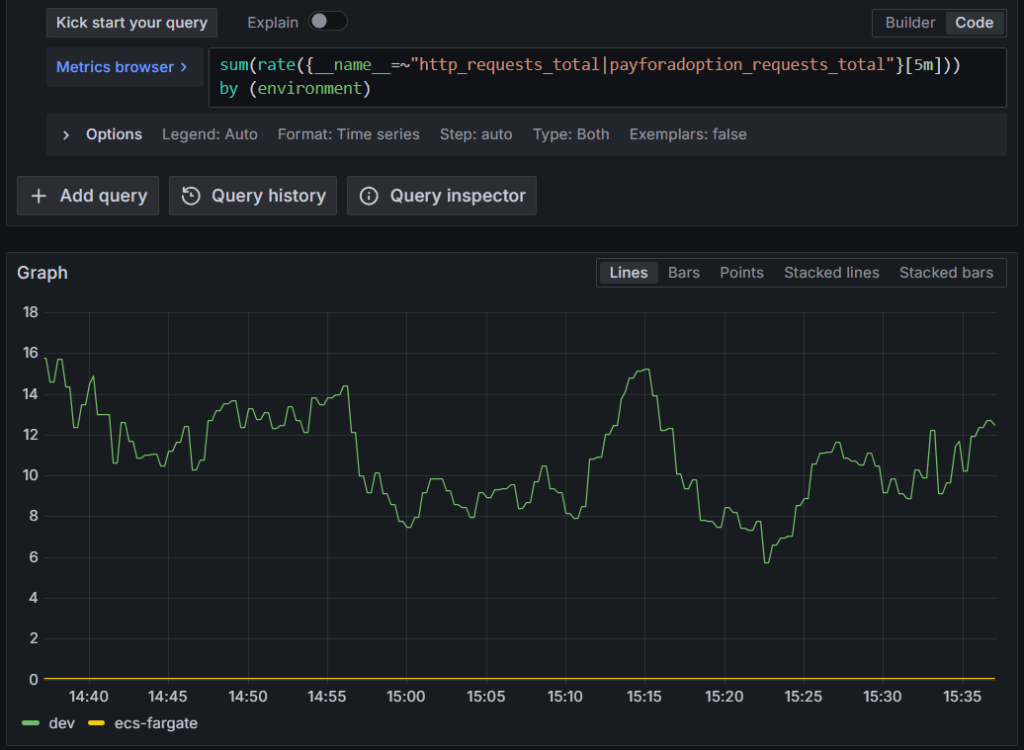
Hình 7: Truy vấn Amazon Managed Service for Prometheus để lấy tổng tốc độ yêu cầu trên tất cả các dịch vụ
Giám sát mức sử dụng CPU trên các loại tính toán:
Truy vấn này hoạt động giống hệt nhau cho các phiên bản EC2 và broker MSK vì cả hai đều hiển thị số liệu Node Exporter với cùng quy ước đặt tên.
100 - (avg by (instance, job) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
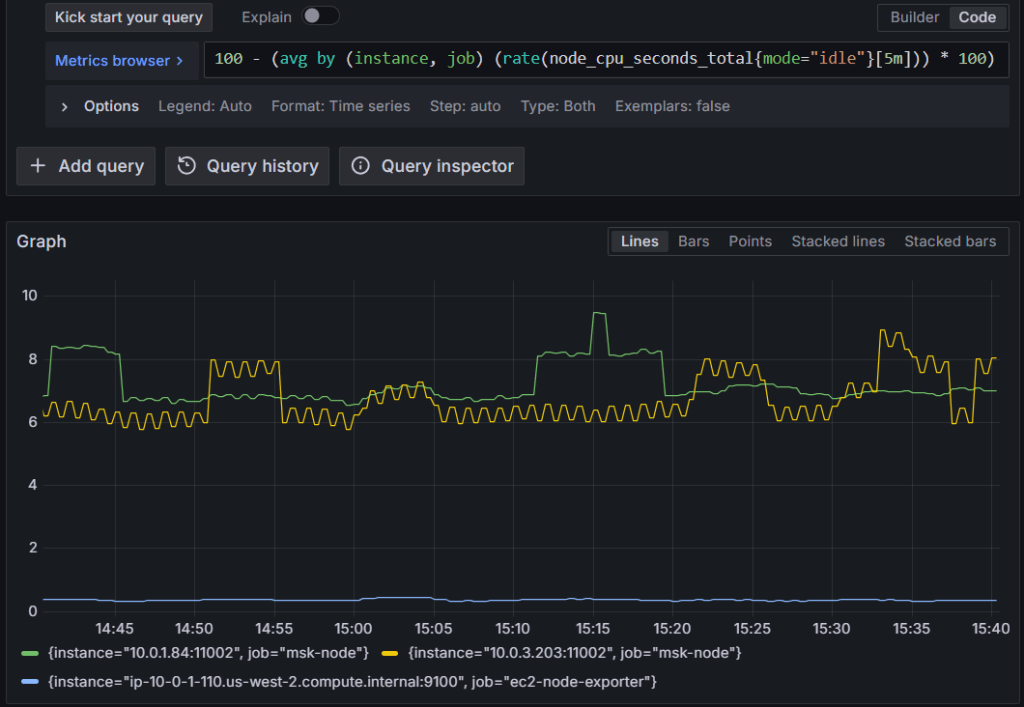
Hình 8: Truy vấn Amazon Managed Service for Prometheus để lấy mức sử dụng CPU trên tất cả các loại tính toán
Theo dõi độ trễ của Kafka consumer cho các consumer ECS:
Điều này giúp bạn xác định xem các Amazon MSK consumer của bạn có theo kịp việc sản xuất tin nhắn hay không.
sum(kafka_consumer_group_ConsumerLagMetrics_Value) by (groupId, topic)
Cảnh báo đa dịch vụ
Bạn có thể định nghĩa các cảnh báo bao gồm toàn bộ hạ tầng. Ví dụ, cảnh báo khi độ trễ của consumer vượt quá ngưỡng VÀ tốc độ lỗi của dịch vụ tiêu thụ tăng lên:
( sum(kafka_consumer_group_ConsumerLagMetrics_Value{topic="payment-processor"}) > 10000 and rate(http_requests_total{service_name="payment-api",status=~"5.."}[5m]) > 0.01)
Việc tương quan số liệu Kafka với số liệu ứng dụng có thể giúp bạn xác định nguyên nhân gốc rễ nhanh hơn và giảm thời gian trung bình để khắc phục sự cố.
Các cân nhắc về bảo mật
- Theo Mô hình Trách nhiệm Chung của AWS, AWS quản lý bảo mật của hạ tầng managed scraper trong khi bạn chịu trách nhiệm cấu hình quyền truy cập an toàn vào tài nguyên của mình.
- Triển khai các chính sách IAM với quyền hạn tối thiểu. Mỗi scraper đảm nhận một IAM role. Hãy tuân thủ nguyên tắc quyền hạn tối thiểu bằng cách chỉ cấp các quyền cần thiết:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "aps:RemoteWrite" ], "Resource": "arn:aws:aps:us-west-2:ACCOUNT_ID:workspace/ws-WORKSPACE_ID" } ]}
- Hạn chế ingress của nhóm bảo mật chỉ cho nhóm bảo mật của scraper trên các cổng exporter cụ thể
- Triển khai scraper trong các subnet riêng tư và sử dụng VPC endpoint cho Amazon Managed Service for Prometheus để giữ lưu lượng truy cập trong VPC của bạn
- Dữ liệu được gửi từ scraper đến workspace Amazon Managed Service for Prometheus được mã hóa trong quá trình truyền bằng TLS
- Scraper giao tiếp với các mục tiêu qua mạng riêng của VPC của bạn. Bạn có thể cấu hình TLS trên các exporter của mình bằng cách sử dụng
scheme: httpsđể bảo vệ bổ sung - Số liệu được lưu trữ trong Amazon Managed Service for Prometheus được mã hóa khi lưu trữ theo mặc định. Bạn có thể tùy chọn sử dụng khóa do khách hàng quản lý để kiểm soát bổ sung
- Bật ghi nhật ký scraper vào Amazon CloudWatch Logs để kiểm tra và khắc phục sự cố
Các phương pháp hay nhất cho triển khai sản xuất
Dựa trên các triển khai thực tế, dưới đây là các phương pháp hay nhất quan trọng để đảm bảo việc thu thập số liệu đáng tin cậy, an toàn và có khả năng mở rộng:
- Đối với khối lượng công việc EC2, hãy cân nhắc di chuyển từ các mục tiêu tĩnh sang khám phá dịch vụ dựa trên DNS bằng cách sử dụng chỉ thị
dns_sd_configstrong cấu hình scraper của bạn và đăng ký các phiên bản EC2 của bạn trong AWS Cloud Map. - Triển khai nhiều scraper khi bạn có các mục tiêu với vòng đời, mẫu truy cập hoặc rủi ro bảo mật khác nhau để cách ly, bảo mật và linh hoạt vận hành tốt hơn
- Đặt khoảng thời gian scrape thích hợp để cân bằng độ chi tiết của số liệu với chi phí và hiệu suất:
- 30 giây: Mặc định tốt cho hầu hết các số liệu ứng dụng
- 60 giây: Đủ cho các số liệu hạ tầng (CPU, bộ nhớ)
- 90 giây+: Môi trường phi sản xuất hoặc các ứng dụng có thông lượng thấp
- Hãy nhớ rằng việc giảm một nửa khoảng thời gian scrape sẽ tăng gấp đôi chi phí nhập dữ liệu của bạn
- Loại bỏ các số liệu nhiễu bằng cấu hình relabel
metric_relabel_configs: - source_labels: [__name__] regex: '.*_debug_.*' action: drop
Dọn dẹp
Để tránh phát sinh chi phí liên tục, hãy xóa các tài nguyên được tạo trong quá trình hướng dẫn này khi chúng không còn cần thiết.
Xóa các managed scraper bằng AWS CLI:
aws amp list-scrapersaws amp delete-scraper --scraper-id $SCRAPER_ID
Ngoài ra, hãy xóa workspace Amazon Managed Service for Prometheus nếu nó được tạo cho mục đích thử nghiệm:
aws amp delete-workspace --workspace-id $WORKSPACE_ID
Nếu bạn đã triển khai các tài nguyên hỗ trợ như các phiên bản EC2, dịch vụ ECS, cụm MSK, nhóm bảo mật hoặc workspace Amazon Managed Grafana đặc biệt cho hướng dẫn này, hãy xóa chúng để ngừng tất cả các chi phí liên quan.
Kết luận
Bài viết này đã hướng dẫn cách triển khai AWS managed collector của Amazon Managed Service for Prometheus trên ba môi trường tính toán riêng biệt — Amazon EC2, Amazon ECS và các cụm Amazon MSK — chứng minh cách một dịch vụ được quản lý duy nhất có thể thay thế nhiều triển khai Prometheus tự quản lý. Bằng cách sử dụng khám phá dịch vụ dựa trên DNS, các chiến lược gắn nhãn nhất quán và truy vấn hợp nhất trong Grafana, bạn có thể xây dựng một giải pháp quan sát toàn diện mà không phải chịu gánh nặng vận hành của việc quản lý hạ tầng scraper.
Các lợi ích chính của phương pháp này:
- Giảm gánh nặng vận hành: Không cần vá lỗi, mở rộng hoặc giám sát các Prometheus server
- Khả năng phục hồi tự động: Khám phá dựa trên DNS tự động thích ứng với các thay đổi hạ tầng
- Quan sát hợp nhất: Truy vấn số liệu trên tất cả các nền tảng tính toán từ một giao diện duy nhất
- Tối ưu hóa chi phí: Thanh toán hợp nhất và lọc số liệu dễ dàng giúp giảm chi phí
- Bảo mật: Dịch vụ được quản lý xử lý bảo mật hạ tầng trong khi bạn kiểm soát các chính sách truy cập
Cho dù bạn đang chạy kiến trúc lai trên nhiều loại tính toán hay đang có kế hoạch di chuyển giữa các nền tảng, AWS managed collector của Amazon Managed Service for Prometheus cung cấp sự linh hoạt và độ tin cậy mà bạn cần cho khả năng quan sát sản xuất.
Các bước tiếp theo
Sẵn sàng triển khai điều này trong môi trường của bạn? Dưới đây là một số tài nguyên để bắt đầu:
- Tài liệu Amazon Managed Service for Prometheus
- Tham chiếu API của AWS managed collectors
- AWS One Observability Workshop – Các phòng thí nghiệm thực hành
- Các phương pháp hay nhất về cấu hình Prometheus
- Tài liệu Amazon Managed Grafana
Có câu hỏi hoặc muốn chia sẻ triển khai của bạn? Hãy để lại bình luận bên dưới hoặc liên hệ với nhóm quan sát của AWS thông qua nhóm tài khoản của bạn.
Về tác giả

Nilo Bustani
Nilo Bustani là Kiến trúc sư Giải pháp Cấp cao tại AWS với hơn 20 năm kinh nghiệm trong phát triển ứng dụng, kiến trúc đám mây và lãnh đạo kỹ thuật. Cô chuyên giúp khách hàng xây dựng các chiến lược quan sát mạnh mẽ và thực hành quản trị trên các môi trường lai và đa đám mây. Cô tận tâm trao quyền cho các tổ chức bằng các công cụ và thực tiễn cần thiết để thành công trong hành trình chuyển đổi đám mây và AI của họ.

Rodrigue Koffi
Rodrigue là Kiến trúc sư Giải pháp Chuyên gia về Khả năng Quan sát tại Amazon Web Services. Anh đam mê khả năng quan sát, hệ thống phân tán và học máy. Anh có nền tảng vững chắc về DevOps và phát triển phần mềm, đồng thời yêu thích lập trình bằng Go. Ngoài công việc, Rodrigue thích bơi lội và dành thời gian chất lượng bên gia đình. Tìm anh ấy trên LinkedIn tại /grkoffi

Alexis Perez-Mendoza
Alexis là Kỹ sư Phát triển Phần mềm tại AWS, chuyên về các giải pháp Khả năng Quan sát Mã nguồn Mở. Anh đóng góp vào các sáng kiến quan sát hàng đầu của AWS, bao gồm AWS Managed Service for Prometheus (AMP) và tích hợp liền mạch với Amazon CloudWatch. Alexis thiết kế và mở rộng các hệ thống phân tán, kiến trúc các giải pháp giúp khách hàng giám sát, khắc phục sự cố và tối ưu hóa ứng dụng của họ một cách chính xác.
